原文:
Lucene.Net 2.3.1开发介绍 —— 一、接触Lucene.Net
1、引用Lucene.Net类库
找到Lucene.Net的源代码,在“C#\src\Lucene.Net”目录。打开Visual Studio,我的版本是2008,而Lucene.Net默认的是2005。先创建一个项目,简单起见,创建一个C#控制台程序。
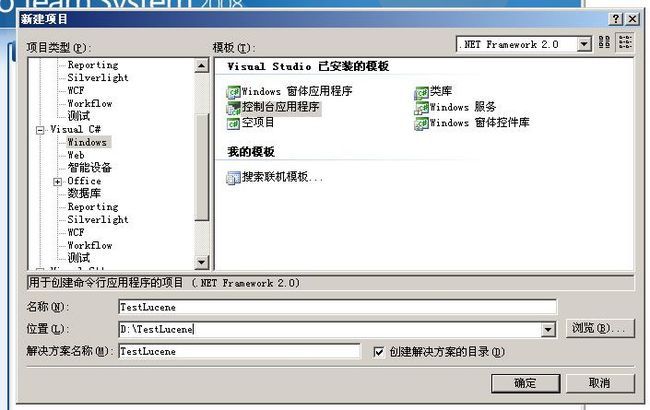
图 1.1
然后添加Lucene.Net进项目,如图 1.2 - 1.3。
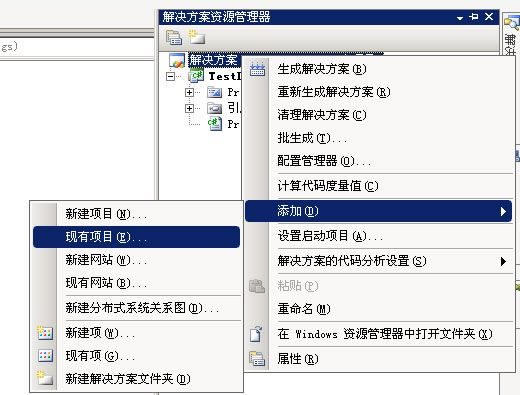
图 1.2
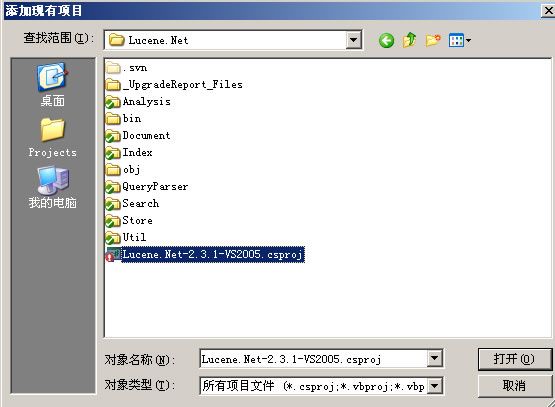
图 1.3
这个过程要进行一个VS2005到2008的转换。添加后,解决方案就有Lucene.Net项目了,如图1.4。
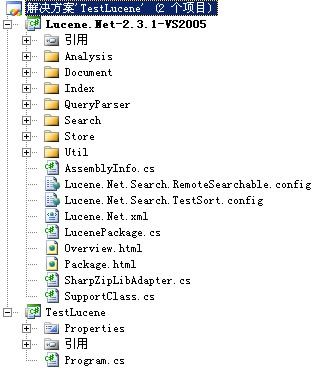
图 1.4
然后把Lucene.Net引入TestLucene项目。如图1.5 -1.6:
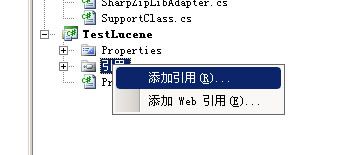
图1.5
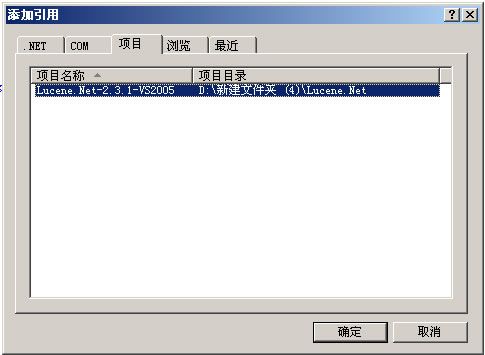
图1.6
点确定后就可以了。这时候,就可以在TestLucene项目中使用Lucene.Net的API了。
2、简单示例
对Lucene.Net的操作分为建立索引,和搜索两部分。
2.1 建立索引
通过代码 2.1.1,就可以简单地建立一个索引了。代码 2.1.1将在应用程序目录下建立一个IndexDirectory目录,并在目录下创建索引文件。
代码 2.1.1

 Code
Code
1 using System;
using System;
2using System.Collections.Generic;
3using System.Text;
4
5
6namespace TestLucene
7 {
{
8 using Lucene.Net.Index;
using Lucene.Net.Index;
9 using Lucene.Net.Store;
10 using Lucene.Net.Analysis;
11 using Lucene.Net.Analysis.Standard;
12 using Lucene.Net.Documents;
13
14 class Program
15
 {
{
16 static void Main(string[] args)
17 {
18 Analyzer analyzer = new StandardAnalyzer();
19 IndexWriter writer = new IndexWriter("IndexDirectory", analyzer, true);
20 AddDocument(writer, "SQL Server 2008 的发布", "SQL Server 2008 的新特性");
21 AddDocument(writer, "ASP.Net MVC框架配置与分析", "而今,微软推出了新的MVC开发框架,也就是Microsoft ASP.NET 3.5 Extensions");
22 writer.Optimize();
23 writer.Close();
24 }
}
25
26 static void AddDocument(IndexWriter writer, string title, string content)
27 {
28 Document document = new Document();
29 document.Add(new Field("title", title, Field.Store.YES, Field.Index.TOKENIZED));
30 document.Add(new Field("content", content, Field.Store.YES, Field.Index.TOKENIZED));
31 writer.AddDocument(document);
32 }
33 }
34 }
}
35
2.2 搜索索引
代码2.2.1就可以搜索刚才建立的索引。
代码 2.2.1
Code
1using System;
2using System.Collections.Generic;
3using System.Text;
4
5
6namespace TestLucene
7{
8 using Lucene.Net.Index;
9 using Lucene.Net.Store;
10 using Lucene.Net.Analysis;
11 using Lucene.Net.Analysis.Standard;
12 using Lucene.Net.Documents;
13 using Lucene.Net.Search;
14 using Lucene.Net.QueryParsers;
15
16 class Program
17 {
18 static void Main(string[] args)
19 {
20 Analyzer analyzer = new StandardAnalyzer();
21 //IndexWriter writer = new IndexWriter("IndexDirectory", analyzer, true);
22 //AddDocument(writer, "SQL Server 2008 的发布", "SQL Server 2008 的新特性");
23 //AddDocument(writer, "ASP.Net MVC框架配置与分析", "而今,微软推出了新的MVC开发框架,也就是Microsoft ASP.NET 3.5 Extensions");
24 //writer.Optimize();
25 //writer.Close();
26
27 IndexSearcher searcher = new IndexSearcher("IndexDirectory");
28 MultiFieldQueryParser parser = new MultiFieldQueryParser(new string[] { "title", "content" }, analyzer);
29 Query query = parser.Parse("sql");
30 Hits hits = searcher.Search(query);
31
32 for (int i = 0; i < hits.Length(); i++)
33 {
34 Document doc = hits.Doc(i);
35 Console.WriteLine(string.Format("title:{0} content:{1}", doc.Get("title"), doc.Get("content")));
36 }
37 searcher.Close();
38
39 Console.ReadKey();
40 }
41
42 //static void AddDocument(IndexWriter writer, string title, string content)
43 //{
44 // Document document = new Document();
45 // document.Add(new Field("title", title, Field.Store.YES, Field.Index.TOKENIZED));
46 // document.Add(new Field("content", content, Field.Store.YES, Field.Index.TOKENIZED));
47 // writer.AddDocument(document);
48 //}
49 }
50}
51
运行后输出:
title:SQL Server 2008 的发布 content:SQL Server 2008 的新特性
2.3 疑问
2.1,2.2小节介绍了最简单的建立和搜索索引的方式。虽然代码很短,使用也很简单,但是理解起来却不是太容易。
代码 2.1.1中,先是建立了一个分词器。什么是分词器?为什么要有分词器?分词器是怎么工作的?这些问题真让人头疼。接着建立一个IndexWriter的实例,这个类是负责创建索引的,有很多构造函数,这里使用的是其中的一个。三个参数分别是:索引建立到哪个目录,用什么分词器,还有就是是否创建。如果是否创建为false,那么就是以增量的方式来创建。再下来调用了AddDocument方法,在AddDocument方法中,先组织一个Docuement对象,然后把这个对象交给IndexWriter。然后再调用Optimize优化索引,最后关闭创建过程。这里面又有什么是Document,Document是怎么往存储器里写入的?Optimize方法能干什么?问题真多。
代码2.2.1则相对简单,先是创建IndexSearcher对象实例,并指定其搜索的目录,然后构造了一个查询Query,然后查出Hits,这样就得到想要的结果了。但是这个查询的过程是什么样的呢?这个Query代表什么?Hits是怎么得出来的?结果的顺序是怎么决定的?这些又是留下来的问题。
这么多问题,不能一次说完,欲知后事如何,下面一一道来。