Yolo v5训练并移植到RK3588S平台
一、引言
RK3588S支持NPU,提供高达6.0Tops的算力,可以用于部署深度学习项目。本篇文章介绍Yolo v5代码开发、模型转化(RK3588S只支持rknn模型文件)、部署。
使用的RKNN-TooKit2,具体的环境搭建,请参考博文:RK3588(自带NPU)的环境搭建和体验(一)
本次使用Pytorch框架开发Yolo v5,在Window 10训练模型,在ubuntu下面转化模型。
二、Yolo v5
1、算法结构图
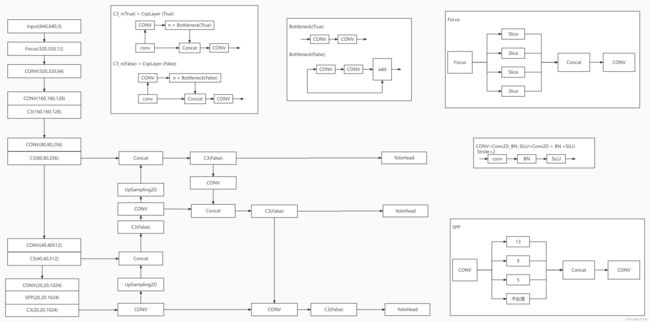 图1 Yolo V5结构图
图1 Yolo V5结构图
Yolo V5算法大致可以分为三个部分Backbone,FPN以及Yolo Head。Backbone是Yolo V5的主干网络,该层提取三个有效特征层,分别为C3(80,80,256)、C3(40,40,512)、C3(30,30,1024)。FPN是对有效层进行特征提取,进行特征融合,目的是结合不同尺度的特征信息。Yolo Head是Yolo V5的分类器和回归器,通过Backbone和FPN获得三个加强过的有效特征层,每个特征层都有宽、高、通道数。
1)Yolo V5使用了残差网络Residual,残差jua年纪可以分为两个部分,一个是1×1的卷积和一次3×3的卷积。残差边部分不做处理,直接与主干的输入、输出结合。
class Bottleneck(nn.Module):
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super(Bottleneck, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))残差网络,容易进行优化,可以通过增加深度提高准确率,内部的残差块使用了跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题。
2)使用CSPnet网络结构,主干部分继续进行原来的残差块的堆叠,另一部分则是经过少量处理直接连接到最后。
class C3(nn.Module):
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(C3, self).__init__()
c_ = int(c2 * e)
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
def forward(self, x):
return self.cv3(torch.cat(
self.m(self.cv1(x)),
self.cv2(x),
), 1)
3)Focus网络结构,具体则是在一个图像中,每隔一个像素拿到一个值,这个时候获得四个独立的特征层,然后将四个独立的特征层进行堆叠。此时,宽高信息集中到了通道信息,输入通道扩大了四倍,拼接起来的特征层相对于原先的三通道变成了十二个通道。如下图所示。

class Focus(nn.Module):
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Focus, self).__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
def forward(self, x):
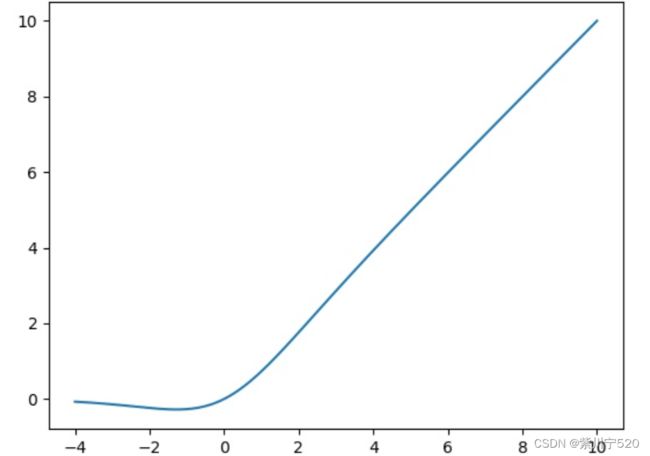
return self.conv(torch.cat((x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]), 1))4)使用SiLU激活函数,SiLU激活是由Sigmoid和ReLU的改进版本。SiLU具有无上界、有下界、平滑、非单调的特点,公式为:
F(x) = x × sigmoid(x)
5) 使用了SPP结构,通过不同池化核大小的最大池化进行特征提取,提高网络的感受野大小。
class SPP(nn.Module):
def __init__(self, c1, c2, k=(5, 9, 13)):
super(SPP, self).__init__()
c_ = c1 // 2
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))主干代码如下:
import torch
import torch.nn as nn
def autopad(k, p=None): # kernel, padding
# pad to 'same'
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
class Bottleneck(nn.Module):
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super(Bottleneck, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C3(nn.Module):
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(C3, self).__init__()
c_ = int(c2 * e)
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
def forward(self, x):
return self.cv3(torch.cat(
self.m(self.cv1(x)),
self.cv2(x),
), 1)
class SPP(nn.Module):
def __init__(self, c1, c2, k=(5, 9, 13)):
super(SPP, self).__init__()
c_ = c1 // 2
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
class Focus(nn.Module):
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Focus, self).__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
def forward(self, x):
return self.conv(torch.cat((x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]), 1))
class CSPDarknet(nn.Module):
def __init__(self, base_channels, base_depth):
super(CSPDarknet, self).__init__()
# 载入图片是[640,640,3],base_channels为64
self.stem = Focus(3, base_channels, k=3) # 640, 640, 3 -> 320, 320, 12 -> 320, 320, 64
self.dark2 = nn.Sequential(
Conv(base_channels, base_channels * 2, 3, 2), # 完成卷积之后,320, 320, 64 -> 160, 160, 128
C3(base_channels * 2, base_channels * 2, base_depth), # 完成C3之后,160, 160, 128 -> 160, 160, 128
)
self.dark3 = nn.Sequential(
Conv(base_channels * 2, base_channels * 4, 3, 2), # 完成卷积之后,160, 160, 128 -> 80, 80, 256
C3(base_channels * 4, base_channels * 4, base_depth * 3), # 完成C3之后,80, 80, 256 -> 80, 80, 256
# 在这里引出有效特征层80, 80, 256
# 进行加强特征提取网络FPN的构建
)
self.dark4 = nn.Sequential(
Conv(base_channels * 4, base_channels * 8, 3, 2), # 完成卷积之后,80, 80, 256 -> 40, 40, 512
C3(base_channels * 8, base_channels * 8, base_depth * 3), # 完成C3之后,40, 40, 512 -> 40, 40, 512
# 在这里引出有效特征层40, 40, 512
# 进行加强特征提取网络FPN的构建
)
self.dark5 = nn.Sequential(
Conv(base_channels * 8, base_channels * 16, 3, 2), # 完成卷积之后,40, 40, 512 -> 20, 20, 1024
SPP(base_channels * 16, base_channels * 16), # 完成SPP之后,20, 20, 1024 -> 20, 20, 1024
C3(base_channels * 16, base_channels * 16, base_depth, shortcut=False), # 完成C3之后,20, 20, 1024 -> 20, 20, 1024
)
def forward(self, x):
x = self.stem(x) # Focus
x = self.dark2(x)
x = self.dark3(x) # dark3的输出为80, 80, 256,是一个有效特征层
feat_1 = x
x = self.dark4(x) # dark4的输出为40, 40, 512,是一个有效特征层
feat_2 = x
x = self.dark5(x) # dark5的输出为20, 20, 1024,是一个有效特征层
feat_3 = x
return feat_1, feat_2, feat_36)在特征利用部分,YoloV5提取多特征层进行目标检测,一共提取三个特征层。
三个特征层位于主干部分CSPdarknet的不同位置,分别位于中间层,中下层,底层,当输入为(640,640,3)的时候,三个特征层的shape分别为feat1=(80,80,256)、feat2=(40,40,512)、feat3=(20,20,1024)。
在获得三个有效特征层后,我们利用这三个有效特征层进行FPN层的构建,构建方式为:
a) feat3=(20,20,1024)的特征层进行1次1X1卷积调整通道后获得P5,P5进行上采样UmSampling2d后与feat2=(40,40,512)特征层进行结合,然后使用CSPLayer进行特征提取获得P5_upsample,此时获得的特征层为(40,40,512)。
b) P5_upsample=(40,40,512)的特征层进行1次1X1卷积调整通道后获得P4,P4进行上采样UmSampling2d后与feat1=(80,80,256)特征层进行结合,然后使用CSPLayer进行特征提取P3_out,此时获得的特征层为(80,80,256)。
c) P3_out=(80,80,256)的特征层进行一次3x3卷积进行下采样,下采样后与P4堆叠,然后使用CSPLayer进行特征提取P4_out,此时获得的特征层为(40,40,512)。
d) P4_out=(40,40,512)的特征层进行一次3x3卷积进行下采样,下采样后与P5堆叠,然后使用CSPLayer进行特征提取P5_out,此时获得的特征层为(20,20,1024)。
特征金字塔可以将不同shape的特征层进行特征融合,有利于提取出更好的特征。
import torch
import torch.nn as nn
from utils.CSPDarknet import *
# 只使用's'模型,其他的暂时不考虑
class YoloNet(nn.Module):
def __init__(self, anchors_mask, num_classes, input_shape=[640, 640]):
super(YoloNet, self).__init__()
dep_mul, wid_mul = 0.33, 0.50
base_channels = int(wid_mul * 64) # 64
base_depth = max(round(dep_mul * 3), 1) # 3
self.backbone = CSPDarknet(base_channels, base_depth)
self.upsample = nn.Upsample(scale_factor=2, mode="nearest")
self.conv_for_feat3 = Conv(base_channels * 16, base_channels * 8, 1, 1)
self.conv3_for_upsample1 = C3(base_channels * 16, base_channels * 8, base_depth, shortcut=False)
self.conv_for_feat2 = Conv(base_channels * 8, base_channels * 4, 1, 1)
self.conv3_for_upsample2 = C3(base_channels * 8, base_channels * 4, base_depth, shortcut=False)
self.down_sample1 = Conv(base_channels * 4, base_channels * 4, 3, 2)
self.conv3_for_downsample1 = C3(base_channels * 8, base_channels * 8, base_depth, shortcut=False)
self.down_sample2 = Conv(base_channels * 8, base_channels * 8, 3, 2)
self.conv3_for_downsample2 = C3(base_channels * 16, base_channels * 16, base_depth, shortcut=False)
# 80, 80, 256 => 80, 80, 3 * (5 + num_classes) => 80, 80, 3 * (4 + 1 + num_classes)
self.yolo_head_P3 = nn.Conv2d(base_channels * 4, len(anchors_mask[2]) * (5 + num_classes), 1)
# 40, 40, 512 => 40, 40, 3 * (5 + num_classes) => 40, 40, 3 * (4 + 1 + num_classes)
self.yolo_head_P4 = nn.Conv2d(base_channels * 8, len(anchors_mask[1]) * (5 + num_classes), 1)
# 20, 20, 1024 => 20, 20, 3 * (5 + num_classes) => 20, 20, 3 * (4 + 1 + num_classes)
self.yolo_head_P5 = nn.Conv2d(base_channels * 16, len(anchors_mask[0]) * (5 + num_classes), 1)
def forward(self, x):
feat1, feat2, feat3 = self.backbone(x)
# 20, 20, 1024 -> 20, 20, 512
P5 = self.conv_for_feat3(feat3)
# 20, 20, 512 -> 40, 40, 512
P5_upsample = self.upsample(P5)
# 40, 40, 512 -> 40, 40, 1024
P4 = torch.cat([P5_upsample, feat2], 1)
# 40, 40, 1024 -> 40, 40, 512
P4 = self.conv3_for_upsample1(P4)
# 40, 40, 512 -> 40, 40, 256
P4 = self.conv_for_feat2(P4)
# 40, 40, 256 -> 80, 80, 256
P4_upsample = self.upsample(P4)
# 80, 80, 256 cat 80, 80, 256 -> 80, 80, 512
P3 = torch.cat([P4_upsample, feat1], 1)
# 80, 80, 512 -> 80, 80, 256
P3 = self.conv3_for_upsample2(P3)
# 80, 80, 256 -> 40, 40, 256
P3_downsample = self.down_sample1(P3)
# 40, 40, 256 cat 40, 40, 256 -> 40, 40, 512
P4 = torch.cat([P3_downsample, P4], 1)
# 40, 40, 512 -> 40, 40, 512
P4 = self.conv3_for_downsample1(P4)
# 40, 40, 512 -> 20, 20, 512
P4_downsample = self.down_sample2(P4)
# 20, 20, 512 cat 20, 20, 512 -> 20, 20, 1024
P5 = torch.cat([P4_downsample, P5], 1)
# 20, 20, 1024 -> 20, 20, 1024
P5 = self.conv3_for_downsample2(P5)
# ---------------------------------------------------#
# 第三个特征层
# y3=(batch_size,75,80,80)
# ---------------------------------------------------#
out2 = self.yolo_head_P3(P3)
# ---------------------------------------------------#
# 第二个特征层
# y2=(batch_size,75,40,40)
# ---------------------------------------------------#
out1 = self.yolo_head_P4(P4)
# ---------------------------------------------------#
# 第一个特征层
# y1=(batch_size,75,20,20)
# ---------------------------------------------------#
out0 = self.yolo_head_P5(P5)
return out0, out1, out2这里,得到整个Yolo V5的网络,输出三个特征层,下面开始训练Yolo V5算法模型。
2、训练
训练使用的是COCO128数据集进行训练,电脑的显卡太弱了,只能选择这种少量的数据集作为验证。训练部分没啥好说的,慢慢等待就是了。需要注意的是,训练好的模型文件格式是yolov5.pt格式文件,需要使用torch.onnx.export函数将其转化为onnx格式的文件。之后,使用RKNN-TooKit2提供的API,将onnx格式的文件转化为rknn格式的文件。
三、部署
部署到RK3588S平台之前,需要先将环境搭建好,连接好硬件。使用RKNN-TooKit2提供的API进行测试,测试代码比较简单,这里就不放了。常用的API可以参考博文:RKNN-Toolkit2相关API介绍(二)
看着API介绍就能写好代码。
测试结果如下:

自己训练的模型文件,跟使用别人的模型文件进行测试,差别还是有的,没有别人的准确率高。
四、总结
RK3588S部署Yolo V5还是比较容易的,当然也需要进行一些必要的修改。主要的困难依然在Yolo V5算法本身身上,至少我部署的时候没发现特别大的问题。