如何有效使用预训练语言模型
学术论坛·第六期
推荐阅读时长:10min
前言
学术论坛第六期我们有幸邀请到南加州大学硕士生、云智慧智能研究院算法实习生蔺同学,为我们介绍NLP是如何走向了prompt与adapter,在讲述prompt与adapter的原理、具体实现方法及优点后,还对它们进行了区分对比。下面让我们一起来学习吧~
学术论坛内容
一、 NLP如何发展走向了prompt与adapter
二、prompt的原理与实现方法
三、 adapter的原理与实现方法
四、prompt与adapter的区分
五、总结
一、NLP如何发展走向了prompt与adapter
1.模型训练的发展
NLP(自然语言处理)模型通常用监督学习的方法训练。监督学习指模型仅在标注好的目标任务数据集上进行训练,由于带标记的样本数量不足以支撑模型学习到高质量的潜在特征,早期的NLP模型依赖于特征工程。特征工程指人们根据领域先验知识预先定义特征,这些特征帮助模型具有一定程度的归纳偏置(inductive biases),如下图中a所示。
深度神经网络模型的出现,推动特征学习与模型训练共同进行,因此研究的焦点转移到模型的结构上,模型具有的归纳偏置由其结构决定,例如RNN与CNN根据归纳偏置的不同,分别适用于文本与图像领域(下图 b)
BERT(Bidirectional Encoder Representations from Transformers)的出现,令NLP模型的学习方式发生了巨大变化,全监督的方法不再流行,取而代之的方法是预训练(pre-train)与微调(fine-tuning)。
预训练是用一个固定的模型结构作为语言模型(Language Model, LM)并进行预训练,训练方式是对句子中的一部分词语进行遮掩(mask)或替换,再用模型预测正确的词语(BERT)。预训练是一种无监督的方法,可直接在没有标注的数据集上训练并建模语言的通用特征。通过预训练得到的语言模型会进一步适配到不同下游任务,根据任务特定的目标函数进行微调。在预训练与微调的方法下,研究的重点转为如何设计一个合理的目标函数,使得模型在预训练阶段和微调阶段能够更好地学习到语言的通用特征(下图 c)。
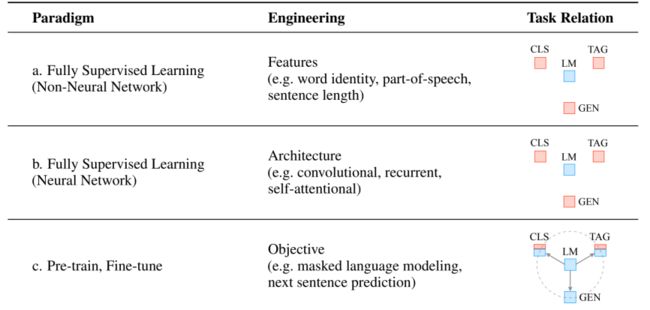
2.预训练语言模型的局限性
尽管在预训练语言模型上以微调的方式适应下游任务,已经是一种非常流行且效果非常好的方法,但是这种方法在微调阶段需要更新并存储所有语言模型的参数。当我们构建并实际使用预训练语言模型的NLP系统时,每一个下游任务都需要存储一份原语言模型微调过后的参数。考虑到预训练语言模型的参数都非常大,例如GPT-2有774M参数,BERT-base也有110M参数,为每个下游任务都保存一个模型将需要不小的空间开销(如下图所示)。
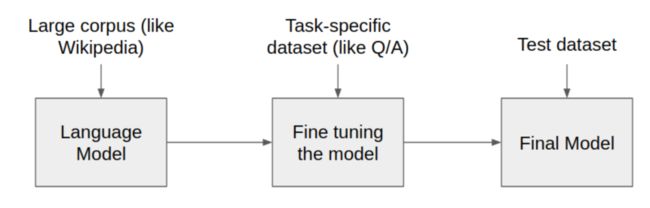
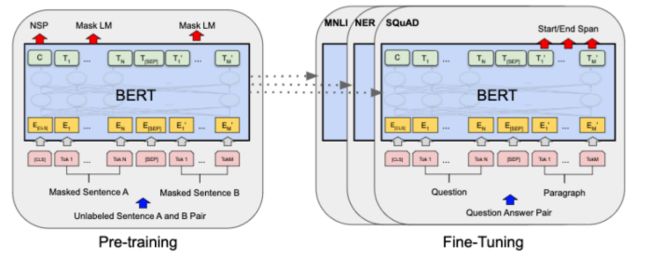
二、prompt的原理与实现方法
受GPT模型启发,学者们提出了prompt方法,避免不同下游任务都对预训练语言模型中参数进行调整。具体来说,通过对下游任务的输入进行修改形成统一形式的prompt,prompt再作为预训练语言模型输入,使得不同下游任务可以共用一个固定不变的参数预训练语言模型。其思路是,通过构建适合下游任务与语言模型的prompt,尽可能发挥语言模型在预训练过程中学习到的知识。例如,BERT在预训练过程中学习到的知识是合理补全不完整句子的能力,GPT-3学习到的知识是根据已有句子进行合理续写的能力。

下面以一个具体例子来说明prompt是如何实现的。如上图所示,当进行情感分类任务时,输入是”I Love Paris”,通过在输入的后面添加”I am ____”构成一个prompt,再将其输入到预训练语言模型中,因为prompt的形式与模型预训练输入的形式相同,这就要求模型完成预训练任务——补全句子或续写句子,这里的prompt要求模型选择可能性最大的词(通常是情感类的词,例如good)补全句子,之后可以根据模型填充的词进一步进行分类。
通过选择合适的prompt,就能控制模型的行为,即控制模型对于可能性最大的词的判断。一个合理的prompt是得到正确结果的前提,如下图所示,三种不同的prompt虽然语义相似,但是第一个却不能得到正确的结果。通过prompt,预训练语言模型自身就可以完成下游任务的预测,从而不同下游任务可以共用一个预训练语言模型的参数。

同时,prompt还能更好地适应few-shot(小样本),甚至zero-shot(零样本)的情况。当我们仅给模型输入以自然语言形式的任务描述和示例时,模型依然可以进行预测,而这一过程没有梯度的更新,如下图所示。

prompt虽然在参数共享和few-shot方面有着很好的表现,但其在下游任务的表现上较差。对于SuperGLUE任务,使用prompt方法的GPT-3模型得分是71.8,而参数量仅是其十分之一的T5-XXL模型却能取得89.3的得分。归根到底,不对预训练语言模型中的参数进行调整只能取得相对不错的成绩,而无法使模型完全学习到不同下游任务。那么,有没有什么办法是prompt和微调两个方法的折中呢?
三、adapter的原理与实现方法
为了在prompt与fine-tuning(微调)方法之间找到一个平衡,adapter被提了出来。adapter主要通过在预训练语言模型中添加额外参数的方式适配下游任务,不需要为每一个下游任务都训练一个全新的模型。具体来说,如果我们希望用BERT适配一个任务,首先在BERT的每一层中添加adapter,作为特定下游任务的可训练参数,然后将原本BERT的参数冻结不进行训练。这样,在具体下游任务微调过程中,只有adapter的参数进行了修改,原本属于BERT的参数则保持不变。
adapter的结构有很多,最简单的结构由一个下采样层和一个上采样层组成。为了限制参数量,通常下采样的维度很小,如果将模型原本d维的特征下采样为m维,则每个adapter中的参数量为2md+d+m。如果m<
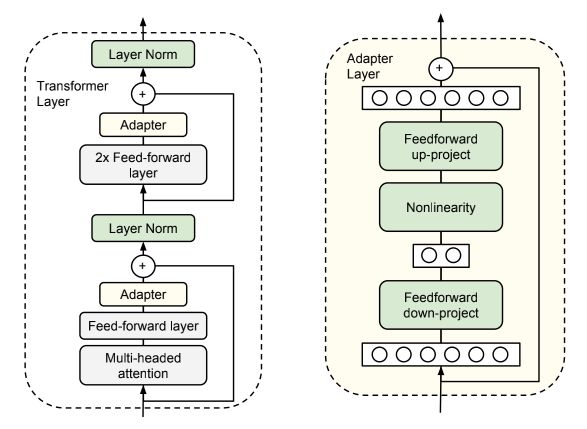
adapter的具体形式与添加位置可以有多个变种,这里选择最简单的一种进行介绍。如上图所示,adapter只包含两层全连接层,首先对输入进行下采样,再对下采样后的数据上采样回原始维度,需要注意的是这里还使用了残差连接。BERT中每层transformer encoder添加两个adapter,分别位于自注意力机制后面与FFN(feedforward network)后面。这样就构成了一个包含adapter的BERT模型,可以用于下游任务的微调了。实验证明,adapter中的参数非常高效:只需要adapter中少量的可训练参数,就可以达到fine-tuning方式中训练大量参数的效果,如下图所示。

adapter的优势在于,因为只有少量参数被修改,adapter-based tuning得到的模型参数与原预训练语言模型的参数很相似,避免了适配下游任务过程中的过拟合和泛化性差两个问题。固定原BERT的参数还极大的缓解了遗忘问题,实验表明,adapter-based tuning得到的模型相比于fine-tuning得到的模型,每层的输出都更接近于原始BERT中对应层的输出,从而更好地规则化(regularization)数据。
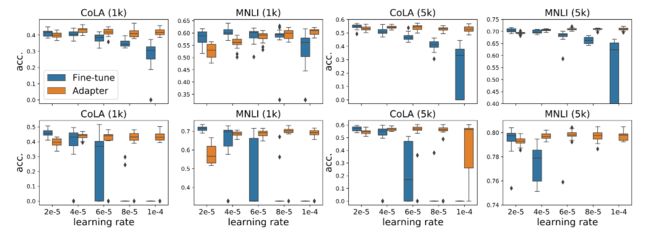
除了效果好外,adapter-based tuning过程更加稳定,对学习率的变化不敏感。下图对比了不同学习率下模型最终效果的分布,可以看到adapter方法的结果更加稳定,方差更小。
四、prompt与adapter的区分
prompt与adapter的核心都在于将预训练语言模型适配到不同下游任务的同时,尽量减少预训练参数的修改,毕竟预训练语言模型的参数量都非常大。两者的区别主要在于如何改变模型原本的行为。
prompt方式将模型视为一个黑盒,不对模型进行修改,而是通过构建新的输入,将原始输入包含起来作为其子序列,通过模型的自注意力机制改变模型对于原始输入的表示,可以形象的理解为,prompt不改变模型,而是告诉模型一些额外信息,让模型的行为发生变化。
adapter方式则将模型拆开来,为其添加新的组件,新的组件只针对一个特定的下游任务,而其他部分则可以共享。可以形象的理解为,BERT是吸尘器的主机,更换不同的吸头就如同更换不同的adapter,以此实现不同的功能。
五、总结
虽然BERT的出现开启了NLP的新时代,但巨大的参数量使其难以扩展到不同的下游任务。在这样的背景下,prompt与adapter的出现了顺应发展的要求,同时,prompt还展现了预训练语言模型的惊人潜力,极有可能成为后BERT时代一个新的发展方向。
本文简要介绍了prompt与adapter的原理与实现方法
在学术论坛中,蔺同学就两个方法
进行了详细的介绍与举例说明
感兴趣的同学快戳下方链接观看视频哟~
END

点击下方“阅读原文”查看论坛视频
↓↓↓
学术论坛第六期如何有效的使用预训练语言模型_哔哩哔哩_bilibili学术论坛第六期,我们请南加州大学硕士生,智能研究院算法实习生蔺同学分享了预训练语言模型在日志领域的应用 https://www.bilibili.com/video/BV1zR4y147BF?share_source=copy_web
https://www.bilibili.com/video/BV1zR4y147BF?share_source=copy_web