bert 源码解读(基于gluonnlp finetune-classifier)
文章目录
- Bert 论文概述
- Bert 模型结构
-
- 总体结构
- attention 结构
- finetune classifier 结构
- Bert 模型源码解析
-
- preprocess_data
- tokenize
- data result
- BERT
-
- embedding
- encoder
-
- BaseTransformerEncoder
- attention
- positionwise_ffn
- 与 transformer 简单比较
Bert 论文概述
bert 是 Pre-training of Deep Bidirectional Transformers for Language Understanding 的缩写,18年10月份Google出的神作,主要思想是:
- 建立双向 Transformer encoder 模型,前期通过大量语料,进行语言模型的训练,得到 pre-trained 的 word embedding
- 随后采用相同的 Transform 模型,进行下游任务(语句分类、语义分析、问答、命名实体识别)的 fine-tune,此时模型需要训练的参数只有 fine-tune 部分的参数,参数数据很少,从而大大减少了下游任务的训练时间;同时刷新了 11 项 NLP 任务的SOTA。
关于BERT论文的解读,此处推荐一篇写的很好的博客,我也从中受益很多。
BERT 原版论文
此文源码解析已整理于 Github – bert source code understand ,包含了全部 bert 代码,可以单步调试进行学习,基本代码跳转不会很乱,不存在函数跳转至其他文件夹下的情况;也可以直接在 repo 中进行源码阅读。
Bert 模型结构
从名字种就可以看出来,BERT 模型的结构事双向 transformer 结构,至于 transformer 就是 Google 的的另一篇论文了:Attention is all you need ,这里不再叙述。
原论文中 bert 结构如下图,:
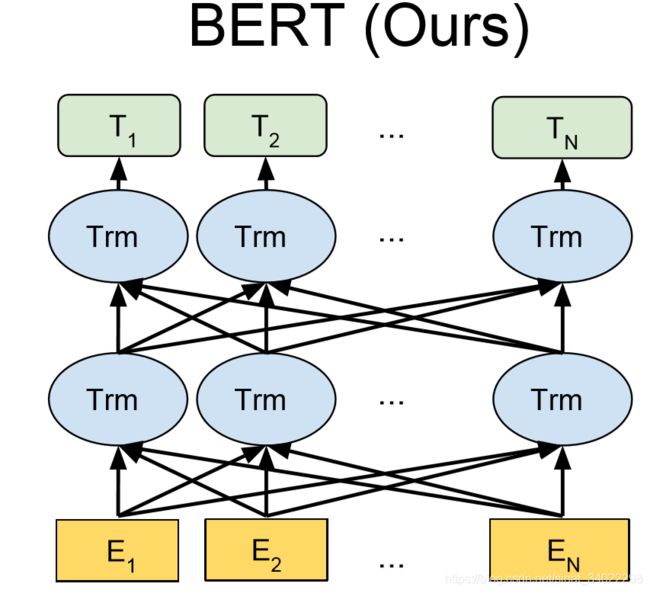 采用了双向的transformer,最下面一行是经过 embedding 之后的模型输入,把语句变为了词向量;随后12层的 transformer 结构,最后输出模型对语言的理解,即 T1, T2… 用来做下游的语言任务。
采用了双向的transformer,最下面一行是经过 embedding 之后的模型输入,把语句变为了词向量;随后12层的 transformer 结构,最后输出模型对语言的理解,即 T1, T2… 用来做下游的语言任务。
bert 子结构 transformer 结构体:
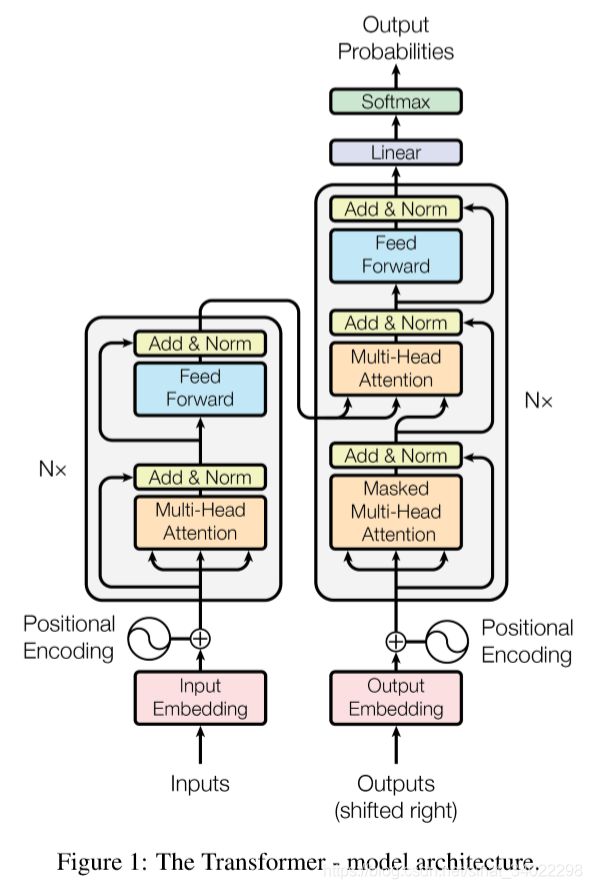 图片左边是 transformer 的 encoder 结构,右边是 decoder ,transformer 这个模型是用来做机器翻译的,使用的是 S2S 模型,所以又 encoder 和 decoder 结构,即先将要翻译的句子进行编码,得到句子语义的编码,随后更具编码结果再进行解码。 BERT 模型只使用了 encoder 结构,所以 bert 的 transfomer 是只有 multi-head attention、LayerNorm、FeedForward 及残差快链接而成。
图片左边是 transformer 的 encoder 结构,右边是 decoder ,transformer 这个模型是用来做机器翻译的,使用的是 S2S 模型,所以又 encoder 和 decoder 结构,即先将要翻译的句子进行编码,得到句子语义的编码,随后更具编码结果再进行解码。 BERT 模型只使用了 encoder 结构,所以 bert 的 transfomer 是只有 multi-head attention、LayerNorm、FeedForward 及残差快链接而成。
使用 netron 工具,进行 mxnet 模型的可视化显示,结果如下:
总体结构
总体结构是12层的 tansformer encoder 结构,因为全局结构图太大,这里这截取一部分,只有两层:

attention 结构
截取了一层 encoder 结构,从中标出了 attention 的各个部分:

finetune classifier 结构
Bert 模型源码解析
由于代码太多,这里把类中、函数中不重要的代码进行省略,使用三行 … 表示有代码省略。
preprocess_data
train_data, dev_data, num_train_examples = preprocess_data(
bert_tokenizer, task, batch_size, dev_batch_size, args.max_len)
data preprocess 是用来生成训练数据集和测试数据集的,处理结果可以查看本节下面的 process result。
def preprocess_data(tokenizer, task, batch_size, dev_batch_size, max_len):
"""Data preparation function."""
# transformation
trans = BERTDatasetTransform(
tokenizer,
max_len,
labels=task.get_labels(),
pad=False,
pair=task.is_pair,
label_dtype='float32' if not task.get_labels() else 'int32')
if task.task_name == 'MNLI':
data_train = task('dev_matched').transform(trans, lazy=False)
data_dev = task('dev_mismatched').transform(trans, lazy=False)
else:
data_train = task('train').transform(trans, lazy=False)
data_dev = task('dev').transform(trans, lazy=False)
data_train_len = data_train.transform(
lambda input_id, length, segment_id, label_id: length)
num_samples_train = len(data_train)
# bucket sampler
batchify_fn = nlp.data.batchify.Tuple(
nlp.data.batchify.Pad(axis=0), nlp.data.batchify.Stack(),
nlp.data.batchify.Pad(axis=0),
nlp.data.batchify.Stack(
'float32' if not task.get_labels() else 'int32'))
batch_sampler = nlp.data.sampler.FixedBucketSampler(
data_train_len,
batch_size=batch_size,
num_buckets=10,
ratio=0,
shuffle=True)
# data loaders
dataloader = gluon.data.DataLoader(
dataset=data_train,
num_workers=1,
batch_sampler=batch_sampler,
batchify_fn=batchify_fn)
dataloader_dev = mx.gluon.data.DataLoader(
data_dev,
batch_size=dev_batch_size,
num_workers=1,
shuffle=False,
batchify_fn=batchify_fn)
return dataloader, dataloader_dev, num_samples_train
基本的逻辑是:
先通过 tokenize 进行分词并生成 tokens --> 通过 BERTDatasetTransform 生成对应 task 需要的数据 --> 进行不同的 bucket 分装 --> train or inference
tokenize
class BERTTokenizer(object):
r"""End-to-end tokenization for BERT models.
Parameters
----------
vocab : gluonnlp.Vocab or None, default None
Vocabulary for the corpus.
lower : bool, default True
whether the text strips accents and convert to lower case.
If you use the BERT pre-training model,
lower is set to Flase when using the cased model,
otherwise it is set to True.
max_input_chars_per_word : int, default 200
Examples
--------
>>> _,vocab = gluonnlp.model.bert_12_768_12(dataset_name='wiki_multilingual',pretrained=False)
>>> tokenizer = gluonnlp.data.BERTTokenizer(vocab=vocab)
>>> tokenizer(u"gluonnlp: 使NLP变得简单。")
['gl', '##uo', '##nn', '##lp', ':', '使', 'nl', '##p', '变', '得', '简', '单', '。']
"""
def __init__(self, vocab, lower=True, max_input_chars_per_word=200):
self.vocab = vocab
self.max_input_chars_per_word = max_input_chars_per_word
self.basic_tokenizer = BERTBasicTokenizer(lower=lower)
def __call__(self, sample):
"""
Parameters
----------
sample: str (unicode for Python 2)
The string to tokenize. Must be unicode.
Returns
-------
ret : list of strs
List of tokens
"""
return self._tokenizer(sample)
def _tokenizer(self, text):
split_tokens = []
for token in self.basic_tokenizer(text):
for sub_token in self._tokenize_wordpiece(token):
split_tokens.append(sub_token)
return split_tokens
def _tokenize_wordpiece(self, text):
"""Tokenizes a piece of text into its word pieces.
This uses a greedy longest-match-first algorithm to perform tokenization
using the given vocabulary.
For example:
input = "unaffable"
output = ["un", "##aff", "##able"]
Args:
text: A single token or whitespace separated tokens. This should have
already been passed through `BERTBasicTokenizer.
Returns:
A list of wordpiece tokens.
"""
...
...
...
def convert_tokens_to_ids(self, tokens):
"""Converts a sequence of tokens into ids using the vocab."""
return self.vocab.to_indices(tokens)
这里BERT分词的代码,从代码注释中可以看到分词的结果如下:
>>> tokenizer = gluonnlp.data.BERTTokenizer(vocab=vocab)
>>> tokenizer(u"gluonnlp: 使NLP变得简单。")
['gl', '##uo', '##nn', '##lp', ':', '使', 'nl', '##p', '变', '得', '简', '单', '。']
代码中调用的是 self._tokenizer(sample) ,把一句话先进行语句级的分割,得到词汇;随后在进行词汇级的分割,得到 tokens ,此时采用的是贪心算法:首次最大长度匹配(感觉以后可以改进一下,贪心算法在这里肯定不是最优的)。
具体做语句级分割的时候,采用的是 BERTBasicTokenizer 分割器,代码如下:
class BERTBasicTokenizer():
r"""Runs basic tokenization
performs invalid character removal (e.g. control chars) and whitespace.
tokenize CJK chars.
splits punctuation on a piece of text.
strips accents and convert to lower case.(If lower is true)
Parameters
----------
lower : bool, default True
whether the text strips accents and convert to lower case.
Examples
--------
>>> tokenizer = gluonnlp.data.BERTBasicTokenizer(lower=True)
>>> tokenizer(u" \tHeLLo!how \n Are yoU? ")
['hello', '!', 'how', 'are', 'you', '?']
>>> tokenizer = gluonnlp.data.BERTBasicTokenizer(lower=False)
>>> tokenizer(u" \tHeLLo!how \n Are yoU? ")
['HeLLo', '!', 'how', 'Are', 'yoU', '?']
"""
def __init__(self, lower=True):
self.lower = lower
def __call__(self, sample):
"""
Parameters
----------
sample: str (unicode for Python 2)
The string to tokenize. Must be unicode.
Returns
-------
ret : list of strs
List of tokens
"""
return self._tokenize(sample)
def _tokenize(self, text):
...
...
...
可以看到,语句级分割就是把一句话分割为单词,这里有 lower 的参数,用来做大小写的开关。
data result
: (
array([ 2, 1996, 2327, 3446, 2097, 2175, 2000, 1018, 1012,
3429, 3867, 2005, 2035, 3901, 2007, 23726, 3468, 29373,
2682, 1002, 3156, 1010, 2199, 1012, 3, 2005, 3901,
2007, 29373, 2682, 1002, 3156, 1010, 2199, 1010, 1996,
3318, 1011, 4171, 3446, 2097, 3623, 2000, 1018, 1012,
3429, 3867, 1012, 3], dtype=int32),
array(49, dtype=int32),
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1], dtype=int32), array([1], dtype=int32)
)
这里只贴出来了单句话的处理结果:
- 第一个 array 是句子的词向量表示;
- 第二个 array 记录了句子有效词汇长度;
- 第三个句子是句子标签(0表示第一个句子,1表示第二个句子);
程序使用 MRPC 数据集进行两个句子语义是否一致的分类问题,所以每个 data sample 是两个句子,不同的任务,数据处理结果不一样。
BERT
Bert 结构基本是 transformer encoder 的堆叠,所以懂了 transformer 基本就懂了 bert。 而 transformer 的核心又在 attention,这里代码学习的流程也基本是按这个逻辑来的,下面一一解读。
先从 BERTModel 来进行代码总流程的学习:
class BERTModel(Block):
"""Model for BERT (Bidirectional Encoder Representations from Transformers).
Parameters
----------
encoder : BERTEncoder
Bidirectional encoder that encodes the input sentence.
vocab_size : int or None, default None
The size of the vocabulary.
token_type_vocab_size : int or None, default None
The vocabulary size of token types.
units : int or None, default None
Number of units for the final pooler layer.
embed_size : int or None, default None
Size of the embedding vectors. It is used to generate the word and token type
embeddings if word_embed and token_type_embed are None.
embed_dropout : float, default 0.0
Dropout rate of the embedding weights. It is used to generate the source and target
embeddings if word_embed and token_type_embed are None.
embed_initializer : Initializer, default None
Initializer of the embedding weights. It is used to generate the source and target
embeddings if word_embed and token_type_embed are None.
word_embed : Block or None, default None
The word embedding. If set to None, word_embed will be constructed using embed_size and
embed_dropout.
token_type_embed : Block or None, default None
The token type embedding. If set to None and the token_type_embed will be constructed using
embed_size and embed_dropout.
use_pooler : bool, default True
Whether to include the pooler which converts the encoded sequence tensor of shape
(batch_size, seq_length, units) to a tensor of shape (batch_size, units)
for segment level classification task.
use_decoder : bool, default True
Whether to include the decoder for masked language model prediction.
use_classifier : bool, default True
Whether to include the classifier for next sentence classification.
prefix : str or None
See document of `mx.gluon.Block`.
params : ParameterDict or None
See document of `mx.gluon.Block`.
Inputs:
- **inputs**: input sequence tensor, shape (batch_size, seq_length)
- **token_types**: input token type tensor, shape (batch_size, seq_length).
If the inputs contain two sequences, then the token type of the first
sequence differs from that of the second one.
- **valid_length**: optional tensor of input sequence valid lengths, shape (batch_size,)
- **masked_positions**: optional tensor of position of tokens for masked LM decoding,
shape (batch_size, num_masked_positions).
Outputs:
- **sequence_outputs**: output tensor of sequence encodings.
Shape (batch_size, seq_length, units).
- **pooled_output**: output tensor of pooled representation of the first tokens.
Returned only if use_pooler is True. Shape (batch_size, units)
- **next_sentence_classifier_output**: output tensor of next sentence classification.
Returned only if use_classifier is True. Shape (batch_size, 2)
- **masked_lm_outputs**: output tensor of sequence decoding for masked language model
prediction. Returned only if use_decoder True.
Shape (batch_size, num_masked_positions, vocab_size)
"""
def __init__(self, encoder, vocab_size=None, token_type_vocab_size=None, units=None,
embed_size=None, embed_dropout=0.0, embed_initializer=None,
word_embed=None, token_type_embed=None, use_pooler=True, use_decoder=True,
use_classifier=True, prefix=None, params=None):
super(BERTModel, self).__init__(prefix=prefix, params=params)
self._use_decoder = use_decoder
self._use_classifier = use_classifier
self._use_pooler = use_pooler
self.encoder = encoder
# Construct word embedding
self.word_embed = self._get_embed(word_embed, vocab_size, embed_size,
embed_initializer, embed_dropout, 'word_embed_')
# Construct token type embedding
self.token_type_embed = self._get_embed(token_type_embed, token_type_vocab_size,
embed_size, embed_initializer, embed_dropout,
'token_type_embed_')
if self._use_pooler:
# Construct pooler
self.pooler = self._get_pooler(units, 'pooler_')
if self._use_classifier:
# Construct classifier for next sentence predicition
self.classifier = self._get_classifier('cls_')
else:
assert not use_classifier, 'Cannot use classifier if use_pooler is False'
if self._use_decoder:
# Construct decoder for masked language model
self.decoder = self._get_decoder(units, vocab_size, self.word_embed[0], 'decoder_')
def _get_classifier(self, prefix):
""" Construct a decoder for the masked language model task """
with self.name_scope():
classifier = nn.Dense(2, prefix=prefix)
return classifier
def _get_decoder(self, units, vocab_size, embed, prefix):
...
...
...
return decoder
def _get_embed(self, embed, vocab_size, embed_size, initializer, dropout, prefix):
""" Construct an embedding block. """
if embed is None:
assert embed_size is not None, '"embed_size" cannot be None if "word_embed" or ' \
'token_type_embed is not given.'
with self.name_scope():
embed = nn.HybridSequential(prefix=prefix)
with embed.name_scope():
embed.add(nn.Embedding(input_dim=vocab_size, output_dim=embed_size,
weight_initializer=initializer))
if dropout:
embed.add(nn.Dropout(rate=dropout))
assert isinstance(embed, Block)
return embed
def _get_pooler(self, units, prefix):
""" Construct pooler.
The pooler slices and projects the hidden output of first token
in the sequence for segment level classification.
"""
with self.name_scope():
pooler = nn.Dense(units=units, flatten=False, activation='tanh',
prefix=prefix)
return pooler
def forward(self, inputs, token_types, valid_length=None, masked_positions=None): # pylint: disable=arguments-differ
"""Generate the representation given the inputs.
This is used in training or fine-tuning a BERT model.
"""
outputs = []
seq_out, _ = self._encode_sequence(inputs, token_types, valid_length)
outputs.append(seq_out)
if self._use_pooler:
pooled_out = self._apply_pooling(seq_out)
outputs.append(pooled_out)
if self._use_classifier:
next_sentence_classifier_out = self.classifier(pooled_out)
outputs.append(next_sentence_classifier_out)
if self._use_decoder:
assert masked_positions is not None, \
'masked_positions tensor is required for decoding masked language model'
decoder_out = self._decode(seq_out, masked_positions)
outputs.append(decoder_out)
return tuple(outputs) if len(outputs) > 1 else outputs[0]
def _encode_sequence(self, inputs, token_types, valid_length=None):
"""Generate the representation given the input sequences.
This is used for pre-training or fine-tuning a BERT model.
"""
# embedding
word_embedding = self.word_embed(inputs)
type_embedding = self.token_type_embed(token_types)
embedding = word_embedding + type_embedding
# encoding
outputs, additional_outputs = self.encoder(embedding, None, valid_length)
return outputs, additional_outputs
def _apply_pooling(self, sequence):
"""Generate the representation given the inputs.
This is used for pre-training or fine-tuning a BERT model.
"""
outputs = sequence[:, 0, :]
return self.pooler(outputs)
def _decode(self, sequence, masked_positions):
...
...
...
return decoded
该类定义初始化都是给各个成员变量进行赋值,这里包括:
self._use_decoder 、self._use_classifier 、self._use_pooler、self.encoder = encoder、word_embed = self._get_embed、self.token_type_embed 等。
mxnet 自定义的模型进行前向传播的时候,其实是在运行 forword函数,所以代码要从 forward 开始看:
- 调用 self._encode_sequence,返回结果 seq_out;
- 判断是否进行 pool 、classifier 和 decoder,对 seq_out 进行相对处理;
- 将处理后的结果进行输出;
这里可以看出,forward 的设计比较简单,依然保留有 decoder 接口,主要工作是在 self._encode_sequence 中进行,接着看这个函数:
- 进行 word_embedding 和 type_embedding
- 将二者进行相加,随后送入 bert 的 self.encoder 里面进行处理
- 得到输出,返回结果
这里可以看到 BERTModel 暴露给我们的只有 embedding,主要工作还是在 encoder 核中进行的。
embedding
下面是 embedding 的代码,也可以看出来, embedding 是通过传参给 nn.embedding 来进行的:
# Construct word embedding
self.word_embed = self._get_embed(word_embed, vocab_size, embed_size, embed_initializer,
embed_dropout, 'word_embed_')
# Construct token type embedding
self.token_type_embed = self._get_embed(token_type_embed, token_type_vocab_size,
embed_size, embed_initializer, embed_dropout, 'token_type_embed_')
# embedding
word_embedding = self.word_embed(inputs)
type_embedding = self.token_type_embed(token_types)
embedding = word_embedding + type_embedding
# encoding
outputs, additional_outputs = self.encoder(embedding, None, valid_length)
return outputs, additional_outputs
def _get_embed(self, embed, vocab_size, embed_size, initializer, dropout, prefix):
""" Construct an embedding block. """
if embed is None:
assert embed_size is not None, '"embed_size" cannot be None if "word_embed" or ' \
'token_type_embed is not given.'
with self.name_scope():
embed = nn.HybridSequential(prefix=prefix)
with embed.name_scope():
embed.add(nn.Embedding(input_dim=vocab_size, output_dim=embed_size,
weight_initializer=initializer))
if dropout:
embed.add(nn.Dropout(rate=dropout))
assert isinstance(embed, Block)
return embed
encoder
在上面 BERTModel 中的 调用 self._encode_sequence 可以看到,数据在进行了 embedding 之后,会送入 encoder 中,得到输出,这个是整个模型的核心,基本架构继承自 transformer 。这里以标准 bert_12_768_12 为例,BERTEncoder 参数全部来自与 bert_12_768_12 的配置,如下:
predefined_args = bert_hparams[model_name]
# encoder
encoder = BERTEncoder(attention_cell=predefined_args['attention_cell'],
num_layers=predefined_args['num_layers'],
units=predefined_args['units'],
hidden_size=predefined_args['hidden_size'],
max_length=predefined_args['max_length'],
num_heads=predefined_args['num_heads'],
scaled=predefined_args['scaled'],
dropout=predefined_args['dropout'],
use_residual=predefined_args['use_residual'])
bert_12_768_12_hparams = {
'attention_cell': 'multi_head',
'num_layers': 12,
'units': 768,
'hidden_size': 3072,
'max_length': 512,
'num_heads': 12,
'scaled': True,
'dropout': 0.1,
'use_residual': True,
'embed_size': 768,
'embed_dropout': 0.1,
'token_type_vocab_size': 2,
'word_embed': None,
}
class BERTEncoder(BaseTransformerEncoder):
"""Structure of the BERT Encoder.
Different from the original encoder for transformer,
`BERTEncoder` uses learnable positional embedding, `BERTPositionwiseFFN`
and `BERTLayerNorm`.
Parameters
----------
attention_cell : AttentionCell or str, default 'multi_head'
Arguments of the attention cell.
Can be 'multi_head', 'scaled_luong', 'scaled_dot', 'dot', 'cosine', 'normed_mlp', 'mlp'
num_layers : int
Number of attention layers.
units : int
Number of units for the output.
hidden_size : int
number of units in the hidden layer of position-wise feed-forward networks
max_length : int
Maximum length of the input sequence
num_heads : int
Number of heads in multi-head attention
scaled : bool
Whether to scale the softmax input by the sqrt of the input dimension
in multi-head attention
dropout : float
Dropout probability of the attention probabilities.
use_residual : bool
output_attention: bool
Whether to output the attention weights
weight_initializer : str or Initializer
Initializer for the input weights matrix, used for the linear
transformation of the inputs.
bias_initializer : str or Initializer
Initializer for the bias vector.
prefix : str, default None.
Prefix for name of `Block`s. (and name of weight if params is `None`).
params : Parameter or None
Container for weight sharing between cells. Created if `None`.
Inputs:
- **inputs** : input sequence of shape (batch_size, length, C_in)
- **states** : list of tensors for initial states and masks.
- **valid_length** : valid lengths of each sequence. Usually used when part of sequence
has been padded. Shape is (batch_size, )
Outputs:
- **outputs** : the output of the encoder. Shape is (batch_size, length, C_out)
- **additional_outputs** : list of tensors.
Either be an empty list or contains the attention weights in this step.
The attention weights will have shape (batch_size, num_heads, length, mem_length)
"""
def __init__(self, attention_cell='multi_head', num_layers=2,
units=512, hidden_size=2048, max_length=50,
num_heads=4, scaled=True, dropout=0.0,
use_residual=True, output_attention=False,
weight_initializer=None, bias_initializer='zeros',
prefix=None, params=None):
super(BERTEncoder, self).__init__(attention_cell=attention_cell,
num_layers=num_layers, units=units,
hidden_size=hidden_size, max_length=max_length,
num_heads=num_heads, scaled=scaled, dropout=dropout,
use_residual=use_residual,
output_attention=output_attention,
weight_initializer=weight_initializer,
bias_initializer=bias_initializer,
prefix=prefix, params=params,
# extra configurations for BERT
positional_weight='learned',
use_bert_encoder=True,
use_layer_norm_before_dropout=False,
scale_embed=False)
BaseTransformerEncoder
class BaseTransformerEncoder(HybridBlock, Seq2SeqEncoder):
"""Base Structure of the Transformer Encoder.
Parameters
----------
attention_cell : AttentionCell or str, default 'multi_head'
Arguments of the attention cell.
Can be 'multi_head', 'scaled_luong', 'scaled_dot', 'dot', 'cosine', 'normed_mlp', 'mlp'
num_layers : int
Number of attention layers.
units : int
Number of units for the output.
hidden_size : int
number of units in the hidden layer of position-wise feed-forward networks
max_length : int
Maximum length of the input sequence
num_heads : int
Number of heads in multi-head attention
scaled : bool
Whether to scale the softmax input by the sqrt of the input dimension
in multi-head attention
dropout : float
Dropout probability of the attention probabilities.
use_residual : bool
output_attention: bool
Whether to output the attention weights
weight_initializer : str or Initializer
Initializer for the input weights matrix, used for the linear
transformation of the inputs.
bias_initializer : str or Initializer
Initializer for the bias vector.
positional_weight: str, default 'sinusoidal'
Type of positional embedding. Can be 'sinusoidal', 'learned'.
If set to 'sinusoidal', the embedding is initialized as sinusoidal values and keep constant.
use_bert_encoder : bool, default False
Whether to use BERTEncoderCell and BERTLayerNorm. Set to True for pre-trained BERT model
use_layer_norm_before_dropout: bool, default False
Before passing embeddings to attention cells, whether to perform `layernorm -> dropout` or
`dropout -> layernorm`. Set to True for pre-trained BERT models.
scale_embed : bool, default True
Scale the input embeddings by sqrt(embed_size). Set to False for pre-trained BERT models.
prefix : str, default 'rnn_'
Prefix for name of `Block`s
(and name of weight if params is `None`).
params : Parameter or None
Container for weight sharing between cells.
Created if `None`.
"""
def __init__(self, attention_cell='multi_head', num_layers=2,
units=512, hidden_size=2048, max_length=50,
num_heads=4, scaled=True, dropout=0.0,
use_residual=True, output_attention=False,
weight_initializer=None, bias_initializer='zeros',
positional_weight='sinusoidal', use_bert_encoder=False,
use_layer_norm_before_dropout=False, scale_embed=True,
prefix=None, params=None):
super(BaseTransformerEncoder, self).__init__(prefix=prefix, params=params)
assert units % num_heads == 0, \
'In TransformerEncoder, The units should be divided exactly ' \
'by the number of heads. Received units={}, num_heads={}' \
.format(units, num_heads)
self._num_layers = num_layers
self._max_length = max_length
self._num_heads = num_heads
self._units = units
self._hidden_size = hidden_size
self._output_attention = output_attention
self._dropout = dropout
self._use_residual = use_residual
self._scaled = scaled
self._use_layer_norm_before_dropout = use_layer_norm_before_dropout
self._scale_embed = scale_embed
with self.name_scope():
self.dropout_layer = nn.Dropout(dropout)
self.layer_norm = _get_layer_norm(use_bert_encoder, units)
self.position_weight = self._get_positional(positional_weight, max_length, units,
weight_initializer)
self.transformer_cells = nn.HybridSequential()
for i in range(num_layers):
cell = self._get_encoder_cell(use_bert_encoder, units, hidden_size, num_heads,
attention_cell, weight_initializer, bias_initializer,
dropout, use_residual, scaled, output_attention, i)
self.transformer_cells.add(cell)
def _get_positional(self, weight_type, max_length, units, initializer):
if weight_type == 'sinusoidal':
encoding = _position_encoding_init(max_length, units)
position_weight = self.params.get_constant('const', encoding)
elif weight_type == 'learned':
position_weight = self.params.get('position_weight', shape=(max_length, units),
init=initializer)
else:
raise ValueError('Unexpected value for argument position_weight: %s' % (position_weight))
return position_weight
def _get_encoder_cell(self, use_bert, units, hidden_size, num_heads, attention_cell,
weight_initializer, bias_initializer, dropout, use_residual,
scaled, output_attention, i):
from bert_func import BERTEncoderCell
cell = BERTEncoderCell if use_bert else TransformerEncoderCell
return cell(units=units, hidden_size=hidden_size,
num_heads=num_heads, attention_cell=attention_cell,
weight_initializer=weight_initializer,
bias_initializer=bias_initializer,
dropout=dropout, use_residual=use_residual,
scaled=scaled, output_attention=output_attention,
prefix='transformer%d_' % i)
def __call__(self, inputs, states=None, valid_length=None): # pylint: disable=arguments-differ
"""Encoder the inputs given the states and valid sequence length.
Parameters
----------
inputs : NDArray
Input sequence. Shape (batch_size, length, C_in)
states : list of NDArrays or None
Initial states. The list of initial states and masks
valid_length : NDArray or None
Valid lengths of each sequence. This is usually used when part of sequence has
been padded. Shape (batch_size,)
Returns
-------
encoder_outputs: list
Outputs of the encoder. Contains:
- outputs of the transformer encoder. Shape (batch_size, length, C_out)
- additional_outputs of all the transformer encoder
"""
return super(BaseTransformerEncoder, self).__call__(inputs, states, valid_length)
def forward(self, inputs, states=None, valid_length=None, steps=None): # pylint: disable=arguments-differ
"""
Parameters
----------
inputs : NDArray, Shape(batch_size, length, C_in)
states : list of NDArray
valid_length : NDArray
steps : NDArray
Stores value [0, 1, ..., length].
It is used for lookup in positional encoding matrix
Returns
-------
outputs : NDArray
The output of the encoder. Shape is (batch_size, length, C_out)
additional_outputs : list
Either be an empty list or contains the attention weights in this step.
The attention weights will have shape (batch_size, length, length) or
(batch_size, num_heads, length, length)
"""
length = inputs.shape[1]
if valid_length is not None:
mask = mx.nd.broadcast_lesser(
mx.nd.arange(length, ctx=valid_length.context).reshape((1, -1)),
valid_length.reshape((-1, 1)))
mask = mx.nd.broadcast_axes(mx.nd.expand_dims(mask, axis=1), axis=1, size=length)
if states is None:
states = [mask]
else:
states.append(mask)
if self._scale_embed:
inputs = inputs * math.sqrt(inputs.shape[-1])
steps = mx.nd.arange(length, ctx=inputs.context)
if states is None:
states = [steps]
else:
states.append(steps)
if valid_length is not None:
step_output, additional_outputs = \
super(BaseTransformerEncoder, self).forward(inputs, states, valid_length)
else:
step_output, additional_outputs = \
super(BaseTransformerEncoder, self).forward(inputs, states)
return step_output, additional_outputs
def hybrid_forward(self, F, inputs, states=None, valid_length=None, position_weight=None):
# pylint: disable=arguments-differ
"""
Parameters
----------
inputs : NDArray or Symbol, Shape(batch_size, length, C_in)
states : list of NDArray or Symbol
valid_length : NDArray or Symbol
position_weight : NDArray or Symbol
Returns
-------
outputs : NDArray or Symbol
The output of the encoder. Shape is (batch_size, length, C_out)
additional_outputs : list
Either be an empty list or contains the attention weights in this step.
The attention weights will have shape (batch_size, length, length) or
(batch_size, num_heads, length, length)
"""
if states is not None:
steps = states[-1]
# Positional Encoding
positional_embed = F.Embedding(steps, position_weight, self._max_length, self._units)
inputs = F.broadcast_add(inputs, F.expand_dims(positional_embed, axis=0))
if self._use_layer_norm_before_dropout:
inputs = self.layer_norm(inputs)
inputs = self.dropout_layer(inputs)
else:
inputs = self.dropout_layer(inputs)
inputs = self.layer_norm(inputs)
outputs = inputs
if valid_length is not None:
mask = states[-2]
else:
mask = None
additional_outputs = []
for cell in self.transformer_cells:
outputs, attention_weights = cell(inputs, mask)
inputs = outputs
if self._output_attention:
additional_outputs.append(attention_weights)
if valid_length is not None:
outputs = F.SequenceMask(outputs, sequence_length=valid_length,
use_sequence_length=True, axis=1)
return outputs, additional_outputs
def _get_layer_norm(use_bert, units):
from bert_func import BERTLayerNorm
layer_norm = BERTLayerNorm if use_bert else nn.LayerNorm
return layer_norm(in_channels=units)
def _position_encoding_init(max_length, dim):
"""Init the sinusoid position encoding table """
position_enc = np.arange(max_length).reshape((-1, 1)) \
/ (np.power(10000, (2. / dim) * np.arange(dim).reshape((1, -1))))
# Apply the cosine to even columns and sin to odds.
position_enc[:, 0::2] = np.sin(position_enc[:, 0::2]) # dim 2i
position_enc[:, 1::2] = np.cos(position_enc[:, 1::2]) # dim 2i+1
return position_enc
def _get_attention_cell(attention_cell, units=None,
scaled=True, num_heads=None,
use_bias=False, dropout=0.0):
"""
Parameters
----------
attention_cell : AttentionCell or str
units : int or None
Returns
-------
attention_cell : AttentionCell
"""
if isinstance(attention_cell, str):
if attention_cell == 'scaled_luong':
return DotProductAttentionCell(units=units, scaled=True, normalized=False,
use_bias=use_bias, dropout=dropout, luong_style=True)
elif attention_cell == 'scaled_dot':
return DotProductAttentionCell(units=units, scaled=True, normalized=False,
use_bias=use_bias, dropout=dropout, luong_style=False)
elif attention_cell == 'dot':
return DotProductAttentionCell(units=units, scaled=False, normalized=False,
use_bias=use_bias, dropout=dropout, luong_style=False)
elif attention_cell == 'cosine':
return DotProductAttentionCell(units=units, scaled=False, use_bias=use_bias,
dropout=dropout, normalized=True)
elif attention_cell == 'mlp':
return MLPAttentionCell(units=units, normalized=False)
elif attention_cell == 'normed_mlp':
return MLPAttentionCell(units=units, normalized=True)
elif attention_cell == 'multi_head':
base_cell = DotProductAttentionCell(scaled=scaled, dropout=dropout)
return MultiHeadAttentionCell(base_cell=base_cell, query_units=units, use_bias=use_bias,
key_units=units, value_units=units, num_heads=num_heads)
else:
raise NotImplementedError
else:
assert isinstance(attention_cell, AttentionCell),\
'attention_cell must be either string or AttentionCell. Received attention_cell={}'\
.format(attention_cell)
return attention_cell
attention
WIP
positionwise_ffn
WIP
与 transformer 简单比较
WIP