TCP/IP协议簇
TCP/IP
参考视频:网络协议 TCP/IP 视频教程全集(23P)| 14 小时从入门到精通
一、概述:分层
七层模型:物理层,数据链路层,网络层,传输层,会话层,表示层,应用层
TCP/IP协议族四层模型
- 链路层:处理与电缆(或其他任何传输媒介)物理接口细节
- 网络层:处理分组在网络中的活动,例如分组选路
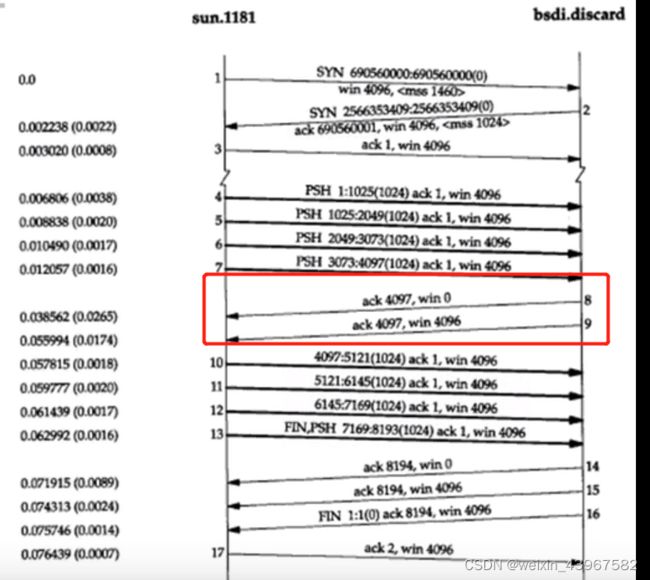
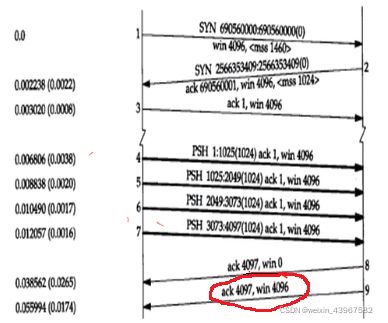
- 运输层:为两台主机上的应用程序提供端到端的通讯
- 应用层:处理特定的应用程序细节

实例
运行FTP的两台主机
- 大多数的网络应用程序都被设计成客户——服务器模式
- 双方都有对应的一个或多个协议进行通信
- 应用程序通常是用户进程,而下三层一般在内核执行
- 应用层关心应用程序的细节,下三层处理通讯细节

通过路由器连接的两个网络
- 端系统(end system)
- 中间系统(intermediate system)
- 应用层和传输层使用端到端(end-to-end)协议
- 网络层提供的是逐跳(hop-to-hop)协议
- 网络ip提供的是一种不可靠的服务,它只是尽可能地把分组从源节点送到目的节点,但不提供可靠性保障
- TCP在不可靠的IP层上提供了可靠的传输层
- 互联网的目的之一就是在应用程序中隐藏所有的物理细节

下图可以说明TCP在不可靠的IP层上提供一个可靠的传输
首先IP层只负责尽量把数据从源端送到目的端,并不保证可靠性。如果数据丢包,类比与快递丢件,买家会找卖家协商解决,比如重传,TCP重传机制保证了数据就算丢包也能重写传输,保证让目的端收到,确保了可靠性。因此TCP在不可靠的IP层上提供一个可靠的传输

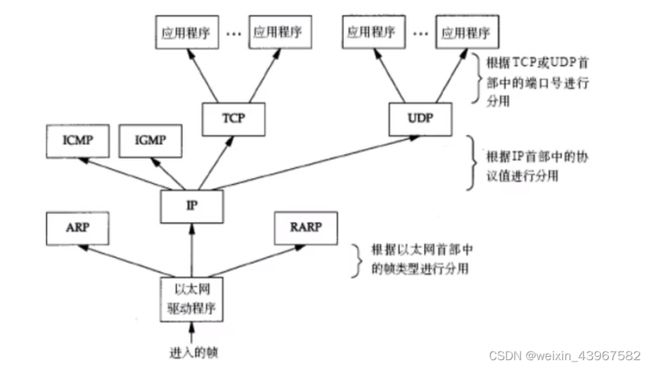
TCP/IP协议簇中不同层次的协议

- TCP提供不可靠的IP服务,并提供一种可靠的传输层服务
- UDP为应用程序发送和接收数据报,和TCP不同,UDP是不可靠的
- IP是网络层上的主要协议,同时被TCP和UDP使用
- ICMP是IP协议的附属协议
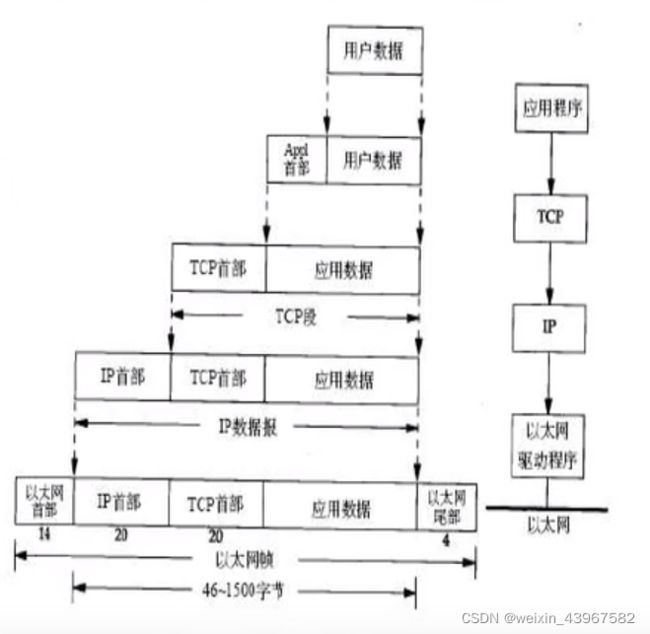
封装
- 以太网数据帧的物理特性是其长度必须在46-1500字节之间
- 以太网的帧首部也有一个16bit的帧类型域(ip,arp,rarp)
- ip在首部中存入一个长度为8bit的数值,成为协议域(icmp,igmp,tcp,udp,esp,gre)
- TCP和UDP都用一个16bit的端口号来不是不同的应用程序(ftp,telnet,http)
每个首部都会有一定的位数标识紧接着的下一个头部是什么
分用
端口号
- 服务器一般都是通过知名端口号来识别的(ftp 21,telnet23)
- 客户端端口号又称为临时端口号(即存在时间很短)
- 大多数TCP/IP实现给临时端口分配1024-5000之间的端口号
- 大于5000的端口号是为其他服务器预留的(Internet上并不常用的服务)
二、链路层:以太网和IEEE 802封装
以太网(与802不同)
- 以太网这个术语一般是指数字设备公司、英特尔公司和Xerox公司在1982年联合公布的一个标准。
- 它采用一种称作CSMA/CD的媒体接入方法(Carrier Sense,Multiple Access With Collision Detection)
- 他的速率是10Mb/s,mat地址为48bit
IEEE 802封装
- 802.3 针对整个CSMA/CD网络
- 802.4 针对令牌总线网络
- 802.5 针对令牌环网络
- 这三者的共同特征性由802.2标准来定义,那就是802网络共有的逻辑链路控制(LLC )
封装格式
- 两种帧格式都采用48bit(6字节)的目的地址和源地址
- ARP和RARP协议对32bit的IP地址和48bit的硬件地址进行映射
- 802定义的有效长度值和以太网的有效类型值不同,这样就可以对这两种帧格式进行区分
- 目的服务访问点和源服务访问点的值都设为0xaa,ctrl字段的值设为3.随后的3个字节org code都设为0.在接下来的2字节类型字段和以太网帧格式一样
- 802.3规定数据部分至少为38字节,而对于以太网,则要求最少要有46字节。为了保证这一点,必须在不足的空间插入填充(pad)字节
- 类型:0806ARP,0800IP

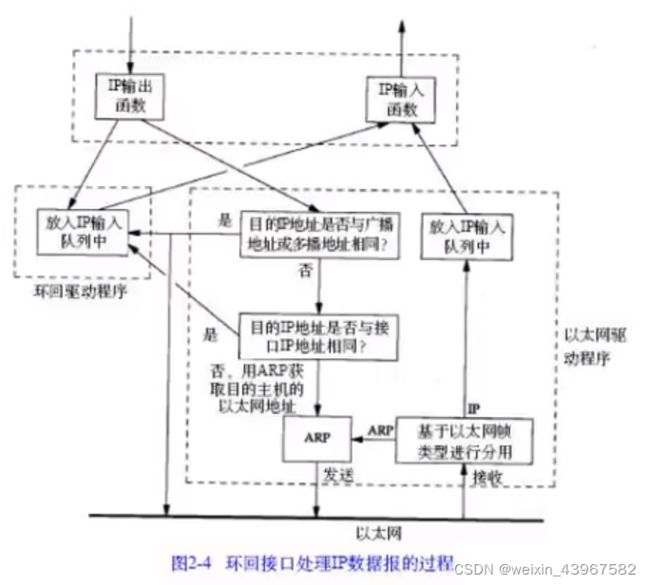
环回接口
- 传给环回地址(一般是127.0.0.1)的任何数据均作为IP输入
- 传给广播地址或多播地址的数据报复制一份传给环回接口,然后送到以太网上。这是因为广播传输和多播传送的定义包含主机本身
- 任何传给该主机IP地址的数据均送到环回接口
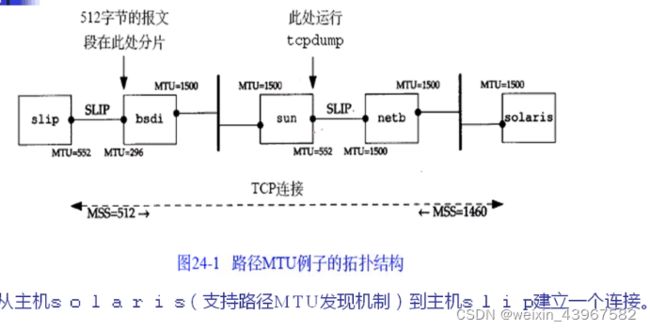
MTU和路径MTU
- 以太网和802.3对数据帧的长度都有一个限制,其最大值分别为1500和1492字节。链路层的这个特性称为MTU,最大传输单位
- 如果IP层有一个数据报要传,而且数据的长度比链路层的MTU还大,那么IP层就需要进行分片,把数据分成若干片,这样每一片都小于MTU。
- 点到点的链路层的MTU并非指的是网络媒体的物理特性,相反,他是一个逻辑限制,目的是为交换使用提供足够快的响应时间
- 两台通信主机路径中最小的MTU,他称为路径MTU
- 路径MTU在两个方向上不一定是一致的
- MTU是计算出方向

三、IP介绍
- IP是TCP/IP协议簇中最核心的协议,所有的TCP、UDP、ICMP及IGMP数据都以IP数据报格式传输
- IP提供不可靠、无连接的数据报传送服务
- 不可靠(unreliable)的意思是他不能保证IP数据报能成功到达目的地。IP仅提供最好的传输服务。如果发生某种错误时,如某个路由器暂时用完缓存区,IP有一个简单的错误处理算法:丢弃该数据报,然后发送ICMP消息报给源端。任何要求的可靠性必须有上层来提供(如TCP)
- 无连接(connectionless)这个术语的意思是IP并不维护任何关于后续数据报的状态信息。每个数据包的的处理是相互独立的。IP数据报可以不按发送顺序接收。如果一信源向相同的信宿发送两个连续的数据报(先是A,然后是B),每个数据报都是独立进行路由选择,可能选择不同的路线,因此B可能再A到达之前先到达
- 两个有用的命令:
ifconfig和netstat
- 两个有用的命令:
IP首部
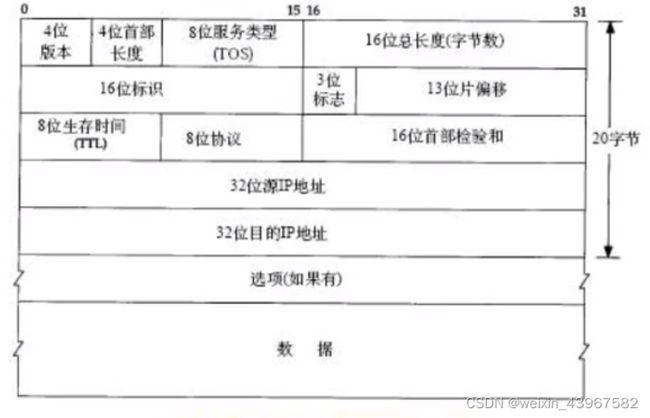
首部字段分析
- 4个字节的32bit值以下面的次序传输:首先是0-7bit,其次是8-15bit,然后16-23bit,最后24-31bit。这种传输次序称为big endian字节序。由于TCP/IP首部中所有二进制整数再网络中传输时都要求以这种次序,因此他又称为网络字节序
- 目前的协议版本号是4,因此IP有时也称作IPv4
- 首部长度指的是首部占32bit(4字节)的数目,包括任何选项,由于他是一个4bit字段,因此首部最长为60字节。
- 服务类型(TOS)字段包括一个3bit的优先权字段(现在已被忽略),4bit的TOS子字段和1bit末用位但必须置0
- 4bit的TOS分别代表:最小时延、最大吞吐量、最高可靠性和最小费用。4bit中只能置其中1bit。如果所有4bit均为0,那么就意味着是一般服务
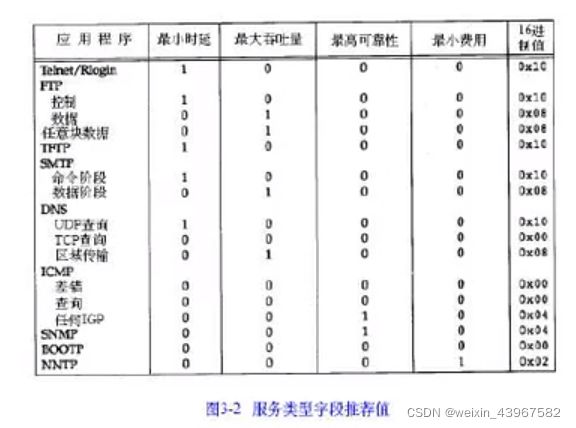
- 总长度字段是指整个IP数据报的长度,以字节为单位,利用首部长度字段和总长度字段,就可以知道IP数据报中数据内容的起始位置和长度。由于该字段长16比特,所以IP数据报最长可达65535字节,当数据报被分片时,该字段的值也随着变化
- 标识字段唯一的标识主机发送的每一份数据报。通常每发送一份报文它的值就会加1
- TTL(Time-to-live)生存时间字段设置了数据报可以经过的最多路由器数
- 协议字段被IP用来对数据报进行分用。根据他可以识别时那个协议向IP传送数据 1:ICMP、6:TCP、17:UDP
- 首部校验和字段时根据IP首部计算的校验和码
- 如果结果不是全1(即校验和错误),那么IP就丢弃收到的数据报,但是不生成差错报文,由上层去发现丢失的数据报并进行重传
- 由于路由器经常只修改TTL字段(减1),因此当路由器转发一份报文时可以增加它的校验和,而不需要对整个IP首部进行重新计算
IP首部的选项
-
最后一个字段是任选项,是数据报中的一个可变长的可选信息,目前,这些任选项定义如下:
- 安全和处理限制(用于军事领域)
- 记录路径(让每个路由器都几下它的IP地址)
- 时间戳(让每个路由器都记下它的IP地址和时间)
- 宽松的源站选路(为数据报制定一系列必须经过的IP地址)
- 严格的源站选路(于宽松的源站选路类似,但是要求只能经过指定的这些地址,不能经过其他的地址)
这些选项很少被使用,并非所有的主机和路由器都支持这些选项,选项字段一直都是以32bit作为界限,再必要的时候插入值0的填充字节。这样就保证IP首部始终是32bit的整数倍(首部长度字段所要求的)
IP路由选择
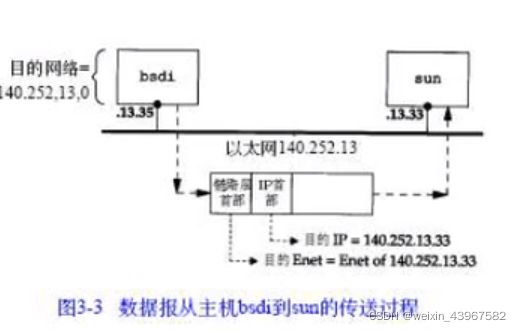
源地址和目的地址在同一个网络
源地址和目的地址在不同一个网络
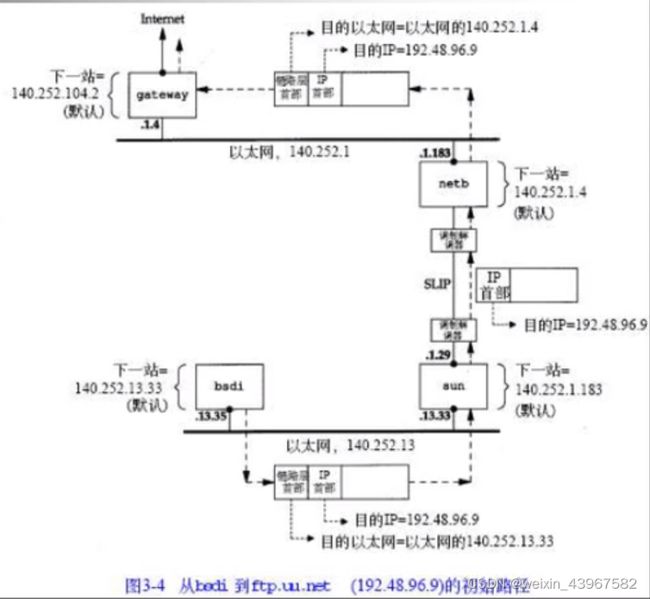
- 所有的主机和路由器都使用默认路由。事实上,大多数主机和一些路由器可以用默认路由来处理任何目的,除非他在本地局域网上
- 数据报中的目的IP地址始终不发生任何变化(只有使用源路由选项时,目的IP地址才有可能不修改,这种情况很少出现)。所有的路由选择决策都是基于这个目的IP地址
- 每个链路层可能具有不同的数据帧首部,而链路层的目的地址(如果有的话)始终指的是下一站的链路层地址(mat地址)。在例子中,两个以太网封装了含义下一站以太网地址的链路层首部,但是SLIP链路没有这样做。以太网一般通过ARP获得
特殊的IP地址
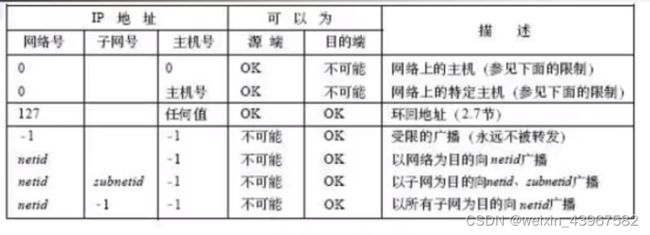
- 0表示所有的比特位全为0;-1表示所有的比特位全为1;netid、subnetid和hostid分别表示不为全0或全1的对应字段。子网号栏位空表示该地址没有进行子网划分
- 表的头两项时特殊的源地址,中间项是特殊的环回地址,最后四项是广播地址
- 表中的头两项,网络号为0,如主机使用BOOTP协议确定本机IP地址时只能作为初始化过程中的源地址出现
四、ARP介绍
- 当一台主机把以太网数据帧发送到位于同一局域网上的另一台主机时,是根据48bit的以太网地址来确定目的接口的。设备驱动程序从不检查IP数据报中的目的IP地址。
- 地址解析为这两种不同的地址形式提供映射:32bit的IP地址和数据链路层使用的任何类型的地址
- ARP为IP地址到对应的硬件地址之间提供动态映射。我们之所以用动态这个词是因为这个过程时自动完成的,一般应用程序用户或系统管理员不必关心
- RARP是被哪些没有磁盘驱动器的系统使用的(一般是无盘工作站或X终端),他需要系统管理员进行手工设置
例子
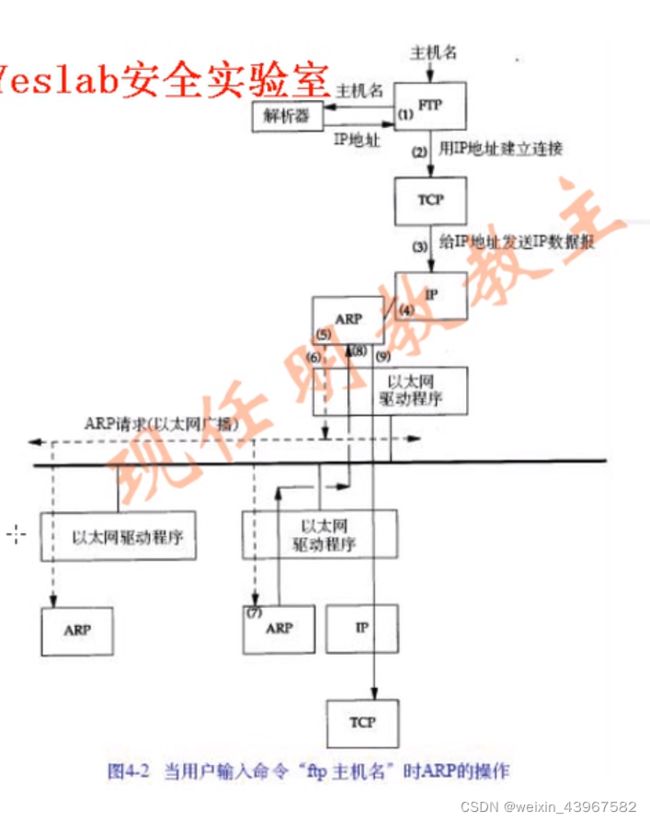
ARP过程
通过ftp badi
- 应用程序FTP客户端调用函数gethostbyname把主机名(hosts)转换成32bit的IP地址,这个函数在DNS中称作解析器。这个转换过程或者使用DNS,或者在较小网络中使用一个静态的主机文件(/etc/hosts)
- FTP客户端请求TCP用得到的IP地址建立连接
- TCP发送一个连接请求分段到远端的主机,即用上述的IP地址发送一份IP数据报
- 如果目的主机在本地网络上(如以太网、令牌环网或点对点连接的另一端),那么IP数据报可以直接送到目的主机上,如果目的主机在一个远程网络上,那么就通过IP选路函数来确定位于本地网络上的下一站路由器地址,并让他转发IP数据报。在这两种情况下,IP数据包都是被送到位于本地网络上的一台主机或者路由器
- 假定是一个以太网,那么发送端主机必须把32bit的IP地址转换成48bit的以太网地址,从逻辑Internet地址到对应的物理硬件地址需要进行翻译。这就是ARP的功能,ARP本来是用于广播网络的,有许多主机或路由器连在同一个网络上。
- ARP发送一份称为ARP请求的以太网数据帧给以太网上的每个主机,这个过程称为广播,如上图虚线部分。ARP请求数据帧中包含目的主机的IP地址(主机名为bsdi),其意思是如果你是这个IP地址的拥有者,请回答你的硬件地址。
- 目的主机的ARP层收到这份广播报文后,识别出这是发送端在询问他的IP地址,于是发送一个ARP应答。这个ARP应答包含IP地址及对应的硬件地址
- 收到ARP应答后,使ARP进行请求——应答交换的IP数据报现在就可以传送了
- 发送IP数据报到目的主机
ARP背后的一个基本概念
- ARP背后有一个基本概念,那就是网络接口有一个硬件地址(一个48bit的值识别不同的以太网或令牌环网络接口)。在硬件层次上进行的数据帧交换必须有正确的接口地址。但是,TCP/IP有自己的地址:32bit的IP地址。知道主机的IP地址并不能让内核发送一帧数据给主机。内核(如以太网驱动程序)必须知道目的端的硬件地址才能发送数据。ARP的功能是在32bit的IP地址和采用不同网络技术的硬件地址之间提供动态映射
- 点对点链路不使用ARP。当设置这些链路时(一般在引导过程进行),必须告知内核链路每一端的IP地址。像以太网这样的硬件地址并不涉及。
ARP高速缓存
ARP高效运行的关键时由于每个主机上都有一个ARP高速缓存。这个高速缓存存放了最近Internet地址到硬件地址之间的映射记录。高速缓存中每一项的生存时间一般为20分钟,起始时间从被创建时开始算起
查看缓存arp -a
ARP分组格式
在以太网上解析IP地址时,ARP请求和应答分组的格式如下,(ARP可以用于其他类型的网络,可以解析IP地址以外的地址。紧跟着帧类型字段的前四个字段指定了最后四个字段的类型和长度)
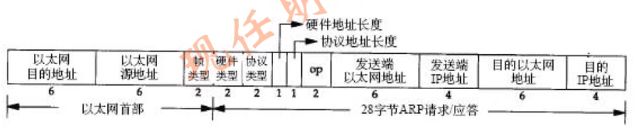
ARP包字段解析
- 以太网报头中的前两个字段是以太网的源地址和目的地址。目的地址为全1的特殊地址是广播地址。电缆上的所有以太网接口都要接收广播的数据帧
- 两个字节长的以太网帧类型表示后面数据的类型。对于ARP请求或应答来说,该字段的值为0x0806.
- 形容词hardware(硬件)和protocol(协议)用来描述ARP分组中的各个字段。例如,一个ARP请求分组询问协议地址(这里是IP地址)对应的硬件地址(这里时以太网地址)
- 硬件类型字段表示硬件地址的类型,它的值为1表示以太网地址。协议类型字段表示要映射的协议地址类型。它的值为0x0800表示IP地址。它的值包含IP数据报的以太网数据帧中的类型字段的值相同,这里是有意设计的
- 接下来的两个1字节的字段,硬件地址长度和协议地址长度分别指出硬件地址和协议地址的长度,以字节为单位。对于以太网上IP地址的ARP请求或应答来说,它们的值分别为6和4
- 操作字段指出四种操作类型,它们时ARP请求(值为1)、ARP应答(值为2)、RARP请求(值为3)、RARP应答(值为4)。这个是字段必须的,因为ARP请求和ARP应答的帧类型字段值是相同的
- 接下来的四个字段是发送端的硬件地址(本例是以太网地址)、发送端的协议地址(IP地址)、目的端的硬件地址、目的端的协议地址。注意,这里有一些重要选项:在以太网的数据帧包头中和ARP请求数据帧中都有发送端的硬件地址
- 对于一个ARP请求来说,除了目的端硬件地址外的所有其他字段都有填充值。当系统收到一份目的端为主机的ARP请求报文后,他就把硬件地址填进去,然后用两个目的端地址分别与两个发送端地址交换,并把操作字段置为2,最后把他发送回去
ARP代理

免费arp
两个作用:
- 一个主机可以通过它来确定另一个主机是否设置了相同的IP地址,主机bsdi并不希望对此请求有一个回答。但是,如果收到了一个回答,那么就会在终端日志上产生一个错误信息“以太网地址:
a:b:c:d:e:f发送来重复的IP地址。这样就可以警告系统管理员,某个系统又不正确的设置(ARP源和目的都为自己的ARP请求) - 如果发送免费ARP的主机刚好改变了硬件地址(很可能是主机关机了,并换了一块接口卡,然后重新启动),那么这个分组就可以对其他主机高速缓存中旧的硬件地址进行对应的更新。一个比较著名的ARP协议事实是,如果主机收到某个IP地址的ARP请求,而且它已经在接受者的高速缓存中,那么就要用ARP请求中的发送端硬件地址(如以太网地址)对高速缓存中相应的内容进行更新。主机接收到任何ARP请求都要完成这个操作(ARP请求是在网上广播的,因此每次发送ARP请求时网上的所有主机都要这样做)
- 通过发送含有备份硬件地址和故障地址服务器的IP地址的免费ARP请求,使得备份文件服务器可以顺利的接替故障服务器进行工作。这使得所有目的地为故障服务器的报文都被送到备份服务器那里,客户程序不用关心原来的服务器是否除了故障(HSRP、VRRP)
五、ICMP接介绍
- ICMP经常被认为是IP层的一个组成部分。它传递差错报文以及其他需要注意的信息。ICMP报文通常被IP层或更高层协议(TCP或UD)使用。一些ICMP报文把差错报文返回给用户进程。
- ICMP报文是在IP数据报内部被传输的

- ICMP报文的格式如下。所有报文的前4个字节都是一样的,但是剩下的其他字节则互不相同
- 类型字段可以有15个不同的值,以描述特定类型的ICMP报文,某些ICMP报文还使用代码字段的值来进一步描述不同的条件
- 验证和字段覆盖整个ICMP报文,使用的算法与IP首部校验和算法相同。ICMP的校验和是必须的

ICMP报文类型
0 0 ping应答
8 0 ping请求
| TYPE | CODE | Description | Query | Error |
| 0 | 0 | Echo Reply——回显应答(Ping应答) | x | |
| 3 | 0 | Network Unreachable——网络不可达 | x | |
| 3 | 1 | Host Unreachable——主机不可达 | x | |
| 3 | 2 | Protocol Unreachable——协议不可达 | x | |
| 3 | 3 | Port Unreachable——端口不可达 | x | |
| 3 | 4 | Fragmentation needed but no frag. bit set——需要进行分片但设置不分片比特 | x | |
| 3 | 5 | Source routing failed——源站选路失败 | x | |
| 3 | 6 | Destination network unknown——目的网络未知 | x | |
| 3 | 7 | Destination host unknown——目的主机未知 | x | |
| 3 | 8 | Source host isolated (obsolete)——源主机被隔离(作废不用) | x | |
| 3 | 9 | Destination network administratively prohibited——目的网络被强制禁止 | x | |
| 3 | 10 | Destination host administratively prohibited——目的主机被强制禁止 | x | |
| 3 | 11 | Network unreachable for TOS——由于服务类型TOS,网络不可达 | x | |
| 3 | 12 | Host unreachable for TOS——由于服务类型TOS,主机不可达 | x | |
| 3 | 13 | Communication administratively prohibited by filtering——由于过滤,通信被强制禁止 | x | |
| 3 | 14 | Host precedence violation——主机越权 | x | |
| 3 | 15 | Precedence cutoff in effect——优先中止生效 | x | |
| 4 | 0 | Source quench——源端被关闭(基本流控制) | ||
| 5 | 0 | Redirect for network——对网络重定向 | ||
| 5 | 1 | Redirect for host——对主机重定向 | ||
| 5 | 2 | Redirect for TOS and network——对服务类型和网络重定向 | ||
| 5 | 3 | Redirect for TOS and host——对服务类型和主机重定向 | ||
| 8 | 0 | Echo request——回显请求(Ping请求) | x | |
| 9 | 0 | Router advertisement——路由器通告 | ||
| 10 | 0 | Route solicitation——路由器请求 | ||
| 11 | 0 | TTL equals 0 during transit——传输期间生存时间为0 | x | |
| 11 | 1 | TTL equals 0 during reassembly——在数据报组装期间生存时间为0 | x | |
| 12 | 0 | IP header bad (catchall error)——坏的IP首部(包括各种差错) | x | |
| 12 | 1 | Required options missing——缺少必需的选项 | x | |
| 13 | 0 | Timestamp request (obsolete)——时间戳请求(作废不用) | x | |
| 14 | Timestamp reply (obsolete)——时间戳应答(作废不用) | x | ||
| 15 | 0 | Information request (obsolete)——信息请求(作废不用) | x | |
| 16 | 0 | Information reply (obsolete)——信息应答(作废不用) | x | |
| 17 | 0 | Address mask request——地址掩码请求 | x | |
| 18 | 0 | Address mask reply——地址掩码应答 |
- 不同类型由报文中的类型字段和代码字段来共同决定
- 图中最后两列表明ICMP报文时一份查询报文还是一份差错报文
- 当发送一份ICMP差错报文时,报文始终包含IP的首部和产生ICMP差错报文的IP数据报的前8个字节(含有端口号的信息)。这样,接收ICMP差错报文的模块就会把它与某个特定的协议(根据IP数据包首部中的协议字段来判断)和用户进程(根据包含在IP数据报前8个字节中的TCP或UDP报文首部的TCP或UDP端口号来判断)联系起来。
ICMP差错报文
什么情况不会导致差错报文
- ICMP差错报文
- 目的地址是广播地址或多播地址的IP数据报
- 作为链路层广播的数据报
- 不是IP分片的第一片(没有端口号信息)
- 源地址不是单个主机的数据包。这就是说,源地址不能为零地址、环回地址、广播地址或多播地址
这些规则是为了防止过去允许ICMP差错报文对广播分组响应所带来的广播风暴
六、Ping介绍
- ping这个名字源于声纳定位操作。ping程序由Mike Muuss编写,目的是为了测试另一台主机是否可达。该程序发送一份ICMP回显请求报文给主机,并等待返回ICMP回显应答
- 可以用ping程序来确定问题出在哪里。ping程序还能测出到这台主机的往返时间,以表明该主机离我们有多远
- 一台主机的可达性可能不知取决于IP层是否可达,还取决于使用何种协议以及端口号。ping程序的运行结果可能显示某台主机不可达,但我们可以用telnet远程登录到该台主机的25号端口
ping程序
- 我们称发送回显请求的ping程序为客户,而称被ping的主机为服务器。大多数的TCP/IP实现都在内核中直接支持ping服务器——Z何种服务器不是一个用户进程(两种ICMP查询服务,地址掩码和时间戳请求,也都是在内核中进行处理得到)

- 对于其它类型的ICMP查询报文,服务器必须响应标识符和序列号字段,另外,客户发送的选项数据必须回显,假设客户对这些选项都会感兴趣
- unix系统在实现ping程序是是把ICMP报文中的识别符字段设置成发送进程的ID号,这样即使在同一台主机上同时运行了多个ping程序实例,ping程序也可以识别出返回的信息
- 在window下,不管开多少个窗口ping的identifier(标识符)都是相同的,而且每增加一个出去的ping包序列号增加256
IP记录路由选项
- 大多数不同版本的pping程序都提供**-R选项,以提供记录路由的功能**,它使得ping程序在发送出去的IP数据报中设置IPRR选项(该IP数据报包含ICMP回显请求报文)。这样,每个处理该数据报的路由器都把它的IP地址(出接口)放入选项字段中。当数据报到达目的端时,IP地址清单应该复制到ICMP回显应答中,这样返回途中所经过的路由器地址也被加入清单中。当ping程序收到回显应答时,他就打印出这份ip地址清单
- 源端主机生成RR选项,中间路由器对RR选项的处理,以及把ICMP回显请求中的RR清单复制到ICMP回显应答中,所以这些都是选项功能。幸运的是,现在的大多数系统都支持这些选项功能,只是有一些系统不把ICMP请求中的IP清单复制到ICMP应答中
- 但是,最大的问题是IP首部中只有有限的空间来存放IP地址。IP首部中的首部长度字段只有4bit,因此整个IP首部最长只能包括15个32bit长的字(60字节)。由于IP首部固定长度为20字节,RR选项用去3个字节,这样只剩下37个字节来存放IP地址清单,也就是说只能存放9个IP地址

- code是一个字节,指明IP选项的类型,对于RR选项来说,它的值为7.len是RR选项总字节长度,在这种情况下为39(尽量可以为RR选项设置比最大长度小的长度,但是ping程序总是提供39字节的选项字段,最多可以记录9个IP地址,由于IP首部中留给选项的空间有限,他一般情况都设置成最大长度)
- ptr称为指针字段。他是一个基于1的指针,指向存放下一个IP地址的位置,它的最小值为4,指向存放第一个IP地址的位置。随着每个IP地址存入清单,ptr的值分别为8,12,16,最大到36.当记录下9个IP地址后,ptr的值为40,表示清单已满
- 当路由器(根据定义应该是多穴)在清单中记录IP地址时,记录的是入口地址还是出口地址?RFC791【Postel 1981a】指定路由器记录出口IP地址。我们在后面将看到,当原始主机(运行ping程序的主机)收到带有RR选项的ICMP回显应答时,他也要把它的入口IP地址放入清单中。
IP时间戳选项

- 时间戳选项的代码为0x44.其他两个字段len和ptr有记录路由选项相同:选项总长度(一般为36或40)和指向下一个可用空间的指针(5,9,13等)
- 接下来两个字段是4bit的值:OF表示溢出字段,FT表示标志字段。时间戳选项的操作
- 时间戳的取值一般为自UTC午夜开始记的毫秒数,与ICMP时间戳请求和应答相类似。如果路由器不使用这种格式,他就可以插入任何它使用的时间表示格式,但是必须打开时间戳中的高位以表明为非标准值
- 与我们遇到的记录路由选项所受到的限制相比,时间戳选项遇到情况要更坏一些。我们如果要同时记录IP地址和时间戳(标志位为1),那么就可以同时存在其中的四对值。只记录时间戳是没有用处的,因为我们没有标明时间戳与路由器之间的对应关系(除非有一个永远不变的拓扑结构)
七、Traceroute程序
- 由Van Jacobson编写的Traceroute程序是一个能更深入探索TCP/IP协议的方便可用的工具
- Traceroute程序可以让我们看到IP数据报从一台主机传到另一台主机所经过的路由
- Traceroute程序还可以让我们使用IP源路由选项
- 使用手册上说:”程序由Steve Deering提议,由Van Jacobson实现,并由许多其他人根据C。Philip Wood,Tim Seaver及Ken Adelman等人提出的令人信服的建议或补充意见进行调整。“
Traceroute和IP路径选项的比较
为什么不用IP记录路径选项
- 并不是所有的路由器都支持记录路由选项(Traceroute程序不需要中间路由器具备任何特殊或可选功能)
- 记录路由一般是单向的选项。发送端设置该选项,接收端不得不从收到的IP首部中提取出所有信息,然后全部返回给发送端。我们看到大多数ping服务器的实现(内核中的ICMP回显应答功能)把接收到的RR清单返回,但是这样使得记录下来的IP地址翻了一番(一来一回)。这样做会受到一些限制(Traceroute程序只需要目的端运行一个UDP模块——其他不需要任何特殊的服务器应用程序)
- ip首部中留给选项的空间有限,不能存放当前大多数的路径
Traceroute程序的操作
- Tracerout程序使用ICMP报文和IP首部中的TTL字段(生存周期)。TTL 字段是由发送端初始设置一个8 bit字段。推荐的初始值由分配数字RFC指定,当前值为6 4。较老版本的系统经常初始化为1 5或3 2。我们从第7章中的一些p i n g程 序例子中可以看出,发送IC M P回显应答时经常常把T T L设为最大值255。
- 每个处理数据报的路由器都需要把T T L的值减1或减去数据报在路由器中停留的秒 数。由于大多数的路由器转发数据报的时延都小于1秒钟,因此TTL最终成为一个 跳站的计数器,所经过的每个路由器都将其值减1。
- 当路由器收到一份IP数据报,如果其T T L字段是0或1 ,则路由器不转发该数据报 (接收到这种数据报的目的主机可以将它交给应用程序,这是因为不需要转发该数 据报。但是在通常情况下,系统不应该接收TTL字段为0的数据报)。相反,路由器将该数据报丢弃,并给信源机发一份**ICMP超时"信息。**Tracerout程序的 关键在于包含这份IC MP信息的I P报文的信源地址是该路由器的I P地址。
- 我们该如何判断是否已经到达目的主机了呢?
- Tracerout程序发送一份U D P数据报给目的主机,但它选择一个不可能的值作为UDP端口号(大于30 000),使目的主机的任何f 应用程序都不可能使用该端口。因为,当该数据报到达时,将使目的主机的UD模块产生一份"端口不可 达"错误(见6.5节)的ICMP报文。这样,Tracerout程序所要做的就是区 分接收到的IC M P报文是超时还是端口不可达,以判断什么时候结束。
Traceroute的一些注意事项
- 源端口号( 42804 )看起来有些大.traceroute程序将其发送的U D P数据报的源端口号设置为Unix进程号与32768之间的逻辑或值.对于在同一台主机上多次运行traceroute程序的情况,每个进程都看看I C MP返回的UDP首部的源端口号,并且只处理那些对自己发送应答的报文.
- 首先,并不能保证现在的路由也是将来所要采用的路由,甚至两份连续的IP数据报都可能采用不同的路由.
- 第二,不能保证ICMP报文的路由与traceroute程序发送的UDP数据报采用同一路由. 这表明所打印出来的往返时间可能并不能真正体现数据报发出和返回的时间差(如果U D P数 据报从信源到路由器的时间是1秒,而ICMP报文用另一条路由返回信源用了3秒时间,则打印出来的往返时间是4秒).
- 第三,返回的ICMP报文中的信源I Pi地址是UDP数据报到达的路由器接口的IP地址.这与IP记录路由选项不同,记录的IP地址指的是发送接口地址.由于每个定义的路由器都白2个或更多的接口,因此,从A主机到B主机上运行t racerout e程序和从B主机到A主 机上运行tracerout e程序所得到的结果可能是不同的.
IP源站选路选项
-
源站选路(source routing)的思想是由发送者指定路由。它可以采用以下两种形式:
-
•严格的源路由选择。发送端指明I P数据报所必须采用的确切路由。如果一个路由器发现源路由所指定的下一个路由器不在其直接连接的网络上,那么它就返回一个"源站路由失败"的I C M P差错报文。
-
•宽松的源站选路。发送端指明了一个数据报经过的IP地址清单,但是数据报在清单上指明的任意两个地址之间可以通过其他路由器。
-
这个格式与记录路由选项格式基本一致。不同之处是,对于源站选路,我们必须在发送I P数据报前填充I P地址清单;而对于记录路由选项,我们需要为IP地址清单分配并清空一些空间,并让路由器填充该清单中的各项。同时,对于源站选路,只要为所需要的IP地址数分配空间并进行初始化,通常其教量小于9。而对于记录路由选项来说,必须尽可能地分配空间,以达到9个地址.
对于宽松的源站选路来说,cod e字段的值是0x83;而对于严格的源站选路,其值为0 x 8 9。1 e n和p t r字段与记录路由选项所描述的一样。

IP源站选路的操作机制
- 源站路由选项的实际称呼为"源站及记录路由"(对于宽松的源站选路和严梏的源站选路,分别用L S R R和S S R R表示),这是因为在数据报沿路由发送过程中,对IP地址清单进行了更新.下面是其运行过程:
- •发送主机从应用程序接收源站路由清单,将第1个表项去掉(它是数据报的最终目的地址),将剩余的项移到1个项中,并将原来的目的地址作为清单的展后一项.指针仍然指向清单的第1项(即,指针的值为4 ).
- •每个处理数据报的路由器检查其是否为数据报的最终地址.如果不是,则正常转发数据报 (在这种情况下,必须指明宽松源站选路,否则就不能接收到该数据报).
- •如果该路由器是最终目的,目指针不大于路径的长度,那么(1) 由ptr所指定的清单中的下一个地址就是数据报的最终目的地址;( 2) 由外出接口( outgoinginterface) 相对应的IP地址取代刚才使用的源地址;(3) 指针加4。
- Host Requirements RFC指明,T C P客户必须能指明源站选路,同时,TC P服务器必须能够接收源站选路,并且对于该TCP连接的所有报文段都能采用反向路由.如果TCP服务器下面接收到一个不同的源站选路,那么新的源站路由将取代旧的源站路由.

可以使用宽松源站路由+traceroute实现双向trace
八、IP选路
- 选路是IP最重要的功能之一.
- 在图9 - 1中,我们还描述了一个路由守护程序(daemon),通常这是一个用户进程.
- 在Unix系统中,大多数普通的守护程序都是路由程序和网关程序
- 路由表经常被IP访问,但是它被路由守护程序更新的频度却要低得多
- 当接收到I C M P重定向报文时,路由表也要被更新,
- 在本章中,我们还将用
netstat -r命令采显示路由表.
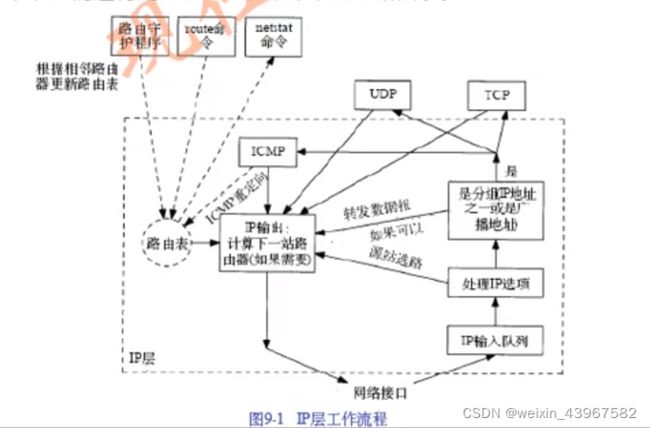
选路的原理
我们列出了IP搜索路由表的几个步骤:
- 1) 搜索匹配的主机地址;
- 2) 搜索匹配的网络地址;
- 3) 搜索默认表项(默认表项一般在路由表中被指定为一个网络表项,其网络号为0 ) 。
- ( cisco的选路策略)
- IP执行选路机制,而路由守护程序则一般提供选路策略。
简单路由表

- U该路由可以使用。
- G该路由是到一个网关(路由器)。如果没有设置该标志,说明目的地是直接相连的。
- H该路由是到一个主机,也就是说,目的地址是一个完整的主机地址。如果没有设置该标志,说明该路由是到一个网络,而目的地址是一个网络地址:一个网络号,或者网络号与子网号的组合。
- D该路由是由重定向报文创建的(9 . 5节)。
- M该路由已被重定向报文修改(9 . 5节)。
初始化路由表
- 每当初始化一个接口时(通常是用ifconfi g命令设置接口地址),就为接口自动创建一个直接路由。对于点对点链路和环回接口来说,路由是到达主机(例如,设置H标志)。对于广播接口来说,如以太网,路由是到达网络。
- 到达主机或网络的路由如果不是直接相连的,那么就必须加入路由表。
route add default sun 1
route add slip bsdi 1
route add 1.1.1.0 mask 255.255.255.0 1.1.1.1 - 第3个参数(defauIt和slip)代表目的端,第4个参数代表网关(路由器), 最后一个参数代表路由的度量(metric), route命令在度量值大于0时要为该路由设置G标志,否则,当耗费值为0时就不设置G标志。
没有到达目的地的路由
ping不通使用debug ip icmp
- 我们所有的例子都假定对路由表的搜索能找到匹配的表项,即使匹配的是默认项。如果路由表中没有默认项,而又没有找到匹配项,这时会发生什么情况呢?
- 如果数据报是由本地主机产生的,那么就给发送该数据报的应用程序返回一个差错,或者是主机不可达差错"或者是"网络不可达差错"。
- 如果是被转发的数据报,那么就给原始发送端发送一份IC M P主机不可达的差错报文。
转发或不转发
- 一般都假定主机不转发IP数据报,除非对它们进行特殊配置而作为路由器使用。
- 大多数伯克利派生出来的系统都有一个内核变量ipforwarding ,
- SunOS 4. 1.x允许该变量可以有三个不同的值:-1表示始终不转发并且始终不改变它的值;0表示默认条件下不转发,但是当打开两个或更多个接口时就把该值设为1 ; 1表示始终转发。Solaris 2.x把这三个值改为0(始终不转发)、1 (始终转发)和2 (在打开两个或更多个接口时才转发).
- 较早版本的4.2BSD主机在默认条件下可以转发数据报,这给没有进行正确配置的系统带来了许多问题。这就是内核选项为什么要设成默认的“始终不转发"的原因,除非系统管理员进行特殊设置。
PC启动服务才能转发,二层交换机不转发,三层交换机启动ip routing功能才能转发
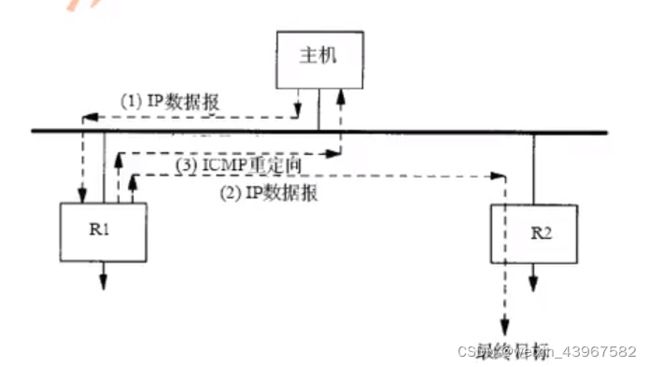
ICMP重定向差错
- 我们假定主机发送一份i p数据报给R 1。这种选路决策经常发生,因为R 1是该主机的默认路由。
- R1收到数据报并且检查它的路由表,发现R 2是发送该数据报的下一站。当它把数据报发送给R 2时,R 1检测到它正在发送的接口与数据报到达接口是相同的(即主机和两个路由器所在的LAN) 。这样就给路由器发送重定向报文给原始发送端提供了线索。
- R1发送一份I C M P值定向报文给主机,告诉它以后把数据报发送给R2而不是R 1.
只有在源端没有ip routing才生效
九、UDP
UDP介绍
- U D P是一个简单的面向数据报的运输层协议:进程的每个输出操作都正好产生一个UDP数据报,并组装成一份待发送的IP数据包。
- 这与面向流字符的协议不同,如T C P ,应用程序产生的全体数据与真正发送的单个I P数据报可能没有什么联系。
- U D P不提供可靠性:它把应用程序传给I P层的数据发送出去,但是并不保证它们能到达目的地。
- 应用程序必须关心IP数据报的长度。如果它超过网络的MTU( 2.8节),那么就要对IP数据报进行分片。我们将讨论IP分片机制。
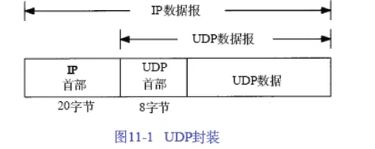
UDP三大典型运用
-
查询类:DNS
- 没有TCP三次握手过程,
- 多个DNS同时查询。
-
数据传输:TFTP
- 停止等待协议,慢(需运用层确认数据)
- 适合于无盘工作站
-
语音视频流
- 支持广播和组播
- 支持丢包,保障效率
UDP首部
-
端口号表示发送进程和接收进程
-
TC端口号与UDP端口号是相互独立的。(rsh和syslog=514)
-
尽管相互独立,如果T C P和U D P同时提供某种知名服务,两个协议通常选择相同的端口号。这纯粹是为了使用方便,而不是协议本身的要求。(dns )
-
UDP长度字段指的是UDP首部和UD数据的字节长度.该字段的最小值为8字节

UDP校验和
- U D P检验和覆盖U D P首部和U D P数据.
- ip首部的检验和,它只覆盖i p的首部
- U D P的检验和是可选的,而T C P的检验和是必需的.
- IP计算检验和和UD曲算检验和之间存在不同的地方。首先,UDP数据报的长度可以为奇数字节, 但是检验和算法是把若干个16 bit字相加。解决方法是必要时在最后增加填充字节0 ,这只是为了检验
和的计算(也就是说,可能增加的填充字节不被传送) - U D P数据报和T C P段都包含一个1 2字节长的伪首部,它是为了计算检验和而设置的。伪首部包含IP首部一些字段.其目的是让U D P两次检查数据是否已经正确到达目的地(例如,I P没有接受地址不是本主机的数据报,以及I P没有把应传给另一高层的数据报传给U D P )

IP分片
- IP把MTU与数据报长度进行比较。
- 如果需要则进行分片。分片可以发生在原始发送端主机上,也可以发生在中间路由器上。
- 把一份IP数据报分片以后,只有到达目的地才进行重新组装。(FR fragment)
- 重新组装由目的端的IP层来完成,其目的是使分片和重新组装过程对运输层(T C P和U D P) 是透明的。
- 已经分片过的数据报有可能会再次进行分片(可能不止一次)。
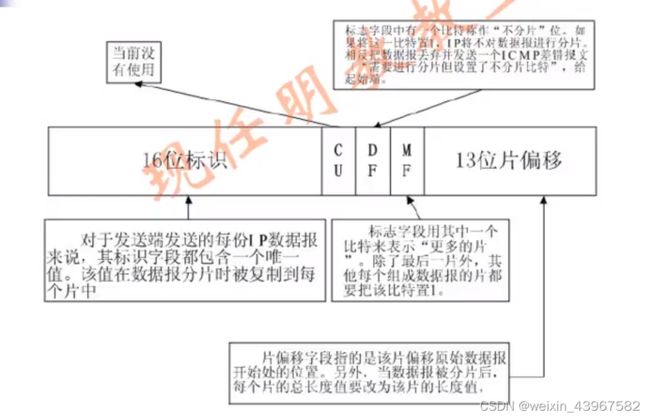
- 当IP数据报被分片后,每一片都成为一分组,具有自己的IP首部,并在选择路由时与其他分组独立。这样,当数据报的这些片到达目的端时有可能会失序,但是在IP首部中有足够的信息让接收端能正确组装这些数据报片。
- 尽管IP分片过程看起来是透明的,但有一点让人不想使用它:即使只丢失一片数据也要重传整个数据报。
- IP层本身没有超时重传的机制——由更高层来负责超时和重传(T C P有超时和重传机制,但UDP没有。一些U D P应用程序本身也执行超时和重传)。当来自T C P报文段的某一片丢失后,T C P在超时后会重发整个T C P报文段,该报文段对应于一份I P数据报。 没有办法只重传数据报中的一个数据报片。
- 如果对数据报分片的是中间路由器,而不是起始端系统,那么起始端系统就无法知道数据报是如何被分片的。就这个原因,经常要避免分片。
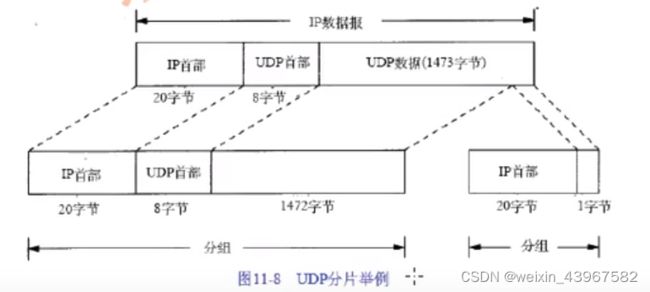
IP分片:注意事项
- 在分片时,除最后一片外,其他每一片中的数据部分(除I P首部外的其余部分)必须是8字节的整数
倍。 - IP首部被复制到各个片中。但是,端口号在UDP首部,只能在第1片中被发现。
- 需要解释几个术语:IP数据报是指IP层端到端的传输单元(在分片之前和重新组装之后),分组是
指在IP层和链路层之间传送的数据单元。一个分组可以是一个完整的I P数据报,也可以是I P数据报的
一个分片。
ICMP不可达差错(需要分片)
- 发生I c M P不可达差错的另一种情况是,当路由器收到一份需要分片的数据报,而在IP首部又设置了不分片(DF) 的标志比特。如果某个程序需要判断到达目的端的路途中最小MTU是多少一称作路径M T U发现机制,那么这个差错就可以被该程序使用。
- 如果路由器没有提供这种新的I C M P差错报文格式,那么下一站的M TU设为0。

最大UDP数据报长度
- IP数据报的最大长度是6 5 5 3 5字节,这是由I P首部1 6比特总长度字段所限制的
- 我们将遇到两个限制因素。第一,应用程序可能会受到其程序接口的限制。socket APl提供了一个可供应用程序调用的函数,以设置接收和发送缓存的长度。对于UDP socket ,这个长度与应用程序可以读写的最大U D P数据报的长度直接相关。现在的大部分系统都默认提供了可读写大于8 1 9 2字节的U D P数据报(使用这个默认值是因为8 1 9 2是N F S读写用户数据数的默认值).
- 第二个限制来自于TCP/I P的内核实现。可能存在一些实现特性(或差错),使I P数据报长度小于6 553 5字节。
- 在SunOS 4.1.3下使用环回接口的最大IP数据报长度是3 2 7 6 7字节。比它大的值都会发生差错。IMAB SD/3 8 6到SunOS 4.1.3情况下,S u n所能接收到最大IP数据报长度为32786字节(即3 2 7 5 8字节用户数据).在Solaris 2.2下使用坏回接口,最大可收发IP数据报长度为65535字节。从Solaris 2.2到AIX 3.2.2 ,发送的最大IP数据报长度可以是65535字节.很显然,这个限制与源端和目的端的实现有关。
- 之前提过,要求主机必须能够接收最短为576字节的IP数据报。在许多U D P应用程序的设计中,其应用程数据 被限制成5 1 2字节或更小,因此比这个限制值小。
数据报截断
- 由于IP能够发送或接收特定长度的数据报并不意味着接收应用程序可以读取该长度的数据。因此,UDP编程接口允许应用程序指定每次返回的最大字节数。如果接收到的数据报长度大于应用程序所能处理的长度,那么会发生什么情况呢?
- 不幸的是,该问题的答案取决于编程接口和实现.
- 典型的B e r k e 1 e y版socket API对数据报进行截断,并丢弃任何多余的数据。应用程序何时能够知道,则与版本有关(4.3BSDReno及其后的版本可以通知应用程序数据报被截断)
- SVR4下的socket API(包括Solaris 2.x) 并不截断数据报。超出部分数据在后面的读取中返回。它也不通知应用程序从单个UDP数据报中多次进行读取操作。
- TLI API不丢弃数据。相反,它返回一个标志表明可获得更多的数据,而应用程序后面的读操作将返回数据报的其余部分。
- 在讨论TCP时,我们发现它为应用程序提供连续的字节流,而没有任何信息边界 。TCP以应用程序读操作时所要求的长度来传送数据,因此,在这个接口下,不会发生数据丢失。
ICMP源站抑制差错
- 新的Router Requirements RFC提出路由器不应该产生源站抑制差错报文。由于源站抑制要消耗网络带宽,且对于拥塞来说是一种无效而不公平的调整,因此现在人们对于源站抑制差错的态度是不支持的。
- 还需要指出的是,sock程序要么没有接收到源站抑制差错报文,要么接收到却将它们忽略了。结果是如果采用UDP协议,那么 B S D实现通常忽略其接收到的源站抑制报文(TC P接受源站抑制差错报文,并将放慢在该连接上的数据传输速度)。其部分原因在于,在接收到源站抑制差错报文时,导致源站抑制的进程可能已经中止了。
UDP输入队列
- 我们还可以看到,服务器的-E选项使其可以知道每个数据报的目的IP地址。如果需要,它可以选择如何处理其接收到的第一个数据报,这个数据报的地址是广播地址。
- 我们可以从本例中看到以下几个要点。首先,应用程序并不知道其输入队列何时溢出。只是由UDP对超出数据报进行丢弃处理。同时,从tcpdump输出结果,我们看到,没有发回任何信息告诉客户其数据报被丢弃(对IP和UDP来说包已经到达目的地了)。这里不存在像ICMP源站抑制这样发回发送端的消息。最后,看来UDP输出队列是FIFO(先进先出)的,而ARP输入却是LIF0(后进先出)的。
每个端口有多个接受者
大多数的系统在某一时刻只允许一个程序端点与某个本地IP地址及UDP端口号相关联。当目的地为该IP地址及端口号的UDP数据报到达主机时,就复制一份传给该端点。
十、广播和多播
- 三种IP地址:单播地址、广播地址和多播地址。本章将更详细地介绍广播和多播。
- 广播和多播仅应用于UDP,它们对需将报文同时传往多个接收者的应用来说十分重要。
- TCP是一个面向连接的协议,它意味着分别运行于两主机(由IP地址确定)内的两进程(由端口号确定)间存在一条连接。一定单播
- 有时一个主机要向网上的所有其他主机发送帧,这就是广播。通过ARP和RARP可以看到这一过程。
- 多播(multicast)处于单播和广播之间:帧仅传送给属于多播组的多个主机。
数据帧过滤过程


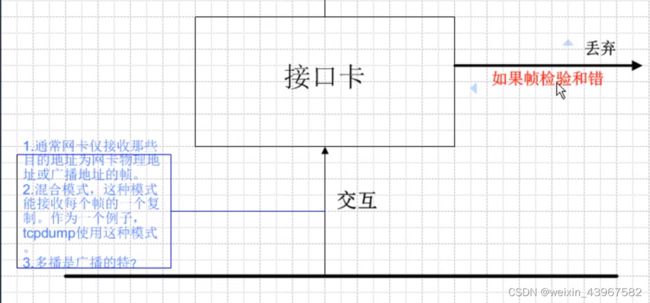
广播
- 受限的广播.255.255.255.255
- 指向网络的广播10.255.255.255 192.168.1.255
- 指向子网的广播10.1.1.255 10.1.255.255
- 指向所有子网的广播10.255.255.255
- 主机处理的地址 192.168.255.255(cisco路由器支持)
- 路由器支持255.255.255.255,主机不支持(当主机处理)
十一、DNS
十二、TFTP
十一、TCP传输控制协议
1.TCP的服务
-
TCP提供一种面向连接的、可靠的字节流服务。
-
面向连接意味着两个使用TCP的应用(通常是一个客户和一个服务器)在彼此交换数据之前必须先建立一个TCP连接。
-
在一个TCP连接中,仅有两方进行彼此通信。广播和多播不能用于TCP。
-
TCP通过下列方式来提供可靠性:
- 应用数据被分割成TCP认为最适合发送的数据块。
- 当TCP发出一个段后,它启动一个定时器,等待目的端确认收到这个报文段。如果不能及时收到一个确认,将重发这个报文段。
- 当TCP收到发自TCP连接另一端的数据,它将发送一个确认。这个确认不是立即发送,通常将推迟几分之一秒。
- TCP将保持它首部和数据的检验和。
- 既然TCP报文段作为IP数据报来传输,而IP数据报的到达可能会失序,因此TCP报文段的到达也可能会失序。如果必要,TCP将对收到的数据进行重新排序,将收到的数据以正确的顺序交给应用层。
- 既然IP数据报会发生重复,TCP的接收端必须丢弃重复的数据。
- TCP还能提供流量控制。TCP连接的每一方都有固定大小的缓冲空间。TCP的接收端只允许另一端发送接收端缓冲区所能接纳的数据。这将防止较快主机致使较慢主机的缓冲区溢出。
2.TCP的字节流
-
两个应用程序通过TCP连接交换8bit字节构成的字节流。 TCP不在字节流中插入记录标识符。我们将这称为字节流服务(byte stream service)。如果一方的应用程序先传10字节又传20字节,再传50字节,连接的另一方将无法了解发方每次发送了多少字节。收方可以分4次接收这80个字节,每次接收20字节。一端将字节流放到TCP连接上,同样的字节流将出现在TCP连接的另一端。
-
另外,TCP对字节流的内容不作任何解释。TCP不知道传输的数据字节流是二进制数据,还是ASCII字符、EBC DIC字符或者其他类型数据。对字节流的解释由TCP连接双方的应用层解释。
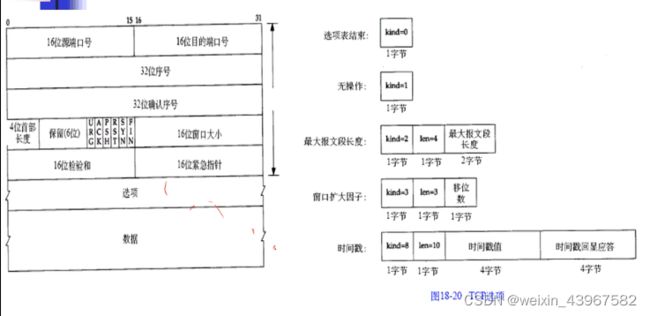
3.TCP的首部
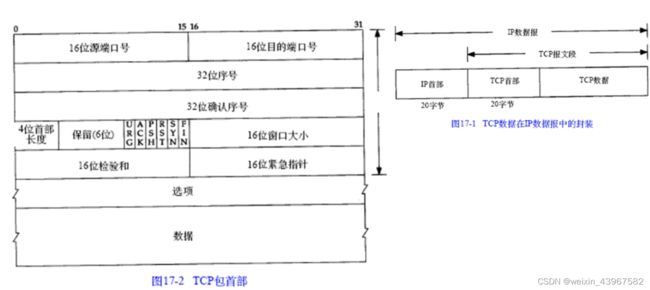
-
每个TCP段都包含源端和目的端的端口号,用于寻找发端和收端应用进程。这两个值加上IP首部中的源端IP地址和目的端IP地址唯一确定一个TCP连接。
-
一个IP地址和一个端口号也称为一个插口(socket)插口对(socketpair)
-
序号用来标识从TCP发端向TCP收端发送的数据字节流,它标识在这个报文段中的的第一个数据字节的序号。如果将字节流看作在两个应用程序间的单向流动,则TCP用序号对每个字节进行计数。序号是32bit的无符号数,序号到达2的32次方减1后又从0开始。SYN标志消耗了一个序号(将在下章详细介绍如何建立和终止连接,届时我们将看到FIN标志也要占用一个序号)。
-
确认序号应当是上次已成功收到数据字节序号加1只有ACK标志(下面介绍)为1时确认序号字段才有效。
-
发送ACK无需占用任何序号,因为32bit的确认序号字段和ACK标志一样,总是TCP首部的一部分。因此,我们看到一旦一个连接建立起来,这个字段总是被设置,AC K标志也总是被设置为1。
-
TCP为应用层提供全双工服务。这意味数据能在两个方向上独立地进行传输。因此,连接的每一端必须保持每个方向上的传输数据序号
-
TCP可以表述为一个没有选择确认(现已支持选择性确认)或否认的滑动窗口协议(滑动窗口协议用于数据传输将在20.3节介绍)。我们说TCP缺少选择确认是因为TCP首部中的确认序号表示发方已成功收到字节,但还不包含确认序号所指的字节。当前还无法对数据流中选定的部分进行确认。例如,如果11024字节已经成功收到,下一报文段中包含序号从20493072的字节,收端并不能确认这个新的报文段。它所能做的就是发回一个确认序号为1025的ACK。它也无法对一个报文段进行否认。例如,如果收到包含1025~2048字节的报文段,但它的检验和错,TCP接收端所能做的就是发回一个确认序号为1025的ACK。
-
首部长度给出首部中32bit字的数目。需要这个值是因为任选字段的长度是可变的。这个字段占4bit,因此TCP最多有60字节的首部。然而,没有任选字段,正常的长度是20字节。
-
在TCP首部中有6个标志比特。它们中的多个可同时被设置为1。

- TCP的流量控制由连接的每一端通过声明的窗口大小来提供。窗口大小为字节数这个值是接收方控制发送方可以连续发送未经确认的报文的数量。窗口大小是一个16bit字段,因而窗口大小最大为65535字节。在24.4节我们将看到新的窗口刻度选项,它允许这个值按比例变化以提供更大的窗口。
- 检验和覆盖了整个的TCP报文段:TCP首部和TCP数据。这是一个强制性的字段,一定是由发端计算和存储,并由收端进行验证。TCP检验和的计算和UDP检验和的计算相似,使用如113节所述的一个伪首部。
- 只有当URG标志置1时紧急指针才有效。紧急指针是一个正的偏移量,和序号字段中的值相加表示紧急数据最后一个字节的序号。TCP的紧急方式是发送端向另一端发送紧急数据的一种方式。
- 最常见的可选字段是最长报文大小,又称为MSS(MaximumSegmentSize)。每个连接方通常都在通信的第一个报文段(为建立连接而设置SYN标志的那个段)中指明这个选项。它指明本端所能接收的最大长度的报文段。
- TCP报文段中的数据部分是可选的。我们将在之后中看到在一个连接建立和一个连接终止时,双方交换的报文段仅有TCP首部。如果一方没有数据要发送,也使用没有任何数据的首部来确认收到的数据。在处理超时的许多情况中,也会发送不带任何数据的报文段。
4.TCP链接的建立和终止
建立链接协议
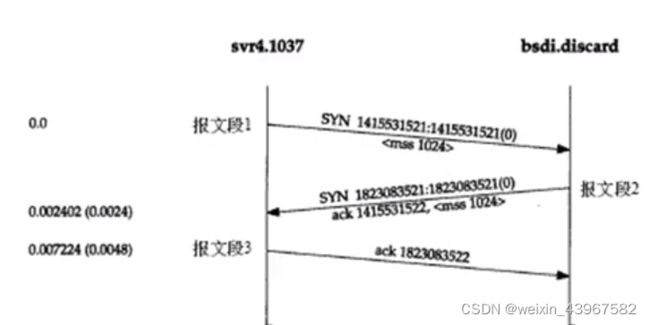
- 发送第一个SYN的一端将执行主动打开(activeopen)。接收这个SYN并发回下一个SYN的另一端执行被动打开(passive open)
- 当一端为建立连接而发送它的SYN时,它为连接先择一个初始序号。ISN有时间而变化因此每个连接都将且有不同的ISN。RFC 793[Postel 1981c]指出ISN可看作是一个32比特的计数器,每4ms加1。这样选择序号的目的在于防止在网络中被延迟的分组在以后又被传送,而导致某个连接的一方对它作错误的解释。
- 如何进行序号选择?在4.4BSD(和多数的伯克利的实现版)中,系统初始化时初始的发送序号破初始化为1。这种方法违背了Host RequirementsRFC(在这个代码中的一个注释确认这是一个错误)。这个变量每05秒增加64000,并每隔95小时又回到0(对四文个计数器每8ms加1,而不是每4ms加1)。另外,每次建立一个连接后,这个变量将增加64000。
链接终止协议

-
建立一个连接需要三次握手,而终止一个连接要经过4次握手。这由TCP的半关闭(half-c lose)造成的。既然一个TCP连接是全双工(即数据在两个方向上能同时传递),因此每个方向必须单独地进行关闭。这原则就是当一方完成它的数据发送任务后就能发送一个FIN来终止这个方向连接。当一端收到一个FIN它必须通知应用层另一端几经终止了那个方向的数据传送。发送FIN通常是应用层进行关闭的结果。
-
收到一个FIN只意味着在这一方向上没有数据流动。一个TCP连接在收到一个FIN后仍能发送数据。而这对利用半关闭的应用来说是可能的,尽管在实际应用中只有很少的TCP应用程序这样做。
-
首先进行关闭的一方(即发送第一个FIN)将执行主动关闭,而另一方(收到这个FIN)执行被动关闭。通常一方完成主动关闭而另一方完成被动关闭。
-
发送FIN将导致应用程序关闭它们的连接,这些FIN的ACK是由TCP软件自动产生。
链接建立的超时

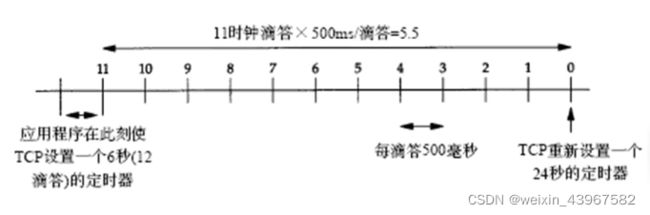
-
在这个输出中有趣的一点是客户间隔多长时间发送一个SYN试图建立连接。第2个SYN与第1个的间隔是5.8秒,而第3个与第2个的间隔是24秒
-
作为一个附注,这个例子是运行38分钟后客户机启动tcp连接。这对应初始序号为291008001(约为38x60x64000x2)。我们曾经介绍过使用典型的伯克利实现版的系统将初始序号初始化为1然后每隔05秒就增加64000。另外,因为这是系统启动后的第一个TCP连接,因此客户的端口号是1024。
-
时间差值是76秒。大多数伯克利系统将建立一个新连接的最长时间限制为75秒。我们将在21.4节看到由客户发出的第3个分组大约在162529超时,客户在它第3个分组发出后48秒而不是75秒后放弃连接。
-
上个例子中一个令人困惑的问题是第一次超时时间为5.8秒,接近6秒,但不准确,相比之下第二个超时时间几乎准确地为24秒。运行十多次测试,发现第一次超时时间在5.59秒~5.93秒之间变化。然而,第二次超时时间则总是24.00秒(精确到小数点后面两位)。
最大报文段长度
- 在有些书中,将它看作可“协商”选项。它并不是任何条件下都可协商。当建立一个连接时,每一方都有用于通告它期望接收的MSS选项(MSS选项只能出现在SYN报文段中)。如果一方不接收来自另一方的MSS值,则MSS就定为默认值536字节
- 一般说来,如果没有分段发生,MSS还是越大越好(这也并不总是正确,参见图24-3和图24-4中的例子)。报文段越大允许每个报文段传送的数据就越多,相对IP和TCP首部有更高的网络利用率。当TCP发送一个SYN时,或者是因为一个本地应用进程想发起一个连接,或者是因为另一端的主机收到了一个连接请求,它能将MSS值设置为外出接口上的MTU长度减去固定的IP首部和T CP首部长度(40字节)。对于一个以太网,MSS值可达1460字节。使用IEEE8023的封装(参见2.2节)它的MSS可达1452字节。
- 如果目的IP地址为"非本地的(nonlocal)”MSS通常的默认值为536。而区分地址是本地还是非本地是简单的,如果目的IP地址的网络号与子网号都和我们的相同,则是本地的;如果目的IP地址的网络号与我们的完全不同,则是非本地的:如果目的IP地址的网络号与我们的相同而子网号与我们的不同,则可能是本地的,也可能是非本地的。大多数TCP实现版都提供了一个配置选项(附录E和图E-1),让系统管理员说明不同的子网是属于本地还是非本地。这个选项的设置将确定MS S可以选择尽可能的大(达到外出接目的MTU长度)或是默认值536
TCP的半关闭
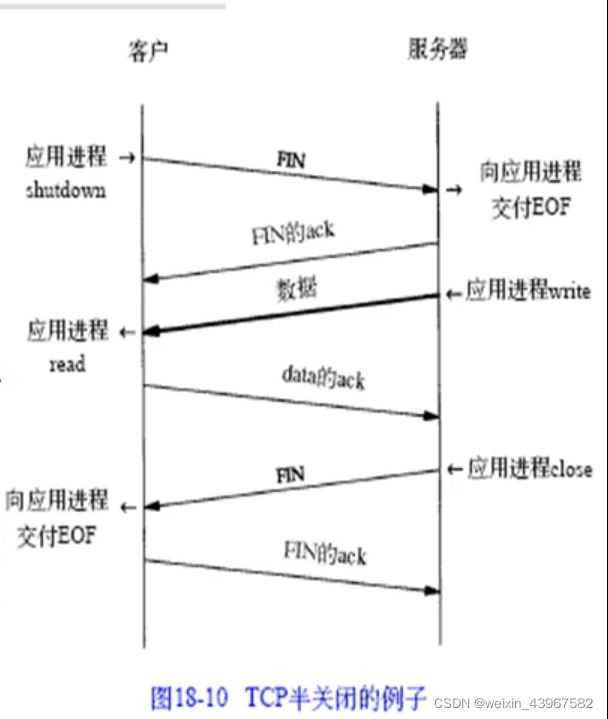
- TCP提供了连接的一端在结束它的发送后还能接收来自另一端数据的能力。这就是所谓的半关闭。正如我们早些时候提到的只有很少的应用程序使用它。
- 为什么要有半关闭?一个例子是Unix中的rsh(1命令,它将完成在另一个系统上执行一个命令。命令
sun%rsh bsdi sort - 将在主机bsdi上执行sort排序命令rs h命令的标准输入来自文件datafile.rsh将在它与在另一主机上执行的程序间建立一个T CP连接。rsh的操作很简单:它将标准输入(datafile)复制给TCP连接,并将结果从T CP连接中复制给标准输出(我们的终端)。图18-11显示了这个建立过程(牢记TCP连接是全双工的)。
- 没有半关闭,需要其他的一些技术让客户通知服务器客户端已经完成了它的数据传送,但仍要接收来自服务器的数据。使用两个TCP连接也可作为一个选择

TCP状态变迁图
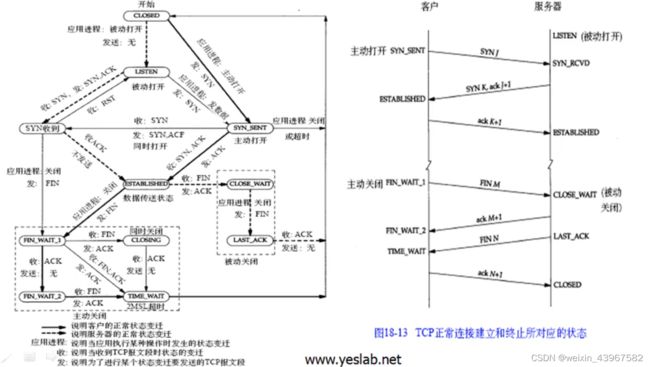
2MSL等待状态
-
TIMEWAIT状态也称为2MSL等待状态。每个具体TCP实现必须选择一个报文段最大生存时间MSL(MaximumSegmentLifetime)。它是任何报文段被丢弃前在网络内的最长时间。
-
RFC793[Postel1981c]指出MSL为2分钟。然而,实现中的常用值是30秒,1分钟,或2
分钟。 -
对一个具体实现所给定的MSL值,处理的原则是:当TCP执行一个主动关闭,并发回最后一个ACK,该连接必须在TIMEWAIT状态停留的时间为2倍的MSL。这样可让TCP再次发送最后的ACK以防这个ACK丢失(另一端超时并重发最后的FIN)。
-
这种2MSL等待的另一个结果是这个TCP连接在2MSL等待期间,定义这个连接的插口(处于timewait的那一端(客户/服务器)的IP地址和端口号)不能再被使用。这个连接只能在2MSL结束后才能再被使用。
-
在连接处于2MSL等待时,任何迟到的报文段将被丢弃。因为处于2MSL等待的、由该插口对(socketpair)定义的连接在这段时间内不能被再用,因此当要建立一个有效的连接时,来自该连接的一个较早替身(incarnation)的迟到报文段作为新连接的一部分不可能不被曲解
-
客户执行主动关闭并进入TIMEWAIT是正常的。服务器通常执行被动关闭,不会进入TIME WAIT状态。这暗示如果我们终止一个客户程序,并立即重新启动这个客户程序,则这个新客户程序将不能重用相同的本地端口。这不会带来什么问题,因为客户使用本地端口,而并不关心这个端口号是什么。
-
对于服务器,情况就有所不同,因为服务器使用知名端口。如果我们终止一个已经建立连接的服务器程序,并试图立即重新启动这个服务器程序,服务器程序将不能把它的这个知名端口赋值给它的端点,因为那个端口是处于2MSL连接的一部分。在重新启动服务器程序前,它需要在1~4分钟。

平静时间的概念
- 对于来自某个连接的较早替身的迟到报文段,2MSL等待可防止将它解释成使用相同插口对的新连接的一部分。但这只有在处于2MSL等待连接中的主机处于正常工作状态时才有效。
- 如果使用处于2MSL等待端口的主机出现故障,它会在MSL秒内重新启动,并立即使用故障前仍处于2MSL的插口对来建立一个新的连接吗?如果是这样,在故障前从这个连接发出而迟到的报文段会被错误地当作属于重启后新连接的报文段。无论如何选择重启后新连接的初始序号,都会发生这种情况。
- 为了防止这种情况,RFC793指出TCP在重启动后的MSL秒内不能建立任何连接。这就称为平静时间(quiettime)。
- 只有极少的实现版遵守这一原则,因为大多数主机重启动的时间都比MSL秒要长。
FIN_WAIT_2状态
- 在FINWAIT2状态我们已经发出了FIN,并且另一端也已对它进行确认。除非我们在实行半关闭,否则将等待另一端的应用层意识到它已收到一个文件结束符说明,并向我们发一个FIN来关闭另一方向的连接。只有当另一端的进程完成这个关闭,我们这端才会从FINWAIT2状态进入TIMEWAIT状态。
- 这意味着我们这端可能永远保持这个状态。另一端也将处于CLO SEWAIT状态,并一直保持这个状态直到应用层决定进行关闭。
复位报文段
-
我们已经介绍了TCP首部中的RST比特是用于“复位”的。(收到RST比特,链接直接断掉)
-
一般说来,无论何时一个报文段发往基准的连接(referenced connection)出现错误,TCP都会发出一个复位报文段(这里提到的“基准的连接”是指由目的IP地址和目的端口号以及源IP地址和源端口号指明的连接)。
-
到不存在的端口的链接请求
异常终止一个链接
-
终止一个连接的正常方式是一方发送FIN。有时这也称为有序释放(orderlyrelease)。
-
有可能发送一个复位报文段而不是FIN来中途释放一个连接。有时称这为异常释放(abortive release)。
-
异常终止一个连接对应用程序来说有两个优点:(1)丢弃任何待发数据并立即发送复位报文段(快);(2)RS T的接收方会区分另一端执行的是异常关闭还是正常关闭。应用程序使用的API必须提供产生异常关闭而不是正常关闭的手段。
-
检测半打开链接(服务器重启,发送reset)
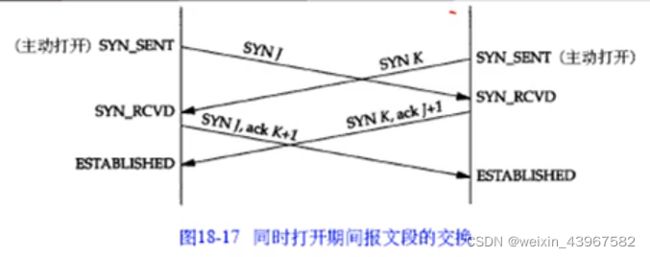
同时打开
原端口号,目的端口号,协议号是,发送时间一样
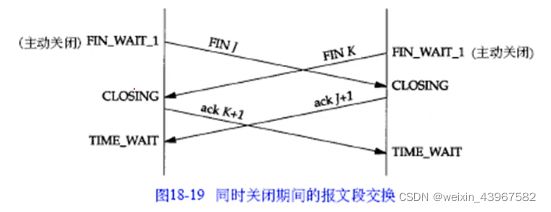
同时关闭
5.TCP选项
- 每个选项的开始是1字节kind字段,说明选项的类型。kind字段为0和1的选项仅占1个字节。其他的选项在kind字节后还有len字节。它说明的长度是指总长度,包括kind字节和len字节。
- MSS选项设置为512,后面是NOP,接着是窗口扩大选项。第一个NOP用来将窗口扩大选项填充为4字节的边界。同样,10字节的时间戳选项放在两个NOP后占12字节,同时使两个4字节的时间戳满足4字节边界。

6.TCP的交互数据流
- 如果按照分组数量计算,约有一半的TCP报文段包含成块数据(如FTP、电子邮件和Usenet新闻)另一半则包含交互数据(如Telnet和Rlogin)。
- 如果按字节计算,则成块数据与交互数据的比例约为90%和10%。
- TCP需要同时处理这两类数据,但使用的处理算法则有所不同。本章将以Rlogin应用为例来观察交互数据的传输过程。
交互式输入
- 通常每一个交互按键都会产生一个数据分组
- 这样就会产生4个报文段:(1)来自客户的交互按键:(2)来自服务器的按键确认;(3)来自服务器的按键回显;(4)来自客户的按键回显确认。
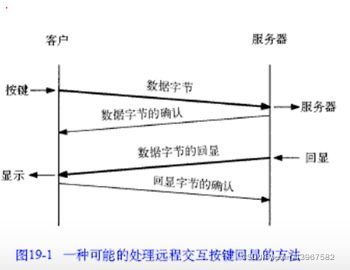
经受时延确认
- 通常TCP在接收到数据时并不立即发送ACK;相反它推迟发送,以便将ACK与需要沿该方向发送的数据一起发送(有时称这种现象为数据捎带ACK)。绝大多数实现采用的时延为200 ms,也就是说,TCP将以最大200ms的时延等待是否有数据一起发送。
Negle算法
- 该算法要求一个TCP连接上最多只能有一个未被确认的未完成的小分组,在该分组的确认到达之前不能发送其他的小分组。相反,TCP收集这些少量的分组,并在确认到来时以一个分组的方式发出去。该算法的优越之处在于它是自适应的:确认到达得越快,数据也就发送得越快。而在希望减少微小分组数目的低速广域网上则会发送更少的分组
- 注意到从左到右待发数据的长度是不同的分别为:1、1、2、1、2、2、3、1和3个字节。这是因为客户只有收到前一个数据的确认后才发送已经收集的数据。通过使用Nagle算法,为发送16个字节的数据客户只需要使用9个报文段,而不再是16个

- 有时我们也需要关闭Nagle算法。一个典型的例子是X窗口系统服务器(见305节):小消息(鼠标移动)必须无时延地发送,以便为进行某种操作的交互用户提供实时的反馈。
- 这里将举另外一个更容易说明的例子-在一个交互注册过程中键入终端的一个特殊功能键。这个功能键通常可以产生多个字符序列,经常从ASCII码的转义(escape)字符开始。如果TCP每次得到一个字符,它很可能会发送序列中的第一个字符(ASCII码的ESC),然后缓存其他字符并等待对该字符的确认。但当服务器接收到该字符后它并不发送确认,而是继续等待接收序列中的其他字符。这就会经常触发服务器的经受时延的确认算法,表示剩下的字符没有在200ms内发送。对交互用户而言,这将产生明显的时延。
窗口大小通告
Nagle算法中:
- 报文段5通告的窗口大小为4095个字节,这意味着在TCP的缓冲区中仍然有一个字节等待应用程序(Rlogin客户)读取。同样,来自客户的下一个报文段声明其窗口大小为4094个字节,这说明仍有两个字节等待读取。
- 服务器通常通告窗口大小为8192个字节,这是因为服务器在读取并回显接收到的数据之前,其TCP没有数据发送。
- 然而,在ACK到来时,客户的TCP总是有数据需要发送。这是因为它在等待ACK的过程中缓存接收到的字符。当客户TCP发送缓存的数据时Rlogin客户没有机会读取来自服务器的数据,因此,客户通告的窗口大小总是小于4096。
7.TCP成块数据流
正常数据流
- 通常使用的“隔一个报文段确认”的策略。
- 我们在线路上看到的分组顺序依赖于许多无法控制的因素:发送方TCP的实现、接收方TCP的实现、接收进程读取数据(依赖于操作系统的调度)和网络的动态性(如以太网的冲突和退避等)。对这两个TCP而言,没有一种单一的、正确的方法来交换给定数量的数据。
快的发送方和慢的接收方
- 接收方发送ACK(报文段8)但通告其窗口大小为0,这说明接收方已收到所有数据,但这些数据都在接收方的TCP缓冲区因为应用程序还没有机会读取这些数据。
- 另一个ACK(称为窗口更新)在17.4ms后发送,表明接收方现在可以接收另外的4096个字节的数据。虽然这看起来像一个A CK,但由于它并不确认任何新数据,只是用来增加窗口的右边沿,因此被称为窗口更新。
滑动窗口

- 在这个图中,我们将字节从1至11进行标号。接收方通告的窗口称为提出的窗口(offeredwindow),它覆盖了从第4字节到第9字节的区域,表明接收方已经确认了包括第3字节在内的数据,且通告窗口大小为6。回顾第17章,我们知道窗口大小是与确认序号相对应的。发送方计算它的可用窗口,该窗口表明多少数据可以立即被发送。当接收方确认数据后,这个滑动窗口不时地向右移动。窗口两个边沿的相对运动增加或减少了窗口的大小。

1)称窗口左边沿向右边沿靠近为窗口合拢。这种现象发生在数据被发送和确认时。
2)当窗口右边沿向右移动时将允许发送更多的数据,我们称之为窗口张开。这种现象发生在另一端的接收进程读取已经确认的数据并释放了TCP的接收缓存时。
3)当右边沿向左移动时,我们称之为窗口收缩。HostRequirements RFC强烈建议不要使用这种方式。
左边沿移动到ACK确定的序号位置
右边沿移动到ACK确定的序号位置+winsize
4)发送方不必发送一个全窗口大小的数据。
5)来自接收方的一个报文段确认数据并把窗口左边沿向右滑动。这是因为窗口的大小是相对于确认序号的。
6正如从报文段7到报文段8中变化的那样,窗口的大小可以减小,但是窗口的右边沿却不能够向左移动。
7)接收方在发送一个ACK前不必等待窗口被填满。在前面我们看到许多实现每收到两个报文段就会发送一个ACK。
PUSH标志
在每一个TCP例子中,我们都看到了PUSH标志,但一直没有介绍它的用途发送方使用该标志通知接收方将所收到的数据全部提交给接收进程。这里的数据包括与PUSH一起传送的数据以及接收方TCP已经为接收进程收到的其他数据。
慢启动
- 迄今为止,在本章所有的例子中,发送方一开始便向网络发送多个报文段,直至达到接收方通告的窗口大小为止。当发送方和接收方处于同一个局域网时,这种方式是可以的。但是如果在发送方和接收方之间存在多个路由器和速率较慢的链路时,就有可能出现一些问题。一些中间路由器必须缓存分组,并有可能耗尽存储器的空间,然后发生丢包。
- TCP采用“慢启动(slowstart)”算法来降低一开始就发送过多的数据到网络。
- 慢启动为发送方的TCP增加了另一个窗口:拥塞窗口(congestion window),记为cwnd。当与另一个网络的主机建立TCP连接时,拥塞窗口被初始化为1个报文段(即另一端通告的报文段大小)。每收到一个ACK,拥塞窗口就增加一个报文段(cwnd 以字节为单位,但是慢启动以报文段大小为单位进行增加)。发送方取拥塞窗口与通告窗口中的最小值作为发送上限。拥塞窗口是发送方使用的流量控制,而通告窗口则是接收方使用的流量控制。(发送数据大小为拥塞窗口和通告窗口小的那个)
- 发送方开始时发送一个报文段,然后等待ACK。当收到该ACK时拥塞窗口从1增加为2,即可以发送两个报文段。当收到这两个报文段的 ACK时,拥塞窗口就增加为4。这是一种指数增加的关系。
- 在某些点上可能达到了互联网的容量,于是中间路由器开始丢弃分组,发送方检测到丢包,相当于得到通知:发送方的拥塞窗口开得过大,需要调整。我们将在下一章讨论TCP的超时和重传机制。
发送一个分组的时间
- 通常发送一个分组的时间取决于两个因素:传播时延和发送时延(带宽)。
- 对于一个给定的两个接点之间的通路,传播时延一般是固定的,而发送时延则取决于分组的大小。
- 在速率较慢的情况下发送时延起主要作用,而在千兆比特速率下传播时延则占主要地位。
带宽时延乘积
- 为了最大限度的利用链路带宽,必须确保发送方源源不断的收到接收方发送的ACK,做为对收到数据的确认和更新widowsize的大小。
- 在开始阶段,通告的windowsize必须大于等于带宽和往返时延的乘积,才能确保在收到第一个ACK前,能够一直发送数据流量。因为发送第一个数据报文到收到对应的ACK,时间至少为RTT时间。
- 因此传送通道容量为:
capacity(bit)=bandwidth(b/s)xround-triptime(s)
拥塞
高速电路到低速电路
汇聚电路
紧急方式
-
TCP提供了"紧急方式(urgentmode)”,它使一端可以告诉另一端有些具有某种方式的“紧急数据”已经放置在普通的数据流中。另一端被通知这个紧急数据已被放置在普通数据流中,由接收方决定如何处理。可以通过设置TC P首部(图17-2)中的两个字段来发出这种从一端到另一端的紧急数据已经被放置在数据流中的通知。URG比特被置1,并且一个16bit的紧急指针被置为一个正的偏移量,该偏移量必预与TCP首部中的序号字段相加,以便得出紧急数据的最后一个字节的序号。
-
TCP必须通知接收进程,已接收到一个紧急数据指针。接收进程读取数据流并被告知何时碰到紧急数据指针。只要从接收方当前读取位置到紧急数据指针之间有数据存在,就认为应用程序处于“紧急方式”。在紧急指针通过之后,应用程序便转回到正常方式。
-
TCP本身对紧急数据知之其少。没有办法指明紧急数据从数据流的何处开始。 TCP通过连接传送的唯一信息就是紧急万式已经开始(TCP首部中的URG比特)和指向紧急数据最后一个字节的指针。其他的事情留给应用程序去处理。
-
紧急方式有什么作用呢?两个最常见的例子是Telnet和Rlogin。当交互用户键入中断键时,我们在第26章将看到使用紧急方式来完成这个功能的例子。另一个例子是FTP,当交互用户放弃一个文件的传输时。
-
Telnet和Rlogin从服务器到客户使用紧急万式是因为在这个方向上的数据流很可能要被客户的TCP停止(也即,它通告了一个大小为0的窗口)。但是如果服务器进程进入了紧急方式,尽管它不能够发送任何数据,服务器TCP也会立即发送紧急指针和UR G标志。当客户TCP接收到这个通知时就会通知客户进程,于是客户可以从服务器读取其输入、打开窗口并使数据流动。
例子

该图还可以让我们观察TCP是如何对应用进程写的数据进行重新分组化的,体现了TCP传送的是字节流。当进入紧急方式时待输出的1个字节是与在缓存中的后面1023个字节一同发送的。下一个报文段也包含1024字节的数据,而最后一个报文段则只包含一个字节
8.TCP的超时和重传
TCP提供可靠的运输层。它使用的方法之一就是确认从另一端收到的数据。但数据和确认都有可能会丢失。TCP通过在发送端发送数据时时设置一个定时器来解决这种问题。如果当定时器溢出时还没有收到接收方确认,发送端就重传该数据。对任何实现而言,关键之处就在于超时和重传的策略,即怎样决定超时间隔和重传的间隔。
4个定时器
对每个连接,TCP管理4个不同的定时器
1)重传定时器用于当发送一个数据报文时,在规定时间内,发送方需要收到另一端发出的接收报文确认。在本章我们将详细讨论这个定时器以及一些相关的问题,如拥塞避免。
2)坚持(persis))定时器使窗口大小信息保持不断流动,即使另一端关闭了其接收窗口。
3)保活(keepalive)定时器用于检测一个空闲连接的另一端是否依然还保持连接。
4)2MSL定时器测量一个连接处于TIMEWAIT状态的时间。
例子


检查连续重传之间不同的时间差,它们取整后分别为1、3、6、12、24、48和多个64秒
当第一次发送后所设置的超时时间实际上为1.5秒
指数退避(exponential backoff)
首次分组传输(第6行,24.480秒)与复位信号传输(第19行566.488秒)之间的时间差约为9分钟。
Solaris2.2允许管理者改变这个时间(E.4节中的tcp_ip ortin erval变量),且其默认值为2分钟,而不是常用的9分钟。
往返时间测量
意义:TCP超时与重传中最重要的部分就是对一个TCP连接的往返时间(RTT)的测量由于网络状况的多变性,RTT时间经常会发生变化,TCP应该跟踪这些变化并相应地改变超时重传时间。
RFC793计算方法
TCP使用低通过滤器来更新一个被平滑的RTT值(记为0)。 R←&R+(1-&)M(M当前测出的RTT)
&是一个推荐值为0.9的平滑因子。每次进行新测量的时候,这个被平滑的RTT将得到更新。每个新估计的90%来自前一个估计,而10%则取自新的测量。
该算法在给定这个随RTT的变化而变化的平滑因子的条件下,RFC793推荐的重传超时时间RTO(RetransmissionTimeOut)的值应该设置为 RTO=R@
这里的**@是一个推荐值为2的时延离散因子**。
RFC793测量方法的缺陷
在RTT变化范围很大时,使用这个方法无法跟上这种变化,从而引起不必要的重传。正如Jacobson记述的那样,当网络已经处于饱和状态时,不必要的重传会增加网络的负载,对网络而言这就像在火上浇油一样。
新的测量方法
除了被平滑的RTT,还需要跟踪RTT的方差,这样,在往返时间变化起伏很大的情况下,基于均值和方差来计算RTO,比只用均值的常数倍数来计算RTO提供更好的对网络传送数据状况的表示方法

M为当前测出的RTT,A为之前的RTT
A是被平滑的RTT(均值的估计器)而D则是被平滑的均值偏差。Err是刚得到的测量结果与当前的RTT估计器之差。A和D均被用于计算下一个重传时间(RTO)。增量g起平均作用,取为1/8(0.125)。偏差的增益是h,取值为0.25。当RTT变化时,较大的偏差增益将使RTO快速上升
Jacobson阐述了一种使用整数运算来计算这些公式的方法,并被许多实现所采用(这也就是g,h和倍数4均是2的乘方的一个原因,这样一来,计算只需要通过移位操作而不需要乘、除运算来完成)。
两种测量方法比较
Jacobson计算RTO的公式依赖于被平滑的RTT和被平滑的均值偏差,而 RFC793方法则使用了被平滑的RTT的一个倍数。
重传多义性问题
在一个分组重传时会产生这样一个问题:假定一个分组被发送。当超时发生时,RTO正进行指数退避,分组以更长的RTO进行重传,然后收到一个确认。那么这个ACK是针对第一个分组的还是针对第二个分组呢?
Karn算法
当一个超时和重传发生时,在重传数据的确认最后到达之前,不能更新RTT估计器
大多数源于伯克利的TCP实现在任何时候对每个连接仅测量一次RTT值。在发送一个报文段时,如果给定连接的定时器已经被使用,则该报文段不被计时。
对每个连接而言,除了这个滴答计数器,报文段中数据的起始序号也被记录下来。当收到一个包含这个序号的确认后,该定时器就被关闭。如果ACK到达时数据没有被重传(定时器没有超时),则被平滑的RTT和被平滑的均值偏差将基于这个新的测量值进行更新。
RTT估计器的计算
RTT估计器(平滑的RTT和平滑的均值偏差)
变量A和D被初始化为0和3秒
1.初始的重传超时
RTO=A+2D=0+2x3=6s

当超时在6秒后发生时,计算当前的RTO值为 RTO=A+4D=0+4x3=12s
2.测量到第一个RTT后重传超时时间的计算
当第1个数据报文段的ACK(如上图)到达时,经历了3个时钟滴答,A和D被初始化为 :
A=M+0.5=1.5+0.5=2
D=A/2=1
(3个时钟滴答,M取值为1.5)。
使用第1个RTT的测量结果M对估计器进行首次计算的初始值。计算的RTO值为
RTO=A+4D=2+4x1=6s
3.当第2个数据报文段的ACK到达时,经历了1个时钟滴答(0.5秒),估计器按如下更新:
Err=M-A=0.5-2=-1.5
A=A+gErr=2-0.125x1.5=1.8125
D=D+h(|Err|-D)=1+0.25x(1.5-1)=1.125
RTO=A+4D=1.8125+4x1.125=6.3125
采用上面公式计算的E1A和D的信与实际使用的定点计算方法得到结果有一些微小的差别。后一种方法得到的RTO值为6秒(而非63125秒)
拥塞避免算法
有两种分组丢失的指示:超时和接收到重复的确认。
重复确认(收到新的数据,但新的数据的起始序列号都不是接收方需要的,所以不断重传ACK,收到3个重复的ACK就默认为丢包)
——使用超时作为丢包指示,需要一个好的RTT算法
-
拥塞避免算法是一种处理丢失分组的方法
-
该算法假定由于分组受到损坏引起的丢失是非常少的(远小于1%),因此分组丢失就意味着在源主机和目的主机之间的某处网络上发生了拥塞。
拥塞避免算法和慢启动算法是两个目的不同、独立的算法。当拥塞发生时,我们希望降低分组进入网络的传输速率,于是可以调用慢启动来实现这一点。在实际中这两个算法通常在一起实现。
拥塞避免和慢启动都是发送方使用的流量控制(慢启动允许一方发送连续的未经确认的分组的增加方式采用指数增加,拥塞避免允许一方发送连续的未经确认的分组的增加方式采用线性增加),而通告窗口则是接收方进行的流量控制。拥塞避免是发送方对网络可能发生拥塞的估计,而后者则与接收方分配给该连接的接收缓存大小有关。
拥塞避免算法和慢启动算法需要对每个连接维持两个变量:一个拥塞窗口cwnd和一个慢启动门限ssthresh。算法的工作过程如下:
1)对一个给定的连接,初始化cwnd为1个报文段,ssthresh为65535个字节
2)TCP发出未经确认的报文总大小不能超过cwnd和接收方通告窗口的大小。
3)当拥塞发生时(超时或收到重复确认)ssthresh被设置为当前窗口大小的一半(cwnd和接收方通告窗口大小的最小值,但最少为2个报文段)。此外,如果是超时引起了拥塞,则cwnd被设置为1个报文段(这就是慢启动)。
4)当新的数据被对方确认时,就增加cwnd,但增加的方法依赖于我们是否正在进行慢启动或拥塞避免。如果cwnd小于或等于ssthresh,则正在进行慢启动,否则正在进行拥塞避免。慢启动一直持续到我们回到当拥塞发生时所处位置一半时才停止(因为我们记录了在步骤3中给我们制造麻烦的窗口大小的一半,就是ssthresh),接下来执行的是拥塞避免。
慢启动算法初始设置cwnd为1个报文段,此后每收到一个确认就加1这会使窗口按指数方式增长:发送1个报文段,然后是2个,接着是4个
拥塞避免算法要求每次收到一个确认时将cwnd增加1/cwnd。与慢启动的指数增加比起来,这是一种加性增长(additiveincrease)。我们希望在一个往返时间内最多为cwnd增加1个报文段(不管在这个RTT中收到了多少个ACK),然而慢启动将根据这个往返时间中所收到的确认的个数增加cwnd。
快速重传算法:如果一连串收到3个或3个以上的重复ACK,就非常可能是一个报文段丢失了。于是我们就重传丢失的数据报文段,而无需等待超时定时器溢出。
快速恢复算法:快速重传后执行的不是慢启动算法而是拥塞避免算法。
没有执行慢启动的原因是:
收到重复的ACK不仅仅告诉我们一个分组丢失了,还告诉我们一个数据包离开网络顺利的到达接收者。这是由于接收方只有在收到另一个报文段并发现这个报文不是我当前需要序号的报文才会产生重复的ACK,说明有一个报文段已经离开了网络并进入了接收方的缓存。也就是说,在收发两端之间仍然有流动的数据,而我们不想执行慢启动来突然减少数据流。
快速恢复算法
1)当收到第3个重复的ACK时,将ssthresh设置为当前拥塞窗口cwnd的一半。重传丢失的报文段。设置cwnd为ssthresh加上3倍的报文段大小
ssthresh本应立即设置为当重传发生时正在起作用的窗口大小的一半,但是在接收到重复ACK的过程中cwnd允许保持增加,这是因为每个重复的ACK表示1个报文段已离开了网络,收到3个重复的ACK,表示有3个报文离开了网络,并被接收TCP缓存了这几个报文段,正在等待所缺数据的到达)。
2)每次收到另一个重复的ACK时,cwnd增加1个报文段大小并发送1个分组。
3)当下一个确认新数据的ACK到达时,设置cwnd为ssthresh(在第1步中设置的值)。这个ACK应该是在进行重传后的一个往返时间内对步骤1中重传的确认。另外,这个ACK也应该是对丢失的分组和收到的第1个重复的ACK之间的所有中间报文段的确认。这一步采用的是拥塞避免,因为当分组丢失时我们将当前的速率减半。
按每条路由进行度量
新的TCP实现在路由表项中维持许多我们在前面已经介绍过的指标。当一个TCP连接关闭时,如果已经发送了足够多的数据来获得有意义统计资料,且目的结点的路由表项不是一个默认的表项,那么下列信息就保存在路由表项中以备下次使用:被平滑的RTT、被平滑的均值偏差以及慢启动门限。所谓“足够多的数据”是指16个窗口的数据,这样就可得到16个RTT采样。
当建立一个新的连接时,不论是主动还是被动,如果该连接将要使用的路由表项已经有这些度量的值,则用这些度量来对相应的变量进行初始化。
ICMP的差错
让我们来看一下TCP是怎样处理一个给定的连接返回的ICMP的差错。TCP能够遇到的最常见的ICMP差错就是源站抑制、主机不可达和网络不可达。当前基于伯克利的实现对这些错误的处理是:
- 接收到的源站抑制ICMP差错报文:拥塞窗口cwnd被置为1个报文段大小,开始慢启动,但是慢启动门限ssthresh没有变化,所以发送窗口将打开直至它或者充分利用收发双方的链路(受窗口大小和往返时间的限制)或者发生了拥塞。
- 接收到的主机不可达或网络不可达的ICMP错误都被忽略,因为这两个差错都被认为是短暂现象。这有可能是由于网络发生故障而收敛,需要一定的时间选择替换路径。在收效过程中可能引起发送这两种ICMP差错中的一种,但是TCP连接并不必被关闭。相反,TCP试图发送引起该差错的数据,尽管最终有可能会超时。
TCP的重新分组
当TCP超时并重传时,它不一定要重传同样的报文段。相反,TCP允许进行重新分组而发送一个较大的报文段,这将有助于提高性能 (当然,这个较大的报文段不能够超过接收方声明的MSS)。在协议中这是允许的,因为TCP是使用字节序号而不是报文段序号来进行识别它所要发送的数据和进行确认。
9.TCP的坚持定时器
ACK的传输并不可靠,也就是说,TCP不对ACK报文段进行确认,TCP只确认那些包含有数据的ACK报文段。如果报文段9丢失怎么办”?
问题:
如果一个通告窗口更新的确认丢失了,则双方就有可能一直等待下去:接收方等待接收数据(因为它已经向发送方通告了一个非0的窗口),而发送方在等待允许它继续发送数据的窗口更新。
解决方法:
为防止这种死锁情况的发生,发送方使用一个坚持定时器(persist timer)来周期性地向接收方查询,以便发现窗口是否已增大。这些从发送方发出的报文段称为窗口探查(windowprobe)。
坚持定时器特点
计算坚持定时器时使用了普通的TCP指数退避。
在收到一个大小为0的窗口通告后的第1个(报文段14)间隔为4.949秒,下一个(报文段16)间隔是4.996秒,随后的间隔分别约为61224,48和多个60秒。
窗口探查包含一个字节的数据(序号为9217)。TCP总是允许在关闭连接前发送一个字节的数据。请注意,尽管如此,所返回的窗口为0的A CK并不是确认该字节(它们确认了包括9216在内的所有数据),因此这个字节被持续重传。被持续用来探测对端窗口的变化情况。
糊涂窗口综合征
基于窗口的流量控制方案,如TCP所使用的,会导致一种被称为“糊涂窗口综合症SWS(SillyWindow Svndrome)”的状况。如果发生这种情况,则少量的数据将通过连接进行交换,而不是满长度的报文段。导致传输效率低下
现象:
该现象可发生在两端中的任何一端:接收方可以通告一个小的窗口(而不是一直等到有大的窗口时才通告),而发送方也可以发送少量的数据(而不是等待其他的数据以便发送一个大的报文段)
解决
可以在任何一端采取措施避免出现糊涂窗口综合症的现象。
1)接收方不通告小窗口。通常的算法是接收方不通告这样的窗口,窗口小于一个报文段(也就是将要接收的MSS),或者窗口小于接收方缓存空间的一半,不论实际有多少。
2)发送方避免出现糊涂窗口综合症的措施是只有以下条件之一满足时才发送数据:(a)可以发送一个满长度的报文段;(b)可以发送至少是接收方通告最大窗口大小一半的报文段;©没有还未被确认的数据或者该TCP连接上禁止使用Nagle算法。
在有尚未被确认数据的情况下,Nagle算法阻止我们发送小的报文段:禁止nagle算法后,即便有未确认数据包,也可以发送数据包
10.TCP的保活定时器
如果TCP连接的双方都没有向对方发送数据,则在两个TCP模块之间不交换任何信息。
这意味着我们可以启动一个客户与服务器建立一个连接,然后离去数小时、数天、数个星期或者数月,而连接依然保持。
许多时候一个服务器希望知道客户主机是否关机或者崩溃又重新启动。许多实现提供的保活定时器可以提供这种能力。但是保活定时器并不是TCF规范中的一部分。
Host Requirements RFC提供了3个不使用保活定时器的理由:
1)在出现短暂差错的情况下,这可能会使一个非常好的连接释放掉;
2)它们耗费不必要的带宽;
(3) 在按分组计费的情况下会在互联网上花掉更多的钱。并且,许多实现提供了保活定时器。
保活定时器是一个有争论的功能。许多人认为如果需要,这个功能不应该在TCP中提供,而应该由应用程序来完成。这是应当认真对待的一些问题之一
保活探测的工作细节
如果一个给定的连接在两个小时之内没有任何动作,则服务器就向客户发送一个探查报文段。客户主机必须处于以下4个状态之一。
1)客户主机依然正常运行,并从服务器可达。客户的TCP响应正常,而服务器也知道对方是正常工作的。服务器在两小时以后将保活定时器复位。如果在两个小时定时器到时间之前有应用程序的通信量通过此连接,则定时器在交换数据后的未来2小时再复位。
2)客户主机已经崩溃,并且关闭或者正在重新启动。在任何一种情况下,客户的 TCP都没有响应。服务器将不能够收到对探查的响应,并在75秒后超时。服务器总共发送10个这样的探查,每个间隔75秒。如果服务器没有收到一个响应,它就认为客户主机已经关闭并终止连接。
3)客户主机崩溃并已经重新启动。这时服务器将收到一个对其保活探查的响应,但是这个响应是一个复位,使得服务器终止这个连接。
4)客户主机正常运行,但是从服务器不可达。这与状态2相同,因为TCP不能够区分状态4与状态2之间的区别,它所能发现的就是没有收到探查的响应。
11.TCP的未来和性能
路劲MTU的发现
TCP的路径MTU发现按如下方式进行:在连接建立时,TCP使用输出接口 MTU或对端声明的MSS中的最小值作为起始的报文段大小。路径MTU发现不允许TCP超过对端声明的MSS。如果对端没有指定一个MSS,则默认为536.
一但选定了起始的报文段大小,在该连接上的所有被TCP发送的IP数据报都将被设置DF比特。如果某个中间路由器需要对一个设置了DF标志的数据报进行分片,它就丢弃这个数据报,并产生一个ICMP的"不能分片”差错。如果收到这个ICMP差错,TCP就减少段大小并进行重传。如果路由器产生的是一个较新的该类CMP差错,则报文携带为下一跳的MTU值。如果是一个较旧的该类ICMP差错,则必须尝试下一个可能的最小MTU。当由这个ICMP差错引起的重传发生时,拥塞窗口不需要变化*,但要启动慢启动
大分组还是小分组
常规知识告诉我们较大的分组比较好[Mogul199315.28节],因为发送较少的大分组比发送较多的小分组“花费”要少(假定分组的大小不足以引起分片,否则会引起其他方面的问题)。这些减少的花费与网络(分组首部负荷)、路由器(选路的决定)和主机(协议处理和设备中断)等有关。但并非所有的人都同意这种观点[Bellovin1993]。
长肥管道
我们把一个连接的容量表示为
capacity(b)=bandwidth(b/s)xroundtriptime(s)
并称之为带宽时延乘积。也可称它为两端的管道大小。
当这个乘积变得越来越大时,TCP的某些局限性就会暴露出来。下图显示了多种类型的网络的某些数值。
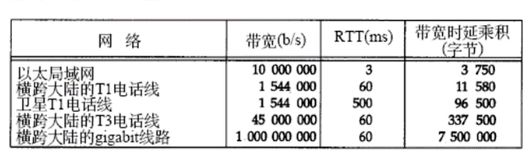
具有大的带宽时延乘积的网络被称为长肥网络(LongFatNetwork),而一个运行在LFN上的TCP连接被称为长肥管道。
长肥管道局限性
1)TCP首部中窗口大小为16bit,从而将窗口限制在65535个字节内。然而现有的网络需要一个更大的窗口来提供最大的吞吐量。后面将介绍窗口扩大选项可以解决这个问题。
2)在一个长肥网络LFN内的分组丢失会使吞吐量急剧减少。
3)我们在前面看到许多TCP实现对每个窗口的RTT仅进行一次测量。它们并不对每个报文段进行RTT测量。在一个长肥网络LFN上需要更好的RTT测量机制。我们将在后面介绍时间戳选项,它允许更多的报文段被计时,包括重传。
4)TCP对每个字节数据使用一个32bit无符号的序号来进行标识。如果在网络中有一个被延迟一段时间的报文段,它所在的连接已被释放,而一个新的连接在这两个主机之间又建立了,怎样才能防止这样的报文段再次出现呢?首先回想起IP首部中的TT L为每个IP段规定了一个生存时间的上限-255跳或255秒,看哪一个上限先达到。我们还定义了最大的报文段生存时间(MSL)作为一个实现的参数来阻止这种情况的发生。推荐的MSL的值为2分钟(给出一个240秒的2MSL),然而许多实现使用的MSL为30秒。
TCP序号回绕问题
在长肥网络LFN上,TCP的序号会碰到一个不同的问题。由于序号空间是有限的在已经传输了4294967296个字节以后序号会被重用。如果一个包含序号N字节数据的报文段在网络上被迟延并在连接仍然有效时又出现,会发生什么情况呢?
在一个以太网上要发送如此多的数据通常需要60分钟左右,因此不会发生这种情况。但是在带宽增加时,这个时间将会减少:一个T3的电话线(45Mb/s)在12分钟内会发生回绕,FDDI(100Mb/s)为5分钟,而一个千兆比网络(1000Mb/s)则为34秒。这时问题不再是带宽时延乘积,而在于带宽本身。
一种对付这种情况的办法:使用TCP的时间戳选项的PAWS
(Protection Against Wrapped Sequence numbers)算法(保护回绕的序号)
窗口扩大选项
假定我们正在使用窗口扩大选项,发送移位记数为s,而接收移位记数则为R。于是我们从另一端收到的每一个16bit的通告窗口将被左移R位以获得实际的通告窗口大小。每次当我们向对方发送一个窗口通告的时候,我们将实际的32bit窗口大小右移s比特,然后用它来替换TCP首部中的16bit的值。
TCP根据接收缓存的大小自动选择移位计数。这个大小是由系统设置的,但是通常向应用进程提供了修改途径
时间戳选项
时间戳选项使发送方在每个报文段中放置一个时间戳值。接收方在确认中返回这个数值,从而允许发送方为每一个收到的ACK计算RTT。我们提到过目前许多实现为每一个窗口只计算一个RTT,对于包含8个报文段的窗口而言这是正确的。然而,较大的窗口大小则需要进行更好的RTT计算。
发送方在第1个字段中放置一个32bit的值,接收方在应答字段中回显这个数值包含这个选项的TCP首部长度将从正常的20字节增加为32字节,时间戳是一个单调递增的值。由于接收方只需要回显收到的内容,因此不需要关注时间戳单元是什么。这个选项不需要在两个主机之间进行任何形式的时钟同步。
工作细节
为了减少任一端所维持的状态数量,对于每个连接只保持一个时间戳的数值。选择何时更新这个数值的算法非常简单:
1)TCP跟踪下一个ACK中将要发送的时间戳的值(一个名为tsrecen的变量以及最后发送的ACK中的确认序号(一个名为lastack的变量)。这个序号就是接收方期望的序号。
2)当一个包含有字节号lastack的报文段到达时,则该报文段中的时间戳被保存在tsrecent中。
3)无论何时发送一个时间戳选项,tsrecent就作为时间戳回显应答字段被发送,而序号字段被保存在lastack中。
PAWS:防止回绕的序号
考虑一个使用窗口扩大选项的TCP连接,其最大可能的窗口大小为1干兆字节下图显示了在传输6千兆字节的数据时,在两个主机之间可能的数据流。
假定一个报文段在时间B丢失并被重传。还假定这个丢失的报文段在时间E重新出现。这个时候回绕序号出现
使用时间戳可以避免这种情况。接收方将时间戳视为序列号的一个32bit的扩展。由于在时间E重新出现的报文段的时间戳为2,这比最近有效的时间戳小(5或6),因此PAWS算法将其丢弃。
PAWS算法不需要在发送方和接收方之间进行任何形式的时间同步。接收方所需要的就是时间戳的值应该单调递增,并且每个窗口至少增加1。
T/TCP:为事务用的TCP扩展
TCP提供的是一种虚电路方式的运输服务。一个连接的生存时间包括三个不同的阶段:建立、数据传输和终止。这种虚电路服务非常适合诸如远程注册和文件传输之类的应用。
一个事务(transaction)就是符合下面这些特征的一个客户请求及其随后的服务器响应。
1)应该避免连接建立和连接终止的开销,在可能的时候,发送一个请求分组并接收一个应答分组。
2)等待时间应当减少到等于RTT与SPT之和。其中RTT(Round-Trip Time)为往返时间,而SPT(ServerProcessingTime)则是服务器处理请求的时间。
3)服务器应当能够检测出重复的请求,并且当收到一个重复的请求时不重新处理事务(避免重新处理意味着服务器不必再次处理请求,而是返回保存的与该请求对应的应答)
TCP and UDP
TCP提供了过多的事务特征,而UDP提供的则不够。通常应用程序使用UDP来构造(避免TCP连接的开销),而许多需要的特征(如动态超时和重传、拥塞避免等)被放置在应用层,一遍又一遍的重新设计和实现。
一个较好的解决方法是提供一个能够提供足够多的事务处理功能的运输层。我们称这样的事务协议为T/TCP。
T/TCP
TCP为处理事务而需要进行的两个改动是避免三次握手和缩短WAITTIME状态 。T/TCP通过使用加速打开来避免三次握手:
1)它为打开的连接指定一个32bit的连接计数CC(ConnectionCount),无论主动打开还是被动打开。一个主机的CC值从一个全局计数器中获得,该计数器每次被使用时加1
2)在两个使用T/TCP的主机之间的每一个报文段都包括一个新的TCP选项CC。
3)一个服务器维持一个缓存,该缓存保留每个主机上一次的CC值,这些值从来自这个主机的一个可接受的SYN报文段中获得。
4)当在一个开始的SYN中收到一个CC选项的时候,接收方比较收到的值与为该发送方缓存的CC值。如果接收到的CC比缓存的大,则该SYN是新的,报文没中的任何数据被传递给接收应用进程(服务器)。这个连接被称为半同步。如果接收的CC比缓存的小,或者接收主机上没有对应这个客户的缓存CC,则执行正常的TCP三次握手过程。
5)为响应一个开始的SYN,带有SYN和ACK的报文段在另一个被称为CCECHO的选项中回显所接收到的CC值。
通过使用这些特征,最小的事务序列是交换三个报文段:
1)由一个主动打开引起的客户到服务器:客户的SYN、客户的数据(请求)、客户的 FIN以及客户的CC。当被动的服务器TCP接收到这个报文段的时候,如果客户的CC比为这个客户缓存的CC要大,则客户的数据被传送给服务器应用程序进行处理。小或没有建立新的TCP链接
2)服务器到客户:服务器的SYN、服务器的数据(应答)、服务器的FIN、对客户的 FIN的ACK、服务器的CC以及客户的CC的CCECHO。由于TCP的确认是累积的这个对客户的FIN的ACK也对客户的SYN、数据及FIN进行了确认。当客户TCP接收到这个报文段,就将其传送给客户应用进程。
3)客户到服务器:对服务器的FIN的ACK,它也确认了服务器的SYN、数据和FIN。
T/TCP的特征中吸引人的地方在于它对现有协议进行了最小的修改,同时又兼容了现有的实现。它还利用了TCP中现有的工程特征(动态超时和重传、拥塞避免等),而不是迫使应用进程来处理这些问题
TCP的性能——非常高效
TCP吞吐率测试情况:
在FDDI(100Mb/s)网络上Schryver1993指出三个商业厂家已经演示了在FDDI上的TCP在80Mb/s~90Mb/s之间。[Borman19921]报告说两个Gray Y-MP计算机在一个800Mb/s的HIPPI通道上最大值为781Mb/s,而运行在一个GrayY-MP上的使用环回接口的两个进程间的速率为907Mb/s。
TCP吞吐率限制:
1)不能比最慢的链路运行得更快。
2)不能比最慢的机器的内存运行得更快
3)不能够比由接收方提供的窗口大小除以往返时间所得结果运行得更快(这就是带宽时延来积公式,使用窗口大小作为带宽时延来积,就得到带宽值)
TCP的最高运行速率的真正上限是由TCP的窗口大小和光速决定的。
十二、FTP
简介
-
数据传输主流协议
-
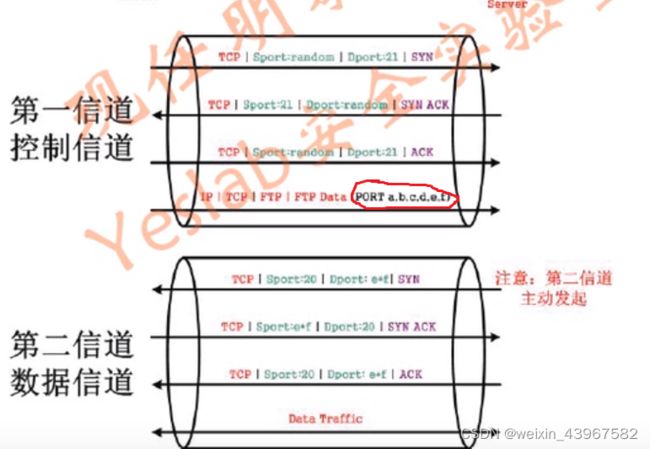
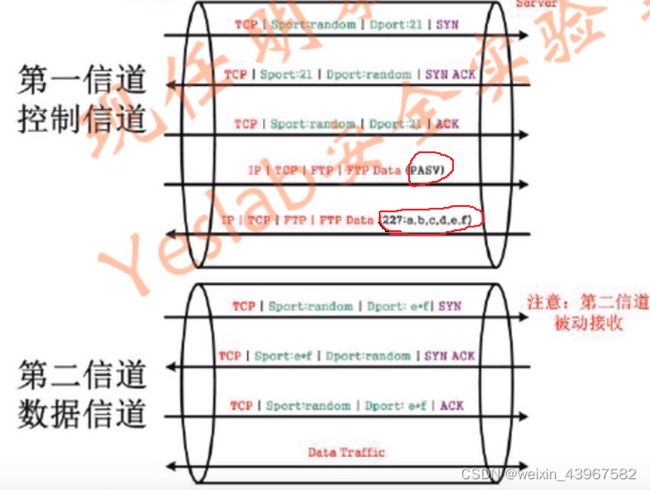
两个信道
- 控制信道(21端口)
- 数据信道 (主动模式20端口或被动模式port计算)
-
FTP两个模式
- -Active Mode
- -Passive Modeeslab
主动模式
第二信道是服务器发起的:主动模式
第二信道是客户端发起的:被动模式
PORT a,b,c,d,e,f a,b,c,d为客户端ip,e * 256 + f 为建立数据信道的客户端端口
被动模式
更安全,端口号都随机。一般使用被动模式
十三、Telnet(23端口)
简介
Telnet协议是TCP/IP协议族中的一员,是Internet远程登陆服务的标准协议和主要方式。它为用户提供了在本地计算机上完成远程主机工作的能力。在终端使用者的电脑上使用telnet程序,用它连接到服务器。终端使用者可以在telnet程序中输入命令,这些命令会在服务器上运行,就像直接在服务器的控制台上输入一样。可以在本地就能控制服务器。要开始一个telnet会话,必须输入用户名和密码来登录服务器。Telnet是常用的远程控制路由器的方法。
1交互式TCP数据流的特点(键入数据不是直接由键盘打印上去的,直接由键盘输入到网络,然后对面回写过来的)
2.安全问题(替代协议SSH)(明文不安全)
任何一条命令不是在一个包里出现的,而是在一个流里很多包里出现的
十四、HTTP
简介
HTTP协议(Hypertext Transfer Protocol,超文本传输协议)是用于从 WWW服务器传输超文本到本地浏览器的传送协议,是一个客户端和服务器端请求和应答的标准(TCP)。超文本传输协议是互联网上应用最为广泛的一种网络协议所有的WWW文件都必须遵守这个标准。
HTTP协议特点

主要特点:哑服务器
HTTP术语介绍

Cookie问题
HTTP为瞬时协议,不是长期存在的,获取了就没有了,是无状态。使用Cookie记录状态,使得连接看起来像是一直存在没有端口。(用于记录登录)
多连接问题
你请求一个网页,网页上有很多数据也需要请求,会产生很多瞬时连接
HTTP RFC标准命令

get获取响应头+响应体(数据部分)
head获取头部信息
十五、SMTP/POP3
SMTP简介
SMTP是一种提供可靠且有效的电子邮件传输的协议。SMTP是建立在FTP文件传输服务上的一种邮件服务,主要用于系统之间的邮件信息传递,并提供有关来信的通知。SMTP独立于特定的传输子系统,且只需要可靠有序的数据流信道支持,SMTP的重要特性之一是其能跨越网络传输邮件,即“SMTP邮件中继”。使用SMTP,可实现相同网络处理进程之间的邮件传输,也可通过中继器或网关实现某处理进程与其他网络之间的邮件传输
传输协议 TCP/25
SMTP协议的邮件路由过程
SMTP服务器基于域名服务DNS中计划收件人的域名来路由电子邮件。SMTP服务器基于DNS中的MX记录来路由电子邮件,MX记录注册了域名和相关的SMTP中继主机,属于该域的电子邮件都应向该主机发送。若SMTP服务器mail.abc.com收到一封信要发到[email protected],则执行以下过程:
(1)Sendmail请求DNS给出主机sh.abc.com的CNAME记录,如有,假若CNAME(别名记录)到shmail.abc.com,则再次请求 shmail.abc.com的CNAME记录,直到没有为止。
(2)假定被CNAME到shmail.abc.com,然后sendmail请求@abc.com域的DNS给出shmail.abc.com的MX记录(邮件路由及记录), shmail MX 5 shmail.abc.com 10 shmail2.abc.com。
(3)Sendmail组合请求DNS给出shmail.abc.com的A记录(主机名(或域名)对应的IP地址记录),即IP地址,若返回值为1.2.3.4(假设值)。
(4)Sendmail与1234连接,传送这封给[email protected]的信到1234这台服务器的SMTP后台程序。
SMTP协议工作原理
SMTP是工作在两种情况下:一是电子邮件从客户机传输到服务器:二是从某一个服务器传输到另一个服务器。SMTP也是个请求响应协议,命令和响应都是基于ASCII文本,并以CR和LF符结束响应包括一个表示返回状态的三位数字代码。SMTP在TCP协议25号端口监听连续请求连接和发送过程如下
(1)建立TCP连接。
(2)客户端发送**EHLO 电子邮件服务器(如smtp.163.com)命令以标识发件人自己的身份**,(AUTH LOGIN登录)然后客户端发送MAIL FROM:<发件人邮箱>命令;服务器端正希望以OK作为响应,表明准备接收。
(3)客户端发送**RCPT FROM:<收件人邮箱>命令**,以标识该电子邮件的计划接收人,可以有多个RCPT行;服务器端则表示是否愿意为收件人接收邮件。
(4)协商结束,发送邮件,用命令DATA发送。
(5)以**“.”号表示结束输入内容一起发送出去**,结束此次发送,用QUIT命令退出。
SMTP inspection介绍

例子


POP3简介
POP3,全名为“PostOffice Protocol-Version 3”,即“邮局协议版本3”。是TCP/IP协议族中的一员,由RFC1939定义。本协议主要用于支持使用客户端远程管理在服务器上的电子邮件。提供了SSL加密的POP3协议被称为 POP3S。
POP协议支持“离线”邮件处理。其具体过程是:邮件发送到服务器上,电子邮件客户端调用邮件客户机程序以连接服务器,并下载所有未阅读的电子邮件。这种离线访问模式是一种存储转发服务,将邮件从邮件服务器端送到个人终端机器上,一般是PC机或MAC。一旦邮件发送到 PC机或MAC上,邮件服务器上的邮件将会被删除。但目前的POP3邮件服务器大都可以“只下载邮件,服务器端并不删除”,也就是改进的POP3协议。
传输协议:TCP/110
收件过程
USER 用户名
PASS 密码
STAT(查看服务器状态)
LIST(罗列邮件)
RETR 序号(收ID为所选序号的邮件)
DELETE 序号(删除ID为所选序号的邮件)
QUIT (退出)
十六、SSL
SSL和TLS
安全套接层俗称Secure Socket Layer(SSL)是由Netscape Communication于1990年开发用于保障Word WideWeb(www)通讯的安全。主要任务是提供私密性,信息完整性和身份认证。1994年改版为S5801995年改版为SSLv3.(私有标准)
Transport Layer Security(TLS)标准协议由 IETF于1999年颁布,整体来说TLS非常类似与 SSLv3,只是对SSLv3做了些增加和修改。(公有标准)
SSL协议介绍
SSL是一个不依赖于平台和运用程序的协议用于保障TCP-based运用安全,SSL在TCP层和应用层之间,就像应用层连接到TCP连接的一个插口。

SSL加密知名协议
-
HTTPoverSSL:加密网页流量是设计SSL的初衷,HTTP也是第一个使用SSL保障安全的运用层协议。
当Netscape在它的Navigator里边运用HTTP over SSL的时候,它使用https://来标识HTTP over SSL,因此HTTP over SSL就以HTTPS的格式被我们熟知。后来HTTPS在RFC2818被标准化。HTTPS工作在TCP443号端口,但是普通的HTTP默认工作在TCP80端口 -
EmailoverSSL:类似于HTTPoverSSL,邮件协议例
如:SMTP,POP3和IMAP也能够支持SSL
SMTP over TLS的标准化文档在RFC2487
POP3和IMAP over TLS的标准化文档在RFC2595
SSL Handshake示意图
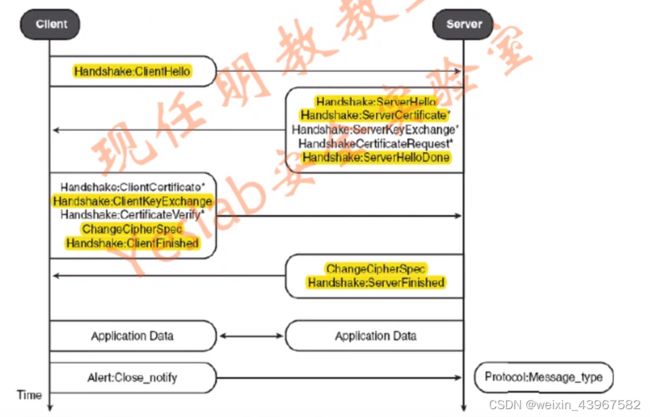
Client:ClientHello:包含浏览器支持的算法
Server:ServerHello:选择了什么算法,ServerCertificate:数字证书
Client:ClientKeyExchange:密钥交换,ChangeCipherSpec :接下来的内容使用密钥加密
Server:ChangeCipherSpec :接下来的内容使用密钥加密
数据交换
结束
十七、SNMP
SNMP简单网络管理协议
简单网络管理协议(SNMP)在网络管理系统中用于监视网络连接设备是否存在需要管理注意的情况。
三大组件:SNMP manager 、SNMP agent(UDP 端口号161)、Managerment Information Base(MIB)
三大操作
GET:用于从受管设备检索信息。
SET:用于设置受管设备中的变量或触发受管设备上的操作
Trap:是从受管设备发送到SNMP管理器的未经请求的消息。它可用于通知SNMP管理器受管设备上发生的重大事件(manager UDP:端口号162)
GET、SET是manager主动要求的,Trap是agent主动推送的
安全问题
版本3安全,既会加密也会做完整性校验,版本1.2不安全(community)
Community的安全问题
您可以将community string想象成密码。另外,请注意,目前市场上的多个符合SNMP的设备都具有默认的只读的community string“public”和默认的读写的community string“private”。纯明文发送
十八、语音协议分析
三种协议

语音整个过程协议介绍
-
CDP:获得VLAN信息(Voice VLAN),如果有 Cisco inline power(获取相应的功率)。
-
DHCP:(通过Voice VLAN),获得TFTP地址。
-
TFTP:获取配置文件。
-
SCCP/SIP:注册到Call Agent。
-
SCCP/SIP:信令建立过程。
-
RTP:两个电话间的语音流量(RTP)
信令建立过程
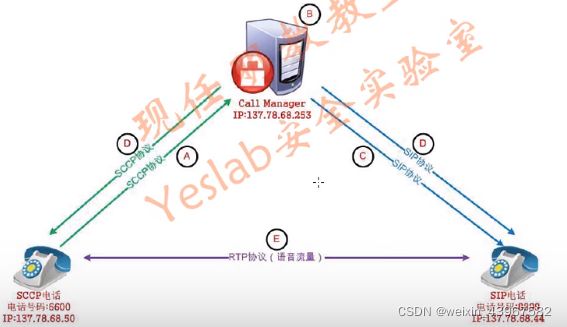
A、SCCP送号码到Call Agent
B、Call Manager呼叫路由查找(查询8899电话是否注册)
C、Call Manager尝试发起邀请,8899确认。
D、CallAgent向两台电话发送对方的地址,RTP端口号,编码等信息。
E、两个电话间直接交换RTP(语音)流量。
SCCP操作细节
1.off hook(SCCP电话到Call Manager)
2.播放提示音(Call Manager到SCCP电话)
3.免提(Call Manager到SCCP电话)
4.显示(Call Manager到SCCP电话)
5确认电话的呼叫状态(CallManager到SCCP电话)
6.ACK(SCCP电话到Call Manager)
7功能键的定义(Call Manager到SCCP电话)
8.ACK(SCCP电话到Call Manager)
9.发送号码“8”(SCCP电话到Call Manager)
10.停止拨号提示音(CallManager到SCCP电话)
11.功能键更新(CallManager到SCCP电话)
12.ACK(SCCP电话到Call Manager)
13.发送号码8”(SCCP电话到Call Manager)
14.ACK(Call Manager到SCCP电话)
15.发送号码“9”(SCCP电话到Call Manager)
16.ACK(CallManager到SCCP电话)
17.发送号码“9” (SCCP电话到CallManager)
18.ACK(CallManager到SCCP电话)
19.更新电话屏幕显示“8899”(Call Manager到 SCCP电话)
20.呼叫状态改变(CallManager到SCCP电话)