CentOS7下基于Hadoop2.7.3集群搭建
一、准备工作
1.修改Linux主机名
2.修改IP
3.修改主机名和IP的映射关系
4.关闭防火墙
5.ssh免登陆
6.安装JDK,配置环境变量等
7.集群规划:
主机名 IP 所需安装工具 运行进程
hadoop01 220.192.10.10 jdk、hadoop、zookeeper DataNode、NodeManager、JournalNode、QuorumPeerMain
hadoop02 220.192.10.11 jdk、hadoop、zookeeper DataNode、NodeManager、JournalNode、QuorumPeerMain
hadoop03 220.192.10.12 jdk、hadoop、zookeeper DataNode、NodeManager、JournalNode、QuorumPeerMain
hadoop04 220.192.10.13 jdk、hadoop NameNode、DFSZKFailoverController
hadoop05 220.192.10.14 jdk、hadoop NameNode、DFSZKFailoverController
hadoop06 220.192.10.15 jdk、hadoop ResourceManager
hadoop07 220.192.10.16 jdk、hadoop ResourceManager
二、安装
1.在hadoop01上安装并配置zookeeper
1.1 解压zookeeper-3.4.9.tar.gz tar -zxvf zookeeper-3.4.9.tar.gz /hadoop
2.2 进入到conf目录(cd /hadoop/zookeeper-3.4.9/conf/),修改zoo_sample.cfg文件:mv zoo_sample.cfg zoo.cfg ;vi zoo.cfg
修改dataDir=/hadoop/zookeeper-3.4.9/data,在最后添加
server.1=hadoop01:2888:3888
server.2=hadoop02:2888:3888
server.3=hadoop03:2888:3888
保存后退出,创建tmp文件夹:mkdir /hadoop/zookeeper-3.4.9/tmp ,在创建一个空文件:touch /hadoop/zookeeper-3.4.9/tmp/myid,在myid文件夹中写入ID:1
2.将配置好的zookeeper拷贝到hadoop02、hadoop03上
scp -r /hadoop/zookeeper-3.4.9 hadoop02:/hadoop/
scp -r /hadoop/zookeeper-3.4.9 hadoop03:/hadoop/
修改tmp目录下的myid文件:vi myid,在hadoop02上将1改成2,在hadoop03上改成3,wq保存退出.
3.在hadoop01上安装配置hadoop2.7.3
3.1 解压到hadoop目录下:tar -zxvf hadoop-2.7.3.tar.gz /hadoop
3.2 配置环境变量:
export JAVA_HOME=/usr/java/jdk1.8.0_112
export HADOOP_HOME=/hadoop/hadoop-2.7.3
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
3.3 进入hadoop的etc目录修改配置文件:cd /hadoop/hadoop-2.7.3/etc/hadoop/
3.3.1 修改hadoop-env.sh : export JAVA_HOME=/usr/java/jdk1.8.0_112
3.3.2 修改core-site.xml
3.3.3 修改hdfs-site.xml
sshfence
shell(/bin/true)
3.3.4 修改mapred-site.xml
3.3.5 修改yarn-site.xml
3.3.6 修改slaves:slaves是指定子节点的位置,因为要在hadoop04上启动HDFS、在hadoop06启动yarn,所以hadoop04上的slaves文件指定的是datanode的位置,hadoop06上的slaves文件指定的是nodemanager的位置.
vi slaves
hadoop01
hadoop02
hadoop03
3.3.7 配置免密码登陆:在本机生成密钥:ssh-keygen -t rsa

将生成的公钥拷贝到其他节点上:
ssh-copy-id hadoop01
ssh-copy-id hadoop02
ssh-copy-id hadoop03
ssh-copy-id hadoop04
ssh-copy-id hadoop05
ssh-copy-id hadoop06
ssh-copy-id hadoop07
同样步骤在hadoop04,hadoop06上执行。
将hadoop04的公钥拷贝到hadoop05上,将hadoop06的公钥拷贝到hadoop01,hadoop02,hadoop03,hadoop07上。
3.4 将配置好的hadoop拷贝到其他节点
scp -r /hadoop/hadoop-2.7.3 hadoop02:/hadoop/
scp -r /hadoop/hadoop-2.7.3 hadoop03:/hadoop/
scp -r /hadoop/hadoop-2.7.3 hadoop04:/hadoop/
scp -r /hadoop/hadoop-2.7.3 hadoop05:/hadoop/
scp -r /hadoop/hadoop-2.7.3 hadoop06:/hadoop/
scp -r /hadoop/hadoop-2.7.3 hadoop07:/hadoop/
3.5 启动zookeeper集群(分别在hadoop01、hadoop02、hadoop03上启动zk)
cd /hadoop/zookeeper-3.4.9/bin/
./zkServer.sh start
#查看状态:一个leader,两个follower
./zkServer.sh status



3.6 启动journalnode(分别在hadoop01、hadoop02、hadoop03上执行)
cd /hadoop/hadoop-2.7.3/sbin
执行:hadoop-daemon.sh start journalnode
运行jps:在hadoop01、hadoop02、hadoop03上多了JournalNode进程
3.7 格式化HDFS
在hadoop04上执行:hdfs namenode -format 将生成的tmp文件拷贝给hadoop05:scp -r tmp/ hadoop05:/hadoop/hadoop2.7.3
3.8 格式化ZK(在hadoop04上执行即可)
hdfs zkfc -formatZK
3.9 启动HDFS(在hadoop04上执行)
sbin/start-dfs.sh
3.10 启动YARN(注:是在hadoop06上执行start-yarn.sh,把namenode和resourcemanager分开是因为性能问题,因为他们都要占用大量资源,
所以把他们分开了,他们分开了就要分别在不同的机器上启动)
start-yarn.sh

4. 测试
4.1 在浏览器中输入:220.192.10.13:50070
220.192.10.14:50070

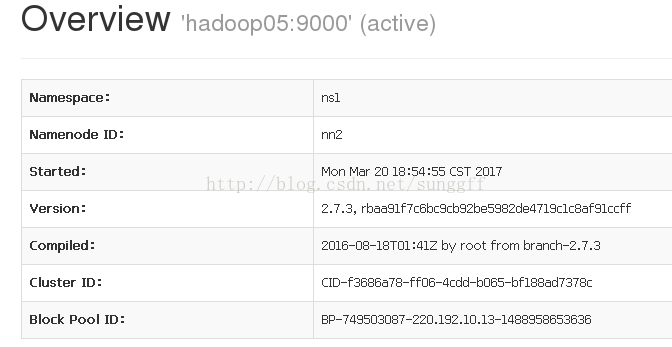
4.2 验证HDFS HA
首先向hdfs上传一个文件
hadoop fs -put /etc/profile /profile
hadoop fs -ls /
然后再kill掉active的NameNode
kill -9 2402
通过浏览器访问:220.192.10.13:50070,若状态变为active,且上传的文件还在,则说明配置正确。
将hadoop05的namenode手动启动:hadoop-daemon.sh start namenode
通过浏览器访问:220.192.10.14:50070,状态变为standby。