深度学习(二)吴恩达给你的人工智能第一课: 02.改善深层神经网络:超参数调试、正则化以及优化
目录
第一周 深度学习的实用层面
1.1 训练 / 开发 / 测试集
1.1.1、 训练集、验证集、测试集
1.2 偏差 / 方差
1.3 机器学习基础
1.3.1、降低偏差/降低方差,往往存在一种折中关系(trade off)。
1.3.2、偏差
1.3.4、方差
1.4 正则化
1.5 为什么正则化可以减少过拟合?
1.6 Dropout 正则化
1.7 理解 Dropout
1.8 其他正则化方法
1.8.1、 数据扩展
1.8.2、early stopping
1.9、正则化输入
1.10 梯度消失(Vanishing gradients)与梯度爆炸(exploding gradients)
1.10.1、什么是梯度消失与梯度爆炸呢?
1.10.2、什么情况下会出现这两种情况?
1.10.3、如何解决梯度消失与梯度爆炸?
1.11、神经网络的权重初始化 (理论知识需补给)
1.12、梯度的数值逼近(Numerical approximation of gradients)
1.13 梯度检验(Gradient Checking)
1.14 关于梯度检验实现的标记
第二周 优化算法
2.1 Mini-batch 梯度下降法
2.2 理解 mini-batch 梯度下降法(Mini-batch 梯度下降法、batch 梯度下降法、stochastic 梯度下降法区别)
2.3 指数加权平均(Exponentially Weighted Averages)
2.4 理解指数加权平均
2.5 指数加权平均的偏差修正
2.6 动量梯度下降法(Gradient descent with momentum)
2.7 RMSprop(root mean square propagation,均方根传递)
2.8 Adam 优化算法(Adam optimization algorithm)
2.9 学习率衰减
2.10 局部最优的问题
第三周 超参数调试、Batch 正则化和程序框架
第四周、人工智能行业大师访谈
以下内容主要摘自吴恩达老师的课程(截图为主)
https://study.163.com/my#/smarts
第一周 深度学习的实用层面
1.1 训练 / 开发 / 测试集
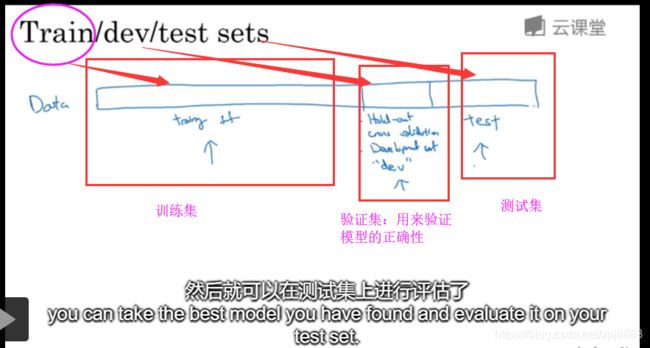
1.1.1、 训练集、验证集、测试集
https://blog.csdn.net/kieven2008/article/details/81582591
训练集(估计模型):用来训练数据。
验证集(验证算法或网络结构或参数):验证不同的算法(一般需要验证2-10个算法),检验哪种算法更加有效。
测试集(验证性能):检验最终选择最优的模型的性能如何。
1.1.2、训练集/验证集/测试集的数据比例一般为60%/20%/20%。当数据量比较庞大的时候(如100W条),这个比例可以调到98%/1%/%。

1.2 偏差 / 方差
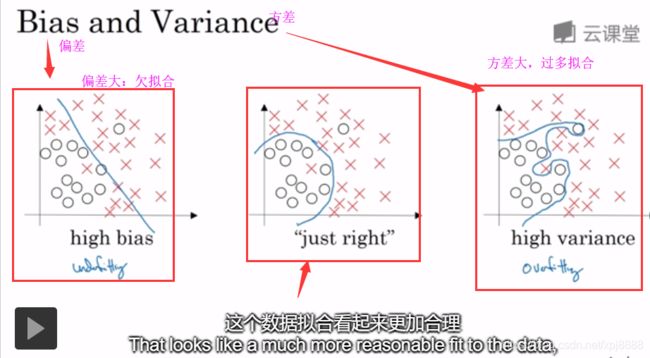
1.2.1、我们训练一个模型后,然后需要验证。于是,我们先看看偏差是否很低(即识别事物的错误率是不是很低),然后看看方差是不是也很低,最后,只有这两个都很低的时候,这个模型才能用。
1.2.2、而且需要注意,训练集和验证集的数据必须来自相同分布。否则的话,需要更加复杂的方法来分析偏差 / 方差。
1.3 机器学习基础
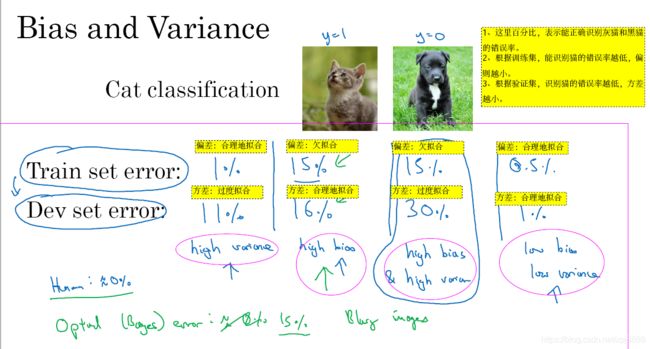
1.3.1、降低偏差/降低方差,往往存在一种折中关系(trade off)。
1.3.2、偏差
如果偏差较大,你需要重新设计网络(层数/神经元数据等等)或者花费更长时间训练或者选择更先进的算法。这样偏差才能降下来。
重新设计大规模网络往往可以降低偏差。
花费更长时间训练不一定有用。
1.3.4、方差
如果方差较高,尽可能获取更多的验证数据。
或者,有时候我们手头上的数据有限,可通过正则化来减少过拟合。但是正则化会出现偏差/方差trade off问题,如果网络足够大,我们在偏差稍微增幅的前提下,进行大幅度地优化方差。
1.4 正则化
https://blog.csdn.net/speargod/article/details/80233619
https://www.cnblogs.com/pinking/p/9310728.html
http://muchong.com/t-8449084-1-pid-4 “拉格朗日乘子” 和“正则化参数“两者之间的差别?“拉”属于“正”的一部分。
1.4.1、正则化的方式2(即L1)的稀疏矩阵,即矩阵中存在很多0,可以降低内存。
1.4.2、由于正则化的方式1(即L2)比较稳定,所以被采用得更加广泛。



1.5 为什么正则化可以减少过拟合?
就拿tanh(z)精活函数来说,lamda增大,要是目标函数J变小,w必须较小。其中,z=w*a+b。当z变小,tanh(z)接近线性函数。若是每个节点都为线性函数,那么整个神经网络就等于线程网络。
如下图所示:

1.6 Dropout 正则化
该方法会删除网络中的隐藏的某些节点,使的训练变快,而不影响网络性能。
具体参考下面的博客:
https://blog.csdn.net/u012328159/article/details/80210363GitHub上有源码
https://blog.csdn.net/Einstellung/article/details/79966825
学到了这里,基础理论打得差不多了。这时候,我们要一边学习理论或课程,一边把里面的算法实现。所以,我们应该开始着手做Python的东西了。
我在博客上,专门建立对应专利来介绍Python工具。
1.7 理解 Dropout
Dropout主要应用在计算机视觉领域,如果数据不够,就会容易发生过拟合,这就是为什么Dropout广泛应用在计算机视觉的原因。
每层的Keep-prob可能都不一样。
Dropout通常有两种方法来解决过拟合。 (方法1)某些层更容易发生过拟合,你可以把Keep-prob设置得低一些;但是为了使用交叉验证,你需要搜索的更多的超级参数,这也是缺点。(方法2)或者某些层用Dropout,某些层不用。

1.8 其他正则化方法
- 方差大——过拟合。
- 偏差大——欠拟合。
其他正则化方法,包括数据扩展方法、early stopping方法,其目的用来减少过拟合。
1.8.1、 数据扩展
数据扩展的方法——数据扩展可作为正则化方法使用:通过图片或字符做翻转、裁剪、扭曲等等操作,可以增加样本数据集,操作简单、花费廉价,可以用于减少过拟合。但是这样的样本信息冗余较大。如下图1-8-1所示。
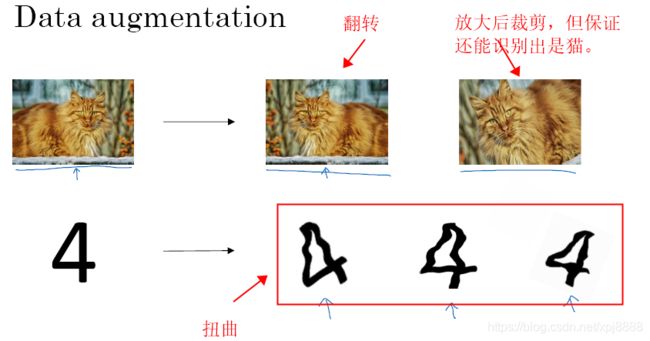
图1-8-1
1.8.2、early stopping
- early stopping方法——即提前停止训练神经网络。它的优点是防止过拟合的出现。缺点是并不能得到较好的代价函数,即偏差较大。如下图1-8-2所示。
- 交化概念正——若既要防止过拟合,又要达到较小的偏差,就需要用正交化的方式来处理了。课程的后面会提到交化概念正。
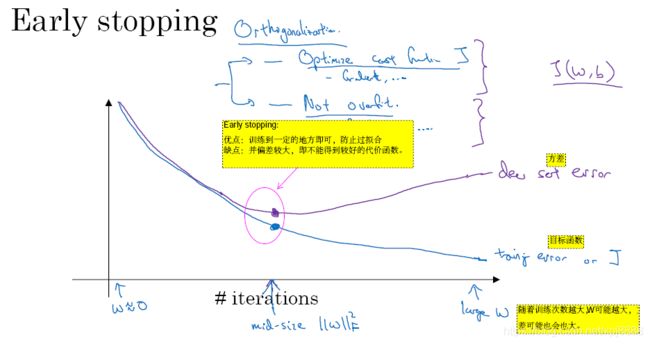
图1-8-2
1.9、正则化输入
正则化输入的方法,往往采用归一化的输入的方法。关于归一化
- 归一化输入——其有可能加快神经网络的训练速度或算法速度,但一定不会减慢速率速度训练速度或算法速度。
- 归一化的过程——如图1-9-1所示。
- 归一化的参数——x1和x2的方差都为1,均值都为0。
即
- 归一化的使用场景——输入特征分散,类似1~1000之间,就需要归一化了。若是输入特征集中,类似0~1,就不需要了。
- 归一化的使用原则——如果你想用归一化数据来训练、测试,必须相同的
参数值。
- 归一化的优点——使用归一化输入后,代价函数看起来像一个碗,便于我们评估性能(如图1-9-2的图二所示)。否则的化,就不好看(如图1-9-2的图一所示)。
- 非归一化——如图1-9-2的图一和图三所示,如果你要对图一和图三采用梯度下降法,W必须足够小。
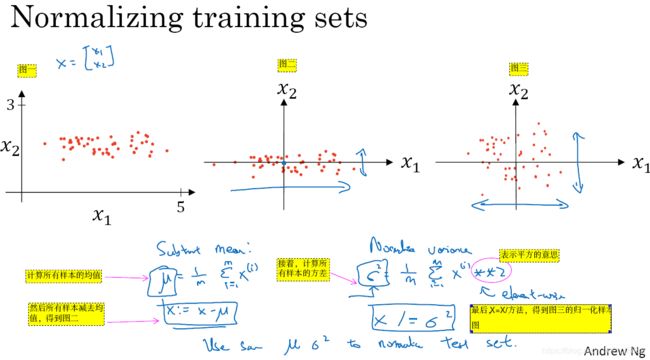
图1-9-1
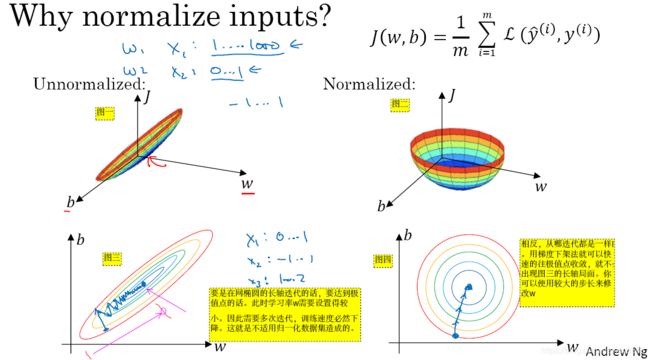
图1-9-2
1.10 梯度消失(Vanishing gradients)与梯度爆炸(exploding gradients)
1.10.1、什么是梯度消失与梯度爆炸呢?
- 梯度消失——训练深度神经网络时,激活函数系数以指数级减小,同时导数非常小,接近0。
- 梯度爆炸——训练深度神经网络时,激活函数系数以指数级增加,导数非常大,接近无穷。
1.10.2、什么情况下会出现这两种情况?
训练神经网络时,会出现梯度消失与梯度爆炸的局面,这种局面会导致神经节网络训练的困难。为什么会困难,假如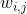 非常小(或非常大),每次迭代的步进必须设置得非常小(或非常大),将会花费很长时间来训练。
非常小(或非常大),每次迭代的步进必须设置得非常小(或非常大),将会花费很长时间来训练。
如图1-10-1所示,假设有L层神经网路,每层神经元(除了最后一层)的激活函数为线性函数![]() ,令
,令![]() ,那么系统输出可能变成下面的L-1次方输出。
,那么系统输出可能变成下面的L-1次方输出。
- 当
,比如
,那么L-1次方后,梯度就会爆炸。
- 当
,比如
,那么L-1次方后,梯度就会消失。
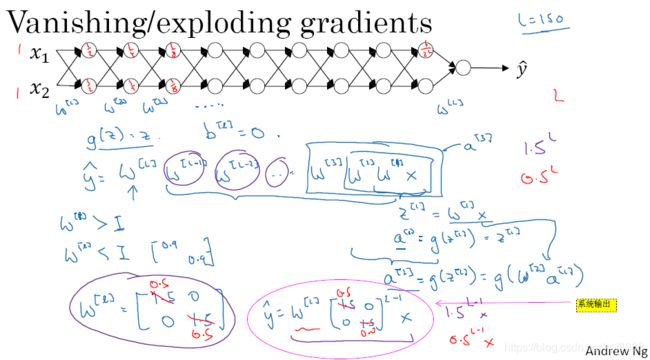
图1-10-1
1.10.3、如何解决梯度消失与梯度爆炸?
目前没有根本的解决办法,但是通过设置初始化权重(即初始化)可以有效解决。1.11节会讲到。
1.11、神经网络的权重初始化 (理论知识需补给)
有些论文中理论权重的初始化,比如某层的输入单元数为n,并且用线性函数作为激活函数,此时令![]() 。那么可以初始化为
。那么可以初始化为![]() 。为什么这样做呢?因为
。为什么这样做呢?因为 得到的值,既不会太大也不会太小。
得到的值,既不会太大也不会太小。
如果你用Relu作为激活函数,那么可以初始化为![]() 。
。
如果你用tanh作为激活函数,那么可以初始化为![]() 或
或 。其中L代表第几层神经元,n表示输入特征数。
。其中L代表第几层神经元,n表示输入特征数。
如图1-11-1所示的几种方法。
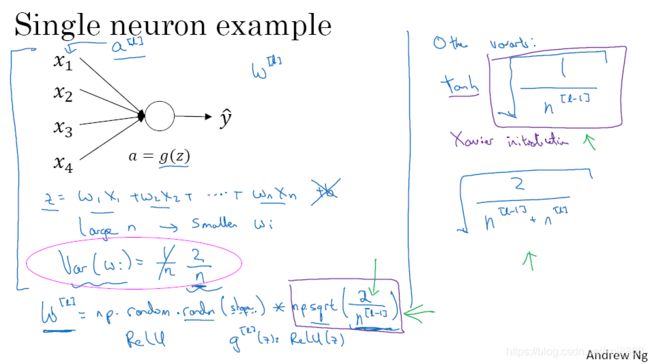
图1-11-1
1.12、梯度的数值逼近(Numerical approximation of gradients)
在利用backpro时,虽然你写完了这些表达式方程,但不能100%执行backprop的所有细节都是正确的,最终导致
因此我们需要对方程式进行梯度校验。做梯度校验的时候,我们首先需要对计算梯度做数值逼近(本节讨论),然后然后才是做校验(下节讨论)。
- 现在我们来计算
在
的导数,令
,如果我们只利用区间1或区间2来求导(导数为3.0301),其误差远远比区间3一起求导的结果要大(导数为3.0001)。如图1-12-1所示。
- 现在我们确定,图1-12-1的
可能是一个导数
正确实现,因为它比区间1或区间2更加准确,它的导数误差为
,这个误差可以根据图1-12-1的
- 要是在区间1或区间2求导,它的误差就变成了
。因为
很小,因此

图1-12-1
1.13 梯度检验(Gradient Checking)
梯度检验的作用体现在可以发现公式推导中backprop的bug问题。本节介绍如何使用梯度检验。我们定义代价函数写成
![]()
那么,它的导数为
![]() ,
,![]()
那么我们在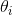 上计算导数,如下图1-13-1所示
上计算导数,如下图1-13-1所示
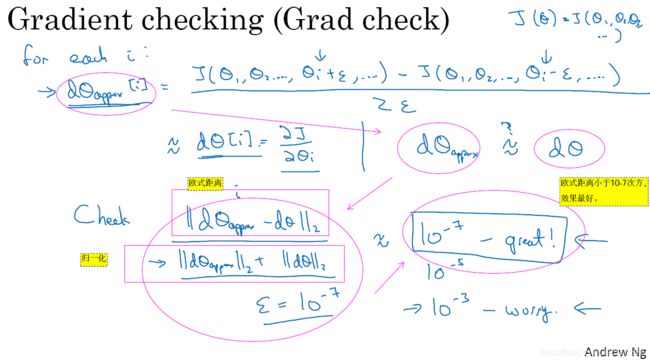
图1-13-1
图1-13-1中,![]() 最后写成了
最后写成了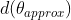 。那么如何判断与
。那么如何判断与![]() 是否一致,最好非常非常接近。利用两者的欧式距离,并做归一化处理(即除以两者的各自向量长度的欧几里得范数之和,防止比较结果过大或过小)。那么如何判断两者是否接近呢?
是否一致,最好非常非常接近。利用两者的欧式距离,并做归一化处理(即除以两者的各自向量长度的欧几里得范数之和,防止比较结果过大或过小)。那么如何判断两者是否接近呢?
若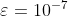 ,
, 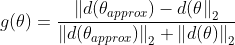 要比更小,那么有可能是正确的。若是
要比更小,那么有可能是正确的。若是![]() ,你还是要仔细检查下自己的导数是否正确。
,你还是要仔细检查下自己的导数是否正确。
特别注意的是,多余所有的 ,你都应该检查一次,所以需要进行遍历L次,从而发现我们神经网络存在的bug问题。对于所有的,误差都在合理范围的时候,你的求导才没有出错,也就是说在导数这一环节上,你的神经网络用起来才没有错误。
,你都应该检查一次,所以需要进行遍历L次,从而发现我们神经网络存在的bug问题。对于所有的,误差都在合理范围的时候,你的求导才没有出错,也就是说在导数这一环节上,你的神经网络用起来才没有错误。
1.14 关于梯度检验实现的标记
如图1-14-1所示, 这节分享神经网络在梯度校验中的使用技巧和注意事项:
- 1、不要在训练中使用梯度校验,梯度校验只适用于调试。若是在训练中使用,由于导数计算量大,会导致训练效率变慢。
- 2、当
与
不太一致,应检验所有的项。
- 3、 利用dropout正则化时,导数应包含正则项。
- 4、梯度检验不能与dropout同时使用,因为每次迭代过程中,dropout会随机消除隐层单元的的不同子集,从而导致难以计算dropout在梯度下降上的代价函数J。也就是说,dropout迭代的前后,代价函数发生了细微的变化,梯度检验不能用来检验前后不一致的代价函数。

图1-14-1
第二周 优化算法
- 机器学习的应用,是一个高度依赖经验的过程。多次的迭代过程,才能找到哪个模型适用。
- 此外,在大数据领域,由于数据集庞大,找到合适的优化算法,可以提升网络效率、团队效率。
- 因此,本周将学习优化算法,将帮助你快速训练模型,让神经网络运行得更加快。
- 这些算法包括了Mini-batch 梯度下降法、指数加权平均法等等。指数加权平均法就比梯度下降法快。
2.1 Mini-batch 梯度下降法
假设我们神经网络的样本集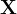 表示为
表示为
![\mathbf{X\mathbf{}} = \left [ x^{1},x^{2},...,x^{m} \right ]](http://img.e-com-net.com/image/info8/71369ee83e3c4ecfb77bc8b46aa9ad83.gif)
输出集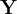 表示
表示
![]()
当样本很庞大的时候,比如500W个样本,那么按照以前的算法,若是对所有的数据集进行训练的时候,那么就要对500W个样本进行梯度下降,循环迭代了500W次,从而大大降低了算法效率。所以,必须想办法加快训练速度。
若是将样本集划分了5000个1000维度的子集,如下所示
那么输出就表示为
![\mathbf{Y\mathbf{}} = \left [ Y^{\left \{1\right \}},Y^{\left \{2\right \}},..., Y^{\left \{t\right \}} \right ]](http://img.e-com-net.com/image/info8/d4f49fd13ef746d5bdb1ae50a5053f0c.gif) ,
, ![]()
那么我们就需要迭代5000次,在每次迭代中,用向量化同时处理1000个样本,就大大地节约了时间。同时,我们应该注意一下大括号、中括号、小括号上标代表啥意思: 
图2-1-1
那么我要遍历一次500W的数据集,就要进行5000次迭代过程,在每个子集t中,都要进行批处理、损失函数、梯度下降等等计算,即总共进行了5000次梯度下降运算,:

图2-1-2
当然,若是你想遍历多次数据集,可以在for外面加上While或for循环,直到到达你的收敛条件。
2.2 理解 mini-batch 梯度下降法(Mini-batch 梯度下降法、batch 梯度下降法、stochastic 梯度下降法区别)
参考(更加详细的,可以参考这些博客):
https://blog.csdn.net/cs24k1993/article/details/79120579(重点)
https://blog.csdn.net/yato0514/article/details/82261821
https://blog.csdn.net/ycheng_sjtu/article/details/49804041
https://blog.csdn.net/qq_34059989/article/details/78161188
https://blog.csdn.net/stay_foolish12/article/details/91984832
在阐明这三种方法之前,必须要特别注意:

batch就是块的意思。关于Mini-batch 梯度下降法,它与batch 梯度下降法、stochastic 梯度下降法存在着大同小异。
| 类型 | 原理 | 优点 | 缺点 | 应用 |
| batch 梯度下降法 | 遍历全部数据集算一次损失函数、梯度下降的计算。即每次迭代需要处理大量的样本。 | 便于并行实现。。当目标函数为凸函数时,一定能够得到全局最优。 | 效率最慢 | 样本较小的条件可以用(小于2000) |
| stochastic 梯度下降法 | 对每个样本,都进行一次损失函数、梯度下降计算,直到计算完全部数据集。 | 效率最快 | 损失值容易跑偏、震动大、准确度下降、可能会收敛到局部最优、不易于并行实现。 | |
| Mini-batch 梯度下降法 | 如2.1.1的步骤,迭代多个子集,每次子集里面按1000个样本(即按批)来更新参数,梯度下降由每个子集的1000样本决定,梯度不容易跑偏,减少随机性。
|
效率与损失值折中下,获得局部最优,减少随机性、损失值不容易跑偏、计算量小、便于并行实现。 |
样本较大、在深度学习中训练数据。 考虑到电脑内存设置和使用方式(比如符合CPU/GPU的内存),batchSize 往往是2的多次方,这样效率更快。典型的 batchSize = 64、128、256、512、1024 |
|
如图2-2-1给出了batch 梯度下降法与mini-batch 梯度下降法的趋势,如图2-2-1 :
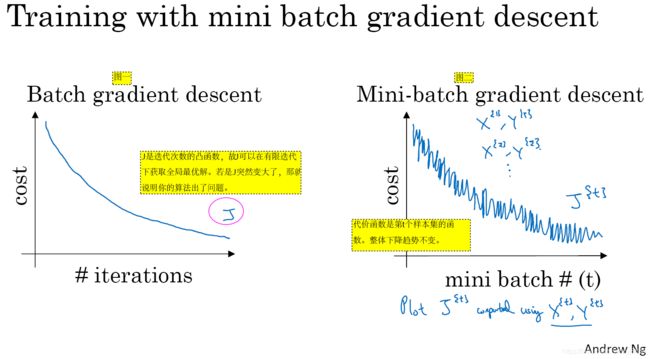
图2-2-1
- 对于图2-2-1,batchSize=m时,mini-batch 梯度下降法就是batch 梯度下降法了。
- 当batchSize= 1,mini-batch 梯度下降法就是stochastic 梯度下降法了。
对于三种它们收敛趋势,如图2-2-2所示:

图2-2-2
2.3 指数加权平均(Exponentially Weighted Averages)
- 本节讨论指数加权平均法,指数加权平均法就比梯度下降法快,其可以用在神经网络的梯度计算上。
- 本节讨论指数加权平均法后,将会讨论其他优化算法。
- 指数加权平均,在统计中,也叫指数加权移动平均。
- 本节视频中提到,世界上大部分国家使用摄氏度,但是美国使用华氏度。
我们先看下面的公式
![]()
- 其中,
表示上一天温度的动量值,
表示今天温度的动量值,
表示今天的温度,
就是英文Vector的缩写。或者从另外一个角度理解
意思是想求今天的温度,可以用过去近几天的温度和今天的温度,就可以得到。如图2-3-1所示。
表示天数的权重因子。若
,那上面的等式就表示取以前天数的0.9权重 + 取今天的0.1权重,一共就是10天,来计算今天温度。那么这10天是怎么来的呢?
,就是这样来的。简单的理解,今天占了0.1的权重,只占了10%,那么剩下的权重,是由过去90%决定的。
- 图2-3-2的线越平坦,平均的天数就越多。并且
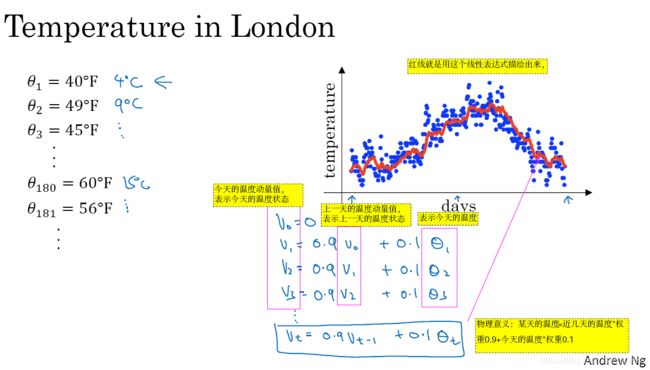
图2-3-1
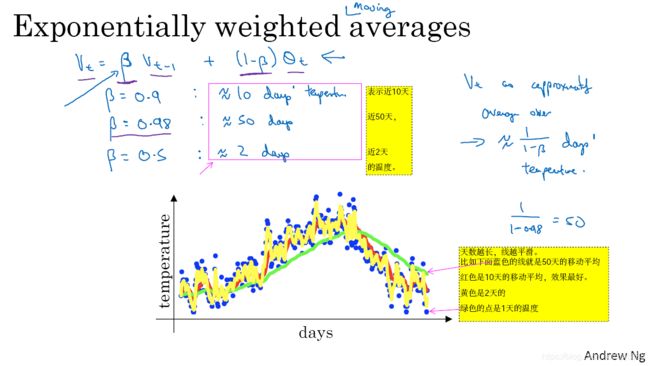
图2-3-2
2.4 理解指数加权平均
- 本小节,进一步阐述上一节的内容,以便我们理解该算法的本质作用。
- 如图2-4-1所示,将
第展开之后,它等于前99天以及今天温度的加权之和。实际上,
- 利用
可以写成
,编程时代码量少,占计算机内存很少。
- 注意一点,并不是说近期天数越多越好,前第n天系数是今天的
,我们就取到前第n天。前第(n+1)天的数据数据不要了,这是经验值。
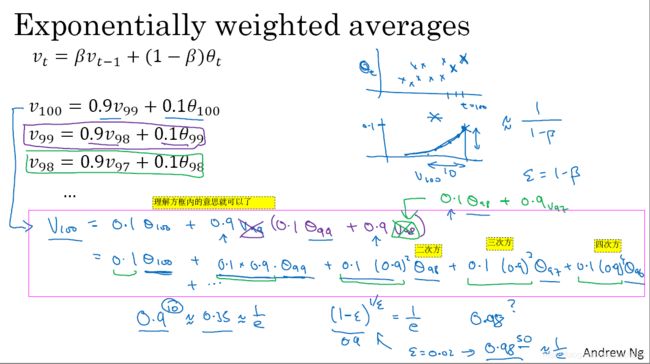
图2-4-1
2.5 指数加权平均的偏差修正
参考:https://www.cnblogs.com/cloud-ken/p/7723755.html
- 指数加权平均的偏差修正,可以让指数加权平均更加准确。为什么呢?它修正了什么东西?它修正了统计开始的前面哪些偏离点。
- 如图2-5-1所示,假如用
,那理想的温度曲线如绿色所示,但实际上,画出来曲线却是如紫色所示。我们用修正方法后,才能得到绿色的曲线。
- 吴老师的视频中说的偏差修正方法用
替代
或
等等。事实上,还是用
、
、
......
操作,
就是我们修正后的值。为什么这样做呢?在数学上,由于
,当
很大的时候,
接下来,如图2-5-1所示,根据指数加权平均![]() ,采用修正方法与否的估算结果:
,采用修正方法与否的估算结果:
| 不采用修正方法 | 采用修正方法 | |
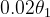 |
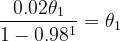 |
|
|
||
| ... | ... | ... |
| 效果如何 | 比如 |
1、估算出来的温度点,几乎与其实温度值的大小一致,相差不大。这时候,紫线和绿线重合了。 2、特别是在起始点的时候,估算效果更加好。 |
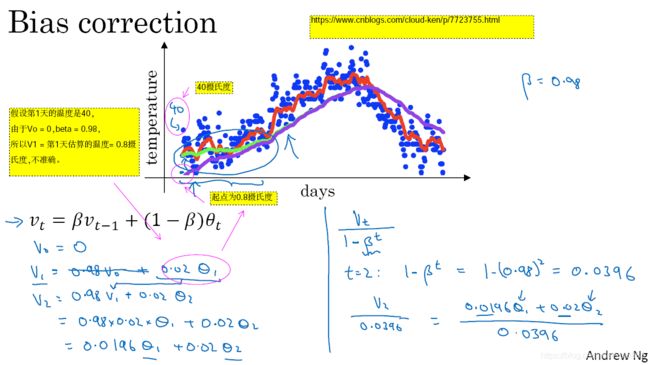
图2-5-1
2.6 动量梯度下降法(Gradient descent with momentum)
参考https://blog.csdn.net/Harpoon_fly/article/details/85345560
- 动量梯度下降法运行速度总是快于标准的梯度下降算法。它的基本思想是,计算梯度的指数加权平均数,并用该梯度更新你的权重。相比于2.5.1小结的指数加权,动量梯度下降法多了计算平均数这一步。
- 如图2-6-1所示,如果优化效益函数,我们希望达到红色点的最小值,在效益函数不偏离函数的范围条件下,那么我们希望学习率越大越好,这样效率更加。
- 如果用 梯度下降法、batch法、mini-batch法算法优化,就需要进行多个步骤计算或多次计算,最后慢慢摆动到最小值,如A曲线所示。
- A曲线的这种上下波动(在纵轴上下波动),减慢了梯度下降法的速度,你就无法使用更大的学习率,如果你使用更大的学习率(学习率越大,神经网络训练效率就越高),效益函数优化的结果就可能偏离函数的范围了,如B曲线所示。因此,为了避免摆动过大,你需要一个较小的学习率。
- 在另外一个角度理解A曲线的问题,若是帝都在纵轴上下波动很大,那结果会导致训练速度变慢,所以希望梯度在纵轴上下波动小,尽量沿着横轴方向变化。
- 若想摆动小、学习率大、训练速度快,可以用动量梯度下降算法来解决。本小结事件上是把2.1-2.5小结的知识综合起来用了。首先确定算法,比如mini-bacth算法,然后第t次iteration中,用动量来更新梯度,保证梯度的趋势基本不变。
- 进一步分析图2-6-1中动量梯度下降算法,为什么可以保证梯度的基本趋势不变。图2-6-1中的6个紫色小圆代表梯度下降法的六个梯度,可以看出它们具有一定的波动性。若是我们把这些梯度值进行平均,那么它们在纵轴上平均值接近于零,也就是说,这些梯度在纵轴方向上下摆动,几乎为零了,只剩下在横轴方向的波动了。此时微风
指向了横轴方向,我们就可以根据公式梯度更新公式
来更新梯度了,由于我们在横轴方向上波动大(即设置较大的学习率),那么函数收敛就会加快、神经网络就会训练加快。
- 用动量梯度下降算法,最终的效果如图2-6-1的红色曲线所示。
- 动量梯度下降算法,使用在碗装函数(凸函数),并不是用在所有函数。对于如何理解动量梯度下降算法的梯度更新公式
,举个例子来说:想像你有一个碗,碗上有一个球,微分项
就相当于这个球的上一个状态速度,
- 当我们迭代了多次之后,就不在收到偏差的困扰。因此
,如图2-6-2所示。
- 有些资料书中,动量用
表示,删除了
,相当于
- 我们还可以做别的事情来加快学习率。下节会讲到。
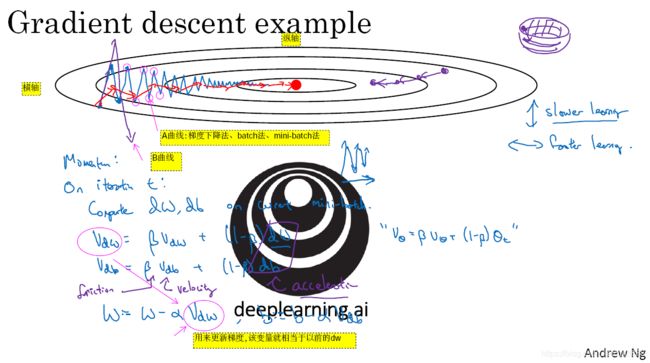
图2-6-1

图2-6-2
2.7 RMSprop(root mean square propagation,均方根传递)
- 对比动量梯度下降法,该算法也可以加快梯度下降,其更大的优点体现在即使沿着梯度变化大方向,也可以加大学习率
,不会偏离函数。参考https://blog.csdn.net/u012223913/article/details/78432412?utm_source=blogxgwz1
- 如图2-7-1所示,该算法可以加快横轴方向的学习,降低纵轴方向的学习。
- 该算法的基本步骤是:首先在第t次迭代中,计算法mini-batch的微分
。
- 然后,计算横轴方向的动量
、纵轴方向的动量
,即微分平方的加权平均,比2.6小结加权平均,差别就在这个平方项。
- 接着,更新
和
,
、
。我们希望
较小,那么经过
后,
较大,那么经过
,
- 注意图2-7-1的等高线椭圆,它代表着性能函数的登高线。如果沿着
- 该算法的收敛趋势,如图2-7-1的绿色线所示。此外,我们可以用一个更大学习率
- 在实际中,
,最后写成
和
。
。
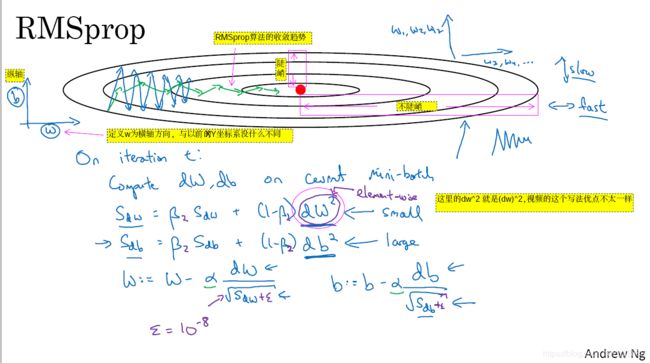
图2-7-1
2.8 Adam 优化算法(Adam optimization algorithm)
参考https://blog.csdn.net/junjun_zhao/article/details/79105995
- 在深度学习的历史上,包括许多知名研究者在内,提出了优化算法,并很好地解决了一些问题,但随后这些优化算法被指出,并不能一般化,并不适用于多种神经网络,时间久了 深度学习圈子里的人开始,多少有些质疑全新的优化算法,很多人都觉得, Momentum 梯度下降法很好用,很难再想出更好的优化算法。
- 本节的这个算法,为什么这个算法叫做 Adam ?Adam 代表的是Adaptive Moment Estimation,
用于计算这个微分,叫做第一矩,
用来计算平方数的指数加权平均数,叫做第二矩。所以 Adam 的名字由此而来,但是大家都简称为 Adam 权威算法。如图2-8-2所示。
- Adam 优化算法也是本视频的内容,就是少有的经受住人们考验的两种算法,已被证明,适用于不同的深度学习结构,这个算法,我会毫不犹豫地推荐给你,因为很多人都试过,并且用它很好地解决了许多问题。
- Adam 优化算法基本上就是,将 Momentum 和 RMSprop 结合在一起,因此我们要计算Momentum 的
、计算RMSprop
- Adam 算法结合了Momentum 和 RMSprop 梯度下降法,并且是一种极其常用的学习算法,被证明能有效适用于不同神经网络,适用于广泛的结构。
- Adam 算法超参数学习率 α 很重要,也经常需要调试你可以尝试一系列值,然后看哪个有效。这是经常调整的参数。
- 超参数
使用 0.999。
- 设置
- 超参数如图2-8-2所示。

图2-8-1

图2-8-2
2.9 学习率衰减
参考https://blog.csdn.net/JUNJUN_ZHAO/article/details/79106795
- 加快学习算法的一个办法就是,随时间慢慢减少学习率,我们将之称为学习率衰减。
- 我们来看看如何做到,首先通过一个例子看看,为什么要计算学习率衰减,假设你要使用 mini-batch 梯度下降法, mini-batch 数量不大,大概 64 或者 128 个样本,在迭代过程中会有噪音,下降朝向的最小值,但是不会精确地收敛,所以你的算法最后在最小值附近摆动,并不会真正地收敛。为什么会这样呢?因为你用的 α 是固定值,才导致效益值在最小值附近摆动,如图2-9-1的曲线A所示。
- 如图2-9-1的曲线B:初期学习率较大,后期学习率较小。在初期的时候,α 学习率还较大,你的学习还是相对较快,但是随着 α 变小,你的步伐也会变慢变小,所以最后你的曲线会在最小值附近的一小块区域里摆动。所以慢慢减少 α 的本质在于,在学习初期你能承受较大的步伐,但当开始收敛的时候,小一些的学习率能让你步伐小一些。
- 你可以这样做到学习率衰减,记得一代要历遍一次数据,如果你有以下这样的训练集,你应该拆分成不同的 mini-batch ,第一次历遍训练集叫做第一代,第二次就是第二代 以此类推,如图图2-9-2所示。于是,我们可以这样设置学习率
,其中
表示衰减率,衰减率
表示初始学习率。
- 如果
,
,那么在第一代中,所以学习率
,第二代学习率为 0.67,第三代变成 0.5, 第四代为 0.4 等等。最终,学习率呈递减趋势,如图2-9-2所示。
- 如果你想用学习率衰减,要做的是,要去尝试不同的值 包括超参数
- 除了这个学习率衰减的公式
- 下一周 我们会讲到,如何系统选择超参数。设定一个固定的 α,然后好好调整 会有很大的影响,学习率衰减的确大有裨益,有时候可以加快训练,但调整 α并不是我会率先尝试的内容。
- 下周我们将涉及超参数调整,你能学到更多系统的办法,来管理所有的超参数,以及如何高效搜索超参数。
- 最后我还要讲讲神经网络中的局部最优以及鞍点,所以你能更好理解局部最优以及鞍点,那么在训练神经网络过程中,你的算法正在解决这你的优化问题,下个视频我们就好好聊聊这些问题。
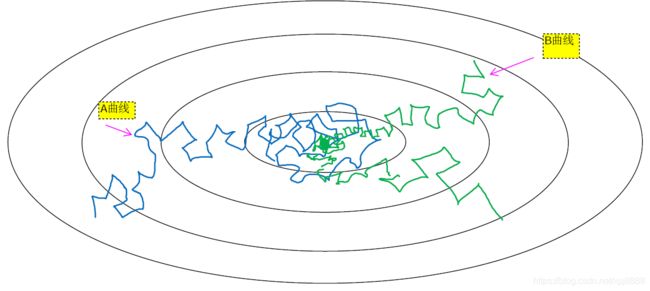
图2-9-1
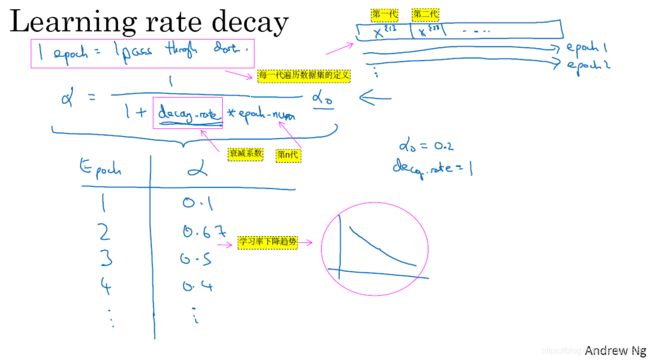
图2-9-2

图2-9-3
2.10 局部最优的问题
参考https://blog.csdn.net/JUNJUN_ZHAO/article/details/79106830
- 在深度学习研究早期,人们总是担心优化算法,会困在极差的局部最优,不过随着深度学习理论不断发展,我们对局部最优的理解也发生了改变。
- 我向你展示一下现在我们怎么看局部最优,以及深度学习中的优化问题,图2-10-1的图一是曾经人们在想到局部最优时,脑海里会出现的图,也许你想优化一些参数,我们把它们称之为
和
,平面的高度就是损失函数
。
- 在图2-10-1的图一中,似乎各处都分布着局部最优,梯度下降法,或者某个算法可能困在一个局部最优中,而不会抵达全局最优,如果你要作图计算一个数字,比如说这两个维度,就容易出现,有多个不同局部最优的图,而这些低维的图,曾经影响了我们的理解,但是这些理解并不正确。
- 事实上,如果你要创建一个神经网络,通常梯度为零的点并不局部最优点,比如是图2-10-1图一的A点。局部最优解的A点,每个方向都相同,它可能是凸函数或凹函数。关于什么是凸函数或凹函数,自己百度吧。本质上,凸函数可以与凹函数互相转换。
- 实际上成本函数的零梯度点,通常是鞍点,也就是图2-10-1图二的B点。
- 图2-10-1图二的
- 鞍点:实际上看起来向马鞍形状,在B点上,往一个方向是向上的,往另一个方向是向下的。所以B点不是局部最优解,而是鞍点。
- 神经网络中,如果局部最优不是大的问题,那么大的问题是什么?问题是平稳段会减缓学习,平稳段是一块区域,其中导数长时间接近于 0。如果你在图2-10-2的A点,梯度会从平面从上向下下降,因为梯度等于或接近 0,平面很水平,你得花上很长时间,慢慢抵达平稳段的图2-10-2的B点。
- 因为左边或右边的随机扰动,我换个笔墨颜色 大家看得清楚一些,然后你的算法能够走出平稳段,我们可以沿着这段长坡走,直到C点,然后走出平稳段AB。
- 所以此次视频的要点是,首先 你不太可能,困在极差的局部最优中,条件是你在训练较大的神经网络,存在大量参数,并且成本函数 J,被定义在较高的维度空间。参数越多,随机扰动就越多,由AB端往BC端走的机会就越多。
- 平稳段是一个问题,这样使得学习十分缓慢,这也是像 Momentum,或是 RmsProp Adam 这样的算法,能够加速学习算法的地方。在这些情况下,更成熟的观察算法,如 Adam 算法,能够加快速度,让你尽早往下走出平稳段。
- 因为你的网络要解决优化问题,说实话 要面临如此之高的维度空间,我觉得没有人有那么好的直觉,知道这些空间长什么样,而且我们对它们的理解还在不断发展,不过我希望这一点能够让你更好地理解,优化算法所面临的问题,恭喜你学会了,本周所有的内容,麻烦你做一下本周的小测以及练习,希望你能学以致用并乐在其中,期待你观看下周的视频。
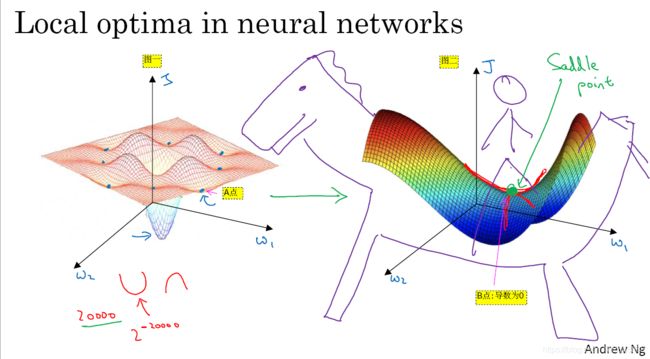
图 2-10-1
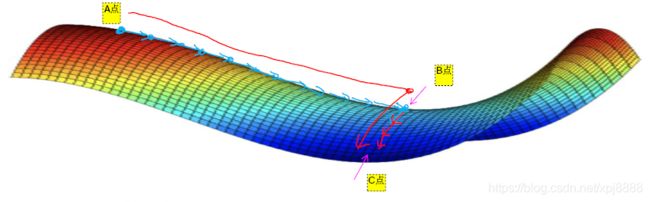
图 2-10-2
第三周 超参数调试、Batch 正则化和程序框架
参考:https://blog.csdn.net/Harpoon_fly/article/details/86500088(重点参考)
https://blog.csdn.net/kk123k/article/details/85334524
https://blog.csdn.net/kk123k/article/details/85334524
https://blog.csdn.net/qq_27806947/article/details/87734956
3.1 调试处理
本小结将了参数搜索的常规3种方式(对应了下面的三个图):对超参数分主次进行重点搜索、网格搜索到随机搜索、由粗糙到精密进行搜索。
- 大家好,欢迎回来,目前为止,你已经了解到,神经网络的改变会涉及到许多不同超参数的设置。现在,对于超参数而言,你要如何找到一套好的设定呢?在此视频中,我想和你分享一些指导原则,一些关于如何系统地组织超参调试过程的技巧,希望这些能够让你更有效的聚焦到合适的超参设定中。
- 关于训练深度最难的事情之一是你要处理的参数的数量,从学习率
,
和ε,也许你还得选择层数,也许你还得选择不同层中隐藏单元的数量,也许你还想使用学习率衰减。所以,你使用的不是单一的学习率
- 结果证实一些超参数比其它的更为重要,我认为,最为广泛的学习应用是
- 我还会调试mini-batch的大小,以确保最优算法运行有效。
- 我还会经常调试隐藏单元,我用橙色圈住的这三个(图3-1-1)。
- 当应用Adam算法时,事实上,我从不调试

图3-1-1
- 现在,如果你尝试调整一些超参数,该如何选择调试值呢?在早一代的机器学习算法中,如果你有两个超参数,这里我会称之为超参1,超参2,常见的做法是在网格中取样点(如图3-1-2的图一所示),然后系统的研究这些数值。这里我放置的是5×5的网格,实践证明,网格可以是5×5,也可多可少,但对于这个例子,你可以尝试这所有的25个点,然后选择哪个参数效果最好。当参数的数量相对较少时,这个方法很实用。
- 在深度学习领域,我们常做的,我推荐你采用下面的做法,随机选择点(如图3-1-2的图二所示),所以你可以选择同等数量的点,对吗?25个点,接着,用这些随机取的点试验超参数的效果。之所以这么做是因为,对于你要解决的问题而言,你很难提前知道哪个超参数最重要,正如你之前看到的,一些超参数的确要比其它的更重要。举个例子,假设超参数1是
- 我已经解释了两个参数的情况,实践中,你搜索的超参数可能不止两个。假如,你有三个超参数,这时你搜索的不是一个方格,而是一个立方体,超参数3代表第三维。接着,在三维立方体中取值,你会试验大量的更多的值,三个超参数中每个要搜索。实践中,你搜索的可能不止三个超参数,有时很难预知,哪个是最重要的超参数,对于你的具体应用而言,随机取值而不是网格取值表明——你探究了更多重要超参数的潜在值,无论结果是什么。(如图3-1-2的图二所示)
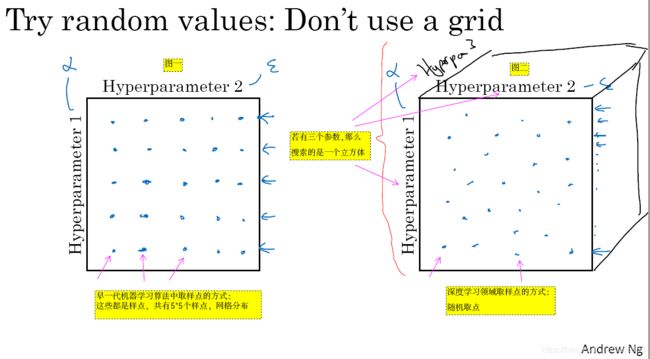
图3-1-2
- 当你给超参数取值时,另一个惯例是采用由粗糙到精细的策略。比如在二维的那个例子中,你进行了取值,也许你会发现效果最好的某个点,也许这个点周围的其他一些点效果也很好,那在接下来要做的是放大这块小区域(小蓝色方框内),然后在其中更密集得取值或随机取值,聚集更多的资源,在这个蓝色的方格中搜索。如图3-1-3所示,先粗糙搜索、后精密搜索。如果你怀疑这些超参数在这个区域的最优结果,那在整个的方格中进行粗略搜索后,你会知道接下来应该聚焦到更小的方格中。在更小的方格中,你可以更密集得取点。所以这种从粗到细的搜索也经常使用。
- 通过试验超参数的不同取值,你可以选择对训练集目标而言的最优值,或对于开发集而言的最优值,或在超参搜索过程中你最想优化的东西。
- 希望这能给你提供一种方法去系统地组织超参数搜索过程。另一个关键点是随机取值和精确搜索,考虑使用由粗糙到精细的搜索过程。但超参数的搜索内容还不止这些,在下一个笔记中,我会继续讲解关于如何选择超参数取值的合理范围。
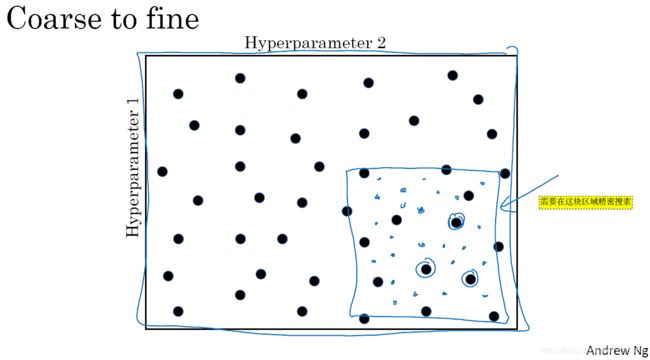
图3-1-3
3.2 为超参数选择合适的范围
参考https://blog.csdn.net/junjun_zhao/article/details/79115798
- 图3-2-1大概提供了如何随机选取层的单元数、或随机选取层数。
- 在上一个视频中 你已经看到了在超参数范围中,随机取值可以提升你的搜索效率,但随机取值并不是在有效值范围内的随机均匀取值,而是选择合适的标尺,合适的标尺用于探究这些超参数这很重要。在这个视频中 我会教你怎么做。
- 假设 你要选取隐藏单元的数量
,对于给定层
而言,假设你选择的取值范围是从 50 到 100 中某点,这种情况下 看到如图3-2-1这条从 50 - 100 的数轴,你可以随机在其上取点,这是一个搜索特定超参数的很直观的方式。(选隐层的单元数)
- 或者 如果你要选取神经网络的层数(选神经网络的层数),我们称之为字母 L,你也许会选择层数为 2 到 4 中的某个值,接着 顺着 2、3、4 随机均匀取样才比较合理,你还可以应用网格搜索,你会觉得 2、3、4,这三个数值是合理的, 这是几个在你的考虑范围内随机均匀取值的例子,这些取值还蛮合理的,但这对某些超参数而言不适用。

图3-2-1
- 如图3-2-2所示,在线性轴上,进行线性随机取值的话,在0.0001~0.1之间的搜索概率占了10%,不能充分利用更小的区间段0.0001~0.1。为了充分利用更小的区间段0.0001~0.1的搜索值来选取学习率
- 看看这个例子,假设你在搜索超参数
- 所以 在Python中 你可以这样做,使 r = -4 * np.random.rand(),然后
,所以 第一行可以得出r∈[-4,0],那
和
之间,所以最左边的数字是
和
之间取值,在此例中 这是
算出 a 的值,即 -4.在右边的值是
即 0
- 你要做的 就是在【a,b】区间随机均匀地给 r 取值,这个例子中 r∈[-4,0],然后你可以设置
,这就是在对数轴上取值的过程。

图3-2-2
- 如图3-2-3所示,这里讨论了如何随机搜索指数加权平均值
。也是进行了对数搜索,如图3-2-2所示一样的道理。
- 最后 另一个棘手的例子是给
,此值在 0.1 到 0.001 区间内,所以我们会给
和
。
- 值得注意的是 在之前的幻灯片里 我们把把最小值写在左边,最大值写在右边 但在这里 我们颠倒了大小,这里 左边的是最大值,右边的是最小值,所以你要做的就是在 [-3,-1] 里随机均匀的给 r 取值,你设定了
,所以
,然后这就变成了你的超参数随机取值,在特定的选择范围内,希望用这种方式可以得到想要的结果,你在 0.9 到 0.99 区间探究的资源,和在 0.99 到 0.999 区间探究的一样多。
- 所以 如果你想研究更多正式的数学证据,关于为什么我们要这样做 为什么用线性轴取值不是个好方法,这是因为当
,当
- 希望能帮助你选择合适的标尺,来给超参数取值。如果你没有在超参数选择中做出正确的标尺决定,别担心,即使你在均匀的标尺上取值,如果数值总量较多的话 你也会得到还不错的结果,尤其是应用从粗到细的搜索方法 在之后的迭代中,你还是会聚焦到有用的超参数取值的范围上,希望这会对你的超参数搜索有帮助,下一个视频中 我将会分享一些,关于如何组建搜索过程的思考,希望它能使你的工作更高效。
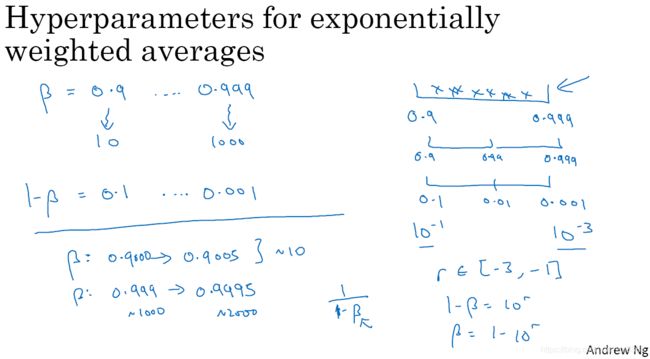
图3-2-3
3.3 超参数训练的实践:Panda vs. Caviar
参考https://blog.csdn.net/junjun_zhao/article/details/79118185
- 到现在为止 你已经听了许多关于如何搜索最优超参数的内容,在结束我们关于超参数搜索的讨论之前,我想最后和你分享一些建议和技巧,关于如何组织你的超参数搜索过程。
- 如今的深度学习已经应用到许多不同的领域,某个应用领域的超参数设定,有可能通用于另一领域,不同的应用领域出现相互交融,比如 我曾经看过计算机视觉领域中涌现的巧妙方法,比如说 Confonets 或 ResNets 这我们会在后续课程中讲到。它还成功应用于语音,我还看过最初起源于语音的想法成功应用于NLP等等。
- 深度学习领域中发展很好的一点是,不同应用领域的人们会阅读越来越多其它研究领域的文章,跨领域去寻找灵感,就超参数的设定而言,我见到过有些直觉想法变得很缺乏新意,所以即使你只研究一个问题 比如说逻辑学,你也许已经找到一组好的超参数设置并继续发展算法。或也许在几个月的过程中 观察到你的数据会逐渐改变,或也许只是在你的数据中心 更新了服务器,正因为有了这些变化,你原来的超参数的设定不再好用。所以我建议,或许只是重新测试或评估你的超参数 每隔几个月至少一次,以确保你对数值依然很满意。
- 最后 关于如何搜索超参数的问题,我见过大概两种重要的思想流派,人们通常采用的两种重要但不同的方式,一种方法是你照看一个模型,通常是有庞大的数据组,但没有许多计算资源或足够的CPU和GPU的前提下,基本而言 你只可以一次负担起试验一个模型或一小批模型,这种情况下 即使当它在试验时 你也可以逐渐改良,比如图3-3-1的图一,在第 0 天 你将随机参数初始化,然后开始试验,然后你逐渐观察自己的学习曲线 也许是损失函数 J,或者数据设置误差或其他的东西 在第一天内逐渐减少,那这一天末的时候 你可能会说 看 它学习得真不错,我要试着增加一点学习速率 看看它会怎样,也许结果证明它做得更好,那是你第二天的表现。两天后 你会说 它依旧做得不错,也许我现在可以填充下 momentum或减少变量,然后 进入第三天,每天 你都会观察它 不断调整你的参数,也许有一天你会发现你的学习率太大了,所以 你可能又回归之前的模型。像这样,但你可以说是在每天花时间照看此模型,即使是它在许多天或许多星期的试验过程中,所以 这是一个人们照料一个模型的方法,观察它的表现 耐心地调试学习率,但那通常是因为你没有足够的计算能力,不能在同一时间试验大量模型时才采取的办法。(该方法需要人工照看、并需要人工调整参数、效率低、只适用少量参数少量模型)
- 另一种方法则是同时试验多种模型(如图3-3-1的图二),你设置了一些超参数,尽管让它自己运行 或者是一天甚至多天,然后你会获得像这样的学习曲线,这可以是损失函数 J 或实验误差的损失或数据设置误差的损失 但都是你曲线轨迹的度量。同时 你可以开始一个有着不同超参数设定的不同模型,所以 你的第二个模型会生成一个不同的学习曲线,也许是像这样的一条,我会说这条看起来更好些,与此同时 你可以试验第三种模型,其可能产生一条像这样的学习曲线 还有另一条,也许这条有所偏离 像这样 等等,或者你可以同时平行试验许多不同的模型,橙色的线就是不同的模型 对 是这样,用这种方式你可以试验许多不同的参数设定,然后只是最后快速选择工作效果最好的那个,在图3-3-1的图二这个例子中 也许这条(A曲线)看起来是最好的。(该方法效果高、并行处理不同参数的不同模型,但需要更多的计算机资源)
- 打个比方,我把左边的方法称为熊猫方式,当熊猫有了孩子 他们的孩子非常少,一次通常只有一个,然后他们花费很多精力抚养熊猫宝宝以确保其能成活,所以 这的确是一种照料,一种模型类似于一只熊猫宝宝,对比而言 右边的方式更像鱼类的行为,我称之为鱼子酱方式,在交配季节 有些鱼类会产下一亿颗卵,但鱼类繁殖的方式是 它们会产很多卵,但不对其中任何一个多加照料,只是希望其中一个 或其中一群 能够表现出色,我猜 这就是哺乳动物繁衍和,鱼类 很多爬虫类动物繁衍的区别,我将称之为熊猫方式与鱼子酱方式,因为这很有趣 更容易记住。
- 所以 这两个方式的选择,是由你拥有的计算资源决定的,如果你拥有足够的计算机去平行试验许多模型,那绝对采取鱼子酱方式,尝试许多不同的超参数 看效果怎样,但在一些应用领域 比如在线广告设置,和计算机视觉应用领域,那里的数据太多了 需要试验大量的模型,所以同时试验大量的模型是很困难的,它的确是依赖于应用的过程,但我看到那些应用熊猫方式多一些的组织,那里 你会像对婴儿一样照看一个模型,调试参数 试着让它工作运转,尽管 当然 甚至是在熊猫方式中 试验一个模型,观察它工作与否 也许第二或第三个星期后,也许我应该建立一个不同的模型,像熊猫那样照料它 我猜 这样一生中可以培育几个孩子,即使它们一次只有一个孩子 或孩子的数量很少。
- 所以希望你能学会,如何进行超参数的搜索过程,现在 还有另一种技巧,能使你的神经网络变得更加坚实,它并不是对所有的神经网络都适用 但当适用时,它可以使超参数搜索变得容易许多并加速试验过程,我们在下个视频中再讲解这个技巧。

图3-3-1
3.4 正则化网络的激活函数
参考https://blog.csdn.net/junjun_zhao/article/details/79119257
- 注意,由于公司编辑器无法加粗希腊字母,但本小结的
和
和
都是表示矢量的意思。本小结
- 以前介绍了归一化输入样本,如图3-4-1的图一所示。本节介绍归一化每层激活函数前的线性表达式
(默认归一化这个值)、或归一激活函数
也可以。
- 在深度学习兴起后,最重要的一个思想是它的一种算法叫做 Batch 归一化,由 Sergey Ioffe 和 Christian Szegedy 两位研究者创造, Batch 归一化会使你的参数搜索问题变得很容易,使神经网络对超参数的选择更加稳定,超参数的范围会更庞大工作效果也很好,也会使你很容易的训练甚至是深层网络,让我们来看看 Batch 归一化是怎么起作用的吧。
- 当训练一个模型 比如 logistic 回归时 你也许会记得,归一化输入特征可加速学习过程,你计算了平均值,从训练集中减去平均值。计算了方差,即
的平方和,这是点积平方,接着根据方差归一化你的数据集,在之前的视频中我们看到,这是如何把学习问题的轮廓,从很长的东西变成更圆的东西,更易于算法优化。所以,对 logistic 回归和神经网络的归一化输入特征值而言,这是有效的。
- 那么更深的模型呢,你不仅输入了特征值
,而且图3-4-1的图二中,有激活值
、激活值
等等,如果你想训练这些参数 比如
、
,那归一化
- logistic 回归的例子中,我们看到了如何归一化
和
,所以问题来了,对于任何一个隐藏层而言,我们能否规归一化
- 简单来说 这就是 Batch 归一化的作用,尽管 严格来说 我们真正归一化的不是
,深度学习文献中有一些争论,关于在激活函数之前是否应将值
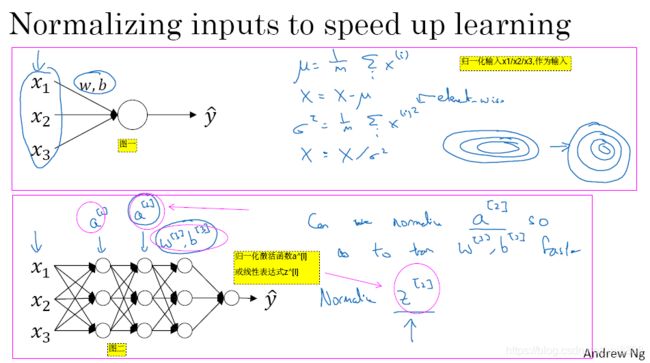
图3-4-1
- 本小结的Batch 归一化实际上,就是归一化每层的
,并通过
- 那下面就是 Batch 归一化的使用方法,在神经网络中已知一些中间值,假设你在第
层有一些隐藏单元值 从
。你要计算平均值和方差,如图3-4-2所示。接着你会取每个
再除以标准偏差。为了使数值稳定通常将
作为分母,以防
的情况,所以现在 我们已把这些
- 但我们不想让隐藏单元总是含有平均值 0 和方差 1,也许隐藏单元有了不同的分布会更有意义,所以我们所要做的就是计算,称之为
,这里
- 请注意
的平均值,事实上 如果
,即
,通过对
- 从根本来说 只是计算恒等函数,通过赋予
、
等等,现在则会用
- 所以我希望你学到的是归一化输入特征
- 图3-4-2的A曲线是sigmoid函数。B曲线是高斯分布函数,若我们通过改变
- 我希望你能学会怎样使用 Batch 归一化,至少就神经网络的单一层而言,在下一个视频中 我会教你如何将 Batch 归一化与神经网络,甚至是深度神经网络相匹配,对于神经网络许多不同层而言 又该如何使它适用,之后 我会告诉你, Batch 归一化有助于训练神经网络的原因,所以如果觉得 Batch 归一化起作用的原因还显得有点神秘 那跟着我走,在接下来的两个视频中 我们会弄清楚。
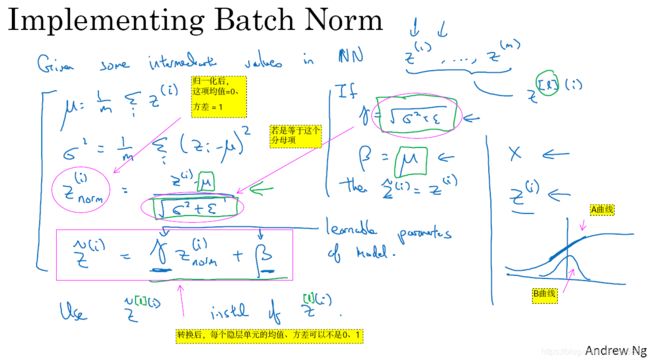
图3-4-2
3.5 将 Batch Norm 拟合进神经网络
相关参考:https://blog.csdn.net/junjun_zhao/article/details/79122303
- 注意,由于公司编辑器无法加粗希腊字母,但本小结的
- 你已经看到那些等式,它可以在单一隐藏层上进行 Batch 归一化,接下来 让我们看看它是怎样在深度网络训练中拟合的吧,假设你有一个这样的神经网络(如图3-5-1所示),我之前说过,你可以认为每个单元负责计算两件事,第一 它先计算
和
等。
- 所以 如果你没有应用 Batch 归一化,你会把拟合到第一隐藏层,然后首先计算
,这是由
和
两个参数控制得。接着,通常而言,你会把
和
两参数控制,这一步操作会给你一个新的规范化的
。
- 现在 你已在第一层进行了计算,此时 这项 Batch 归一化发生在
和
控制的,与你在第一层所做的类似,你会将
和
,现在你得到
,再通过激活函数计算出
。
- 需要澄清的是 请注意 这里的这些
没有任何关系,下一张幻灯片中会解释原因。后者是用于 momentum ,或计算各个指数的加权平均值, Adam 论文的作者,在论文里用
- 在之前的视频中,我已经解释过 Batch 归一化是怎么操作的,计算均值和方差 减去 再被它们除,如果它们使用的是深度学习编程框架,通常 你不必自己,把 Batch 归一化步骤应用于 Batch 归一化层,因此 探究框架,可写成一行代码,比如说 在 TensorFlow 框架中,你可以用这个函数
来实现 Batch 归一化,我们会稍后讲解。但实践中 你不必自己操作所有这些具体的细节,但知道它是如何作用的,这样,你会更好的理解代码的作用,但在深度学习框架中 Batch 归一化的过程,经常是类似一行代码的东西,所以 到目前为止 我们已经讲了 Batch 归一化,就像你在整个训练站点上训练一样,或就像你正在使用 Batch 梯度下降。
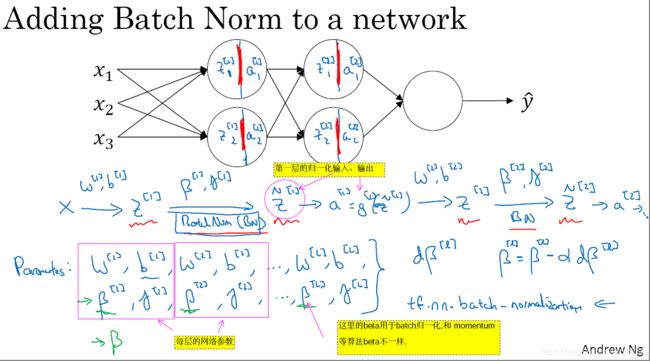
图3-5-1
- 实践中, Batch 归一化通常和训练集的 mini-batch 一起使用。你应用 Batch 归一化的方式就是,你用第一个 mini-batch
然后计算
- 接着 继续第二个 mini-batch
,接着 Batch 归一化会减去均值 除以标准差,由
,而所有的这些都是在第一个 mini-batch 的基础上,你再应用激活函数得到
- 所以在 Batch 归一化的此步中,你用第二个 mini-batch 中的数据使
- 现在 我想澄清此参数化的一个细节,先前 我说过每层的参数是
和
,还有
,但 Batch 归一化做的是,它要看这个 mini-batch ,先将
归一化 结果为均值 0 和标准方差,再由
,然后你计算归一化的
,你最后会用参数
的取值,这就是原因。
- 所以 总结一下,因为 Batch 归一化 0 超过了此层
- 最后 请记住
),
隐藏单元 所以
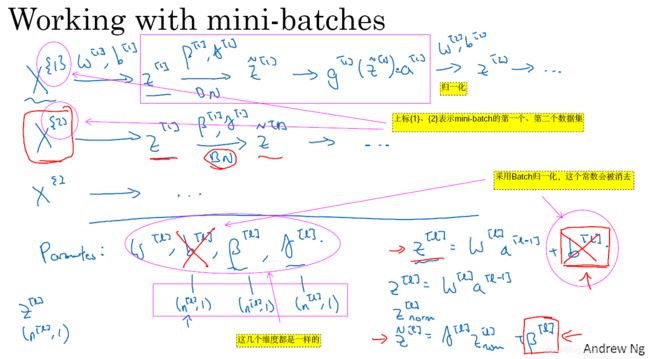
图3-5-2
- 让我们总结一下,关于如何把 Batch 归一化来应用于梯度下降法。假设你在使用 mini-batch 梯度下降法,你运行 batch -size数量的 for 循环,你会应用正向 prop 于 mini-batch
,每个隐藏层都应用正向 prop,用 Batch 归一化替代
和
,及
和
。尽管 严格来说 因为你要去掉 b(如图3-5-3),这部分其实已经去掉了。最后 你更新这些参数,
和以前一样,
,对于
- 我希望 你能学会如何从头开始应用 Batch 归一化 。如果你想的话,如果你使用深度学习编程框架之一,我们之后会谈到,希望 你可以直接叫别人应用于编程框架, 这会使 Batch 归一化的使用变得很容易,现在,以防 Batch 归一化仍然看起来有些神秘或模糊不清楚,尤其是你还不清楚为什么其能如此显著的加速训练,我们下一个视频中会谈到, Batch 归一化为何效果如此显著,它到底在做什么。

图3-5-3
3.6 Batch Norm 为什么凑效?
参考https://blog.csdn.net/junjun_zhao/article/details/79122690
https://www.cnblogs.com/xiaojianliu/articles/9695464.html
- 为什么 batch 归一化会起作用呢? 一个原因是 你已经看到如何归一化输入特征值
,使其均值为 0 、方差为 1,它又是怎样加速学习的,与其有一些从 0 到 1,从 1 到 1000 的特征值,通过归一化所有的输入特征值
- Batch 归一化有效的第二个原因是,它可以使权重比你的网络更滞后或更深层,比如 第 10 层的权重更能经受得住变化,相比于神经网络中前层的权重 比如层一,为了解释我的意思,让我们来看看这个最生动形象的例子,这是一个网络的训练,也许是个浅层网络,比如 logistic 回归或是一个神经网络,也许是个浅层网络 像这个回归函数 或一个深层网络,建立在我们著名的猫脸识别检测上,但假设你已经在所有黑猫的图像上训练了数据集,如果现在你要把此网络应用于有色猫,这种情况下正面的例子不只是左边的黑猫,还有右边其它颜色的猫,那么你的 cosfa(性能、结果)可能适用的不会很好。如图3-6-1所示。
- 如果图3-6-1图像中,你的训练集是这个样子的,你的正面例子在这儿(图3-6-1的A1的数据集)、反面例子在那儿(B1的数据点),但你试图把它们都统一于一个数据集,也许正面例子在这儿(A2)反面例子在那儿(B2),你也许无法期待 在左边训练得很好的模块,同样在右边也运行得很好,即使存在运行都很好的同一个函数,但你不会希望你的学习算法去发现,绿色的决策边界 如果只看左边数据的话。所以,使你数据改变分布的这个想法,有个有点怪的名字 covariate shift,想法是这样的,如果你已经学习了 x 到 y 的映射,如果 x的分布改变了,那么你可能需要重新训练你的学习算法,这种做法同样适用于真实函数。如果真实函数,由 x 到 y的 映射保持不变,正如此例中,因为真实函数,是此图片是否是一只猫,训练你的函数的需要变得更加迫切,如果真实函数也改变情况就更糟了,covariate shift的问题怎么应用于神经网络呢?吴恩达这里阐述得很啰嗦,他的本质意思是训练黑猫的网络可能不适合训练彩色猫,因为两者的数据集可能分布不太一样,黑猫数据集、非猫数据集 如A1 B1所示,彩色猫数据集、非猫数据集如A2B2所示。这种数据分布的改变叫做covariate shift。具体可以理解在x到y的映射中,但是如果x的分布改变了,那么可能需要重新训练学习算法。
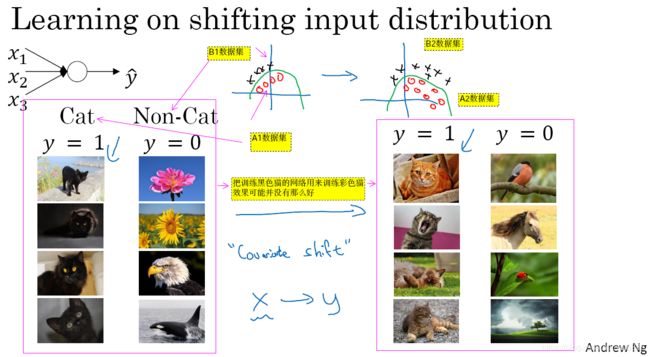
图3-6-1
- 这部分阐述了由于Batch归一化,使得神经网路每层的
分布几乎是一致的。若
- 试想一个像这样的深度网络(如图3-6-2所示),让我们从第三隐藏层来看看学习过程,此网络已经学了参数
和
,从第三隐藏层的角度来看,它从前层中取得一些值,接着它需要做些什么,希望使输出值
接近真实值
。让我先遮住左边的东西,从第三隐藏层的角度来看,它得到一些值,称为
,但这些值也可以是特征值
(视频中的公式可能描述有问题,与我的不太一样)。第三隐藏层的工作是,找到一种方式使这些值映射到
和
、
和
,也许是所有这些参数,所以网络性能的不错。从左边我用黑笔写的,映射到输出值
- 现在我们把网络的左边揭开,这个网络还有参数
和
、
和
,如果这些参数改变,这些
的分布,我要绘制两个值而不是四个值,以便我们设想为2D, batch 归一化讲的是,
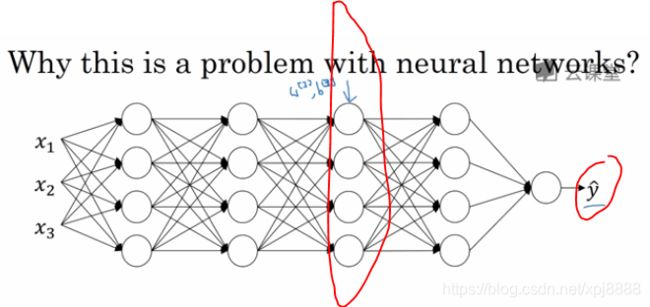
图3-6-2
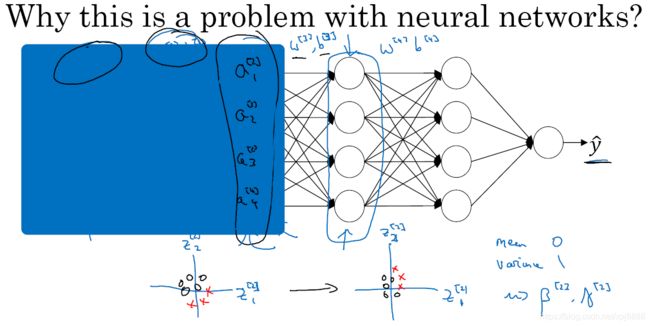
图3-6-3
- 该部分,吴恩达将得太啰嗦了。实际上,他想描述的是,由于mini- batch
是采用了多个样本计算的,因为第t次训练计算出的结果
,
- 所以 希望这能带给你更好的直觉,重点是 batch 归一化的意思是,尤其从神经网络后层之一的角度而言,前层不会左右移动的那么多,因为它们被同样的均值和方差所限制。所以,这会使得后层的学习工作变得更容易些。batch 归一化还有一个作用,它有轻微的正则化效果, batch 归一化中非直观的一件事是每个 mini- batch ,我会说 mini- batch
和一个
- 因为在 mini- batch 上计算的均值和方差,而不是在整个数据集上,均值和方差有一些小噪音,因为它只在你的 mini- batch 上计算,比如 64 或 128 或 256,或更大的训练例子,因为均值和方差有一点小噪音,因为它只是由一小部分数据估计得出的,缩放过程从
到
- 所以和 dropout 相似,它往每个隐藏层的激活值上增加了噪音, dropout 有噪音的方式,它使一个隐藏的单元 以一定的概率乘以 0,以一定的概率乘以 1,所以你的 dropout 含几重噪音,因为它乘以 0 或 1,对比而言 batch 归一化含几重噪音,因为标准偏差的缩放,和减去均值带来的额外噪音,这里均值和标准偏差的估值也是有噪音的。
- 所以类似于 dropout , batch 归一化有轻微的正则化效果,因为给隐藏单元添加了噪音,这迫使后部单元,不过分依赖任何一个隐藏单元,类似于 dropout ,它给隐藏层增加了噪音,因此有轻微的正则化效果,因为添加的噪音很微小,所以并不是巨大的正则化效果,你可以将 batch 归一化和 dropout 一起使用,你可以将两者共同使用,如果你想得到 dropout 更强大的正则化效果,也许另一个轻微的非直观的效果是,如果你应用了较大的 mini- batch ,对 比如说 你用了,512 而不是 64,通过应用较大的 mini- batch ,你减少了噪音,因此减少了正则化效果,这是 dropout 的一个奇怪的性质,就是应用较大的 mini- batch ,可以减少正则化效果,说到这儿 我把会把 batch 归一化当成一个规则,这确实不是其目的,但有时他会对你的算法有额外的期望效应,或非期望效应,但是不要把 batch 归一化当作规则,把它当作将你归一化隐藏单元激活值,并加速学习的方式,我认为正规化几乎是一个意想不到的副作用。
- 所以希望这能让你更理解 batch 归一化的工作,在我们结束 batch 归一化的讨论之前,我想确保你还知道一个细节, batch 归一化一次只能处理一个 mini- batch 数据,它在 mini- batch 上计算均值和方差,所以测试时,你试图做出预测试着评估神经网络,你也许没有 mini- batch 例子,你也许一次只能进行一个简单的例子,所以测试时 你需要做一些不同的东西,以确保你的预测有意义,在下一个和最后的 batch 归一化的视频中,让我们详细谈谈你需要的细节,来让你的神经网络应用 batch 归一化来做出预测。
3.7 测试时的 Batch Norm
- 本节讨论了如何测试我们计算的
和
的正确性。我们在测试时,随机代入少量样本就可以验证
、
、.....
,利用指数加权平均的方式(即动量的方式),来获取
,我们可以用公式3和公式4 来代入验证,只要
- batch 归一化将你的数据以 mini-batch 的形式逐一处理,但在测试时,你可能需要对每一个样本逐一处理,我们来看一下怎样调整你的网络来做到这一点。
- 回想一下在训练时,这些就是用来执行 Batch 归一化的等式(图3-7-1所示),在一个 mini-batch 中,你将 mini-batch 的
来表示这个 mini-batch 中的样本数量,而不是整个训练集。然后计算方差,再算
是用
- 但是在测试时 你可能不能将一个 mini-batch 中的6428 个或 2056 个样本同时处理,因此你需要用其他方式来得到
- 那么实际上,为了将你的神经网络运用于测试,就需要单独估算
、
..........,以及对应的 y 值等等。那么在为
,我当你训练第二个 mini-batch ,你就会得到第二个
值。
- 正如我们之前用指数加权平均,来计算
的均值,当时是试着计算当前气温的指数加权平均,你会这样来追踪,你看到的这个均值向量的最新平均值,于是这个指数加权平均就成了
,你对这一隐藏层的
均值的估值,同样的你也可以用指数加权平均来追踪,你在这一层的第一个 mini-batch 中所见的
- 最后在测试时,对应这个等式(图3-7-1所示的公式3),你只需要用你的
- 估算的方式有很多种,理论上你可以在最终的网络中运行整个训练集,来得到

图3-7-1
3.8 Softmax 回归(Softmax regression)
- 到目前为止 我们讲到过的分类的例子都使用了二分分类,这种分类只有两种可能的标记 0 或 1,这是一只猫或者不是一只猫。如果我们有多种可能的类型的话呢?有一种 logistic 回归的一般形式,叫做 Softmax 回归,能让你在试图识别某一分类时做出预测,或者说是多种分类中的一个,不只是识别两个分类。我们来一起看一下,假设你不单需要识别猫,而是想要识别猫、狗和小鸡,我把猫叫做类1, 狗为类2,小鸡是类3。如果不属于以上任何一类,就分到”其他”,或者说,”以上均不符合”这一类 我把它叫做类0。这里显示的图片及其对应的分类就是一个例子,图3-8-1所示,这幅图片上是一只小鸡,所以是类3,猫是类1,狗是类2,我猜这是一只考拉 所以以上均不符合,那就是类0。下一个类3,以此类推。

图3-8-1
- 如图3-8-2所示,我们将会用符号表示 我会用大写 C ,来表示你的输入会被分入的类别总个数。在这个例子中 我们有 4 种可能的类别,包括”其他”或”以上均不符合”这一类,当有 4 个分类时 指示类别的数字,就是从 0 到大写 C-1,换句话说 就是 0、1、2、3。在这个例子中 我们将建立一个神经网络 其输出层有 4个,或者说变量大写字母 C 个输出单元,因此 n 即输出层也就是 L 层的单元数量,等于 4 或者一般而言等于C 。我们想要输出层单元的数字告诉我们,这 4 种类型中每一个的概率有多大。所以图3-8-1的第一个节点输出的应该是其他类的概率(a点),或者说我们希望它输出”其他”类的概率。在输入 x 的情况下,这个会输出是猫的概率(b点)。 在输入 x 的情况下,这个会输出是狗的概率(c点)。 在输入 x 的情况下,这个会输出小鸡的概率(d点)。在输入 x 的情况下,因此这里的
将是一个 4∗1维向量,因为它必须输出四个数字,输出的中的四个数字加起来应该等于 1。
图3-8-2
- 让你的网络做到这一点的标准模型,要用到Softmax 层以及输出层来生成输出。让我把式子写下来,然后回过头来 就会对 Softmax 的作用有一点感觉了。在神经网络的最后一层,你将会像往常一样计算各层的线性部分,z大写L,这是最后一层的z变量,记住这是大写L层。如图3-8-3所示,和往常一样,计算方法是
乘以上一层的激活值
,再加上最后一层的偏差
,算出了
之后,你需要应用 Softmax 激活函数,这个激活函数对于 Softmax 层而言有些不同。它的作用是这样的,首先我们要计算一个临时变量,我们把它叫做
,它等于e的
,这适用于每个元素,而这里的
等于每个输出元素除以所有维度e的
- 实际上,这里讨论的神经网络的输出
图3-8-3
- 如图3-8-4所示,以防这里的计算不够清晰易懂,我们马上会举个例子来详细解释,以防计算不够清晰,我们来看一个例子详细解释。假设你算出了
,
,
,
,如果你按一下计算器就会得到以下值,
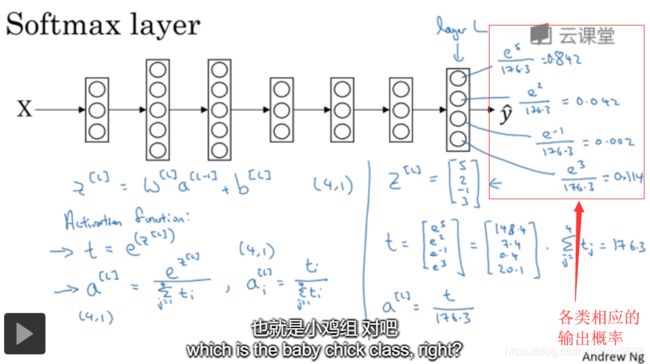
图3-8-4
- 那么,Softmax 分类器(就是刚才图3-8-4讨论的分类方法)还可以代表其他的什么东西呢?我来举几个例子,如图3-8-5所示, 你有两个输入
,
,它们直接输入到 Softmax 层,它有三四个或者更多的输出节点 输出
- 图3-8-5中的B图是另一个 Softmax 分类器可以代表的决策边界的例子,用有三个分类的数据集来训练。图3-8-5中的C图也是一个,对吧。
- 但是直觉告诉我们,任何两个分类之间的决策边界都是线性的,这就是为什么你看到比如这里(图3-8-5中的C图的边界线),黄色和红色分类之间的决策边界是线性边界,紫色和红色之间的也是线性边界,紫色和黄色之间的也是线性决策边界,但它能用这些不同的线性函数,来把空间分成三类。
- 我们来看一下更多分类的例子,图3-8-5中的D图中 C 等于4,因此这个绿色分类和 Softmax 仍旧可以代表多种分类之间的这些类型的线性决策边界。图3-8-5中的E图另一个例子是 C 等于5类,图3-8-5中的F图最后一个例子是 C 等于6。
- 这显示了 Softmax 分类器在没有隐藏层的情况下,能够做到的事情。当然,更深的神经网络会有
,然后是一些隐藏单元 以及更多隐藏单元等等,你就可以学习更复杂的非线性决策边界,来区分多种不同分类,我希望你了解了神经网络中的 Softmax 层,或者 Softmax 激活函数有什么作用,下一个视频中 我们来看一下你该怎样训练,一个使用 Softmax 层的神经网络。
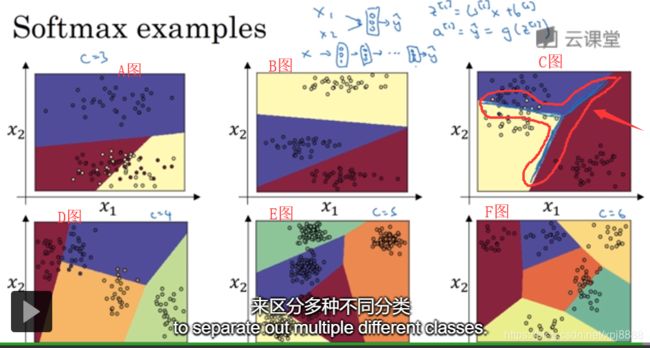
图3-8-5
总结几点:
- 本小结阐述了Softmax分类器,这个分类器相当于一个线性系统,它是一个线性分类器。它将神经网络的输出作为输入,转换为各个类别可能的概率,从而将最大的概率值所对应的类别作为输入样本的输出类别。
- Softmax分类器没有隐藏从层。
- Softmax层称为Softmax激活函数,如图3-8-4所示。
3.9 训练一个Softmax分类器
- 上一个视频中我们学习了 Softmax 层和Softmax 激活函数,在这个视频中 你将更深入地了解 Softmax 分类,并学习如何训练一个使用了 Softmax 层的模型,回忆一下我们之前举的例子,输出层计算出的
,是 Softmax 激活函数,那么输出就会是这样的,简单来说就是用临时变量tt将它归一化,使总和为 1,于是这就变成了
- Softmax 这个名称的来源是与所谓 hard max 对比,hard max 会把向量 z 变成这个向量,hard max 函数会观察 z 的元素,然后在 z 中最大元素的位置放上 1,其他位置放上 0,所以这是一个很硬 (hard) 的 max,也就是最大的元素的输出为 1,其他的输出都为 0,如图3-9-1所示。与之相反, Softmax 所做的从 z 到这些概率的映射更为温和,我不知道这是不是一个好名字,但至少这就是 Softmax 这一名称背后所包含的想法,与 hard max 正好相反,有一点我没有细讲 但之前已经提到过的,就是 Softmax 回归或 Softmax 激活函数,将 logistic 激活函数推广到 C 类 而不仅仅是两类,结果就是如果 C 等于 2 那么 C 等于 2 的 Softmax 实际上变回到了 logistic 回归,我不会在这个视频中给出证明,但是大致的证明思路是这样的,如果 C 等于 2 并且你应用了 Softmax ,那么输出层

图3-9-1
- 接下来我们来看,怎样训练带有 Softmax 输出层的神经网络,具体而言,我们先定义训练神经网络时会用到的损失函数,举个例子,我们来看看训练集中某个样本的目标输出,真实标签是0 1 0 0,用上一个视频中讲到过的例子,这表示这是一张猫的图片 因为它属于类 1,现在我们假设你的神经网络输出的是
,我们来看上面的单个样本,来更好地理解整个过程,注意在这个样本中(图3-9-2的a样本),
,因为这些都是 0,只有
,如果你看这个求和,所有含有值为 0 的
的项都等于 0。
- 最后只剩下
,因为当你按照下标 j 全部加起来,所有的项都为 0 除了 j 等于 2 时,又因为
。这就意味着,如果你的学习算法试图将效益函数变小(图3-9-2的b处),因为梯度下降法是用来减少训练集的损失的,要使效益函数变小的唯一方式就是使
尽可能大,因为这些是概率((图3-9-2的a样本元素都是概率值) 所以不可能比 1 大。但这的确也讲得通,因为在这个例子中 x 是猫的图片,你就需要这项输出的概率尽可能地大,概括来讲 损失函数所做的就是,它找到你的训练集中的真实类别,然后试图使该类别相应的概率尽可能地高,如果你熟悉统计学中的最大似然估计,这其实就是最大似然估计的一种形式。但如果你不知道那是什么意思 也不用担心,用我们刚刚讲过的算法思维也足够了。
- 这是单个训练样本的损失,整个训练集的损失 J 又如何呢,也就是设定参数的代价之类的,还有各种形式的偏差的代价,它的定义你大致也能猜到,就是整个训练集损失的总和,把你的训练算法对所有训练样本的预测都加起来,因此你要做的就是用梯度下降法,使总的训练集的损失最小化(如图3-9-2的c处)。
- 最后还有一个实现细节,注意因为
,是一个4∗1向量,
、
到
的横向排列,这个(图3-9-2的d处)其实就是

图3-9-2

图3-9-3
- 最后我们来看一下,在有 Softmax 输出层时如何实现梯度下降法,这个输出层( 图3-9-4的输出层 )会计算
,我们已经讲了如何实现神经网络前向传播的步骤,来得到这些输出 并计算损失,那么反向传播步骤或者梯度下降法又如何呢?其实初始化反向传播,所需的关键步骤或者说关键方程是这个表达式
,对于最后一层的
的一般定义,这是对于
- 如果你精通微积分 就可以自己推导,或者说如果你精通微积分,可以试着自己推导,但是如果你需要从零开始使用这个公式,它也一样有用,有了这个 你就可以计算
- 这个表达式( 图3-9-4的a处表达式 )值得牢记,如果你需要从头开始,实现 Softmax 回归或者 Softmax 分类,但其实在这周的初级练习中你不会用到它,因为编程框架会帮你搞定导数计算, Softmax 分类就讲到这里,有了它 你就可以运用学习算法,将输入分成不止两类,而是 C 个不同类别,接下来我想向你展示一些深度学习编程框架,可以让你在实现深度学习算法时更加高效,让我们在下个视频中一起讨论。
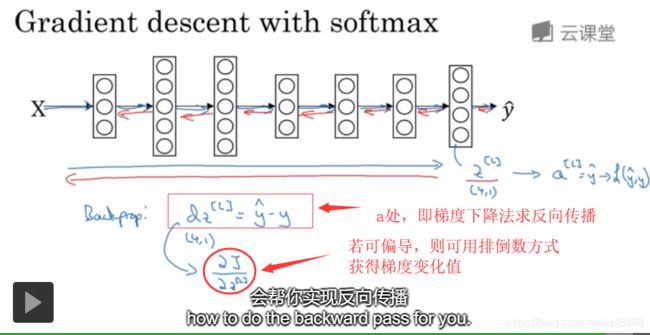
图3-9-4
总结几点:
- TensorFlow深度学习框架,可以自动实现反向传播的计算,只要你正常传播的计数无错误。
- 前传传播要学好,尽可能的用Matlab、Python实现。
- TensorFlow深度学习框架要学习好。
3.10 深度学习框架
- 你已经差不多从零开始学习了,使用 Python 和 NumPy实现深度学习算法,我很高兴你这样做了。 因为我希望你,理解这些深度学习算法实际上在做什么,但是你会发现除非应用更复杂的模型,例如卷积神经网络,或者循环神经网络,或者当你开始应用很大的模型,否则它就越来越不实用了,至少对大多数人而言,从零开始全部靠自己实现并不现实。幸运的是,现在有很多好的深度学习软件框架,可以帮助你实现这些模型。
- 类比一下,我猜你知道如何做矩阵乘法,你还应该知道如何用编程实现两个矩阵相乘。但是当你在建很大的应用时,你很可能不想用你自己的矩阵乘法函数,而是想要访问一个数值线性代数库,它会更高效。但如果你明白两个矩阵相乘是怎么回事,还是挺有用的,我认为现在深度学习已经很成熟了,利用一些深度学习框架会更加实用,会使你的工作更加有效,那就让我们来看一下有哪些框架。
- 如图3-10-1所示,现在有许多深度学习框架,能让实现神经网络变得更简单,我们来讲主要的几个,每个框架都是针对某一个用户或开发者群体的。我觉得这里的每一个框架,都是某类应用的可靠选择,有很多人写文章比较这些深度学习框架,以及这些深度学习框架发展得有多好,而且因为这些框架往往不断进化,每个月都在改进,如果你想看看关于这些框架的优劣之处的讨论,我留给你自己去上网搜索,但我认为很多框架都在很快进步,越来越好。
- 因此我就不做强烈推荐了,而是与你分享推荐一下选择框架的标准。第一个重要标准,就是便于编程,这既包括神经网络的开发和迭代,还包括为产品进行配置,为了成千上百万 甚至上亿用户的实际使用,取决于你想要做什么。第二个重要标准,就是运行速度,特别是训练大数据集时,一些框架能让你更高效地运行和训练神经网络。还有一个标准人们不常提到 ,但我觉得很重要,那就是这个框架是否真的开放,要是一个框架真的开放,它不仅需要开源,而且需要良好的管理。不幸的是,在软件行业中,一些公司有开源软件的历史,但是公司保持着对软件的全权控制,当几年时间过去,人们开始使用他们的软件时,一些公司开始逐渐关闭曾经开放的资源,或者将功能转移到他们专营的云服务中,因此我会注意的一件事就是,你能否相信这个框架能长时间保持开源,而不是在一家公司的控制之下,它未来有可能出于某些原因选择停止开源,即便现在这个软件是以开源的形式发布的。
- 但至少在短期内,取决于你对语言的偏好,看你更喜欢 Python Java还是C++或者其他什么,也取决于你在开发的应用,是计算机视觉 还是自然语言处理,或者线上广告 等等,我认为这里的多个框架都是很好的选择,程序框架就讲到这里,通过提供比数值线性代数库更高程度的抽象化,这里的每一个程序框架都能让你,在开发深度机器学习应用时更高效。
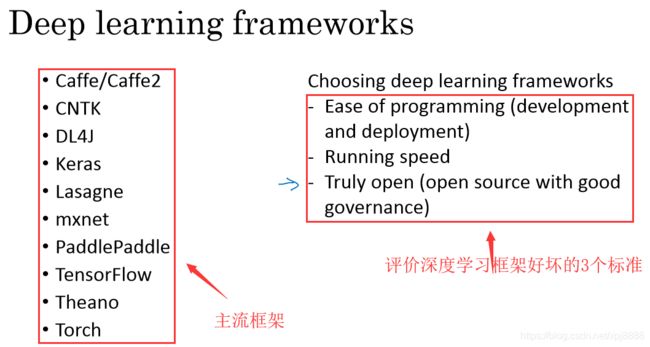
图3-9-5
3.11 TensorFlow
第四周、人工智能行业大师访谈