2020:UNITER: Universal Image_Text Representation Learning
摘要
本文引入UNITER,一种通用的图像-文本表示,从四个图像-文本数据集(COCO, Visual Genome, Conceptual Caption, and SBU Captions)的大规模预训练学习,通过联合多模态嵌入为下游V+L任务提供动力。我们设计四个预训练任务:掩码语言建模MLM,掩码区域建模MRM,图像-文本匹配ITM,和单词-区域对齐WRA。与之前将联合随机掩码应用到这两个模态的工作不同,我们在预训练任务中使用条件掩码(如,掩码语言/区域建模以对图像/文本的完全观察为条件)。除了用于全局图像-文本对齐的ITM外,我们还通过使用最优传输OT提出了WRA,以明确地在预训练期间鼓励单词和图像区域之间的细粒度对齐。综合分析表明,条件掩蔽和基于OT的WRA都有助于更好的预训练。我们还进行了一个彻底的消融研究,以找到一个预训练任务的最佳组合,大量实验表明,UNITER在6个V+L任务上实现了最新结果,包括视觉问答、图像-文本检索、参考表达式理解、视觉常识推理、视觉暗示和NLVR。
一、介绍
大多数视觉和语言任务依赖于联合多模态嵌入来弥合图像和文本中的视觉和文本线索之间的语义差距,尽管这种表示通常是为特定任务量身定制的。如,MCB, BAN和DFAF提出了先进的多模态融合方法用于VQA。SCAN和MAttNet研究了学习单词和图像区域间的潜在对齐,用于图像-文本检索和参考表达理解。虽然这些模型在各自的基准上推动了最新结果,但它们的架构是多样的,学习的表示是高于特定任务的,防止它们无法推广到其它任务。
我们引入通用图像-文本表示(UNITER),一种用于联合多模态嵌入的大规模预训练模型,我们采用Transformer作为模型核心,利用为学习上下文表示而设计的自注意力机制。受BERT的启发,我们通过大规模语言建模成功地将transformer应用到NLP任务,我们通过四个预训练任务预训练UNITER:(1)基于图像有条件的掩码语言建模(MLM);(2)基于文本有条件的掩码区域建模(MRM);(3)图像-文本匹配(ITM);和(4)单词-区域对齐(WRA)。为进一步研究MRM的影响,我们提出三种MRM变体:(1)掩码区域分类(MRC);(2)掩码区域特征回归(MRFR);(3)具有KL发散的掩码区域分类(MRC-kl)。
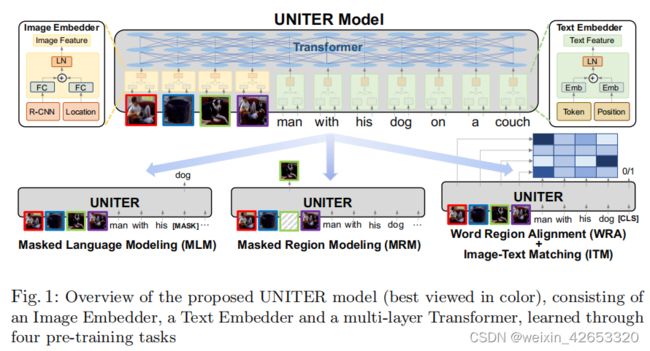
如图1所示,UNITER首先编码图像区域(视觉特征和边界框特征)和文本单词(标记和位置)到一个共同的有着图像编码器和文本编码器的嵌入空间,然后应用一个Transformer模块通过之后的预训练任务学习每个区域和单词的可推广的上下文嵌入。与之前的多模态预训练工作相比,(1)我们的掩码语言/区域建模是以对图像/文本的充分观察为条件,而不是对两个模态应用联合随机掩码;(2)我们通过使用最佳传输(OT)引入一种新的WRA预训练任务,明确地鼓励单词和区域间的细粒度的对齐。直观地说,基于OT的学习目标是通过最小化将一个分布传输到另一个分布的成本来优化分布匹配。在本文中,我们的目标是最小化传输嵌入从图像区域到单词的成本(反之亦然),从而优化到更好的跨模态对齐。我们证明,条件掩码和基于OT的WRA都可以成功的缓解图像和文本之间的错位,从而为下游任务提供更好的联合嵌入。
为论证UNITER的泛化性,我们评估了跨9个数据集的6个V+L任务,包括:(1)VQA,(2)VCR,(3)NLVR,(4)Visual Entailment,(5)图像文本检索;(6)参考表达式理解。我们的UNITER模型在四个子集构成的一个大规模V+L数据集上训练:COCO、Visual Genome、Conceptual Caption和SBU Caption。实验表明,UNITER在所有九个下游数据集上显著提高了新的性能,此外,在额外的CC和SBU数据(包含下游任务的看不见的图像/文本)上训练可以进一步提高模型性能。
我们的贡献被总结如下:(1)我们引入UNITER,一种强大的通用图像-文本表示的V+L任务,(2)本文提出了掩码的语言/区域建模的条件掩码方法,并提出一种新的基于最优传输的单词-区域对齐任务,(3)在广泛的V+L基准测试上实现了新的技术水平,大大超过了现有的多模态预训练方法。我们还提出了广泛的实验和分析,以提供有用的见解,以了解每个预训练任务/数据集的多模态编码器训练的有效性。
二、相关工作
自监督学习利用原始数据作为自己的监督来源。最近,预训练好的语言模型,如ELMo,BERT,GPT2,XLNet,RoBERTa和ALBERT,推动NLP任务取得了巨大的进展。它们的成功有两个关键:在大型语言语料库上进行有效的预训练任务,以及使用Transformer来学习上下文的文本表示。
最近,人们对多模态任务的自我监督学习的兴趣激增,通过在大规模的图像/视频和文本对进行预训练,然后对下游任务进行微调。例如,VideoBERT和CBT应用BERT从视频-文本对中学习在视频帧特征和语言标记上的联合分布,ViLBERT和LXMERT引入双流结构,B2T2、VisualBERT、Unicoder-VL和VL-BERT提出单流结构。最近,多任务学习和对抗训练进一步提高学习性能,VALUE开发了一组探测任务来理解预训练过的模型。
我们的贡献: 在我们的UNITER模型和其它方法的主要差异在两方面:(1)UNITER在MLM和MRM上使用条件掩码,如只掩码一种模态,同时保持另一模态不受污染;(2)一种通过使用最优传输来实现的新型单词-区域对齐预训练对齐,而在以前工作中,这种对齐知识通过特定与任务的损失而隐含地强制执行。此外,我们通过彻底的消融研究,检验预训练任务的最佳组合,并在多个V+L数据集上实现了新的技术水平,往往大大优于之前工作。
三、通用的图像-文本表示
3.1 模型概述
给定一组图像和句子,UNITER将视觉区域和文本标记作为输入,我们设计一个图像编码器和文本编码器来提取各自的嵌入,这些嵌入被送入一个多层的Transformer来学习一个跨模态上下文嵌入,注意到Transformer中的自注意力机制是无序的,因此有必要明确地将区域和标记的位置编码为额外的输入。
我们引入四个主要任务来预训练我们的模型:基于图像区域条件下的掩码语言建模(MLM) ,基于输入文本条件下的掩码区域建模(MRM),图像-文本匹配(ITM),和单词-区域对齐(WRA)。图1所示,我们的MRM和MLM与BERT类似,从输入中随机掩码一些单词或区域,并学习恢复这些单词或区域作为Transformer的输出。具体地,单词掩码通过一个特殊标记[MASK]来实现的,区域掩码通过用所有的零替换视觉特征向量来实现,注意,每次只掩码一种模态,而保持其它模态完整,而不是像其它预训练方法中使用的随机掩码两种模态。这可以防止当掩码区域恰好被掩码单词描述时可能出现的错位。
我们还通过ITM学习了整个输入图像和句子之间的实例级对齐。训练期间,我们同时采样正和负图像-句子对,并学习它们的匹配分数。此外,为了在单词标记和图像区域之间提供更细粒度的对齐,我们通过使用最优传输提出WRA,有效地计算出将上下文图像嵌入传输到单词嵌入的最小成本(反之亦然)。因此,推断出的传输计划可以作为一个螺旋桨,以更好的跨模态对齐。根据实验,我们证明了条件掩码和WRA都有助于提高性能,为了对这些任务预训练,我们为每个mini-batch采样了一个任务,并在每次SGD更新中只训练一个目标。
3.2 预训练任务
掩码语言建模(MLM) 我们以15%的概率随机掩码输入词,并用特殊标记[MASK]替换掩码的词。目标是基于周围的词和所有图像区域的观察,通过最小化负对数似然来预测掩码的单词:
![]()
其中,θ为可训练参数。每对(w、v)都是从整个训练集D中采样的。
图像-文本匹配(ITM) 在ITM中,一个额外的特殊标记[CLS]被输入到模型中,表示两个模态的融合表示。ITM的输入是一个句子和一组图像区域,输出是一个二值标签,表示采样对是否匹配。我们提取[CLS]标记作为输入图像-文本对的共同表示,然后将其输入一个FC层和一个sigmoid函数来预测0到1之间的分数。我们将输出分数表示为sθ(w,v),ITM监督位于[CLS]标记之上。在训练期间,我们在每一步从数据集D中抽取一个正或负的对(w,v),负对是通过用其它样本中随机选择的图像或文本替换配对样本中的图像或文本来产生的。我们应用二进制交叉熵损失进行优化:
![]()
单词-区域对齐(WRA) 我们为WRA使用最优传输,其中一个传输计划T是优化w和v之间的对齐。OT具有几个特殊的特点,使其称为WRA的好选择:(1)自归一化:T的所有元素和为1,(2)稀疏性:当精确求解时,OT产生一个最多包含(2r−1)非零元素的稀疏解T,其中r=max(K,T),导致一个更可解释和稳健的对齐。(3)效率:与传统的线性规划求解器相比,我们的解决方案可以很容易地通过只需要矩阵向量积的迭代过程得到,因此很容易使用于大规模的模型预训练。
具体地,(w,v)可以被考虑为两个离散分布µ,ν,µ和ν之间的OT距离(因此也将(w,v)对的对齐损失)定义为:
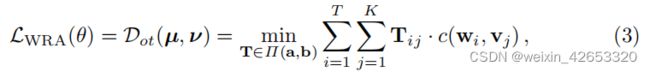
矩阵T表示为传输计划,解释了两种模态间的对齐,不幸的是,在T上的精确最小化是难以计算的,我们认为IPOT算法近似于OT距离。在求解T后,OT距离作为WRA损失,可以用来更新参数θ。
掩码区域建模(MRM) 类似于MLM,我们也采样图像区域,以15%的概率掩码视觉特征,训练模型通过剩余的区域和所有的单词预测掩码区域。掩码区域的视觉特征被零代替。与用离散标签表示的文本标记不同,视觉特征是高维的和连续的,因此不能通过类似然法来进行监督,相反,我们为MRM提出了三个变体,它们具有相同的目标基础:
![]()
1)掩码区域特征回归(MRFR) MRFR学习将每个掩码区域vmi的transformer输出回归到视觉特征。具体地,我们应用一个FC层将它的transformer输出转换为与输入ROI池化特征r(v(i)m)相同维度的向量hθ(v(i)m),然后在两者之间应用L2回归:
![]()
2)掩码区域分类(MRC) MRC学习为每个掩码区域预测对象语义类。首先将掩码区域v(i)m的transformer输出输入到一个FC层,以预测K个对象类的分数,然后进一步通过一个softmax函数转换为一个归一化的分布gθ(v(i)m)∈RK。注意到,没有真实标签,因为没有提供对象类。因此,我们使用Faster R-CNN的对象检测输出,并将检测到的对象类别作为掩码区域的标签,将其转换为一个one-hot向量c(v(i)m)∈RK,最终的目标使交叉熵(CE)损失最小化:
![]()
3)具有KL发散度的掩码区域分类(MRC-kl) MRC将对象检测模型中最有可能的对象类作为硬标签(0或1),假设检测到的对象类是该区域的真实标签,这可能不是真的,因为没有地面真实的标签是可用的。因此,在MRC-kl,我们通过使用软标签作为监督信号来避免这种假设,这是检测器的原始输出(即,对象类c(v(i)m)的分布)。MRC-kl的目的是通过最小化两个分布之间的KL散度,将这些知识提炼进UNITER:
![]()
3.3 预训练数据集
我们基于我们的四个现有的V+L数据集构建我们的预训练数据集:COCO、Visual Genome(VG)、Conceptual Captions(CC)、SBU Captions。只有图像和句子被用作预训练,使模型框架更可伸缩,因为额外的图像-句子对很容易收获用于进一步的预训练。
四、实验