测开必备:使用MQ的优势、劣势及常见问题
一、简介
MQ全称为Message Queue-消息队列,是一种应用程序对应用程序的消息通信,一端只管往队列不断发布信息,另一端只管往队列中读取消息,发布者不需要关心读取消息的谁,读取消息者不需要关心发布消息的是谁,各干各的互不干扰。
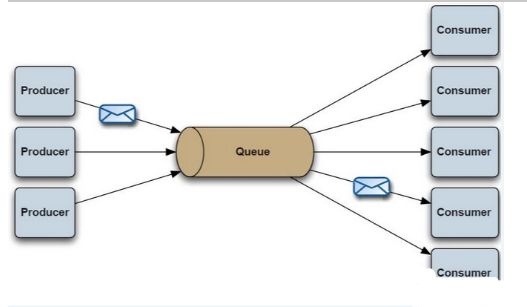
市场上现在常用的消息队列有:RabbitMQ、RocketMQ、Kafka,ActiveMQ。
先从开发语言来说,几款MQ对应的开发语言:
-
Kafka:Scala
-
RabbitMQ:Erlang
-
RocketMQ:java
-
ActiveMQ:java
详细对比如下(ActiveMQ->RabbitMQ->RocketMQ->Kafka):

一般的业务系统要引入MQ,最早大家都用ActiveMQ,但是现在用的并不多了,没经过大规模吞吐量场景的验证,社区也不是很活跃;
后来大家开始用RabbitMQ,但是确实erlang语言阻止了大量的java工程师去深入研究和掌控他,对公司而言,几乎处于不可控的状态,但是确实人是开源的,比较稳定的支持,活跃度也高;
不过现在确实越来越多的公司,会去用RocketMQ,确实很不错,对自己公司技术实力有绝对自信的,我推荐用RocketMQ。
所以中小型公司,技术实力较为一般,技术挑战不是特别高,用RabbitMQ是不错的选择;大型公司,基础架构研发实力较强,用RocketMQ是很好的选择。
如果是大数据领域的实时计算、日志采集等场景,用Kafka是业内标准的,绝对没问题,社区活跃度很高,目前几乎是全世界这个领域的事实性规范了。
二、MQ的优势
(1) 解耦
使用消息MQ后,只需要保证消息格式不变,不需要关心发布者及消费者之间的关系,这两者不需要彼此联系
(2) 异步
在一些不需要即时(同步)的返回结果操作,通过消息队列来实现异步。
(3) 削峰
在大量请求时(秒杀场景),使用消息队列做缓冲处理,削弱峰值流量,防止系统在短时间内被峰值流量冲垮。
场景:在大量流量涌入高峰,如数据库只能抗住2000的并发流量,可以使用MQ控制2000到数据库中
(4) 日志处理
日志存储在消息队列中,用来处理日志,比如kafka。
三、MQ的劣势
- 系统的可用性降低
在还未引进MQ之前,系统只需要关系生产端与消费端的接口一致性就可以了,现在引进后,系统需要关注生产端、MQ与消费端三者的稳定性,这增加系统的负担,系统运维成本增加。
- 系统的复杂性提高
引入了MQ,需要考虑的问题就增加了,如何保障消息的一致性,消费不被重复消费等问题,
- 一致性问题
A系统发送完消息直接返回成功,但是BCD系统之中若有系统写库失败,则会产生数据不一致的问题。
四、常见问题
(1) 怎么保证消息没有重复消费?使用消息队列如何保证幂等性
幂等性:就是用户对于同一操作发起的一次请求或者多次请求的结果是一致的,不会因为多次点击而产生了副作用
问题出现原因
我们先来了解一下产生消息重复消费的原因,对于MQ的使用,有三个角色:生产者、MQ、消费者,那么消息的重复这三者会出现:
- 生产者:生产者可能会推送重复的数据到MQ中,有可能controller接口重复提交了两次,也可能是重试机制导致的
- MQ:假设网络出现了波动,消费者消费完一条消息后,发送ack时,MQ还没来得及接受,突然挂了,导致MQ以为消费者还未消费该条消息,MQ回复后会再次推送了这条消息,导致出现重复消费。
- 消费者:消费者接收到消息后,正准备发送ack到MQ,突然消费者挂了,还没得及发送ack,这时MQ以为消费者还没消费该消息,消费者重启后,MQ再次推送该条消息。
解决方案
在正常情况下,生产者是客户,我们很难避免出现用户重复点击的情况,而MQ是允许存在多条一样的消息,但消费者是不允许出现消费两条一样的数据,所以幂等性一般是在消费端实现的:
- 状态判断:消费者把消费消息记录到redis中,再次消费时先到redis判断是否存在该数据,存在则表示消费过,直接丢弃
- 业务判断:消费完数据后,都是需要插入到数据库中,使用数据库的唯一约束防止重复消费。插入数据库前先查询是否存在该数据,存在则直接丢弃消息,这种方式是比较简单粗暴地解决问题
(2) 消息丢失的情况

(3) 消息的传输顺序性
解决思路
在生产端发布消息时,每次法发布消息都把上一条消息的ID记录到消息体中,消费者接收到消息时,做如下操作
-
先根据上一条Id去检查是否存在上一条消息还没被消费,如果不存在(消费后去掉id),则正常进行,如果正常操作
-
如果存在,则根据id到数据库检查是否被消费,如果被消费,则正常操作
-
如果还没被消费,则休眠一定时间(比如30ms),再重新检查,如被消费,则正常操作
-
如果还没被消费,则抛出异常
(4) 怎么解决百万消息积压问题
根据消息重要程度,可以分为两种情况处理
- 如果消息可以被丢弃,那么直接丢弃就好了
- 一般情况下,消息是不可以被丢弃的,那么这样需要考虑策略了,我们可以把原来的消费端重新当做生产端,重新部署一天MQ,再后面出现增加消费端,这样形成另一条生产-消息-消费的线路
如果这篇文章对你有所帮助,或者有所启发的话,帮忙点赞、转发、收藏,你的支持就是我坚持下去的最大动力!
绵薄之力
最后感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走
这些资料,对于想进阶【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!凡事要趁早,特别是技术行业,一定要提升技术功底。希望对大家有所帮助,需要的小伙伴点击下方插件进群免费领取: