深度学习之文本分类总结
一、文本分类概况
文本分类是NLP中的最基础的一个任务,很多场景中都涉及到,比如对话机器人、搜索推荐、情绪识别、内容理解,企业风控,质量检测等方向。在对话机器人中,一般的文本分类任务主要是解决 用户query 的意图,确定相关domain.在确定的 domain中进行 NLU的语义理解,进而下游更多的任务。针对 内容理解 或者风控,质检方向都是针对于用户的query进行理解和意图识别,确定是否是涉黄涉爆,等非法的输入,进而进行控制,由于本人主要是做对话NLU 相关的,具体的其他的场景 不做过多叙述,主要分为以下两种情况:
多分类(Multi-Class)
1.二分类, 如邮件垃圾分类,0-1分类,只有两种情况,也可以使用于据识模型中
2.三分类,情感分类,【正面,中立,负面】,情绪识别
3.多分类,意图识别,domain领域识别,新闻类别识别,财经、体育、娱乐等
以上统称为多分类领域,每一个类别是独立的
多标签分类(Multi-Lable)
1.多领域类别,比如说,帮我打开导航、并播放一首歌曲、此时刻的domain 属于 musicX音乐 、mapU 导航领域
2.文本段落,可能即属于金融领域 也属于政治领域
多标签分类,主要的区别是 每一个类别不是独立的,每一个文本可以有多个标签
区别:
1.多分类任务中一条数据只有一个标签,但这个标签可能有多种类别。比如判定某个人的性别,只能归类为"男性"、"女性"其中一个。再比如判断一个文本的情感只能归类为"正面"、"中面"或者"负面"其中一个。
2.多标签分类任务中一条数据可能有多个标签,每个标签可能有两个或者多个类别(一般两个)。例如,一篇新闻可能同时归类为"娱乐"和"运动",也可能只属于"娱乐"或者其它类别。
二、文本分类常见的方法
文本分类主要是分为两种,一种是前几年兴起的 传统的机器学习方案,其次是近几年的深度学习模型(https://github.com/649453932/Chinese-Text-Classification-Pytorch)https://github.com/649453932/Chinese-Text-Classification-Pytorch
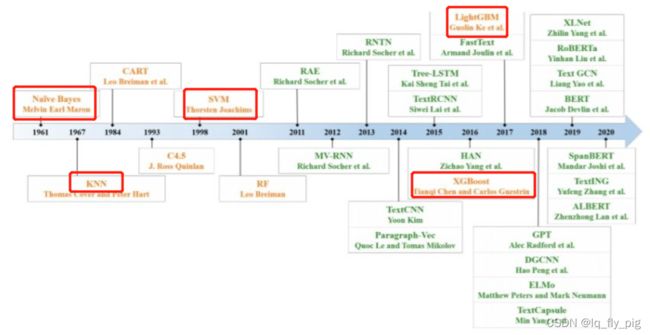
传统的机器学习模型(浅层学习模型)
1.以统计模型占主导,如朴素贝叶斯分类(NB), K近邻(KNN),支持向量机(SVM) 、以及树模型结构 XGBoost和LightGBM
上文提到的模型,与早期的基于规则的方法相比,该方法在准确性和稳定性方面具有明显的优势。但是,这些方法仍然需要进行功能设计,这既耗时又昂贵。此外,它们通常会忽略文本数据中的自然顺序结构或上下文信息,这使学习单词的语义信息变得困难
2.浅层学习模型,词袋子模型,tf-idf统计等
浅层学习模型,主要是忽略掉了文本的语法和语序,用特定的一些符号表示一个文本或者段落。
词袋子模型(BOW)用一组无序的单词序列来表达一段文字或者一个文档, 把整个文档集的所有出现的词都丢进袋子里面,然后 无序去重 地排出来(去掉重复的)。对每一个文档,按照词语出现的次数来表示文档
以下例子(来源于网络):
句子1:我/有/一个/苹果
句子2:我/明天/去/一个/地方
句子3:你/到/一个/地方
句子4:我/有/我/最爱的/你统计所有的词语,放到一个袋子中,得到10个单词: “我,有,一个,苹果,明天,去,地方,你,到,最爱的“

得到4个句子的特征如下:
- 句子 1 特征: ( 1 , 1 , 1 , 1 , 0 , 0 , 0 , 0 , 0 , 0 )
- 句子 2 特征: ( 1 , 0 , 1 , 0 , 1 , 1 , 1 , 0 , 0 , 0 )
- 句子 3 特征: ( 0 , 0 , 1 , 0 , 0 , 0 , 1 , 1 , 1 , 0 )
- 句子 4 特征: ( 2 , 1 , 0 , 0 , 0 , 0 , 0 , 1 , 0 , 1 )
通过以上方案,亦能得到句子的浅层语义表达,可以进行基本的下游任务,如相似度计算,文本分类等任务
缺点就是:语义表达非常稀疏,容易造成维度灾难 只能表示词语本身 ,无法体现单词语义信息,以及单词之间的关系
TF-IDF模型:
主要是使用词汇统计的词频特征来 作为句子的语义表征,TF表示的(Term frequency,词频) IDF 表示的是(Inverse document frequency ) 逆文档频率 。
TF即词频(Term Frequency),每篇文档中关键词的频率(该文档单词/该文档单词总数),TF体现的是词语在文档内部的重要性,举个例子,有两篇文档 ![]() 和
和![]() ,
,
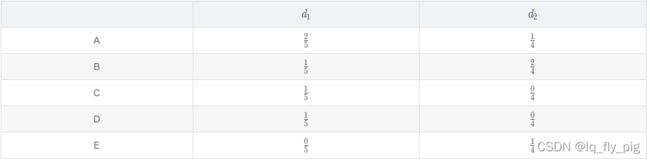
d1 = (A,B,C,D,A),一共是5个单词,d2 = (B,E,A,B), 一共是4个单词。得到如下的TF计算结果:
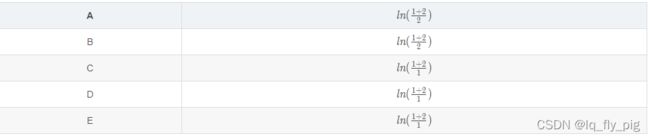
IDF即逆文档频率(Inverse Document Frequency),文档总数/关键词t出现的文档数目,即 ![]() D代表文档的总体数目,分母部分
D代表文档的总体数目,分母部分![]() 表示的是 包括该词语的文档数目,原始公式是分母没有 +1 的,这里是采用了拉普拉斯平滑,避免了有部分新的词没有在语料库中出现而导致分母为零的情况出现。IDF体现的是 词语在文档中的重要性,如果某个词语在 文档中出现的次数越少,表示的 idf 数值越大,越重要。得到如下的,IDF 数值:
表示的是 包括该词语的文档数目,原始公式是分母没有 +1 的,这里是采用了拉普拉斯平滑,避免了有部分新的词没有在语料库中出现而导致分母为零的情况出现。IDF体现的是 词语在文档中的重要性,如果某个词语在 文档中出现的次数越少,表示的 idf 数值越大,越重要。得到如下的,IDF 数值:
d1 文档的向量化表示(最终的结果是 tf * idf):
![]()
后面再通过向量的余弦相似度计算,得到语义的相似度
深度学习模型时代(文本分类模型)
1.Fasttext 模型
论文:https://arxiv.org/abs/1607.01759
代码:https://github.com/facebookresearch/fastText
fastText是Facebook于2016年开源的一个词向量计算和文本分类工具,包含文本分类和词向量训练两个功能。把输入转化为词向量,取平均,再经过线性分类器得到类别。输入的词向量可以是预先训练好的,也可以随机初始化,跟着分类任务一起训练。最终的embedding 也是分类的产物。
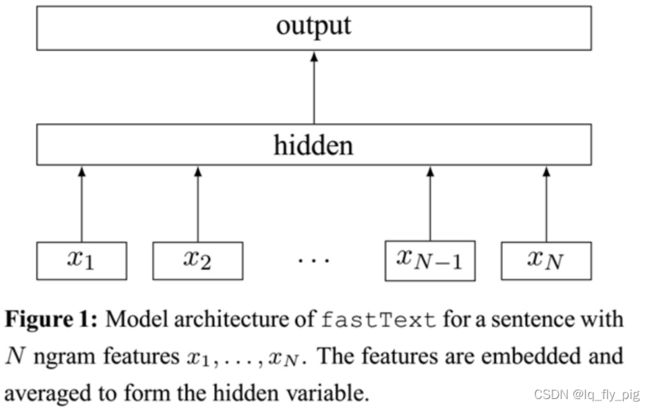
上图为模型结构图,目前多数人也在使用 fastText模型,主要是由于:
1.模型本身比较简单,能快速的产生baseLine
2.采用char-level(字符级别)的 n-gram作为附加特征,这里举个例子,apple 这个单词,bigram 是:[ap,pp,pl,le] ,trigram结果是[app,ppl,ple],最终的模型输入,是把apple转化为embedding 和 bigram 、trigram也转成embedding , 最终拼接一起 作为输入。
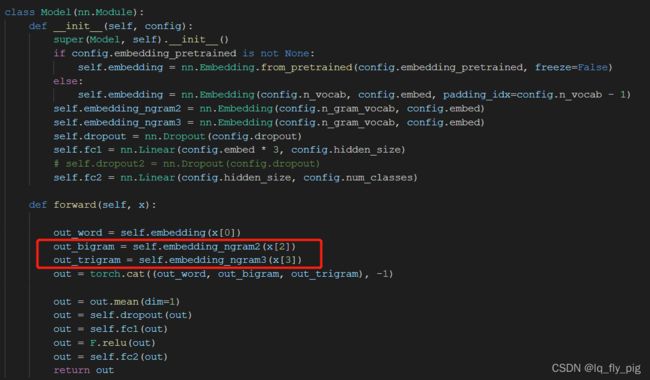
2.TextCNN 模型
TextCNN是Yoon Kim小哥在2014年提出的模型,相关论文和仓库如下:
论文:https://arxiv.org/abs/1408.5882
代码:https://github.com/yoonkim/CNN_sentence
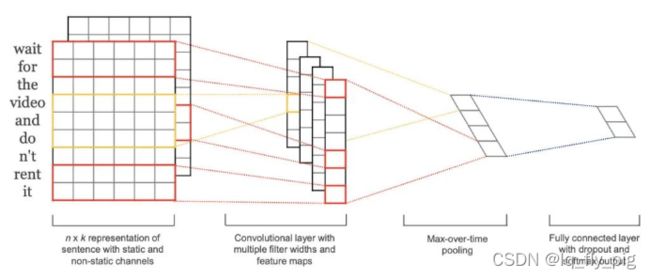
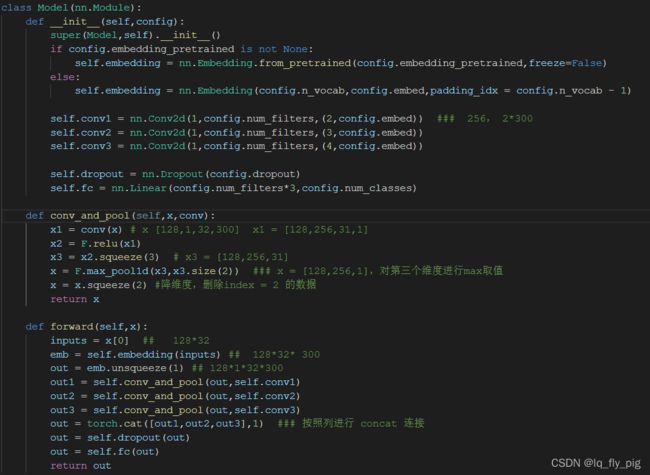
TextCNN 使用的是一维的卷积操作,图像中多数使用的是二维卷积.参考代码如下:
CNN网络结构不清楚的,可以看另一篇Blog,其中有详细的解释CNN网络结构。
大致的步骤如下:
1.输入query 经过embedding 得到,[batch_size,seq_len,embedding_dim]
2.设置卷积核的大小为 [filter_size * embedding_dim],filter_size一般为滑动窗口的大小(先不理解没关系),假设一共有N个卷积核,得到N个长度为,seq_len - filter_size + 1 大小的一维feature_map,比如句子长度为10,filter_size的长度为2,最终得到的feature_map的长度为10-2+1= 9
3. feature_map进行max-pooling 得到N个 1*1的数值,最终为N维向量,作为句子的表达,最终得到 [batch_size,N]的结果,如果 batch_size = 64, N = 256 ,那么最终得到的向量为[64,256]
4.最终结果 经过 全连接网络,线性变化,最后进行softmax分类
相关解释:
卷积核大小为2的时候,一次处理2-gram,也就是2个单词,卷积核大小为3-gram,一次处理三个大小的单词。 所以卷积核在对文本进行卷积的操作,更像是对在提取文本在n-gram上的特征。
取不同卷积核大小进行卷积操作的原因,可以理解为提取这个句子中多个维度不同的信息,使得特征更加的丰富。所以上文中使用了 不同filter_size 的 卷积层 进行 conv1,conv2,conv3来进行提取特征
这个其中有些需要注意的优化的点,可以参考以下博客(一个大神写的):
https://mp.weixin.qq.com/s?__biz=MzAxMTk4NDkwNw==&mid=2247485854&idx=1&sn=040d51b0424bdee66f96d63d4ecfbe7e&chksm=9bb980faacce09ec069afa79c903b1e3a5c0d3679c41092e16b2fdd6949aa059883474d0c2af&token=793481651&lang=zh_CN&scene=21#wechat_redirect
CNN模型主要是 基于上下文token的编码,然后pooling出句子再进行分类,池化时候,max-pooling表现效果最好,文本分类颗粒度比较高,只需要关注部分的关键词即可
3. Rnn+ Attention 模型
论文:https://www.aclweb.org/anthology/P16-2034.pdf
代码:https://github.com/649453932/Chinese-Text-Classification-Pytorch
RNN 模型现在主流的都是LSTM模型、GRU类型的,针对颗粒度比较细的语义表征,需要使用attention进行
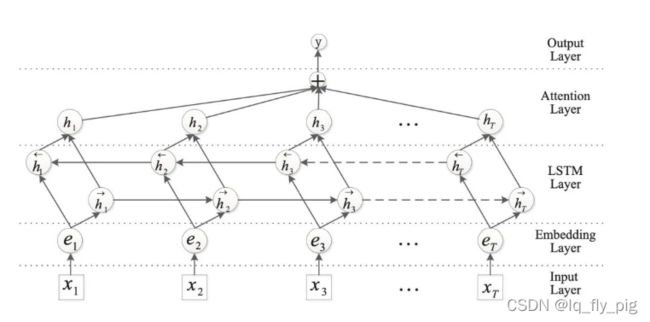
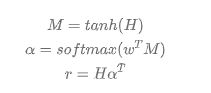
H表示的是LSTM模型输出的 hidden信息,其中 w是context vector,随机初始化并随着训练更新。最后得到句子表示r ,再进行分类。
attention 的作用 主要是 寻找句子中,对句子含义最重要,贡献最大的词语找出来


4. Bert模型
-
不同的预训练模型,比如ELECTRA、RoBERT、WWM、ALBERT
-
除了 [CLS] 外还可以用 avg、max 池化做句表示,也可以各种组合起来
-
在领域数据上增量预训练,结合多任务的预训练
-
Boosting的思想,使用集成蒸馏,训多个大模型集成起来后蒸馏到一个,理论上会有一定的提升(涉及到知识蒸馏)
-
先用多任务训,再迁移到自己的任务
三、文本分类模型实际中遇到的问题(Q&A)
1.模型的选择问题
- 短文本,可以尝试下 TextCNN 模型,fastText模型,作为一个基线baseLine的效果
- 长文本,可以尝试使用RNN 模型,如BiLSTM模型、GRU模型,后接上一个attention注意力机制
无脑使用Bert模型 但是,要是模型上线 还是需要考虑下模型的推理性能,使用模型的知识蒸馏,或者使用多个大模型的集成,再去蒸馏到一个小模型
2.样本类别不均衡问题
样本不均衡问题,对于Nlp任务来说,基本上都是老生常谈的问题,不管是在分类还是NER中经常会出现,针对这些问题的解决办法,网上也是一大堆,知乎博客,到处都是,这里只是做一个简单的整理吧。这里提一点,样本数量不均衡的本质,还是样本难易程度不一样,本质上还是一个 hard example的问题 。通常是两种方案,一个是样本数据上修改(重采样),另一个是train的时候 Loss部分的修改(重加权)
- 重采样
- 欠采样,去掉一些case
- 过采样,可能会导致一些过拟合现象
- 数据增强,非常常用的方案,较为常见的方法为,EDA(增加,删除,同义词替换)、回译、Masked LM(借鉴预训练语言模型(如BERT)中的自编码语言模型,可以启发式地Mask词汇并进行预测替换)、句法交换、SIMBERT 等预训练模型生成相似度句子,等等
- 重加权,重加权就是改变分类loss。相较于重采样,重加权loss更加灵活和方便。其常用方法
- loss类别加权,通常根据类别数量进行加权,加权系数
 与类别数量成反比
与类别数量成反比 - Focal Loss, 上述loss类别加权主要关注正负样本数量的不平衡,并没有关注难易不平衡。Focal Loss主要关注难易样本的不平衡问题,可根据对高置信度(p)样本进行降权
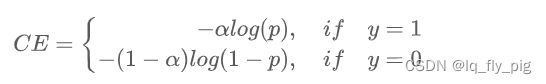 loss类别加权
loss类别加权
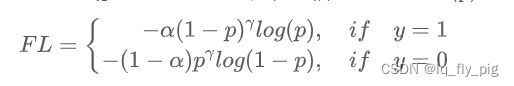 focal loss
focal loss
- loss类别加权,通常根据类别数量进行加权,加权系数
3.数据相关问题
- 任务定义:先和产品定义好场景和分类任务,初略看看数据,是否有些歧义的数据,挑选出来找产品定义好,尽量规避那些歧义的定义说法,不管是去掉该类说法,还是说统一规定为某一个分类label ,总之人都区分不了的问题,别想着让模型去解决
- 数据清洗:
- 标注错误问题,模型测试集错误的case,拿出来,规则筛选一遍,同时检查下训练集中的 case,是否有case标注错误的例子,就是训练集中是否存在同样类似的case,标注存在不一致性。
- 去掉文本强pattern, 很多对文本无意义,出现频次较高的pattern去掉,如,对一段文本进行 意图识别,属于“财经、体育、政治”等Label,文本中出现大量的 xx报道说法,对于文本无意义的说法。
- 大量无标注数据使用(挖掘无标注数据的价值,利用自监督和半监督学习)
- 自监督学习,目前火热的预训练模型(Pre-model) 充分利用无标注数据,展现强大能力,进行任务级别的预训练,如,设计分类任务时候,我们在预训练时候 ,MLM的loss 可以和分类的loss一起 进行多任务学习
- 半监督学习,使用baseLine模型 学习去预测 无标注数据,然后利用数据蒸馏知识生成大量带标签的 数据
4.分类的损失函数选择
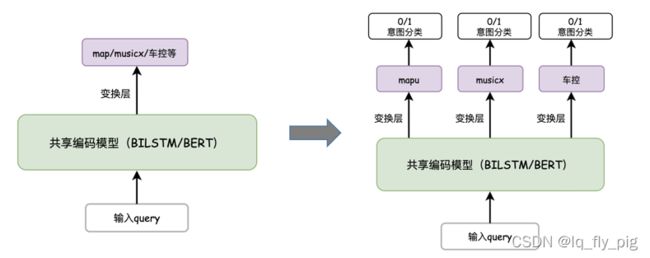
- sigmod分类
- 使用于二分类,类似于常用的0、1分类,Torch版本 是 BCELoss()函数
- softmax分类
- lable标签的多分类,torch版本使用的是 nn.CrossEntropyLoss()函数
由上图所示,对于多分类的任务,可以定义为,多个二分类,如N分类的任务,我们可以定义N个 sigmoid二分类。优点:
1.每个分类domain 单独维护不同的fc解码层,可以后续支持多意图的输出,解码空间相对于之前的softmax 扩大
2.新分类domain增加,维护成本较小,只需要更新 fc层就可以,减少对其他的domain的干扰
3.实际上,每一个domain的fc层,就是一个据识模型,后续可以修改训练策略,灵活的对定义的domain进行据识