实体链指(1)Entity Linking 综述
实体链指(1)Entity Linking 综述
- What is Entity Linking?
- Formal Definition
- Architecture
-
- Candidate Generation
- Context-mention Encoding
- Entity Encoding
- Entity Ranking
- Unlinkable Mention Prediction
- Modifications of the General Architecture
- Evaluation Metrics
- Applications of EL
- TODO
What is Entity Linking?
实体链接(entity linking) 任务是指识别出文本中的提及(mention)、确定mention的含义并消除其可能存在的歧义,然后建立该mention到 知识库(KB) 中 实体(entity) 的链接,从而将非结构化数据连接到结构化数据的过程。
实体链接利用知识库中大量实体的丰富信息,可以实现各种语义应用,如实体链接是很多信息抽取(IR)、知识问答、构建知识图谱等,是自然语言理解(NLU)pipeline 中的重要组件。

通常这个过程一般分为2个子任务,即NER/MD(mention detection)和实体消歧。由这2个子任务是否拆分开独立进行,形成了目前2种主流的实体链指方法:
- 端到端(End-to-End)
- 实体消歧(Disambiguation-Only)
End-to-End是指不拆分子任务,一次性实现query mention的识别并将其链指到KB中正确的实体;而Disambiguation-Only需要提供确定的mention及其边界,相当于就是默认NER任务已完成并能确切的给出gold query mention,然后再将此mention链指到KB中的实体。
接下来我们通过2020年的一篇综述: 《Neural entity linking: A survey of models based on deep learning》 来大致了解下自2015年以来EL任务的定义、实现框架、模型、以及应用。
Formal Definition
- Knowledge Graph (KG)
- Entity Recognition (ER)
E R : C → M n ER:C\rightarrow M^n ER:C→Mn - Entity Recognition (ER)
E D : ( M , C ) n → E n ED:(M,C)^n \rightarrow E^n ED:(M,C)n→En
我们可以把实体识别的过程定义成一个文本到mention的函数ER,其中 c i ∈ C c_i \in C ci∈C, C C C即为文档集context,可以是一个document、或question、或query;n个m, m i ∈ M m_i \in M mi∈M ,M是文本中所有可能的text spans。
可以把实体消歧的任务定义成由输入文本context以及文本中的mention映射到KB中实体的函数ED
为了学习这种映射关系,EL models需要使用有监督信号进行学习,也就是说需要query以及mention-entity pair对的充分的标注数据。
Architecture
作者总结了EL的一个通用框架主要包含2步,即 NER 和 实体消歧 ,而实体消歧又可继续拆分成2步:即 候选生成 和 排序 ,候选生成用于产出mention对应KB中的候选实体列表,是一个粗召过程,然后第2步就是在候选集上进行精排,得到最终gold link,而这一步通常需要基于context/mention和entity的表征来计算相似度,给出得分最高的mention-entity pair。
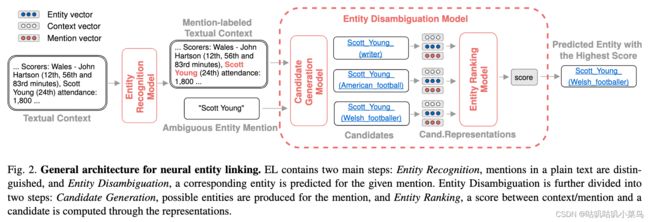
上述过程主要涉及候选生成 、mention/entity的表征或者叫编码、排序等几个模块:
- Candidate Generation
C G : M → ( e 1 , e 2 , . . . , e k ) CG:M \rightarrow (e_1,e_2,...,e_k) CG:M→(e1,e2,...,ek) - Context-mention Encoding
m E N C : ( C , M ) n → ( y m 1 , y m 2 , . . . , y m n ) mENC:(C,M)^n \rightarrow (y_{m_1}, y_{m_2},...,y_{m_n}) mENC:(C,M)n→(ym1,ym2,...,ymn) - Entity Encoding
e E N C : E k → ( y e 1 , y e 2 , . . . , y e k ) eENC: E^k \rightarrow (y_{e_1},y_{e_2},...,y_{e_k}) eENC:Ek→(ye1,ye2,...,yek) - Entity Ranking
R N K : ( ( e 1 , e 2 , . . . , e k ) , C , M ) n → R n × k RNK:((e^1,e^2,...,e^k),C,M)^n \rightarrow R^{n\times k} RNK:((e1,e2,...,ek),C,M)n→Rn×k - Unlinkable Mention Prediction
N I L p : ( C , M ) n → { 0 , 1 } n NIL_p:(C,M)^n\rightarrow \{0,1\}^n NILp:(C,M)n→{0,1}n
Candidate Generation
首先说下 候选生成(Candidate Generation) ,候选生成的过程可以定义成由mention到KB中可能相关的实体列表的映射,这一步的主要作用是找到一个尽可能小、尽可能包含目标实体的集合。常用的方法可参考 @Table1 ,大致有3种:
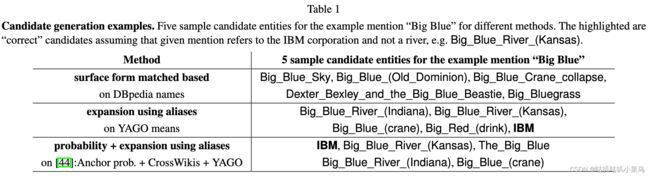
- 第一种方法是一些基于字面的浅显的匹配,例如基于编辑距离、n-grams等。但是有些场景下这种方法并不能work well,例如mention=“Big Blue”时使用这种方法很难匹配出entity=“IBM”(看表中示例);
- 第二种方法基于别名词典,或同义词词典,这通常需要别名挖掘等工作,构建成本比较高、无法处理未登录词,召回率受词表的完整度的限制;
- 第三种方法基于一些先验概率 p ( e ∣ m ) p(e|m) p(e∣m)、词向量或语义召回等方式。
当然,上述的这些方法在候选生成阶段可以组合使用。
Context-mention Encoding
第2个模块是说如何产出context-mention的表征向量,当前主流的方法是使用一个encoder网络来构建一个能表征上下文的稠密向量(dense contextualized vector representation)。早些时候会使用卷积encoder或在候选与mention之间使用attention机制,但近期的模型里有2种方法占了上风:recurrent networks(例如双向LSTM) and self-attention(例如利用预训练好的Bert等基于Transformer的其他的预训练语言模型)。
Entity Encoding
第3个模块是实体的表征,它可以基于KB中的doc的字词构建词向量,类似于word2vec,或者可以利用知识库中实体之间的关系来构建表征(利用知识图谱),还还可以和context-mention一样也train一个encoder网络,其训练可以基于实体描述、实体页面标题、实体类型、实体的热度、链接次数(先验知识)等各种特征。
Entity Ranking

最后的排序阶段就是基于context-mention的语义表征和候选entity的表征计算相似度,在所有候选实体上按相似度打分排序,得分最高者即为gold enity。
相似度 s ( m , e i ) s(m,e_i) s(m,ei) 计算可使用点乘或者余弦相似度等:
- dot product: s ( m , e i ) = y m ⋅ y e i s (m, e_i) = y_m \cdot y_{e_i} s(m,ei)=ym⋅yei
- cosine similarity: s ( m , e i ) = cos ( y m , y e i ) = y m ⋅ y e i ∣ ∣ y m ∣ ∣ ⋅ ∣ ∣ y e i ∣ ∣ s (m, e_i) = \cos(y_m, y_{e_i})=\frac{y_m \cdot y_{e_i}}{||y_m|| \cdot ||y_{e_i}||} s(m,ei)=cos(ym,yei)=∣∣ym∣∣⋅∣∣yei∣∣ym⋅yei
最后infer做决策时使用的概率分布 p ( e i ∣ m ) p(e_i|m) p(ei∣m),这一般可使用候选集上的softmax来近似: P ( e i ∣ m ) = exp ( s ( m , e i ) ) ∑ i = 1 k exp ( s ( m , e i ) ) P(e_i|m)=\frac{\exp(s(m,e_i))}{\sum^k_{i=1}\exp(s(m,e_i))} P(ei∣m)=∑i=1kexp(s(m,ei))exp(s(m,ei)) ,同时也可以和其他先验特征: f ( e i , m ) f(e_i,m) f(ei,m)结合使用(例如候选生成阶段获得的mention-entity priors): Φ ( e i , m ) = ϕ ( P ( e i ∣ m ) , f ( e i , m ) ) \Phi(e_i,m)=\phi(P(e_i|m),f(e_i,m)) Φ(ei,m)=ϕ(P(ei∣m),f(ei,m))。
训练目标training objective可以当做分类任务进行,即使用标准的负对数似然损失(standard negative log likelihood objective),也可以是各种各样的ranking loss:
- standard negative log likelihood objective
L ( m ) = − s ( m , e ∗ ) + log ∑ i = 1 k exp ( s ( m , e i ) ) L(m)=-s(m,e_*)+\log\sum^k_{i=1}\exp(s(m,e_i)) L(m)=−s(m,e∗)+logi=1∑kexp(s(m,ei))
其中 e ∗ e_* e∗表示true entity。 - ranking loss
L ( n ) = ∑ i l ( e i , m ) L(n)=\sum_i l(e_i,m) L(n)=i∑l(ei,m)
其中 l ( e i , m ) = [ γ − Φ ( e ∗ , m ) + Φ ( e i , m ) ] + l(e_i,m)=[\gamma-\Phi(e_*,m)+\Phi(e_i,m)]_+ l(ei,m)=[γ−Φ(e∗,m)+Φ(ei,m)]+
或者 l ( e i , m ) = { [ γ − Φ ( e i , m ) ] + i f e i = e ∗ [ Φ ( e i , m ) ] + o t h e r w i s e l(e_i,m)=\begin{cases} [\gamma-\Phi(e_i,m)]_+&if \;e_i =e_*\\ [\Phi(e_i,m)]_+&otherwise\\\end{cases} l(ei,m)={[γ−Φ(ei,m)]+[Φ(ei,m)]+ifei=e∗otherwise
Unlinkable Mention Prediction
最后需要重点提到的是[NIL](Unlinkable Mention),即无法链接到KB中任何实体的mention,这可能是NER误识别引起的、或mention对应的实体在还没有登录在KB中,毕竟知识库的构建是一个逐步完善的过程。那对于Unlinkable Mention的处理,一般常见的有以下4种方法:
(1)候选阶段不产生任何候选
(2)卡阈值
(3)空实体[NIL]直接参与排序
(4)排序后再接二分类,二分类输入:m-e pairs,或者其他额外的特征,例如best linking score等,来对mention是否能被linking做最终决策
Modifications of the General Architecture
在通用框架上,又逐步演化成如下4种变种EL任务:
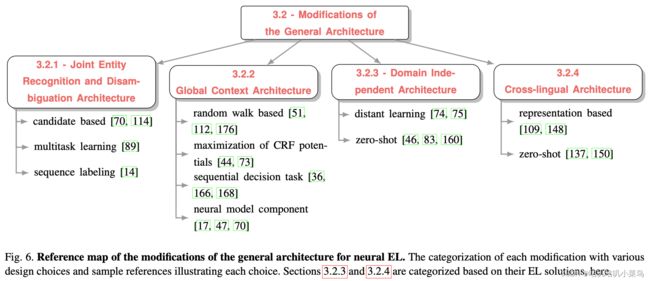
第1种是NER任务和ED(Entity Disambiguation)任务同时进行,其实就是前面提到的End2End的方法,这一块后续的文章会专门介绍,这里不多说。
E L : C → ( M , E ) n EL:C\rightarrow(M,E)^n EL:C→(M,E)n
第2种是指 全局实体消歧 (指同时对多个mention进行消歧,认为实体之间也是有相互关联的):the consistency score(一致性) between correct entity candidates is expected to be higher than between incorrect ones。
L E D : ( M , C ) → E LED:(M,C)\rightarrow E LED:(M,C)→E
G E D : ( ( m 1 , m 2 , . . . , m q ) , C ) → E q GED:((m_1,m_2,...,m_q),C)\rightarrow E^q GED:((m1,m2,...,mq),C)→Eq
除此之外,GED(Global Entity Disambiguation)中还经常考虑更长的context甚至是整个doc,虽然增加了消歧的acc,但这也会增加计算复杂度。
第3种是指领域无关的EL任务。大部分任务存在的共性挑战是标注数据不足的问题。目前实体链接任务只在很有限的几个领域内有相对高质量的标注数据,因此如何能够做到充分利用这些标注数据甚至于不需要标注数据完成实体链接是当前存在的一个重要挑战。早期的方法基于 无监督和半监督方法(unsupervised and semi-supervised models) ,近期主要有两方面的解决方案: Distant Learning和Zero-shot Learning 。其中Distant Learning与关系抽取任务中的distant superviced思想相似,使用一些surface matching的启发式规则生成部分带噪声的远程监督数据集,并在此基础上进行弱监督学习。另一方面Zero-shot learning的核心思想是在标注数据充足的领域(Domain)训练得到具有普适性的特征,并使用尽量少的新领域信息完成领域迁移。
最后,另一个存在的挑战是 跨语言的实体链接 问题。由于部分语言的相关语料库数据非常少,实体-mention之间的先验信息也很少,所以从候选实体生成到实体排序阶段都非常有挑战。跨语言的实体链接方法试图充分利用不同语言的相同实体之间的wiki链接信息来实现尽量准确的跨语言链接。当前的跨语言实体链接方法大多严重依赖于预训练的跨语言语言模型,试图将不同语言的表征约束在同一个向量空间中,再使用同样的方法进行实体排序。
Evaluation Metrics
-
ED (Disambiguation-Only):
F 1 = P = R = A c c = # o f c o r r e c t l y d i s a m b . m e n t i o n s # o f t o t a l m e n t i o n s F_1=P=R=Acc=\frac{\#\; of\; correctly\; disamb.\; mentions}{\#\; of\; total\; mentions} F1=P=R=Acc=#oftotalmentions#ofcorrectlydisamb.mentions -
ER+ED (End-to-End):
P = # o f c o r r e c t l y d e t e c t e d a n d d i s a m b . m e n t i o n s # o f p r e d i c t e d m e n t i o n s b y m o d e l P=\frac{\#\; of\; correctly\; detected\; and\; disamb.\; mentions}{\#\; of\; predicted\; mentions\; by\; model} P=#ofpredictedmentionsbymodel#ofcorrectlydetectedanddisamb.mentions
R = # o f c o r r e c t l y d e t e c t e d a n d d i s a m b . m e n t i o n s # o f m e n t i o n s i n g r o u n d t r u t h R=\frac{\#\; of\; correctly\; detected\; and\; disamb.\; mentions}{\#\; of\; mentions\; in\; ground\; truth} R=#ofmentionsingroundtruth#ofcorrectlydetectedanddisamb.mentions
F 1 = 2 ⋅ P ⋅ R P + R F_1=\frac{2 \cdot P \cdot R}{P+R} F1=P+R2⋅P⋅R
Applications of EL
除了一些常规应用:文本挖掘、构建知识图谱、信息检索、问答等,
EL还解锁了一些新的应用:将实体链接系统集成到更大的网络模型中。例如在LM中集成EL任务做联合学习,由于扩展了EL而使用到KG中丰富的信息,这种集成后的训练通常能使LM得到更好的语义表征。
L J O I N T = L B E R T + L E L − r e l a t e d L_{JOINT}=L_{BERT}+L_{EL-related} LJOINT=LBERT+LEL−related
L E R N I E = L N S P + L M L M + L d E L L_{ERNIE}=L_{NSP}+L_{MLM}+L_{dEL} LERNIE=LNSP+LMLM+LdEL
TODO
后续会从Disambiguation-Only和End2End 两种方法分别介绍比较具有代表性的、并且效果SOTA的几篇paper,来详细了解下具体EL任务的实现过程。
[1] Sevgili, Özge, et al. “Neural entity linking: A survey of models based on deep learning.” Semantic Web Preprint (2022): 1-44.
[2]: [KG笔记]九、实体链接(Entity Linking)
如果需要其他NLP相关内容请移步至: 我的github:https://github.com/qingyujean/Magic-NLPer,求赞求星求鼓励~~~
最后:如果本文中出现任何错误,请您一定要帮忙指正,感激~