SQL面试题总结(MySQL实现/持续更新)
前言:下面很多都是个人的解题思路,部分参考网上代码,确保在需求实现上没有问题,但未必就是最简洁的解法,如有更好的解法欢迎留言。
- 1.行列转换
-
- 行转列
- 列转行
- 2.分组求top-N
- 3.连续登录
- 4.组内求中位数、众数
-
- 中位数
- 众数
1.行列转换
行转列
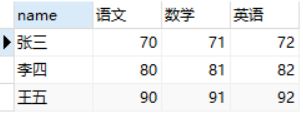
导入测试数据,
create table tmp (
`name` varchar(20),
`course` varchar(20),
`score` int
);
insert into tmp values('张三','语文',70),('张三','数学',71),('张三','英语',72),
('李四','语文',80),('李四','数学',81),('李四','英语',82),
('王五','语文',90),('王五','数学',91),('王五','英语',92);
select * from tmp;

select
name,
max(if(course='语文',score,0)) as '语文',
max(if(course='数学',score,0)) as '数学',
max(if(course='英语',score,0)) as '英语'
from tmp
group by name;
列转行
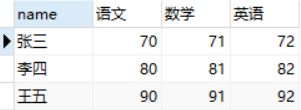
建测试数据表,
create table tmp1 as (
select
name,
max(if(course='语文',score,0)) as '语文',
max(if(course='数学',score,0)) as '数学',
max(if(course='英语',score,0)) as '英语'
from tmp
group by name
);
select * from tmp1;
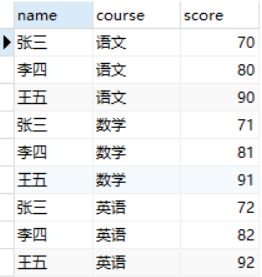
select
name,
'语文' as 'course',
max(语文) as 'score'
from tmp1
group by name
union
select
name,
'数学' as 'course',
max(数学) as 'score'
from tmp1
group by name
union
select
name,
'英语' as 'course',
max(英语) as 'score'
from tmp1
group by name;
2.分组求top-N
例如有 id,score 两个字段,求每组id中最高的前2个score对应的记录。
建表并导入测试数据:
create table if not exists tmp (id int, score int);
insert into tmp values(1,15),(1,25),(1,35),(1,45),
(2,55),(2,65),(2,75),(2,85);
select * from tmp;
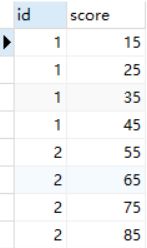
最容易实现的方式是通过开窗函数:
select id, score from (
select
*,
row_number() over(partition by id order by score desc) rn
from tmp
) t where t.rn <= 2;
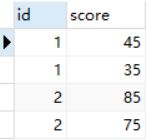
也可以不使用开窗函数实现,
select
*
from tmp t1
where (select count(*) from tmp t2 where t2.id=t1.id and t2.score>t1.score) < 2;
上面代码的思路用大白话描述一下就是,对tmp表中的每条数据逐一过滤,判断这条数据在所在分组中有几条数据比它大,因为这题是选出每组前2个最大的,所以组内仅有1条记录或0条记录比它大时,那么这条记录一定是组内最大的2个中的一个。
如果把这题改成求top1,还有种思路可以借鉴:select * from tmp where score in (select max(score) from tmp group by id);,思路简单,但是使用前提要保证表中的top字段score不要重复,不然可能出现错误,比如A组内最大的score=5,B组内最大的值=6,同时也包含5,那么B组中的这个5本不应该出现但是也被选出来了。
3.连续登录
表中有id,date两个字段,求连续三天及以上登录的用户id。
导入测试数据,
create table tmp (
id int,
date date
);
insert into tmp values(1,'2020-01-15'),(1,'2020-01-16'),(1,'2020-01-17'),(1,'2020-01-19'),
(2,'2020-01-15'),(2,'2020-01-16'),(2,'2020-01-18'),(2,'2020-01-19'),
(3,'2020-01-15'),(3,'2020-01-17'),(3,'2020-01-18'),(3,'2020-01-19');
select * from tmp;

select
max(id) as id
from (
select
*,
row_number() over(partition by id order by date) as 'rn'
from tmp
) t
group by
t.id,
date_sub(t.date, interval rn day)
having
count(*) >= 3;

连续登录的关键思路在于如果连续登录,则这些连续的登录日期减去组内行号的值相同。
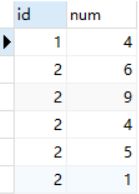
4.组内求中位数、众数
测试数据:
create table tmp(
id int,
num int
);
insert into tmp values(1,2),(1,3),(1,1),(1,4),(1,5),(1,4),
(2,6),(2,9),(2,4),(2,5),(2,1);
select * from tmp;

中位数
中位数指的是对一组数进行排序后,如果这组数的个数为奇数个,则中间的那个数为中位数,如果这组数的个数为偶数个,则中位数为中间两个数的平均值。
求解思路是通过开窗函数,分别对这组数进行正序排序和倒序排序,此时对应两种情况:1.当这组数为奇数个时,正序=倒序的那个数即为中位数。2.当这组数个数为偶数个时,正序-倒序=±1的那两个数的平均值就是中位数。
这里面有一个特别需要注意的点:就是针对重复数据进行正序和倒序标记,结果并不是类似于3 2 1,1 2 3,而是会形如3 1 2,1 2 3,也就是说相同的数据在正序和倒序里面的相对位置其实是不变的,并不是绝对意义上的排序,下面是不考虑重复数据的代码和结果:
select * from (
select
*,
row_number() over(partition by id order by num) as 'th1',
row_number() over(partition by id order by num desc) as 'th2'
from tmp
) t;

可以看到 ‘th1’ 列并不是 654321,这个问题可以通过增加不包含重复数据的列,并以此列为排序的第二个字段,以此确保重复数据会被交换位置。网上很多代码都没有考虑到这一点,至少在mysql中是不对的。
根据上面的思路代码如下:
with t1 as(
select
*,
row_number() over(partition by id order by num) as 'rn'
from tmp
),
t2 as(
select
*,
row_number() over(partition by id order by num, rn) as 'th1',
row_number() over(partition by id order by num desc, rn desc) as 'th2'
from t1
)
select * from t2;
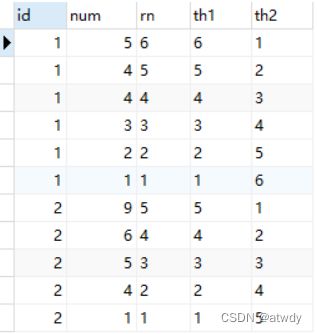
可以看到根据 rn 进行二次排序后就能保证重复数据可以被交换位置了,再根据上一步的结果求平均数就很简单了,完整代码如下:
-- 增加不重复列
with t1 as(
select
*,
row_number() over(partition by id order by num) as 'rn'
from tmp
),
-- 分别打上正序倒序标记
t2 as(
select
*,
row_number() over(partition by id order by num, rn) as 'th1',
row_number() over(partition by id order by num desc, rn desc) as 'th2'
from t1
),
-- 找出每组内的中位数或者中间的两个数
t3 as(
select * from t2 where th1=th2 or abs(convert(th1,signed)-convert(th2,signed))=1
)
-- 分组求均值
select id, avg(num) from t3 group by id;
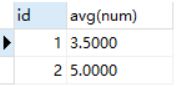
为了便于理解使用了CTE语句代替了子查询。
众数
众数指出现次数最多的数,一组数中可以有多个众数。
还是上面的测试数据:
实现思路是:(1)先通过 (id, num) 分组并统计每组内记录数count,结果作为一个临时表tmp1。(2)在这个临时表的基础上再根据id分组,找出每组内最大的count值max_count,并作为另一个临时表tmp2。(3)用tmp1关联tmp2,关联条件为tmp1.id=tmp2.id and tmp1.count=tmp2.max_count,前面确保同一组,后面确保出现次数最多。
代码实现如下:
with tmp1 as (
select id, num, count(*) count from tmp group by id, num
),
tmp2 as (
select id, max(count) max_count from tmp1 group by id
)
select tmp1.id, num from tmp1, tmp2 where tmp1.id = tmp2.id and tmp1.count = tmp2.max_count;