【实验课程】图像识别全流程代码实战
转载地址:【实验课程】图像识别全流程代码实战_MindSpore_昇腾论坛_华为云论坛
作者:yangyaqin
图像识别全流程代码实战
实验介绍
图像分类在我们的日常生活中广泛使用,比如拍照识物,还有手机的AI拍照,在学术界,每年也有很多图像分类的比赛,本实验将会利用一个开源数据集来帮助大家学习如何构建自己的图像识别模型。本实验会使用MindSpore来构建图像识别模型,然后将模型部署到ModelArts上提供在线预测服务。主要介绍部署上线,读者可以根据【实验课程】花卉图像分类实验( https://bbs.huaweicloud.com/forum/thread-80033-1-1.html )调节参数、改变网络使分类结果更优。
实验环境要求
ModelArts平台:MindSpore-0.5.0-python3.7-aarch64
实验总体设计
该实验主要步骤包括
1. 导入实验环境
2. 数据集准备
3. 定义网络结构
4. 开始模型训练
5. 模型保存和转换
6. 编辑模型推理代码和配置文件
7. 模型部署上线
注解:其中导入实验环境、数据集准备请参考花卉图像分类实验( https://bbs.huaweicloud.com/forum/thread-80033-1-1.html )。模型转换和部署参考:
https://support.huaweicloud.com/bestpractice-modelarts/modelarts_10_0026.html
实验过程
本节将详细介绍实验的设计与实现。数据集获取;模型构建; 模型保存和转换;模型部署上线。
数据集获取
从华为云对象存储服务(OBS)获取
深度学习课程为了学员方便学习与使用,在华为云开通了相应的数据存储服务OBS,学员可直接通过链接进行数据集下载。
测试数据集需下载到本地电脑并解压,训练数据集无需下载。
训练数据集链接:https://professional.obs.cn-north-4.myhuaweicloud.com/flower_photos_train.zip
测试数据集链接:https://professional.obs.cn-north-4.myhuaweicloud.com/flower_photos_test.zip
完整数据集链接:https://professional.obs.cn-north-4.myhuaweicloud.com/flower_photos.zip
从TensorFlow网站获取
链接:http://download.tensorflow.org/example_images/flower_photos.tgz
或者在ModelArts平台输入代码一下代码自动获取数据
!wget https://professional.obs.cn-north-4.myhuaweicloud.com/flower_photos_train.zip
!unzip flower_photos_train.zip
导入模型和数据集处理
导入模型
from easydict import EasyDict as edict
import glob
import os
import numpy as np
import matplotlib.pyplot as plt
import mindspore
import mindspore.dataset as ds
import mindspore.dataset.transforms.vision.c_transforms as CV
import mindspore.dataset.transforms.c_transforms as C
from mindspore.dataset.transforms.vision import Inter
from mindspore.common import dtype as mstype
from mindspore import context
from mindspore.common.initializer import TruncatedNormal
from mindspore import nn
from mindspore.train import Model
from mindspore.train.callback import ModelCheckpoint, CheckpointConfig, LossMonitor, TimeMonitor
from mindspore import Tensor
from mindspore.train.serialization import export
from mindspore.ops import operations as P
#context.set_context(mode=context.PYNATIVE_MODE,device_target="Ascend")
context.set_context(mode=context.GRAPH_MODE,device_target="Ascend")
定义变量
cfg = edict({
'data_path': 'flower_photos_train',
'test_path':'./code/flowers/flower_photos_test',
'data_size': 3618,
'image_width': 128, # 图片宽度
'image_height': 128, # 图片高度
'batch_size': 32,
'channel': 3, # 图片通道数
'num_class': 5, # 分类类别
'weight_decay': 0.0,
'lr':0.001, # 学习率
'dropout_ratio': 0.9,
'epoch_size': 20, # 训练次数
'sigma':0.01,
'save_checkpoint_steps': 1, # 多少步保存一次模型
'keep_checkpoint_max': 3, # 最多保存多少个模型
'output_directory': './code/flowers/checkpoint', # 保存模型路径
'output_prefix': "CKP" # 保存模型文件名字
})
读取数据并处理
def read_data(path,config):
de_dataset = ds.ImageFolderDatasetV2(path,
class_indexing={'daisy':0,'dandelion':1,'roses':2,'sunflowers':3,'tulips':4})
rescale = 1.0 / 127.5
shift = -1.0
transform_img=CV.RandomCropDecodeResize([config.image_width,config.image_height], scale=(0.08, 1.0), ratio=(0.75, 1.333)) #改变尺寸
hwc2chw_op = CV.HWC2CHW()
type_cast_op = C.TypeCast(mstype.float32)
rescale_op = CV.Rescale(rescale, shift)
de_dataset = de_dataset.map(input_columns="image", operations=transform_img, num_parallel_workers=8)
de_dataset = de_dataset.map(input_columns="image", operations=rescale_op, num_parallel_workers=8)
de_dataset = de_dataset.map(input_columns="image", operations=hwc2chw_op, num_parallel_workers=8)
#de_dataset = de_dataset.map(input_columns="image", operations=type_cast_op, num_parallel_workers=8)
de_dataset = de_dataset.shuffle(buffer_size=cfg.data_size)
de_dataset = de_dataset.batch(config.batch_size, drop_remainder=True)
de_dataset = de_dataset.repeat(config.epoch_size)
return de_dataset
de_train = read_data(cfg.data_path,cfg)
de_test = read_data(cfg.test_path,cfg)
print('训练数据集数量:',de_train.get_dataset_size()*cfg.batch_size)
print('测试数据集数量:',de_test.get_dataset_size()*cfg.batch_size)
de_dataset = de_train
data_next = de_dataset.create_dict_iterator().get_next()
print('通道数/图像长/宽:', data_next['image'][0,...].shape)
print('一张图像的标签样式:', data_next['label'][0]) # 一共5类,用0-4的数字表达类别。
plt.figure()
plt.imshow(data_next['image'][0,0,...])
plt.colorbar()
plt.grid(False)
plt.show()
训练数据集数量: 3616 测试数据集数量: 32 通道数/图像长/宽: (3, 128, 128) 一张图像的标签样式: 1
模型构建
本节主要介绍了如何构建一个图片识别模型。
在章节的最后,我们又介绍了如何保存一个模型的计算图和模型结构,为后续的模型部署上线做准备。
步骤 1 定义模型
# 定义CNN图像识别网络
class Identification_Net(nn.Cell):
def __init__(self, num_class=5,channel=3,dropout_ratio=0.7,trun_sigma=0.01):
super(Identification_Net, self).__init__()
self.num_class = num_class
self.channel = channel
self.dropout_ratio = dropout_ratio
self.conv1 = nn.Conv2d(self.channel, 64,
kernel_size=1, stride=1,
has_bias=True, pad_mode="same",
weight_init='xavier_uniform', bias_init='zeros')
self.conv2 = nn.Conv2d(64, 128,
kernel_size=1, stride=1,
has_bias=True, pad_mode="same",
weight_init='xavier_uniform', bias_init='zeros')
self.max_pool2d = nn.MaxPool2d(kernel_size=4, stride=4)
self.conv3 = nn.Conv2d(128, 128,
kernel_size=5, stride=2,
has_bias=True, pad_mode="same",
weight_init='xavier_uniform', bias_init='zeros')
self.conv4 = nn.Conv2d(128, 128,
kernel_size=3, stride=2, padding=0,
has_bias=True, pad_mode="same",
weight_init='xavier_uniform', bias_init='zeros')
self.conv5 = nn.Conv2d(128, 64,
kernel_size=1, stride=1,
has_bias=True, pad_mode="same",
weight_init='xavier_uniform', bias_init='zeros')
self.flatten = nn.Flatten()
self.fc1 = nn.Dense(8*8*64,512,weight_init=TruncatedNormal(sigma=trun_sigma),bias_init = 0.1)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(self.dropout_ratio)
self.fc2 = nn.Dense(512, 256, weight_init=TruncatedNormal(sigma=trun_sigma), bias_init=0.1)
self.fc3 = nn.Dense(256, self.num_class, weight_init=TruncatedNormal(sigma=trun_sigma), bias_init=0.1)
self.relu = nn.ReLU()
self.concat = P.Concat(axis=1)
def construct(self, x):
x = self.conv1(x) #(32, 64, 128, 128)
x = self.relu(x)
x = self.conv2(x) #(32, 128, 126, 126)
x = self.relu(x)
x = self.max_pool2d(x) #(32, 128, 31, 31)
#print(x.shape)
x = self.conv3(x) #(32, 128, 16, 16)
x = self.relu(x)
x = self.conv4(x) #(32, 128, 8, 8)
x = self.relu(x)
x = self.conv5(x) #(32, 128, 8, 8)
x = self.relu(x)
x = self.flatten(x) #(32, 4096)
x = self.fc1(x) #(32, 512)
x = self.relu(x) #(32, 512)
x = self.dropout(x) #(32, 512)
x = self.fc2(x) #(32, 256)
x = self.relu(x) #(32, 256)
x = self.dropout(x) #(32, 256)
x = self.fc3(x) #(32, 5)
return x
步骤 2 开始训练
net=Identification_Net(num_class=cfg.num_class, channel=cfg.channel, dropout_ratio=cfg.dropout_ratio,trun_sigma=cfg.sigma)
net_loss = nn.SoftmaxCrossEntropyWithLogits(is_grad=False, sparse=True, reduction="mean")
#opt
fc_weight_params = list(filter(lambda x: 'fc' in x.name and 'weight' in x.name, net.trainable_params()))
else_params=list(filter(lambda x: x not in fc_weight_params, net.trainable_params()))
group_params = [{'params': fc_weight_params, 'weight_decay': cfg.weight_decay},
{'params': else_params}]
net_opt = nn.Adam(group_params, learning_rate=cfg.lr, weight_decay=0.0)
model = Model(net, loss_fn=net_loss, optimizer=net_opt, metrics={"acc"})
loss_cb = LossMonitor(per_print_times=de_train.get_dataset_size())
#config_ck = CheckpointConfig(save_checkpoint_steps=cfg.save_checkpoint_steps,
# keep_checkpoint_max=cfg.keep_checkpoint_max)
#ckpoint_cb = ModelCheckpoint(prefix=cfg.output_prefix, directory=cfg.output_directory, config=config_ck)
print("============== Starting Training ==============")
model.train(cfg.epoch_size, de_train, callbacks=[loss_cb], dataset_sink_mode=True)
# 使用测试集评估模型,打印总体准确率
metric = model.eval(de_test)
print(metric)
模型保存和转换
步骤 1 保存模型为onnx格式
x = np.random.uniform(-1.0, 1.0, size = [1, 3, 128, 128]).astype(np.float32)
export(net, Tensor(x), file_name = './code/flowers/best_model.onnx', file_format = 'ONNX')
步骤 2 保存模型到obs桶里面
import moxing
moxing.file.copy_parallel(src_url='./code/flowers/best_model.onnx', dst_url='s3://users-obs/flowers/model/onnx/best_model.onnx')
步骤3 在's3://users-obs/flowers/model/onnx'中放如转换模型需要配置文件insert_op_conf.cfg
内容为:
aipp_op {
aipp_mode: static
input_format : RGB888_U8
mean_chn_0 : 123
mean_chn_1 : 117
mean_chn_2 : 104
}
需要在OBS创建桶,不然会报错。
链接: https://storage.huaweicloud.com/obs/?region=cn-north-4#/obs/manager/buckets
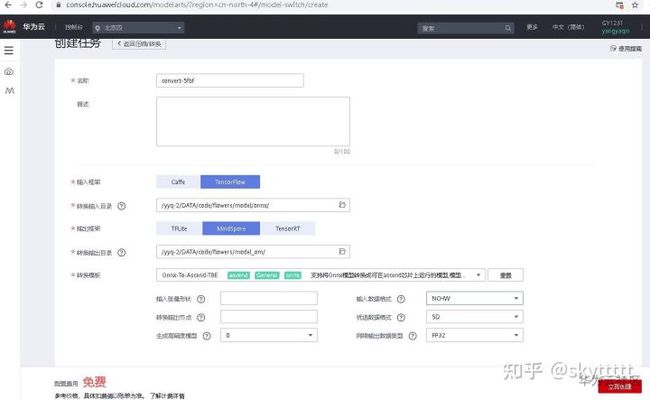
步骤 3 转换模型格式为om格式
进入ModelArts控制台,点击模型管理>压缩/转换>创建任务

按照下图填写。其中转换输入目录是前面代码生成的.onnx文件目录。转换输出路径为空白目录(提前在obs桶中建好空白目录)
点击立即创建,得到下图所示:
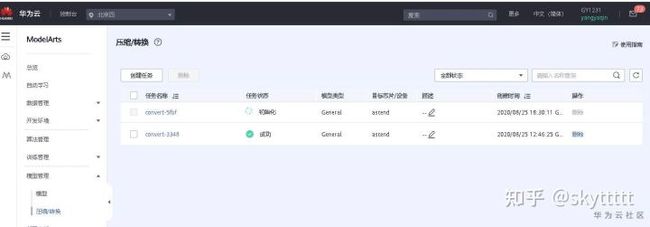
等待几分钟,运行成功好,查看obs输出目录下是否有生成的.om文件。
模型部署上线
步骤 1 编写读测试数据代码文件
编写测试数据读取代码如下所示,并将写好的度测试数据代码文件customize_service.py上传到obs桶内的om模型路径下。即:和上一步生成的om模型在一个文件夹里面。
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import os
import numpy as np
from PIL import Image
from hiai.nn_tensor_lib import NNTensor
from hiai.nntensor_list import NNTensorList
from model_service.hiai_model_service import HiaiBaseService
"""AIPP example
aipp_op {
aipp_mode: static
input_format : RGB888_U8
mean_chn_0 : 123
mean_chn_1 : 117
mean_chn_2 : 104
}
"""
labels_list = []
if os.path.exists('labels.txt'):
with open('labels.txt', 'r') as f:
for line in f:
if line.strip():
labels_list.append(line.strip())
def keep_ratio_resize(im, base=128):
short_side = min(float(im.size[0]), float(im.size[1]))
resize_ratio = base / short_side
resize_sides = int(round(resize_ratio * im.size[0])), int(round(resize_ratio * im.size[1]))
im = im.resize(resize_sides)
return im
def central_crop(im, base=128):
width, height = im.size
left = (width - base) / 2
top = (height - base) / 2
right = (width + base) / 2
bottom = (height + base) / 2
# Crop the center of the image
im = im.crop((left, top, right, bottom))
return im
class DemoService(HiaiBaseService):
def _preprocess(self, data):
preprocessed_data = {}
images = []
for k, v in data.items():
for file_name, file_content in v.items():
image = Image.open(file_content)
image = keep_ratio_resize(image, base=128)
image = central_crop(image, base=128)
image = np.array(image) # HWC
image = image.transpose(2,0,1)
# AIPP should use RGB format.
# mean reg is applied in AIPP.
# Transpose is applied in AIPP
tensor = NNTensor(image)
images.append(tensor)
tensor_list = NNTensorList(images)
preprocessed_data['images'] = tensor_list
return preprocessed_data
def _inference(self, data, image_info=None):
result = {}
for k, v in data.items():
result[k] = self.model.proc(v)
return result
def _postprocess(self, data):
outputs = {}
prob = data['images'][0][0][0][0].tolist()
outputs['scores'] = prob
labels_list = ['daisy', 'dandelion', 'roses', 'sunflowers', 'tulips']
if labels_list:
outputs['predicted_label'] = labels_list[int(np.argmax(prob))]
else:
outputs['predicted_label'] = str(int(np.argmax(prob)))
return outputs
步骤 2 导入模型
进入ModelArts控制台,点击模型管理>模型>导入
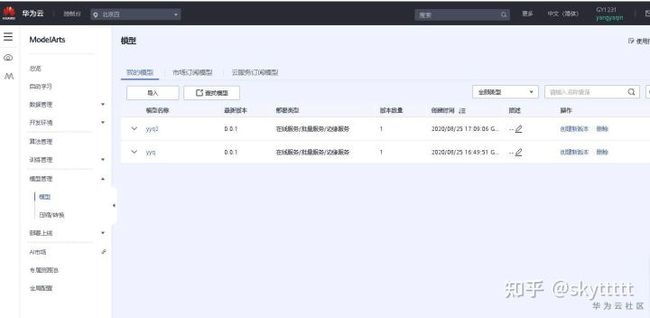
按照下图填写,其中
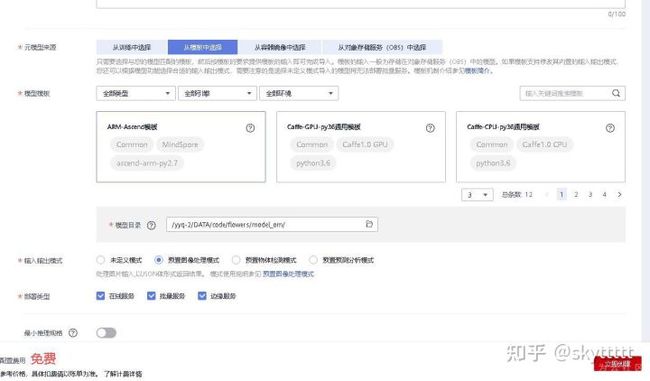
等待几分钟,模型导入成功后点击部署>在线服务,如下图所示:
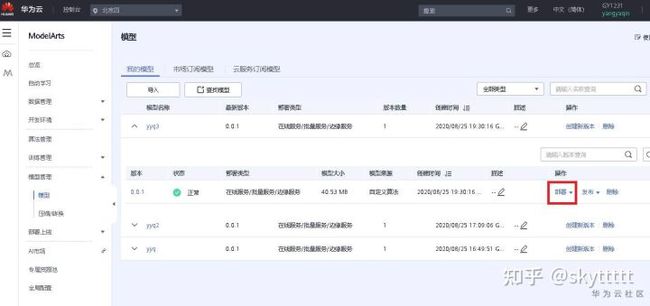
界面会自动跳转到部署上线>在线服务界面。按下图所示填写
其中模型名字必须与前面导入的模型名字相同

点击下一步并提交。进入部署在线>在线服务。如下图所示:
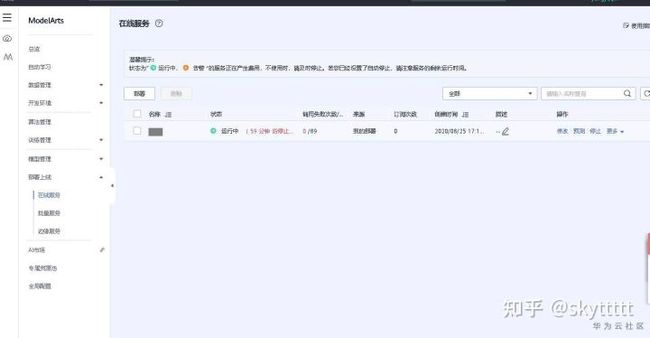
步骤 3 预测
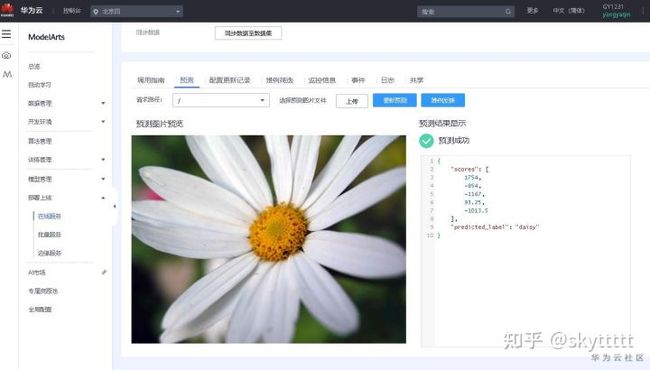
点击上图中预测进入预测界面。如下图所示:

点击上传,在本地目录flower_photos_test(参考6.5.1)中选择图片,点击预测。结果如下所示
实验总结
本章提供了一个基于华为ModelArts平台的花卉图像识别实验。该实验演示了如何利用华为云ModelArts完成图像识别任务。通过MindSpore来构建图像识别模型,然后将模型部署到ModelArts上提供在线预测服务。
创新设计
基于本实验的描述,请尝试构建其他模型(如VGGnet等)进行花卉识别做预测并部署上线。