Pytorch深度学习实践 第十二讲 循环神经网络(基础篇)
循环神经网络RNN:用来处理有序列关系的输入,比如预测天气时,今天的天气要依赖于上一天的天气数据,多用于天气、股票、自然语言处理等。

RNN Cell结构
所有的RNN Cell是同一个Linear模块,只不过是循环使用它对不同的输入序列来进行计算和更新权重,循环次数就是序列长度:
初始化H0=0,是个向量
for Xi in X:
Hi = Linear(Xi, Hi-1)

torch.nn.RNNCell()模块


seqLen是序列长度,即x1~x3
inputSize是每个x的特征维度
hiddenSize是隐层维度,即得到的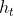 的维度
的维度
示例代码:
import torch
"需要:初始化h0,输入序列"
batch_size = 1
input_size = 4
hidden_size = 2
seq_len = 3
cell = torch.nn.RNNCell(input_size=input_size, hidden_size = hidden_size)
dataset = torch.randn(seq_len,batch_size,input_size) #构造输入序列
hidden = torch.zeros(batch_size, hidden_size) #构造全是0的隐层,即初始化h0
for idex,input in enumerate(dataset):
print('='*20, idex, '='*20)
print('Input size:',input.shape)
hidden = cell(input,hidden)
print('outputs size:',hidden.shape)
print('hidden:', hidden)输出:
==================== 0 ====================
Input size: torch.Size([1, 4])
outputs size: torch.Size([1, 2])
hidden: tensor([[ 0.9321, -0.8409]], grad_fn=)
==================== 1 ====================
Input size: torch.Size([1, 4])
outputs size: torch.Size([1, 2])
hidden: tensor([[-0.5605, -0.9525]], grad_fn=)
==================== 2 ====================
Input size: torch.Size([1, 4])
outputs size: torch.Size([1, 2])
hidden: tensor([[ 0.7112, -0.0875]], grad_fn=) torch.nn.RNN()模块

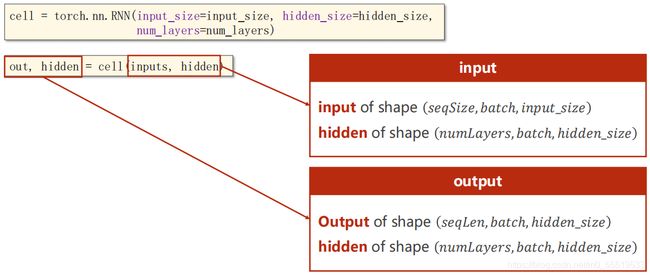

当numLayers=3时:

示例代码:
import torch
batch_size = 1
input_size = 4
hidden_size = 2
seq_len = 3
num_layers = 2
cell = torch.nn.RNN(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers)
inputs = torch.randn(seq_len, batch_size, input_size)
hidden = torch.zeros(num_layers, batch_size, hidden_size)
out,hidden = cell(inputs,hidden)
print('output size:', out.shape)
print('out:',out)
print('hidden size:',hidden.shape)
print('hidden:', hidden)输出:
output size: torch.Size([3, 1, 2])
out: tensor([[[-0.6508, -0.3297]],
[[-0.5962, -0.0341]],
[[-0.7208, 0.0275]]], grad_fn=)
hidden size: torch.Size([2, 1, 2])
hidden: tensor([[[ 0.5388, -0.7976]],
[[-0.7208, 0.0275]]], grad_fn=)
Process finished with exit code 0
如果torch.nn.RNN()中batch_first=Ture,则将batch_size放在首位:

RNNCell和RNN总结:
1.变量维度上:
| shape | RNNCell | RNN |
| input | (batch_size,input_size) | (seqlen,batch_size,input_size) |
| output | (batch_size,hidden_size) | (seqlen,batch_size,hidden_size) |
| hidden | (batch_size,hidden_size) | (numLayers,batch_size,hidden_size) |
| dataset | (seqlen,batch_size,input_size) | (seqlen,batch_size,input_size) |
2.参数设置上:
cell = torch.nn.RNNCell(input_size = _,hidden_size = _)
cell = torch.nn,RNN(input_size = _,hidden_size = _, num_layers = _)
通过RNNCell学习序列“hello”→“ohlol”转换的规律:

序列预处理,将输入序列转换成One-hot向量每行中indices对应的索引位置是1,其他位置均为0:
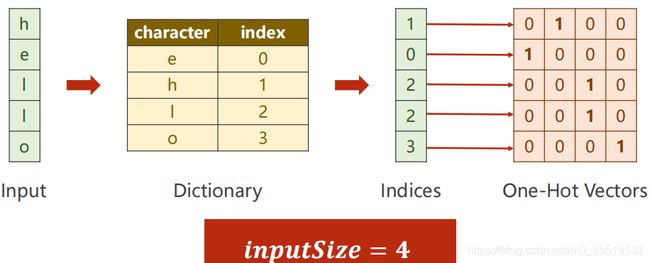
共四个字符即四个类别,最终预测一个分类问题,即每个字符分到4个类别的概率值,取最大的概率值就是预测结果:
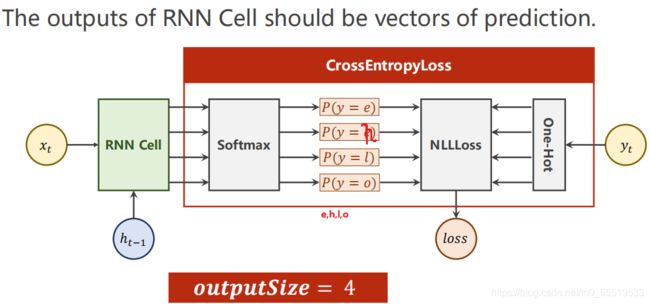
示例代码:
import torch
batch_size = 1
input_size = 4
hidden_size = 4
#准备数据
idx2char = ['e','h','l','o']
x_data = [1,0,2,2,3] #hello
y_data = [3,1,2,3,2] #ohlol
one_hot_lookup = [[1,0,0,0],
[0,1,0,0],
[0,0,1,0],
[0,0,0,1]] #分别对应0,1,2,3即e,h,l,o
x_one_hot = [one_hot_lookup[x] for x in x_data] #组成序列张量
print('x_one_hot:',x_one_hot)
#构造输入序列和标签
inputs = torch.Tensor(x_one_hot).view(-1,batch_size,input_size) #-1即seqLen
labels = torch.LongTensor(y_data).view(-1,1) #(seqLen,1)
class Model(torch.nn.Module):
def __init__(self, input_size, hidden_size, batch_size):
super(Model, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.batch_size = batch_size
self.rnncell = torch.nn.RNNCell(input_size=self.input_size, hidden_size=self.hidden_size)
def forward(self, input, hidden):
hidden = self.rnncell(input, hidden)
return hidden
def init_hidden(self):
'''构造h0'''
return torch.zeros(self.batch_size, self.hidden_size)
net = Model(input_size, hidden_size, batch_size)
critirion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.1)
for epoch in range(15):
loss = 0
optimizer.zero_grad()
hidden = net.init_hidden() #h0
print('predicted string:', end='')
for input,label in zip(inputs,labels):
'依次遍历序列中的每个rnncell块'
hidden = net(input, hidden)
loss += critirion(hidden,label)
_, idx = hidden.max(dim=1) #hidden是4维的,分别表示e,h,l,o的概率值
print(idx2char[idx.item()], end='')
loss.backward()
optimizer.step()
print(',epoch [%d/15] loss=%.4f' % (epoch+1, loss.item()))输出结果:
x_one_hot: [[0, 1, 0, 0], [1, 0, 0, 0], [0, 0, 1, 0], [0, 0, 1, 0], [0, 0, 0, 1]]
predicted string:ooooo,epoch [1/15] loss=6.9857
predicted string:ooooo,epoch [2/15] loss=5.8185
predicted string:ololo,epoch [3/15] loss=5.1750
predicted string:ololl,epoch [4/15] loss=4.7768
predicted string:ololl,epoch [5/15] loss=4.5013
predicted string:ololl,epoch [6/15] loss=4.2760
predicted string:ololl,epoch [7/15] loss=4.0657
predicted string:ololl,epoch [8/15] loss=3.8786
predicted string:oholl,epoch [9/15] loss=3.7131
predicted string:oholl,epoch [10/15] loss=3.5614
predicted string:oholl,epoch [11/15] loss=3.4337
predicted string:oholl,epoch [12/15] loss=3.3326
predicted string:oholl,epoch [13/15] loss=3.2430
predicted string:oholl,epoch [14/15] loss=3.1818
predicted string:oholl,epoch [15/15] loss=3.1441
通过RNN学习序列“hello”→“ohlol”转换的规律:
示例代码:
import torch
batch_size = 1
input_size = 4
hidden_size = 4
num_layers = 1
seq_len = 5
idx2char = ['e', 'h', 'l', 'o']
x_data = [1,0,2,2,3] #hello
y_data = [3,1,2,3,2] #ohlol
one_hot_lookup = [[1,0,0,0],
[0,1,0,0],
[0,0,1,0],
[0,0,0,1]]
x_one_hot = [one_hot_lookup[x] for x in x_data]
inputs = torch.Tensor(x_one_hot).view(seq_len, batch_size, input_size)
labels = torch.LongTensor(y_data) #(seqlen×batchsize,1)
class Model(torch.nn.Module):
def __init__(self, input_size, hidden_size, batch_size, num_layers):
super(Model, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.batch_size = batch_size
self.num_layers = num_layers
self.rnn = torch.nn.RNN(self.input_size, self.hidden_size, self.num_layers)
def forward(self,input):
hidden = torch.zeros(self.num_layers, self.batch_size, self.hidden_size)
out,_ = self.rnn(input, hidden)
return out.view(-1,self.hidden_size) #rashpe out to (seq_len×batch_size, hiddensize)
net = Model(input_size, hidden_size, batch_size, num_layers)
critirion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.05)
for epoch in range(15):
optimizer.zero_grad()
outputs = net(inputs)
loss = critirion(outputs, labels)
loss.backward()
optimizer.step()
print('outputs:',outputs)
_,idx = outputs.max(dim=1)
idx = idx.data.numpy() #reshape to numpy
print('idx',idx)
print('Pridected:', ''.join([idx2char[x] for x in idx]), end='') #end是不自动换行,''.join是连接字符串数组
print(',Epoch [%d/15] loss = %.3f' % (epoch+1,loss.item()))
Embedding
One-hot矩阵是高维、稀疏的,通过Embedding将one-hot稀疏矩阵映射成低维、稠密的矩阵。
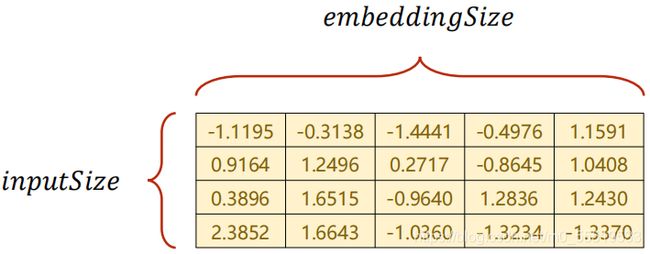

input_size=4,embedding_size=5,由稀疏4维映射到稠密5维,比如输入序列元素是2,对应的one_hot是[0 0 1 0 ],经过Embedding Layer之后就会变成上图绿色这一行。
网络模型:Embedding Layer + RNN Cell + Linear Layer

示例代码:
import torch
num_class = 4 #4个类别,
input_size = 4 #输入维度
hidden_size = 8 #隐层输出维度,有8个隐层
embedding_size = 10 #嵌入到10维空间
num_layers = 2 #2层的RNN
batch_size = 1
seq_len = 5 #序列长度5
idx2char = ['e', 'h', 'l', 'o']
x_data = [[1,0,2,2,3]] #(batch, seq_len) list
y_data = [3,1,2,3,2] #(batch * seq_len)
inputs = torch.LongTensor(x_data) #tensor
labels =torch.LongTensor(y_data)
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.emb = torch.nn.Embedding(input_size, embedding_size)
self.rnn = torch.nn.RNN(input_size=embedding_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True)
self.fc = torch.nn.Linear(hidden_size, num_class)
def forward(self, x):
hidden = torch.zeros(num_layers, x.size(0), hidden_size)
x = self.emb(x) #(batch,seqlen,embeddingSize)
x,_ = self.rnn(x, hidden)
x = self.fc(x)
return x.view(-1, num_class) #矩阵(batchsize×seqlen, numclass)
net = Model()
critirion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.05)
for epoch in range(15):
optimizer.zero_grad()
outputs = net(inputs)
loss = critirion(outputs, labels)
loss.backward()
optimizer.step()
_,idx = outputs.max(dim=1)
idx = idx.data.numpy()
print('idx',idx)
print('Pridected:', ''.join([idx2char[x] for x in idx]), end='') #end是不自动换行,''.join是连接字符串数组
print(',Epoch [%d/15] loss = %.3f' % (epoch+1,loss.item())) 说明:
1.参数设置:torch.nn.Embedding(input_size , embedding_size)
2.各层的输入输出张量:
| shape | Embedding_layer | RNN | Linear_layer |
| input | Longtensor(batch_size, seqlen) | (batch_size, seqlen, embedding_size) | (batch_size, seqlen, hidden_size) |
| output | (batch_size, seqlen, embedding_size) | (batch_size, seqlen, hidden_size) | (batch_size, seqlen, numClass) |