一文详解Redis键过期策略
1 设置带过期时间的 key
# 时间复杂度:O(1),最常用方式
expire key seconds
# 字符串独有方式
setex(String key, int seconds, String value)除了string独有设置过期时间的方法,其他类型都需依靠expire方法设置时间,若:
- 未设置时间,则缓存永不过期
- 设置过期时间,但之后又想让缓存永不过期,使用persist

设置key的过期时间。超时后,将会自动删除该key。在Redis的术语中一个key的相关超时是volatile的。
生存时间可以通过使用 DEL 命令来删除整个 key 来移除,或者被 SET 和 GETSET 命令覆写(overwrite)。这意味着,如果一个命令只是修改(alter)一个带生存时间的 key 的值而不是用一个新的 key 值来代替(replace)它的话,那么生存时间不会被改变。 如使用 INCR 递增key的值,执行 LPUSH 将新值推到 list 中或用 HSET 改变hash的field,这些操作都使超时保持不变。
- 使用 PERSIST 命令可以清除超时,使其变成一个永久key
- 若 key 被 RENAME 命令修改,相关的超时时间会转移到新key
- 若 key 被 RENAME 命令修改,比如原来就存在 Key_A,然后调用 RENAME Key_B Key_A 命令,这时不管原来 Key_A 是永久的还是设为超时的,都会由Key_B的有效期状态覆盖
注意,使用非正超时调用 EXPIRE/PEXPIRE 或具有过去时间的 EXPIREAT/PEXPIREAT 将导致key被删除而不是过期(因此,发出的key事件将是 del,而不是过期)。
1.1 刷新过期时间
对已经有过期时间的key执行EXPIRE操作,将会更新它的过期时间。有很多应用有这种业务场景,例如记录会话的session。
1.2 Redis 之前的 2.1.3 的差异
在 Redis 版本之前 2.1.3 中,使用更改其值的命令更改具有过期集的密钥具有完全删除key的效果。由于现在修复的复制层中存在限制,因此需要此语义。
EXPIRE 将返回 0,并且不会更改具有超时集的键的超时。
1.3 返回值
- 1,如果成功设置过期时间。
- 0,如果key不存在或者不能设置过期时间。
1.4 示例
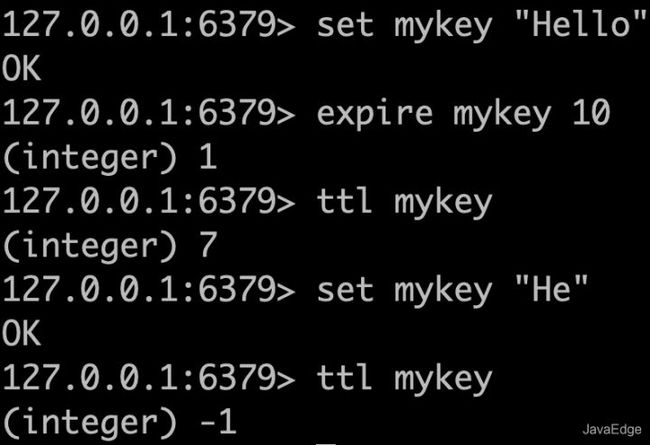
假设有一 Web 服务,对用户最近访问的最新 N 页感兴趣,这样每个相邻页面视图在上一个页面之后不超过 60 秒。从概念上讲,可以将这组页面视图视为用户的导航会话,该会话可能包含有关ta当前正在寻找的产品的有趣信息,以便你可以推荐相关产品。
可使用以下策略轻松在 Redis 中对此模式建模:每次用户执行页面视图时,您都会调用以下命令:
MULTI
RPUSH pagewviews.user: http://.....
EXPIRE pagewviews.user: 60
EXEC 如果用户空闲超过 60 秒,则将删除该key,并且仅记录差异小于 60 秒的后续页面视图。
此模式很容易修改,使用 INCR 而不是使用 RPUSH 的列表。
1.5 带过期时间的 key
通常,创建 Redis 键时没有关联的存活时间。key将永存,除非用户以显式方式(例如 DEL 命令)将其删除。EXPIRE 族的命令能够将过期项与给定key关联,但代价是该key使用的额外内存。当key具有过期集时,Redis 将确保在经过指定时间时删除该key。
可使用 EXPIRE 和 PERSIST 命令(或其他严格命令)更新或完全删除生存的关键时间。
1.6 过期精度
在 Redis 2.4 中,过期可能不准确,并且可能介于 0 到 1 秒之间。
由于 Redis 2.6,过期误差从 0 到 1 毫秒。
1.7 过期和持久化
过期信息的键存储为绝对 Unix 时间戳(Redis 版本 2.6 或更高版本为毫秒)。这意味着即使 Redis 实例不处于活动状态,时间也在流动。
要使过期工作良好,必须稳定计算机时间。若将 RDB 文件从两台计算机上移动,其时钟中具有大 desync,则可能会发生有趣的事情(如加载时加载到过期的所有key)。
即使运行时的实例,也始终会检查计算机时钟,例如,如果将一个key设置为 1000 秒,然后在将来设置计算机时间 2000 秒,则该key将立即过期,而不是持续 1000 秒。
2 Redis的key过期策略
- 被动方式 - 惰性删除
- 主动方式 - 定期删除
为保证 Redis 的高性能,所以不会单独安排一个线程专门去删除。
2.1 惰性删除
key过期时不删除,每次获取key时,再去检查是否过期。若过期,则删除,返回null。
2.1.1 优点
删除操作只发生在取key时,且只删除当前key,所以对CPU时间占用较少。此时删除已非做不可,毕竟若还不删除,就会获取到已过期key。
当查询该key时,Redis再很懒惰地检查是否删除。这和 Spring 的延迟初始化有着异曲同工之妙。
2.1.2 缺点
但这是不够的,因为有过期key,永远不会再访问。若大量key在超出TTL后,很久一段时间内,都没有被获取过,则可能发生内存泄露(无用垃圾占用了大量内存)。
无论如何,这些key都应过期,因此还需要定期 Redis 在具有过期集的key之间随机测试几个key。已过期的所有key将从key空间中删除。
定时删除
在设置key的过期时间的同时,为该key创建一个定时器,让定时器在key的过期时间来临时,对key进行删除。
优点
保证内存被尽快释放
缺点
- 若过期key很多,删除这些key会占用很多的CPU时间,在CPU时间紧张的情况下,CPU不能把所有的时间用来做要紧的事儿,还需要去花时间删除这些key
- 定时器的创建耗时,若为每一个设置过期时间的key创建一个定时器(将会有大量的定时器产生),性能影响严重
所以没人用
2.2 定期删除
每隔一段时间执行一次删除过期key操作。
优点
- 通过限制删除操作的时长和频率,来减少删除操作对CPU时间的占用–处理"定时删除"的缺点
- 定期删除过期key–处理"惰性删除"的缺点
缺点
- 在内存友好方面,不如"定时删除"
- 在CPU时间友好方面,不如"惰性删除"
难点
- 合理设置删除操作的执行时长(每次删除执行多长时间)和执行频率(每隔多长时间做一次删除)(这个要根据服务器运行情况来定了)
每秒 10 次:
- 测试 20 个带有过期的随机键
- 删除找到的所有已过期key
- 如果超过 25% 的key已过期,从步骤 1 重新开始
这是个微不足道的概率算法,假设样本为整个key空间,继续过期,直到可能过期的key百分比低于 25%。
这意味着在任何给定时刻,使用内存的已过期的最大键量等于最大写入操作量/秒除以 4。
定期删除流程

void databasesCron(void) {
/* Expire keys by random sampling. Not required for slaves
* as master will synthesize DELs for us. */
if (server.active_expire_enabled) {
if (iAmMaster()) {
activeExpireCycle(ACTIVE_EXPIRE_CYCLE_SLOW);
} else {
expireSlaveKeys();
}
}
#define ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP 20 /* Keys for each DB loop. */
void activeExpireCycle(int type) {
config_keys_per_loop = ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP +
ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP/4*effort,
// step1
for (j = 0; j < dbs_per_call && timelimit_exit == 0; j++) {
/* 如果没有什么可以过期,请尽快尝试下一个数据库 */
// step2
if ((num = dictSize(db->expires)) == 0) {
db->avg_ttl = 0;
// step3
break;
}
}
}对指定N个库的每个库随机删除≤指定个数的过期K。
- 遍历每个数据库(redis.conf中配置的"database"数量,默认16)
- 检查当前库中的指定个数的key(默认每个库检查20个key,这相当于该循环执行20次,循环体为下边的描述)
- 若当前库没有一个K设置TTL,直接执行下一个库的遍历
- 随机获取一个设置TTL的K,检查其是否过期,若过期,则删除
- 判断定期删除操作是否已达到指定时长,若已达到,直接退出定期删除
定期删除程序中有个全局变量current_db,记录下一个将要遍历的库。默认16个库,这次定期删除遍历了10个,那此时current_db就是11,下一次定期删除就从第11个库开始遍历,假设current_db等于15,那之后就再从0号库开始遍历(此时current_db==0)
Redis采用的过期策略
惰性删除+定期删除。
惰性删除流程
在进行get或setnx等操作时,先检查key是否过期:
- 若过期,删除key,然后执行相应操作
- 若没过期,直接执行相应操作
RDB处理过期key
过期key对RDB无影响:
- 从内存数据库持久化数据到RDB文件
持久化key之前,会检查是否过期,过期的key不进入RDB文件
- 从RDB文件恢复数据到内存数据库
数据载入数据库之前,会对K进行过期检查,若过期,不导入数据库(主库情况)
AOF处理过期K
过期key对AOF没有任何影响。
从内存数据库持久化到AOF文件
- 当key过期后,还没有被删除,此时进行执行持久化操作(该key不会进入aof文件,因为没有发生修改命令)
- 当key过期后,在发生删除操作时,程序会向aof文件追加一条del命令(在将来的以aof文件恢复数据的时候该过期的键就会被删掉)
AOF重写
重写时,会先判断key是否过期,已过期的key不会重写到aof文件
2.3 在复制链路和 AOF 文件中处理过期的方式
为了在不牺牲一致性的情况下获得正确行为,当key过期时,DEL 操作将同时在 AOF 文件中合成并获取所有附加的从节点。这样,过期的这个处理过程集中到主节点中,还没有一致性错误的可能性。
但是,虽然连接到主节点的从节点不会独立过期key(但会等待来自master的 DEL),但它们仍将使用数据集中现有过期的完整状态,因此,当选择slave作为master时,它将能够独立过期key,完全充当master。
默认每台Redis服务器有16个数据库,默认使用0号数据库,所有的操作都是对0号数据库的操作
# 设置数据库数量。默认为16个库,默认使用DB 0,可使用"select 1"来选择一号数据库
# 注意:由于默认使用0号数据库,那么我们所做的所有的缓存操作都存在0号数据库上,
# 当你在1号数据库上去查找的时候,就查不到之前set过的缓存
# 若想将0号数据库上的缓存移动到1号数据库,可以使用"move key 1"
databases 16- memcached只是用了惰性删除,而redis同时使用了惰性删除与定期删除,这也是二者的一个不同点(可以看做是redis优于memcached的一点)
- 对于惰性删除而言,并不是只有获取key的时候才会检查key是否过期,在某些设置key的方法上也会检查(eg.setnx key2 value2:该方法类似于memcached的add方法,如果设置的key2已经存在,那么该方法返回false,什么都不做;如果设置的key2不存在,那么该方法设置缓存key2-value2。假设调用此方法的时候,发现redis中已经存在了key2,但是该key2已经过期了,如果此时不执行删除操作的话,setnx方法将会直接返回false,也就是说此时并没有重新设置key2-value2成功,所以对于一定要在setnx执行之前,对key2进行过期检查)
可是,很多过期key,你没及时去查,定期删除也漏掉了,大量过期key堆积内存,Redis内存殆耗尽!
因此内存满时,还需有内存淘汰机制!这就是 Redis 自己 主动删除 数据了!小伙伴们有兴趣想了解内容和更多相关学习资料的请点赞收藏+评论转发+关注我,后面会有很多干货。我有一些面试题、架构、设计类资料可以说是程序员面试必备!所有资料都整理到网盘了,需要的话欢迎下载!私信我回复【999】即可免费获取