基于编辑距离纯逻辑实现相似地址聚类
需求背景:

香港公司发来的账单中,有很多相对的地址却使用的不同的派送方式采用了不同的收费,这部分数据明显存在问题需要与香港公司进行确认。所以我们需要将所有相同的地址聚类在一起判断为相同的地址。
上图中展示了一种极度简单的情况,只需要将文本所有空格去掉即可找出来,但是部分地址是仅仅差几个汉字字符仍然是相同的地址,为了最高的准确度我们使用编辑距离计算地址间的相似度更佳。
前面已经写过一篇文章:《相似文本聚类与调参》
这篇文章的方法优势在于几百万条地址数据时也能快速计算出结果,但是不调参的情况下准确性一般,调参操作比较复杂。
不过今天我们需要处理的地址数量在几万以内,不是特别多,所以完全可以使用编辑距离算法暴力遍历。
首先我们读取数据:
import pandas as pd
df = pd.read_csv("相似地址.csv")
df
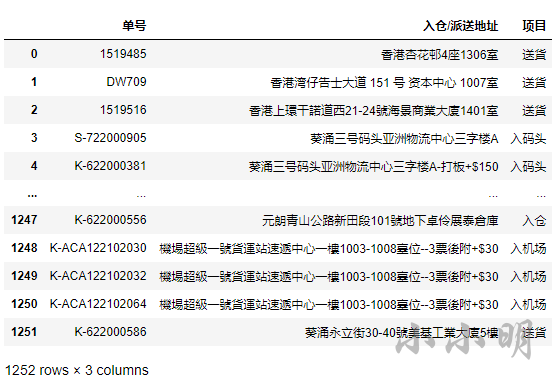
为了提高识别的准确率,我们可以事先对地址数据作一些预处理,经观察可以看到部分地址包含小数点、空白字符以及最后面的附加费用信息,例如:
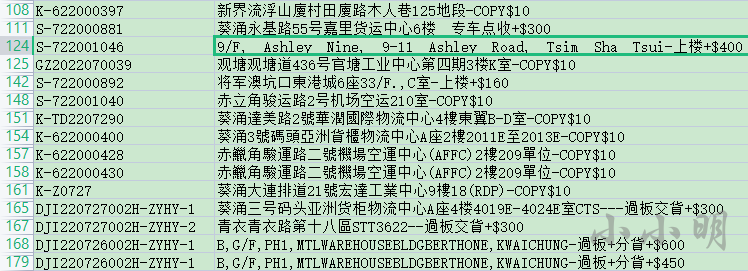
我们可以通过代码将其替换掉:
import re
# 去除小数点和空白字符
df["入仓/派送地址"] = df["入仓/派送地址"].str.replace("[\.\s]+", "", regex=True)
# 五个以上汉字之前的-可以删除
df["入仓/派送地址"] = df["入仓/派送地址"].str.replace(
"-+([一-龟]{5,})", r"\1", regex=True)
# -后面不是数字或字母,则-后面的全部去掉
df["入仓/派送地址"] = df["入仓/派送地址"].str.replace("-+[^\da-zA-Z].*$", "", regex=True)
# copy后面的全部去掉
df["入仓/派送地址"] = df["入仓/派送地址"].str.replace(
"[-+]*COPY.+$", "", flags=re.IGNORECASE, regex=True)
# $ 标识后面的全部去掉
df["入仓/派送地址"] = df["入仓/派送地址"].str.replace("[-+]*\$.+$", "", regex=True)
# +标识后面带数字的全部去掉
df["入仓/派送地址"] = df["入仓/派送地址"].str.replace("\+\d.+$", "", regex=True)
df
可以清晰的看到,对应的非地址数据已经被清理:
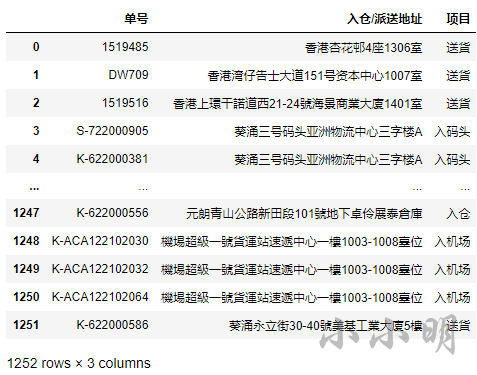
各位读取应该根据数据的实际情况编写正则清理非地址数据。
下面我们基于编辑距离开始对相似地址聚类,这里我们需要先安装fuzz:
pip install fuzzywuzzy
然后就可以使用内部计算编辑距离的类:
from Levenshtein._levenshtein import ratio
ratio("葵涌永立街30-40號美基工業大廈5樓", "葵涌永立街30-40號美基工業大廈五樓")
0.9473684210526315
开始计算,这里我们定义相似度超过0.7的地址被认为是相同的地址:
from Levenshtein._levenshtein import ratio
nums = {}
addrs = df["入仓/派送地址"].values
x = 0
for i in range(addrs.shape[0]-1):
for j in range(i+1, addrs.shape[0]):
if i in nums and j in nums:
continue
if ratio(addrs[i], addrs[j]) >= 0.7:
num = nums.get(i, nums.get(j))
if num is None:
num = x
x += 1
nums[i] = nums[j] = num
len(nums), x
(689, 184)
仅0.5秒的时间已经计算出结果,共689地址出现重复,其中有183个不同的地址。
然后我们可以排序并保存结果:
df["重复编号"] = pd.Series(nums)
df = df.convert_dtypes()
df.sort_values("重复编号", inplace=True)
df.to_excel("相似地址聚类.xlsx", index=False)

可以看到一些比较相似的地方都被顺利找到。