detectron2的简介和配置
-
detectron2的简介和配置
前言:距离上一篇博客过了两年,几近放弃DL和RL这非常有趣的领域,近日重拾DL,在摸索中打算整理一下深度学习框架,争取做到“探索”和“利用“相统一hhh,还是要紧跟潮流啊。因为重装了一遍服务器并且更新了显卡驱动,很多基础的库需要重新安装。
下一篇博客detectron2的结构介绍及代码实现_d948142375的博客-CSDN博客介绍了DET2的关键代码,并贴了我的代码,实现了“客制化数据集注册-训练-测试”的流程,没写训练中进行评估,若有错欢迎指出。
如果小伙伴们踩到了新坑或者我写错了的地方,欢迎提出,谢谢。
detectron2简介(以下简称DET2)
detectron2是facebook AI research(FAIR)重构detectron的深度学习框架,是2020年最火的深度学习框架(另外还有mmdetection,simpledet,目标检测三大开源神器:Detectron2/mmDetection/SimpleDet - 知乎 (zhihu.com))。detectron2从基于caffe重构为完全基于pytorch,集成了先进的目标检测和语义分割算法,并有一大批预训练好的模型,即插即用十分方便,包含:
1. faster-RCNN (pytorch版的faster-RCNN是端到端实现的,而不是论文中提到的交替训练),这里我没有看源码,不过应该是把RPN和fast-RCNN实现联合训练的优化之后的版本。——目标检测,COCO数据集预训练
2. retina-net——目标检测,COCO
3. RPN+fast-RCNN——目标检测,COCO
4. mask-RCNN——实例分割,COCO,LVIS
5. keypoint-RCNN——姿态检测,COCO
6. panoptic-FPN——全景分割,COCO
7. 其它
全部模型地址:detectron2/model_zoo.py at master · facebookresearch/detectron2 · GitHub
其中,预训练模型(weights)、超参数(config)均可从该项目的model_zoo下载。
支持docker。
框架或模型若用于研究,请加上FAIR的标签:
@misc{wu2019detectron2,
author = {Yuxin Wu and Alexander Kirillov and Francisco Massa and
Wan-Yen Lo and Ross Girshick},
title = {Detectron2},
howpublished = {\url{https://github.com/facebookresearch/detectron2}},
year = {2019}
}配置detectron2(ubuntu,conda)
我配的V**,下不动或打不开网页的考虑配一个,以下均为V**连接下的可用方法。
DET2的github地址:GitHub - facebookresearch/detectron2: Detectron2 is FAIR's next-generation platform for object detection, segmentation and other visual recognition tasks.
tutorials:Installation — detectron2 0.4 documentation
要求:python >=3.6,pytorch>=1.6并有匹配版本的pytorch。但是鉴于opencv,建议使用python=3.6创建虚拟环境。
如何安装对应版本的pytorch:PyTorch,给出了匹配本机配置的指令,复制对应指令到终端即可,注意在自己的虚拟环境下做。内容很大,提前配置好清华源。
建议:安装opencv,可视化用。
conda添加清华源:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --set show_channel_urls yes
配置pytorch等
需要在 PyTorch 中找到自己对应版本的指令,终端输入即可,东西大但是下载挺快的,耐心等待。
配置cuda
先确保你的显卡驱动是正常的,输入nvidia-smi或进入/proc/driver,打开version文件查看你的显卡驱动。显卡驱动及匹配的cuda版本列表在这里:Release Notes :: CUDA Toolkit Documentation (nvidia.com),或是输入ubuntu-drivers devices查看当前环境支持的驱动列表,然后输入sudo ubuntu-drivers autoinstall安装系统建议的显卡驱动版本(保险起见,退出你的虚拟环境,以及查看是否和你需要的cuda匹配,并安装指定版本,注意不要随便apt-upgrade,若是老版本显卡驱动,随便更新将导致linux内核的更新,从而使得显卡驱动与内核版本不匹配使得显卡驱动失效)
由于本机是在conda环境下进行配置,终端输入:conda search cudatoolkit 及 conda search cudnn 查看conda库内的cudatoolkit和cudnn版本,无需考虑本机自带cudatoolkit和cudnn(因为是在虚拟环境下配置),但是需要考虑cudatoolkit和cudnn版本匹配,以及cuda和显卡驱动版本匹配。对照:cuDNN Archive | NVIDIA Developer 查看版本匹配
或直接输入conda install cudatoolkit cudnn,自动匹配安装。
conda list查看当前虚拟环境的cuda版本(cudatoolkit)和cudnn版本,到 PyTorch 选择对应版本的conda安装指令。
配置opencv
输入:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ opencv-contrib-python
从清华源安装opencv-contrib版,一步到位。
安装detectron2,其它库
tutorials: Installation — detectron2 0.4 documentation
先pip一下:google-colab,值得注意的是,我现在的DET2版本(2021.06.21)的依赖库互相有冲突,估计是官方偷懒了。存在有以下两个冲突:
1. google-colab=1.0.0需求google-auth~=1.4.0,但是tensorboard=2.5.0需求google-auth在1.6.3到2.0之间,只能先保证google-colab了。所以这里应当先:
pip install google-auth==1.4.0
若不先pip这里,后续将自动安装google-auth=1.3.1,还是会报错。
2. DET2可以用onnx来转换pytorch的pth文件到onnx文件,onnx文件可以进一步转化为其它框架的文件例如tensorflow的pb文件。但是onnx所需tensorflow的稳定版本为2.x,而装tensorflow=2.x又有几个坑。如直接使用torch.onnx进行文件转换,可能将报错,原因是onnx调用的是tensorflow=2.x的API,但是当前环境安装的是tensorflow=1.x。不过,安装tensorflow=2.x存在限制,已知的是tensorflow=2.2可以正常使用onnx,tensorflow=2.x的其它版本可能存在问题。此外,tensorflow=2.x基于cpu扩展指令集avx2,太老的cpu或是一些奇怪的cpu可能并不支持,当报tensorflow=2.x的错误且无法解决时,应当查看自己cpu所支持的指令集是否包含avx2。
接下来,安装DET2的剩余依赖库,当你第一次install DET2时,会自动配置相关库,但是其中仍然有些坑。
终端输入下列代码即可
python -m pip install 'git+https://github.com/facebookresearch/detectron2.git'
# (add --user if you don't have permission)
# Or, to install it from a local clone:
git clone https://github.com/facebookresearch/detectron2.git
python -m pip install -e detectron2
# On macOS, you may need to prepend the above commands with a few environment variables:
CC=clang CXX=clang++ ARCHFLAGS="-arch x86_64" python -m pip install ...To rebuild detectron2 that’s built from a local clone, use rm -rf build/ **/*.so to clean the old build first. You often need to rebuild detectron2 after reinstalling PyTorch.
重装pytorch之后需要删除之前build的文件。当你出现各类奇怪的问题无法解决时,若曾更改过pytorch版本等,或是强行中断过一些库的安装等操作,建议如上删除build镜像,若必要时,建议直接删除虚拟环境并重新按照本文进行配置。
本机先git clone的DET2源码,然后build的,过程中会自动安装一些依赖库,以下库下载较慢,
建议预先conda一下以下几个包:matplotlib,tensorboard,以及万恶之源opencv。
此外,你还需要conda一下:tqdm
至此,我在自己的虚拟环境下python了一下demo:
cd demo/
python demo.py --config-file ../configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml \
--input input1.jpg input2.jpg \
[--other-options]
--opts MODEL.WEIGHTS detectron2://COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x/137849600/model_final_f10217.pkl其中,yaml文件可以在detectron2目录下找到,但是pkl需要下载,非常的慢,我只验证流程是否正常,可以不加opt这一句。我进行了实例分割demo测试,可以返回一张图片和测试结果:
![]()
我报了1个错误和1个警告,经查和前文配置无关,有报类似错误的可作参考:
错误:
qt.qpa.xcb: could not connect to display
qt.qpa.plugin: Could not load the Qt platform plugin "xcb" in "/home/wudi/anaconda3/envs/det2/lib/python3.6/site-packages/cv2/qt/plugins" even though it was found.
This application failed to start because no Qt platform plugin could be initialized. Reinstalling the application may fix this problem.
警告:
/home/wudi/anaconda3/envs/det2/lib/python3.6/multiprocessing/semaphore_tracker.py:143: UserWarning: semaphore_tracker: There appear to be 1 leaked semaphores to clean up at shutdown
len(cache))
关于错误:本机使用了pycharm连接服务器进行远程调试,当切换到服务器远程桌面时,本错误消失,应当是因为pycharm的远程通信相关的问题(可能是xserver),或是建议直接用ssh连接进行调试,无伤大雅。
关于警告:查看了demo.py的源码以后,发现demo的功能主要由另一个文件predictor.py实现,而这个predictor则使用的是cpu的多线程,由于本服务器cpu有特殊性,所以这个警告应当是本机出现的个例,如果你仍有同类问题,建议复制并搜索本警告,尝试shm内存分配的解决方案。
以上是从源码建立一个detectron2项目大致的全部流程,另外还有docker版的和colab版的,以及prebuild版的,我还没有玩过,可能以后会搞一下docker版的。至此,detectron2的安装编译已完成,本文后续只做错误修正。
下一篇我会介绍detectron2框架的几份切入代码,若你仔细阅读了下一篇博客,了解过我提到的代码逻辑,你将有能力独立建立 客制化voc数据集——训练——测试 的流程。本系列文章不是指导性文章,仅作本人从无到有的踩坑实录,尽可能做到依照本系列文章便可以将detectron2从一无所知到进入应用,如有错误,期望指出。
以下为踩过的坑,本机在conda虚拟环境下实验,并不需要进行以下步骤配置环境,且这一版本cuDNN最后并未安装成功(并无必要)。
本人的理解如有错误,请以这篇文章为准:显卡,显卡驱动,nvcc, cuda driver,cudatoolkit,cudnn到底是什么? - marsggbo - 博客园 (cnblogs.com)
![]() 本机虚拟环境的cuda是10.2+7.6 (conda list)
本机虚拟环境的cuda是10.2+7.6 (conda list)
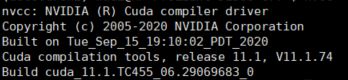 本机运行cuda是11.1 (nvcc -V)
本机运行cuda是11.1 (nvcc -V)
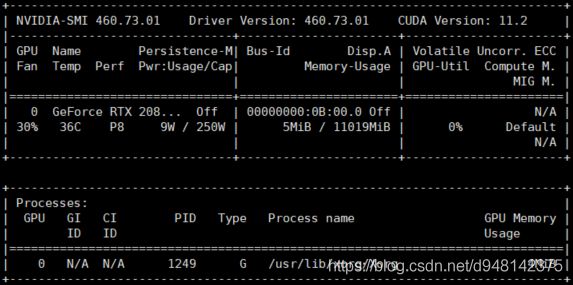 本机显卡驱动是460,最高适配cuda是11.2 (nvidia-smi)
本机显卡驱动是460,最高适配cuda是11.2 (nvidia-smi)
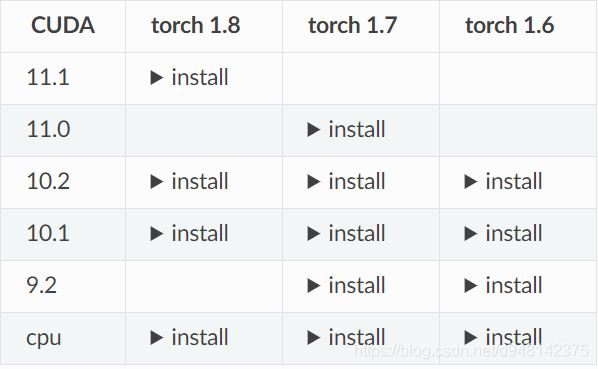 注意下自己的版本匹配,例如本机是10.2+1.8
注意下自己的版本匹配,例如本机是10.2+1.8
cudatoolkit安装
多用nvidia-smi,看本机显卡驱动版本,和CUDA Version(注意是最高适用CUDA版本,而不是本机版本,本机可能尚未安装CUDA)。
特别的,截至2021.05,对于CUDA11.1的小伙伴,安装cudatoolkit应当加入-c nvidia指定nvidia源(土豆中的战斗土豆,CUDA10的小伙伴正常装即可),所以国内的小伙伴可能下载失败。
CUDA Toolkit Archive | NVIDIA Developer
 依照自己需求的版本和环境选择下去即可。
依照自己需求的版本和环境选择下去即可。
 本机配置,下面runfile(local)即可,另两个分别是本地仓库、联网仓库,然后运行下面给出的两条指令。其中,wget下载到当前终端所在路径。
本机配置,下面runfile(local)即可,另两个分别是本地仓库、联网仓库,然后运行下面给出的两条指令。其中,wget下载到当前终端所在路径。
建议安装显卡驱动相关的包的小伙伴先弄懂SSH远程终端,容易丢图形界面2333。
如果先安装显卡驱动,后安装cuda(也就是cudatoolkit)的,会警告多了package manager(其实指的就是本机已有显卡驱动),如果你的显卡驱动是(按照ubuntu-drivers devices那一套安装的)新的稳定版本,那么在cudatoolkit后续选项选择不安装driver即可;否则,先退出cudatoolkit安装引导,卸载old driver,再安装cudatoolkit安装引导的driver。系统同时安装多个版本的驱动应该会出奇怪的问题,ubuntu的不同版本自动覆盖很不靠谱,需要手动卸载重装。最后,记得修改环境变量,否则nvcc可能无反应。
详见这篇文章,写的很详细,但是版本按需选择:深度学习三件套:Ubuntu 20.04 安装 NVIDIA 驱动/CUDA/cuDNN全流程 | CO + 2Fe = COFFee (cyfeng.science)
cuDNN安装
下载地址:cuDNN Archive | NVIDIA Developer
tutorials:Installation Guide :: NVIDIA Deep Learning cuDNN Documentation
登录nvidia账号,做个简单的问卷。转到下载地址,找到你的CUDA版本(即cudatoolkit版本)对应的cuDNN,其中,深度学习项目的开发选择developer library,只需要应用深度学习功能的选择runtime library。
 这三项适用于所有linux平台设备(大约不是指PC)
这三项适用于所有linux平台设备(大约不是指PC)
![]() 本机是ubuntu18.04,选择下面deb版安装
本机是ubuntu18.04,选择下面deb版安装
 对应于tutorial安装指令,分别是runtime库,developer库,样例和doc,本机是developer库。
对应于tutorial安装指令,分别是runtime库,developer库,样例和doc,本机是developer库。
依照指令安装deb版,修改cuDNN为下载的对应版本。本机这里踩了个坑,报错:“依赖关系问题使得......”
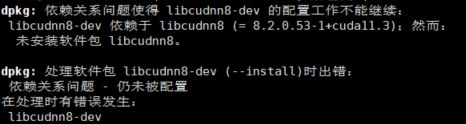
这个问题本机未能解决。