windows平台使用Docker搭建分布式hadoop集群
先修篇
下载Docker可参考该博客的Docker安装
安装Docker可能遇到的一些问题可参考该博客的Docker安装问题
操作环境
- windows : 10
- Docker : 4.7.0
- 将要拉取的镜像 : centos 7.6.1810
1. 安装centos 7.6镜像
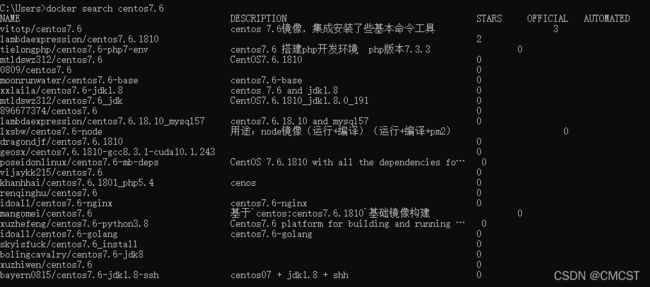
1.1 搜索centos 7.6镜像
docker search centos7
1.2 拉取镜像
docker pull centos:7.6.1810
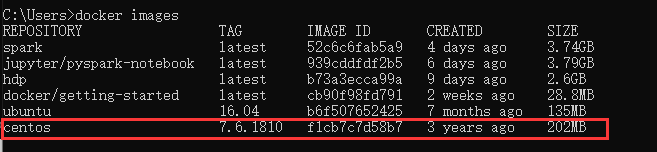
1.3 验证镜像安装成功
docker images
1.4 创建桥接网络(Docker默认使用桥接,此处亦使用桥接)
1.4.1 将网络名称命名为hadoop
docker network create -d bridge hadoop
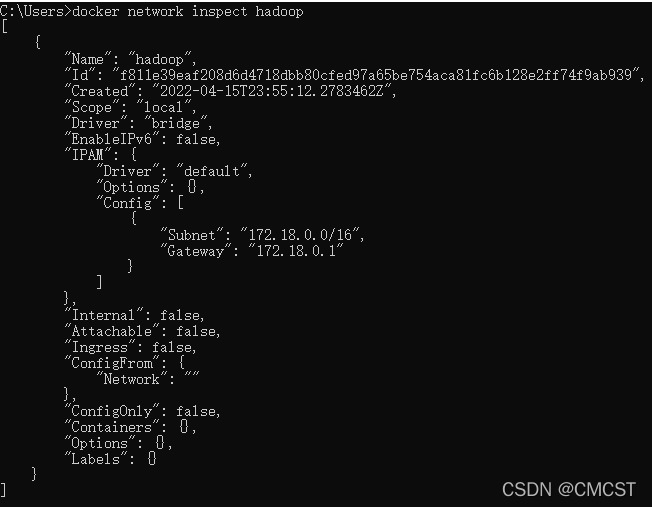
1.4.2 查看网络hadoop
docker network inspect hadoop
1.5 运行镜像成容器
# 将本地目录A挂载至镜像centos:7.6.1810,并以特权模式在后台启动容器(命名为centos7)
docker run -v E:\COURSE\spark:/home -itd --privileged --name centos7 centos:7.6.1810 /usr/sbin/init
![]()
docker run参数
- -v windows本地目录挂载至容器centos7的目录下
- -itd 后台启动
- –privileged 特权模式
- –name 对容器起名
# 连接当前运行容器,获取bash
docker exec -it centos7 /bin/bash
2. 为搭建hadoop做准备
2.1 配置centos镜像
阿里centos 镜像源
2.1.1 备份
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
2.1.2 下载新的 CentOS-Base.repo 到 /etc/yum.repos.d/
curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
2.1.3 生成缓存
yum makecache
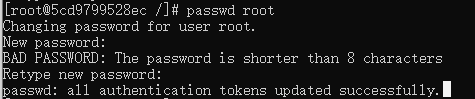
2.2 为root用户设置密码
yum -y install passwd
passwd root
2.3 安装工具
可不执行该语句
yum -y install vim passwd openssh-clients openssh-server net-tools
2.3.1 安装vim
yum install -y vim
2.2.2 安装open-ssh
yum install -y openssh-server openssh-clients
ssh-keygen命令常用选项:
- -t TYPE:指定密钥加密类型
- -P PASSWORD:指定私钥加密的密码,建议为空
- -f FILENAME:指定密钥保存位置
- 配置ssh免密登录
ssh-keygen -t rsa -P ""
- 将公钥追加到authorized_keys 文件中
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
- 编辑文件/etc/ssh/sshd_config
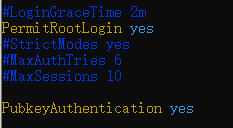
vim /etc/ssh/sshd_config
将PermitRootLogin yes、PubkeyAuthentication yes的注释去掉
4. 设置 SSH 服务为自启动
systemctl enable sshd.service
- 启动 SSH 服务
systemctl start sshd.service
- 免密登录自己(验证ssh是否配置成功)
ssh 127.0.0.1
![]()
2.2.3 安装JAVA
方式一 使用yum源安装
yum search java| grep jdk
yum install -y java-1.8.0-openjdk*
2.2.3.1. 寻找JAVA安装位置
第二条和第三条命令中具体ls 哪个目录, 视上一步输出结果而定
which java
ls -lr /usr/bin/java
ls -lr /etc/alternatives/java

2.2.3.2 由①寻得java安装目录为/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.322.b06-1.el7_9.x86_64/jre/bin/java
2.2.3.3 配置有关java环境变量
vim /etc/profile
在末尾添加如下内容:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.322.b06-1.el7_9.x86_64
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
2.2.3.4 验证
source /etc/profile
echo $JAVA_HOME
![]()
方式二 压缩包式安装
第一步 : Oracle JDK官网下载至(之前启动容器时挂载的目录A)
tar -zxvf /home/jdk-8u331-linux-x64.tar.gz -C /usr/local/
mv /usr/local/jdk-8u331-linux-x64 /usr/local/java
第二步 : 配置有关java环境变量
vim /etc/profile
在末尾添加如下内容:
export JAVA_HOME=/usr/local/java
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
第三步 : 验证
source /etc/profile
echo $JAVA_HOME

2.2.4 将hadoop3.2.2解压至/usr/local目录下
此前启动容器时,将目录A(E:\COURSE\spark文件夹)挂载至容器的/home下
hadoop-3.2.3.tar.gz清华镜像站
tar -zxvf /home/hadoop-3.2.2.tar.gz -C /usr/local/
mv /usr/local/hadoop-3.2.2 /usr/local/hadoop
3. 搭建hadoop集群
3.1 修改文件
3.1.1 /etc/profile
vim /etc/profile
在末尾添加如下内容:
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_PREFIX=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_CONF_DIR=$HADOOP_HOME
export HADOOP_LIBEXEC_DIR=$HADOOP_HOME/libexec
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
export HADOOP_CONF_DIR=$HADOOP_PREFIX/etc/hadoop
export HDFS_DATANODE_USER=root
export HDFS_DATANODE_SECURE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_NAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
使文件/etc/profile生效:
source /etc/profile
3.1.2 $HADOOP_HOME/etc/hadoop/hadoop-env.sh
vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh
在末尾添加如下内容:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.322.b06-1.el7_9.x86_64
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
3.1.3 $HADOOP_HOME/etc/hadoop/core-site.xml
vim $HADOOP_HOME/etc/hadoop/core-site.xml
将原文件的
<configuration>
<property>
<name>fs.default.namename>
<value>hdfs://node01:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/home/hadoop/tmpvalue>
property>
<property>
<name>io.file.buffer.sizename>
<value>131702value>
property>
configuration>
3.1.4 $HADOOP_HOME/etc/hadoop/hdfs-site.xml
vim $HADOOP_HOME/etc/hadoop/hdfs-site.xml
将原文件的
<configuration>
<property>
<name>dfs.namenode.name.dirname>
<value>file:/home/hadoop/hdfs_namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/home/hadoop/hdfs_datavalue>
property>
<property>
<name>dfs.replicationname>
<value>2value>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>node01:9001value>
property>
<property>
<name>dfs.webhdfs.enabledname>
<value>truevalue>
property>
configuration>
3.1.5 $HADOOP_HOME/etc/hadoop/mapred-site.xml
vim $HADOOP_HOME/etc/hadoop/mapred-site.xml
将原文件的
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>node01:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>node01:19888value>
property>
<property>
<name>mapreduce.application.classpathname>
<value>
/usr/local/hadoop/etc/hadoop,
/usr/local/hadoop/share/hadoop/common/*,
/usr/local/hadoop/share/hadoop/common/lib/*,
/usr/local/hadoop/share/hadoop/hdfs/*,
/usr/local/hadoop/share/hadoop/hdfs/lib/*,
/usr/local/hadoop/share/hadoop/mapreduce/*,
/usr/local/hadoop/share/hadoop/mapreduce/lib/*,
/usr/local/hadoop/share/hadoop/yarn/*,
/usr/local/hadoop/share/hadoop/yarn/lib/*
value>
property>
configuration>
3.1.6 $HADOOP_HOME/etc/hadoop/yarn-site.xml
vim $HADOOP_HOME/etc/hadoop/yarn-site.xml
将原文件的
<configuration>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>node01value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
property>
<property>
<name>yarn.resourcemanager.addressname>
<value>node01:8032value>
property>
<property>
<name>yarn.resourcemanager.scheduler.addressname>
<value>node01:8030value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.addressname>
<value>node01:8031value>
property>
<property>
<name>yarn.resourcemanager.admin.addressname>
<value>node01:8033value>
property>
<property>
<name>yarn.resourcemanager.webapp.addressname>
<value>node01:8088value>
property>
configuration>
3.1.7 $HADOOP_HOME/etc/hadoop/workers
vim $HADOOP_HOME/etc/hadoop/workers
将原文件的替换为如下内容:
node02
node03
3.2 从容器中保存镜像
# 当前容器 可使用命令 docker ps 查看镜像ID
docker commit -m “hadoop” -a “hadoop“ 当前容器 目标镜像
本人此处命令为
docker commit -m “Deploy Hadoop based on centos” -a “CMCST“ centos7 hadoop_centos
docker commit :从容器创建一个新的镜像。
语法
docker commit [OPTIONS] CONTAINER [REPOSITORY[:TAG]]
| OPTIONS说明 | 说明 |
|---|---|
| -a | 提交的镜像作者; |
| -c | 使用Dockerfile指令来创建镜像; |
| -m | 提交时的说明文字; |
| -p | 在commit时,将容器暂停 |
3.3 启动hadoop
3.3.1 运行Master节点: node01
docker run -itd --privileged --network hadoop -h "node01" --name "node01" -p 9870:9870 -p 8088:8088 -p 50070:50070 -p 9001:9001 -p 8030:8030 -p 8031:8031 -p 8032:8032 hadoop_centos /usr/sbin/init
3.3.2 运行Worker节点: node02
docker run -itd --privileged --network hadoop -h "node02" --name "node02" hadoop_centos /usr/sbin/init
3.3.3 运行Worker节点: node03
docker run -itd --privileged --network hadoop -h "node03" --name "node03" hadoop_centos /usr/sbin/init
3.3.4 修改文件/etc/hosts
获取node01、node02、node03的terminal
分别打开三个cmd窗口,分别执行
docker exec -it node01 /bin/bash
docker exec -it node02 /bin/bash
docker exec -it node03 /bin/bash
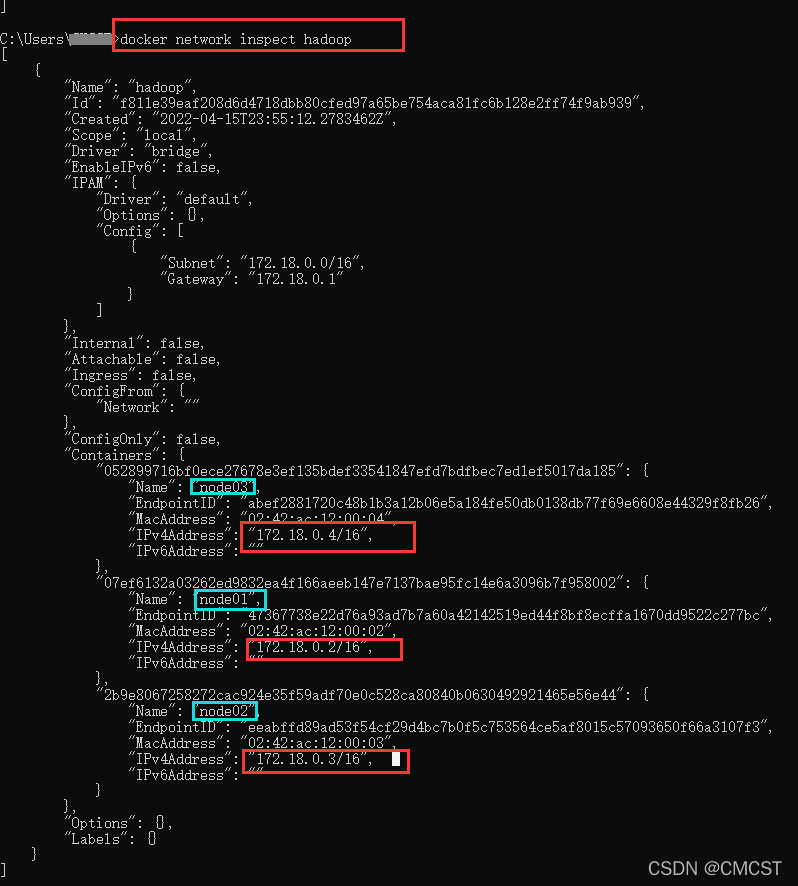
获取node01、node02、node03的IP地址
docker network inspect 网络名称
docker network inspect hadoop
在node01、node02、node03中修改文件/etc/hosts
vim /etc/hosts
在文件首部添加如下内容
172.18.0.2 node01
172.18.0.3 node02
172.18.0.4 node03
3.3.4 格式化[node1下]
/usr/local/hadoop/bin/hadoop namenode -format
3.3.5 启动hadoop集群[node1下]
/usr/local/hadoop/sbin/start.all.sh