【独家】让你一次性掌握Neo4j性能优化秘籍的三大狠招

作者| 西湖数据智能研究院高级研发工程师 无极
大千世界纷繁复杂,万物之间总会有千丝万缕的关系。随着现代商业社会的发展,事物的关联关系越发错综复杂,传统的关系存储已经不能满足我们的业务需求。“图”作为关系探索未来发展的风向标,可以更为直观地帮助人们认知事物,挖掘数据之间的奥秘,为数据价值的体现开辟了新天地。
作为专业的数据智能上市公司,个推在图应用分析方面也进行了丰富的实践。本文将讲述图的常见业务场景、Neo4j在个推的落地应用案例和优化举措,并在此基础上创新性地提出了个推独有的Neo4j社区版 HA(High Availability) 方案。
01 图
著名的柯尼斯堡七桥问题拉开了图的新篇章。1736年, 莱昂哈德·欧拉针对该问题,进行了数学抽象,用二维矩阵予以表示,奠定了图论的基础。

图片来源于neo4j.com
什么是图?
图的定义指出,图G由两个集合构成,记作G=
图片来源于neo4j.com
图中展示了3200个机场与60000条航线。对应图的定义,每个机场就是 V集合,航线则是E集合。
图有哪些存储方式?
• 图的邻接矩阵
• 图的邻接表
• 有向图的十字链表存储表示
• 无向图的邻接多重表存储表示
图有哪些遍历方式?
• 深度优先遍历(DFS)
• 广度优先遍历(BFS)
图数据库
图数据库(GraphDatabase) 并非指存储图片的数据库,而是指支持以图数据结构存储和查询数据的数据库。图数据库是一种在线数据库管理系统,具有处理图数据模型的创建、读取、更新和删除(CRUD)操作。
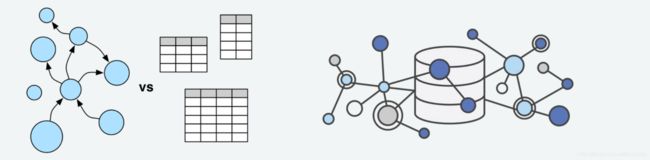
图片来源于amazon.com
图存储
一些图数据库使用原生图存储,这类存储是经过优化的,并且是专门为了存储和管理图而设计的。并不是所有图数据库都使用原生图存储,也有一些图数据库将图数据序列化,然后保存到关系型数据库、面向对象数据库,或其他通用数据存储中。
图处理引擎
原生图处理(也称为无索引邻接)由于其连接的节点在数据库中可以物理地指向彼此,因此被认为是处理图数据的最有效的方法。非原生图处理使用其他方法来处理CRUD操作。
图常见业务场景
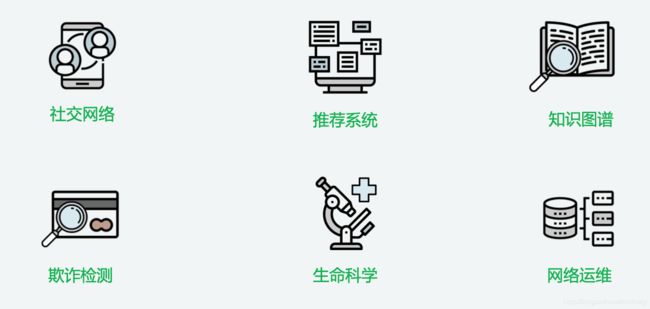
图片来源于amazon.com
上图中展示了图在 社交网络、推荐系统、知识图谱、欺诈检测、生命科学、网络运维等业务场景中的应用。推荐系统是图的一个典型应用,比如当我们想要查询好看的影片之时,售票软件会根据我们经常看的类型和风格帮我们推荐类似的电影。
图数据库排名
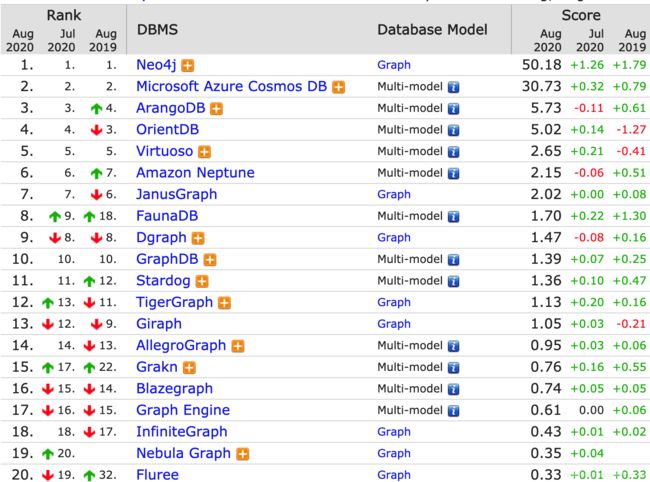
根据 DB-Engines 统计, 2020 年图数据库受欢迎程度排行榜清晰地表明Neo4j 已经抢占了图数据库的半壁江山。
02 Neo4j 图数据库
Neo4j是一个高性能的NOSQL图形数据库,它将结构化数据存储在网络上而不是表中。它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎,也可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性。
Neo4j让程序员工作在一个面向对象的、灵活的网络结构下而不是严格、静态的表中——但他们可以还能享受到具备完全的事务特性、企业级的数据库的所有好处。
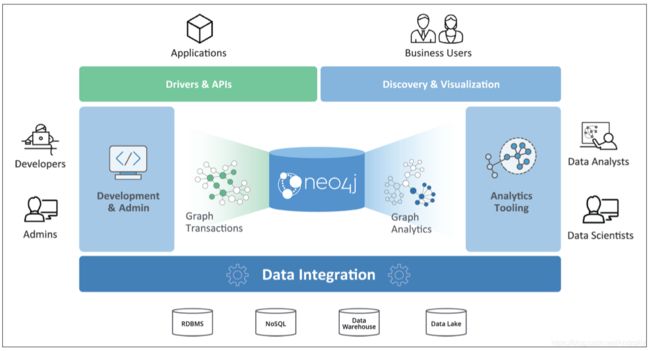
图片来源于neo4j.com
图中展示了Neo4j图数据库从存储到分析的平台生态。
Neo4j 社区版(4.0.6)存储分析
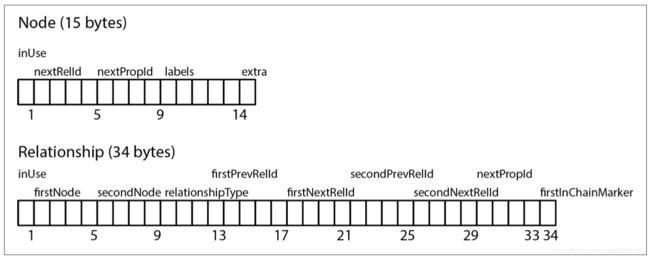
图片来源于neo4j.com
Node 存储(15 bytes)
节点存储文件为 neostore.nodestore.db ,定长记录文件,每个记录代表一个节点。
• inUse(1 byte)
– [x x x x,_ _ _ _ ] 1-4 表示 nextPropId的高4位
– [ _ _ _ _ , x x x _ ] 5-7 表示nextRelId的高3位
– [ _ _ _ _ , _ _ _ x ] 8 表示节点是否可用
• nextRelId (4 bytes ) : 节点关联的第一条边的id的低位,加上inUse中的3个bit,relId一共35个bit
• nextPropId (4 bytes):节点关联的第一个属性的id的低位,加上inUse中的4个bit,propId一共36个bit
• labels (5 bytes ) : 存储label信息,前4个byte为低位,最后一个1个byte为高位
– [1 x x x ,_ _ _ _ ] : 第一个 bit (1)表示 内联,2-4 表示 label 数量, 剩下的36个bit使用除法均分给每个label,代表label的id
– [0 _ _ _ ,_ _ _ _ ] : 第一个 bit (0)表示 非内联,则低位的36个bit表示第一个动态label记录的id
• extra (1 byte) : [ _ _ _ _ , _ _ _ x ] 只用到最后一个bit,用来标记是否为超级节点
边的id长度为35bit,即边上限320亿左右,属性的id长度为36bit,则属性上限约640亿。
Relationship 存储 (34 bytes)
边存储文件为 neostore.relationshipstore.db,定长记录文件,每个记录代表一条边
• inUse(1 byte)
– [x x x x,_ _ _ _ ] 1-4 表示 nextPropId的高4位
– [ _ _ _ _ , x x x _ ] 5-7 表示firstNodeId的高3位
– [ _ _ _ _ , _ _ _ x ] 8 表示节点是否可用
• firstNode(4 bytes):边关联的第一个节点id的低位,加上inUse中的3个bit,nodeId一共35个bit
• secondNode(4 bytes):边关联的第二个节点id的低位,加上relationshipType mid中的3个bit,nodeId一共35个bit
• relationshipType (4 bytes) :
– mid(2 bytes):
• [ _ x x x , _ _ _ _ , _ _ _ _ , _ _ _ _ ]:2-4表示secondNodeId的高3位
• [ _ _ _ _ , x x x _ , _ _ _ _ , _ _ _ _ ]:5-7表示first prevRelId的高3位
• [ _ _ _ _ , _ _ _ x , x x _ _ , _ _ _ _ ]:8-10表示firstNextRelId的高3位
• [ _ _ _ _ , _ _ _ _ , _ _ x x , x _ _ _ ]:11-13表示secondPrevRelId的高3位
• [ _ _ _ _ , _ _ _ _ , _ _ _ _ , _ x x x ]:14-16表示secondNextRelId的高3位
– type(2 bytes):边类型id
• firstPrevRelId(4 bytes):第一个节点相关的前一条边id的低位,加上relationshipType mid中的3个bit,relId一共35个bit
• firstNextRelId(4 bytes):第一个节点相关的后一条边id的低位,加上relationshipType mid中的3个bit,relId一共35个bit
• secondPrevRelId(4 bytes):第二个节点相关的前一条边id的低位,加上relationshipType mid中的3个bit,relId一共35个bit
• secondNextRelId(4 bytes):第二个节点相关的后一条边id的低位,加上relationshipType mid中的3个bit,relId一共35个bit
•nextPropId (4 bytes):边关联的第一个属性的id的低位,加上inUse中的4个bit,propId一共36个bit
• firstInChainMarkers(1 byte):
– [ _ _ _ _ , _ _ x _ ] :第7个bit标识是否为第一个节点的第一条边
– [ _ _ _ _ , _ _ _ x ] :第8个bit标识是否为第二个节点的第一条边
通过存储结构我们可以看出,边存储了两端节点的id以及两条双向链表,参考如图:
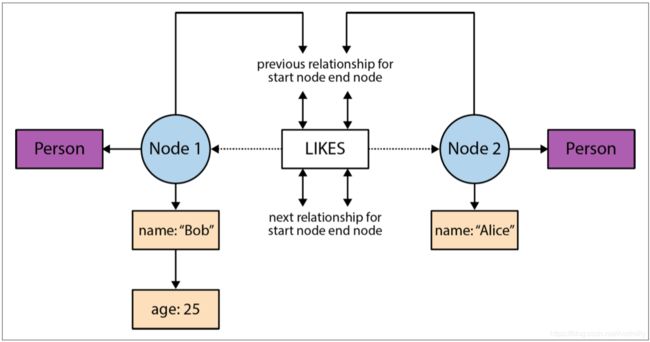
图片来源于neo4j.com
Neo4j大数据量读写优化
读优化
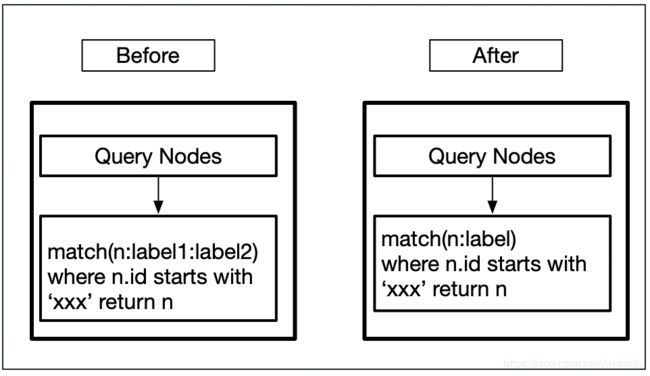
当我们遇到一个任务有很多关系的时候,如果要查询这个任务下所有数据,则需要 match(n)扫描所有的Node,而这样查询效率会非常低。为了解决这个问题,我们仍然采用空间换时间的方式,引入了辅助 label,这样可以高效地抽出指定任务下的所有数据,将原来 8秒 查询的效率优化到了 100毫秒 以内。
写优化
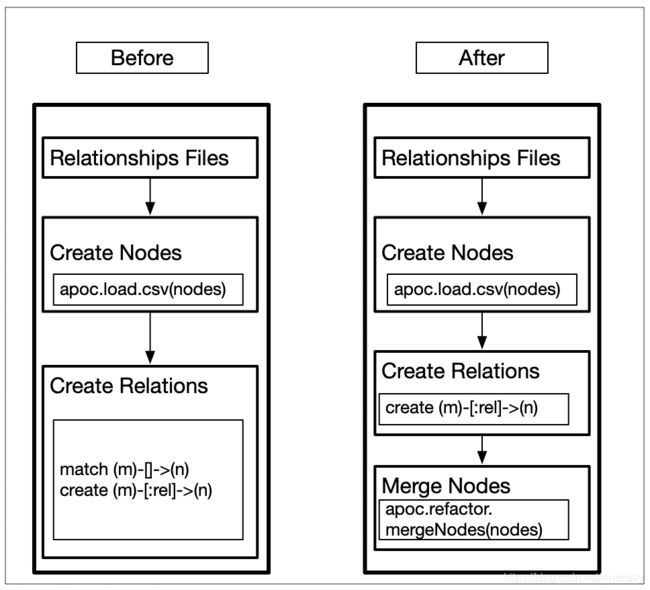
Neo4j传统的数据导入方式是要先创建Node,然后再创建Relation,接着经过 cypher(SQL) 执行计划分析。在此过程中,创建Node和Relation 步骤耗时少,但match 操作却十分耗时。
为了解决创建 Relation 的过程中需要 match 操作而导致的耗时问题,我们先创建 Node 与 Relation (Relation 的起点和终点与创建的Node有共同属性 ),然后通过Node 某个特定属性合并Node,并采用空间换时间的方案来实时写入数据,最终将原来Node、Relation 写入效率从 40 分钟 缩减到了 3 分钟 。
Tips
空间换时间与 时间换空间 是解决性能均衡问题的两种方式,选择时间与空间合理的平衡点能极大地提高我们软件的服务质量。
Neo4j社区版 HA(high availability)方案探索
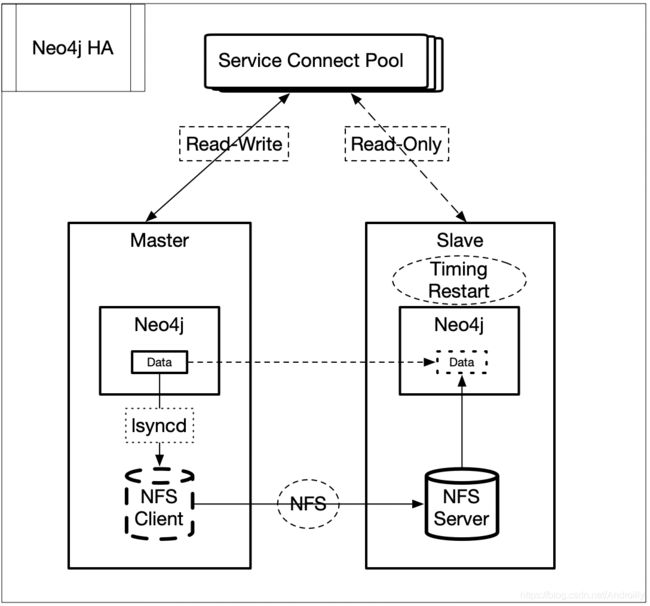
经过对比分析,我们最终选择采用 Neo4j 图数据库。Neo4j企业版功能虽然较全但是价格非常昂贵,为此我们将目标瞄向 Neo4j社区版。而Neo4j 社区版存在不支持高可用、数据无法备份的缺点,不利于其在业务环境下的使用,因此设计一种 HA 方案,来解决单点故障是非常有必要的。以下是 Neo4j社区版高可用的一种探索方案。
1. Neo4j 部署master 节点与 slave 节点 ,master 可读可写,slave 仅可读。
2. 通过 lsyncd 将 Neo4j 主节点的data 目录实时同步到 slave 的 data 目录。
3. slave data目录挂载到 master 节点的特定目录下。
4. 定时重启 slave 节点(Neo4j 社区版需要重启加载同步的数据文件),允许 slave 节点与主节点之间存在一定的数据延迟。
5. 当 master 出现故障后,驱动会连接一个可用的slave,“只读 slave”提供查询,此时无法写入数据,并告知用户 master 节点发生故障,需要及时处理。
03 总结
图数据库具有高度关联的特性,能快速进行复杂关系数据处理,从而可以有效帮助企业获得更深刻的洞察力和更多的竞争优势。业内越来越多的公司开始布局图数据库领域研究,研发自己的图数据库系统。作为拥有海量数据沉淀的数据智能上市公司,个推在图数据库实践领域不断创新,持续打磨自身图挖掘与分析技术的同时,也期待与业界一同碰撞更多的图数据库实践。
参考资料:
https://db-engines.com/en/ranking/graph+dbms
https://neo4j.com/docs/
https://www.tutorialspoint.com/neo4j/index.htm
https://www.6aiq.com/article/1589073236892
https://aws.amazon.com/
https://www.tony-bro.com/posts/2624331944/
