k8s 读书笔记 - 详解 Pod 调度(Ⅱ卷)
前缘再续
这缘分像一道桥,旌旗飘啊飘,你想走就请立马抽刀,爱一笔勾销。
路过,那就是缘分,留下,便是注定。
太阳不会因为你的失意,明天不再升起;月亮不会因为你的抱怨,今晚不再降落。

喜欢我的小伙伴欢迎关注我哟,风雨同舟,一路相伴!您的鼓励就是我成长的动力,一起学习,一起成长! 接下来我们再续前缘吧 === (* ̄︶ ̄)
Pod Priority Preemption,Pod 优先级调度
【特性状态】: Kubernetes v1.14 [stable]
对于运行各种负载(例如:Service、Job)的中等规模或者大规模的集群来说,由于各种原因,需要尽可能的 提高集群的资源利用率,为企业降本增效。而提高资源利用率的通常做法是采用优先级方案,即不同类型的负载对应不同的优先级,同时允许集群中的所有负载所需的资源总量超过集群可提供的资源,在这种情况下,当资源发生不足的情况时,系统可以选择释放一些不重要的负载(依据优先级最低标准),保障最重要的负载能够获取足够的资源稳定运行。
在 k8s v1.8 版本之前,当集群的可用资源不足时,在用户提交新的 Pod 创建请求后,该 Pod 会一直处于 Pending 状态,即使这个 Pod 是一个很重要(很有身份)的 Pod,也只能被动等待其他 Pod 被删除并释放资源,才能有机会被调度成功。k8s v1.8 版本引人了基于 Pod 优先级抢占(Pod Priority Preemption)的调度策略,此时 k8s 会尝试释放目标节点上低优先级的 Pod,以腾出空间(资源)安置高优先级的Pod,这种调度方式被称为 “抢占式调度”。在 k8s v1.11 版本中,该特性升级为 Beta 版本,默认开启,在后继的 k8s v1.14 版本中正式 Release。
Pod 优先级调度策略
如何声明一个负载相对其他负载 “更重要”? 我们可以通过以下几个维度来定义:
- Priority,优先级;
- QoS,服务质量等级;
- 系统定义的其他度量指标。
优先级抢占调度策略 的 核心行为 分别是 驱逐(Eviction) 与 抢占(Preemption),这两种行为的应用场景不同,但效果相同。
Eviction 是 kubelet 进程的行为,即当一个 Node 发生资源不足(under resource pressure)的情况时,该节点上的kubelet 进程会执行驱逐动作,此时 kubelet 会综合考虑Pod 的优先级、资源申请量与实际使用量等信息来计算哪些 Pod 需要被驱逐;当存在同样优先级的 Pod 需要被驱逐时,实际使用的资源量超过申请量最大倍数的高耗能 Pod 会被首先驱逐。对于QoS等级为“Best Effort”的 Pod 来说,由于没有定义资源申请(CPU/Memory Request),所以它们实际使用的资源可能非常大。Preemption 则是 Scheduler 执行的行为,当一个新的 Pod 因为资源无法满足而不能被调度时,Scheduler 可能(有权决定)选择驱逐部分低优先级的 Pod 实例来满足此 Pod 的调度目标,这就是Preemption 机制。
如何使用优先级和抢占?
要使用优先级和抢占:
- 新增一个或多个
PriorityClass。 - 创建 Pod,并将其
priorityClassName设置为新增的 PriorityClass。 当然你不需要直接创建 Pod;通常,你将会添加 priorityClassName 到集合对象(如 Deployment) 的 Pod 模板中。
说明:
Kubernetes 已经提供了 2 个 PriorityClass:system-cluster-critical和system-node-critical。 这些是常见的类,用于确保始终优先调度关键组件。
PriorityClass
PriorityClass 是一个无 Namespace(命名空间) 对象,它定义了从优先级类名称到优先级整数值的映射。 名称在 PriorityClass 对象 metadata(元数据)的 name 字段中指定。值在必填的 value 字段中指定。值越大,优先级越高。 PriorityClass 对象的名称必须是有效的 DNS 子域名, 并且它不能以 "system- " 为前缀。
PriorityClass 对象可以设置任何小于或等于 10 亿的 32 位整数值。 较大的数字是为通常不应被抢占或驱逐的关键的系统 Pod 所保留的。 集群管理员应该为这类映射分别创建独立的 PriorityClass 对象。
PriorityClass 还有两个可选字段:globalDefault 和 description。
globalDefault字段表示这个PriorityClass的值应该用于没有priorityClassName的 Pod。 系统中只能存在一个globalDefault设置为 true 的PriorityClass。 如果不存在设置了globalDefault的PriorityClass, 则没有 priorityClassName 的 Pod 的优先级为零。description字段是一个任意字符串。 它用来告诉集群用户何时应该使用此PriorityClass。
关于 PodPriority 和现有集群的注意事项
- 如果你升级一个已经存在的但尚未使用此特性的集群,该集群中已经存在的 Pod 的优先级等效于零。
- 添加一个将 globalDefault 设置为 true 的 PriorityClass 不会改变现有 Pod 的优先级。 此类 PriorityClass 的值仅用于添加 PriorityClass 后创建的 Pod。
- 如果你删除了某个 PriorityClass 对象,则使用被删除的 PriorityClass 名称的现有 Pod 保持不变, 但是你不能再创建使用已删除的 PriorityClass 名称的 Pod。
Pod 优先级调度示例
注意:Scheduler 可能会驱逐 Node A 上的一个 Pod 以满足 Node B 上的一个新 Pod 的调度任务。比如下面的这个例子:
一个低优先级的 Pod A 在 Node A(属于机架 R)上运行,此时有一个高优先级的 Pod B 等待调度,目标节点是同属机架 R 的 Node B,他们中的一个或全部都定义了 anti-affinity(反亲和性,或互斥性) 规则,不允许在同一个机架上运行,此时 Scheduler 只好 “丢车保帅”,驱逐低优先级的 Pod A 以满足高优先级的 Pod B 的调度。
抢占式 PriorityClass
示例步骤如下:
- 首先,集群管理员创建
ProrityClasses,名称为high-priority(注意:ProrityClasses 不属于任何 Namespace)。
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "此优先级类应仅用于 XYZ 服务 Pod。"
上述 YAML 文件定义了一个名为 high-priority 的优先级类别,优先级为 1000000 (数字越大,优先级越高),超过一亿的数字被系统保留,用于指派给系统组件。
- 接下来,我们可以在任意 Pod 中引用上面创建的名为
high-priority的优先级类别,如下所示:
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
priorityClassName: high-priority
如果发生了需要抢占的调度,高优先级 Pod 就可以能抢占节点 N,并将其低优先级 Pod 驱逐出节点 N,高优先级 Pod 的 status 信息中的 nominatedName 字段会记录目标节点 N 的名称。需要注意,高优先级 Pod 仍然无法保障最终被调度到节点 N 上,在节点 N 上低优先级 Pod 被驱逐的过程中,如果有新的节点满足高优先级 Pod 的需求,就会把它调度到新的 Node 上。而如果在等待低优先级的 Pod 退出的过程中,又出现了优先级更高的 Pod,调度器将会调度这个更高优先级的 Pod 到节点 N 上,并重新调度之前等待的高优先级 Pod。
非抢占式 PriorityClass
【特性状态】: Kubernetes v1.24 [stable]
配置了 preemptionPolicy: Never 的 Pod 将被放置在 调度队列 中较低优先级 Pod 之前, 但它们不能抢占其他 Pod。等待调度的非抢占式 Pod 将留在调度队列中,直到有足够的可用资源,它才可以被调度。非抢占式 Pod,像其他 Pod 一样,受调度程序回退的影响。 这意味着如果调度程序尝试这些 Pod 并且无法调度它们,它们将以更低的频率被重试,从而允许其他优先级较低的 Pod 排在它们之前。
注意:非抢占式 Pod 仍可能被其他高优先级 Pod 抢占。
非抢占式 PriorityClass 示例
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority-nonpreempting
value: 1000000
preemptionPolicy: Never # 默认值 PreemptLowerPriority,该值是区分抢占式和非抢占式的
globalDefault: false
# 此优先级类别不会导致其他 Pod 被抢占。
description: "This priority class will not cause other pods to be preempted."
抢占式 和 非抢占式 PriorityClass 的区别
取决于 preemptionPolicy 设置的值。preemptionPolicy 默认为 PreemptLowerPriority, 这将允许该 PriorityClass 的 Pod 抢占较低优先级的 Pod(现有默认行为也是如此)。如果 preemptionPolicy 设置为 Never,则该 PriorityClass 中的 Pod 将是非抢占式的。
数据科学工作负载是一个应用示例。用户可以提交他们希望优先于其他工作负载的作业, 但不希望因为抢占运行中的 Pod 而导致现有工作被丢弃。 设置为 preemptionPolicy: Never 的高优先级作业将在其他排队的 Pod 之前被调度, 只要足够的集群资源“自然地”变得可用。
优先级调度可能陷入的 “死循环” 状态
优先级抢占的调度方式可能会导致调度陷入 “死循环” 状态。当 k8s 集群配置了 多个调度器(Scheduler) 时,这一行为可能就会发生,比如下面的情况:
- 【Scheduler A】为了调度一个(或一批)Pod,特此在集群环境的某些 node 驱逐了一些 Pod,因此在集群中有了空余的资源空间可以用来调度,此时【Scheduler B】恰好抢在【Scheduler A】之前调度了一些新的 Pod,消耗了相应的 node 资源,因此,当【Scheduler A】清理完资源后正式发起 Pod 的调度时,却发现之前 “剩余的 node 空间” 资源不足,这时就会被目标节点的 kubelet 进程拒绝调度请求!这种情况的确无解,因此
最好的做法是让多个 Scheduler 相互协作来共同实现一个目标。
关于优先级抢占的调度策略的特别说明
使用优先级抢占的调度策略可能会导致某些 Pod 永远无法被成功调度。因此优先级调度不但增加了系统的复杂性,而且还可能带来额外不稳定的因素。因此,一旦发生资源紧张的局面,首先要考虑的是集群扩容,如果无法扩容,则再考虑有监管的优先级调度特性,比如结合基于 Namespace 的资源配额限制来约束任意优先级抢占行为。
警告:
在一个并非所有用户都是可信的集群中,恶意用户可能以最高优先级创建 Pod,导致其他 Pod 被驱逐或者无法被调度。 管理员可以使用ResourceQuota来阻止用户创建高优先级的 Pod。
参见《默认限制优先级消费》:https://kubernetes.io/zh-cn/docs/concepts/policy/resource-quotas/#limit-priority-class-consumption-by-default
关于《Pod 优先级和抢占》的更多信息,请查看:https://kubernetes.io/zh-cn/docs/concepts/scheduling-eviction/pod-priority-preemption/
DaemonSet,在每个节点上都调度一个 Pod
DaemonSet 是 k8s v1.2 版本新增的一种资源对象,用于 管理在集群中每个 Node 上仅运行一份 Pod 的副本实例,如下图所示:
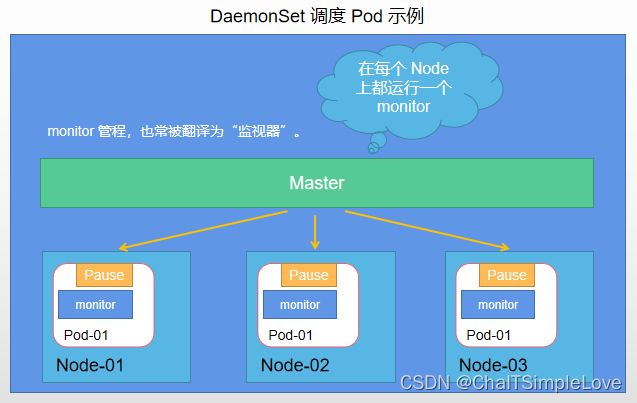
DaemonSet 应用场景
DaemonSet 的应用场景有以下几种情况:
- 在每个 Node 上都运行一个
GlusterFS存储或者Ceph存储的Daemon 守护进程。 - 在每个 Node 上都运行一个
日志采集程序,例如Fluentd或者Logstach。 - 在每个 Node 上都运行一个
性能监控程序,采集该 Node 的运行性能数据,例如:Prometheus Node Exporter、collectd、New Relic agent 或 Ganglia gmond等。
DaemonSet 的 Pod调度策略与 RC/RS 类似,除了使用系统内置的算法在每个 Node 上进行调度,也可以在 Pod 的定义中使用 NodeSelector 或 NodeAffinity 属性来指定满足条件的 Node 范围进行调度。
- 一种【简单的用法】是 为每种类型的守护进程在所有的节点上都启动一个 DaemonSet。
- 一个【稍微复杂的用法】是 为同一种守护进程部署多个 DaemonSet;每个具有不同的标志, 并且对不同硬件类型具有不同的
Memory、CPU要求。
DaemonSet 的 yaml 文件定义示例
举例:定义为在每个 Node 上都启动一个 fluentd 容器,配置文件 fluentd-ds.yaml 定义如下:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations:
# 这些容忍度设置是为了让该守护进程集在控制平面节点上运行
# 如果你不希望自己的控制平面节点运行 Pod,可以删除它们
- key: node-role.kubernetes.io/control-plane
operator: Exists
effect: NoSchedule
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
containers:
- name: fluentd-elasticsearch
image: quay.io/fluentd_elasticsearch/fluentd:v2.5.2
# 资源限额
resources:
limits:
cpu: 200m
memory: 500Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
基于 YAML 文件创建 DaemonSet:
kubectl create -f fluentd-ds.yaml
# 或者
kubectl apply -f fluentd-ds.yaml
其实 k8s 本身就在用 DaemonSet 运行系统组件。执行如下命令:
kubectl get daemonset --namespace=kube-system
查看系统组件运行的 Pod 信息:
kubectl get pod --namespace=kube-system
说明:
查看系统组件,需要在命令行中通过--namespace=kube-system指定namespace kube-system。如果不指定则只返回默认namespace default中的资源。
DaemonSet 部署系统组件
关于 k8s 系统默认组件,我们以 《1 Master(kube-apiserver、kube-schedular、contorller-manager`)+ 2 Node(kubelet、kube-proxy、container_runtime【容器引擎的运行环境】)架构为例》 ,来介绍各个组件,k8s 架构如下图所示:

Master 组件
- kube-apiserver:Kubernetes API 集群的统一入口,各组件的协调者,以
HTTP/RESTful API方式提供接口,所有的对象资源的增删改查(CRUD)和 监听操作都交给APIServer处理后再提交给etcd数据库做持久化存储。 - kube-controller-manager:
controller处理集群中常规后台任务,一个资源对应一个控制器,而controller-manager就是负责管理这些控制器的。 - kube-scheduler:根据 调度算法 为新创建的 Pod 选择一个 Node 节点,可以任意部署,可以部署在同一个 Node 上,也可以部署在不同的 Node 上。
- etcd:
分布式键值(key-value)存储系统,用于 保存集群状态数据,比如Pod、Service等对象信息。
说明:
etcd 可以独立部署,或者使用已有的集群环境,生产环境为了保障高可用性,推荐使用奇数台 node 部署 etcd 集群环境(比如:3、5、7、9 …台 node 部署 etcd 集群)。
Node 组件
- kubelet:kubelet 是 Master 在 Node 节点上的 Agent 进程,管理本机运行容器的生命周期,比如创建容器、Pod 挂载数据卷(Volume)、下载 Secret、获取容器和节点状态等工作,kubelet 将每个 Pod 转换成一组容器。
- kube-proxy:在 Node 节点上实现 Pod 网络代理,维护网络规则和四层负载均衡工作。实现让 Pod 节点(一个或者多个容器)对外提供服务(比如:
Service 就是依赖 kube-proxy 提供的)。 - container runtime:遵循 CRI 插件接口 的容器引擎或运行时,提供容器的运行环境。CRI 是一个插件接口,它使 kubelet 能够使用各种容器运行时,无需重新编译集群组件。你需要在集群中的每个 node 上都有一个可以正常工作的
容器运行时(container runtime),这样 kubelet 能启动 Pod 及其容器。容器运行时接口(Container Runtime Interface,CRI)是 kubelet 和 容器运行时之间通信的主要协议。
说明:
kubelet 是唯一没有被 Pod 化的系统组件。
在 Kubernetes 中几个常见的容器运行时(container runtime):
- containerd,k8s v1.24 默认的容器运行时
- CRI-O
- Docker Engine
- Mirantis Container Runtime
说明:
从 k8s v1.24.x 版本以后,默认使用遵循 CRI(Container Runtime Interface,容器运行时接口) 规范的 容器运行时(Container Runtime )。
更多信息请查看:
- 《容器运行时接口(CRI)》https://kubernetes.io/zh-cn/docs/concepts/architecture/cri/
- 《容器运行时》https://kubernetes.io/zh-cn/docs/setup/production-environment/container-runtimes/
我们提到 DaemonSet 可以用来运行系统组件,通常在 kube-system 的 Namespace 下面,比如:可以用来运行 容器网络插件 (Container Network Interface,CNI) & kube-proxy,k8s 是一个 “扁平化网络” 环境,遵循 CNI 规范。
DaemonSet 更新
如果节点的 Label 标签被修改,DaemonSet 将立刻向新匹配上的节点添加 Pod, 同时删除不匹配的节点上的 Pod。
你可以修改 DaemonSet 创建的 Pod。不过并非 Pod 的所有字段都可更新。 下次当某节点(即使具有相同的名称)被创建时,DaemonSet 控制器还会使用最初的模板。
你可以删除一个 DaemonSet。如果使用 kubectl 并指定 --cascade=orphan 选项, 则 Pod 将被保留在节点上。接下来如果创建使用相同选择算符的新 DaemonSet, 新的 DaemonSet 会收养已有的 Pod。 如果有 Pod 需要被替换,DaemonSet 会根据其 updateStrategy(更新策略) 来替换。
DaemonSet 执行 RollingUpdate(滚动更新)
还可以对 DaemonSet 执行 RollingUpdate(滚动更新) 操作。
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
spec:
# 更新策略
updateStrategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
updateStrategy 的另外一个值是 OnDelete,即只有手工删除 DaemonSet 创建的 Pod 副本,新的 Pod 副本才会被创建出来。如果不设置 updateStrategy 的值,则在 k8s v1.6 之后的版本会被默认为 RollingUpdate。
我们继续以名为 fluentd-elasticsearch 的 DaemonSet 的 fluentd-ds.yaml 文件定义举例,DaemonSet 执行 RollingUpdate(滚动更新) 完整示例如下:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
updateStrategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations:
# 这些容忍度设置是为了让该守护进程集在控制平面节点上运行
# 如果你不希望自己的控制平面节点运行 Pod,可以删除它们
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd-elasticsearch
image: quay.io/fluentd_elasticsearch/fluentd:v2.5.2
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
Deployment 执行 RollingUpdate(滚动更新)
DaemonSet 执行 RollingUpdate(滚动更新)与 Deployment 控制器类似,我们回顾下 Deployment 控制器的滚动更新:
服务在滚动更新时,Deployment 控制器的目的是:给旧版本(old_rs)副本数减少至0、给新版本(new_rs)副本数量增至期望值(replicas)。大家在使用时,通常容易忽视 控制速率的特性,以下是 kubernetes 提供的两个参数:
- maxUnavailable:和期望ready的副本数比,不可用副本数最大比例(或最大值),这个值越小,越能保证服务稳定,更新越平滑;
- maxSurge:和期望ready的副本数比,超过期望副本数最大比例(或最大值),这个值调的越大,副本更新速度越快。
取值范围
- maxUnavailable: [0, 副本数]
- maxSurge: [0, 副本数]
比例
- maxUnavailable: [0%, 100%] 向下取整,比如10个副本,5%的话==0.5个,但计算按照0个;
- maxSurge: [0%, 100%] 向上取整,比如10个副本,5%的话==0.5个,但计算按照1个;
注意:两者不能同时为 0。
建议配置
- maxUnavailable == 0
- maxSurge == 1
生产环境提供给用户的默认配置。即 “一上一下,先上后下” 最平滑原则:1个新版本 pod ready(结合Readiness)后,才销毁旧版本pod。此配置适用场景是 平滑更新、保证服务平稳,但也有缺点,就是 “太慢” 了。
说明:
Readiness 探针用来判断这个容器是否启动完成,即 pod 的 condition(条件) 是否 ready(就绪态)。 如果探测的一个结果是不成功,那么此时它会从 pod 上 Endpoint 上移除,也就是说从接入层上面会把前一个 pod 进行摘除,直到下一次判断成功,这个 pod 才会再次挂到相应的 endpoint 之上。
Deployment 控制器调整 replicas 数量时,严格通过以下公式来控制发布节奏。所以,如需快速发布,可根据实际情况去调整这两个值:
(目标副本数-maxUnavailable) <= 线上实际Ready副本数 <= (目标副本数+maxSurge)
举例:如果期望副本数是 10,期望能有至少 80% 数量的副本能稳定工作,所以:maxUnavailable = 2,maxSurge = 2 (可自定义,建议与 maxUnavailable 保持一致)。
apiVersion: apps/v1
kind: Deployment
metadata:
name: web
namespace: default
spec:
replicas: 3
selector:
matchLabels:
app: web
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
关于 DaemonSet 更多信息,请查看:
- 《工作负载资源 / DaemonSet》https://kubernetes.io/zh-cn/docs/concepts/workloads/controllers/daemonset/
- 《对 DaemonSet 执行滚动更新》https://kubernetes.io/zh-cn/docs/tasks/manage-daemon/update-daemon-set/
- 《maxUnavailable 和 maxSurge》https://www.gl.sh.cn/2021/12/18/maxunavailable_he.html
Job,批处理调度
k8s 从 v1.2 版本开始支持批处理类型的应用,可以通过 k8s 的 Job 资源对象来定义一个批处理任务。
-
Job 资源对象会创建一个或者多个 Pod,并将继续重试 Pod 的执行,直到指定数量的 Pod 成功终止。 随着 Pod 成功结束,Job 跟踪记录成功完成的 Pod 个数。 当数量达到指定的成功个数阈值时,任务(即 Job)结束。 删除 Job 的操作会清除所创建的全部 Pod。 挂起 Job 的操作会删除 Job 的所有活跃 Pod,直到 Job 被再次恢复执行。 -
批处理任务通常并行(或者串行)启动多个计算进程去处理一批 工作项(work item),处理完成后,整个批处理任务结束。
Job 模式概述
Job 对象可以用来支持多个 Pod 的可靠的并发(并行)执行。按照批处理任务实现方式的不同,批处理任务可以分为下面几种模式:

- Job Template Expansion 模式:
一个 Job 对象对应一个待处理的 Work item,有几个 Work item 就产生几个独立的 Job,通常适合 Work item 数量少、每个 Work item 要处理的数据量比较大的场景,比如有一个 100GB 的文件作为一个 Work item,总共有 10 个文件需要处理。 - Queue with Pod Per Work Item 模式:
采用一个 Work Queue(工作队列)存放多个 Work item(工作项),一个 Job 对象作为消费者去完成这些 Work item,在这种模式下,Job 会启动 N 个 Pod,每个 Pod 都对应一个 Work item。 - Oueue with Variable Pod Count 模式:也是
采用一个 Work Queue 存放多个 Work item,一个 Job 对象作为消费者去完成这些 Work item,但与上面的模式不同,Job 启动的 Pod 数量是可变的。 - Single Job with Static Work Assignment 的模式:也是
一个 Job 产生多个 Pod,但它采用程序静态方式分配 Work item,而不是采用队列模式进行动态分配。
批处理任务的模式对比
下面是对这些权衡的汇总,模式的名称对应了相关示例和更详细描述的链接。
| 模式 | 推荐 | 单个 Job 对象 | Pod 数少于 Work item 数 | 直接使用应用无需修改 | k8s 是否支持 |
|---|---|---|---|---|---|
| Job 模板扩展(Job Template Expansion) | / | / | / | ✓ | ✓ |
| 每个工作项目具有 Pod 的队列(Queue with Pod Per Work Item) | ✓ | ✓ | / | -✓ 有时候需要 | ✓ |
| Pod 数量可变的队列(Oueue with Variable Pod Count) | ✓ | ✓ | / | / | ✓ |
| 静态任务分派的单个作业的 Job(Single Job with Static Work Assignment) | / | ✓ | / | ✓ | / |
Job 的并行执行
对于批处理的并行问题,k8s 将 Job 分为以下三种类型:
1、Non-parallel Jobs,非并行 Job
- 通常一个 Job 只启动一个 Pod,除非 Pod 失败(或者异常),才会重启该 Pod。
- 一旦该 Pod 正常结束(成功终止),Job 将结束。
2、Parallel Jobs with a fixed completion count,具有确定完成计数的并行 Job
- 并行 Job 会启动多个 Pod,此时需要设定 Job 的
.spec.completions参数为一个非 0 的正数值。 - Job 用来代表整个任务,当正常结束的 Pod 数量达到
.spec.completions参数设定的值后,Job 结束。 - Job 的
.spee.parallelism参数用来控制并行度,即同时启动几个 Job 来处理 Work Item。 - 当使用
.spec.completionMode="Indexed"时,每个 Pod 都会获得一个不同的索引值,介于0和.spec.completions-1之间。
3、Parallel Jobs with a work queue,带工作队列的并行 Job
任务队列方式的并行 Job 需要一个独立的 Queue,Work item 都在一个 Queue 中存放,不能设置 Job 的 .spec.completions 参数,此时 Job 有以下特性:
- 不设置 spec.completions,默认值为 .spec.parallelism。
- 多个 Pod 之间必须相互协调,或者借助外部服务确定每个 Pod 要处理哪个 Work item 。 例如,任何一个 Pod 都可以从 Work Queue 中取走最多 N 个 Work item 。
- 每个 Pod 都能独立判断和决定是否还有 Work item 需要处理(或者其它 Pod 是否都已完成),进而确定 Job 是否完成。
- 当 Job 中某一个 Pod 正常结束(成功完成),则 Job 不会再创建新的 Pod。
- 一旦任何一个 Pod 成功完成,任何其它 Pod 都不应再对此任务执行任何操作或生成任何输出。 所有 Pod 都应启动退出过程,它们应该都处于即将结束、退出的状态。
- 如果所有 Pod 都结束了,且至少有一个 Pod 成功结束,则整个 Job 成功结束。
批处理模型在 k8s 中的应用举例
下面分别讲解常见的三种 批处理模型 在 Kubernetes 中的应用例子。
1、Job Template Expansion(Job 模板扩展)模式
特点:一个
Work item(工作项)对应一个 Job 实例。
首先定义一个 Job 模板,模板(template) 里的主要参数是 Work item 的 标识($ITEM),因为每个 Job 都处理不同的 Work item。如下所示的 Job 模板(文件名为 job.yaml.txt)中的 SITEM 可以作为任务项的标识:
apiVersion: batch/v1
kind: Job
metadata:
name: process-item-$ITEM
labels:
jobgroup: jobexample
spec:
template:
metadata:
name: process-item-$ITEM
labels:
jobgroup: jobexample
spec:
containers:
- name: c
image: busybox
command: ["/bin/sh", "-c", "echo Processing item $ITEM && sleep 5"]
restartPolicy: Never
backoffLimit: 4 # 表示回退限制,可以指定重试几次后将 Job 标记为失败。
注意上面的 job.yaml.txt 文件是定义 Job 的 yam 文档模板,下面我们通过 shell 脚本操作,生成 3 个对应的 Job 定义的 .yaml 文件,并创建 Job。
# for i in apple banana cherry
> do
> cat job.yaml.txt | sed "s/\$ITEM/$i" > ./jobs/job-$1.yaml
> done
# ls jobs
job-apple.yaml job-banana.yaml job-cherry.yaml
# kubectl create -f jobs
job "process-item-apple" created
job "process-item-banana" created
job "process-item-cherry" created
查看 Job 的运行情况:
# kubectl get jobs -l jobgroup=jobexample
NAME DESIRED SUCCESSFUL AGE
process-item-apple 1 1 4m
process-item-banana 1 1 4m
process-item-cherry 1 1 4m
2、Queue with Pod Per Work Item(每个工作项目具有 Pod 的队列)模式
特点:需要一个
Work Queue存放Work item,Job 会启动 N 个 Pod,每个 Pod 都对应一个 Work item。
提到 Queue 队列,这里我们以 RabbitMQ 举例,客户端(Client)程序先要把处理的任务变成 Work item 存放到 RabbitMQ,然后编写 Worker 程序(比如:.net worker service)打包 image 镜像并定义成为 Job 中的 Work Pod。
Worker 程序的实现逻辑是从任务队列中拉取一个 Work item 并随即处理,在成功处理完成后即结束进程。如下图所示:
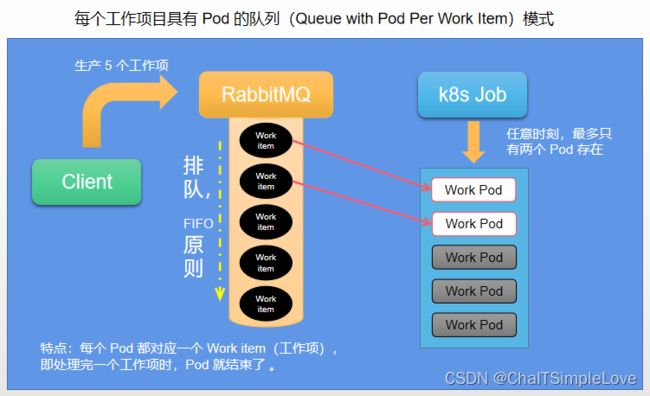
3、Oueue with Variable Pod Count(Pod 数量可变的队列)模式
特点:需要一个
Work Queue存放Work item,Job 启动的 Pod 数量是可变的。
该模式下 Worker 程序需要知道 Oueue 队列中是否有等待处理的 Work item,如果有就需要取出来处理,否则就认为所有工作完成并结束进程,因此任务队列通常要采用 Redis 或者 DB 数据库来实现。如下图所示:

说明:
RabbitMQ 并不能让 Client 客户端知道是否没有数据(客户端只能被动的等待),因此这里我们采用 Redis 队列举例。
关于 Job 的更多信息,请查看:https://kubernetes.io/zh-cn/docs/concepts/workloads/controllers/job/
CronJob,定时任务
【特性状态】: Kubernetes v1.21 [stable]
k8s 从 v1.5 版本开始新增了一种类型的 Job,即类似 Linux Cron 的定时任务 Cron Job。
CronJob 官方定义
CronJob 创建基于时隔重复调度的 Jobs。
一个 CronJob 对象就像 crontab (cron table) 文件中的一行。 它用 Cron 格式进行编写, 并周期性地在给定的调度时间执行 Job。
CronJob 的定时表达式
基本照搬了 Linux Cron 的表达式,格式如下:
# Minutes Hours DayofMonth Month DayofWeek
# ┌───────────── 分钟 (0 - 59)
# │ ┌───────────── 小时 (0 - 23)
# │ │ ┌───────────── 月的某天 (1 - 31)
# │ │ │ ┌───────────── 月份 (1 - 12)
# │ │ │ │ ┌───────────── 周的某天 (0 - 6)(周日到周一;在某些系统上,7 也是星期日)
# │ │ │ │ │ 或者是 sun,mon,tue,web,thu,fri,sat
# │ │ │ │ │
# │ │ │ │ │
# * * * * *
| 输入 | 描述 | 相当于 |
|---|---|---|
| @yearly (or @annually) | 每年 1 月 1 日的午夜运行一次 | 0 0 1 1 * |
| @monthly | 每月第一天的午夜运行一次 | 0 0 1 * * |
| @weekly | 每周的周日午夜运行一次 | 0 0 * * 0 |
| @daily (or @midnight) | 每天午夜运行一次 | 0 0 * * * |
| @hourly | 每小时的开始一次 | 0 * * * * |
其中每个域都可出现的字符如下:
- Minutes :可出现 “,” “-” “*” “/” 这4个字符,有效范围为 0~59 的整数。
- Hours :可出现 “,” “-” “*” “/” 这4个字符,有效范围为 0~23 的整数。
- DayofMonth : 可出现 “,” “-” “*” “/” “?” “L” “W” “C” 这8个字符,有效范围为 0~31 的整数。
- Month :可出现 “,” “-” “*” “/” 这4个字符,有效范围为 0~12 的整数或者 JAN ~ DEC。
- DayofWeek : 可出现 “,” “-” “*” “/” “?” “L” “W” “C” 这8个字符,有效范围为 0~7 的整数或者 SUN ~ SAT。1表示星期天,2表示星期一,依此类推。
表达式中的特殊字符 “*” 与 “/” 的含义如下:
- “*” :表示匹配改域的任意值,假如在 Minutes 域使用该符号,则表示每分钟都会触发事件。
- “/” :表示从起始时间开始触发,假如每隔固定时间触发一次,例如在 Minutes 域设置为 5/20,则意味着第1次触发在 5min 时,接下来每 20min 触发一次,将在 25min 触发第 2 次,45min 触发第 3 次,依次周期执行。
举例,比如需要每隔 1min 执行一次任务,则 Cron 表达式如下:
*/1 * * * *

要生成 CronJob 时间表表达式,你还可以使用 crontab.guru 之类的 Web 工具。
- crontab.guru =》https://crontab.guru/

CronJob 示例
在每分钟打印出当前时间和问候消息(Hello k8s),CronJob 资源对象的 hello-cj.yaml 文件的定义如下:
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
schedule: "* * * * *" # cron 表达式
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox:1.28
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- date; echo Hello k8s
restartPolicy: OnFailure
Pod 重启策略(restartPolicy):
- 1、Always:当容器终止退出后,总是重启容器,默认策略。
- 2、OnFailure:当容器异常退出(退出状态码非0)时,才重启容器。
- 3、Never:当容器终止退出,从不重启容器。
Pod 镜像拉取策略(imagePullPolicy):
- 1、IfNotPresent:优先使用本地:如果本地存在镜像,则使用本地的,不管仓库是否可用。不管仓库中镜像与本地是否一致。
- 2、Always:总是拉取。首先获取仓库镜像信息,如果仓库中的镜像与本地不同,那么仓库中的镜像会被拉取并覆盖本地。如果仓库中的镜像与本地一致,那么不会拉取镜像。如果仓库不可用,那么 pod 运行失败。
- 3、Never:只使用本地镜像,如果本地不存在,则 pod 运行失败
hello-cronjob.yaml 文件中定义的 Cron 表达式,每隔 1min 执行一次任务,运行的 image 镜像是 busybox 版本 1.28,执行 shell 脚本,在控制台输出当前时间(未指定时区时,默认为本地时区)和字符串 “Hello k8s”。
执行命令创建上面定义的 CronJob 资源对象:
kubectl create -f hello-cj.yaml
cronjob "hello" created
接下来每隔 1min 查看任务状态,检查验证是否每隔 1min 调度了一次:
kubectl get cronjob hello
输出类似如下的信息:
NAME SCHEDULE SUSPEND ACTIVE LAST-SCHEDULE
hello */1 * * * * False 0 Thu, 02 Aug 2022 22:14:00 -0700
查看 CronJob 对应的 Container 容器,检查验证是否每隔 1min 调度了一次:
crictl ps -a | grep busybox
输出类似如下的信息:
CONTAINER ID IMAGE CREATED STATE NAME ATTEMPT
1f73f2d81bf98 busybox@sha256:141c253bc4c3fd0a201d32dc1f493bcf3fff003b6df416dea4f41046e0f37d47 1 minutes ago Running sh 1
9c5951df22c78 busybox@sha256:141c253bc4c3fd0a201d32dc1f493bcf3fff003b6df416dea4f41046e0f37d47 2 minutes ago Exited sh 0
查看任意一个容器的 logs 日志:
# 查看某一个容器的全部日志
crictl logs 1f73f2d81bf98
# 获取最近的 N 行日志
crictl logs --tail=1 1f73f2d81bf98
输出类似如下的信息:
Thu Aug 02 22:14:00 UTC 2022
Hello k8s
除了上面的命令方式查看 CronJob 执行信息,还可以通过如下命令更直观的查看任务执行的历史和现状:
# kubectl get jobs --watch
NAME DESIRED SUCCESSFUL AGE
hello-1498761060 1 1 30m
hello-1498761120 1 1 29m
hello-1498761180 1 1 28m
上面输出的信息中,SUCCESSFUL 列为 1 的每一行都是一个调度成功的 Job,以第 1 行的 “hello-1498761060” 为 Job 为例,它对应的 Pod 可以通过如下方式得到:
# kubectl get pods --show-all | grep hello-1498761060
hello-1498761060-shpwx 0/1 Completed 0 36m
查看该 Pod(hello-1498761060-shpwx) 的日志:
# kubectl logs hello-1498761060-shpwx
Thu Aug 02 22:14:00 UTC 2022
Hello k8s
最后,当我们不需要某个 CronJob 时,可以通过下面的命令执行删除:
# kubectl delete cronjob hello
cronjob "hello" deleted
关于命令行更多信息,请查看:
- 《工作负载资源 / CronJob》:https://kubernetes.io/zh-cn/docs/concepts/workloads/controllers/cron-jobs/
- 《 crictl 命令》:https://kubernetes.io/zh-cn/docs/tasks/debug/debug-cluster/crictl/
- 《命令行工具 (kubectl)》:https://kubernetes.io/zh-cn/docs/reference/kubectl/
- 《kubectl-commands》:https://kubernetes.io/docs/reference/generated/kubectl/kubectl-commands
自定义调度器
如果对于 k8s 的默认调度器(kube-scheduler)的众多特性功能还无法满足我们的独特需求,则可以用我们自行开发的调度器替换默认的调度器,执行调度任务。
使用自定义调度器
通常情况,每个新的 Pod 都会由默认的调度器进行调度。但是如果在 Pod 中提供了自定义的调度器名称,此时默认的调度器就会忽略该 Pod,转由指定的调度器完成该 Pod 的调度任务。
使用自定义调度器的示例:
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
# 指定自定义调度器名称
schedulerName: my-scheduler
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
说明:
如果自定义的调度器(my-scheduler)还未在 k8s 集群环境中部署,则默认的调取器会忽略这个 Pod,并且该 Pod 将会永远处于 Pending 状态。
如何创建自定义调度器?
可以用任何语言来实现简单或复杂的自定义调度器。接下来我们通过 bash 脚本实现一个简单的例子,该实例的调度策略是随机选择一个 Node。
注意:这个自定义的调度器需要通过
kubectl proxy来运行。
编辑 my-scheduler.sh 文件:
vi my-scheduler.sh
在 my-scheduler.sh 文件中写入如下 bash 脚本:
#!/bin/bash
SERVER:'localhost:8001'
while true;
do
for PODNAME in $(kubectl --server $SERVER get pods -o json | jq '.items[] | select(.spec.schedulerName == "my-scheduler") | select(.spec.nodeName == null) |.metedata.name' | tr -d '"');
do
NODES=($(kubectl --server $SERVER get nodes -o json | jq '.items[].metedata.name' | tr -d '"'))
NUMNODES=${#NODES[@]}
CHOSEN=${NODES[$[ $SERVER % $NUMNODES]]}
curl --header "Content-Type: application/json;charset=UTF-8" --request POST --data '{"apiVersion":"v1","kind":"Binding","metadata":{"name":"'$PODNAME'"},"target":{"apiVersion":"v1","kind":"Node","name":"'$CHOSEN'"}}'
echo "Assigned $PODNAME to $CHOSEN"
done
sleep 1
done
一旦这个自定义调度器成功启动,上面定义的 Pod 就会被正确地调度到某个 Node 上(随机选择)。
关于 kubectl proxy 命令说明
我们前面的文章介绍 Pod 的基本概念,当在集群环境中的 Pod 上开放一个 Port(端口)并用 ClusterIP Service 绑定创建的一个内部服务,如果没有开放 NodePort 或 LoadBalancer 等 Service 的话,我们是无法在集群外网访问这个内部 Pod 服务的(除非修改了 CNI 插件等)。
1、kubectl proxy 命令语法
| 操作 | 语法 | 描述 |
|---|---|---|
| proxy | kubectl proxy [–port=PORT] [–www=static-dir] [–www-prefix=prefix] [–api-prefix=prefix] [flags] | 运行访问 Kubernetes API 服务器的代理。 |
如果想 临时 在本地和外网调试的话,kubectl proxy 似乎是个不错的选择。使用如下:
# kubectl proxy --insecure-skip-tls-verify --address='0.0.0.0' --accept-hosts='^*$' --port=8001
但其实 kubectl proxy 转发的是 apiserver 所有的能力,而且是 默认不鉴权 的,所以 --address=0.0.0.0 就是极其危险的了。
危险: kubectl proxy 这个子命令有安全隐患(比如:蠕虫利用),慎重使用!
2、kubectl proxy 命令参考文档
关于 kubectl proxy 命令更多信息,请查看如下文档和资料
- 《命令行工具 (kubectl)》,https://kubernetes.io/zh-cn/docs/reference/kubectl/
- 《kubectl-commands#proxy》,https://kubernetes.io/docs/reference/generated/kubectl/kubectl-commands#proxy
- 《运行 Kubernetes API 服务器的代理》,http://kubernetes.kansea.com/docs/user-guide/kubectl/kubectl_proxy/
- 《kubectl proxy》,https://topgoer.cn/docs/kubernetes_defense/kubernetes_defense-1dt3gq5so6fo5
遇见未来,你是否再来
