非支配排序遗传算法(NSGA,NSGA-II )
非支配排序遗传算法(NSGA,NSGA-II )
一、非支配排序遗传算法(NSGA)
1995年,Srinivas和Deb提出了非支配排序遗传算法(Non-dominated Sorting Genetic Algorithms,NSGA)。这是一种基于Pareto最优概念的遗传算法。
1、基本原理
NSGA与简单的遗传算法的主要区别在于:该算法在选择算子执行之前根据个体之间的支配关系进行了分层。其选择算子、交叉算子和变异算子与简单遗传算法没有区别。
在选择操作执行之前,种群根据个体之间的支配与非支配关系进行排序:
首先,找出该种群中的所有非支配个体,并赋予他们一个共享的虚拟适应度值。得到第一个非支配最优层;
然后,忽略这组己分层的个体,对种群中的其它个体继续按照支配与非支配关系进行分层,并赋予它们一个新的虚拟适应度值,该值要小于上一层的值,对剩下的个体继续上述操作,直到种群中的所有个体都被分层。
算法根据适应度共享对虚拟适应值重新指定:
比如指定第一层个体的虚拟适应值为1,第二层个体的虚拟适应值应该相应减少,可取为0.9,依此类推。这样,可使虚拟适应值规范化。保持优良个体适应度的优势,以获得更多的复制机会,同时也维持了种群的多样性。
2、算法流程
NSGA采用的非支配分层方法,可以使好的个体有更大的机会遗传到下一代;适应度共享策略则使得准Pamto面上的个体均匀分布,保持了群体多样性,克服了超级个体的过度繁殖,防止了早熟收敛。算法流程如图所示:

3、算法缺陷
非支配排序遗传算法(NSGA)在许多问题上得到了应用。但NSGA仍存在一些问题:
-
计算复杂度较高,为
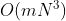 (m为目标函数个数,N为种群大小),所以当种群较大时,计算相当耗时。
(m为目标函数个数,N为种群大小),所以当种群较大时,计算相当耗时。 -
没有精英策略;精英策略可以加速算法的执行速度,而且也能在一定程度上确保已经找到的满意解不被丢失。
-
需要指定共享半径
 。
。
二、带精英策略的非支配排序的遗传算法(NSGA-II)
2000年,Deb又提出NSGA的改进算法一带精英策略的非支配排序遗传算法(NSGA-II),针对以上的缺陷通过以下三个方面进行了改进:
-
提出了快速非支配排序法,降低了算法的计算复杂度。由原来的
降到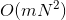 ,其中,m为目标函数个数,N为种群大小。
,其中,m为目标函数个数,N为种群大小。 -
提出了拥挤度和拥挤度比较算子,代替了需要指定共享半径的适应度共享策略,并在快速排序后的同级比较中作为胜出标准,使准Pareto域中的个体能扩展到整个Pareto域,并均匀分布,保持了种群的多样性。
-
引入精英策略,扩大采样空间。将父代种群与其产生的子代种群组合,共同竞争产生下一代种群,有利于保持父代中的优良个体进入下一代,并通过对种群中所有个体的分层存放,使得最佳个体不会丢失,迅速提高种群水平。
1、基本原理
1.1 快速支配排序法
NSGA-II对第一代算法中非支配排序方法进行了改进:对于每个个体 i 都设有以下两个参数 n(i) 和 S(i),
n(i) 为在种群中支配个体 i 的解个体的数量。(别的解支配个体 i 的数量)
S(i) 为被个体 i 所支配的解个体的集合。(个体 i 支配别的解的集合)
-
首先,找到种群中所有 n(i)=0 的个体(种群中所有不被其他个体至配的个体 i),将它们存入当前集合F(1);(找到种群中所有未被其他解支配的个体)
-
然后对于当前集合 F(1) 中的每个个体 j,考察它所支配的个体集 S(j),将集合 S(j) 中的每个个体 k 的 n(k) 减去1,即支配个体 k 的解个体数减1(因为支配个体 k 的个体 j 已经存入当前集 F(1) );(对其他解除去被第一层支配的数量,即减一)
-
如 n(k)-1=0则将个体 k 存入另一个集H。最后,将 F(1) 作为第一级非支配个体集合,并赋予该集合内个体一个相同的非支配序 i(rank),然后继续对 H 作上述分级操作并赋予相应的非支配序,直到所有的个体都被分级。其计算复杂度为
,m为目标函数个数,N为种群大小。(按照1)、2)的方法完成所有分级)
1.2确定拥挤度
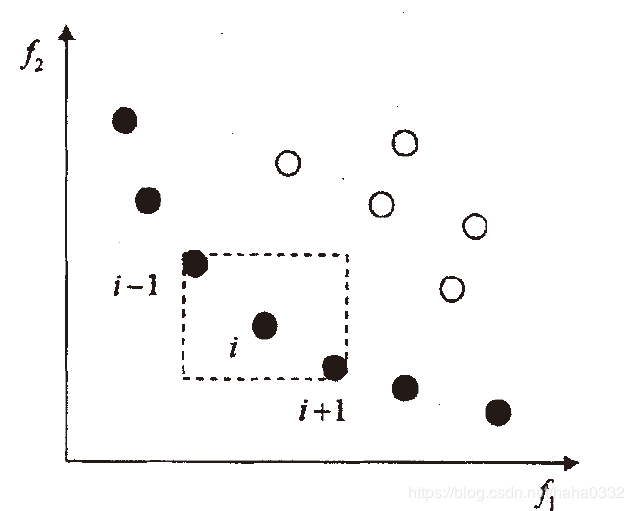
在原来的NSGA中,我们采用共享函数以确保种群的多样性,但这需要由决策者指定共享半径的值。为了解决这个问题,我们提出了拥挤度概念:在种群中的给定点的周围个体的密度,用 表示,它指出了在个体 i 周围包含个体 i 本身但不包含其他个体的长方形(以同一支配层的最近邻点作为顶点的长方形)
如图所示:
拥挤度比较算子:
从图中我们可以看出 值较小时表示该个体周围比较拥挤。为了维持种群的多样性,我们需要一个比较拥挤度的算予以确保算法能够收敛到一个均匀分布的Pareto面上。
值较小时表示该个体周围比较拥挤。为了维持种群的多样性,我们需要一个比较拥挤度的算予以确保算法能够收敛到一个均匀分布的Pareto面上。
由于经过了排序和拥挤度的计算,群体中每个个体 i 都得到两个属性:非支配序 i(rank) 和拥挤度 ,则定义偏序关系:当满足条件 i(rank) < ,或满足 i(rank) = 且 > 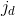 时,定义
时,定义 ,也就是说:如果两个个体的非支配排序不同,取排序号较小的个体(分层排序时,先被分离出来的个体);如果两个个体在同一级,取周围较不拥挤的个体。
,也就是说:如果两个个体的非支配排序不同,取排序号较小的个体(分层排序时,先被分离出来的个体);如果两个个体在同一级,取周围较不拥挤的个体。
2、算法流程

首先,随机初始化一个父代种群P(0),并将所有个体按非支配关系排序且指定一个适应度值,如:可以指定适应度值等于其非支配序 i(rank),则1是最佳适应度值。然后,采用选择、交叉、变异算子产生下一代种群Q(0),大小为N。

如图,首先将第 t 代产生的新种群Q(t)与父代P(t)合并组成R(t),种群大小为2N。然后R(t)。进行非支配排序,产生一系列非支配集 F(t) 并计算拥挤度。由于子代和父代个体都包含在 R(t) 中,则经过非支配排序以后的非支配集 F(1) 中包含的个体是 R(t) 中最好的,所以先将 F(1) 放入新的父代种群 P(t+1) 中。如果 F(1) 的大小小于N,则继续向 P(t+1) 中填充下一级非支配集 F(2),直到添加 F(3) 时,种群的大小超出N,对 F(3) 中的个体进行拥挤度排序(sort(F(3),)),取前![]() 个个体,使 P(t+1) 个体数量达到N。然后通过遗传算子(选择、交叉、变异)产生新的子代种群 Q(t+1)。
个个体,使 P(t+1) 个体数量达到N。然后通过遗传算子(选择、交叉、变异)产生新的子代种群 Q(t+1)。
算法的整体复杂性为,由算法的非支配排序部分决定。
3、代码举例
import geatpy as ea
import numpy as np
class MyProblem(ea.Problem): # 继承Problem父类
def __init__(self):
name = 'NSGA2算法' # 初始化name(函数名称,可以随意设置)
M = 2 # 优化目标个数(两个x)
maxormins = [1] * M # 初始化maxormins(目标最小最大化标记列表,1:最小化该目标;-1:最大化该目标)
Dim = 1 # 初始化Dim(决策变量维数)
varTypes = [0] # 初始化varTypes(决策变量的类型,0:实数;1:整数)
lb = [-10] # 决策变量下界(自定义个上下界搜索)
ub = [10] # 决策变量上界
lbin = [1] # 决策变量下边界(0表示不包含该变量的下边界,1表示包含)
ubin = [1] # 决策变量上边界(0表示不包含该变量的上边界,1表示包含)
# 调用父类构造方法完成实例化
ea.Problem.__init__(self, name, M, maxormins, Dim, varTypes, lb, ub, lbin, ubin)
def evalVars(self, Vars): # 目标函数
f1 = Vars ** 2 # 第一个目标函数
f2 = (Vars - 2) ** 2 # 第二个目标函数
ObjV = np.hstack([f1, f2]) # 计算目标函数值矩阵
CV = -Vars ** 2 + 2.5 * Vars - 1.5 # 构建违反约束程度矩阵(需要转换为小于,反转一下)
return ObjV, CV
# 实例化问题对象
problem = MyProblem()
# 构建算法
algorithm = ea.moea_NSGA2_templet(problem,
# RI编码,种群个体50
ea.Population(Encoding='RI', NIND=50),
MAXGEN=200, # 最大进化代数
logTras=1) # 表示每隔多少代记录一次日志信息,0表示不记录。
# 求解
res = ea.optimize(algorithm, seed=1, verbose=False, drawing=1, outputMsg=True, drawLog=False, saveFlag=False, dirName='result')
4、帕累托最优解

parero寻优类似于推荐系统,简单来说就是系统没有决定权,只有建议权。所以系统会推荐一系列在当前评价函数下性能相似的解。这个时候就需要决策者使用决定权从这些解中选择一个。如果是理论问题的话,最简单的就是随机选一个,反正都一样。但是到了实际问题,那就得具体问题具体分析了。比如,一次期末考试,考数学,语文和英语(三个评价函数),那么系统就会推荐你这三科分别的第一(parero 最优),然后让你从中间选一个最好的,你会怎么选?如果你是个普通老师,你会选总分最高的。但是如果你是一个数学竞赛的老师,你会选一个数学最高的那个。归根到底,还是那句话,具体问题具体分析。
————————————————
资料来源:CSDN博主「蓝色蛋黄包」的原创文章
原文链接:https://blog.csdn.net/haha0332/article/details/88672634