ElasticSearch大集群管理维护的难题与个推GProxy解决方案
前言
用户搜索组件和日志管理平台是个推推送服务的重要组成部分。ElasticSearch(简称ES)作为一个开源的分布式搜索引擎,能较好地满足上述要求。个推在ES的使用上经过了多年迭代,积累了丰富的经验,特别是在数据量不断增大时,如何管理集群、维护集群稳定、优化集群性能,我们进行了许多实践。
本文将从三部分讲述个推ElasticSearch架构的演变过程:大集群的挑战、GProxy如何支持多集群以及当前运行情况。

作者| 个推平台研发总监 逍遥 &高级Java工程师 南洋
01个推ES服务概述
个推使用ES的业务场景主要是对用户信息增删改查和日志存储,是支持个推推送的核心服务之一,其特点是:
● 数据更新快:需要实时更新用户画像等信息
● 查询条件复杂:支持多种维度交并补,组合条件搜索
● 查询数据量大:一个推送任务可能会需要查询千万级的数据
我们选择ES的原因主要有三:
● 提供近实时索引,最短可以在1s内搜索到写入的文档
● 能够支持复杂条件的查询,满足我们各种检索条件的需求
● 分布式特性能够较好地满足水平扩容和高可用的要求
此外,ES官方和社区都非常活跃,周边的生态产品也多,遇到问题基本能够很好地得到解决。
02大集群的挑战
个推集群演进
![]()

上图展示的是个推ES集群演进的过程。个推使用ES时间较早,起初从0.20.x版本开始用,当时集群规模较小,后来为了scroll查询结果不带source,进行了index-source的分离,升级到了0.90.x版本。接着官方推出了支持无source查询功能的1.2.0版本,我们又进行了集群合并。随后,为了使用官方的一些新特性,我们升级到了1.4.x和1.5.x版本。
此时,集群规模已经很大了,升级一次版本比较不方便,而且后续的新特性对我们没有很强的吸引力,于是很长时间没升级,跳过了官方推出的2.x版本。但集群由于规模大,开始出现很多难以解决的问题,需要进行拆分升级,并且官方版本也更新到了5.x版本,不支持直接从1.x升级5.x,于是我们考虑用数据网关的方式解决升级、重启的困难,集群也演化到了上图的最后一版架构。
大集群的问题
大集群还带来很多问题,以下是我们在使用过程中遇到相对比较棘手的几个问题。
● 第一个问题是JVM内存容易居高不下。
ES内存的占用主要有几个部分:Segment Memory、Filter Cache、Field Data cache 、Bulk Queue、Indexing Buffer和Cluster State Buffer 。Segment Memory会随着段文件增长而增长,大集群这块内存占用没法避免。
Filter Cache和Field Data cache个推用到的场景不多,我们便通过参数配置予以禁用。Bulk Queue和Indexing Buffer都比较固定,内存不会不断增长,也没必要调整参数。Cluster State Buffer是当时比较棘手的一个问题,我们设置mapping的方式是在config目录下配置default_mapping.json文件,该文件会匹配所有写入的文档,进行格式解析处理,ES处理解析过之后会在内存中缓存一份ParserContext。而由于type数不断增加,这部分内存占用会越来越多,直到耗尽,如果不索引新type,则不会增长。
在出现内存居高不下的问题时,我们分析了它的dump文件,如下图,发现是ParserContext占用导致的。当时没有很好的办法彻底解决,只能采用重启的方式清空ParserContext,暂时缓解一段时间。但随着文档的不断写入,这部分内存占用还是会重新变大。
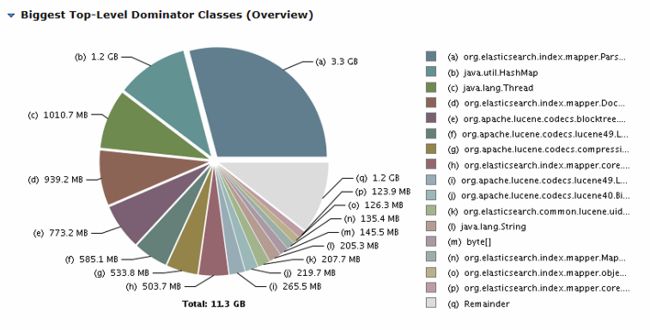
● 第二个问题是超大分片和超大段。
我们默认使用docid作为routing的依据,通过hash算法将文档散列到不同分片上。这种方式在文档数少的时候分片大小还比较均匀,但当文档数涨到了一定程度时,分片的大小差距会变大。在每个分片平均100g大小的时候,差距最大可达20g。此时,达到最大段阈值限制的段数量也非常多,这导致在段合并的时候比较耗时。
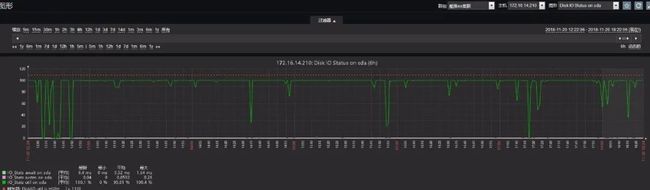
● 第三个问题是磁盘IO高。
我们经常使用scroll查询文档,超大的段文件会导致文件磁盘查找效率降低。并且机器内存被ES节点的JVM占用了大半,致使文件系统很难使用内存缓存段文件页。这就导致scroll查询会直接读取磁盘文件,IO被打满。从监控看,集群的IO基本是时刻处于满的状态。
![]()
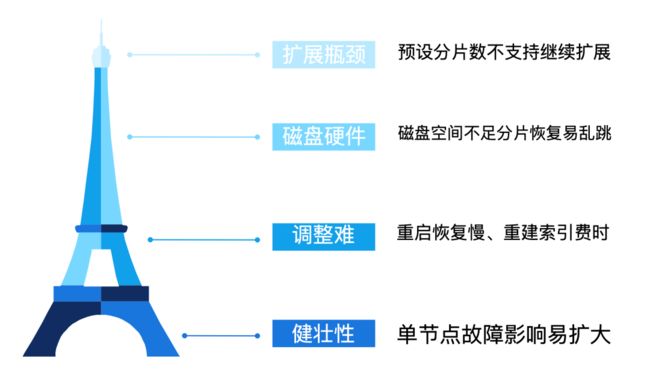
此外还有许多隐患。
首先是扩展瓶颈,集群预设的分片数原本是较充裕的,然而在经过多次扩容后,实例数已经和分片数相等了,扩容实例后,集群也不会将分片分配到新实例。其次是原先机器的磁盘空间逐渐不足,ES默认水位线是85%,到达后分片就会开始乱跳难以恢复。
然后是调整难,重启恢复非常慢,如果升级重建,索引也很慢。
最后集群的健壮性也会受到影响。文档数变大,压力也会变大,更容易出现故障,某个实例故障后压力会分摊给其他节点,业务会产生感知。
![]()
03 GProxy的解决方案
对于上面描述的这些问题,我们希望找到一个解决方案能够提供如下功能:
1、能够平滑升级集群版本,并且升级期间不影响业务使用
2、通过拆分大集群为小集群,使业务分流,减轻集群压力
3、提供集群数据的多IDC热备,为异地多活提供数据层支持
但是之前的架构中,业务服务直接访问ES集群,耦合严重,要实现这些需求就变得比较困难。于是,我们选择了proxy-based架构,通过增加中间层proxy来隔离存储集群和业务服务集群,为更灵活的运维存储集群提供支持。
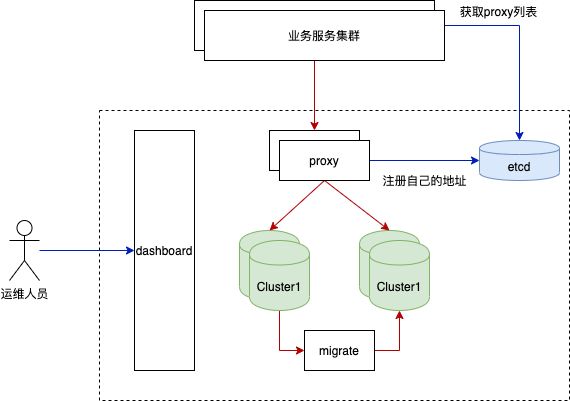
上图是GProxy的整体架构,它是一个三层架构:
● 最上层是业务层,只需和 proxy 交互,通过etcd实现proxy的服务发现
● 中间是GProxy层,提供请求转发和集群的管理
● 最下方是多个ES集群
GProxy包含了多个组件:
● etcd:高可用的元信息存储数据库,包括路由规则、集群信息、proxy服务地址、迁移任务等
● sdk:扩展了es原生sdk,通过其sniffer机制,封装了对proxy服务发现和熔断等功能
● proxy是一个轻量级的代理服务,扩容很方便,启动后可以将自己的地址注册到etcd中
● dashboard 是整个集群的管理服务,并提供 web 界面,方便运维人员对集群进行管理和监控
● migrate服务提供不同集群间的迁移功能
服务发现和路由规则
有了上面的总体架构后,还需要解决两个问题:
1、业务服务如何发现proxy,也即服务发现问题
2、 proxy将请求转发给哪一个集群,也即路由问题
服务发现
etcd是一个高可用的分布式键值数据库,且通过http api进行交互,操作简便,因此我们选择etcd来实现服务发现和元数据存储。

proxy是一个无状态的服务,启动初始化完成之后,将自己的地址注册到etcd中。通过etcd的lease机制,系统可以监控proxy的存活状态。当proxy服务出现异常而不能定时续期lease时,etcd会将其摘除,避免其影响正常的业务请求。
ElasticSearch提供的sdk预留了sniffer接口,sdk可以通过sniffer接口来获取后端地址。我们实现了sniffer接口,其定期从etcd获取proxy列表,并通过etcd的watch机制,监听服务的上下线,及时更新内部的连接列表。业务方还是可以按原来的方式使用原生的sdk,不需要过多的改动,只需要将sniffer注入到SDK就行。
路由规则
在个推推送业务场景中,每个app推送需要的数据都可以视为是一个整体,因此我们选择按照app的维度进行请求的路由,每个app推送所需的数据都存储在一个集群内。
路由信息保存在etcd中,格式是 appid->clusterName 这样一个对应关系。如果没有这样一个对应关系,proxy会将appid归属到一个默认集群。
proxy启动时会拉取最新的路由表,并通过etcd的watch机制,监控路由表的变更。
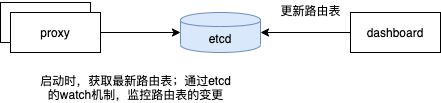
路由关系的变更通过迁移操作实现,以下是迁移流程的介绍。
迁移流程
每个app都属于一个集群。当集群的负载不均衡时,管理员可以按照app维度,通过迁移服务进行集群间的数据迁移。
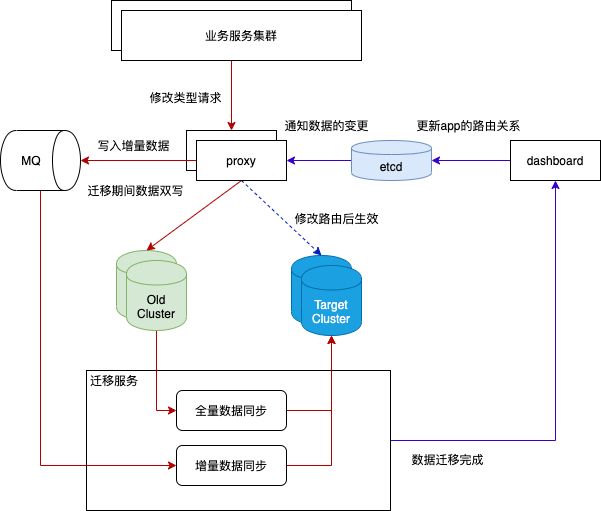
迁移流程包含两个步骤:数据同步和路由规则的修改。数据同步需要同步两份数据:全量数据和增量数据。
1、全量数据通过ElasticSearch的scroll api导出
2、因为ElasticSearch没有提供增量数据的获取方式(类似mysql的binlog协议来实现增量数据的获取),因此我们通过proxy双写来实现增量数据的获取。
迁移服务负责数据的同步,并在数据同步完成后通知dashboard,dashboard更新etcd的路由关系。proxy通过watch机制,得到新的路由关系,更新内部的路由表,此时app新的请求就会路由到新的集群。
多IDC数据热备
在个推实际业务场景中,推送作为企业级服务,对服务的可用性要求很高,个推有多个机房对外提供服务,每个app归属到一个机房。为了应对机房级故障,我们需要对数据进行多IDC的热备,这样才能在机房发生故障后,将客户的请求路由到非故障机房,从而不影响客户的正常使用。
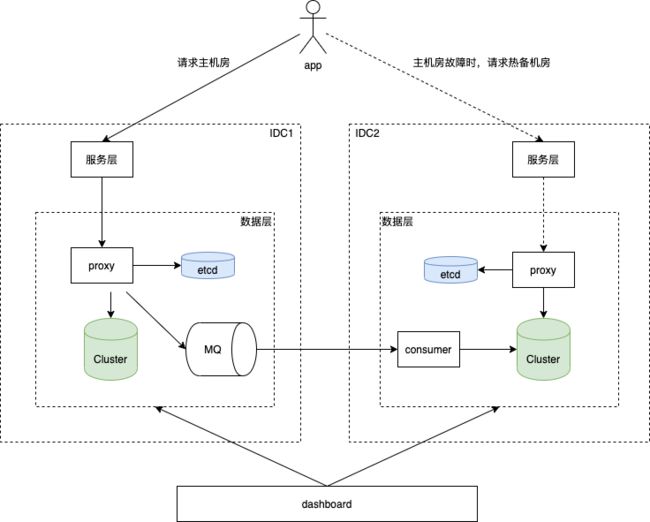
我们对数据的热备采用集群维度进行,每个集群的数据会备份到另一个机房。proxy收到请求后,根据集群的热备信息,实时将增量数据写入到MQ中,另一个机房的consumer服务不断消费MQ的增量数据,并写入至对应的集群中。dashboard服务负责管控所有IDC的热备任务的状态。
性能
引入一个中间层后,不可避免地会带来一定的性能损失。我们选择 GO 开发的原因,就是希望损失尽可能减小。最终性能结果如下:
![]()

由上图可知,QPS降低10%左右,平均延时约等于ES调用和proxy本身平均延时之和。虽然有了10%的性能下降,但是带来了更灵活的运维能力。
当前运行情况
GProxy服务上线之后,顺利完成了ES版本的升级(从1.5升级到6.4),并将原来大集群拆分为多个小集群。整个升级和拆分过程对于业务方无感,并且GProxy提供的无损回滚功能可以让操作更放心(数据的迁移需要十分谨慎)。
有了GProxy的支持,DBA日常对ES运维操作,如参数的优化、集群间的压力平衡,变得更加方便。
结语
个推通过使用Go语言,自主研发了Gproxy,成功解决ElasticSearch大集群存在的问题,为上层业务提供了稳定可靠的数据存储服务。此外,个推也将持续打磨自身技术,在搜索和数据存储领域不断探索,不断拓宽ElasticSearch的应用场景,与开发者一起分享关于如何保证数据存储高可用的最新实践。