Spring Cloud Alibaba-Sentinel服务保护
一、什么是Sentinel?
Sentinel (分布式系统的流量防卫兵) 是阿里开源的一套用于服务容错的综合性解决方案。它以流量为切入点, 从流量控制、熔断降级、系统负载保护等多个维度来保护服务的稳定性。
Sentinel 分为两个部分:
核心库(Java 客户端 微服务) 不依赖任何框架/库,能够运行于所有 Java 运行时环境,同时对 Dubbo /Spring Cloud 等框架也有较好的支持。
控制台(Dashboard==sentinel服务)基于 Spring Boot 开发,打包后可以直接运行,不需要额外的 Tomcat 等应用容器。
二、安装Sentinel控制台
1.下载sentinel的jar包
2.启动sentinel
-Dserver.port=8090是指定端口号根据自己需要修改,默认端口号是8080
java -Dserver.port=8090 -jar sentinel-dashboard-1.8.1.jar
3.访问sentinel
http://localhost:8090/
默认用户名密码是 sentinel/sentinel
三、Sentinel在微服务的使用
1.导入依赖
com.alibaba.cloud
spring-cloud-starter-alibaba-sentinel
2.修改配置文件中的内容,配置控制台地址
#指定sentinel控制台的地址
spring.cloud.sentinel.transport.dashboard=localhost:80903.访问微服务的任意端点,触发sentinel监控

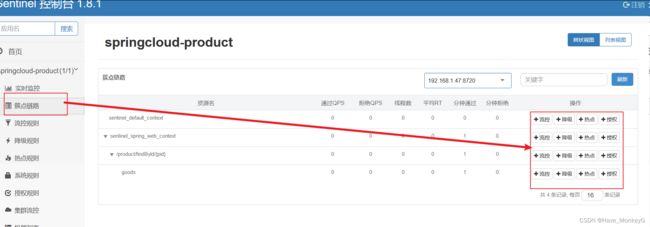
四、簇点链路
簇点链路:就是项目内的调用链路,链路中被监控的每个接口就是一个资源。默认情况下sentinel会监控SpringMVC的每一个端点(Endpoint),因此SpringMVC的每一个端点(Endpoint)就是调用链路中的一个资源。
流控、熔断等都是针对簇点链路中的资源来设置的,因此我们可以点击对应资源后面的按钮来设置规则:
五、流控规则
流量控制,其原理是监控应用流量的QPS(每秒查询率) 或并发线程数等指标,当达到指定的阈值时对流量进行控制,以避免被瞬时的流量高峰冲垮,从而保障应用的高可用性。
流控规则界面:
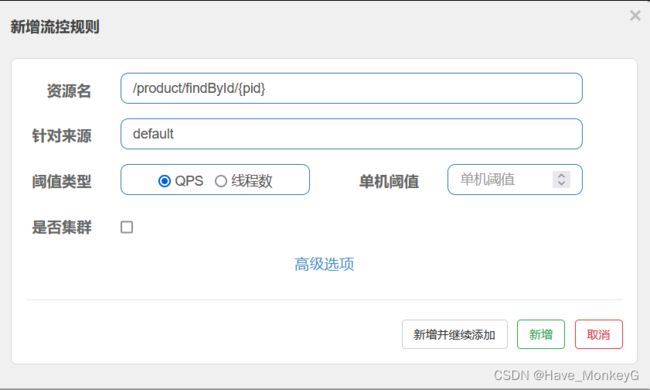
资源名:唯一名称,默认是请求路径,可自定义
针对来源:指定对哪个微服务进行限流,默认指default,意思是不区分来源,全部限制
阈值类型/单机阈值:
- QPS(每秒请求数量): 当调用该接口的QPS达到阈值的时候,进行限流
- 线程数:当调用该接口的线程数达到阈值的时候,进行限流
是否集群:暂不需要集群
接下来我们以QPS为例来研究限流规则的配置
1.配置流控规则
点击上面设置流控规则的编辑按钮,然后在编辑页面点击高级选项,会看到有流控模式一栏。
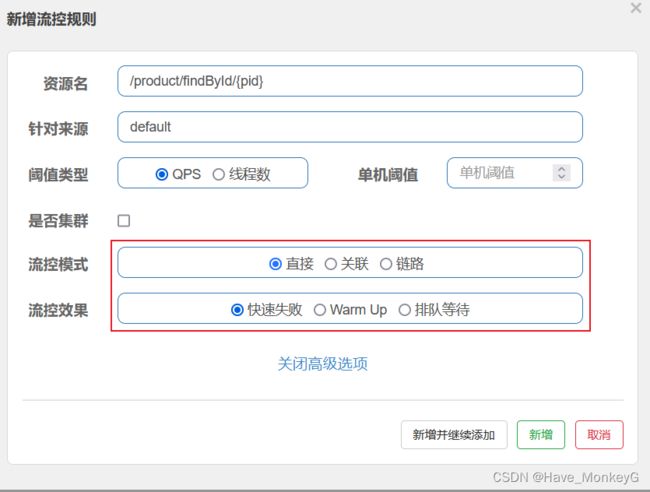
sentinel共有三种流控模式:
- 直接(默认):接口达到限流条件时,开启限流 ,(统计当前资源的请求,触发阈值时对当前资源直接限流,也是默认的模式)
- 关联:当关联的资源达到限流条件时,开启限流 [适合做应用让步] (统计与当前资源相关的另一个资源,触发阈值时,对当前资源限流)
- 链路:当从某个接口过来的资源达到限流条件时,开启限流(统计从指定链路访问到本资源的请求,触发阈值时,对指定链路限流)
2.直接流控模式
直接流控模式是最简单的模式,当指定的接口达到限流条件时开启限流。
3.关联流控模式
关联模式:
统计与当前资源相关的另一个资源,触发阈值时,对当前资源限流
使用场景:
比如用户支付时需要修改订单状态,同时用户要查询订单。查询和修改操作会争抢数据库锁,产生竞争。业务需求是有限支付和更新订单的业务,因此当修改订单业务触发阈值时,需要对查询订单业务限流。
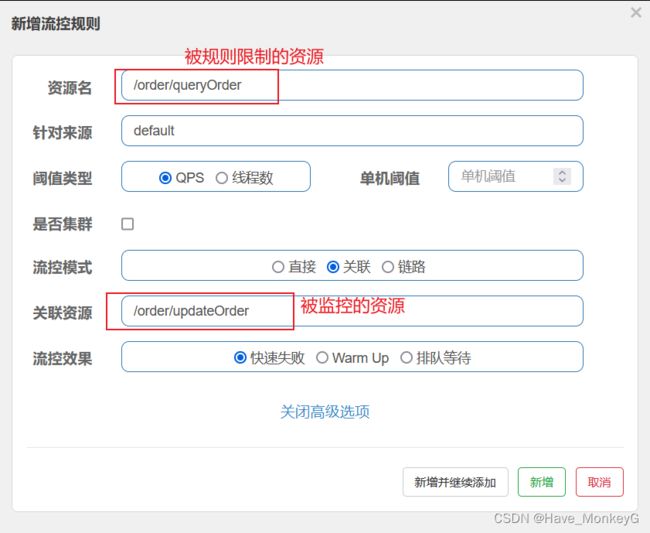
当/order/updateOrder资源访问量触发阈值时,就会对/order/queryOrder资源限流,避免影响/order/updateOrde资源。
总结:
满足下面条件可以使用关联模式:
两个有竞争关系的资源
一个优先级较高,一个优先级较低
4.链路流控模式
链路流控模式指的是,当从某个接口过来的资源达到限流条件时,开启限流。它的功能有点类似于针对来源配置项,区别在于:针对来源是针对上级微服务,而链路流控是针对上级接口,也就是说它的粒度更细。
例如有两条请求链路:
/test1 /common
/test2 /common
如果只希望统计从/test2进入到/common的请求,则可以这样配置:

例子:
有查询订单和创建订单业务,两者都需要查询商品。针对从查询订单进入到查询商品的请求统计,并设置限流。
使用链路需要注意的:
1.
Sentinel默认只标记Controller中的方法为资源,如果要标记其它方法,需要利用@SentinelResource注解

2.
Sentinel默认会将Controller方法做context整合,导致链路模式的流控失效,修改配置文件,添加
#关闭上下文
spring.cloud.sentinel.web-context-unify=false2.配置流控效果
- 快速失败(默认): 直接失败,抛出异常,不做任何额外的处理,是最简单的效果
- Warm Up:它从开始阈值到最大QPS阈值会有一个缓冲阶段,一开始的阈值是最大QPS阈值的1/3,然后慢慢增长,直到最大阈值,适用于将突然增大的流量转换为缓步增长的场景。
- 排队等待:让请求以均匀的速度通过,单机阈值为每秒通过数量,其余的排队等待; 它还会让设置一个超时时间,当请求超过超时间时间还未处理,则会被丢弃。
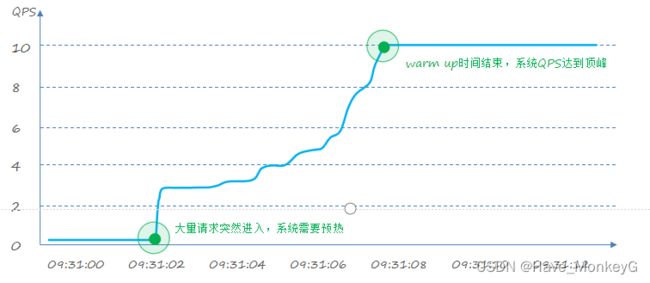
Warm up预热模式
warm up也叫预热模式,是应对服务冷启动的一种方案。请求阈值初始值是 threshold / coldFactor,持续指定时长后,逐渐提高到threshold值。而coldFactor的默认值是3.
例如,我设置QPS的threshold为10,预热时间为5秒,那么初始阈值就是 10 / 3 ,也就是3,然后在5秒后逐渐增长到10.
排队等待
当请求超过QPS阈值时,快速失败和warm up 会拒绝新的请求并抛出异常。而排队等待则是让所有请求进入一个队列中,然后按照阈值允许的时间间隔依次执行。后来的请求必须等待前面执行完成,如果请求预期的等待时间超出最大时长,则会被拒绝。
例如:QPS = 5,意味着每200ms处理一个队列中的请求;timeout = 2000,意味着预期等待超过2000ms的请求会被拒绝并抛出异常
六、热点规则
热点参数流控规则是一种更细粒度的流控规则, 它允许将规则具体到参数上。
之前的限流是统计访问某个资源的所有请求,判断是否超过QPS阈值。而热点参数限流是分别统计参数值相同的请求,判断是否超过QPS阈值。
配置示例:
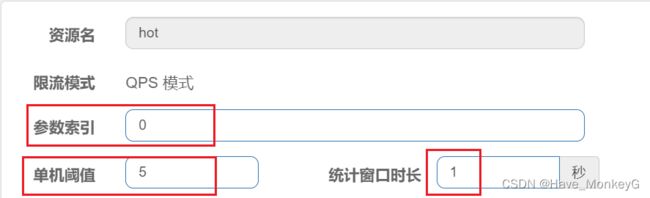
代表的含义是:对hot这个资源的0号参数(第一个参数)做统计,每1秒相同参数值的请求数不能超过5
在热点参数限流的高级选项中,可以对部分参数设置例外配置
注意
热点参数限流对默认的SpringMVC资源无效
我们那需要加上SentinelResource注解来来自定义资源
@GetMapping("/getOrder/{orderid}")
@SentinelResource(value = "hot")//热点参数限流对默认springmvc资源无效,我们那需要加上SentinelResource注解来来自定义资源
public CommonResult getOrder(@PathVariable Integer orderid){
return orderService.findOrder(orderid);
}七、Feign整合Sentinel
SpringCloud中,微服务调用都是通过Feign来实现的,因此做客户端保护必须整合Feign和Sentinel。
1.引入依赖(如果引入就不需要再重复引了)
com.alibaba.cloud
spring-cloud-starter-alibaba-sentinel
2.在配置文件中开启Feign对Sentinel的支持
#开启feign整合sentinel
feign.sentinel.enabled=true3. 兜底逻辑
给FeignClient编写失败后的降级逻辑
方式一:FallbackClass,无法对远程调用的异常做处理
方式二:FallbackFactory,可以对远程调用的异常做处理,我们选择这种
4.创建容错类,实现FallbackFactory
package com.gsh.order.feign;
import com.gsh.entity.Product;
import com.gsh.util.CommonResult;
import feign.hystrix.FallbackFactory;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
/**
*@Auther: haohao
*@Date:2022/8/2509:47
*/
@Slf4j
@Component
public class ProductFeignFactory implements FallbackFactory {
//1.开启openfeign和sentinel的整合
//2.创建fallbackfactory工厂类
//3.在使用feignClien的地方指定fallbackFactory工厂类的反射
@Override
public ProductFeign create(Throwable throwable) {
//创建UserClient接口实现类,实现其中的方法,编写失败降级的处理逻辑
System.out.println(throwable.getMessage());
return new ProductFeign() {
@Override
public CommonResult findById(Integer pid) {
//记录异常的信息
log.error("遇到未知异常,调用了兜底方法!",throwable);
//返回业务需求的默认数据
Product product=new Product();
product.setPname("错误!!!!!!!!!!!!"+throwable.getMessage());
return new CommonResult(4002,"出现未知异常",product);
}
};
}
}
5.为被容器的接口指定容错类
@FeignClient(value = "springcloud-product",fallbackFactory = ProductFeignFactory.class)//被调用的微服务的名称
public interface ProductFeign {
//被调用的方法
@GetMapping("/product/findById/{pid}")
public CommonResult findById(@PathVariable Integer pid);
}八、熔断和降级
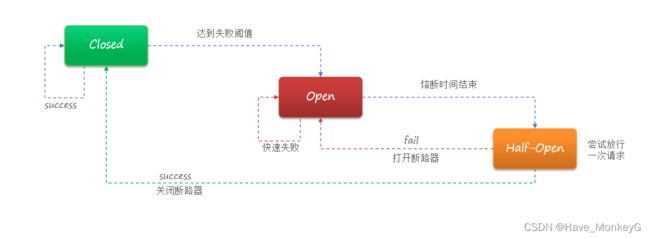
熔断降级是解决雪崩问题的重要手段。其思路是由断路器统计服务调用的异常比例、慢请求比例,如果超出阈值则会熔断该服务。即拦截访问该服务的一切请求;而当服务恢复时,断路器会放行访问该服务的请求。
1.熔断策略-慢调用
断路器熔断策略有三种:慢调用、异常比例、异常数
慢调用:业务的响应时长(RT)大于指定时长的请求认定为慢调用请求。在指定时间内,如果请求数量超过设定的最小数量,慢调用比例大于设定的阈值,则触发熔断。例如:

分析:
最大RT:RT超过500ms的调用是慢调用,可以理解为调用这个资源的响应时间
统计时长:统计最近10000ms(1m)内的请求,
最小请求次数:请求量至少超过10次才会触发,
比例阈值:并且慢调用比例不低于0.5(即触发最大RT超过百分之50%),则触发熔断,
熔断时长:熔断时长为5秒。然后进入half-open状态,放行一次请求做测试。
如果这一次依旧超过最大RT则继续熔断。
2.熔断策略-慢调用
异常比例或异常数:统计指定时间内的调用,如果调用次数超过指定请求数,并且出现异常的比例达到设定的比例阈值(或超过指定异常数),则触发熔断。
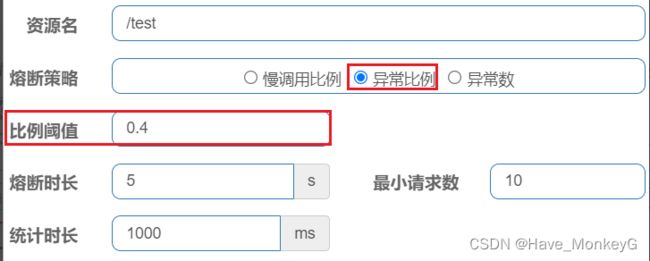
解读:统计最近1000ms内的请求,如果请求量超过10次,并且异常比例不低于0.4,则触发熔断,熔断时长为5秒。然后进入half-open状态,放行一次请求做测试。
九、隔离和降级
虽然限流可以尽量避免因高并发而引起的服务故障,但服务还会因为其它原因而故障。而要将这些故障控制在一定范围,避免雪崩,就要靠线程隔离(舱壁模式)和熔断降级手段了。
不管是线程隔离还是熔断降级,都是对客户端(调用方)的保护。