Object Detection in 20 Years: A Survey 20年间的目标检测:综述
摘要
物体检测作为计算机视觉中最基本和最具挑战性的问题之一,近年来受到了极大的关注。它在过去二十年中的发展可以看作是计算机视觉历史的缩影。如果我们把今天的物体探测看成是深度学习力量下的技术美学,那么把时钟拨回到20年前,我们就见证了冷武器时代的智慧。本文根据其技术演变(从1990年代到2019年)广泛回顾了400多篇关于物体检测的论文。本文涵盖了许多主题,包括历史上的里程碑探测器,检测数据集,指标,检测系统的基本构建块,加速技术以及最近的最先进的检测方法。本文还综述了行人检测、人脸检测、文本检测等一些重要的检测应用,并对近年来的挑战和技术改进进行了深入分析。
1简介
对象检测是一项重要的计算机视觉任务,用于检测数字图像中特定类别的视觉对象(如人类、动物或汽车)的实例。对象检测的目标是开发计算模型和技术,以提供计算机视觉应用所需的最基本的信息之一:哪些对象在哪里?
作为计算机视觉的基本问题之一,对象检测构成了许多其他计算机视觉任务的基础,例如实例分割[1,2,3,4],图像标题[5,6,7],对象跟踪[8]等。从应用角度看,对象检测可以分为"一般目标检测"和"检测应用"两个研究课题,前者旨在探索在统一框架下检测不同类型物体的方法,以模拟人类的视觉和认知,后一个则是指特定应用场景下的检测,如行人检测、人脸检测、文本检测等。近年来,深度学习技术的飞速发展[9]为物体检测带来了新生力量,取得了显著的突破,并以前所未有的关注度将其推向了研究热点。物体检测现已广泛应用于许多实际应用,如自动驾驶、机器人视觉、视频监控等。图1显示了过去二十年中与"物体检测"相关的出版物数量不断增加。
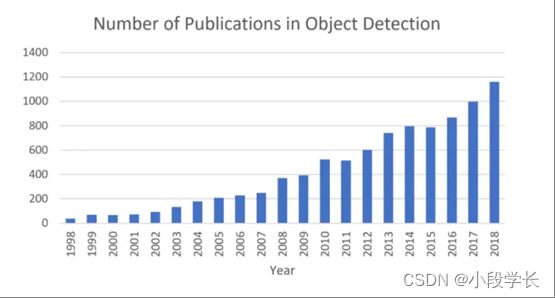
图 1从1998年到2018年,物体检测领域的出版物数量不断增加。(数据来自Google学术搜索高级搜索:allintitle:“对象检测"和"检测对象”
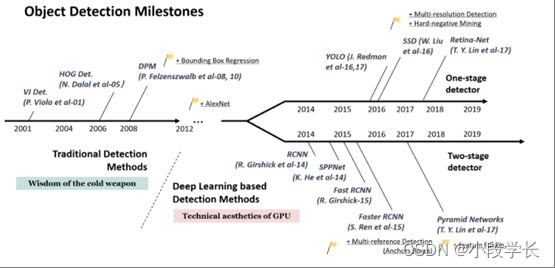
图 2对象检测的路线图。此图中的里程碑检测器:VJ Det. [10, 11], HOG Det. [12], DPM [13, 14, 15],RCNN[16],SPPNet[17],Fast RCNN[18],Faster RCNN[19],YOLO[20],SSD[21],Pyramid Networks [22],Retina-Net[23].
与其他相关评论的区别
近年来发表了许多关于一般物体检测的评论[24,25,26,27,28]。本文与上述综述的主要区别总结如下:
1.根据技术演进进行全面综述:本文广泛综述了跨越四分之一世纪(从20世纪90年代到2019年)的物体检测发展史上的400多篇论文。之前的大多数评论仅关注较短的历史时期或某些特定的检测任务,而没有考虑其整个生命周期中的技术演变。站在历史的高速公路上,不仅有助于读者建立完整的知识层次结构,还有助于找到这个快速发展的领域的未来方向。
2.对关键技术和近期技术水平的深入探索:经过多年的发展,最先进的物体检测系统已与"多尺度检测"、“硬负挖掘”、"边界盒回归"等大量技术相结合。然而,以前的评论缺乏基本面分析,以帮助读者理解这些复杂技术的本质,例如,“它们来自哪里,它们是如何演变的?“每组方法的优缺点是什么?“本文对读者的上述顾虑进行了深入的分析。
3.对检测加速技术的全面分析:长期以来,物体检测的加速一直是一项关键但具有挑战性的任务。本文从多个层面对20年对象检测历史中的加速技术进行了广泛的综述,包括"检测管道”(如级联检测、特征图共享计算)、“检测骨干网”(如网络压缩、轻量级网络设计)和"数值计算”(如积分图像、矢量量化)。以前的评论很少涉及此主题。
物体检测的难点和挑战
尽管人们总是问"物体检测有哪些困难和挑战?”,但实际上,这个问题并不容易回答,甚至可能被过度概括。由于不同的检测任务具有完全不同的目标和约束,因此它们的难度可能彼此不同。除了其他计算机视觉任务中的一些常见挑战,例如不同视点下的物体,照明和类内变化之外,物体检测中的挑战包括但不限于以下方面:物体旋转和尺度变化(例如,小物体),准确的物体定位,密集和闭塞的物体检测,检测速度等。在第4节和第5节中,我们将对这些主题进行更详细的分析。
本文的其余部分组织如下。在第2节中,我们回顾了物体检测20年的进化历史。第3节将介绍对象检测中的一些加速技术。第4节总结了最近三年中一些最先进的检测方法。一些重要的检测应用程序将在第5节中进行审查。在第6节中,我们总结了本文,并对进一步的研究方向进行了分析。
2.20年内的物体检测
在本节中,我们将在多个方面回顾对象检测的历史,包括里程碑检测器、对象检测数据集、指标以及关键技术的演变。
2.1对象检测路线图
近二十年来,人们普遍认为,目标检测的进展普遍经历了两个历史时期:“传统物体检测期(2014年以前)“和"基于深度学习的检测期(2014年以后)”,如图2所示。
里程碑:传统探测器
如果我们把今天的物体探测看成是深度学习力量下的技术美学,那么把时钟拨回到20年前,我们就会见证"冷武器时代的智慧”。大多数早期的物体检测算法都是基于手工制作的特征构建的。由于当时缺乏有效的图像表示,人们别无选择,只能设计复杂的特征表示,并采用各种加速技能来耗尽有限的计算资源。
中提琴琼斯探测器
18年前,P. Viola和M. Jones首次实现了人脸的实时检测,没有任何限制(例如,肤色分割)[10,11]。该探测器采用700MHz奔腾III CPU,在相当的检测精度下,其速度比任何其他算法快数十倍甚至数百倍。检测算法后来被称为"Viola-Jones(VJ)探测器",本文由作者的名字给出,以纪念他们的重大贡献。
VJ探测器遵循最直接的检测方式,即滑动窗口:浏览图像中所有可能的位置和比例,以查看是否有任何窗口包含人脸。虽然这似乎是一个非常简单的过程,但它背后的计算远远超出了计算机当时的能力。VJ探测器通过结合三种重要技术,大大提高了其检测速度:“积分图像”,“特征选择"和"检测级联”。
1)积分图像:积分图像是一种加速盒子过滤或卷积过程的计算方法。与其时[29,30,31]中的其他物体检测算法一样,Haar小波在VJ检测器中用作图像的特征表示。积分图像使VJ检测器中每个窗口的计算复杂性与其窗口大小无关。
2)特征选择:作者没有使用一组手动选择的Haar基过滤器,而是使用Adaboost算法[32]从一组巨大的随机特征池(约180k维)中选择一小组对人脸检测最有帮助的特征。
3)检测级联:VJ检测器中引入了多级检测范例(也称为"检测级联"),通过在后台窗口上花费更少的计算而在人脸目标上花费更多的计算来减少其计算开销。
猪检测仪
定向梯度直方图(HOG)特征描述符最初由N. Dalal和B. Triggs于2005年提出[12]。HOG可以被认为是其当时的尺度不变特征变换[33,34]和形状上下文[35]的重要改进。为了平衡特征不变性(包括平移、比例、照明等)和非线性(在区分不同对象类别时),HOG 描述符设计为在均匀间隔的单元的密集网格上计算,并使用重叠的局部对比度归一化(在"块"上)以提高准确性。虽然HOG可用于检测各种对象类别,但它的动机主要是行人检测的问题。为了检测不同大小的物体,HOG检测器会多次重新缩放输入图像,同时保持检测窗口的大小不变。HOG探测器长期以来一直是许多物体探测器[13,14,36]和各种计算机视觉应用的重要基础。
可变形零件模型(DPM)
DPM作为VOC-07、-08和-09检测挑战的赢家,是传统物体检测方法的巅峰之作。DPM最初由P. Felzenszwalb [13]在2008年提出,作为HOG探测器的扩展,然后R.Girshick[14,15,37,38]进行了各种改进。
DPM遵循"分而治之"的检测理念,其中训练可以简单地视为学习分解对象的正确方法,推理可以被视为对不同对象部分的检测的集合。例如,检测"汽车"的问题可以被视为检测其车窗,车身和车轮。这部分工作,又名"星模",由P.Felzenszwalb等人完成[13]。后来,R.Girshick进一步将恒星模型扩展到"混合模型"[14,15,37,38],以处理现实世界中更大变化的物体。
典型的DPM检测器由一个根筛选器和多个部分筛选器组成。在DPM中开发了一种弱监督学习方法,而不是手动指定零件过滤器的配置(例如,大小和位置),其中零件过滤器的所有配置都可以作为潜在变量自动学习。R.Girshick进一步将这一过程表述为多实例学习的一个特例[39],其他一些重要技术,如"硬负挖掘",“边界框回归"和"上下文启动"也用于提高检测准确性(将在第2.3节中介绍)。).为了加快检测速度,Girshick开发了一种将检测模型"编译"成更快的技术,该技术实现了级联架构,在不牺牲任何精度的情况下实现了超过10倍的加速度[14,38]。
虽然今天的物体检测器在检测精度方面已经远远超过了DPM,但其中许多检测器仍然深受其宝贵见解的影响,例如混合模型、硬负挖掘、边界框回归等。2010年,P.Felzenszwalb和R.Girshick被PASCAL VOC授予"终身成就”。
里程碑:基于CNN的两级探测器
随着手工制作的特征的性能变得饱和,物体检测在2010年之后达到了一个平台。R. Girshick说:“…在2010-2012年期间,进展缓慢,通过构建集成系统和采用成功方法的次要变体获得了很小的收益”[38]。2012年,世界见证了卷积神经网络的重生[40]。由于深度卷积网络能够学习图像的鲁棒性和高级特征表示,一个自然的问题是我们是否可以将其用于对象检测?R. Girshick等人在2014年率先打破了僵局,提出了具有CNN特征的区域(RCNN)用于对象检测[16,41]。从那时起,物体检测开始以前所未有的速度发展。
在深度学习时代,对象检测可以分为两种类型:“两阶段检测"和"单阶段检测”,前者将检测框定为"粗略到精细"的过程,而后者将其框定为"一步到位"。
断续器
RCNN背后的想法很简单:它从通过选择性搜索[42]提取一组对象提案(对象候选框)开始。然后,每个提案被重新缩放为固定大小的图像,并输入到在ImageNet上训练的CNN模型(例如AlexNet [40])以提取特征。最后,线性SVM分类器用于预测每个区域中物体的存在并识别物体类别。RCNN在VOC07上显著提升了性能,平均精度(mAP)从33.7%(DPM-v5 [43]) 大幅提升至58.5%。
尽管RCNN取得了很大的进步,但其缺点是显而易见的:对大量重叠提案(一个图像的2000多个框)的冗余特征计算导致检测速度极慢(使用GPU时每个图像14个)。同年晚些时候,SPPNet[17]被提出并克服了这个问题。
断续器
2014年,K.他等人提出了空间金字塔池网络(SPPNet)[17]。以前的CNN型号需要固定大小的输入,例如,AlexNet的224x224图像[40]。SPPNet的主要贡献是引入了空间金字塔池(SPP)层,这使得CNN能够生成固定长度的表示,而不管感兴趣图像/区域的大小如何,而无需重新缩放。使用SPPNet进行物体检测时,只能从整个图像中计算一次特征图,然后可以生成任意区域的固定长度表示来训练探测器,从而避免了重复计算卷积特征。SPPNet比R-CNN快20倍以上,而不会牺牲任何检测精度(VOC07 mAP = 59.2%)。
虽然SPPNet有效地提高了检测速度,但仍然存在一些缺点:首先,训练仍然是多阶段的,其次,SPPNet仅微调其完全连接的层,而简单地忽略了所有先前的层。次年晚些时候,Fast RCNN [18]被提出并解决了这些问题。
快速RCNN
2015年,R.Girshick提出了Fast RCNN探测器[18],这是对R-CNN和SPPNet的进一步改进[16,17]。快速RCNN使我们能够在相同的网络配置下同时训练检测器和边界盒回归器。在VOC07数据集上,Fast RCNN将mAP从58.5%(RCNN)提高到70.0%,同时检测速度比R-CNN快200倍以上。
虽然Fast-RCNN成功集成了R-CNN和SPPNet的优势,但其检测速度仍受到提案检测的限制(详见第2.3.2节)。然后,自然会出现一个问题:"我们可以用CNN模型生成对象提案吗?后来,Faster R-CNN [19]回答了这个问题。
更快的RCNN
2015年,S. Ren等人在Fast RCNN之后不久提出了Faster RCNN探测器[19,44]。Faster RCNN是第一个端到端的,也是第一个近实时的深度学习检测器(COCO [email protected]=42.7%,COCO mAP@[.5,.95]=21.9%,VOC07 mAP=73.2%,VOC12 mAP=70.4%,采埃孚-Net为17fps[45])。Faster-RCNN的主要贡献是引入了区域提案网络(RPN),可实现几乎免费的区域提案。从R-CNN到Faster RCNN,对象检测系统的大多数单个模块,例如提案检测,特征提取,边界框回归等,已经逐渐集成到一个统一的端到端学习框架中。
虽然 Faster RCNN 突破了 Fast RCNN 的速度瓶颈,但在后续检测阶段仍然存在计算冗余。后来,提出了各种改进,包括RFCN [46]和Light head RCNN [47]。(有关详细信息,请参阅第 3 节。
要素金字塔网络
2017年,T.-Y.Lin等人在Faster RCNN的基础上提出了特征金字塔网络(FPN)[22]。在FPN之前,大多数基于深度学习的检测器仅在网络顶层运行检测。虽然CNN更深层的特征有利于类别识别,但不利于对象的定位。为此,在FPN中开发了一种具有横向连接的自上而下的架构,用于构建所有规模的高级语义。由于CNN通过其前向传播自然形成特征金字塔,因此FPN在检测具有各种尺度的物体方面显示出巨大的进步。在基本的Faster R-CNN系统中使用FPN,它可以在MSCOCO数据集上实现最先进的单模型检测结果,而不会出现花里胡哨的东西(COCO [email protected] = 59.1%,COCO mAP@[.5,.95]= 36.2%)。FPN现已成为许多最新探测器的基本组成部分。
里程碑:基于CNN的单级探测器
你只看一次 (YOLO)
YOLO由R. Joseph等人于2015年提出。它是深度学习时代的第一个单级探测器[20]。YOLO非常快:YOLO的快速版本以155fps的速度运行,VOC07 mAP = 52.7%,而其增强版本以45fps的速度运行,VOC07 mAP = 63.4%,VOC12 mAP = 57.9%。YOLO是"你只看一次"的缩写。从其名称可以看出,作者已经完全放弃了之前"提案检测+验证"的检测范式。相反,它遵循一个完全不同的哲学:将单个神经网络应用于完整图像。该网络将图像划分为多个区域,并同时预测每个区域的边界框和概率。后来,R. Joseph在YOLO的基础上做了一系列的改进,并提出了v2和v3版本[48,49],在保持极高检测速度的同时,进一步提高了检测精度。
尽管YOLO的检测速度有了很大的提高,但与两级检测器相比,YOLO的定位精度有所下降,特别是对于一些小物体。YOLO的后续版本[48,49]和后者提出的SSD [21]更加关注这个问题。
单次多盒探测器 (SSD)
SSD [21]由W. Liu等人于2015年提出。它是深度学习时代的第二个单级探测器。SSD的主要贡献是引入了多参考和多分辨率检测技术(将在2.3.2节中介绍),这显着提高了单级探测器的检测精度,特别是对于一些小物体。SSD在检测速度和精度方面均具有优势(VOC07 mAP=76.8%,VOC12 mAP=74.9%,COCO [email protected]=46.5%,mAP@[.5,.95]=26.8%,快速版本以59fps的速度运行)。SSD与以前的任何探测器之间的主要区别在于,前者在网络的不同层上检测不同比例的物体,而后者仅在其顶层上运行检测。
视网膜网
尽管速度快,简单,但单级探测器多年来一直落后于两级探测器的精度。T.-Y. Lin等人发现了背后的原因,并在2017年提出了RetinaNet[23]。他们声称,在密集探测器训练期间遇到的极端前景 - 背景类不平衡是核心原因。为此,RetinaNet中引入了一个名为"焦点损失"的新损失函数,通过重塑标准的交叉熵损失,使探测器在训练期间更加关注困难的、错误分类的例子。焦散使单级探测器能够达到与两级探测器相当的精度,同时保持非常高的检测速度。(COCO [email protected]=59.1%,mAP@[.5, .95]=39.1%)。
2.2对象检测数据集和衡量指标
构建偏差较小的大型数据集对于开发高级计算机视觉算法至关重要。在对象检测方面,过去10年已经发布了许多知名的数据集和基准测试,包括PASCAL VOC挑战[50,51](例如VOC2007,VOC2012),ImageNet大规模视觉识别挑战赛(例如ILSVRC2014)[52],MS-COCO检测挑战赛[53]等数据集。这些数据集的统计数据见表I。图 4 显示了这些数据集的一些图像示例。图3显示了2008年至2018年VOC07、VOC12和MS-COCO数据集检测精度的提高情况。
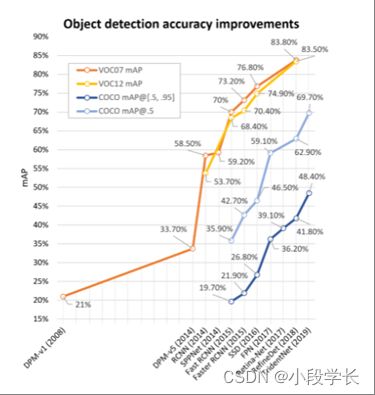
图 3改进了VOC07、VOC12和MS-COCO数据集上物体检测的准确性。此图中的探测器:DPM-v1 [13]、DPM-v5 [54]、RCNN [16]、SPPNet [17]、Fast RCNN [18]、Faster RCNN [19]、SSD [21]、FPN [22]、Retina-Net [23]、RefineDet [55]], TridentNet[56].
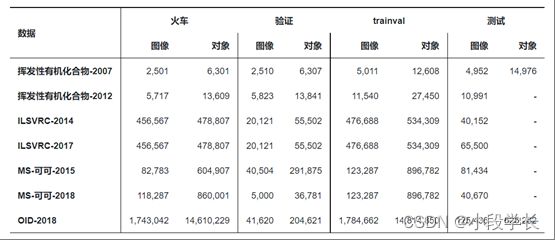
表 1一些众所周知的对象检测数据集及其统计信息。
帕斯卡挥发性有机化合物
PASCAL 可视对象类 (VOC) 挑战(2005年至2012年)[50,51]是早期计算机视觉界最重要的竞赛之一。PASCAL VOC 中有多个任务,包括图像分类、对象检测、语义分割和动作检测。Pascal-VOC的两个版本主要用于对象检测:VOC07和VOC12,前者由5k tr.图像+ 12k注释对象组成,后者由11k tr.图像+ 27k注释对象组成。在这两个数据集中注释了生活中常见的20类对象(人:人;动物:鸟,猫,牛,狗,马,羊;车辆:飞机,自行车,船,公共汽车,汽车,摩托车,火车;室内:瓶子,椅子,餐桌,盆栽植物,沙发,电视/显示器)。近年来,随着ILSVRC和MS-COCO(即将推出)等一些较大的数据集的发布,VOC逐渐过时,现在已成为大多数新探测器的试验台。
伊尔斯沃研究中心
ImageNet 大规模视觉识别挑战赛(ILSVRC)推动了通用物体检测领域的技术水平。ILSVRC从2010年到2017年每年举办一次。它包含使用 ImageNet 图像的检测挑战 [57]。ILSVRC 检测数据集包含 200 类可视对象。其图像/对象实例的数量比VOC大两个数量级。例如,ILSVRC-14 包含 517k 图像和 534k 带注释的对象。
可可
可可[53]是目前最具挑战性的物体检测数据集。基于MS-COCO数据集的年度竞赛自2015年以来一直举行。与 ILSVRC 相比,它的对象类别数量较少,但对象实例更多。例如,MS-COCO-17 包含来自 80 个类别的 164k 图像和 897k 注释对象。与VOC和ILSVRC相比,MS-COCO最大的进步是除了边界框注释之外,每个对象都使用每个实例分割进一步标记,以帮助精确定位。此外,MS-COCO包含比VOC和ILSVRC更多的小物体(其面积小于图像的1%)和更密集的物体。所有这些功能使MS-COCO中的对象分布更接近现实世界的对象分布。就像当时的ImageNet一样,MS-COCO已经成为物体检测社区事实上的标准。
打开图像
2018年引入了开放图像检测(OID)挑战赛,紧随MS-COCO之后,但规模空前。打开图像中有两个任务:1)标准对象检测,以及2)视觉关系检测,用于检测特定关系中的配对对象。对于对象检测任务,数据集由 1,910k 图像和 600 个对象类别上的 15,440k 带注释的边界框组成。
其他检测任务的数据集
除了一般的物体检测,近20年来,行人检测、人脸检测、文字检测、交通标志/灯光检测、遥感目标检测等特定领域的检测应用蓬勃发展。表 II-VI 列出了这些检测任务的一些常用数据集55#Cites显示了截至2019年2月的统计数据。.有关这些任务的检测方法的详细介绍,请参见第 5 节。
数据 年 描述 #Cites
麻省理工学院佩德。[注30]
2000 首批行人检测数据集之一。包括∼500 培训和∼200 张测试映像(基于 LabelMe 数据库构建)。url:http://cbcl.mit.edu/software-datasets/PedestrianData.html
1515
因里亚 [12]
2005 早期最著名和最重要的行人检测数据集之一。由HOG论文介绍[12]。 网址:http://pascal.inrialpes.fr/data/human/
24705
加州理工学院 [59, 60]
2009 最著名的行人检测数据集和基准之一。包括∼190,000 名行人在训练场和∼160,000 在测试集。该指标是 Pascal-VOC @ 0.5 IoU。网址: http://www.vision.caltech.edu/Image_Datasets/CaltechPedestrians/
2026
基蒂 [61]
2012 交通场景分析最著名的数据集之一。在德国卡尔斯鲁厄被俘。包括∼100,000 名行人 (∼6,000人)。网址: http://www.cvlibs.net/datasets/kitti/index.php
2620
市民 [62]
2017 基于 CityScapes 数据集构建 [63]。包括 ∼19,000 名行人参加训练集和∼测试集 11,000。与加州理工学院的指标相同。网址: https://bitbucket.org/shanshanzhang/citypersons
50
欧洲城 [64]
2018 迄今为止最大的行人检测数据集。从12个欧洲国家的31个城市捕获。包括∼238,000 个实例∼47,000 张图片。与加州理工学院的指标相同。 1
表 2一些常用行人检测数据集的概述。
数据 年 描述 #Cites
FDDB [65]
2010 包括∼2,800 张图片和∼来自雅虎的5,000张面孔!遮挡、姿势更改、失焦等 url:http://vis-www.cs.umass.edu/fddb/index.html
531
迷航 [66]
2011 包括∼来自 Flickr 的 26,000 张面孔和 22,000 张图像,带有丰富的面部地标注释。 网址:https://www.tugraz.at/institute/icg/research/team-bischof/lrs/downloads/aflw/
414
伊吉布 [67]
2015 IJB-A/B/C 由超过 50,000 个图像和视频帧组成,用于识别和检测任务 https://www.nist.gov/programs-projects/face-challenges。
279
加宽面 [68]
2016 最大的人脸检测数据集之一。包括∼32,000 张图像和 394,000 张具有丰富注释的面孔,即比例、遮挡、姿势等 http://mmlab.ie.cuhk.edu.hk/projects/WIDERFace/。
193
UFDD [69]
2018 包括∼6,000 张图片和∼11,000 张面孔。变化包括基于天气的退化,运动模糊,焦点模糊等 http://www.ufdd.info/。
1
最狂野的脸 [70]
2018 跟∼68,000 个视频帧和∼2,200个镜头,64个与名人在不受约束的场景中战斗。数据集尚未发布。 2
表 3一些常用人脸检测数据集的概述。
数据 年 描述 #Cites
ICDAR [71]
2003 ICDAR2003 是首批用于文本检测的公共数据集之一。ICDAR 2015 和 2017 是 ICDAR 挑战赛 [72, 73] 的其他热门迭代 http://rrc.cvc.uab.es/。
530
全景电视 [74]
2010 包括∼350 张图片和∼720 个文本实例取自 Google 街景。 网址:http://tc11.cvc.uab.es/datasets/SVT_1
339
MSRA-TD500 [75]
2012 包括∼500张室内/室外图片,附中英文文本, 网址: http://www.iapr-tc11.org/mediawiki/index.php/MSRA_Text_Detection_500_Database_(MSRA-TD500)
413
IIIT5k [76]
2012 包括∼1,100 张图片和∼来自街道和原生数字图像的5,000字。 网址:http://cvit.iiit.ac.in/projects/SceneTextUnderstanding/IIIT5K.html
165
可湿90k [77]
2014 一个综合数据集,其中包含从 90,000 个多种字体词汇表生成的 900 万张图像 http://www.robots.ox.ac.uk/~vgg/data/text/。
246
可可文本 [78]
2016 迄今为止最大的文本检测数据集。基于 MS-COCO 构建,包括∼63,000 张图片和∼173,000 个文本批注。 https://bgshih.github.io/cocotext/。
69
表 4一些常用场景文本检测数据集的概述。
数据 年 描述 #Cites
TLR [79]
2009 在巴黎被一辆移动的车辆捕获。包括∼11,000 个视频帧和∼9,200 个红绿灯实例。 网址: http://www.lara.prd.fr/benchmarks/trafficlightsrecognition
164
丽莎 [80]
2012 首批交通标志检测数据集之一。包括∼6,600 帧视频,∼47 个美国标志的 7,800 个实例。 网址:http://cvrr.ucsd.edu/LISA/lisa-traffic-sign-dataset.html
325
GTSDB [81]
2013 最受欢迎的交通标志检测数据集之一。包括∼900 张图片∼1,200 个交通标志在一天中的不同时间捕获各种天气条件。 网址:http://benchmark.ini.rub.de/?section=gtsdb&subsection=news
259
比利时TSD [82]
2012 包括∼7,300 张静态图像,∼120,000 个视频帧,以及∼11,000个交通标志注释,共269种。每个标志的 3D 位置都已添加注释。网址: https://btsd.ethz.ch/shareddata/
224
TT100K [83]
2016 迄今为止最大的交通标志检测数据集,具有∼100,000 张图像 (2048 x 2048) 和∼128 个类的 30,000 个流量标志实例。每个实例都使用类标签、边界框和像素掩码进行批注。网址: http://cg.cs.tsinghua.edu.cn/traffic%2Dsign/
111
英国国家图书馆 [84]
2017 最大的交通灯检测数据集。包括∼5000 张静态图像,∼8300 个视频帧,以及∼24000 个红绿灯实例。 https://hci.iwr.uni-heidelberg.de/node/6132
21
表 5一些常用的交通信号灯检测和交通标志检测数据集的概述。
数据 年 描述 #Cites
塔斯马尼亚州 [85]
2008 由来自 Google 地球的 729x636 像素的 30 张图像组成,以及∼1,300 辆车。 网址: http://ai.stanford.edu/~gaheitz/Research/TAS/
419
手术室 [86]
2009 包含由机载摄像头捕获的 900 张图像(0.08-0.3 米/像素)和 1,800 个带注释的车辆目标。 url: https://sourceforge.net/projects/oirds/
32
数码单反3K [87]
2013 小型车辆检测最常用的数据集。由9,300辆汽车和160辆卡车组成。
网址: https://www.dlr.de/eoc/en/desktopdefault.aspx/tabid-5431/9230_read-42467/
68
UCAS-AOD [88]
2015 包括∼900 谷歌地球图片,∼2,800辆汽车和∼3,200 架飞机。
网址: http://www.ucassdl.cn/resource.asp
19
吠代 [89]
2016 包括∼1,200 张图像(0.1-0.25 米/像素),∼9个班级的3,600个目标。设计用于检测遥感图像中的小目标。
网址: https://downloads.greyc.fr/vedai/
65
新世界疫苗-VHR10 [90]
2016 近年来使用最频繁的遥感探测数据集。包括∼800 张图像(0.08-2.0 米/像素)和∼3800个十类遥感目标(如飞机、轮船、棒球钻石、网球场等 http://jiong.tea.ac.cn/people/JunweiHan/NWPUVHR10dataset.html)。 204
莱维尔 [91]
2018 包括∼22,000 谷歌地球图片和∼10,000 个独立标记的目标(飞机、轮船、油罐)。 网址:https://pan.baidu.com/s/1geTwAVD
15
多塔 [92]
2018 第一个包含旋转边界框的遥感检测数据集。包括∼2,800 谷歌地球图片和∼15 个类的 200,000 个实例。
url:https://captain-whu.github.io/DOTA/dataset.html
32
xView [93]
2018 迄今为止最大的遥感探测数据集。包括∼100万个60类遥感目标(30万/像素),覆盖1415个km2 土地面积。 网址: http://xviewdataset.org
10
表 6部分遥感目标检测数据集概述.
我们如何评估物体检测器的有效性?这个问题甚至可能在不同的时间有不同的答案。
在早期的检测界,没有广泛接受的检测性能评估标准。例如,在行人检测的早期研究中[12],“每个窗口的误报率与误报率(FPPW)“通常被用作指标。然而,在某些情况下,每窗口测量(FPPW)可能存在缺陷,无法预测完整的图像性能[59]。2009年,加州理工学院创建了行人检测基准[59,60],从那时起,评估指标已从每个窗口(FPPW)更改为每个图像的误报(FPPI)。
近年来,最常用的物体检测评估是"平均精度(AP)”,它最初是在VOC2007中引入的。AP定义为不同召回率下的平均检测精度,通常以特定类别的方式进行评估。为了比较所有对象类别的性能,通常使用所有对象类别的平均 AP (mAP) 作为性能的最终衡量指标。为了测量对象定位精度,使用并集交叉点 (IoU) 来检查预测框和地面实况框之间的 IoU 是否大于预定义的阈值(例如 0.5)。如果是,则该对象将被标识为"成功检测到”,否则将被标识为"错过"。多年来,基于 0.5 IoU 的 mAP 已成为对象检测问题的事实指标。
2014年后,由于MS-COCO数据集的普及,研究人员开始更加关注边界框位置的准确性。MS-COCO AP 不是使用固定的 IoU 阈值,而是在 0.5(粗略定位)和 0.95(完美定位)之间的多个 IoU 阈值上取平均值。指标的这种变化鼓励了更准确的对象定位,并且对于某些实际应用可能非常重要(例如,想象有一个机器人手臂试图抓住扳手)。
最近,在Open Images数据集中,评估有一些进一步的发展,例如,通过考虑框组和非穷尽的图像级类别层次结构。一些研究人员还提出了一些替代指标,例如"本地化召回精度"[94]。尽管最近发生了变化,但基于VOC/COCO的mAP仍然是对象检测最常用的评估指标。
2.3物体检测技术演进
在本节中,我们将介绍检测系统的一些重要构建模块及其在过去20年中的技术演变。
早期时代的黑暗知识
早期的物体检测(2000年之前)没有遵循像滑动窗口检测那样的统一检测理念。当时的探测器通常是根据低级和中级视觉设计的,如下所示。

图 4早期的一些众所周知的探测模型:(a)特征面[95],(b)共享重量网络[96],(c)空间位移网络(Lenet-5)[97],(d)VJ探测器的哈尔小波[10]。
组件、形状和边缘
"按组件识别"作为一种重要的认知理论[98],长期以来一直是图像识别和物体检测的核心思想[99,100,13]。一些早期的研究人员将物体检测框定为对物体组件,形状和轮廓之间相似性的测量,包括距离变换[101],形状上下文[35]和Edgelet [102]等。尽管初步结果很有希望,但在更复杂的检测问题上,情况并不顺利。因此,基于机器学习的检测方法开始蓬勃发展。
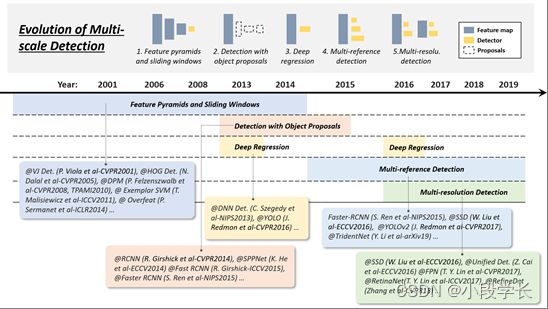
图 5从2001年到2019年,物体检测中多尺度检测技术的演变:1)特征金字塔和滑动窗口,2)使用对象建议进行检测,3)深度回归,4)多参考检测,以及5)多分辨率检测。此图中的检测器:VJ Det. [10]、HOG Det. [12]、DPM [13, 15]、示例 SVM [36]、Overfeat [103]、RCNN [16]、SPPNet [17]、Fast RCNN [18]、Faster RCNN [19], DNN Det. [104], YOLO [20], YOLO-v2 [48], SS
基于机器学习的检测经历了多个时期,包括外观统计模型(1998年之前)、小波特征表示(1998-2005)和基于梯度的表示(2005-2012)。
构建对象的统计模型,如图5(a)所示,如特征面[95,106],是对象检测历史上第一波基于学习的方法。1991年,M. Turk等人通过使用特征面分解[95]在实验室环境中实现了实时人脸检测。与当时基于规则或基于模板的方法相比[107,108],统计模型通过从数据中学习特定于任务的知识,更好地提供了对象外观的整体描述。
自2000年以来,小波特征转换开始主导视觉识别和物体检测。这组方法的本质是通过将图像从像素转换为一组小波系数来学习。在这些方法中,Haar小波由于其高计算效率,主要用于许多物体检测任务,如一般物体检测[29],人脸检测[109,10,11],行人检测[30,31]等。图5(d)显示了由VJ探测器[10,11]为人脸学习的一组Haar小波基。
早期的 CNN 用于对象检测
使用CNN检测物体的历史可以追溯到1990年代[96],当时Y. LeCun等人做出了巨大贡献。由于计算资源的限制,当时的CNN模型比今天的模型小得多,也浅得多。尽管如此,计算效率仍然被认为是早期基于CNN的检测模型中难以破解的难题之一。Y. LeCun等人进行了一系列改进,如"共享权重复制神经网络"[96]和"空间位移网络"[97],通过扩展卷积网络的每一层来减少计算,从而覆盖整个输入图像,如图5所示。 (b)-(c)。通过这种方式,整个图像的任何位置的特征都可以通过仅采取一次网络的正向传播来提取。这可以被认为是当今全卷积网络(FCN)[110,111]的原型,该网络是在近20年后提出的。CNN还被应用于其他任务,如人脸检测[112,113]和当时的手部跟踪[114]。
多尺度检测的技术演进
多尺度检测具有"不同尺寸"和"不同长宽比"的物体是物体检测中的主要技术挑战之一。在过去的20年中,多尺度检测经历了多个历史时期:“特征金字塔和滑动窗口(2014年之前)”,“使用对象提案进行检测(2010-2015年)”,“深度回归(2013-2016年)”,“多参考检测(2015年后)“和"多分辨率检测(2016年后)”,如图6所示。
特色金字塔+推拉窗(2014年以前)
随着VJ探测器后计算能力的提高,研究人员开始更多地关注通过构建"特征金字塔+滑动窗口"的直观检测方式。从2004年到2014年,基于这种检测范式构建了许多里程碑式的探测器,包括HOG探测器,DPM,甚至是深度学习时代的Overfeat探测器[103](ILSVRC-13定位任务的获胜者)。
VJ探测器和HOG探测器等早期检测模型专门设计用于检测具有"固定长宽比"的物体(例如,人脸和直立的行人),只需构建特征金字塔并在其上滑动固定尺寸的检测窗口即可。当时没有考虑检测"各种宽高比”。为了检测具有更复杂外观的物体,如PASCAL VOC中的物体,R. Girshick等人开始在特征金字塔之外寻求更好的解决方案。“混合模型”[15]是当时最好的解决方案之一,通过训练多个模型来检测具有不同长宽比的物体。除此之外,基于示例的检测[36,115]通过为训练集的每个对象实例(示例)训练单个模型提供了另一种解决方案。
随着现代数据集中的对象(例如MS-COCO)变得更加多样化,混合模型或基于示例的方法不可避免地导致更多的杂项检测模型。那么自然而然地出现了一个问题:是否有统一的多尺度方法来检测不同宽高比的物体?“对象提案”(待提出)的引入已经回答了这个问题。
带目标的检测建议(2010-2015)
对象建议是指一组可能与类无关的候选框,这些候选框可能包含任何对象。它于2010年首次应用于物体检测[116]。使用对象建议进行检测有助于避免在图像上进行详尽的滑动窗口搜索。
一种对象提案检测算法应满足以下三个要求:1)召回率高,2)定位精度高,3)在前两个要求的基础上,提高精度,缩短处理时间。现代提案检测方法可分为三类:1)分割分组方法[42,117,118,119],2)窗口评分方法[116,120,121,122]和3)基于神经网络的方法[123,124, 125, 126, 127, 128].我们向读者推荐以下论文,以全面回顾这些方法[129,130]。
早期提出的检测方法遵循自下而上的检测理念[116,120],并受到视觉显著性检测的深刻影响。后来,研究人员开始转向低级视觉(例如,边缘检测)和更仔细的手工技能,以改善候选框的定位[42,117,118,131,119,122]。2014年后,随着深度CNN在视觉识别中的普及,自上而下、基于学习的方法开始在这个问题上显示出更多的优势[121,123,124,19]。从那时起,对象提案检测已经从自下而上的视觉演变为"过度拟合到一组特定的对象类",探测器和提案生成器之间的区别变得越来越模糊[132]。
由于"物体提案"彻底改变了滑动窗口检测,并迅速主导了基于深度学习的探测器,在2014-2015年,许多研究人员开始提出以下问题:物体提案在检测中的主要作用是什么?是提高准确性,还是仅仅为了加快检测速度?为了回答这个问题,一些研究人员试图削弱提案的作用[133],或者只是对CNN特征[134,135,136,137,138]进行滑动窗口检测,但没有一个获得令人满意的结果。在单级检测器和"深度回归"技术(即将推出)的兴起之后,建议的检测很快就溜走了。

图 7: 2001年至2019年对象检测中边界框回归技术的演变。此图中的检测器:VJ Det. [10]、HOG Det. [12]、示例 SVM [36]、DPM [13、 15]、Overfeat [103]、RCNN [16]、SPPNet [17]、Fast RCNN [18]、Faster RCNN [19], YOLO [20], SSD [21], YOLO-v2 [48], Unified Det. [105], FPN [22],RetinaNet [23],RefineDet [55],TridentNet [56].
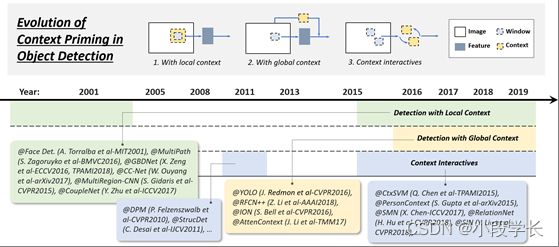
图 8: 从2001年到2019年,对象检测中上下文启动的演变:1)使用本地上下文进行检测,2)使用全局上下文进行检测,3)使用上下文交互进行检测。此图中的检测器:Face Det. [139]、MultiPath [140]、GBDNet [141, 142]、CC-Net [143]、MultiRegion-CNN [144]、CoupleNet [145]、DPM [14、 15]、StructDet [146]、YOLO [20], RFCN++ [147], ION [148], AttenContext [149], CtxSVM [150], PersonContext [151], SMN [152], RetinaNet [23], SIN [153].
深度回归(2013-2016)
近年来,随着GPU计算能力的提高,人们处理多尺度检测的方式变得越来越直接和蛮力。使用深度回归来解决多尺度问题的想法非常简单,即基于深度学习特征[104,20]直接预测边界框的坐标。这种方法的优点是它简单且易于实现,而缺点是本地化可能不够准确,特别是对于某些小对象。“多参考检测”(即将推出)后来解决了这个问题。
多参考/分辨率检测(2015年以后)
多引用检测是用于多尺度对象检测的最常用框架 [19, 44, 48, 21]。其主要思想是在图像的不同位置预先定义一组具有不同大小和宽高比的参考框(又名锚框),然后根据这些参考预测检测框。
每个预定义锚盒的典型损失由两部分组成:1) 用于类别识别的交叉熵损失和 2) 用于对象定位的 L1/L2 回归损失。损失函数的一般形式可以写如下:
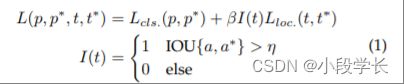
哪里t和t∗是预测和地面实况边界框的位置,p和p∗是它们的类别概率。借据{一个,一个∗}是锚点之间的 IOU一个及其基本事实一个∗.η是 IOU 阈值,例如 0.5。如果锚点未覆盖任何对象,则其定位损失不计入最终损失。
过去两年中另一种流行的技术是多分辨率检测[21,22,105,55],即通过检测网络不同层中不同尺度的物体。由于CNN在其向前传播过程中自然形成特征金字塔,因此更容易在较深的层中检测较大的物体,而在较浅的层中检测较小的物体。多参考和多分辨率检测现已成为最先进的物体检测系统中的两个基本构建块。
边界框回归的技术演变
边界框 (BB) 回归是对象检测中的一项重要技术。它旨在根据初始建议或锚点框优化预测边界框的位置。在过去的20年中,BB回归的演变经历了三个历史时期:“没有BB回归(2008年之前)”,"从BB到BB(2008-2013)“和"从特征到BB(2013年后)”。图 7 显示了边界框回归的演变。
无BB回归(2008年之前)
VJ检测器、HOG检测器等早期检测方法大多不使用BB回归,通常直接考虑滑动窗口作为检测结果。为了获得物体的准确位置,研究人员别无选择,只能建造非常密集的金字塔,并在每个位置密集地滑动探测器。
从BB到BB(2008-2013)
BB 回归首次引入对象检测系统是在 DPM [15] 中。当时的BB回归通常充当后处理块,因此它是可选的。由于 PASCAL VOC 中的目标是预测每个对象的单个边界框,因此 DPM 生成最终检测的最简单方法应直接使用其根筛选器位置。后来,R. Girshick等人引入了一种更复杂的方法来预测基于对象假设的完整配置的边界框,并将此过程表述为线性最小二乘回归问题[15]。这种方法在PASCAL标准下产生了明显的检测改进。
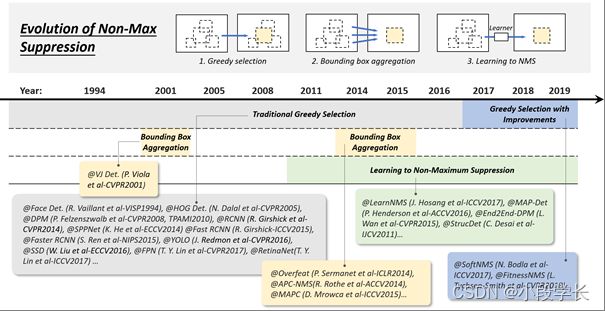
图 9: 从1994年到2019年,非最大抑制(NMS)技术在对象检测中的演变:1)贪婪选择,2)边界框聚合,以及3)学习NMS。此图中的探测器:VJ Det. [10],Face Det. [96],HOG Det. [12],DPM [13,15],RCNN [16],SPPNet [17],Fast RCNN [18],Faster RCNN [19],YOLO [20],SSD[21], FPN [22], RetinaNet [23], LearnNMS [154], MAP-Det [155], End2End-DPM [136], StrucDet [146], Overfeat [103], APC-NMS [156], MAPC [157], SoftNMS [158], FitnessNMS [159].
从功能到BB(2013年以后)
在 2015 年引入 Faster RCNN 后,BB 回归不再用作单独的后处理块,而是与检测器集成并以端到端方式进行训练。同时,BB回归已经发展到直接基于CNN特征预测BB。为了获得更稳健的预测,通常使用平滑-L1 函数 [19],
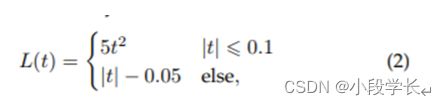
或平方根函数 [20],
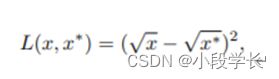
作为其回归损失,对于异常值而言,它们比 DPM 中使用的最小二乘法损失更可靠。一些研究人员还选择对坐标进行归一化,以获得更可靠的结果[18,19,21,23]。
上下文启动的技术演变
可视对象通常嵌入在具有周围环境的典型上下文中。我们的大脑利用物体和环境之间的关联来促进视觉感知和认知[160]。上下文启动长期以来一直用于改进检测。在其进化史上有三种常见的方法:1)使用局部上下文进行检测,2)使用全局上下文进行检测,以及3)上下文交互,如图8所示。
使用本地上下文进行检测
局部上下文是指要检测的对象周围区域中的视觉信息。人们早就认识到,本地上下文有助于改进对象检测。在2000年代初,Sinha和Torralba[139]发现,包含局部上下文区域(如面部边界轮廓)可显着提高面部检测性能。Dalal和Trigs还发现,结合少量的背景信息可以提高行人检测的准确性[12]。最近的基于深度学习的探测器也可以通过简单地扩大网络的接收场或对象提案的大小[140,141,142,161,143,144,145]来改进本地环境。
全局上下文检测
全局上下文利用场景配置作为对象检测的附加信息源。对于早期的物体检测器,整合全球背景的一种常见方法是整合构成场景的元素的统计摘要,如Gist [160]。对于基于现代深度学习的探测器,有两种方法可以整合全局上下文。第一种方法是利用大接受场(甚至大于输入图像)[20]或CNN特征的全局池操作[147]。第二种方法是将全球语境视为一种顺序信息,并使用递归神经网络学习它[148,149]。
上下文交互
上下文交互是指通过视觉元素的交互(如约束和依赖关系)传达的信息片段。对于大多数对象检测器,可以单独检测和识别对象实例,而无需利用它们之间的关系。最近的一些研究表明,通过考虑上下文交互,可以改进现代物体探测器。最近的一些改进可以分为两类,第一类是探索单个对象之间的关系[15,150,146,162,152],第二类是探索对象和场景之间的依赖关系建模[151,153,151]。
非最大抑制的技术演进
非最大抑制 (NMS) 是对象检测中的一组重要技术。由于相邻窗口通常具有相似的检测分数,因此本文将非最大抑制用作后处理步骤,以删除复制的边界框并获得最终的检测结果。在物体检测的早期,NMS并不总是集成的[30]。这是因为当时物体检测系统的期望输出并不完全清楚。在过去的20年中,NMS已逐渐发展为以下三组方法:1)贪婪选择,2)边界盒聚合,3)学习NMS,如图9所示。
贪婪的选择
贪婪选择是一种老式的,但在对象检测中执行NMS的最流行方式。此过程背后的思想简单直观:对于一组重叠检测,选择具有最大检测分数的边界框,同时根据预定义的重叠阈值(例如,0.5)删除其相邻框。上述处理以贪婪的方式迭代执行。
虽然贪婪选择现在已经成为NMS的事实方法,但它仍然有一些改进的空间,如图11所示。首先,得分最高的盒子可能不是最合适的。其次,它可能会抑制附近的物体。最后,它不会抑制误报。近年来,尽管最近进行了一些手动修改以提高其性能[158,159,163](有关详细信息,请参阅第4.4节),但据我们所知,贪婪的选择仍然是当今物体检测的最强基准。

图 10: 1994年至2019年物体检测中硬负片采矿技术的演变。此图中的探测器:面部 [164]、哈尔区 [29]、VJ 区 [10]、HOG 分机组 [12]、DPM [13、 15]、RCNN [16]、SPPNet [17]、快速 RCNN [18]、速度更快的 RCNN [19]、YOLO [20], SSD [21], FasterPed [165], OHEM [166], RetinaNet [23], Refinedet [55].

图 11: 使用基于标准贪婪选择的非最大抑制时可能失败的示例:(a) 最高评分框可能不是最合适的,(b) 它可能抑制附近的对象,以及 (c) 它不抑制误报。图片来自R. Rothe等人, ACCV2014 [156]。
BB 聚合
BB聚合是用于NMS [10,156,103,157]的另一组技术,其思想是将多个重叠的边界框组合或聚类到一个最终检测中。这种类型的方法的优点是它充分考虑了对象关系及其空间布局。有一些众所周知的探测器使用这种方法,例如VJ探测器[10]和Overfeat[103]。
学习 NMS
最近受到广泛关注的一组NMS改进正在学习NMS [154,155,136,146]。这些方法组的主要思想是将NMS视为过滤器,以重新对所有原始检测进行评分,并以端到端的方式将NMS训练为网络的一部分。与传统的手工制作的NMS方法相比,这些方法在改善遮挡和密集物体检测方面取得了有希望的结果。
硬负极挖矿的技术演变
对象检测器的训练本质上是一个不平衡的数据学习问题。在基于滑动窗口的探测器的情况下,背景和物体之间的不平衡可能非常极端104∼105每个对象的背景窗口。现代检测数据集需要预测对象长宽比,进一步将不平衡比提高到106∼107 在这种情况下,使用所有背景数据将对训练有害,因为大量简单的负面因素将淹没学习过程。硬负挖掘(HNM)旨在解决训练过程中数据不平衡的问题。HNM在物体检测中的技术演变如图10所示。
启动
对象检测中的 Bootstrap 是指一组训练技术,其中训练从一小部分背景样本开始,然后在训练过程中迭代添加新的未分类背景。在早期,引入自举的目的是减少数百万个背景样本的训练计算[164,29,10]。后来,它成为DPM和HOG检测器[12,13]中解决数据不平衡问题的标准训练技术。
基于深度学习的探测器中的 HNM
在深度学习时代的后期,由于计算能力的提高,自举在2014-2016年期间很快在对象检测中被丢弃[16,17,18,19,20]。为了缓解训练期间的数据不平衡问题,像Faster RCNN和YOLO这样的检测器只是简单地平衡了正负窗口之间的权重。然而,研究人员后来注意到,权重平衡不能完全解决不平衡的数据问题[23]。为此,在2016年之后,自举被重新引入基于深度学习的探测器[21,165,166,167,168]。例如,在SSD [21]和OHEM [166]中,只有极少数样本(具有最大损耗值的样本)的梯度将反向传播。在 RefineDet [55] 中,设计了一个"锚点细化模块"来过滤容易出现的负面因素。另一种改进是设计新的损失函数[23,169,170],通过重塑标准的交叉熵损失,使其更加关注困难的,错误分类的例子[23]。
3加速检测
长期以来,物体检测的加速一直是一个重要但具有挑战性的问题。在过去的20年中,物体检测界已经开发出复杂的加速技术。这些技术大致可分为三个层次的组:“检测管道加速”、“检测引擎加速"和"数值计算加速”,如图12所示。
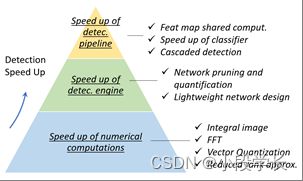
图 12: 对象检测中的加速技术概述。
3.1特征图共享计算
在对象检测器的不同计算阶段中,特征提取通常主导计算量。对于基于滑动窗口的检测器,计算冗余从位置和尺度开始,其中前者是由相邻窗口之间的重叠引起的,而后者是由相邻尺度之间的特征相关性引起的。
空间计算冗余和加速
减少空间计算冗余的最常用思想是特征图共享计算,即在滑动窗口之前仅计算整个图像的特征图一次。本文中传统探测器的"图像金字塔"可以被认为是"特征金字塔"。例如,为了加速HOG行人探测器,研究人员通常会积累整个输入图像的"HOG地图",如图13所示。然而,这种方法的缺点也很明显,即特征图分辨率(该特征图上滑动窗口的最小步长)将受到像元大小的限制。如果一个小物体位于两个单元格之间,则所有检测窗口都可能忽略它。此问题的一个解决方案是构建一个完整的要素金字塔,这将在第 3.6 节中介绍。
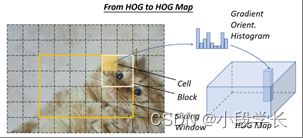
图 13: 如何计算图像的 HOG 映射的图示。
特征图共享计算的思想也已被广泛用于基于卷积的探测器。一些相关作品可以追溯到1990年代[97,96]。近年来,大多数基于CNN的探测器,例如SPPNet [17],Fast-RCNN [18]和Faster-RCNN [19],都应用了类似的想法,这些想法已经实现了数十甚至数百倍的加速度。
扩展计算冗余并加快速度
为了减少尺度计算冗余,最成功的方法是直接缩放特征而不是图像,这首先应用于VJ检测器[10]。但是,由于模糊效果,这种方法不能直接应用于类似 HOG 的特征。对于这个问题,P. Dollár等人通过广泛的统计分析发现了HOG的相邻尺度与积分通道特征之间的强(对数线性)相关性[171]。这种相关性可用于通过近似相邻比例的要素图来加速要素金字塔[172]的计算。此外,构建"探测器金字塔"是避免尺度计算冗余的另一种方法,即通过简单地在一个特征图上滑动多个探测器而不是重新缩放图像或特征来检测不同尺度的物体[173]。
3.2加速分类器
传统的基于滑动窗口的检测器,例如HOG检测器和DPM,由于其计算复杂性低,更喜欢使用线性分类器而不是非线性分类器。使用非线性分类器(如内核 SVM)进行检测表明精度更高,但同时会带来较高的计算开销。作为一种标准的非参数方法,传统的核方法没有固定的计算复杂度。当我们有一个非常大的训练集时,检测速度会变得非常慢。
在对象检测中,有许多方法可以加速内核化分类器,其中"模型近似"是最常用的[30,174]。由于经典内核 SVM 的决策边界只能由其一小部分训练样本(支持向量)确定,因此推理阶段的计算复杂性将与支持向量的数量成正比:O(Nsv).简集向量 [30] 是一种用于核 SVM 的近似方法,旨在从少量合成向量中获得等效的决策边界。在对象检测中加速内核SVM的另一种方法是将其决策边界近似为分段线性形式,以实现恒定推理时间[174]。内核方法也可以使用稀疏编码方法[175]进行加速。
3.3级联检测
级联检测是物体检测[10,176]中常用的技术。它需要一个粗略到精细的检测理念:使用简单的计算过滤掉大多数简单的背景窗口,然后用复杂的窗口处理那些更困难的窗口。VJ探测器是级联检测的代表。之后,许多后续的经典物体探测器,如HOG探测器和DPM,通过使用这种技术[177,14,38,54,178]进行了加速。
近年来,级联检测也被应用于基于深度学习的检测器,特别是针对那些"大场景中的小物体"的检测任务,例如人脸检测[179,180],行人检测[177,165,181]等。除了算法加速之外,级联检测还被应用于解决其他问题,例如,改进硬示例的检测[182,183,184],集成上下文信息[185,143],并提高定位精度[125,104]。
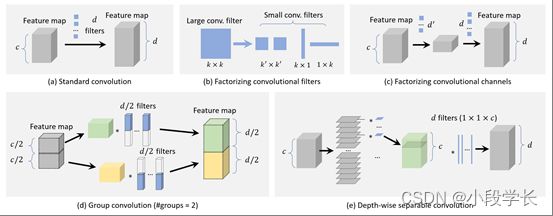
图 14: CNN卷积层的加速方法概述及其计算复杂性的比较:(a)标准卷积:O(dk2c).(b) 分解卷积滤波器(k×k → (k′×k′)2或1×k,k×1)(dk′2c)或O(dkc).(c) 分解卷积通道:O(d′k2c)+O(dk2d′).(d) 群卷积 (#groups=m)(dk2c/m).(e) 按深度分可分卷积:O(ck2)+O(dc).
3.4网络修剪和量化
"网络修剪"和"网络量化"是加速CNN模型的两种常用技术,前者是指修剪网络结构或权重以减小其大小,后者是指减少激活或权重的代码长度。
网络修剪
"网络修剪"的研究可以追溯到20世纪80年代。当时,Y. LeCun等人提出了一种称为"最佳脑损伤"的方法,以压缩多层感知器网络的参数[186]。在这种方法中,通过取二阶导数来近似网络的损失函数,以便去除一些不重要的权重。遵循这一思路,近年来的网络修剪方法通常采用迭代训练和修剪过程,即在每个训练阶段后只去掉一小群不重要的权重,并重复这些操作[187]。由于传统的网络修剪只是简单地删除了不重要的权重,这可能会导致卷积滤波器中出现一些稀疏的连接模式,因此无法直接应用于压缩 CNN 模型。这个问题的一个简单解决方案是移除整个过滤器而不是独立权重[188,189]。
网络量化
最近关于网络量化的工作主要集中在网络二值化上,其目的是通过将网络的激活或权重量化为二进制变量(例如0/1)来加速网络,以便将浮点运算转换为AND,OR,NOT逻辑运算。网络二值化可以显著加快计算速度并减少网络的存储,从而可以更轻松地将其部署在移动设备上。上述想法的一个可能的实现是用最小二乘法[190]近似二进制变量的卷积。通过使用多个二进制卷积的线性组合可以获得更准确的近似值[191]。此外,一些研究人员进一步开发了用于二值化计算的GPU加速库,从而获得了更显着的加速结果[192]。
网络蒸馏
网络提炼是一个通用框架,用于将大型网络(“教师网络”)的知识压缩成一个小网络(“学生网络”)[193,194]。最近,这个想法已被用于加速物体检测[195,196]。这个想法的一个直接方法是使用教师网络来指导(轻量级)学生网络的训练,以便后者可用于加速检测[195]。另一种方法是对候选区域进行变换,以最小化学生网和教师网之间的特征距离。这种方法使检测模型的速度提高了2倍,同时达到了相当的精度[196]。
3.5轻量级网络设计
加速基于CNN的探测器的最后一组方法是直接设计轻量级网络,而不是使用现成的检测引擎。长期以来,研究人员一直在探索网络的正确配置,以便在有限的时间成本下获得准确性。除了一些一般的设计原则,如"更少的通道和更多的层"[197],近年来还提出了一些其他方法:1)分解卷积,2)群卷积,3)深度可分离卷积,4)瓶颈设计,以及5)神经架构搜索。
分解卷积
分解卷积是构建轻量级 CNN 模型的最简单、最直接的方法。分解方法有两组。
第一组方法是将一个大卷积滤波器分解成一组空间维度的小滤波器[198,147,47],如图14(b)所示。例如,可以将 7x7 滤波器分解为三个 3x3 滤波器,其中它们共享相同的接受域,但后者更有效。另一个例子是分解k×k过滤成k×1过滤器和1×k过滤器 [198, 199],对于非常大的过滤器,例如 15x15 [199],可能更有效。这个想法最近被用于对象检测[200]。
第二组方法是将一大组卷积分解为两个通道维[201,202]中的小组,如图14(c)所示。例如,可以近似于卷积层d过滤器和的特征图c渠道由d′滤波器 + 一个非线性激活 + 另一个d过滤器 (d′
群卷积旨在通过将特征通道划分为许多不同的组来减少卷积层中的参数数量,然后在每个组上独立卷积[203,189],如图14(d)所示。如果我们将功能通道平均划分为m组,在不改变其他配置的情况下,卷积的计算复杂度理论上将降低到1/m之前。
按深度可分卷积
如图14(e)所示,深度可分卷积是最近流行的构建轻量级卷积网络的方法[204]。当组数设置为等于通道数时,可以将其视为组卷积的特殊情况。
假设我们有一个卷积层d过滤器和的特征图c渠道。每个过滤器的大小为k×k.对于深度可分离卷积,每个k×k×c过滤器首先拆分为c每个切片的大小k×k×1,然后使用滤波器的每个切片在每个通道中单独执行卷积。最后,使用许多 1x1 筛选器进行维度转换,以便最终输出应具有d渠道。通过使用深度可分离卷积,计算复杂性可以降低O(dk2c)自O(ck2)+O(dc).这个想法最近被应用于物体检测和细粒度分类[205,206,207]。

图 15: 如何计算"积分 HOG 图"的插图 [177]。通过积分图像技术,我们可以有效地计算任何位置和任何大小的直方图特征,并具有恒定的计算复杂性。
瓶颈设计
与前几层相比,神经网络中的瓶颈层包含的节点很少。它可用于学习具有降低维数的输入的高效数据编码,这在深度自动编码器[208]中已常用。近年来,瓶颈设计已被广泛用于设计轻量级网络[209,210,211,47,212]。在这些方法中,一种常见的方法是压缩检测器的输入层,以减少从检测管道一开始的计算量[209,210,211]。另一种方法是压缩检测引擎的输出,使特征图更薄,从而使其在后续检测阶段[47,212]中更有效率。
神经架构搜索
最近,人们对通过神经架构搜索(NAS)自动设计网络架构产生了浓厚的兴趣,而不是严重依赖专家经验和知识。NAS已应用于大规模图像分类[213,214],对象检测[215]和图像分割[216]任务。NAS最近在设计轻量级网络方面也显示出有希望的结果,其中在搜索过程中都考虑了对预测准确性和计算复杂性的限制[217,218]。
3.6数值加速度
在本节中,我们主要介绍物体检测中常用的四种重要的数值加速度方法:1)使用积分图像加速,2)在频域中加速,3)矢量量化,以及4)减少秩近似。
通过整体图像加速
积分图像是图像处理中的重要方法。它有助于快速计算图像子区域的总和。积分图像的本质是信号处理中卷积的积分微分可分离性:
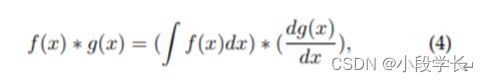
其中,如果dg(x)/dx是一个稀疏信号,那么卷积可以通过这个等式的右部分加速。虽然VJ探测器[10]以积分图像加速度而闻名,但在它诞生之前,积分图像已经被用来加速CNN模型[219]并实现了超过10倍的加速度。
除上述示例外,积分图像还可用于加速物体检测中更一般的特征,例如颜色直方图,梯度直方图[220,177,221,171]等。一个典型的例子是通过计算积分HOG图[220,177]来加速HOG。积分 HOG 映射不是在传统的积分图像中累积像素值,而是在图像中累积梯度方向,如图 15 所示。由于像元的直方图可以看作是某个区域中梯度矢量的总和,因此通过使用积分图像,可以在具有恒定计算开销的任意位置和大小的矩形区域中计算直方图。积分HOG地图已用于行人检测,并在不损失任何精度的情况下实现了数十倍的加速度[177]。
2009年晚些时候,P. Dollár等人提出了一种称为积分通道特征(ICF)的新型图像特征,可以将其视为积分图像特征的更一般情况,并已成功用于行人检测[171]。ICF在其时间的近乎实时的检测速度下实现了最先进的检测精度。
在频域中加速
卷积是物体检测中一种重要的数值运算类型。由于线性检测器的检测可以看作是特征图和检测器权重之间的窗口内积,因此此过程可以通过卷积来实现。
卷积可以通过多种方式加速,其中傅里叶变换是一个非常实用的选择,特别是对于加速那些大滤波器。在频域中加速卷积的理论基础是信号处理中的卷积定理,即在合适的条件下,两个信号卷积的傅里叶变换是其傅里叶空间中的逐点积:
![]()
哪里F是傅里叶变换,F−1是逆傅里叶变换,我和W是输入图像和过滤器,∗是卷积运算,并且⊙是按点划分的产品。可以使用快速傅里叶变换 (FFT) 和逆快速傅里叶变换 (IFFT) 来加速上述计算。FFT和IFFT现在经常用于加速CNN模型[222,223,224,225]和一些经典的线性物体探测器[226],这已经将检测速度提高了一个数量级。图16显示了在频域中加速线性物体检测器(例如,HOG和DPM)的标准管道。
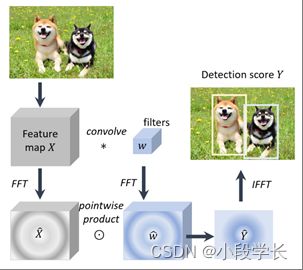
图 16: 如何利用快速傅里叶变换和逆快速傅里叶变换在频域中加速线性检测器(例如,HOG检测器、DPM 等)的图示[226]。
矢量量化
矢量量化(VQ)是信号处理中的一种经典量化方法,旨在通过一小组原型矢量近似于一大组数据的分布。它可用于数据压缩和加速对象检测[227,228]中的内积操作。例如,使用 VQ,可以将 HOG 直方图分组并量化为一组原型直方图向量。然后在检测阶段,特征向量和检测权重之间的内部生成可以通过表查找操作来实现。由于在此过程中没有浮点乘法和除法,DPM和示例SVM检测器的速度可以加速超过一个数量级[227]。
降低秩近似值
在深度网络中,全连接层中的计算本质上是两个矩阵的乘法。当参数矩阵W∈Ru×v体积大,一个探测器的计算负担会很重。例如,在快速RCNN检测器[18]中,近一半的前向传递时间用于计算完全连接的层。简化的秩近似是加速矩阵乘法的方法。它旨在对矩阵进行低秩分解W:
![]()
哪里U是u×t矩阵包括第一个t的左单数向量W,Σt是t×t包含顶部的对角矩阵t的单数值W和V是v×t矩阵包括第一个t的右奇异向量W.上述过程(也称为截断 SVD)减少了以下位置的参数计数uv自t(u+v),这在以下情况下可能很重要:t远小于 min(u,v).截断的SVD已被用于加速快速RCNN检测器[18]并实现x2加速。
4物体检测的最新进展
在本节中,我们将回顾近三年来最先进的物体检测方法。
4.1使用更好的引擎进行检测
近年来,Deep CNN在许多计算机视觉任务中发挥了核心作用。由于探测器的精度在很大程度上取决于其特征提取网络,在本文中,我们将骨干网络(例如ResNet和VGG)称为探测器的"引擎"。图17显示了三种众所周知的检测系统的检测精度:更快的RCNN [19],R-FCN [46]和SSD [21],具有不同的引擎选择[27]。
在本节中,我们将介绍深度学习时代一些重要的检测引擎。我们向读者推荐以下调查,以获取有关此主题的更多详细信息[229]。
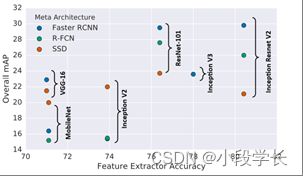
图 17: 比较了三种探测器的检测精度:更快的RCNN [19],R-FCN [46]和SSD [21]在具有不同检测引擎的MS-COCO数据集上。图片来自J. Huang等人, CVPR2017 [27]。
AlexNet:AlexNet [40]是一个八层深度网络,是第一个在计算机视觉领域掀起深度学习革命的CNN模型。AlexNet在2012年ImageNet LSVRC-2012竞赛中以很大的优势获胜[15.3%对26.2%(第二名)错误率]。截至2019年2月,Alexnet论文已被引用超过30,000次。
VGG:VGG是由牛津大学视觉几何小组(VGG)于2014年提出的[230]。VGG将模型的深度增加到16-19层,并使用非常小(3x3)的卷积滤波器,而不是以前在AlexNet中使用的5x5和7x7。VGG在其当时的ImageNet数据集上实现了最先进的性能。
GoogLeNet:GoogLeNet,又名Inception [231, 232, 198, 233],是Google Inc.自2014年以来提出的CNN模型大家族。GoogLeNet增加了CNN的宽度和深度(最多22层)。Inception 系列的主要贡献是引入了因式分解卷积和批处理规范化。
ResNet: The Deep Residual Networks (ResNet) [234],由K提出。他在2015年等人是一种新型的卷积网络架构,比以前使用的架构更深(最多152层)。ResNet旨在通过将网络的层重新表述为参考层输入的学习残差函数来简化网络的训练。ResNet 在 2015 年赢得了多项计算机视觉竞赛,包括 ImageNet 检测、ImageNet 定位、COCO 检测和 COCO 分割。
DenseNet:DenseNet [235]由G. Huang和Z. Liu等人于2017年提出。ResNet的成功表明,CNN中的捷径连接使我们能够训练更深入,更准确的模型。作者接受了这一观察结果,并引入了一个密集连接的块,该块以前馈方式将每一层连接到每隔一层。
SENet:Squeeze and Excitation Networks(SENet)由J. Hu和L. Shen等人于2018年提出[236]。它的主要贡献是集成了全局池和洗牌,以学习功能映射的渠道重要性。SENet在ILSVRC 2017分类竞赛中获得第一名。
带有新引擎的物体探测器
近三年来,许多最新的引擎已被应用于物体检测。例如,一些最新的对象检测模型,如STDN [237],DSOD [238],TinyDSOD [207]和Pelee [209]选择DenseNet [235]作为其检测引擎。Mask RCNN [4]作为实例分割的最新模型,应用了下一代ResNet:ResNeXt [239]作为其检测引擎。此外,为了加快检测速度,由Incepion的改进版本Xception [204]引入的深度可分离卷积操作也被用于MobileNet [205]和LightHead RCNN [47]等探测器。
4.2具有更好功能的检测
特征表示的质量对于对象检测至关重要。近年来,许多研究人员在一些最新引擎的基础上努力进一步提高图像特征的质量,其中最重要的两组方法是:1)特征融合和2)学习具有大接受场的高分辨率特征。
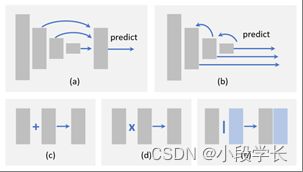
图 18: 不同特征融合方法的例证:(a)自下而上的融合,(b)自上而下的融合,(c)元素总和,(d)元素乘积,以及(e)串联。
为什么功能融合很重要?
不变性和等方差是影像要素制图表达中的两个重要属性。分类需要不变的特征表示,因为它旨在学习高级语义信息。对象定位需要等变表示,因为它旨在区分位置和尺度变化。由于对象检测由对象识别和定位两个子任务组成,因此检测器同时学习不变性和等方差至关重要。
特征融合在过去三年中已广泛应用于物体检测。由于 CNN 模型由一系列卷积层和池化层组成,因此更深层中的要素将具有更强的不变性,但等方差较小。虽然这可能有利于类别识别,但它在对象检测中的定位精度较低。相反,较浅层中的特征不利于学习语义,但它有助于对象定位,因为它包含有关边缘和轮廓的更多信息。因此,在 CNN 模型中集成深层和浅层特征有助于提高不变性和等方差。
不同方式的功能融合
在对象检测中执行特征融合的方法有很多种。在这里,我们在两个方面介绍一些最新的方法:1)处理流程和2)元素操作。
处理流程
物体检测中最近的特征融合方法可分为两类:1)自下而上的融合,2)自上而下的融合,如图18(a)-(b)所示。自下而上的融合通过跳跃连接[240,241,242,237]将浅层前馈到更深的层。相比之下,自上而下的融合将较深层的特征反馈到较浅的层[22,243,244,245,246,55]中。除了这些方法之外,最近还提出了更复杂的方法,例如,在不同层之间编织特征[247]。
由于不同图层的特征图在空间和通道尺寸方面可能具有不同的大小,因此可能需要容纳特征图,例如通过调整通道数、上采样低分辨率映射或将高分辨率映射下采样到适当的大小。最简单的方法是使用最接近或双线性插值[22,244]。此外,分数步进卷积(又名转置卷积)[248,45]是最近另一种流行的调整特征图大小和调整通道数量的方法。使用分数步进卷积的优点是它可以学习一种适当的方法来自行执行上采样[212,249,243,241,242,245,246,55]。
按元素操作
从局部角度来看,特征融合可以看作是不同特征图之间的元素操作。有三组方法:1)逐元素和,2)元素乘积和3)串联,如图18(c)-(e)所示。
元素总和是执行特征融合的最简单方法。它经常用于许多最近的物体探测器[22,243,241,246,55]。元素乘积 [249, 245, 250, 251] 与元素总和非常相似,而唯一的区别是使用乘法而不是求和。元素乘积的一个优点是,它可以用来抑制或突出某个区域内的特征,这可能进一步有利于小物体检测[245,250,251]。特征串联是另一种特征融合方式 [240, 244, 212, 237]。它的优点是它可以用来整合不同区域的上下文信息[105,161,149,144],而它的缺点是增加了内存[235]。
学习具有大接受域的高分辨率特征
接受场和特征分辨率是基于CNN的探测器的两个重要特征,前者是指有助于计算输出单个像素的输入像素的空间范围,后者对应于输入和特征图之间的下采样率。具有较大接受场的网络能够捕获更大范围的上下文信息,而具有较小接受场的网络可能更专注于本地细节。
如前所述,特征分辨率越低,检测小物体就越困难。提高要素分辨率的最直接方法是删除池化层或降低卷积下采样率。但这会引起新的问题,由于输出步幅的减小,接受场会变得太小。换句话说,这将缩小探测器的"视线",并可能导致一些大型物体的未命中检测。
同时增加感受场和特征分辨率的海盗方法是引入膨胀卷积(又名atrous卷积,或带孔的卷积)。膨胀卷积最初是在语义分割任务[252,253]中提出的。它的主要思想是扩展卷积滤波器并使用稀疏参数。例如,膨胀率为 2 的 3x3 滤波器将具有与 5x5 核相同的接受域,但只有 9 个参数。膨胀卷积现已广泛用于物体检测[21,254,255,56],并且被证明可以有效地提高精度,而无需任何额外的参数和计算成本[56]。
4.3超越滑动窗口
尽管对象检测已经从使用手工制作的特征发展到深度神经网络,但检测仍然遵循"特征图上的滑动窗口"的范式[137]。最近,有一些探测器建在滑动窗户之外。
检测作为子区域搜索
子区域搜索[256, 257, 258, 184]提供了一种新的检测方法。最近的一种方法是将检测视为一个路径规划过程,该过程从初始网格开始,最终收敛到所需的地面实况框[256]。另一种方法是将检测视为迭代更新过程,以优化预测边界框的角[257]。
检测作为关键点定位
关键点定位是一项重要的计算机视觉任务,具有广泛的应用,如面部表情识别[259]、人体姿势识别[260]等。由于图像中的任何对象都可以通过其地面实况框的左上角和右下角唯一确定,因此,检测任务可以等效地框定为成对关键点定位问题。这个想法最近的一个实现是预测角落的热图[261]。这种方法的优点是它可以在语义分割框架下实现,并且不需要设计多尺度锚盒。
4.4本地化的改进
为了提高定位精度,最近的检测器中有两组方法:1)边界盒细化,以及2)设计新的损耗函数以实现精确定位。
边界框优化
提高定位精度的最直观方法是边界框细化,这可以被视为检测结果的后处理。尽管边界框回归已集成到大多数现代对象检测器中,但仍有一些具有意外比例的对象无法被任何预定义的锚点很好地捕获。这将不可避免地导致对其位置的不准确预测。因此,最近引入了"迭代边界框细化"[262,263,264],方法是迭代地将检测结果馈送到BB回归器中,直到预测收敛到正确的位置和大小。然而,一些研究人员也声称,这种方法并不能保证定位精度的单调性[262],换句话说,如果多次应用,BB回归可能会使定位退化。
改进损失函数以实现精确定位
在大多数现代探测器中,物体定位被认为是坐标回归问题。但是,这种范式有两个缺点。首先,回归损失函数与定位的最终评估不对应。例如,我们无法保证较低的回归误差将始终产生较高的 IoU 预测,尤其是当对象具有非常大的纵横比时。其次,传统的边界框回归方法不提供本地化的置信度。当有多个BB相互重叠时,这可能导致非最大抑制失败(请参阅2.3.5小节中的更多详细信息)。
上述问题可以通过设计新的损耗函数来缓解。最直观的设计是直接使用IoU作为定位损耗函数[265]。其他一些研究人员进一步提出了一种IoU引导的NMS,以改善训练和检测阶段的定位[163]。此外,一些研究人员还试图在概率推理框架下改进定位[266]。与之前直接预测框坐标的方法不同,此方法预测边界框位置的概率分布。
4.5通过细分学习
对象检测和语义分割都是计算机视觉中的重要任务。最近的研究表明,通过语义分割学习可以改进对象检测。
为什么分割可以改进检测?
语义分割改进对象检测的原因有三个。
细分有助于类别识别
边缘和边界是构成人类视觉认知的基本元素[267,268]。在计算机视觉中,物体(例如,汽车,人)和物体(例如,天空,水,草)之间的区别在于前者通常具有封闭且明确定义的边界,而后者则没有。由于语义分割任务的功能很好地捕获了对象的边界,因此分割可能有助于类别识别。
细分有助于准确本地化
对象的地面真值边界框由其明确定义的边界确定。对于一些具有特殊形状的物体(例如,想象一只尾巴很长的猫),很难预测高IoU位置。由于对象边界可以在语义分割特征中很好地编码,因此学习分割将有助于准确的对象定位。
细分可以嵌入为上下文
日常生活中的物体被不同的背景所包围,如天空、水、草等,所有这些元素构成了物体的语境。整合语义分割的上下文将有助于对象检测,例如,飞机更有可能出现在天空中而不是水上。
分割如何改进检测?
通过分割来改进对象检测有两种主要方法:1)使用丰富的特征进行学习,以及2)使用多任务丢失函数进行学习。
通过丰富的功能进行学习
最简单的方法是将分割网络视为固定的特征提取器,并将其作为附加特征集成到检测框架中[144,269,270]。这种方法的优点是易于实现,而缺点是分段网络可能带来额外的计算。
使用多任务丢失函数进行学习
另一种方法是在原始检测框架之上引入额外的分割分支,并使用多任务丢失函数(分割丢失+检测丢失)训练该模型[269,4]。在大多数情况下,分割早午餐将在推理阶段被删除。优点是检测速度不会受到影响,但缺点是训练需要像素级的图像注释。为此,一些研究人员遵循了"弱监督学习"的想法:他们不是基于像素注释蒙版进行训练,而是简单地基于边界框级注释训练分割早午餐[271,250]。
4.6可靠检测旋转和比例变化
物体旋转和比例变化是物体检测中的重要挑战。由于CNN所学的特征并非随轮换和规模变化而不变,近年来,许多人在这个问题上做出了努力。
旋转稳健检测
对象旋转在人脸检测、文本检测等检测任务中非常常见。这个问题最直接的解决方案是数据增强,这样任何方向的物体都可以被增强数据很好地覆盖[88]。另一种解决方案是为每个方向训练独立的探测器[272,273]。除了这些传统方法之外,最近还有一些新的改进方法。
旋转不变损失函数
使用旋转不变损失函数学习的想法可以追溯到1990年代[274]。最近的一些工作对原始的检测损失函数引入了约束,以使旋转物体的特征保持不变[275,276]。
旋转校准
改进旋转不变检测的另一种方法是对候选对象进行几何变换[277,278,279]。这对于多级检测器特别有用,其中早期阶段的相关性将有利于后续检测。这个想法的代表是空间变压器网络(STN)[278]。STN 现已用于旋转文本检测 [278] 和旋转人脸检测 [279]。
轮换 RoI 池化
在两阶段检测器中,要素池旨在通过首先将方案平均划分为一组格网,然后连接格网要素,为具有任何位置和大小的对象方案提取固定长度的特征表示。由于格网网格是在笛卡尔坐标中执行的,因此要素与旋转变换不是不变的。最近的一项改进是在极坐标中对格网进行网格网格剖分,以便特征可以对旋转变化具有鲁棒性[272]。
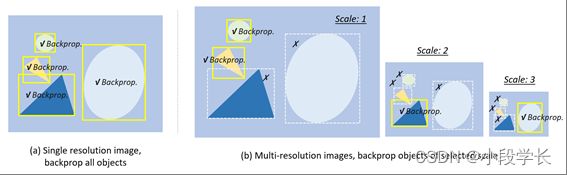
图 19: 多尺度物体检测的不同训练策略:(a):在单个分辨率图像上进行训练,向后传播所有尺度的物体[17,18,19,21]。(b) 多分辨率图像(图像金字塔)的培训,向后传播选定比例的物体。如果对象太大或太小,其渐变将被丢弃 [280, 281, 56]。
规模稳健检测
最近在训练和检测阶段都进行了改进,以实现规模稳健检测。
规模自适应训练
大多数现代探测器将输入图像重新缩放到固定大小,并在所有尺度上反向传播物体的损耗,如图19(a)所示。但是,这样做的缺点是会出现"规模不平衡"问题。在检测过程中建立图像金字塔可以缓解这个问题,但不能从根本上缓解[46,234]。最近的一项改进是图像金字塔的比例归一化(SNIP)[280],它在训练和检测阶段都构建图像金字塔,并且仅反向传播一些选定尺度的损失,如图19(b)所示。一些研究人员进一步提出了一种更有效的训练策略:具有高效重采样(SNIPER)的SNIP[281],即裁剪图像并将其重新缩放到一组子区域,以便从大批量训练中受益。
规模自适应检测
大多数现代探测器使用固定配置来检测不同尺寸的物体。例如,在典型的基于CNN的探测器中,我们需要仔细定义锚点的大小。这样做的缺点是配置无法适应意外的比例变化。为了改善对小物体的检测,在最近的一些探测器中提出了一些"自适应放大"技术,以适应性地将小物体放大为"较大的物体"[184,258]。最近的另一项改进是学习预测图像中物体的比例分布,然后根据分布[282,283]自适应地重新缩放图像。
4.7从头开始培训
大多数基于深度学习的探测器首先在大规模数据集(例如ImageNet)上进行预训练,然后在特定的检测任务上进行微调。人们一直认为,预训练有助于提高泛化能力和训练速度,问题是,我们真的需要在ImageNet上对检测器进行预训练吗?事实上,在对象检测中采用预先训练的网络时存在一些限制。第一个限制是 ImageNet 分类和对象检测之间的差异,包括它们的损失函数和比例/类别分布。第二个限制是域不匹配。由于ImageNet中的图像是RGB图像,而检测有时会应用于深度图像(RGB-D)或3D医学图像,因此预先训练的知识无法很好地转移到这些检测任务中。
近年来,一些研究人员试图从头开始训练物体探测器。为了加速训练并提高稳定性,一些研究人员引入了密集连接和批量归一化,以加速浅层中的反向传播[238,284]。K最近的工作。他等人[285]通过探索相反的制度,进一步质疑了预训练的范式:他们报告了使用从随机初始化训练的标准模型在COCO数据集上进行对象检测的竞争结果,唯一的例外是增加训练迭代次数,以便随机初始化的模型可以收敛。即使仅使用10%的训练数据,从随机初始化进行训练也令人惊讶地健壮,这表明ImageNet预训练可能会加速收敛,但不一定提供正则化或提高最终检测精度。
4.8对抗训练
由A. Goodfellow等人于2014年推出的生成对抗网络(GAN)[286]近年来受到极大关注。典型的GAN由两个神经网络组成:生成器网络和鉴别器网络,在最小最大优化框架中相互竞争。通常,生成器学习从潜在空间映射到感兴趣的特定数据分布,而鉴别器旨在区分来自真实数据分布的实例和生成器生成的实例。GAN已被广泛用于许多计算机视觉任务,如图像生成[286,287],图像样式传输[288]和图像超分辨率[289]。近两年来,GAN也已应用于物体检测,特别是用于提高对小物体和遮挡物体的检测。
GAN已被用于通过缩小小物体和大物体之间的表示来增强对小物体的检测[290,291]。为了改善对被遮挡物体的检测,最近的一个想法是通过使用对抗训练来生成遮挡掩码[292]。对抗网络不是在像素空间中生成示例,而是直接修改特征以模仿遮挡。
除了这些工作之外,旨在研究如何用对抗性例子攻击探测器的"对抗性攻击"[293]最近引起了越来越多的关注。关于这个主题的研究对于自动驾驶尤其重要,因为在保证对抗性攻击的鲁棒性之前,它不能完全可信。
4.9弱监督对象检测
现代物体检测器的训练通常需要大量的手动标记数据,而标记过程耗时,昂贵且效率低下。弱监督对象检测 (WSOD) 旨在通过训练仅使用图像级注释而不是边界框的探测器来解决此问题。
最近,多实例学习已用于 WSOD [294, 295]。多实例学习是一组监督学习方法[296,39]。多实例学习模型不是使用一组单独标记的实例进行学习,而是接收一组标记的袋子,每个袋子包含许多实例。如果我们将一个图像中的对象候选对象视为一个包,并将图像级注释视为标签,那么WSOD可以制定为多实例学习过程。
类激活映射是 WSOD 的另一组最新方法 [297, 298]。对CNN可视化的研究表明,尽管对物体的位置没有监督,但CNN的卷积层仍充当物体探测器。类激活映射阐明了如何使CNN具有定位能力,尽管在图像级标签上进行了训练[299]。
除了上述方法之外,其他一些研究人员还通过选择信息最丰富的区域,然后用图像级注释训练这些区域,将WSOD视为提案排名过程[300]。WSOD的另一种简单方法是遮罩图像的不同部分。如果检测分数急剧下降,那么物体将被高概率覆盖[301]。此外,交互式注释[295]在训练过程中会考虑人类反馈,以改进WSOD。最近,生成对抗训练已被用于WSOD [302]。
5应用
在本节中,我们将回顾过去20年中一些重要的检测应用,包括行人检测,人脸检测,文本检测,交通标志/灯光检测和遥感目标检测。
5.1行人检测
行人检测作为重要的物体检测应用,在自动驾驶、视频监控、刑事侦查等诸多领域受到广泛关注。一些早期的行人检测方法,如HOG检测器[12],ICF检测器[171],在特征表示[171,12],分类器[174]的设计以及检测加速度[177]方面为一般物体检测奠定了坚实的基础。. 近年来,一些通用的物体检测算法,如Faster RCNN[19],已被引入行人检测[165],并极大地推动了这一领域的进步。
困难和挑战
行人检测的挑战和困难可以总结如下。
小行人:图20(a)显示了远离相机捕获的小行人的一些示例。在加州理工学院数据集[59,60]中,15%的行人身高低于30像素。
硬底片:街景图像中的一些背景在视觉外观上与行人非常相似,如图20(b)所示。
密集和被遮挡的行人:图20(c)显示了一些密集和被遮挡的行人的例子。在加州理工学院数据集[59,60]中,未被遮挡的行人仅占行人总数的29%。
实时检测:高清视频的实时行人检测对于自动驾驶和视频监控等某些应用至关重要。

图 20: 加州理工学院数据集[59,60]中行人检测的一些硬例子:(a)小行人,(b)硬负片,以及(c)密集和被遮挡的行人。
文献综述
行人检测具有很长的研究历史[101,30,31]。它的发展可以分为两个技术时期:1)传统的行人检测和2)基于深度学习的行人检测。我们向读者推荐以下调查,以获取有关此主题的更多详细信息[303,304,60,305,306,307]。
传统的行人检测方法
由于计算资源的限制,Haar小波特征已被广泛用于早期的行人检测[30,31,308]。为了改善对被遮挡的行人的检测,当时的一个流行思想是"组件检测"[31,102,220],即将检测视为多个零件探测器的集合,这些探测器在不同的人体部位(例如头部,腿部和手臂)上进行单独训练。随着计算能力的提高,人们开始设计更复杂的检测模型,并且从2005年开始,基于梯度的表示[12,177,309,220,37]和DPM[15,37,54] 已成为行人检测的主流。2009年,通过使用积分图像加速,提出了一种有效且轻量级的特征表示:积分通道特征(ICF)[171]。ICF随后成为当时行人检测的新基准[60]。除了特征表示之外,还考虑了一些领域知识,例如外观恒定性和形状对称性[310]和立体信息[173,311]。
基于深度学习的行人检测方法
行人检测是最早应用深度学习的计算机视觉任务之一[312]。
为了改善小型行人检测:尽管深度学习对象检测器(如Fast/Faster R-CNN)在一般物体检测方面已经显示出最先进的性能,但由于卷积特征的分辨率较低,它们在检测小型行人方面的成功有限[165]。这个问题的一些最新解决方案包括特征融合[165],引入超高分辨率手工制作特征[313,314],以及在多种分辨率上结合检测结果[315]。
为了改进硬阴性检测:最近的一些改进包括增强决策树的集成[165]和语义分割(作为行人的上下文)[316]。此外,还引入了"跨模态学习"的想法,通过使用RGB和红外图像[317]来丰富硬负片的功能。
为了改善密集和被遮挡的行人检测:正如我们在第2.3.2节中提到的,CNN更深层中的特征具有更丰富的语义,但对于检测密集的物体无效。为此,一些研究人员通过考虑目标的吸引力和其他周围物体的排斥力来设计新的损失函数[318]。目标遮挡是通常由密集行人引起的另一个问题。零件探测器[319,320]和注意力机制[321]的集合是改善被遮挡行人检测的最常见方法。
5.2人脸检测
人脸检测是最古老的计算机视觉应用之一[96,164]。早期的面部检测,如VJ探测器[10],极大地促进了物体检测,即使在今天的物体检测中,它的许多非凡想法仍然发挥着重要作用。人脸检测现已应用于各行各业,如数码相机中的"微笑"检测、电子商务中的"刷脸"、移动应用中的面部化妆等。
困难和挑战
人脸检测的难点和挑战可以概括如下:
类内变化:人脸可能呈现各种表情、肤色、姿势和动作,如图21(a)所示。
遮挡:人脸可能被其他物体部分遮挡,如图21(b)所示。
多尺度检测:检测各种比例的人脸,特别是对于一些微小的人脸,如图21(c)所示。
实时检测:移动设备上的人脸检测通常需要CPU实时检测速度。

图 21: 人脸检测方面的挑战:(a)类内变异,来自WildestFaces数据集的图像[70]。(b)面部遮挡,来自UFDD数据集的图像[69]。(c) 多尺度人脸检测。图片来自P. Hu et al. CVPR2017 [322]。
文献综述
人脸检测的研究可以追溯到1990年代初[95,108,106]。然后,它经历了多个历史时期:早期的人脸检测(2001年之前),传统的人脸检测(2001-2015年)和基于深度学习的人脸检测(2015年至今)。我们向读者推荐以下调查以获取更多详细信息[323,324]。
早期的人脸检测(2001年之前)
早期的人脸检测算法可以分为三组:1)基于规则的方法。这组方法编码人类对典型面部构成的知识,并捕获面部元素之间的关系[107,108]。2)基于子空间分析的方法。这组方法分析了底层线性子空间中的人脸分布[95,106]。特征面是这组方法的代表[95]。3)基于学习的方法:将人脸检测框定为滑动窗口+二元分类(目标与背景)过程。该组的一些常用模型包括神经网络[96,164,325]和SVM [29,326]。
传统人脸检测(2000-2015)
这一时期有两组人脸检测器。第一组方法是基于提升决策树[10,109,11]构建的。这些方法易于计算,但在复杂场景下通常存在低检测精度的问题。第二组基于早期时间的卷积神经网络,其中特征的共享计算用于加速检测[112,113,327]。
基于深度学习的人脸检测(2015年以后)
在深度学习时代,大多数人脸检测算法都遵循了更快的RCNN、SSD等一般对象检测器的检测思路。
为了加快人脸检测的速度:级联检测(参见第3.3节中的更多细节)是深度学习时代加速人脸检测器的最常见方法[179,180]。另一种加速方法是预测图像中人脸的比例分布[283],然后在一些选定的刻度上运行检测。
为了改善多姿势和闭塞人脸检测:“人脸校准"的想法已被用于通过估计校准参数[279]或通过多个检测阶段使用渐进校准[277]来改善多姿势人脸检测。为了改善闭塞人脸检测,最近提出了两种方法。第一个是结合"注意力机制”,以突出潜在面部目标的特征[250]。第二个是"基于零件的检测"[328],它继承了DPM的思想。
为了改进多尺度人脸检测:最近关于多尺度人脸检测[329,322,330,331]的工作使用与一般物体检测中类似的检测策略,包括多尺度特征融合和多分辨率检测(有关详细信息,请参阅第2.3.2节和第4.2.2节)。
5.3文本检测
几千年来,文本一直是人类的主要信息载体。文本检测的基本目标是确定给定图像中是否存在文本,如果存在,则进行本地化和识别。文本检测具有非常广泛的应用。它帮助视障人士"阅读"街道标志和货币[332,333]。在地理信息系统中,门牌号和街道标志的检测和识别使得构建数字地图变得更加容易[334,335]。
困难和挑战
文本检测的难点和挑战可以总结如下:
不同的字体和语言:文本可能具有不同的字体、颜色和语言,如图 22 (a) 所示。
文本旋转和透视失真:文本可能具有不同的方向,甚至可能具有透视失真,如图 22 (b) 所示。
密集排列的文本本地化:具有大纵横比和密集布局的文本行难以准确定位,如图 22 (c) 所示。
破碎和模糊的字符:破碎和模糊的字符在街景图像中很常见。

图 22: 文本检测和识别方面的挑战:(a) 字体、颜色和语言的变化。图片来自maxpixel(无版权)。(b) 文本旋转和透视失真。图片来自Y. Liu等人。CVPR2017 [336].(c) 密集排列的文本本地化。图片来自Y. Wu et al. ICCV2017 [337]。
文献综述
文本检测由两个相关但相对独立的任务组成:1) 文本本地化和 2) 文本识别。现有的文本检测方法可以分为两组:“逐步检测"和"集成检测”。我们向读者推荐以下调查以获取更多详细信息[338,339]。
分步检测与集成检测
逐步检测方法[340,341]由一系列处理步骤组成,包括字符分割,候选区域验证,字符分组和单词识别。这组方法的优点是大部分背景可以在粗分割步骤中过滤,这大大降低了后续过程的计算成本。缺点是所有步骤的参数都需要仔细设置,并且错误将在每个步骤中发生并累积。相比之下,集成方法[342,343,344,345]将文本检测构建为联合概率推理问题,其中字符定位,分组和识别的步骤在统一的框架下进行处理。这些方法的优点是避免了累积误差,并且易于集成语言模型。缺点是,在考虑大量字符类和候选窗口时,推理的计算成本很高[339]。
传统方法与深度学习方法
大多数传统的文本检测方法以无监督的方式生成文本候选项,其中常用的技术包括最大稳定极值区域(MSER)分割[341]和形态滤波[346]。一些领域知识,如文本的对称性和笔画的结构,也在这些方法中被考虑在内[340,341,347]。
近年来,研究人员更加关注文本本地化而不是识别的问题。最近提出了两组方法。第一组方法将文本检测框定为一般对象检测的特殊情况[348,349,350,351,352,353,354,355,251,356,357].这些方法具有统一的检测框架,但对于检测具有方向或具有大纵横比的文本效果较差。第二组方法将文本检测框定为图像分割问题[358,336,337,359,360]。这些方法的优点是对文本的形状和方向没有特殊限制,但缺点是根据分割结果不容易区分密集排列的文本行。最近基于深度学习的文本检测方法针对上述问题提出了一些解决方案。
对于文本旋转和透视更改:此问题的最常见解决方案是在锚点框和 RoI 池层中引入与旋转和透视更改 [351, 352, 356, 357, 353, 355] 相关的其他参数。
为了改进密集排列的文本检测:基于分割的方法在检测密集排列的文本方面显示出更多的优势。为了区分相邻的文本行,最近提出了两组解决方案。第一个是"段和链接",其中"段"是指字符热图,"链接"是指两个相邻段之间的连接,表明它们属于同一个单词或文本行[358,336]。第二组是引入额外的角/边界检测任务,以帮助分离密集排列的文本,其中一组角或闭合边界对应于一行文本[337,359,360]。
为了改进破碎和模糊的文本检测:最近处理破碎和模糊文本的一个想法是使用单词级别[77,361]识别和句子级别识别[335]。为了处理具有不同字体的文本,最有效的方法是使用合成样本进行训练[77,348]。
5.4交通标志和交通信号灯检测
随着自动驾驶技术的发展,近年来交通标志和交通信号灯的自动检测引起了极大的关注。在过去的几十年里,尽管计算机视觉界在很大程度上推动了对一般物体的检测,而不是像交通信号灯和交通标志这样的固定模式,但认为它们的识别没有挑战性仍然是一个错误。
困难和挑战
交通标志/灯光检测的挑战和困难可以总结如下:
照明变化:当驶入太阳眩光或夜间时,检测将特别困难,如图23(a)所示。
运动模糊:车载摄像头拍摄的图像会因汽车的运动而变得模糊,如图23(b)所示。
恶劣天气:在恶劣天气下,例如雨天和下雪天,图像质量会受到影响,如图23(c)所示。
实时检测:这对于自动驾驶尤为重要。

图 23: 交通标志检测和交通信号灯检测方面的挑战:(a)照明变化。图片来自pxhere(不受版权保护)。(b) 运动模糊。图片来自GTSRB数据集[81]。(c) 恶劣天气下的探测。图片来自Flickr和Max Pixel(无版权)。
文献综述
现有的交通标志/灯光检测方法可以分为两类:1)传统的检测方法和2)基于深度学习的检测方法。我们向读者推荐以下调查[80],以获取有关此主题的更多详细信息。
传统检测方法
基于视觉的交通标志/灯光检测的研究可以追溯到20年前[362,363]。由于交通标志/灯光具有特定的形状和颜色,传统的检测方法通常基于颜色阈值[364,365,366,367,368],视觉显著性检测[369],形态学过滤[79]和边缘/轮廓分析[370,371]].由于上述方法仅基于低级视觉设计,因此在复杂环境下通常会失败(如图23所示),因此,一些研究人员开始寻找基于视觉的方法以外的其他解决方案,例如,在交通灯检测中结合GPS和数字地图[372,373].虽然"特征金字塔+滑动窗"在当时已经成为一般物体检测和行人检测的标准框架,但除了极少数作品[374]外,交通标志/灯光检测方法的主流直到2010年[375,376,377]才遵循这一范式。
基于深度学习的检测方法
在深度学习时代,一些著名的探测器,如Faster RCNN和SSD被应用于交通标志/灯光检测任务[83,84,378,379]。在这些探测器的基础上,一些新技术,如注意力机制和对抗训练,已被用于改善复杂交通环境下的检测[378,290]。
5.5遥感目标检测
遥感成像技术为人们更好地了解地球打开了一扇门。近年来,随着遥感影像分辨率的提高,遥感目标检测(如飞机、船舶、油罐等的检测)已成为研究热点。遥感目标探测具有广泛的应用,如军事调查、灾害救援、城市交通管理等。
困难和挑战
遥感目标探测的挑战和难点总结如下:
"大数据"中的检测:由于遥感影像数据量巨大,如何快速准确地探测遥感目标仍然是一个问题。图24(a)显示了遥感图像和自然图像之间数据量的比较。
遮挡目标:每天超过50%的地球表面被云层覆盖。遮挡目标的一些示例如图24(b)所示。
域适应:由不同传感器(例如,使用不同的调制和分辨率)捕获的遥感图像存在高度差异。

图 24: 遥感目标检测的挑战:(a)“大数据"中的检测:单视点遥感图像与VOC、ImageNet和MS-COCO的平均图像尺寸之间的数据量比较。(b) 被云遮挡的目标。图片来自S. Qiu et al. JSTARS2017 [380] 和 Z. Zou et al. TGRS2016 [381]。
文献综述
我们向读者推荐以下调查,以获取有关此主题的更多详细信息[90,382]。
传统检测方法
传统的遥感目标检测方法大多遵循两阶段检测模式:1)候选提取和2)目标验证。在候选提取阶段,一些常用的方法包括基于灰度值过滤的方法[383,384],基于视觉显著性的方法[385,386,387,388],基于小波变换的方法[389],基于异常检测的方法[390]等。上述方法的一个相似之处是它们都是无监督方法,因此通常在复杂环境中失败。在目标验证阶段,一些常用的功能包括HOG [391, 390]、LBP [384]、SIFT [386, 388, 392]等。此外,还有一些其他方法遵循滑动窗口检测范式[391,392,393,394]。
为了检测具有特定结构和形状的目标,例如油罐和近海船舶,使用了一些领域知识。例如,油罐检测可以被视为圆弧检测问题[395,396]。近岸船舶检测可以被认为是前甲板和船尾的检测[397,398]。为了改进闭塞目标的检测,一个常用的想法是"按部分检测”[399,380]。为了检测具有不同方向的目标,使用"混合模型"为不同方向的目标训练不同的探测器[273]。
基于深度学习的检测方法
在2014年RCNN取得巨大成功后,深度CNN很快被应用于遥感目标检测[275,276,400,401]。像Faster RCNN和SSD这样的通用对象检测框架在遥感社区引起了越来越多的关注[381,402,167,403,404,405,91]。
由于遥感图像和日常图像之间存在巨大差异,因此对深部CNN特征对遥感图像的有效性进行了一些研究[406,407,408]。人们发现,尽管CNN取得了巨大的成功,但它并不比传统的光谱数据方法更好[406]。为了检测具有不同方向的目标,一些研究人员改进了ROI池化层,以获得更好的旋转不变性[409,272]。为了改善域适应性,一些研究人员从贝叶斯的观点制定了检测,即在检测阶段,模型根据测试图像的分布进行自适应更新[91]。此外,注意力机制和特征融合策略也已被用于改善小目标检测[410,411]。
6结论和未来方向
在过去的20年中,物体检测取得了令人瞩目的成就。本文不仅广泛回顾了其20年历史中的一些里程碑检测器(如VJ检测器、HOG检测器、DPM、Faster-RCNN、YOLO、SSD等)、关键技术、加速方法、检测应用、数据集和指标,还讨论了社区目前面临的挑战,以及如何进一步扩展和改进这些检测器。
未来对物体检测的研究可能重点但不限于以下几个方面:
轻量级对象检测:加快检测算法,使其能够在移动设备上平稳运行。一些重要的应用包括移动增强现实,智能相机,人脸验证等。虽然近年来已经付出了很大的努力,但机器和人眼之间的速度差距仍然很大,特别是在检测一些小物体时。
检测与AutoML相遇:最近基于深度学习的检测器变得越来越复杂,并且严重依赖体验。未来的方向是通过使用神经架构搜索来减少设计检测模型时的人为干预(例如,如何设计引擎以及如何设置锚框)。AutoML可能是对象检测的未来。
检测与域适应相结合:任何目标检测器的训练过程基本上都可以被视为在独立且相同分布(i.i.d.)数据的假设下的可能性估计过程。使用非 i.i.d. 进行物体检测数据,特别是对于一些现实世界的应用程序,仍然是一个挑战。GAN在领域适应方面显示出有希望的结果,并可能对未来的物体检测有很大帮助。
弱监督检测:基于深度学习的检测器的训练通常依赖于大量注释良好的图像。注释过程耗时、昂贵且效率低下。开发弱监督检测技术,其中探测器仅使用图像级注释进行训练,或部分使用边界框注释进行训练,这对于降低人工成本和提高检测灵活性非常重要。
小物体检测:长期以来,在大型场景中检测小物体一直是一项挑战。该研究方向的一些潜在应用包括用遥感图像计算野生动物的数量和检测一些重要军事目标的状态。一些进一步的方向可能包括视觉注意力机制的集成和高分辨率轻量级网络的设计。
视频中的检测:高清视频中的实时物体检测/跟踪对于视频监控和自动驾驶非常重要。传统的物体检测器通常设计为图像检测,而只是忽略了视频帧之间的相关性。通过探索时空相关性来提高检测水平是一个重要的研究方向。
信息融合检测:使用多种数据源/数据模式(例如RGB-D图像、3D点云、激光雷达等)进行对象检测对于自动驾驶和无人机应用具有重要意义。一些悬而未决的问题包括:如何将训练有素的探测器迁移到不同的数据形式,如何进行信息融合以改善检测等。
站在技术演进的高速公路上,我们相信本文将帮助读者建立一个物体检测的大图景,并找到这个快速发展的研究领域的未来方向。
参考文献
[1] B. Hariharan, P. Arbelaez, R. Girshick, and J. Malik, ´ “Simultaneous detection and segmentation,” in European Conference on Computer Vision. Springer, 2014, pp. 297– 312.
[2] “Hypercolumns for object segmentation and finegrained localization,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 447– 456.
[3] J. Dai, K. He, and J. Sun, “Instance-aware semantic segmentation via multi-task network cascades,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 3150–3158.
[4] K. He, G. Gkioxari, P. Dollar, and R. Girshick, “Mask r- ´ cnn,” in Computer Vision (ICCV), 2017 IEEE International Conference on. IEEE, 2017, pp. 2980–2988.
[5] A. Karpathy and L. Fei-Fei, “Deep visual-semantic alignments for generating image descriptions,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 3128–3137.
[6] K. Xu, J. Ba, R. Kiros, K. Cho, A. Courville, R. Salakhudinov, R. Zemel, and Y. Bengio, “Show, attend and tell: Neural image caption generation with visual attention,” in International conference on machine learning, 2015, pp. 2048–2057.
[7] Q. Wu, C. Shen, P. Wang, A. Dick, and A. van den Hengel, “Image captioning and visual question answering based on attributes and external knowledge,” IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 6, pp. 1367–1381, 2018.
[8] K. Kang, H. Li, J. Yan, X. Zeng, B. Yang, T. Xiao, C. Zhang, Z. Wang, R. Wang, X. Wang et al., “T-cnn: Tubelets with convolutional neural networks for object detection from videos,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 28, no. 10, pp. 2896–2907, 2018.
[9] Y. LeCun, Y. Bengio, and G. Hinton, “Deep learning,” nature, vol. 521, no. 7553, p. 436, 2015.
[10] P. Viola and M. Jones, “Rapid object detection using a boosted cascade of simple features,” in Computer Vision and Pattern Recognition, 2001. CVPR 2001. Proceedings of the 2001 IEEE Computer Society Conference on, vol. 1. IEEE, 2001, pp. I–I.
[11] P. Viola and M. J. Jones, “Robust real-time face detection,” International journal of computer vision, vol. 57, no. 2, pp. 137–154, 2004.
[12] N. Dalal and B. Triggs, “Histograms of oriented gradients for human detection,” in Computer Vision and Pattern Recognition, 2005. CVPR 2005. IEEE Computer Society Conference on, vol. 1. IEEE, 2005, pp. 886–893.
[13] P. Felzenszwalb, D. McAllester, and D. Ramanan, “A discriminatively trained, multiscale, deformable part model,” in Computer Vision and Pattern Recognition, 2008. CVPR 2008. IEEE Conference on. IEEE, 2008, pp. 1–8.
[14] P. F. Felzenszwalb, R. B. Girshick, and D. McAllester, “Cascade object detection with deformable part models,” in Computer vision and pattern recognition (CVPR), 2010 IEEE conference on. IEEE, 2010, pp. 2241–2248.
[15] P. F. Felzenszwalb, R. B. Girshick, D. McAllester, and D. Ramanan, “Object detection with discriminatively trained part-based models,” IEEE transactions on pattern analysis and machine intelligence, vol. 32, no. 9, pp. 1627– 1645, 2010.
[16] R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich feature hierarchies for accurate object detection and semantic segmentation,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2014, pp. 580– 587.
[17] K. He, X. Zhang, S. Ren, and J. Sun, “Spatial pyramid pooling in deep convolutional networks for visual 29 recognition,” in European conference on computer vision. Springer, 2014, pp. 346–361.
[18] R. Girshick, “Fast r-cnn,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 1440–1448.
[19] S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards real-time object detection with region proposal networks,” in Advances in neural information processing systems, 2015, pp. 91–99.
[20] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 779–788.
[21] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, and A. C. Berg, “Ssd: Single shot multibox detector,” in European conference on computer vision. Springer, 2016, pp. 21–37.
[22] T.-Y. Lin, P. Dollar, R. B. Girshick, K. He, B. Hariharan, ´ and S. J. Belongie, “Feature pyramid networks for object detection.” in CVPR, vol. 1, no. 2, 2017, p. 4.
[23] T.-Y. Lin, P. Goyal, R. Girshick, K. He, and P. Dollar, ´ “Focal loss for dense object detection,” IEEE transactions on pattern analysis and machine intelligence, 2018.
[24] L. Liu, W. Ouyang, X. Wang, P. Fieguth, J. Chen, X. Liu, and M. Pietikainen, “Deep learning for generic object de- ¨ tection: A survey,” arXiv preprint arXiv:1809.02165, 2018.
[25] S. Agarwal, J. O. D. Terrail, and F. Jurie, “Recent advances in object detection in the age of deep convolutional neural networks,” arXiv preprint arXiv:1809.03193, 2018.
[26] A. Andreopoulos and J. K. Tsotsos, “50 years of object recognition: Directions forward,” Computer vision and image understanding, vol. 117, no. 8, pp. 827–891, 2013.
[27] J. Huang, V. Rathod, C. Sun, M. Zhu, A. Korattikara, A. Fathi, I. Fischer, Z. Wojna, Y. Song, S. Guadarrama et al., “Speed/accuracy trade-offs for modern convolutional object detectors,” in IEEE CVPR, vol. 4, 2017.
[28] K. Grauman and B. Leibe, “Visual object recognition (synthesis lectures on artificial intelligence and machine learning),” Morgan & Claypool, 2011.
[29] C. P. Papageorgiou, M. Oren, and T. Poggio, “A general framework for object detection,” in Computer vision, 1998. sixth international conference on. IEEE, 1998, pp. 555–562.
[30] C. Papageorgiou and T. Poggio, “A trainable system for object detection,” International journal of computer vision, vol. 38, no. 1, pp. 15–33, 2000.
[31] A. Mohan, C. Papageorgiou, and T. Poggio, “Examplebased object detection in images by components,” IEEE Transactions on Pattern Analysis & Machine Intelligence, no. 4, pp. 349–361, 2001.
[32] Y. Freund, R. Schapire, and N. Abe, “A short introduction to boosting,” Journal-Japanese Society For Artificial Intelligence, vol. 14, no. 771-780, p. 1612, 1999.
[33] D. G. Lowe, “Object recognition from local scale-invariant features,” in Computer vision, 1999. The proceedings of the seventh IEEE international conference on, vol. 2. Ieee, 1999, pp. 1150–1157.
[34] ——, “Distinctive image features from scale-invariant keypoints,” International journal of computer vision, vol. 60, no. 2, pp. 91–110, 2004.
[35] S. Belongie, J. Malik, and J. Puzicha, “Shape matching and object recognition using shape contexts,” CALIFORNIA UNIV SAN DIEGO LA JOLLA DEPT OF COMPUTER SCIENCE AND ENGINEERING, Tech. Rep., 2002.
[36] T. Malisiewicz, A. Gupta, and A. A. Efros, “Ensemble of exemplar-svms for object detection and beyond,” in Computer Vision (ICCV), 2011 IEEE International Conference on. IEEE, 2011, pp. 89–96.
[37] R. B. Girshick, P. F. Felzenszwalb, and D. A. Mcallester, “Object detection with grammar models,” in Advances in Neural Information Processing Systems, 2011, pp. 442–450.
[38] R. B. Girshick, From rigid templates to grammars: Object detection with structured models. Citeseer, 2012.
[39] S. Andrews, I. Tsochantaridis, and T. Hofmann, “Support vector machines for multiple-instance learning,” in Advances in neural information processing systems, 2003, pp. 577–584.
[40] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” in Advances in neural information processing systems, 2012, pp. 1097–1105.
[41] R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Regionbased convolutional networks for accurate object detection and segmentation,” IEEE transactions on pattern analysis and machine intelligence, vol. 38, no. 1, pp. 142– 158, 2016.
[42] K. E. Van de Sande, J. R. Uijlings, T. Gevers, and A. W. Smeulders, “Segmentation as selective search for object recognition,” in Computer Vision (ICCV), 2011 IEEE International Conference on. IEEE, 2011, pp. 1879–1886.
[43] R. B. Girshick, P. F. Felzenszwalb, and D. McAllester, “Discriminatively trained deformable part models, release 5,” http://people.cs.uchicago.edu/ rbg/latentrelease5/.
[44] S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: towards real-time object detection with region proposal networks,” IEEE Transactions on Pattern Analysis & Machine Intelligence, no. 6, pp. 1137–1149, 2017.
[45] M. D. Zeiler and R. Fergus, “Visualizing and understanding convolutional networks,” in European conference on computer vision. Springer, 2014, pp. 818–833.
[46] J. Dai, Y. Li, K. He, and J. Sun, “R-fcn: Object detection via region-based fully convolutional networks,” in Advances in neural information processing systems, 2016, pp. 379–387.
[47] Z. Li, C. Peng, G. Yu, X. Zhang, Y. Deng, and J. Sun, “Light-head r-cnn: In defense of two-stage object detector,” arXiv preprint arXiv:1711.07264, 2017.
[48] J. Redmon and A. Farhadi, “Yolo9000: better, faster, stronger,” arXiv preprint, 2017.
[49] ——, “Yolov3: An incremental improvement,” arXiv preprint arXiv:1804.02767, 2018.
[50] M. Everingham, L. Van Gool, C. K. Williams, J. Winn, and A. Zisserman, “The pascal visual object classes (voc) challenge,” International journal of computer vision, vol. 88, no. 2, pp. 303–338, 2010.
[51] M. Everingham, S. A. Eslami, L. Van Gool, C. K. Williams, J. Winn, and A. Zisserman, “The pascal visual object classes challenge: A retrospective,” International journal of computer vision, vol. 111, no. 1, pp. 98–136, 2015.
[52] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein et al., “Imagenet large scale visual recognition challenge,” International Journal of Computer Vision, vol. 115, no. 3, pp. 211–252, 2015.
[53] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollar, and C. L. Zitnick, “Microsoft coco: ´ Common objects in context,” in European conference on computer vision. Springer, 2014, pp. 740–755.
[54] M. A. Sadeghi and D. Forsyth, “30hz object detection with dpm v5,” in European Conference on Computer Vision. Springer, 2014, pp. 65–79.
[55] S. Zhang, L. Wen, X. Bian, Z. Lei, and S. Z. Li, “Singleshot refinement neural network for object detection,” in IEEE CVPR, 2018.
[56] Y. Li, Y. Chen, N. Wang, and Z. Zhang, “Scale-aware trident networks for object detection,” arXiv preprint arXiv:1901.01892, 2019.
[57] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on. Ieee, 2009, pp. 248–255.
[58] I. Krasin and T. e. a. Duerig, “Openimages: A 30 public dataset for large-scale multi-label and multiclass image classification.” Dataset available from https://storage.googleapis.com/openimages/web/index.html, 2017.
[59] P. Dollar, C. Wojek, B. Schiele, and P. Perona, “Pedestrian ´ detection: A benchmark,” in Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on. IEEE, 2009, pp. 304–311.
[60] P. Dollar, C. Wojek, B. Schiele, and P. Perona, “Pedestrian detection: An evaluation of the state of the art,” IEEE transactions on pattern analysis and machine intelligence, vol. 34, no. 4, pp. 743–761, 2012.
[61] A. Geiger, P. Lenz, and R. Urtasun, “Are we ready for autonomous driving? the kitti vision benchmark suite,” in Computer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on. IEEE, 2012, pp. 3354–3361.
[62] S. Zhang, R. Benenson, and B. Schiele, “Citypersons: A diverse dataset for pedestrian detection,” in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), vol. 1, no. 2, 2017, p. 3.
[63] M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele, “The cityscapes dataset for semantic urban scene understanding,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 3213–3223.
[64] M. Braun, S. Krebs, F. Flohr, and D. M. Gavrila, “The eurocity persons dataset: A novel benchmark for object detection,” arXiv preprint arXiv:1805.07193, 2018.
[65] V. Jain and E. Learned-Miller, “Fddb: A benchmark for face detection in unconstrained settings,” Technical Report UM-CS-2010-009, University of Massachusetts, Amherst, Tech. Rep., 2010.
[66] M. Koestinger, P. Wohlhart, P. M. Roth, and H. Bischof, “Annotated facial landmarks in the wild: A large-scale, real-world database for facial landmark localization,” in Computer Vision Workshops (ICCV Workshops), 2011 IEEE International Conference on. IEEE, 2011, pp. 2144–2151.
[67] B. F. Klare, B. Klein, E. Taborsky, A. Blanton, J. Cheney, K. Allen, P. Grother, A. Mah, and A. K. Jain, “Pushing the frontiers of unconstrained face detection and recognition: Iarpa janus benchmark a,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 1931–1939.
[68] S. Yang, P. Luo, C.-C. Loy, and X. Tang, “Wider face: A face detection benchmark,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 5525–5533.
[69] H. Nada, V. A. Sindagi, H. Zhang, and V. M. Patel, “Pushing the limits of unconstrained face detection: a challenge dataset and baseline results,” arXiv preprint arXiv:1804.10275, 2018.
[70] M. K. Yucel, Y. C. Bilge, O. Oguz, N. Ikizler-Cinbis, P. Duygulu, and R. G. Cinbis, “Wildest faces: Face detection and recognition in violent settings,” arXiv preprint arXiv:1805.07566, 2018.
[71] S. M. Lucas, A. Panaretos, L. Sosa, A. Tang, S. Wong, and R. Young, “Icdar 2003 robust reading competitions,” in null. IEEE, 2003, p. 682.
[72] D. Karatzas, L. Gomez-Bigorda, A. Nicolaou, S. Ghosh, A. Bagdanov, M. Iwamura, J. Matas, L. Neumann, V. R. Chandrasekhar, S. Lu et al., “Icdar 2015 competition on robust reading,” in Document Analysis and Recognition (ICDAR), 2015 13th International Conference on. IEEE, 2015, pp. 1156–1160.
[73] B. Shi, C. Yao, M. Liao, M. Yang, P. Xu, L. Cui, S. Belongie, S. Lu, and X. Bai, “Icdar2017 competition on reading chinese text in the wild (rctw-17),” in Document Analysis and Recognition (ICDAR), 2017 14th IAPR International Conference on, vol. 1. IEEE, 2017, pp. 1429–1434.
[74] K. Wang and S. Belongie, “Word spotting in the wild,” in European Conference on Computer Vision. Springer, 2010, pp. 591–604.
[75] C. Yao, X. Bai, W. Liu, Y. Ma, and Z. Tu, “Detecting texts of arbitrary orientations in natural images,” in 2012 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2012, pp. 1083–1090.
[76] A. Mishra, K. Alahari, and C. Jawahar, “Scene text recognition using higher order language priors,” in BMVCBritish Machine Vision Conference. BMVA, 2012.
[77] M. Jaderberg, K. Simonyan, A. Vedaldi, and A. Zisserman, “Synthetic data and artificial neural networks for natural scene text recognition,” arXiv preprint arXiv:1406.2227, 2014.
[78] A. Veit, T. Matera, L. Neumann, J. Matas, and S. Belongie, “Coco-text: Dataset and benchmark for text detection and recognition in natural images,” arXiv preprint arXiv:1601.07140, 2016.
[79] R. De Charette and F. Nashashibi, “Real time visual traffic lights recognition based on spot light detection and adaptive traffic lights templates,” in Intelligent Vehicles Symposium, 2009 IEEE. IEEE, 2009, pp. 358–363.
[80] A. Møgelmose, M. M. Trivedi, and T. B. Moeslund, “Vision-based traffic sign detection and analysis for intelligent driver assistance systems: Perspectives and survey.” IEEE Trans. Intelligent Transportation Systems, vol. 13, no. 4, pp. 1484–1497, 2012.
[81] S. Houben, J. Stallkamp, J. Salmen, M. Schlipsing, and C. Igel, “Detection of traffic signs in real-world images: The german traffic sign detection benchmark,” in Neural Networks (IJCNN), The 2013 International Joint Conference on. IEEE, 2013, pp. 1–8.
[82] R. Timofte, K. Zimmermann, and L. Van Gool, “Multiview traffic sign detection, recognition, and 3d localisation,” Machine vision and applications, vol. 25, no. 3, pp. 633–647, 2014.
[83] Z. Zhu, D. Liang, S. Zhang, X. Huang, B. Li, and S. Hu, “Traffic-sign detection and classification in the wild,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 2110–2118.
[84] K. Behrendt, L. Novak, and R. Botros, “A deep learning approach to traffic lights: Detection, tracking, and classification,” in Robotics and Automation (ICRA), 2017 IEEE International Conference on. IEEE, 2017, pp. 1370–1377.
[85] G. Heitz and D. Koller, “Learning spatial context: Using stuff to find things,” in European conference on computer vision. Springer, 2008, pp. 30–43.
[86] F. Tanner, B. Colder, C. Pullen, D. Heagy, M. Eppolito, V. Carlan, C. Oertel, and P. Sallee, “Overhead imagery research data setan annotated data library & tools to aid in the development of computer vision algorithms,” in 2009 IEEE Applied Imagery Pattern Recognition Workshop (AIPR 2009). IEEE, 2009, pp. 1–8.
[87] K. Liu and G. Mattyus, “Fast multiclass vehicle detection on aerial images.” IEEE Geosci. Remote Sensing Lett., vol. 12, no. 9, pp. 1938–1942, 2015.
[88] H. Zhu, X. Chen, W. Dai, K. Fu, Q. Ye, and J. Jiao, “Orientation robust object detection in aerial images using deep convolutional neural network,” in Image Processing (ICIP), 2015 IEEE International Conference on. IEEE, 2015, pp. 3735–3739.
[89] S. Razakarivony and F. Jurie, “Vehicle detect 31 cessing, vol. 27, no. 3, pp. 1100–1111, 2018.
[90] G. Cheng and J. Han, “A survey on object detection in optical remote sensing images,” ISPRS Journal of Photogrammetry and Remote Sensing, vol. 117, pp. 11–28, 2016.
[91] Z. Zou and Z. Shi, “Random access memories: A new paradigm for target detection in high resolution aerial remote sensing images,” IEEE Transactions on Image Pro- 31 cessing, vol. 27, no. 3, pp. 1100–1111, 2018.
[92] G.-S. Xia, X. Bai, J. Ding, Z. Zhu, S. Belongie, J. Luo, M. Datcu, M. Pelillo, and L. Zhang, “Dota: A large-scale dataset for object detection in aerial images,” in Proc. CVPR, 2018.
[93] D. Lam, R. Kuzma, K. McGee, S. Dooley, M. Laielli, M. Klaric, Y. Bulatov, and B. McCord, “xview: Objects in context in overhead imagery,” arXiv preprint arXiv:1802.07856, 2018.
[94] K. Oksuz, B. C. Cam, E. Akbas, and S. Kalkan, “Localization recall precision (lrp): A new performance metric for object detection,” in European Conference on Computer Vision (ECCV), vol. 6, 2018.
[95] M. Turk and A. Pentland, “Eigenfaces for recognition,” Journal of cognitive neuroscience, vol. 3, no. 1, pp. 71–86, 1991.
[96] R. Vaillant, C. Monrocq, and Y. Le Cun, “Original approach for the localisation of objects in images,” IEE Proceedings-Vision, Image and Signal Processing, vol. 141, no. 4, pp. 245–250, 1994.
[97] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, “Gradientbased learning applied to document recognition,” Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998.
[98] I. Biederman, “Recognition-by-components: a theory of human image understanding.” Psychological review, vol. 94, no. 2, p. 115, 1987.
[99] M. A. Fischler and R. A. Elschlager, “The representation and matching of pictorial structures,” IEEE Transactions on computers, vol. 100, no. 1, pp. 67–92, 1973.
[100] B. Leibe, A. Leonardis, and B. Schiele, “Robust object detection with interleaved categorization and segmentation,” International journal of computer vision, vol. 77, no. 1-3, pp. 259–289, 2008.
[101] D. M. Gavrila and V. Philomin, “Real-time object detection for” smart” vehicles,” in Computer Vision, 1999. The Proceedings of the Seventh IEEE International Conference on, vol. 1. IEEE, 1999, pp. 87–93.
[102] B. Wu and R. Nevatia, “Detection of multiple, partially occluded humans in a single image by bayesian combination of edgelet part detectors,” in null. IEEE, 2005, pp. 90–97.
[103] P. Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus, and Y. LeCun, “Overfeat: Integrated recognition, localization and detection using convolutional networks,” arXiv preprint arXiv:1312.6229, 2013.
[104] C. Szegedy, A. Toshev, and D. Erhan, “Deep neural networks for object detection,” in Advances in neural information processing systems, 2013, pp. 2553–2561.
[105] Z. Cai, Q. Fan, R. S. Feris, and N. Vasconcelos, “A unified multi-scale deep convolutional neural network for fast object detection,” in European Conference on Computer Vision. Springer, 2016, pp. 354–370.
[106] A. Pentland, B. Moghaddam, T. Starner et al., “Viewbased and modular eigenspaces for face recognition,” 1994.
[107] G. Yang and T. S. Huang, “Human face detection in a complex background,” Pattern recognition, vol. 27, no. 1, pp. 53–63, 1994.
[108] I. Craw, D. Tock, and A. Bennett, “Finding face features,” in European Conference on Computer Vision. Springer, 1992, pp. 92–96.
[109] R. Xiao, L. Zhu, and H.-J. Zhang, “Boosting chain learning for object detection,” in Computer Vision, 2003. Proceedings. Ninth IEEE International Conference on. IEEE, 2003, pp. 709–715.
[110] J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional networks for semantic segmentation,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 3431–3440.
[111] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille, “Semantic image segmentation with deep convolutional nets and fully connected crfs,” arXiv preprint arXiv:1412.7062, 2014.
[112] C. Garcia and M. Delakis, “A neural architecture for fast and robust face detection,” in Pattern Recognition, 2002. Proceedings. 16th International Conference on, vol. 2. IEEE, 2002, pp. 44–47.
[113] M. Osadchy, M. L. Miller, and Y. L. Cun, “Synergistic face detection and pose estimation with energy-based models,” in Advances in Neural Information Processing Systems, 2005, pp. 1017–1024.
[114] S. J. Nowlan and J. C. Platt, “A convolutional neural network hand tracker,” Advances in neural information processing systems, pp. 901–908, 1995.
[115] T. Malisiewicz, Exemplar-based representations for object detection, association and beyond. Carnegie Mellon University, 2011.
[116] B. Alexe, T. Deselaers, and V. Ferrari, “What is an object?” in Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on. IEEE, 2010, pp. 73–80.
[117] J. R. Uijlings, K. E. Van De Sande, T. Gevers, and A. W. Smeulders, “Selective search for object recognition,” International journal of computer vision, vol. 104, no. 2, pp. 154–171, 2013.
[118] J. Carreira and C. Sminchisescu, “Constrained parametric min-cuts for automatic object segmentation,” in Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on. IEEE, 2010, pp. 3241–3248.
[119] P. Arbelaez, J. Pont-Tuset, J. T. Barron, F. Marques, and ´ J. Malik, “Multiscale combinatorial grouping,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2014, pp. 328–335.
[120] B. Alexe, T. Deselaers, and V. Ferrari, “Measuring the objectness of image windows,” IEEE transactions on pattern analysis and machine intelligence, vol. 34, no. 11, pp. 2189– 2202, 2012.
[121] M.-M. Cheng, Z. Zhang, W.-Y. Lin, and P. Torr, “Bing: Binarized normed gradients for objectness estimation at 300fps,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2014, pp. 3286–3293.
[122] C. L. Zitnick and P. Dollar, “Edge boxes: Locating object ´ proposals from edges,” in European conference on computer vision. Springer, 2014, pp. 391–405.
[123] C. Szegedy, S. Reed, D. Erhan, D. Anguelov, and S. Ioffe, “Scalable, high-quality object detection,” arXiv preprint arXiv:1412.1441, 2014.
[124] D. Erhan, C. Szegedy, A. Toshev, and D. Anguelov, “Scalable object detection using deep neural networks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2014, pp. 2147–2154.
[125] A. Ghodrati, A. Diba, M. Pedersoli, T. Tuytelaars, and L. Van Gool, “Deepproposal: Hunting objects by cascading deep convolutional layers,” in Proceedings of the IEEE International Conference on Computer Vision, 2015, pp. 2578–2586.
[126] W. Kuo, B. Hariharan, and J. Malik, “Deepbox: Learning objectness with convolutional networks,” in Proceedings of the IEEE International Conference on Computer Vision, 2015, pp. 2479–2487.
[127] S. Gidaris and N. Komodakis, “Attend refine repeat: Active box proposal generation via in-out localization,” arXiv preprint arXiv:1606.04446, 2016.
[128] H. Li, Y. Liu, W. Ouyang, and X. Wang, “Zoom out-andin network with recursive training for object proposal,” arXiv preprint arXiv:1702.05711, 2017.
[129] J. Hosang, R. Benenson, P. Dollar, and B. Schiele, “What ´ makes for effective detection proposals?” IEEE transactions on pattern analysis and machine intelligence, vol. 38, no. 4, pp. 814–830, 2016.
[130] J. Hosang, R. Benenson, and B. Schiele, “How 32 good are detection proposals, really?” arXiv preprint arXiv:1406.6962, 2014.
[131] J. Carreira and C. Sminchisescu, “Cpmc: Automatic object segmentation using constrained parametric min-cuts,” IEEE Transactions on Pattern Analysis & Machine Intelligence, no. 7, pp. 1312–1328, 2011.
[132] N. Chavali, H. Agrawal, A. Mahendru, and D. Batra, “Object-proposal evaluation protocol is’ gameable’,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 835–844.
[133] K. Lenc and A. Vedaldi, “R-cnn minus r,” arXiv preprint arXiv:1506.06981, 2015.
[134] P.-A. Savalle, S. Tsogkas, G. Papandreou, and I. Kokkinos, “Deformable part models with cnn features,” in European Conference on Computer Vision, Parts and Attributes Workshop, 2014.
[135] N. Zhang, J. Donahue, R. Girshick, and T. Darrell, “Partbased r-cnns for fine-grained category detection,” in European conference on computer vision. Springer, 2014, pp. 834–849.
[136] L. Wan, D. Eigen, and R. Fergus, “End-to-end integration of a convolution network, deformable parts model and non-maximum suppression,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 851–859.
[137] R. Girshick, F. Iandola, T. Darrell, and J. Malik, “Deformable part models are convolutional neural networks,” in Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2015, pp. 437–446.
[138] B. Li, T. Wu, S. Shao, L. Zhang, and R. Chu, “Object detection via end-to-end integration of aspect ratio and context aware part-based models and fully convolutional networks,” arXiv preprint arXiv:1612.00534, 2016.
[139] A. Torralba and P. Sinha, “Detecting faces in impoverished images,” MASSACHUSETTS INST OF TECH CAMBRIDGE ARTIFICIAL INTELLIGENCE LAB, Tech. Rep., 2001.
[140] S. Zagoruyko, A. Lerer, T.-Y. Lin, P. O. Pinheiro, S. Gross, S. Chintala, and P. Dollar, “A multipath network for ´ object detection,” arXiv preprint arXiv:1604.02135, 2016.
[141] X. Zeng, W. Ouyang, B. Yang, J. Yan, and X. Wang, “Gated bi-directional cnn for object detection,” in European Conference on Computer Vision. Springer, 2016, pp. 354–369.
[142] X. Zeng, W. Ouyang, J. Yan, H. Li, T. Xiao, K. Wang, Y. Liu, Y. Zhou, B. Yang, Z. Wang et al., “Crafting gbd-net for object detection,” IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 9, pp. 2109–2123, 2018.
[143] W. Ouyang, K. Wang, X. Zhu, and X. Wang, “Learning chained deep features and classifiers for cascade in object detection,” arXiv preprint arXiv:1702.07054, 2017.
[144] S. Gidaris and N. Komodakis, “Object detection via a multi-region and semantic segmentation-aware cnn model,” in Proceedings of the IEEE International Conference on Computer Vision, 2015, pp. 1134–1142.
[145] Y. Zhu, C. Zhao, J. Wang, X. Zhao, Y. Wu, H. Lu et al., “Couplenet: Coupling global structure with local parts for object detection,” in Proc. of Intl Conf. on Computer Vision (ICCV), vol. 2, 2017.
[146] C. Desai, D. Ramanan, and C. C. Fowlkes, “Discriminative models for multi-class object layout,” International journal of computer vision, vol. 95, no. 1, pp. 1–12, 2011.
[147] Z. Li, Y. Chen, G. Yu, and Y. Deng, “R-fcn++: Towards accurate region-based fully convolutional networks for object detection.” in AAAI, 2018.
[148] S. Bell, C. Lawrence Zitnick, K. Bala, and R. Girshick, “Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 2874–2883.
[149] J. Li, Y. Wei, X. Liang, J. Dong, T. Xu, J. Feng, and S. Yan, “Attentive contexts for object detection,” IEEE Transactions on Multimedia, vol. 19, no. 5, pp. 944–954, 2017.
[150] Q. Chen, Z. Song, J. Dong, Z. Huang, Y. Hua, and S. Yan, “Contextualizing object detection and classification,” IEEE transactions on pattern analysis and machine intelligence, vol. 37, no. 1, pp. 13–27, 2015.
[151] S. Gupta, B. Hariharan, and J. Malik, “Exploring person context and local scene context for object detection,” arXiv preprint arXiv:1511.08177, 2015.
[152] X. Chen and A. Gupta, “Spatial memory for context reasoning in object detection,” arXiv preprint arXiv:1704.04224, 2017.
[153] Y. Liu, R. Wang, S. Shan, and X. Chen, “Structure inference net: Object detection using scene-level context and instance-level relationships,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 6985–6994.
[154] J. H. Hosang, R. Benenson, and B. Schiele, “Learning nonmaximum suppression.” in CVPR, 2017, pp. 6469–6477.
[155] P. Henderson and V. Ferrari, “End-to-end training of object class detectors for mean average precision,” in Asian Conference on Computer Vision. Springer, 2016, pp. 198–213.
[156] R. Rothe, M. Guillaumin, and L. Van Gool, “Nonmaximum suppression for object detection by passing messages between windows,” in Asian Conference on Computer Vision. Springer, 2014, pp. 290–306.
[157] D. Mrowca, M. Rohrbach, J. Hoffman, R. Hu, K. Saenko, and T. Darrell, “Spatial semantic regularisation for large scale object detection,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 2003–2011.
[158] N. Bodla, B. Singh, R. Chellappa, and L. S. Davis, “Softnmsimproving object detection with one line of code,” in Computer Vision (ICCV), 2017 IEEE International Conference on. IEEE, 2017, pp. 5562–5570.
[159] L. Tychsen-Smith and L. Petersson, “Improving object localization with fitness nms and bounded iou loss,” arXiv preprint arXiv:1711.00164, 2017.
[160] S. K. Divvala, D. Hoiem, J. H. Hays, A. A. Efros, and M. Hebert, “An empirical study of context in object detection,” in Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on. IEEE, 2009, pp. 1271– 1278.
[161] C. Chen, M.-Y. Liu, O. Tuzel, and J. Xiao, “R-cnn for small object detection,” in Asian conference on computer vision. Springer, 2016, pp. 214–230.
[162] H. Hu, J. Gu, Z. Zhang, J. Dai, and Y. Wei, “Relation networks for object detection,” in Computer Vision and Pattern Recognition (CVPR), vol. 2, no. 3, 2018.
[163] B. Jiang, R. Luo, J. Mao, T. Xiao, and Y. Jiang, “Acquisition of localization confidence for accurate object detection,” in Proceedings of the European Conference on Computer Vision, Munich, Germany, 2018, pp. 8–14.
[164] H. A. Rowley, S. Baluja, and T. Kanade, “Human face detection in visual scenes,” in Advances in Neural Information Processing Systems, 1996, pp. 875–881.
[165] L. Zhang, L. Lin, X. Liang, and K. He, “Is faster rcnn doing well for pedestrian detection?” in European Conference on Computer Vision. Springer, 2016, pp. 443– 457.
[166] A. Shrivastava, A. Gupta, and R. Girshick, “Training region-based object detectors with online hard example mining,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 761–769.
[167] T. Tang, S. Zhou, Z. Deng, H. Zou, and L. Lei, “Vehicle detection in aerial images based on region convolutional neural networks and hard negative example mining,” Sensors, vol. 17, no. 2, p. 336, 2017.
[168] X. Sun, P. Wu, and S. C. Hoi, “Face detection using deep 33 learning: An improved faster rcnn approach,” Neurocomputing, vol. 299, pp. 42–50, 2018.
[169] J. Jin, K. Fu, and C. Zhang, “Traffic sign recognition with hinge loss trained convolutional neural networks,” IEEE Transactions on Intelligent Transportation Systems, vol. 15, no. 5, pp. 1991–2000, 2014.
[170] M. Zhou, M. Jing, D. Liu, Z. Xia, Z. Zou, and Z. Shi, “Multi-resolution networks for ship detection in infrared remote sensing images,” Infrared Physics & Technology, 2018.
[171] P. Dollar, Z. Tu, P. Perona, and S. Belongie, “Integral ´ channel features,” 2009.
[172] P. Dollar, R. Appel, S. Belongie, and P. Perona, “Fast ´ feature pyramids for object detection,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 36, no. 8, pp. 1532–1545, 2014.
[173] R. Benenson, M. Mathias, R. Timofte, and L. Van Gool, “Pedestrian detection at 100 frames per second,” in Computer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on. IEEE, 2012, pp. 2903–2910.
[174] S. Maji, A. C. Berg, and J. Malik, “Classification using intersection kernel support vector machines is efficient,” in Computer Vision and Pattern Recognition, 2008. CVPR 2008. IEEE Conference on. IEEE, 2008, pp. 1–8.
[175] A. Vedaldi and A. Zisserman, “Sparse kernel approximations for efficient classification and detection,” in Computer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on. IEEE, 2012, pp. 2320–2327.
[176] F. Fleuret and D. Geman, “Coarse-to-fine face detection,” International Journal of computer vision, vol. 41, no. 1-2, pp. 85–107, 2001.
[177] Q. Zhu, M.-C. Yeh, K.-T. Cheng, and S. Avidan, “Fast human detection using a cascade of histograms of oriented gradients,” in Computer Vision and Pattern Recognition, 2006 IEEE Computer Society Conference on, vol. 2. IEEE, 2006, pp. 1491–1498.
[178] A. Vedaldi, V. Gulshan, M. Varma, and A. Zisserman, “Multiple kernels for object detection,” in Computer Vision, 2009 IEEE 12th International Conference on. IEEE, 2009, pp. 606–613.
[179] H. Li, Z. Lin, X. Shen, J. Brandt, and G. Hua, “A convolutional neural network cascade for face detection,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 5325–5334.
[180] K. Zhang, Z. Zhang, Z. Li, and Y. Qiao, “Joint face detection and alignment using multitask cascaded convolutional networks,” IEEE Signal Processing Letters, vol. 23, no. 10, pp. 1499–1503, 2016.
[181] Z. Cai, M. Saberian, and N. Vasconcelos, “Learning complexity-aware cascades for deep pedestrian detection,” in Proceedings of the IEEE International Conference on Computer Vision, 2015, pp. 3361–3369.
[182] B. Yang, J. Yan, Z. Lei, and S. Z. Li, “Craft objects from images,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 6043–6051.
[183] F. Yang, W. Choi, and Y. Lin, “Exploit all the layers: Fast and accurate cnn object detector with scale dependent pooling and cascaded rejection classifiers,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 2129–2137.
[184] M. Gao, R. Yu, A. Li, V. I. Morariu, and L. S. Davis, “Dynamic zoom-in network for fast object detection in large images,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
[185] W. Ouyang, K. Wang, X. Zhu, and X. Wang, “Chained cascade network for object detection,” in Computer Vision (ICCV), 2017 IEEE International Conference on. IEEE, 2017, pp. 1956–1964.
[186] Y. LeCun, J. S. Denker, and S. A. Solla, “Optimal brain damage,” in Advances in neural information processing systems, 1990, pp. 598–605.
[187] S. Han, H. Mao, and W. J. Dally, “Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding,” arXiv preprint arXiv:1510.00149, 2015.
[188] H. Li, A. Kadav, I. Durdanovic, H. Samet, and H. P. Graf, “Pruning filters for efficient convnets,” arXiv preprint arXiv:1608.08710, 2016.
[189] G. Huang, S. Liu, L. van der Maaten, and K. Q. Weinberger, “Condensenet: An efficient densenet using learned group convolutions,” group, vol. 3, no. 12, p. 11, 2017.
[190] M. Rastegari, V. Ordonez, J. Redmon, and A. Farhadi, “Xnor-net: Imagenet classification using binary convolutional neural networks,” in European Conference on Computer Vision. Springer, 2016, pp. 525–542.
[191] X. Lin, C. Zhao, and W. Pan, “Towards accurate binary convolutional neural network,” in Advances in Neural Information Processing Systems, 2017, pp. 345–353.
[192] I. Hubara, M. Courbariaux, D. Soudry, R. El-Yaniv, and Y. Bengio, “Binarized neural networks,” in Advances in neural information processing systems, 2016, pp. 4107–4115.
[193] G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,” arXiv preprint arXiv:1503.02531, 2015.
[194] A. Romero, N. Ballas, S. E. Kahou, A. Chassang, C. Gatta, and Y. Bengio, “Fitnets: Hints for thin deep nets,” arXiv preprint arXiv:1412.6550, 2014.
[195] G. Chen, W. Choi, X. Yu, T. Han, and M. Chandraker, “Learning efficient object detection models with knowledge distillation,” in Advances in Neural Information Processing Systems, 2017, pp. 742–751.
[196] Q. Li, S. Jin, and J. Yan, “Mimicking very efficient network for object detection,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2017, pp. 7341–7349.
[197] K. He and J. Sun, “Convolutional neural networks at constrained time cost,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 5353– 5360.
[198] C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna, “Rethinking the inception architecture for computer vision,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 2818–2826.
[199] C. Peng, X. Zhang, G. Yu, G. Luo, and J. Sun, “Large kernel mattersimprove semantic segmentation by global convolutional network,” in Computer Vision and Pattern Recognition (CVPR), 2017 IEEE Conference on. IEEE, 2017, pp. 1743–1751.
[200] K.-H. Kim, S. Hong, B. Roh, Y. Cheon, and M. Park, “Pvanet: deep but lightweight neural networks for realtime object detection,” arXiv preprint arXiv:1608.08021, 2016.
[201] X. Zhang, J. Zou, X. Ming, K. He, and J. Sun, “Efficient and accurate approximations of nonlinear convolutional networks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 1984–1992.
[202] X. Zhang, J. Zou, K. He, and J. Sun, “Accelerating very deep convolutional networks for classification and detection,” IEEE transactions on pattern analysis and machine intelligence, vol. 38, no. 10, pp. 1943–1955, 2016.
[203] X. Zhang, X. Zhou, M. Lin, and J. Sun, “Shufflenet: An extremely efficient convolutional neural network for mobile devices,” 2017.
[204] F. Chollet, “Xception: Deep learning with depthwise separable convolutions,” arXiv preprint, pp. 1610–02 357, 2017.
[205] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “Mobilenets: Efficient convolutional neural networks for mo- 34 bile vision applications,” arXiv preprint arXiv:1704.04861, 2017.
[206] M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen, “Mobilenetv2: Inverted residuals and linear bottlenecks,” in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE, 2018, pp. 4510–4520.
[207] Y. Li, J. Li, W. Lin, and J. Li, “Tiny-dsod: Lightweight object detection for resource-restricted usages,” arXiv preprint arXiv:1807.11013, 2018.
[208] G. E. Hinton and R. R. Salakhutdinov, “Reducing the dimensionality of data with neural networks,” science, vol. 313, no. 5786, pp. 504–507, 2006.
[209] R. J. Wang, X. Li, S. Ao, and C. X. Ling, “Pelee: A real-time object detection system on mobile devices,” arXiv preprint arXiv:1804.06882, 2018.
[210] F. N. Iandola, S. Han, M. W. Moskewicz, K. Ashraf, W. J. Dally, and K. Keutzer, “Squeezenet: Alexnet-level accuracy with 50x fewer parameters and¡ 0.5 mb model size,” arXiv preprint arXiv:1602.07360, 2016.
[211] B. Wu, F. N. Iandola, P. H. Jin, and K. Keutzer, “Squeezedet: Unified, small, low power fully convolutional neural networks for real-time object detection for autonomous driving.” in CVPR Workshops, 2017, pp. 446– 454.
[212] T. Kong, A. Yao, Y. Chen, and F. Sun, “Hypernet: Towards accurate region proposal generation and joint object detection,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 845–853.
[213] B. Zoph, V. Vasudevan, J. Shlens, and Q. V. Le, “Learning transferable architectures for scalable image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 8697–8710.
[214] B. Zoph and Q. V. Le, “Neural architecture search with reinforcement learning,” arXiv preprint arXiv:1611.01578, 2016.
[215] Y. Chen, T. Yang, X. Zhang, G. Meng, C. Pan, and J. Sun, “Detnas: Neural architecture search on object detection,” arXiv preprint arXiv:1903.10979, 2019.
[216] C. Liu, L.-C. Chen, F. Schroff, H. Adam, W. Hua, A. Yuille, and L. Fei-Fei, “Auto-deeplab: Hierarchical neural architecture search for semantic image segmentation,” arXiv preprint arXiv:1901.02985, 2019.
[217] X. Chu, B. Zhang, R. Xu, and H. Ma, “Multi-objective reinforced evolution in mobile neural architecture search,” arXiv preprint arXiv:1901.01074, 2019.
[218] C.-H. Hsu, S.-H. Chang, D.-C. Juan, J.-Y. Pan, Y.-T. Chen, W. Wei, and S.-C. Chang, “Monas: Multi-objective neural architecture search using reinforcement learning,” arXiv preprint arXiv:1806.10332, 2018.
[219] P. Simard, L. Bottou, P. Haffner, and Y. LeCun, “Boxlets: a fast convolution algorithm for signal processing and neural networks,” in Advances in Neural Information Processing Systems, 1999, pp. 571–577.
[220] X. Wang, T. X. Han, and S. Yan, “An hog-lbp human detector with partial occlusion handling,” in Computer Vision, 2009 IEEE 12th International Conference on. IEEE, 2009, pp. 32–39.
[221] F. Porikli, “Integral histogram: A fast way to extract histograms in cartesian spaces,” in Computer Vision and Pattern Recognition, 2005. CVPR 2005. IEEE Computer Society Conference on, vol. 1. IEEE, 2005, pp. 829–836.
[222] M. Mathieu, M. Henaff, and Y. LeCun, “Fast training of convolutional networks through ffts,” arXiv preprint arXiv:1312.5851, 2013.
[223] H. Pratt, B. Williams, F. Coenen, and Y. Zheng, “Fcnn: Fourier convolutional neural networks,” in Joint European Conference on Machine Learning and Knowledge Discovery in Databases. Springer, 2017, pp. 786–798.
[224] N. Vasilache, J. Johnson, M. Mathieu, S. Chintala, S. Piantino, and Y. LeCun, “Fast convolutional nets with fbfft: A gpu performance evaluation,” arXiv preprint arXiv:1412.7580, 2014.
[225] O. Rippel, J. Snoek, and R. P. Adams, “Spectral representations for convolutional neural networks,” in Advances in neural information processing systems, 2015, pp. 2449–2457.
[226] C. Dubout and F. Fleuret, “Exact acceleration of linear object detectors,” in European Conference on Computer Vision. Springer, 2012, pp. 301–311.
[227] M. A. Sadeghi and D. Forsyth, “Fast template evaluation with vector quantization,” in Advances in neural information processing systems, 2013, pp. 2949–2957.
[228] I. Kokkinos, “Bounding part scores for rapid detection with deformable part models,” in European Conference on Computer Vision. Springer, 2012, pp. 41–50.
[229] J. Gu, Z. Wang, J. Kuen, L. Ma, A. Shahroudy, B. Shuai, T. Liu, X. Wang, L. Wang, G. Wang et al., “Recent advances in convolutional neural networks,” arXiv preprint arXiv:1512.07108, 2015.
[230] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014.
[231] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich, “Going deeper with convolutions,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 1–9.
[232] S. Ioffe and C. Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” arXiv preprint arXiv:1502.03167, 2015.
[233] C. Szegedy, S. Ioffe, V. Vanhoucke, and A. A. Alemi, “Inception-v4, inception-resnet and the impact of residual connections on learning.” in AAAI, vol. 4, 2017, p. 12.
[234] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
[235] G. Huang, Z. Liu, L. Van Der Maaten, and 35 ject detection,” arXiv preprint arXiv:1612.06851, 2016.
[236] J. Hu, L. Shen, and G. Sun, “Squeeze-and-excitation networks,” arXiv preprint arXiv:1709.01507, vol. 7, 2017.
[237] P. Zhou, B. Ni, C. Geng, J. Hu, and Y. Xu, “Scaletransferrable object detection,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 528–537.
[238] Z. Shen, Z. Liu, J. Li, Y.-G. Jiang, Y. Chen, and X. Xue, “Dsod: Learning deeply supervised object detectors from scratch,” in The IEEE International Conference on Computer Vision (ICCV), vol. 3, no. 6, 2017, p. 7.
[239] S. Xie, R. Girshick, P. Dollar, Z. Tu, and K. He, ´ “Aggregated residual transformations for deep neural networks,” in Computer Vision and Pattern Recognition (CVPR), 2017 IEEE Conference on. IEEE, 2017, pp. 5987– 5995.
[240] J. Jeong, H. Park, and N. Kwak, “Enhancement of ssd by concatenating feature maps for object detection,” arXiv preprint arXiv:1705.09587, 2017.
[241] K. Lee, J. Choi, J. Jeong, and N. Kwak, “Residual features and unified prediction network for single stage detection,” arXiv preprint arXiv:1707.05031, 2017.
[242] G. Cao, X. Xie, W. Yang, Q. Liao, G. Shi, and J. Wu, “Feature-fused ssd: fast detection for small objects,” in Ninth International Conference on Graphic and Image Processing (ICGIP 2017), vol. 10615. International Society for Optics and Photonics, 2018, p. 106151E.
[243] L. Zheng, C. Fu, and Y. Zhao, “Extend the shallow part of single shot multibox detector via convolutional neural network,” arXiv preprint arXiv:1801.05918, 2018.
[244] A. Shrivastava, R. Sukthankar, J. Malik, and A. Gupta, “Beyond skip connections: Top-down modulation for ob- 35 ject detection,” arXiv preprint arXiv:1612.06851, 2016.
[245] T. Kong, F. Sun, A. Yao, H. Liu, M. Lu, and Y. Chen, “Ron: Reverse connection with objectness prior networks for object detection,” in IEEE Conference on Computer Vision and Pattern Recognition, vol. 1, 2017, p. 2.
[246] S. Woo, S. Hwang, and I. S. Kweon, “Stairnet: Top-down semantic aggregation for accurate one shot detection,” in 2018 IEEE Winter Conference on Applications of Computer Vision (WACV). IEEE, 2018, pp. 1093–1102.
[247] Y. Chen, J. Li, B. Zhou, J. Feng, and S. Yan, “Weaving multi-scale context for single shot detector,” arXiv preprint arXiv:1712.03149, 2017.
[248] M. D. Zeiler, G. W. Taylor, and R. Fergus, “Adaptive deconvolutional networks for mid and high level feature learning,” in Computer Vision (ICCV), 2011 IEEE International Conference on. IEEE, 2011, pp. 2018–2025.
[249] C.-Y. Fu, W. Liu, A. Ranga, A. Tyagi, and A. C. Berg, “Dssd: Deconvolutional single shot detector,” arXiv preprint arXiv:1701.06659, 2017.
[250] J. Wang, Y. Yuan, and G. Yu, “Face attention network: An effective face detector for the occluded faces,” arXiv preprint arXiv:1711.07246, 2017.
[251] P. He, W. Huang, T. He, Q. Zhu, Y. Qiao, and X. Li, “Single shot text detector with regional attention,” in The IEEE International Conference on Computer Vision (ICCV), vol. 6, no. 7, 2017.
[252] F. Yu and V. Koltun, “Multi-scale context aggregation by dilated convolutions,” arXiv preprint arXiv:1511.07122, 2015.
[253] F. Yu, V. Koltun, and T. A. Funkhouser, “Dilated residual networks.” in CVPR, vol. 2, 2017, p. 3.
[254] Z. Li, C. Peng, G. Yu, X. Zhang, Y. Deng, and J. Sun, “Detnet: A backbone network for object detection,” arXiv preprint arXiv:1804.06215, 2018.
[255] S. Liu, D. Huang, and Y. Wang, “Receptive field block net for accurate and fast object detection,” arXiv preprint arXiv:1711.07767, 2017.
[256] M. Najibi, M. Rastegari, and L. S. Davis, “G-cnn: an iterative grid based object detector,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 2369–2377.
[257] D. Yoo, S. Park, J.-Y. Lee, A. S. Paek, and I. So Kweon, “Attentionnet: Aggregating weak directions for accurate object detection,” in Proceedings of the IEEE International Conference on Computer Vision, 2015, pp. 2659–2667.
[258] Y. Lu, T. Javidi, and S. Lazebnik, “Adaptive object detection using adjacency and zoom prediction,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 2351–2359.
[259] R. Ranjan, V. M. Patel, and R. Chellappa, “Hyperface: A deep multi-task learning framework for face detection, landmark localization, pose estimation, and gender recognition,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 41, no. 1, pp. 121–135, 2019.
[260] Z. Cao, T. Simon, S.-E. Wei, and Y. Sheikh, “Realtime multi-person 2d pose estimation using part affinity fields,” arXiv preprint arXiv:1611.08050, 2016.
[261] H. Law and J. Deng, “Cornernet: Detecting objects as paired keypoints,” in Proceedings of the European Conference on Computer Vision (ECCV), vol. 6, 2018.
[262] Z. Cai and N. Vasconcelos, “Cascade r-cnn: Delving into high quality object detection,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), vol. 1, no. 2, 2018, p. 10.
[263] R. N. Rajaram, E. Ohn-Bar, and M. M. Trivedi, “Refinenet: Iterative refinement for accurate object localization,” in Intelligent Transportation Systems (ITSC), 2016 IEEE 19th International Conference on. IEEE, 2016, pp. 1528–1533.
[264] M.-C. Roh and J.-y. Lee, “Refining faster-rcnn for accurate object detection,” in Machine Vision Applications (MVA), 2017 Fifteenth IAPR International Conference on. IEEE, 2017, pp. 514–517.
[265] J. Yu, Y. Jiang, Z. Wang, Z. Cao, and T. Huang, “Unitbox: An advanced object detection network,” in Proceedings of the 2016 ACM on Multimedia Conference. ACM, 2016, pp. 516–520.
[266] S. Gidaris and N. Komodakis, “Locnet: Improving localization accuracy for object detection,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 789–798.
[267] B. A. Olshausen and D. J. Field, “Emergence of simplecell receptive field properties by learning a sparse code for natural images,” Nature, vol. 381, no. 6583, p. 607, 1996.
[268] A. J. Bell and T. J. Sejnowski, “The independent components of natural scenes are edge filters,” Vision research, vol. 37, no. 23, pp. 3327–3338, 1997.
[269] S. Brahmbhatt, H. I. Christensen, and J. Hays, “Stuffnet: Using stuffto improve object detection,” in Applications of Computer Vision (WACV), 2017 IEEE Winter Conference on. IEEE, 2017, pp. 934–943.
[270] A. Shrivastava and A. Gupta, “Contextual priming and feedback for faster r-cnn,” in European Conference on Computer Vision. Springer, 2016, pp. 330–348.
[271] Z. Zhang, S. Qiao, C. Xie, W. Shen, B. Wang, and A. L. Yuille, “Single-shot object detection with enriched semantics,” Center for Brains, Minds and Machines (CBMM), Tech. Rep., 2018.
[272] B. Cai, Z. Jiang, H. Zhang, Y. Yao, and S. Nie, “Online exemplar-based fully convolutional network for aircraft detection in remote sensing images,” IEEE Geoscience and Remote Sensing Letters, no. 99, pp. 1–5, 2018.
[273] G. Cheng, J. Han, P. Zhou, and L. Guo, “Multi-class geospatial object detection and geographic image classification based on collection of part detectors,” ISPRS Journal of Photogrammetry and Remote Sensing, vol. 98, pp. 119–132, 2014.
[274] P. Y. Simard, Y. A. LeCun, J. S. Denker, and B. Victorri, “Transformation invariance in pattern recognitiontangent distance and tangent propagation,” in Neural networks: tricks of the trade. Springer, 1998, pp. 239–274.
[275] G. Cheng, P. Zhou, and J. Han, “Rifd-cnn: Rotationinvariant and fisher discriminative convolutional neural networks for object detection,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 2884–2893.
[276] “Learning rotation-invariant convolutional neural networks for object detection in vhr optical remote sensing images,” IEEE Transactions on Geoscience and Remote Sensing, vol. 54, no. 12, pp. 7405–7415, 2016.
[277] X. Shi, S. Shan, M. Kan, S. Wu, and X. Chen, “Real-time rotation-invariant face detection with progressive calibration networks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 2295– 2303.
[278] M. Jaderberg, K. Simonyan, A. Zisserman et al., “Spatial transformer networks,” in Advances in neural information processing systems, 2015, pp. 2017–2025.
[279] D. Chen, G. Hua, F. Wen, and J. Sun, “Supervised transformer network for efficient face detection,” in European Conference on Computer Vision. Springer, 2016, pp. 122– 138.
[280] B. Singh and L. S. Davis, “An analysis of scale invariance in object detection–snip,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 3578–3587.
[281] B. Singh, M. Najibi, and L. S. Davis, “Sniper: Efficient multi-scale training,” arXiv preprint arXiv:1805.09300, 2018.
[282] S. Qiao, W. Shen, W. Qiu, C. Liu, and A. L. Yuille, 36 “Scalenet: Guiding object proposal generation in supermarkets and beyond.” in ICCV, 2017, pp. 1809–1818.
[283] Z. Hao, Y. Liu, H. Qin, J. Yan, X. Li, and X. Hu, “Scaleaware face detection,” in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), vol. 3, 2017.
[284] R. Zhu, S. Zhang, X. Wang, L. Wen, H. Shi, L. Bo, and T. Mei, “Scratchdet: Exploring to train single-shot object detectors from scratch,” arXiv preprint arXiv:1810.08425, 2018.
[285] K. He, R. Girshick, and P. Dollar, “Rethinking imagenet ´ pre-training,” arXiv preprint arXiv:1811.08883, 2018.
[286] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” in Advances in neural information processing systems, 2014, pp. 2672–2680.
[287] A. Radford, L. Metz, and S. Chintala, “Unsupervised representation learning with deep convolutional generative adversarial networks,” arXiv preprint arXiv:1511.06434, 2015.
[288] J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros, “Unpaired image-to-image translation using cycle-consistent adversarial networks,” arXiv preprint, 2017.
[289] C. Ledig, L. Theis, F. Huszar, J. Caballero, A. Cunning- ´ ham, A. Acosta, A. P. Aitken, A. Tejani, J. Totz, Z. Wang et al., “Photo-realistic single image super-resolution using a generative adversarial network.” in CVPR, vol. 2, no. 3, 2017, p. 4.
[290] J. Li, X. Liang, Y. Wei, T. Xu, J. Feng, and S. Yan, “Perceptual generative adversarial networks for small object detection,” in IEEE CVPR, 2017.
[291] Y. Bai, Y. Zhang, M. Ding, and B. Ghanem, “Sod-mtgan: Small object detection via multi-task generative adversarial network,” Computer Vision-ECCV, pp. 8–14, 2018.
[292] X. Wang, A. Shrivastava, and A. Gupta, “A-fast-rcnn: Hard positive generation via adversary for object detection,” in IEEE Conference on Computer Vision and Pattern Recognition, 2017.
[293] S.-T. Chen, C. Cornelius, J. Martin, and D. H. Chau, “Robust physical adversarial attack on faster r-cnn object detector,” arXiv preprint arXiv:1804.05810, 2018.
[294] R. G. Cinbis, J. Verbeek, and C. Schmid, “Weakly supervised object localization with multi-fold multiple instance learning,” IEEE transactions on pattern analysis and machine intelligence, vol. 39, no. 1, pp. 189–203, 2017.
[295] D. P. Papadopoulos, J. R. Uijlings, F. Keller, and V. Ferrari, “We don’t need no bounding-boxes: Training object class detectors using only human verification,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 854–863.
[296] T. G. Dietterich, R. H. Lathrop, and T. Lozano-Perez, ´ “Solving the multiple instance problem with axis-parallel rectangles,” Artificial intelligence, vol. 89, no. 1-2, pp. 31– 71, 1997.
[297] Y. Zhu, Y. Zhou, Q. Ye, Q. Qiu, and J. Jiao, “Soft proposal networks for weakly supervised object localization,” in Proc. IEEE Int. Conf. Comput. Vis.(ICCV), 2017, pp. 1841– 1850.
[298] A. Diba, V. Sharma, A. M. Pazandeh, H. Pirsiavash, and L. Van Gool, “Weakly supervised cascaded convolutional networks.” in CVPR, vol. 1, no. 2, 2017, p. 8.
[299] B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba, “Learning deep features for discriminative localization,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 2921–2929.
[300] H. Bilen and A. Vedaldi, “Weakly supervised deep detection networks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 2846– 2854.
[301] L. Bazzani, A. Bergamo, D. Anguelov, and L. Torresani, “Self-taught object localization with deep networks,” in Applications of Computer Vision (WACV), 2016 IEEE Winter Conference on. IEEE, 2016, pp. 1–9.
[302] Y. Shen, R. Ji, S. Zhang, W. Zuo, and Y. Wang, “Generative adversarial learning towards fast weakly supervised detection,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 5764–5773.
[303] M. Enzweiler and D. M. Gavrila, “Monocular pedestrian detection: Survey and experiments,” IEEE Transactions on Pattern Analysis & Machine Intelligence, no. 12, pp. 2179– 2195, 2008.
[304] D. Geronimo, A. M. Lopez, A. D. Sappa, and T. Graf, “Survey of pedestrian detection for advanced driver assistance systems,” IEEE transactions on pattern analysis and machine intelligence, vol. 32, no. 7, pp. 1239–1258, 2010.
[305] R. Benenson, M. Omran, J. Hosang, and B. Schiele, “Ten years of pedestrian detection, what have we learned?” in European Conference on Computer Vision. Springer, 2014, pp. 613–627.
[306] S. Zhang, R. Benenson, M. Omran, J. Hosang, and B. Schiele, “How far are we from solving pedestrian detection?” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 1259–1267.
[307] “Towards reaching human performance in pedestrian detection,” IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 4, pp. 973–986, 2018.
[308] P. Viola, M. J. Jones, and D. Snow, “Detecting pedestrians using patterns of motion and appearance,” International Journal of Computer Vision, vol. 63, no. 2, pp. 153–161, 2005.
[309] P. Sabzmeydani and G. Mori, “Detecting pedestrians by learning shapelet features,” in Computer Vision and Pattern Recognition, 2007. CVPR’07. IEEE Conference on. IEEE, 2007, pp. 1–8.
[310] J. Cao, Y. Pang, and X. Li, “Pedestrian detection inspired by appearance constancy and shape symmetry,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 1316–1324.
[311] R. Benenson, R. Timofte, and L. Van Gool, “Stixels estimation without depth map computation,” in Computer Vision Workshops (ICCV Workshops), 2011 IEEE International Conference on. IEEE, 2011, pp. 2010–2017.
[312] J. Hosang, M. Omran, R. Benenson, and B. Schiele, “Taking a deeper look at pedestrians,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 4073–4082.
[313] J. Cao, Y. Pang, and X. Li, “Learning multilayer channel features for pedestrian detection,” IEEE transactions on image processing, vol. 26, no. 7, pp. 3210–3220, 2017.
[314] J. Mao, T. Xiao, Y. Jiang, and Z. Cao, “What can help pedestrian detection?” in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2017, pp. 6034–6043.
[315] Q. Hu, P. Wang, C. Shen, A. van den Hengel, and F. Porikli, “Pushing the limits of deep cnns for pedestrian detection,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 28, no. 6, pp. 1358–1368, 2018.
[316] Y. Tian, P. Luo, X. Wang, and X. Tang, “Pedestrian detection aided by deep learning semantic tasks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 5079–5087.
[317] D. Xu, W. Ouyang, E. Ricci, X. Wang, and N. Sebe, “Learning cross-modal deep representations for robust pedestrian detection,” in Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2017.
[318] X. Wang, T. Xiao, Y. Jiang, S. Shao, J. Sun, and C. Shen, “Repulsion loss: Detecting pedestrians in a crowd,” arXiv preprint arXiv:1711.07752, 2017.
[319] Y. Tian, P. Luo, X. Wang, and X. Tang, “Deep learning strong parts for pedestrian detection,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 1904–1912. 37
[320] W. Ouyang, H. Zhou, H. Li, Q. Li, J. Yan, and X. Wang, “Jointly learning deep features, deformable parts, occlusion and classification for pedestrian detection,” IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 8, pp. 1874–1887, 2018.
[321] S. Zhang, J. Yang, and B. Schiele, “Occluded pedestrian detection through guided attention in cnns,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 6995–7003.
[322] P. Hu and D. Ramanan, “Finding tiny faces,” in Computer Vision and Pattern Recognition (CVPR), 2017 IEEE Conference on. IEEE, 2017, pp. 1522–1530.
[323] M.-H. Yang, D. J. Kriegman, and N. Ahuja, “Detecting faces in images: A survey,” IEEE Transactions on pattern analysis and machine intelligence, vol. 24, no. 1, pp. 34–58, 2002.
[324] S. Zafeiriou, C. Zhang, and Z. Zhang, “A survey on face detection in the wild: past, present and future,” Computer Vision and Image Understanding, vol. 138, pp. 1–24, 2015.
[325] H. A. Rowley, S. Baluja, and T. Kanade, “Neural networkbased face detection,” IEEE Transactions on pattern analysis and machine intelligence, vol. 20, no. 1, pp. 23–38, 1998.
[326] E. Osuna, R. Freund, and F. Girosit, “Training support vector machines: an application to face detection,” in Computer vision and pattern recognition, 1997. Proceedings., 1997 IEEE computer society conference on. IEEE, 1997, pp. 130–136.
[327] M. Osadchy, Y. L. Cun, and M. L. Miller, “Synergistic face detection and pose estimation with energy-based models,” Journal of Machine Learning Research, vol. 8, no. May, pp. 1197–1215, 2007.
[328] S. Yang, P. Luo, C. C. Loy, and X. Tang, “Faceness-net: Face detection through deep facial part responses,” IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 8, pp. 1845–1859, 2018.
[329] S. Yang, Y. Xiong, C. C. Loy, and X. Tang, “Face detection through scale-friendly deep convolutional networks,” arXiv preprint arXiv:1706.02863, 2017.
[330] M. Najibi, P. Samangouei, R. Chellappa, and L. S. Davis, “Ssh: Single stage headless face detector.” in ICCV, 2017, pp. 4885–4894.
[331] S. Zhang, X. Zhu, Z. Lei, H. Shi, X. Wang, and S. Z. Li, “Sˆ 3fd: Single shot scale-invariant face detector,” in Computer Vision (ICCV), 2017 IEEE International Conference on. IEEE, 2017, pp. 192–201.
[332] X. Liu, “A camera phone based currency reader for the visually impaired,” in Proceedings of the 10th international ACM SIGACCESS conference on Computers and accessibility. ACM, 2008, pp. 305–306.
[333] N. Ezaki, K. Kiyota, B. T. Minh, M. Bulacu, and L. Schomaker, “Improved text-detection methods for a camera-based text reading system for blind persons,” in Document Analysis and Recognition, 2005. Proceedings. Eighth International Conference on. IEEE, 2005, pp. 257– 261.
[334] P. Sermanet, S. Chintala, and Y. LeCun, “Convolutional neural networks applied to house numbers digit classification,” in Pattern Recognition (ICPR), 2012 21st International Conference on. IEEE, 2012, pp. 3288–3291.
[335] Z. Wojna, A. Gorban, D.-S. Lee, K. Murphy, Q. Yu, Y. Li, and J. Ibarz, “Attention-based extraction of structured information from street view imagery,” arXiv preprint arXiv:1704.03549, 2017.
[336] Y. Liu and L. Jin, “Deep matching prior network: Toward tighter multi-oriented text detection,” in Proc. CVPR, 2017, pp. 3454–3461.
[337] Y. Wu and P. Natarajan, “Self-organized text detection with minimal post-processing via border learning,” in Proc. ICCV, 2017.
[338] Y. Zhu, C. Yao, and X. Bai, “Scene text detection and recognition: Recent advances and future trends,” Frontiers of Computer Science, vol. 10, no. 1, pp. 19–36, 2016.
[339] Q. Ye and D. Doermann, “Text detection and recognition in imagery: A survey,” IEEE transactions on pattern analysis and machine intelligence, vol. 37, no. 7, pp. 1480–1500, 2015.
[340] L. Neumann and J. Matas, “Scene text localization and recognition with oriented stroke detection,” in Proceedings of the IEEE International Conference on Computer Vision, 2013, pp. 97–104.
[341] X.-C. Yin, X. Yin, K. Huang, and H.-W. Hao, “Robust text detection in natural scene images,” IEEE transactions on pattern analysis and machine intelligence, vol. 36, no. 5, pp. 970–983, 2014.
[342] K. Wang, B. Babenko, and S. Belongie, “End-to-end scene text recognition,” in Computer Vision (ICCV), 2011 IEEE International Conference on. IEEE, 2011, pp. 1457–1464.
[343] T. Wang, D. J. Wu, A. Coates, and A. Y. Ng, “End-to-end text recognition with convolutional neural networks,” in Pattern Recognition (ICPR), 2012 21st International Conference on. IEEE, 2012, pp. 3304–3308.
[344] S. Tian, Y. Pan, C. Huang, S. Lu, K. Yu, and C. Lim Tan, “Text flow: A unified text detection system in natural scene images,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 4651–4659.
[345] M. Jaderberg, A. Vedaldi, and A. Zisserman, “Deep features for text spotting,” in European conference on computer vision. Springer, 2014, pp. 512–528.
[346] X.-C. Yin, W.-Y. Pei, J. Zhang, and H.-W. Hao, “Multiorientation scene text detection with adaptive clustering,” IEEE Transactions on Pattern Analysis & Machine Intelligence, no. 9, pp. 1930–1937, 2015.
[347] Z. Zhang, W. Shen, C. Yao, and X. Bai, “Symmetry-based text line detection in natural scenes,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 2558–2567.
[348] M. Jaderberg, K. Simonyan, A. Vedaldi, and A. Zisserman, “Reading text in the wild with convolutional neural networks,” International Journal of Computer Vision, vol. 116, no. 1, pp. 1–20, 2016.
[349] W. Huang, Y. Qiao, and X. Tang, “Robust scene text detection with convolution neural network induced mser trees,” in European Conference on Computer Vision. Springer, 2014, pp. 497–511.
[350] T. He, W. Huang, Y. Qiao, and J. Yao, “Text-attentional convolutional neural network for scene text detection,” IEEE transactions on image processing, vol. 25, no. 6, pp. 2529–2541, 2016.
[351] J. Ma, W. Shao, H. Ye, L. Wang, H. Wang, Y. Zheng, and X. Xue, “Arbitrary-oriented scene text detection via rotation proposals,” IEEE Transactions on Multimedia, 2018.
[352] “Arbitrary-oriented scene text detection via rotation proposals,” IEEE Transactions on Multimedia, 2018.
[353] Y. Jiang, X. Zhu, X. Wang, S. Yang, W. Li, H. Wang, P. Fu, and Z. Luo, “R2cnn: rotational region cnn for orientation robust scene text detection,” arXiv preprint arXiv:1706.09579, 2017.
[354] M. Liao, B. Shi, X. Bai, X. Wang, and W. Liu, “Textboxes: A fast text detector with a single deep neural network.” in AAAI, 2017, pp. 4161–4167.
[355] W. He, X.-Y. Zhang, F. Yin, and C.-L. Liu, “Deep direct regression for multi-oriented scene text detection,” arXiv preprint arXiv:1703.08289, 2017.
[356] Y. Liu and L. Jin, “Deep matching prior network: Toward tighter multi-oriented text detection,” in Proc. CVPR, 2017, pp. 3454–3461.
[357] X. Zhou, C. Yao, H. Wen, Y. Wang, S. Zhou, W. He, and J. Liang, “East: an efficient and accurate scene text detector,” in Proc. CVPR, 2017, pp. 2642–2651.
[358] C. Yao, X. Bai, N. Sang, X. Zhou, S. Zhou, and Z. Cao, “Scene text detection via holistic, multi-channel predic- 38 tion,” arXiv preprint arXiv:1606.09002, 2016.
[359] C. Xue, S. Lu, and F. Zhan, “Accurate scene text detection through border semantics awareness and bootstrapping,” in European Conference on Computer Vision. Springer, 2018, pp. 370–387.
[360] P. Lyu, C. Yao, W. Wu, S. Yan, and X. Bai, “Multi-oriented scene text detection via corner localization and region segmentation,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 7553– 7563.
[361] Z. Tian, W. Huang, T. He, P. He, and Y. Qiao, “Detecting text in natural image with connectionist text proposal network,” in European conference on computer vision. Springer, 2016, pp. 56–72.
[362] A. d. l. Escalera, L. Moreno, M. A. Salichs, and J. M. Armingol, “Road traffic sign detection and classification,” 1997.
[363] D. M. Gavrila, U. Franke, C. Wohler, and S. Gorzig, “Real time vision for intelligent vehicles,” IEEE Instrumentation & Measurement Magazine, vol. 4, no. 2, pp. 22–27, 2001.
[364] C. F. Paulo and P. L. Correia, “Automatic detection and classification of traffic signs,” in Image Analysis for Multimedia Interactive Services, 2007. WIAMIS’07. Eighth International Workshop on. IEEE, 2007, pp. 11–11.
[365] A. De la Escalera, J. M. Armingol, and M. Mata, “Traffic sign recognition and analysis for intelligent vehicles,” Image and vision computing, vol. 21, no. 3, pp. 247–258, 2003.
[366] W. Shadeed, D. I. Abu-Al-Nadi, and M. J. Mismar, “Road traffic sign detection in color images,” in Electronics, Circuits and Systems, 2003. ICECS 2003. Proceedings of the 2003 10th IEEE International Conference on, vol. 2. IEEE, 2003, pp. 890–893.
[367] S. Maldonado-Bascon, S. Lafuente-Arroyo, P. Gil- ´ Jimenez, H. Gomez-Moreno, and F. L ´ opez-Ferreras, ´ “Road-sign detection and recognition based on support vector machines,” IEEE transactions on intelligent transportation systems, vol. 8, no. 2, pp. 264–278, 2007.
[368] M. Omachi and S. Omachi, “Traffic light detection with color and edge information,” 2009.
[369] Y. Xie, L.-f. Liu, C.-h. Li, and Y.-y. Qu, “Unifying visual saliency with hog feature learning for traffic sign detection,” in Intelligent Vehicles Symposium, 2009 IEEE. IEEE, 2009, pp. 24–29.
[370] S. Houben, “A single target voting scheme for traffic sign detection,” in Intelligent Vehicles Symposium (IV), 2011 IEEE. IEEE, 2011, pp. 124–129.
[371] A. Soetedjo and K. Yamada, “Fast and robust traffic sign detection,” in Systems, Man and Cybernetics, 2005 IEEE International Conference on, vol. 2. IEEE, 2005, pp. 1341– 1346.
[372] N. Fairfield and C. Urmson, “Traffic light mapping and detection,” in Robotics and Automation (ICRA), 2011 IEEE International Conference on. IEEE, 2011, pp. 5421–5426.
[373] J. Levinson, J. Askeland, J. Dolson, and S. Thrun, “Traffic light mapping, localization, and state detection for autonomous vehicles,” in Robotics and Automation (ICRA), 2011 IEEE International Conference on. IEEE, 2011, pp. 5784–5791.
[374] C. Bahlmann, Y. Zhu, V. Ramesh, M. Pellkofer, and T. Koehler, “A system for traffic sign detection, tracking, and recognition using color, shape, and motion information,” in Intelligent Vehicles Symposium, 2005. Proceedings. IEEE. IEEE, 2005, pp. 255–260.
[375] I. M. Creusen, R. G. Wijnhoven, E. Herbschleb, and P. de With, “Color exploitation in hog-based traffic sign detection,” in 2010 IEEE International Conference on Image Processing. IEEE, 2010, pp. 2669–2672.
[376] G. Wang, G. Ren, Z. Wu, Y. Zhao, and L. Jiang, “A robust, coarse-to-fine traffic sign detection method,” in Neural Networks (IJCNN), The 2013 International Joint Conference on. IEEE, 2013, pp. 1–5.
[377] Z. Shi, Z. Zou, and C. Zhang, “Real-time traffic light detection with adaptive background suppression filter,” IEEE Transactions on Intelligent Transportation Systems, vol. 17, no. 3, pp. 690–700, 2016.
[378] Y. Lu, J. Lu, S. Zhang, and P. Hall, “Traffic signal detection and classification in street views using an attention model,” Computational Visual Media, vol. 4, no. 3, pp. 253– 266, 2018.
[379] M. Bach, D. Stumper, and K. Dietmayer, “Deep convolutional traffic light recognition for automated driving,” in 2018 21st International Conference on Intelligent Transportation Systems (ITSC). IEEE, 2018, pp. 851–858.
[380] S. Qiu, G. Wen, and Y. Fan, “Occluded object detection in high-resolution remote sensing images using partial configuration object model,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 10, no. 5, pp. 1909–1925, 2017.
[381] Z. Zou and Z. Shi, “Ship detection in spaceborne optical image with svd networks,” IEEE Transactions on Geoscience and Remote Sensing, vol. 54, no. 10, pp. 5832–5845, 2016.
[382] L. Zhang, L. Zhang, and B. Du, “Deep learning for remote sensing data: A technical tutorial on the state of the art,” IEEE Geoscience and Remote Sensing Magazine, vol. 4, no. 2, pp. 22–40, 2016.
[383] N. Proia and V. Page, “Characterization of a bayesian ´ ship detection method in optical satellite images,” IEEE Geoscience and Remote Sensing Letters, vol. 7, no. 2, pp. 226–230, 2010.
[384] C. Zhu, H. Zhou, R. Wang, and J. Guo, “A novel hierarchical method of ship detection from spaceborne optical image based on shape and texture features,” IEEE Transactions on geoscience and remote sensing, vol. 48, no. 9, pp. 3446–3456, 2010.
[385] S. Qi, J. Ma, J. Lin, Y. Li, and J. Tian, “Unsupervised ship detection based on saliency and s-hog descriptor from optical satellite images,” IEEE Geoscience and Remote Sensing Letters, vol. 12, no. 7, pp. 1451–1455, 2015.
[386] F. Bi, B. Zhu, L. Gao, and M. Bian, “A visual search inspired computational model for ship detection in optical satellite images,” IEEE Geoscience and Remote Sensing Letters, vol. 9, no. 4, pp. 749–753, 2012.
[387] J. Han, P. Zhou, D. Zhang, G. Cheng, L. Guo, Z. Liu, S. Bu, and J. Wu, “Efficient, simultaneous detection of multiclass geospatial targets based on visual saliency modeling and discriminative learning of sparse coding,” ISPRS Journal of Photogrammetry and Remote Sensing, vol. 89, pp. 37–48, 2014.
[388] J. Han, D. Zhang, G. Cheng, L. Guo, and J. Ren, “Object detection in optical remote sensing images based on weakly supervised learning and high-level feature learning,” IEEE Transactions on Geoscience and Remote Sensing, vol. 53, no. 6, pp. 3325–3337, 2015.
[389] J. Tang, C. Deng, G.-B. Huang, and B. Zhao, “Compressed-domain ship detection on spaceborne optical image using deep neural network and extreme learning machine,” IEEE Transactions on Geoscience and Remote Sensing, vol. 53, no. 3, pp. 1174–1185, 2015.
[390] Z. Shi, X. Yu, Z. Jiang, and B. Li, “Ship detection in highresolution optical imagery based on anomaly detector and local shape feature,” IEEE Transactions on Geoscience and Remote Sensing, vol. 52, no. 8, pp. 4511–4523, 2014.
[391] A. Kembhavi, D. Harwood, and L. S. Davis, “Vehicle detection using partial least squares,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 33, no. 6, pp. 1250–1265, 2011.
[392] L. Wan, L. Zheng, H. Huo, and T. Fang, “Affine invariant description and large-margin dimensionality reduction 39 for target detection in optical remote sensing images,” IEEE Geoscience and Remote Sensing Letters, vol. 14, no. 7, pp. 1116–1120, 2017.
[393] H. Zhou, L. Wei, C. P. Lim, D. Creighton, and S. Nahavandi, “Robust vehicle detection in aerial images using bag-of-words and orientation aware scanning,” IEEE Transactions on Geoscience and Remote Sensing, no. 99, pp. 1–12, 2018.
[394] M. ElMikaty and T. Stathaki, “Detection of cars in high-resolution aerial images of complex urban environments,” IEEE Transactions on Geoscience and Remote Sensing, vol. 55, no. 10, pp. 5913–5924, 2017.
[395] L. Zhang, Z. Shi, and J. Wu, “A hierarchical oil tank detector with deep surrounding features for high-resolution optical satellite imagery,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 8, no. 10, pp. 4895–4909, 2015.
[396] C. Zhu, B. Liu, Y. Zhou, Q. Yu, X. Liu, and W. Yu, “Framework design and implementation for oil tank detection in optical satellite imagery,” in Geoscience and Remote Sensing Symposium (IGARSS), 2012 IEEE International. IEEE, 2012, pp. 6016–6019.
[397] G. Liu, Y. Zhang, X. Zheng, X. Sun, K. Fu, and H. Wang, “A new method on inshore ship detection in highresolution satellite images using shape and context information,” IEEE Geoscience and Remote Sensing Letters, vol. 11, no. 3, pp. 617–621, 2014.
[398] J. Xu, X. Sun, D. Zhang, and K. Fu, “Automatic detection of inshore ships in high-resolution remote sensing images using robust invariant generalized hough transform,” IEEE Geoscience and Remote Sensing Letters, vol. 11, no. 12, pp. 2070–2074, 2014.
[399] J. Zhang, C. Tao, and Z. Zou, “An on-road vehicle detection method for high-resolution aerial images based on local and global structure learning,” IEEE Geoscience and Remote Sensing Letters, vol. 14, no. 8, pp. 1198–1202, 2017.
[400] W. Diao, X. Sun, X. Zheng, F. Dou, H. Wang, and K. Fu, “Efficient saliency-based object detection in remote sensing images using deep belief networks,” IEEE Geoscience and Remote Sensing Letters, vol. 13, no. 2, pp. 137–141, 2016.
[401] P. Zhang, X. Niu, Y. Dou, and F. Xia, “Airport detection on optical satellite images using deep convolutional neural networks,” IEEE Geoscience and Remote Sensing Letters, vol. 14, no. 8, pp. 1183–1187, 2017.
[402] Z. Shi and Z. Zou, “Can a machine generate humanlike language descriptions for a remote sensing image?” IEEE Transactions on Geoscience and Remote Sensing, vol. 55, no. 6, pp. 3623–3634, 2017.
[403] X. Han, Y. Zhong, and L. Zhang, “An efficient and robust integrated geospatial object detection framework for high spatial resolution remote sensing imagery,” Remote Sensing, vol. 9, no. 7, p. 666, 2017.
[404] Z. Xu, X. Xu, L. Wang, R. Yang, and F. Pu, “Deformable convnet with aspect ratio constrained nms for object detection in remote sensing imagery,” Remote Sensing, vol. 9, no. 12, p. 1312, 2017.
[405] W. Li, K. Fu, H. Sun, X. Sun, Z. Guo, M. Yan, and X. Zheng, “Integrated localization and recognition for inshore ships in large scene remote sensing images,” IEEE Geoscience and Remote Sensing Letters, vol. 14, no. 6, pp. 936–940, 2017.
[406] O. A. Penatti, K. Nogueira, and J. A. dos Santos, “Do deep features generalize from everyday objects to remote sensing and aerial scenes domains?” in Proceedings of the IEEE conference on computer vision and pattern recognition workshops, 2015, pp. 44–51.
[407] L. W. Sommer, T. Schuchert, and J. Beyerer, “Fast deep vehicle detection in aerial images,” in Applications of Computer Vision (WACV), 2017 IEEE Winter Conference on. IEEE, 2017, pp. 311–319.
[408] L. Sommer, T. Schuchert, and J. Beyerer, “Comprehensive analysis of deep learning based vehicle detection in aerial images,” IEEE Transactions on Circuits and Systems for Video Technology, 2018.
[409] Z. Liu, J. Hu, L. Weng, and Y. Yang, “Rotated region based cnn for ship detection,” in Image Processing (ICIP), 2017 IEEE International Conference on. IEEE, 2017, pp. 900–904.
[410] H. Lin, Z. Shi, and Z. Zou, “Fully convolutional network with task partitioning for inshore ship detection in optical remote sensing images,” IEEE Geoscience and Remote Sensing Letters, vol. 14, no. 10, pp. 1665–1669, 2017.
[411] ——, “Maritime semantic labeling of optical remote sensing images with multi-scale fully convolutional network,” Remote Sensing, vol. 9, no. 5, p. 480, 2017.
欢迎大家加我微信交流讨论(请备注csdn上添加)
