Shell脚本详解
一、Shell基础
1、Shell 简介
Shell 是一个 C 语言编写的脚本语言,它是用户与 Linux 的桥梁,用户输入命令交给 Shell 处理,
Shell 将相应的操作传递给内核(Kernel),内核把处理的结果输出给用户。
下面是流程示意图:

Shell 既然是工作在 Linux 内核之上,那我们也有必要了解下 Linux 相关知识。
Linux 是一套免费试用和自由传播的类 Unix 操作系统,是一个基于 POSIX 和 UNIX 的多用户、多任务、支持多线程和多 CPU 的操作系统。
1983 年 9 月 27 日,Richard Stallman(理查德-马修-斯托曼)发起 GNU 计划,它的目标是创建一套完全自由的操作系统。为保证 GNU 软件可以自由的使用、复制、修改和发布,所有的 GNU 软件都有一份在禁止其他人添加任何限制的情况下授权所有权利给任何人的协议条款,GNU 通用公共许可证(GNU General Plubic License,GPL),说白了就是不能做商业用途。
GNU 是"GNU is Not Unix"的递归缩写。UNIX 是一种广泛使用的商业操作系统的名称。
1985 年,Richard Stallman 又创立了自由软件基金会(Free Software Foundation,FSF)来为
GNU 计划提供技术、法律以及财政支持。
1990 年,GNU 计划开发主要项目有 Emacs(文本编辑器)、GCC(GNU Compiler Collection,GNU 编译器集合)、Bash 等,GCC 是一套 GNU 开发的编程语言编译器。还有开发一些 UNIX 系统的程序库和工具。
1991 年,Linuxs Torvalds(林纳斯- 托瓦兹)开发出了与 UNIX 兼容的 Linux 操作系统内核并在
GPL 条款下发布。
1992 年,Linux 与其他 GUN 软件结合,完全自由的 GUN/Linux 操作系统正式诞生,简称 Linux。
1995 年 1 月,Bob Young 创办 ACC 公司,以 GNU/Linux 为核心,开发出了 RedHat Linux 商业版。
Linux 基本思想有两点:第一,一切都是文件;第二,每个软件都有确定的用途。与 Unix 思想十分相近。
2、Shell 基本分两大类
1)图形界面 Shell(GUI Shell)
GUI 为 Unix 或者类 Unix 操作系统构造一个功能完善、操作简单以及界面友好的桌面环境。主流桌面环境有 KDE,Gnome 等。
2)命令行界面 Shell(CLI Shell)
CLI 是在用户提示符下键入可执行指令的界面,用户通过键盘输入指令,完成一系列操作。
在 Linux 系统上主流的 CLI 实现是 Bash,是许多 Linux 发行版默认的 Shell。还有许多 Unix 上
Shell,例如 tcsh、csh、ash、bsh、ksh 等。
3、第一个Shell脚本
主要讲解在大多Linux发行版下默认Bash Shell。Linux系统是RedHat下的CentOS 操作系统,完全免费。与其商业版RHEL(Red Hat Enterprise Linux)出自同样的源代码,不同的是CentOS并不包含封闭源代码软件和售后支持。
用vi打开test.sh,编写:
# vi test.sh
#!/bin/bash
echo "Hello world!"# bash test.sh
Hello world!# ll test.sh
-rw-r--r--. 1 root root 32 Aug 18 01:07 test.sh
# chmod +x test.sh
# ./test.sh
-bash: ./test.sh: Permission denied
# chmod +x test.sh
# ./test.sh # ./在当前目录
Hello world!# source test.sh
Hello world!4、Shell 变量
1)系统变量
在命令行提示符直接执行 env、set 查看系统或环境变量。env 显示用户环境变量,set 显示 Shell 预先定义好的变量以及用户变量。可以通过 export 导出成用户变量。

2)普通变量与临时环境变量
普通变量定义:
VAR=value 临时环境变量定义:
export VAR=value变量引用:
$VAR下面看下他们之间区别:

![]()
ps axjf 输出的第一列是 PPID(父进程 ID),第二列是 PID(子进程 ID)。
当 SSH 连接 Shell 时,当前终端 PPID(-bash)是 sshd 守护程序的 PID(root@pts/0),因此在
当 前终端下的所有进程的 PPID 都是-bash 的 PID,比如执行命令、运行脚本。
所以当在-bash 下设置的变量,只在-bash 进程下有效,而-bash 下的子进程 bash 是无效的,当
export 后才有效。
进一步说明:再重新连接 SSH,去除上面定义的变量测试下:

所以在当前 shell 定义的变量一定要 export,否则在写脚本时,会引用不到。
还需要注意的是退出终端后,所有用户定义的变量都会清除。 在/etc/profile 下定义的变量就是这个原理,后面会讲解 Linux 常用变量文件。
位置变量指的是函数或脚本后跟的第 n 个参数。
$1-$n,需要注意的是从第 10 个开始要用花括号调用,例如${10}。
shift 可对位置变量控制,例如:
#!/bin/bash
echo "1: $1"
shift
echo "2: $2"
shift
echo "3: $3"
# bash test.sh a b c
1: a
2: c
3:每执行一次 shift 命令,位置变量个数就会减一,而变量值则提前一位。shift n,可设置向前移动
n 位。
4)特殊变量

5) 变量引用

① 自定义变量与引用
# VAR=123
# echo $VAR
123
# VAR+=456
# echo $VAR
123456Shell 中所有变量引用使用$符,后跟变量名。
有时个别特殊字符会影响正常引用,那么需要使用${VAR},例如:
# VAR=123
# echo $VAR
123
# echo $VAR_ # Shell 允许 VAR_为变量名,所以此引用认为这是一个有效的变量名,故此返回
空# echo ${VAR}
123还有时候变量名与其他字符串紧碍着,也会误认为是整个变量:
# echo $VAR456
# echo ${VAR}456
123456② 将命令结果作为变量值
# VAR=`echo 123`
# echo $VAR
123
# VAR=$(echo 123)
# echo $VAR
1235、双引号和单引号
# VAR=1 2 3 -bash: 2: command not found
# VAR="1 2 3"
# echo $VAR
1 2 3 # VAR='1 2 3'
# echo $VAR
1 2 3看不出什么区别,再举个说明:
# N=3
# VAR="1 2 $N"
# echo $VAR
1 2 3
# VAR='1 2 $N'
# echo $VAR
1 2 $N6、注释
二、Shell字符串处理
1、获取字符串长度
# VAR='hello world!'
# echo $VAR
hello world!
# echo ${#VAR}
122、字符串切片
格式:
${parameter:offset}
${parameter:offset:length}截取从 offset 个字符开始,向后 length 个字符。
截取 hello 字符串:
# VAR='hello world!'
# echo ${VAR:0:5}
hello
截取 wo 字符:
# echo ${VAR:6:2}
wo
截取 world!字符串:
# echo ${VAR:5}
world!
截取最后一个字符:
# echo ${VAR:(-1)}
!
截取最后二个字符:
# echo ${VAR:(-2)}
d!
截取从倒数第 3 个字符后的 2 个字符:
# echo ${VAR:(-3):2}
ld3、替换字符串
格式:
${parameter/pattern/string}# VAR='hello world world!'
将第一个 world 字符串替换为 WORLD: # echo ${VAR/world/WORLD}
hello WORLD world!
将全部 world 字符串替换为 WORLD: # echo ${VAR//world/WORLD}
hello WORLD WORLD!
替换正则匹配为空: # VAR=123abc
# echo ${VAR//[^0-9]/}
123
# echo ${VAR//[0-9]/}
abc4、字符串截取
格式:
${parameter#word} # 删除匹配前缀
${parameter##word}
${parameter%word} # 删除匹配后缀
${parameter%%word}# URL="http://www.baidu.com/baike/user.html"
以//为分隔符截取右边字符串:
# echo ${URL#*//}
www.baidu.com/baike/user.html
以/为分隔符截取右边字符串:
# echo ${URL##*/}
user.html
以//为分隔符截取左边字符串:
# echo ${URL%%//*}
http:
以/为分隔符截取左边字符串:
# echo ${URL%/*}
http://www.baidu.com/baike
以.为分隔符截取左边:
# echo ${URL%.*}
http://www.baidu.com/baike/user
以.为分隔符截取右边:
# echo ${URL##*.}
html5、变量状态赋值
如果变量为空就返回 hello world!: # VAR=
# echo ${VAR:-'hello world!'}
hello world!
如果变量不为空就返回 hello world!: # VAR="hello"
# echo ${VAR:+'hello world!'}
hello world!
如果变量为空就重新赋值:
# VAR=
# echo ${VAR:=hello}
hello
# echo $VAR
hello
如果变量为空就将信息输出 stderr: # VAR=
# echo ${VAR:?value is null}
-bash: VAR: value is null6、字符串颜色

格式:
\033[1;31;40m # 1 是显示方式,可选。31 是字体颜色。40m 是字体背景颜色。
\033[0m # 恢复终端默认颜色,即取消颜色设置。示例:
#!/bin/bash
# 字体颜色
for i in {31..37}; do
echo -e "\033[$i;40mHello world!\033[0m"
done
# 背景颜色
for i in {41..47}; do
echo -e "\033[47;${i}mHello world!\033[0m"
done
# 显示方式
for i in {1..8}; do
echo -e "\033[$i;31;40mHello world!\033[0m"
done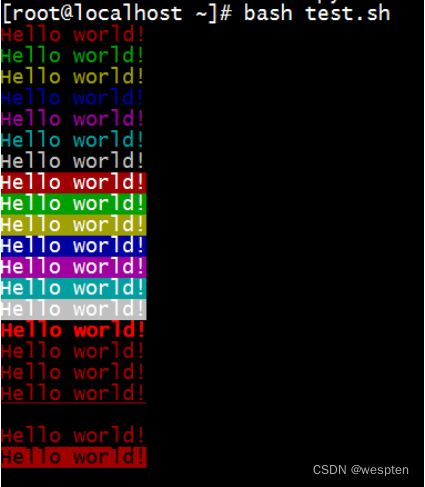
三、Shell表达式与运算符
1、条件表达式


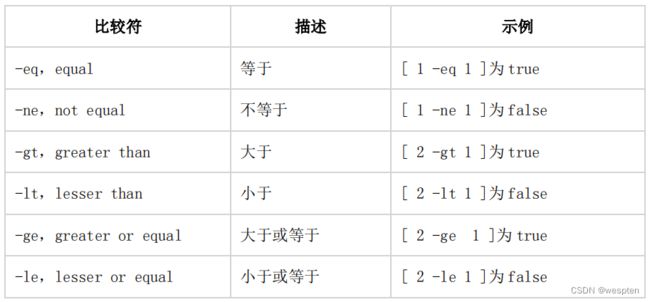
2、整数比较符
3、字符串比较符
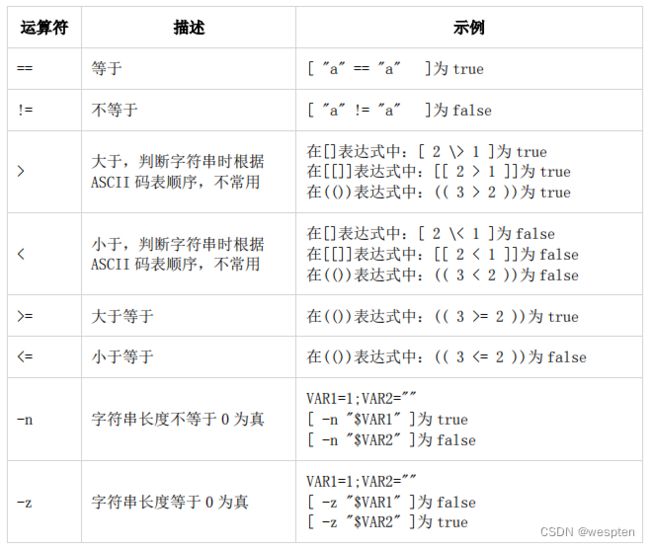

需要注意的是,使用-z 或-n 判断字符串长度时,变量要加双引号。
举例说明:
# [ -z $a ] && echo yes || echo no
yes
# [ -n $a ] && echo yes || echo no
yes
# 加了双引号才能正常判断是否为空
# [ -z "$a" ] && echo yes || echo no
yes
# [ -n "$a" ] && echo yes || echo no
no
# 使用了双中括号就不用了双引号
# [[ -n $a ]] && echo yes || echo no
no
# [[ -z $a ]] && echo yes || echo no
yes4、文件测试

5、布尔运算符

6、逻辑判断符

7、整数运算


上面两个都不支持浮点运算。
$(())表达式还有一个用途,三目运算:
# 如果条件为真返回 1,否则返回 0 # echo $((1<0))
0# echo $((1>0))
1
指定输出数字:
# echo $((1>0?1:2))
1# echo $((1<0?1:2))
2
注意:返回值不支持字符串8、其他运算工具(let/expr/bc)
除了 Shell 本身的算数运算表达式,还有几个命令支持复杂的算数运算:

由于 Shell 不支持浮点数比较,可以借助 bc 来完成需求:
# echo "1.2 < 2" |bc
1# echo "1.2 > 2" |bc
0# echo "1.2 == 2.2" |bc
0# echo "1.2 != 2.2" |bc
1
看出规律了嘛?运算如果为真返回 1,否则返回 0,写一个例子:
# [ $(echo "2.2 > 2" |bc) -eq 1 ] && echo yes || echo no
yes
# [ $(echo "2.2 < 2" |bc) -eq 1 ] && echo yes || echo no
noexpr 还可以对字符串操作,获取字符串长度:
# expr length "string"
6
截取字符串:
# expr substr "string" 4 6
ing
获取字符在字符串中出现的位置:
# expr index "string" str
1# expr index "string" i 4
获取字符串开始字符出现的长度:
# expr match "string" s.*
6# expr match "string" str
39、Shell 括号用途总结
看到这里,想一想里面所讲的小括号、中括号的用途,是不是有点懵逼了。那我们总结一下!

四、Shell流程控制
流程控制是改变程序运行顺序的指令。
1、if 语句
格式:
if list; then list; [ elif list; then list; ] ... [ else list; ] fi1)单分支
if 条件表达式; then
命令
fi#!/bin/bash
N=10
if [ $N -gt 5 ]; then
echo yes
fi
# bash test.sh
yes2)双分支
if 条件表达式; then
命令
else
命令
fi#!/bin/bash
N=10
if [ $N -lt 5 ]; then
echo yes
else
echo no
fi
# bash test.sh
no#!/bin/bash
NAME=crond
NUM=$(ps -ef |grep $NAME |grep -vc grep)
if [ $NUM -eq 1 ]; then
echo "$NAME running."
else
echo "$NAME is not running!"
fi#!/bin/bash
if ping -c 1 192.168.1.1 >/dev/null; then
echo "OK."
else
echo "NO!"
fiif 语句可以直接对命令状态进行判断,就省去了获取$?这一步!
3)多分支
if 条件表达式; then
命令
elif 条件表达式; then
命令
else
命令
fi#!/bin/bash
N=$1
if [ $N -eq 3 ]; then
echo "eq 3"
elif [ $N -eq 5 ]; then
echo "eq 5"
elif [ $N -eq 8 ]; then
echo "eq 8"
else
echo "no"
fi如果第一个条件符合就不再向下匹配。
示例 2:根据 Linux 不同发行版使用不同的命令安装软件
#!/bin/bash
if [ -e /etc/redhat-release ]; then
yum install wget -y
elif [ $(cat /etc/issue |cut -d' ' -f1) == "Ubuntu" ]; then
apt-get install wget -y
else
Operating system does not support.
exit
fi2、for 语句
格式:
for name [ [ in [ word ... ] ] ; ] do list ; donefor 变量名 in 取值列表; do
命令
done示例:
#!/bin/bash
for i in {1..3}; do
echo $i
done
# bash test.sh
1
2
3for 的语法也可以这么写:
#!/bin/bash
for i in "$@"; { # $@是将位置参数作为单个来处理
echo $i
}# bash test.sh 1 2 3
1
2
3#!/bin/bash
for i in 12 34; do
echo $i
done
# bash test.sh
12
34如果想指定分隔符,可以重新赋值$IFS 变量:
#!/bin/bash
OLD_IFS=$IFS
IFS=":"
for i in $(head -1 /etc/passwd); do
echo $i
done
IFS=$OLD_IFS # 恢复默认值
# bash test.sh
root
x
00
root
/root
/bin/bashfor (( expr1 ; expr2 ; expr3 )) ; do list ; done#!/bin/bash
for ((i=1;i<=5;i++)); do # 也可以 i--
echo $i
done#!/bin/bash
for ip in 192.168.1.{1..254}; do
if ping -c 1 $ip >/dev/null; then
echo "$ip OK."
else
echo "$ip NO!"
fi
done#!/bin/bash
URL="www.baidu.com www.sina.com www.jd.com"
for url in $URL; do
HTTP_CODE=$(curl -o /dev/null -s -w %{http_code} http://$url)
if [ $HTTP_CODE -eq 200 -o $HTTP_CODE -eq 301 ]; then
echo "$url OK."
else
echo "$url NO!"
fi
done3、while 语句
格式:
while list; do list; donewhile 条件表达式; do
命令
done#!/bin/bash
N=0
while [ $N -lt 5 ]; do
let N++
echo $N
done
# bash test.sh
1
2
3
4
5#!/bin/bash
while [ 1 -eq 1 ]; do
echo "yes"
done也可以条件表达式直接用 true:
#!/bin/bash
while true; do
echo "yes"
done还可以条件表达式用冒号,冒号在 Shell 中的意思是不做任何操作。但状态是 0,因此为 true:
#!/bin/bash
while :; do
echo "yes"
done# cat a.txt
a b c
1 2 3
x y z#!/bin/bash
cat ./a.txt | while read LINE; do
echo $LINE
done#!/bin/bash
while read LINE; do
echo $LINE
done < ./a.txt#!/bin/bash
exec < ./a.txt # 读取文件作为标准输出
while read LINE; do
echo $LINE
done4、break 和 continue 语句
break 是终止循环。
#!/bin/bash
N=0
while true; do
let N++
if [ $N -eq 5 ]; then
break
fi
echo $N
done
# bash test.sh
1
2
3
4#!/bin/bash
N=0
while [ $N -lt 5 ]; do
let N++
if [ $N -eq 3 ]; then
continue
fi
echo $N
done
# bash test.sh
1
2
4
5当变量 N 等于 3 时,continue 跳过了当前循环,没有执行下面的 echo。
注意:continue 与 break 语句只能循环语句中使用。
5、case 语句
格式:
case word in [ [(] pattern [ | pattern ] ... ) list ;; ] ... esac
case 模式名 in
模式 1)
命令
;;
模式 2)
命令
;;
*)
不符合以上模式执行的命令
esac#!/bin/bash
case $1 in
start)
echo "start."
;;
stop)
echo "stop."
;;
restart)
echo "restart."
;;
*)
echo "Usage: $0 {start|stop|restart}"
esac
# bash test.sh
Usage: test.sh {start|stop|restart}
# bash test.sh start
start.
# bash test.sh stop
stop.
# bash test.sh restart
restart.#!/bin/bash
case $1 in
[0-9])
echo "match number."
;;
[a-z])
echo "match letter."
;;
'-h'|'--help')
echo "help"
;;
*)
echo "Input error!"
exit
esac
# bash test.sh 1
match number.
# bash test.sh a
match letter.
# bash test.sh -h
help
# bash test.sh --help
help6、select 语句
格式:
select name [ in word ] ; do list ; doneselect 变量 in 选项 1 选项 2; do
break
done#!/bin/bash
select mysql_version in 5.1 5.6; do
echo $mysql_version
done
# bash test.sh
1) 5.1
2) 5.6
#? 1
5.1
#? 2
5.6#!/bin/bash
while true; do
select mysql_version in 5.1 5.6; do
echo $mysql_version
break
done
done
# bash test.sh
1) 5.1
2) 5.6
#? 1
5.1
1) 5.1
2) 5.6
#? 2
5.6
1) 5.1
2) 5.6句就简单多了。
#!/bin/bash
PS3="Select a number: "
while true; do
select mysql_version in 5.1 5.6 quit; do
case $mysql_version in
5.1)
echo "mysql 5.1"
break
;;
5.6)
echo "mysql 5.6"
break
;;
quit)
exit
;;
*)
echo "Input error, Please enter again!"
break
esac
done
done
# bash test.sh
1) 5.1
2) 5.6
3) quit
Select a number: 1
mysql 5.1
1) 5.1
2) 5.6
3) quit
Select a number: 2
mysql 5.6
1) 5.1
2) 5.6
3) quit
Select a number: 3五、Shell函数与数组
1、函数
格式:
func() {
command
}#!/bin/bash
func() {
echo "This is a function."
}
func
# bash test.sh
This is a function.Shell 函数很简单,函数名后跟双括号,再跟双大括号。通过函数名直接调用,不加小括号。
示例 2:函数返回值
#!/bin/bash
func() {
VAR=$((1+1))
return $VAR
echo "This is a function."
}
func
echo $?
# bash test.sh
2#!/bin/bash
func() {
echo "Hello $1"
}
func world
# bash test.sh
Hello world通过 Shell 位置参数给函数传参。
函数也支持递归调用,也就是自己调用自己。
例如:
#!/bin/bash
test() {
echo $1
sleep 1
test hello
}
test执行会一直在调用本身打印 hello,这就形成了闭环。
像经典的 fork 炸弹就是函数递归调用:
:(){ :|:& };: 或 .(){.|.&};.这样看起来不好理解,我们更改下格式:
:() {
:|:&
};
:bomb() {
bomb|bomb&
};
bomb分析下:
:(){ } 定义一个函数,函数名是冒号。
: 调用自身函数
| 管道符
: 再一次递归调用自身函数
:|: 表示每次调用函数":"的时候就会生成两份拷贝。
& 放到后台
; 分号是继续执行下一个命令,可以理解为换行。
: 最后一个冒号是调用函数。
因此不断生成新进程,直到系统资源崩溃。
一般递归函数用的也少,了解下即可!
2、数组
格式:
array=(元素 1 元素 2 元素 3 ...)用小括号初始化数组,元素之间用空格分隔。
array=(a b c)定义方法 2:新建数组并添加元素
array[下标]=元素定义方法 3:将命令输出作为数组元素
array=($(command))数组操作:
获取所有元素: # echo ${array[*]} # *和@ 都是代表所有元素
a b c
获取元素下标: # echo ${!a[@]}
0 1 2
获取数组长度: # echo ${#array[*]}
3
获取第一个元素: # echo ${array[0]}
a
获取第二个元素: # echo ${array[1]}
b
获取第三个元素: # echo ${array[2]}
c
添加元素: # array[3]=d
# echo ${array[*]}
a b c d
添加多个元素: # array+=(e f g)
# echo ${array[*]}
a b c d e f g
删除第一个元素: # unset array[0] # 删除会保留元素下标
# echo ${array[*]}
b c d e f g
删除数组: # unset array#!/bin/bash
for i in $(seq 1 10); do
array[a]=$i
let a++
done
echo ${array[*]}
# bash test.sh
1 2 3 4 5 6 7 8 9 10方法 1:
#!/bin/bash
IP=(192.168.1.1 192.168.1.2 192.168.1.3)
for ((i=0;i<${#IP[*]};i++)); do
echo ${IP[$i]}
done
# bash test.sh
192.168.1.1
192.168.1.2
192.168.1.3方法 2:
#!/bin/bash
IP=(192.168.1.1 192.168.1.2 192.168.1.3)
for IP in ${IP[*]}; do
echo $IP
done六、Shell正则表达式
正则表达式在每种语言中都会有,功能就是匹配符合你预期要求的字符串。
Shell 正则表达式分为两种:
基础正则表达式:BRE(basic regular express)
扩展正则表达式:ERE(extend regular express),扩展的表达式有+、?、|和()
下面是一些常用的正则表达式符号,我们先拿 grep 工具举例说明。
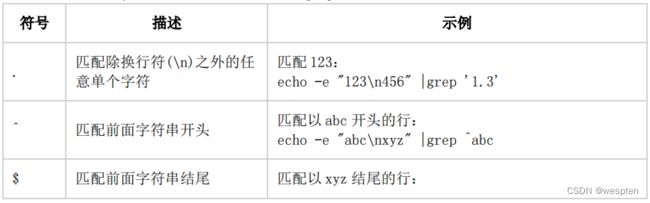

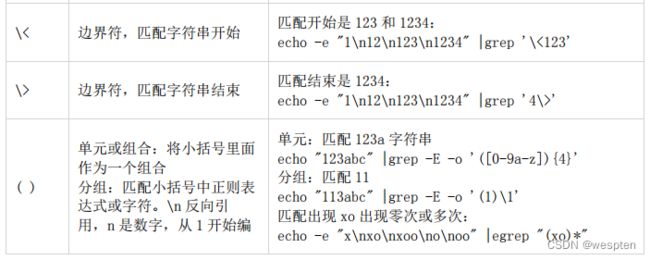


示例:
echo -e "1\n12\n123\n1234a" |grep '[[:digit:]]'在 Shell 下使用这些正则表达式处理文本最多的命令有下面几个工具:




七、Shell文本处理三剑客
1、grep
过滤来自一个文件或标准输入匹配模式内容。
除了 grep 外,还有 egrep、fgrep。egrep 是 grep 的扩展,相当于 grep -E。fgrep 相当于 grep - f,用的少。
Usage: grep [OPTION]... PATTERN [FILE]...



示例:
1)输出 b 文件中在 a 文件相同的行
# grep -f a b# grep -v -f a b# echo "a bc de" |xargs -n1 |grep -e 'a' -e 'bc'
a
bc# grep -E -v "^$|^#" /etc/httpd/conf/httpd.conf# echo "A a b c" |xargs -n1 |grep -i a
或
# echo "A a b c" |xargs -n1 |grep '[Aa]'
A
a6)只显示匹配的字符串
# echo "this is a test" |grep -o 'is'
is
is7)输出匹配的前五个结果
# seq 1 20 |grep -m 5 -E '[0-9]{2}'
10
11
12
13
148)统计匹配多少行
# seq 1 20 |grep -c -E '[0-9]{2}'
11# echo "a bc de" |xargs -n1 |grep '^b'
bc# echo "a ab abc abcd abcde" |xargs -n1 |grep -n 'de$'
5:abcde11) 递归搜索/etc 目录下包含 ip 的 conf 后缀文件
# grep -r '192.167.1.1' /etc --include *.conf12) 排除搜索 bak 后缀的文件
# grep -r '192.167.1.1' /opt --exclude *.bak13) 排除来自 file 中的文件
# grep -r '192.167.1.1' /opt --exclude-from file# seq 41 45 |grep -E '4[12]'
41
4215) 匹配至少 2 个字符
# seq 13 |grep -E '[0-9]{2}'
10
11
12
1316) 匹配至少 2 个字符的单词,最多 3 个字符的单词
# echo "a ab abc abcd abcde" |xargs -n1 |grep -E -w -o '[a-z]{2,3}'
ab
abc# ifconfig |grep -E -o "[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}"18) 打印匹配结果及后 3 行
# seq 1 10 |grep 5 -A 3
5
6
7
8
19) 打印匹配结果及前 3 行
# seq 1 10 |grep 5 -B 3
2
3
4
520) 打印匹配结果及前后 3 行
# seq 1 10 |grep 5 -C 3
2
3
4
5
6
7
821) 不显示输出
不显示错误输出:
# grep 'a' abc
grep: abc: No such file or directory
# grep -s 'a' abc
# echo $?
2
不显示正常输出:
# grep -q 'a' a.txt2、sed
间。然后再将下一行读入模式空间进行处理输出,以此类推,直到最后一行。还有一个空间叫保持空间,又称暂存空间,可以暂时存放一些处理的数据,但不能直接输出,只能放到模式空间输出。
这两个空间其实就是在内存中初始化的一个内存区域,存放正在处理的数据和临时存放的数据。
Usage:
sed [OPTION]... {script-only-if-no-other-script} [input-file]...
sed [选项] '地址 命令' file


借助以下文本内容作为示例讲解:
# tail /etc/services
nimgtw 48003/udp # Nimbus Gateway
3gpp-cbsp 48049/tcp # 3GPP Cell Broadcast Service Protocol
isnetserv 48128/tcp # Image Systems Network Services
isnetserv 48128/udp # Image Systems Network Services
blp5 48129/tcp # Bloomberg locator
blp5 48129/udp # Bloomberg locator
com-bardac-dw 48556/tcp # com-bardac-dw
com-bardac-dw 48556/udp # com-bardac-dw
iqobject 48619/tcp # iqobject
iqobject 48619/udp # iqobject① 匹配打印(p)
1)打印匹配 blp5 开头的行
# tail /etc/services |sed -n '/^blp5/p'
blp5 48129/tcp # Bloomberg locator
blp5 48129/udp # Bloomberg locator2)打印第一行
# tail /etc/services |sed -n '1p'
nimgtw 48003/udp # Nimbus Gateway3)打印第一行至第三行
# tail /etc/services |sed -n '1,3p'
nimgtw 48003/udp # Nimbus Gateway
3gpp-cbsp 48049/tcp # 3GPP Cell Broadcast Service Protocol
isnetserv 48128/tcp # Image Systems Network Services4)打印奇数行
# seq 10 |sed -n '1~2p'
1
3
5
7
95)打印匹配行及后一行
# tail /etc/services |sed -n '/blp5/,+1p'
blp5 48129/tcp # Bloomberg locator
blp5 48129/udp # Bloomberg locator6)打印最后一行
# tail /etc/services |sed -n '$p'
iqobject 48619/udp # iqobject7)不打印最后一行
# tail /etc/services |sed -n '$!p'
3gpp-cbsp 48049/tcp # 3GPP Cell Broadcast Service
Protocol
isnetserv 48128/tcp # Image Systems Network Services
isnetserv 48128/udp # Image Systems Network Services
blp5 48129/tcp # Bloomberg locator
blp5 48129/udp # Bloomberg locator
com-bardac-dw 48556/tcp # com-bardac-dw
com-bardac-dw 48556/udp # com-bardac-dw
iqobject 48619/tcp # iqobject
iqobject 48619/udp # iqobject感叹号也就是对后面的命令取反。
8)匹配范围
# tail /etc/services |sed -n '/^blp5/,/^com/p'
blp5 48129/tcp # Bloomberg locator
blp5 48129/udp # Bloomberg locator
com-bardac-dw 48556/tcp # com-bardac-dw# tail /etc/services |sed -n '/blp5/,$p'
blp5 48129/tcp # Bloomberg locator
blp5 48129/udp # Bloomberg locator
com-bardac-dw 48556/tcp # com-bardac-dw
com-bardac-dw 48556/udp # com-bardac-dw
iqobject 48619/tcp # iqobject
iqobject 48619/udp # iqobject以逗号分开两个样式选择某个范围。
9)引用系统变量,用引号
# a=1
# tail /etc/services |sed -n ''$a',3p'
或
# tail /etc/services |sed -n "$a,3p"sed 命令用单引号时,里面变量用单引号引起来,或者 sed 命令用双引号,因为双引号解释特殊符
号原有意义。
② 匹配删除(d)
# tail /etc/services |sed '/blp5/d'
nimgtw 48003/udp # Nimbus Gateway
3gpp-cbsp 48049/tcp # 3GPP Cell Broadcast Service
isnetserv 48128/tcp # Image Systems Network Services
isnetserv 48128/udp # Image Systems Network Services
com-bardac-dw 48556/tcp # com-bardac-dw
com-bardac-dw 48556/udp # com-bardac-dw
iqobject 48619/tcp # iqobject
iqobject 48619/udp # iqobject
# tail /etc/services |sed '1d'
3gpp-cbsp 48049/tcp # 3GPP Cell Broadcast Service
Protocol
isnetserv 48128/tcp # Image Systems Network Services
isnetserv 48128/udp # Image Systems Network Services
blp5 48129/tcp # Bloomberg locator
blp5 48129/udp # Bloomberg locator
com-bardac-dw 48556/tcp # com-bardac-dw
com-bardac-dw 48556/udp # com-bardac-dw
iqobject 48619/tcp # iqobject
iqobject 48619/udp # iqobject
# tail /etc/services |sed '1~2d'
3gpp-cbsp 48049/tcp # 3GPP Cell Broadcast Service
isnetserv 48128/udp # Image Systems Network Services
blp5 48129/udp # Bloomberg locator
com-bardac-dw 48556/udp # com-bardac-dw
iqobject 48619/udp # iqobject
# tail /etc/services |sed '1,3d'
isnetserv 48128/udp # Image Systems Network Services
blp5 48129/tcp # Bloomberg locator
blp5 48129/udp # Bloomberg locator
com-bardac-dw 48556/tcp # com-bardac-dw
com-bardac-dw 48556/udp # com-bardac-dw
iqobject 48619/tcp # iqobject
iqobject 48619/udp # iqobject去除空格 http.conf 文件空行或开头#号的行:
# sed '/^#/d;/^$/d' /etc/httpd/conf/httpd.conf③ 替换(s///)
# tail /etc/services |sed 's/blp5/test/'
3gpp-cbsp 48049/tcp # 3GPP Cell Broadcast Service
isnetserv 48128/tcp # Image Systems Network Services
isnetserv 48128/udp # Image Systems Network Services
test 48129/tcp # Bloomberg locator
test 48129/udp # Bloomberg locator
com-bardac-dw 48556/tcp # com-bardac-dw
com-bardac-dw 48556/udp # com-bardac-dw
iqobject 48619/tcp # iqobject
iqobject 48619/udp # iqobject
matahari 49000/tcp # Matahari Broker
全局替换加 g: # tail /etc/services |sed 's/blp5/test/g'# tail /etc/services |sed -n 's/^blp5/test/p'
test 48129/tcp # Bloomberg locator
test 48129/udp # Bloomberg locator# tail /etc/services |sed 's/48049/&.0/'
3gpp-cbsp 48049.0/tcp # 3GPP Cell Broadcast Service
isnetserv 48128/tcp # Image Systems Network Services
isnetserv 48128/udp # Image Systems Network Services
blp5 48129/tcp # Bloomberg locator
blp5 48129/udp # Bloomberg locator
com-bardac-dw 48556/tcp # com-bardac-dw
com-bardac-dw 48556/udp # com-bardac-dw
iqobject 48619/tcp # iqobject
iqobject 48619/udp # iqobject
matahari 49000/tcp # Matahari BrokerIP 加单引号:
# echo '10.10.10.1 10.10.10.2 10.10.10.3' |sed -r 's/[^ ]+/"&"/g'
"10.10.10.1" "10.10.10.2" "10.10.10.3"# tail /etc/services | sed '1,4s/blp5/test/'
3gpp-cbsp 48049/tcp # 3GPP Cell Broadcast Service
isnetserv 48128/tcp # Image Systems Network Services
isnetserv 48128/udp # Image Systems Network Services
test 48129/tcp # Bloomberg locator
blp5 48129/udp # Bloomberg locator
com-bardac-dw 48556/tcp # com-bardac-dw
com-bardac-dw 48556/udp # com-bardac-dw
iqobject 48619/tcp # iqobject
iqobject 48619/udp # iqobject
matahari 49000/tcp # Matahari Broker5)对匹配行进行替换
# tail /etc/services | sed '/48129\/tcp/s/blp5/test/'
3gpp-cbsp 48049/tcp # 3GPP Cell Broadcast Service
isnetserv 48128/tcp # Image Systems Network Services
isnetserv 48128/udp # Image Systems Network Services
test 48129/tcp # Bloomberg locator
blp5 48129/udp # Bloomberg locator
com-bardac-dw 48556/tcp # com-bardac-dw
com-bardac-dw 48556/udp # com-bardac-dw
iqobject 48619/tcp # iqobject
iqobject 48619/udp # iqobject
matahari 49000/tcp # Matahari Broker# tail /etc/services |sed 's/blp5/test/;s/3g/4g/'
4gpp-cbsp 48049/tcp # 3GPP Cell Broadcast Service
isnetserv 48128/tcp # Image Systems Network Services
isnetserv 48128/udp # Image Systems Network Services
test 48129/tcp # Bloomberg locator
test 48129/udp # Bloomberg locator
com-bardac-dw 48556/tcp # com-bardac-dw
com-bardac-dw 48556/udp # com-bardac-dw
iqobject 48619/tcp # iqobject
iqobject 48619/udp # iqobject
matahari 49000/tcp # Matahari Broker# tail /etc/services |sed -r 's/(.*) (.*)(#.*)/\1\2test \3/'
3gpp-cbsp 48049/tcp test # 3GPP Cell Broadcast Service
isnetserv 48128/tcp test # Image Systems Network Services
isnetserv 48128/udp test # Image Systems Network Services
blp5 48129/tcp test # Bloomberg locator
blp5 48129/udp test # Bloomberg locator
com-bardac-dw 48556/tcp test # com-bardac-dw
com-bardac-dw 48556/udp test # com-bardac-dw
iqobject 48619/tcp test # iqobject
iqobject 48619/udp test # iqobject
matahari 49000/tcp test # Matahari Broker第一列是第一个小括号匹配,第二列第二个小括号匹配,第三列一样。将不变的字符串匹配分组,
再通过\数字按分组顺序反向引用。
8)将协议与端口号位置调换
# tail /etc/services |sed -r 's/(.*)(\<[0-9]+\>)\/(tcp|udp)(.*)/\1\3\/\2\4/'
3gpp-cbsp tcp/48049 # 3GPP Cell Broadcast Service
isnetserv tcp/48128 # Image Systems Network Services
isnetserv udp/48128 # Image Systems Network Services
blp5 tcp/48129 # Bloomberg locator
blp5 udp/48129 # Bloomberg locator
com-bardac-dw tcp/48556 # com-bardac-dw
com-bardac-dw udp/48556 # com-bardac-dw
iqobject tcp/48619 # iqobject
iqobject udp/48619 # iqobject
matahari tcp/49000 # Matahari Broker9)位置调换
替换 x 字符为大写: # echo "abc cde xyz" |sed -r 's/(.*)x/\1X/'
abc cde Xyz
456 与 cde 调换: # echo "abc:cde;123:456" |sed -r 's/([^:]+)(;.*:)([^:]+$)/\3\2\1/'
abc:456;123:cde10)注释匹配行后的多少行
# seq 10 |sed '/5/,+3s/^/#/'
1
2
3
4
#5
#6
#7
#8
9
1011)注释指定多行
# seq 5 |sed -r 's/^3|^4/&#/'
1
2
3#
4#
5# seq 5 |sed -r '/^3|^4/s/^/#/'
1
2
#3
#4
5# seq 5 |sed -r 's/^3|^4/#\0/'
1
2
#3
#4
512)去除开头和结尾空格或制表符
# echo " 1 2 3 " |sed 's/^[ \t]*//;s/[ \t]*$//'
1 2 3④ 多重编辑(-e)
# tail /etc/services |sed -e '1,2d' -e 's/blp5/test/'
isnetserv 48128/udp # Image Systems Network Services
test 48129/tcp # Bloomberg locator
test 48129/udp # Bloomberg locator
com-bardac-dw 48556/tcp # com-bardac-dw
com-bardac-dw 48556/udp # com-bardac-dw
iqobject 48619/tcp # iqobject
iqobject 48619/udp # iqobject
matahari 49000/tcp # Matahari Broker也可以使用分号分隔:
# tail /etc/services |sed '1,2d;s/blp5/test/'⑤ 添加新内容(a、i 和 c)
# tail /etc/services |sed '/blp5/i \test'
3gpp-cbsp 48049/tcp # 3GPP Cell Broadcast Service
isnetserv 48128/tcp # Image Systems Network Services
isnetserv 48128/udp # Image Systems Network Services
test
blp5 48129/tcp # Bloomberg locator
test
blp5 48129/udp # Bloomberg locator
com-bardac-dw 48556/tcp # com-bardac-dw
com-bardac-dw 48556/udp # com-bardac-dw
iqobject 48619/tcp # iqobject
iqobject 48619/udp # iqobject
matahari 49000/tcp # Matahari Broker# tail /etc/services |sed '/blp5/a \test'
3gpp-cbsp 48049/tcp # 3GPP Cell Broadcast Service
isnetserv 48128/tcp # Image Systems Network Services
isnetserv 48128/udp # Image Systems Network Services
blp5 48129/tcp # Bloomberg locator
test
blp5 48129/udp # Bloomberg locator
test
com-bardac-dw 48556/tcp # com-bardac-dw
com-bardac-dw 48556/udp # com-bardac-dw
iqobject 48619/tcp # iqobject
iqobject 48619/udp # iqobject
matahari 49000/tcp # Matahari Broker# tail /etc/services |sed '/blp5/c \test'
3gpp-cbsp 48049/tcp # 3GPP Cell Broadcast Service
isnetserv 48128/tcp # Image Systems Network Services
isnetserv 48128/udp # Image Systems Network Services
test
test
com-bardac-dw 48556/tcp # com-bardac-dw
com-bardac-dw 48556/udp # com-bardac-dw
iqobject 48619/tcp # iqobject
iqobject 48619/udp # iqobject
matahari 49000/tcp # Matahari Broker4)在指定行下一行添加一行
# tail /etc/services |sed '2a \test'
3gpp-cbsp 48049/tcp # 3GPP Cell Broadcast Service
isnetserv 48128/tcp # Image Systems Network Services
test
isnetserv 48128/udp # Image Systems Network Services
blp5 48129/tcp # Bloomberg locator
blp5 48129/udp # Bloomberg locator
com-bardac-dw 48556/tcp # com-bardac-dw
com-bardac-dw 48556/udp # com-bardac-dw
iqobject 48619/tcp # iqobject
iqobject 48619/udp # iqobject
matahari 49000/tcp # Matahari Broker5)在指定行前面和后面添加一行
# seq 5 |sed '3s/.*/txt\n&/'
1
2
txt
3
4
5
# seq 5 |sed '3s/.*/&\ntxt/'
1
2
3
txt
4
5⑥ 读取文件并追加到匹配行后(r)
# cat a.txt
123
456
# tail /etc/services |sed '/blp5/r a.txt'
3gpp-cbsp 48049/tcp # 3GPP Cell Broadcast Service
isnetserv 48128/tcp # Image Systems Network Services
isnetserv 48128/udp # Image Systems Network Services
blp5 48129/tcp # Bloomberg locator
123
456
blp5 48129/udp # Bloomberg locator
123
456
com-bardac-dw 48556/tcp # com-bardac-dw
com-bardac-dw 48556/udp # com-bardac-dw
iqobject 48619/tcp # iqobject
iqobject 48619/udp # iqobject
matahari 49000/tcp # Matahari Broker⑦ 将匹配行写到文件(w)
# tail /etc/services |sed '/blp5/w b.txt'
3gpp-cbsp 48049/tcp # 3GPP Cell Broadcast Service
isnetserv 48128/tcp # Image Systems Network Services
isnetserv 48128/udp # Image Systems Network Services
blp5 48129/tcp # Bloomberg locator
blp5 48129/udp # Bloomberg locator
com-bardac-dw 48556/tcp # com-bardac-dw
com-bardac-dw 48556/udp # com-bardac-dw
iqobject 48619/tcp # iqobject
iqobject 48619/udp # iqobject
matahari 49000/tcp # Matahari Broker
# cat b.txt
blp5 48129/tcp # Bloomberg locator
blp5 48129/udp # Bloomberg locator⑧ 读取下一行(n 和 N)
# seq 5 |sed -n '/3/{n;p}'
4# seq 6 |sed -n 'n;p'
2
4
6sed 先读取第一行 1,执行 n 命令,获取下一行 2,此时模式空间是 2,执行 p 命令,打印模式空
间。 现在模式空间是 2,sed 再读取 3,执行 n 命令,获取下一行 4,此时模式空间为 4,执行 p 命令,以此类推。
3)打印奇数
# seq 6 |sed 'n;d'
1
3
5sed 先读取第一行 1,此时模式空间是 1,并打印模式空间 1,执行 n 命令,获取下一行 2,执行 d命令,删除模式空间的 2,sed 再读取 3,此时模式空间是 3,并打印模式空间,再执行 n 命令,获取下一行 4,执行 d 命令,删除模式空间的 3,以此类推。
# seq 6 |sed -n 'p;n'
1
3
5# seq 6 |sed 'n;n;p'
1
2
3
3
4
5
6
6sed 先读取第一行 1,并打印模式空间 1,执行 n 命令,获取下一行 2,并打印模式空间 2,再执行 n命令,获取下一行 3,执行 p 命令,打印模式空间 3。sed 读取下一行 3,并打印模式空间 3,以此类推。
5)每三行替换一次
方法 1:
# seq 6 |sed 'n;n;s/^/=/;s/$/=/'
1
2
=3=
4
5
=6=我们只是把 p 命令改成了替换命令。
方法 2:
这次用到了地址匹配,来实现上面的效果:
# seq 6 |sed '3~3{s/^/=/;s/$/=/}'
1
2
=3=
4
5
=6=# seq 6 |sed 'N;q'
1
2
将两行合并一行:
# seq 6 |sed 'N;s/\n//'
12
34
56# seq 5 |sed -n 'N;p'
1
2
3
4
# seq 6 |sed -n 'N;p'
1
2
3
4
5
6为什么第一个不打印 5 呢?
因为 N 命令是读取下一行追加到 sed 读取的当前行,当 N 读取下一行没有内容时,则退出,也不会执行 p 命令打印当前行。
当行数为偶数时,N 始终就能读到下一行,所以也会执行 p 命令。
7)打印奇数行数时的最后一行
# seq 5 |sed -n '$!N;p'
1
2
3
4
5
⑨ 打印和删除模式空间第一行(P 和 D)
# seq 6 |sed -n 'N;P'
1
3
52)保留最后一行
# seq 6 |sed 'N;D'
6⑩ 保持空间操作(h 与 H、g 与 G 和 x)
# seq 6 |sed -e '/3/{h;d}' -e '/5/g'
1
2
4
3
6# seq 6 |sed -e '/3/{h;d}' -e '$G'
1
2
4
5
6
33)交换模式空间和保持空间
# seq 6 |sed -e '/3/{h;d}' -e '/5/x' -e '$G'
1
2
4
3
6
5# seq 5 |sed '1!G;h;$!d'
5
4
3
2
1分析下:
1!G 第一行不执行把保持空间内容追加到模式空间,因为现在保持空间还没有数据。
h 将模式空间放到保持空间暂存。
$!d 最后一行不执行删除模式空间的内容。
读取第一行 1 时,跳过 G 命令,执行 h 命令将模式空间 1 复制到保持空间,执行 d 命令删除模式空间的 1。
读取第二行 2 时,模式空间是 2,执行 G 命令,将保持空间 1 追加到模式空间,此时模式空间是
2\n1,执行 h 命令将 2\n1 覆盖到保持空间,d 删除模式空间。
读取第三行 3 时,模式空间是 3,执行 G 命令,将保持空间 2\n1 追加到模式空间,此时模式空间是3\n2\n1,执行 h 命令将模式空间内容复制到保持空间,d 删除模式空间。
以此类推,读到第 5 行时,模式空间是 5,执行 G 命令,将保持空间的 4\n3\n2\n1 追加模式空间,然后复制到模式空间,5\n4\n3\n2\n1,不执行 d,模式空间保留,输出。
由此可见,每次读取的行先放到模式空间,再复制到保持空间,d 命令删除模式空间内容,防止输
出,再追加到模式空间,因为追加到模式空间,会追加到新读取的一行的后面,循环这样操作, 就把所有行一行行追加到新读取行的后面,就形成了倒叙。
5)每行后面添加新空行
# seq 10 |sed G
1
2
3
4
56)打印匹配行的上一行内容
# seq 5 |sed -n '/3/{x;p};h'
2读取第一行 1,没有匹配到 3,不执行{x;p},执行 h 命令将模式空间内容 1 覆盖到保持空间。
读取第二行 2,没有匹配到 3,不执行{x;p},执行 h 命令将模式空间内容 2 覆盖到保持空间。
读取第三行 3,匹配到 3,执行 x 命令把模式空间 3 与保持空间 2 交换,再执行 p 打印模式空间 2
以此类推。
7)打印匹配行到最后一行或下一行到最后一行
# seq 5 |sed -n '/3/,$p'
3
4
5
# seq 5 |sed -n '/3/,${h;x;p}'
3
4
5
# seq 5 |sed -n '/3/{:a;N;$!ba;p}'
3
4
5
# seq 5 |sed -n '/3/{n;:a;N;$!ba;p}'
4
5匹配到 3 时,n 读取下一行 4,此时模式空间是 4,执行 N 命令读取下一行并追加到模式空间,此时模式空间是 4\n5,标签循环完成后打印模式空间 4\n5。
⑪ 标签(:、b 和 t)
标签可以控制流,实现分支判断。
: lable name 定义标签
b lable 跳转到指定标签,如果没有标签则到脚本末尾
t lable 跳转到指定标签,前提是 s///命令执行成功
1)将换行符替换成逗号
方法 1:
# seq 6 |sed 'N;s/\n/,/'
1,2
3,4
5,6这种方式并不能满足我们的需求,每次 sed 读取到模式空间再打印是新行,替换\n 也只能对 N 命令追加后的 1\n2 这样替换。
这时就可以用到标签了:
# seq 6 |sed ':a;N;s/\n/,/;b a'
1,2,3,4,5,6看看这里的标签使用,:a 是定义的标签名,b a 是跳转到 a 位置。
sed 读取第一行 1,N 命令读取下一行 2,此时模式空间是 1\n2$,执行替换,此时模式空间是
1,2$,执行 b 命令再跳转到标签 a 位置继续执行 N 命令,读取下一行 3 追加到模式空间,此时模式空间是 1,2\n3$,再替换,以此类推,不断追加替换,直到最后一行 N 读不到下一行内容退出。
方法 2:
# seq 6 |sed ':a;N;$!b a;s/\n/,/g'
1,2,3,4,5,6# seq 6 |sed ':a;N;b a;s/\n/,/g'
1
2
3
4
5
6# echo "123456789" |sed -r 's/([0-9]+)([0-9]+{3})/\1,\2/'
123456,789
# echo "123456789" |sed -r ':a;s/([0-9]+)([0-9]+{3})/\1,\2/;t a'
123,456,789
# echo "123456789" |sed -r ':a;s/([0-9]+)([0-9]+{2})/\1,\2/;t a'
1,23,45,67,89执行第一次时,替换最后一个,跳转后,再对 123456 匹配替换,直到匹配替换不成功,不执行 t 命令。
⑫ 忽略大小写匹配(I)
# echo -e "a\nA\nb\nc" |sed 's/a/1/Ig'
1
1
b
c⑬ 获取总行数(#)
# seq 10 |sed -n '$='3、awk
awk 是一个处理文本的编程语言工具,能用简短的程序处理标准输入或文件、数据排序、计算以及
生成报表等等。
在 Linux 系统下默认 awk 是 gawk,它是 awk 的 GNU 版本。可以通过命令查看应用的版本:
ls -l /bin/awk基本的命令语法:
awk option 'pattern {action}' file其中 pattern 表示 AWK 在数据中查找的内容,而 action 是在找到匹配内容时所执行的一系列命令,花括号用于根据特定的模式对一系列指令进行分组。
awk 处理的工作方式与数据库类似,支持对记录和字段处理,这也是 grep 和 sed 不能实现的。
在 awk 中,缺省的情况下将文本文件中的一行视为一个记录,逐行放到内存中处理,而将一行中的某一部分作为记录中的一个字段。用 1,2,3...数字的方式顺序的表示行(记录)中的不同字段。用$后跟数字,引用对应的字段,以逗号分隔,0 表示整个行。
① 选项

② 模式
常用模式有:

而动作呢,就是下面所讲的 print、流程控制、I/O 语句等。
示例:
1)从文件读取 awk 程序处理文件
# vi test.awk
{print $2}
# tail -n3 /etc/services |awk -f test.awk
48049/tcp
48128/tcp
49000/tcp打印第二字段,默认以空格分隔:
# tail -n3 /etc/services |awk '{print $2}'
48049/tcp
48128/tcp
48128/udp
指定冒号为分隔符打印第一字段:
# awk -F ':' '{print $1}' /etc/passwd
root
bin
daemon
adm
lp
sync
......还可以指定多个分隔符,作为同一个分隔符处理:
# tail -n3 /etc/services |awk -F'[/#]' '{print $3}'
iqobject
iqobject
Matahari Broker
# tail -n3 /etc/services |awk -F'[/#]' '{print $1}'
iqobject 48619
iqobject 48619
matahari 49000
# tail -n3 /etc/services |awk -F'[/#]' '{print $2}'
tcp
udp
tcp
# tail -n3 /etc/services |awk -F'[/#]' '{print $3}'
iqobject
iqobject
Matahari Broker
# tail -n3 /etc/services |awk -F'[ /]+' '{print $2}'
48619
48619
49000[]元字符的意思是符号其中任意一个字符,也就是说每遇到一个/或#时就分隔一个字段,当用多个
分隔符时,就能更方面处理字段了。
3)变量赋值
# awk -v a=123 'BEGIN{print a}'
123
系统变量作为 awk 变量的值:
# a=123
# awk -v a=$a 'BEGIN{print a}'
123
或使用单引号
# awk 'BEGIN{print '$a'}'
123# seq 5 |awk --dump-variables '{print $0}'
1
2
3
4
5
# cat awkvars.out
ARGC: number (1)
ARGIND: number (0)
ARGV: array, 1 elements
BINMODE: number (0)
CONVFMT: string ("%.6g")
ERRNO: number (0)
FIELDWIDTHS: string ("")
FILENAME: string ("-")
FNR: number (5)
FS: string (" ")
IGNORECASE: number (0)
LINT: number (0)
NF: number (1)
NR: number (5)
OFMT: string ("%.6g")
OFS: string (" ")
ORS: string ("\n")
RLENGTH: number (0)
RS: string ("\n")
RSTART: number (0)
RT: string ("\n")
SUBSEP: string ("\034")
TEXTDOMAIN: string ("messages")# tail /etc/services |awk 'BEGIN{print "Service\t\tPort\t\t\tDescription\n==="}{print
$0}'
Service Port Description
===
3gpp-cbsp 48049/tcp # 3GPP Cell Broadcast Service
isnetserv 48128/tcp # Image Systems Network Services
isnetserv 48128/udp # Image Systems Network Services
blp5 48129/tcp # Bloomberg locator
blp5 48129/udp # Bloomberg locator
com-bardac-dw 48556/tcp # com-bardac-dw
com-bardac-dw 48556/udp # com-bardac-dw
iqobject 48619/tcp # iqobject
iqobject 48619/udp # iqobject
matahari 49000/tcp # Matahari BrokerEND 模式是在程序处理完才会执行。
例如:打印页尾
# tail /etc/services |awk '{print $0}END{print "===\nEND......"}'
3gpp-cbsp 48049/tcp # 3GPP Cell Broadcast Service
isnetserv 48128/tcp # Image Systems Network Services
isnetserv 48128/udp # Image Systems Network Services
blp5 48129/tcp # Bloomberg locator
blp5 48129/udp # Bloomberg locator
com-bardac-dw 48556/tcp # com-bardac-dw
com-bardac-dw 48556/udp # com-bardac-dw
iqobject 48619/tcp # iqobject
iqobject 48619/udp # iqobject
matahari 49000/tcp # Matahari Broker
===
END......6)格式化输出 awk 命令到文件
# tail /etc/services |awk --profile 'BEGIN{print
"Service\t\tPort\t\t\tDescription\n==="}{print $0}END{print "===\nEND......"}'
Service Port Description
===
nimgtw 48003/udp # Nimbus Gateway
3gpp-cbsp 48049/tcp # 3GPP Cell Broadcast Service Protocol
isnetserv 48128/tcp # Image Systems Network Services
isnetserv 48128/udp # Image Systems Network Services
blp5 48129/tcp # Bloomberg locator
blp5 48129/udp # Bloomberg locator
com-bardac-dw 48556/tcp # com-bardac-dw
com-bardac-dw 48556/udp # com-bardac-dw
iqobject 48619/tcp # iqobject
iqobject 48619/udp # iqobject
===
END......
# cat awkprof.out
# gawk profile, created Sat Jan 7 19:45:22 2017
# BEGIN block(s)
BEGIN {
print "Service\t\tPort\t\t\tDescription\n==="
}
# Rule(s)
{
print $0
}
# END block(s)
END {
print "===\nEND......"
}匹配包含 tcp 的行:
# tail /etc/services |awk '/tcp/{print $0}'
3gpp-cbsp 48049/tcp # 3GPP Cell Broadcast Service
isnetserv 48128/tcp # Image Systems Network Services
blp5 48129/tcp # Bloomberg locator
com-bardac-dw 48556/tcp # com-bardac-dw
iqobject 48619/tcp # iqobject
matahari 49000/tcp # Matahari Broker
匹配开头是 blp5 的行:
# tail /etc/services |awk '/^blp5/{print $0}'
blp5 48129/tcp # Bloomberg locator
blp5 48129/udp # Bloomberg locator
匹配第一个字段是 8 个字符的行:
# tail /etc/services |awk '/^[a-z0-9]{8} /{print $0}'
iqobject 48619/tcp # iqobject
iqobject 48619/udp # iqobject
matahari 49000/tcp # Matahari Broker
如果没有匹配到,请查看你的 awk 版本(awk --version)是不是 3,因为 4 才支持{}8)逻辑 and、or 和 not
匹配记录中包含 blp5 和 tcp 的行:
# tail /etc/services |awk '/blp5/ && /tcp/{print $0}'
blp5 48129/tcp # Bloomberg locator
匹配记录中包含 blp5 或 tcp 的行:
# tail /etc/services |awk '/blp5/ || /tcp/{print $0}'
3gpp-cbsp 48049/tcp # 3GPP Cell Broadcast Service
isnetserv 48128/tcp # Image Systems Network Services
blp5 48129/tcp # Bloomberg locator
blp5 48129/udp # Bloomberg locator
com-bardac-dw 48556/tcp # com-bardac-dw
iqobject 48619/tcp # iqobject
matahari 49000/tcp # Matahari Broker
不匹配开头是#和空行:
# awk '! /^#/ && ! /^$/{print $0}' /etc/httpd/conf/httpd.conf
或
# awk '! /^#|^$/' /etc/httpd/conf/httpd.conf
或
# awk '/^[^#]|"^$"/' /etc/httpd/conf/httpd.conf9)匹配范围
# tail /etc/services |awk '/^blp5/,/^com/'
blp5 48129/tcp # Bloomberg locator
blp5 48129/udp # Bloomberg locator
com-bardac-dw 48556/tcp # com-bardac-dw# seq 5 |awk '/3/,/^$/{printf /3/?"":$0"\n"}'
4
5
另一种判断真假的方式实现:
# seq 5 |awk '/3/{t=1;next}t'
4
5
1 和 2 都不匹配 3,不执行后面{},执行 t,t 变量还没赋值,为空,空在 awk 中就为假,就不打印
当前行。匹配到 3,执行 t=1,next 跳出,不执行 t。4 也不匹配 3,执行 t,t 的值上次赋值的 1, 为真,打印当前行,以此类推。(非 0 的数字都为真,所以 t 可以写任意非 0 数字)
如果想打印匹配行都最后一行,就可以这样了:
# seq 5 |awk '/3/{t=1}t'
3
4
5③ 内置变量


示例:
1)FS 和 OFS
在程序开始前重新赋值 FS 变量,改变默认分隔符为冒号,与-F一样。
# awk 'BEGIN{FS=":"}{print $1,$2}' /etc/passwd |head -n5
root x
bin x
daemon x
adm x
lp x
也可以使用-v 来重新赋值这个变量:
# awk -vFS=':' '{print $1,$2}' /etc/passwd |head -n5 # 中间逗号被换成了 OFS 的默
认值
root x
bin x
daemon x
adm x
lp x
由于 OFS 默认以空格分隔,反向引用多个字段分隔的也是空格,如果想指定输出分隔符这样:
# awk 'BEGIN{FS=":";OFS=":"}{print $1,$2}' /etc/passwd |head -n5
root:x
bin:x
daemon:x
adm:x
lp:x
也可以通过字符串拼接实现分隔:
# awk 'BEGIN{FS=":"}{print $1"#"$2}' /etc/passwd |head -n5
root#x
bin#x
daemon#x
adm#x
lp#x2)RS 和 ORS
RS 默认是\n 分隔每行,如果想指定以某个字符作为分隔符来处理记录:
# echo "www.baidu.com/user/test.html" |awk 'BEGIN{RS="/"}{print $0}'
www.baidu.com
user
test.html
RS 也支持正则,简单演示下:
# seq -f "str%02g" 10 |sed 'n;n;a\-----' |awk 'BEGIN{RS="-+"}{print $1}'
str01
str04
str07
str10
将输出的换行符替换为+号:
# seq 10 |awk 'BEGIN{ORS="+"}{print $0}'
1+2+3+4+5+6+7+8+9+10+
替换某个字符:
# tail -n2 /etc/services |awk 'BEGIN{RS="/";ORS="#"}{print $0}'
iqobject 48619#udp # iqobject
matahari 49000#tcp # Matahari Broker# echo "a b c d e f" |awk '{print NF}'
6
打印最后一个字段:
# echo "a b c d e f" |awk '{print $NF}'
f
打印倒数第二个字段:
# echo "a b c d e f" |awk '{print $(NF-1)}'
e
排除最后两个字段:
# echo "a b c d e f" |awk '{$NF="";$(NF-1)="";print $0}'
a b c d
排除第一个字段:
# echo "a b c d e f" |awk '{$1="";print $0}'
b c d e f4)NR 和 FNR
NR 统计记录编号,每处理一行记录,编号就会+1,FNR 不同的是在统计第二个文件时会重新计数。
打印行数:
# tail -n5 /etc/services |awk '{print NR,$0}'
1 com-bardac-dw 48556/tcp # com-bardac-dw
2 com-bardac-dw 48556/udp # com-bardac-dw
3 iqobject 48619/tcp # iqobject
4 iqobject 48619/udp # iqobject
5 matahari 49000/tcp # Matahari Broker
打印总行数:
# tail -n5 /etc/services |awk 'END{print NR}'
5
打印第三行:
# tail -n5 /etc/services |awk 'NR==3'
iqobject 48619/tcp # iqobject
打印第三行第二个字段:
# tail -n5 /etc/services |awk 'NR==3{print $2}'
48619/tcp
打印前三行:
# tail -n5 /etc/services |awk 'NR<=3{print NR,$0}'
1 com-bardac-dw 48556/tcp # com-bardac-dw
2 com-bardac-dw 48556/udp # com-bardac-dw
3 iqobject 48619/tcp # iqobject# cat a
a
b
c
# cat b
c
d
e
# awk '{print NR,FNR,$0}' a b
1 1 a
2 2 b
3 3 c
4 1 c
5 2 d
6 3 e可以看出 NR 每处理一行就会+1,而 FNR 在处理第二个文件时,编号重新计数。同时也知道 awk 处理两个文件时,是合并到一起处理。
# awk 'FNR==NR{print $0"1"}FNR!=NR{print $0"2"}' a b
a1
b1
c1
c2
d2
e2当 FNR==NR 时,说明在处理第一个文件内容,不等于时说明在处理第二个文件内容。
一般 FNR 在处理多个文件时会用到,下面会讲解。
5)ARGC 和 ARGV
ARGC 是命令行参数数量
ARGV 是将命令行参数存到数组,元素由 ARGC 指定,数组下标从 0 开始
# awk 'BEGIN{print ARGC}' 1 2 3
4
# awk 'BEGIN{print ARGV[0]}'
awk
# awk 'BEGIN{print ARGV[1]}' 1 2
1
# awk 'BEGIN{print ARGV[2]}' 1 2
26)ARGIND
ARGIND 是当前正在处理的文件索引值,第一个文件是 1,第二个文件是 2,以此类推,从而可以通过这种方式判断正在处理哪个文件。
# awk '{print ARGIND,$0}' a b
1 a
1 b
1 c
2 c
2 d
2 e
# awk 'ARGIND==1{print "a->"$0}ARGIND==2{print "b->"$0}' a b
a->a
a->b
a->c
b->c
b->d
b->e7)ENVIRON
ENVIRON 调用系统变量。
# awk 'BEGIN{print ENVIRON["HOME"]}'
/root
如果是设置的环境变量,还需要用 export 导入到系统变量才可以调用:
# awk 'BEGIN{print ENVIRON["a"]}'
# export a
# awk 'BEGIN{print ENVIRON["a"]}'
1238)FILENAME
FILENAME 是当前处理文件的文件名。
# awk 'FNR==NR{print FILENAME"->"$0}FNR!=NR{print FILENAME"->"$0}' a b a->a
a->b
a->c
b->c
b->d
b->e
9)忽略大小写
# echo "A a b c" |xargs -n1 |awk 'BEGIN{IGNORECASE=1}/a/'
Aa④ 操作符

须知: 在 awk 中,有 3 种情况表达式为假:数字是 0,空字符串和未定义的值。
数值运算,未定义变量初始值为 0。字符运算,未定义变量初始值为空。
举例测试:
# awk 'BEGIN{n=0;if(n)print "true";else print "false"}'
false
# awk 'BEGIN{s="";if(s)print "true";else print "false"}'
false
# awk 'BEGIN{if(s)print "true";else print "false"}'
false示例:
1)截取整数
# echo "123abc abc123 123abc123" |xargs -n1 | awk '{print +$0}'
123
0
123
# echo "123abc abc123 123abc123" |xargs -n1 | awk '{print -$0}'
-123
0-1232)感叹号
打印奇数行: # seq 6 |awk 'i=!i'
1
3
5
打印偶数行: # seq 6 |awk '!(i=!i)'
2
4
6读取第一行:i 是未定义变量,也就是 i=!0,!取反意思。感叹号右边是个布尔值,0 或空字符串为
假,非 0 或非空字符串为真,!0 就是真,因此 i=1,条件为真打印当前记录。
没有 print 为什么会打印呢?因为模式后面没有动作,默认会打印整条记录。
读取第二行:因为上次 i 的值由 0 变成了 1,此时就是 i=!1,条件为假不打印。
读取第三行:上次条件又为假,i 恢复初始值 0,取反,继续打印。以此类推...
可以看出,运算时并没有判断行内容,而是利用布尔值真假判断输出当前行。
3)不匹配某行
# tail /etc/services |awk '!/blp5/{print $0}'
3gpp-cbsp 48049/tcp # 3GPP Cell Broadcast Service
isnetserv 48128/tcp # Image Systems Network Services
isnetserv 48128/udp # Image Systems Network Services
com-bardac-dw 48556/tcp # com-bardac-dw
com-bardac-dw 48556/udp # com-bardac-dw
iqobject 48619/tcp # iqobject
iqobject 48619/udp # iqobject
matahari 49000/tcp # Matahari Broker4)乘法和除法
# seq 5 |awk '{print $0*2}'
2
4
6
8
10
# seq 5 |awk '{print $0%2}'
1
0
1
0
1
打印偶数行: # seq 5 |awk '$0%2==0{print $0}'
2
4
打印奇数行: # seq 5 |awk '$0%2!=0{print $0}'
1
3
55)管道符使用
# seq 5 |shuf |awk '{print $0|"sort"}'
1
2
3
4
56)正则表达式匹配
# seq 5 |awk '$0~3{print $0}'
3
# seq 5 |awk '$0!~3{print $0}'
1
2
4
5
# seq 5 |awk '$0~/[34]/{print $0}'
3
4
# seq 5 |awk '$0!~/[34]/{print $0}'
1
2
5
# seq 5 |awk '$0~/[^34]/{print $0}'
1
2
57)判断数组成员
# awk 'BEGIN{a["a"]=123}END{if("a" in a)print "yes"}' # awk 'BEGIN{print 1==1?"yes":"no"}' # 三目运算作为一个表达式,里面不允许写 print
yes
# seq 3 |awk '{print $0==2?"yes":"no"}'
no
yes
no
替换换行符为逗号:
# seq 5 |awk '{print n=(n?n","$0:$0)}'
1
1,2
1,2,3
1,2,3,4
1,2,3,4,5
# seq 5 |awk '{n=(n?n","$0:$0)}END{print n}'
1,2,3,4,5
说明:读取第一行时,n 没有变量,为假输出$0 也就是 1,并赋值变量 n,读取第二行时,n 是 1 为
真,输出 1,2 以此类推,后面会一直为真。
每三行后面添加新一行:
# seq 10 |awk '{print NR%3?$0:$0 "\ntxt"}'
1
2
3
txt
4
5
6
txt
7
8
9
txt
10
在
两行合并一行:
# seq 6 |awk '{printf NR%2!=0?$0" ":$0" \n"}'
1 2
3 4
5 6
# seq 6 |awk 'ORS=NR%2?" ":"\n"'
1 2
3 4
5 6
# seq 6 |awk '{if(NR%2)ORS=" ";else ORS="\n";print}'9)变量赋值
字段求和:
# seq 5 |awk '{sum+=1}END{print sum}'
5
# seq 5 |awk '{sum+=$0}END{print sum}'
15⑤ 流程控制
1)if 语句
格式:
if (condition) statement [ else statement ]单分支:
# seq 5 |awk '{if($0==3)print $0}'
3
也支持正则匹配判断,一般在写复杂语句时使用:
# echo "123abc#456cde 789aaa#aaabbb " |xargs -n1 |awk -F# '{if($2~/[0-9]/)print $2}'
456cde
# echo "123abc#456cde 789aaa#aaabbb " |xargs -n1 |awk -F# '{if($2!~/[0-9]/)print $2}'
aaabbb
或
# echo "123abc#456cde 789aaa#aaabbb" |xargs -n1 |awk -F# '$2!~/[0-9]/{print $2}'
aaabbb
双分支:
# seq 5 |awk '{if($0==3)print $0;else print "no"}'
no
no
3
no
no
多分支:
# cat file
1 2 3
4 5 6
7 8 9
# awk '{if($1==4){print "1"} else if($2==5){print "2"} else if($3==6){print "3"} else
{print "no"}}' file
no
1
no
2)while 语句
格式:
while (condition) statement遍历打印所有字段:
# awk '{i=1;while(i<=NF){print $i;i++}}' file
1
2
3
4
5
6
7
8
9awk 是按行处理的,每次读取一行,并遍历打印每个字段。
3)for 语句 C 语言风格
格式:
for (expr1; expr2; expr3) statement遍历打印所有字段:
# cat file
1 2 3
4 5 6
7 8 9
# awk '{for(i=1;i<=NF;i++)print $i}' file
1
2
3
4
5
6
7
8
9
倒叙打印文本:
# awk '{for(i=NF;i>=1;i--)print $i}' file
3
2
1
6
5
4
9
8
7
都换行了,这并不是我们要的结果。怎么改进呢?
# awk '{for(i=NF;i>=1;i--){printf $i" "};print ""}' file # print 本身就会新打印一行
3 2 1
6 5 4
9 8 7
或
# awk '{for(i=NF;i>=1;i--)if(i==1)printf $i"\n";else printf $i" "}' file
3 2 1
6 5 4
9 8 7
在这种情况下,是不是就排除第一行和倒数第一行呢?我们正序打印看下
排除第一行:
# awk '{for(i=2;i<=NF;i++){printf $i" "};print ""}' file
2 3
5 6
8 9
排除第二行:
# awk '{for(i=1;i<=NF-1;i++){printf $i" "};print ""}' file
1 2
4 5
7 8
IP 加单引号:
# echo '10.10.10.1 10.10.10.2 10.10.10.3' |awk '{for(i=1;i<=NF;i++)printf
"\047"$i"\047"}
'10.10.10.1' '10.10.10.2' '10.10.10.3'
\047 是 ASCII 码,可以通过 showkey -a 命令查看。4)for 语句遍历数组
格式:
for (var in array) statement# seq -f "str%.g" 5 |awk '{a[NR]=$0}END{for(v in a)print v,a[v]}'
4 str4
5 str5
1 str1
2 str2
3 str35)break 和 continue 语句
break 跳过所有循环,continue 跳过当前循环。
# awk 'BEGIN{for(i=1;i<=5;i++){if(i==3){break};print i}}'
1
2
# awk 'BEGIN{for(i=1;i<=5;i++){if(i==3){continue};print i}}'
1
2
4
56)删除数组和元素
格式:
delete array[index] 删除数组元素
delete array 删除数组# seq -f "str%.g" 5 |awk '{a[NR]=$0}END{delete a;for(v in a)print v,a[v]}'
空的…
# seq -f "str%.g" 5 |awk '{a[NR]=$0}END{delete a[3];for(v in a)print v,a[v]}'
4 str4
5 str5
1 str1
2 str27)exit 语句
格式:
exit [ expression ]exit 退出程序,与 shell 的 exit 一样。[ expr ]是 0-255 之间的数字。
# seq 5 |awk '{if($0~/3/)exit (123)}'
# echo $?
123⑥ 数组
数组:存储一系列相同类型的元素,键/值方式存储,通过下标(键)来访问值。
awk 中数组称为关联数组,不仅可以使用数字作为下标,还可以使用字符串作为下标。
数组元素的键和值存储在 awk 程序内部的一个表中,该表采用散列算法,因此数组元素是随机排
序。
数组格式:
array[index]=value1)自定义数组
# awk 'BEGIN{a[0]="test";print a[0]}'
test2)通过 NR 设置记录下标,下标从 1 开始
# tail -n3 /etc/passwd |awk -F: '{a[NR]=$1}END{print a[1]}'
systemd-network
# tail -n3 /etc/passwd |awk -F: '{a[NR]=$1}END{print a[2]}'
zabbix
# tail -n3 /etc/passwd |awk -F: '{a[NR]=$1}END{print a[3]}'
user# tail -n5 /etc/passwd |awk -F: '{a[NR]=$1}END{for(v in a)print a[v],v}'
zabbix 4
user 5
admin 1
systemd-bus-proxy 2
systemd-network 3
# tail -n5 /etc/passwd |awk -F: '{a[NR]=$1}END{for(i=1;i<=NR;i++)print a[i],i}'
admin 1
systemd-bus-proxy 2
systemd-network 3
zabbix 4
user 5上面打印的 i 是数组的下标。
第一种 for 循环的结果是乱序的,刚说过,数组是无序存储。
第二种 for 循环通过下标获取的情况是排序正常。
所以当下标是数字序列时,还是用 for(expr1;expr2;expr3)循环表达式比较好,保持顺序不变。
4)通过++方式作为下标
# tail -n5 /etc/passwd |awk -F: '{a[x++]=$1}END{for(i=0;i<=x-1;i++)print a[i],i}'
admin 0
systemd-bus-proxy 1
systemd-network 2
zabbix 3
user 4x 被 awk 初始化值是 0,没循环一次+1
5)使用字段作为下标
# tail -n5 /etc/passwd |awk -F: '{a[$1]=$7}END{for(v in a)print a[v],v}'
/sbin/nologin admin
/bin/bash user
/sbin/nologin systemd-network
/sbin/nologin systemd-bus-proxy
/sbin/nologin zabbix6)统计相同字段出现次数
# tail /etc/services |awk '{a[$1]++}END{for(v in a)print a[v],v}'
2 com-bardac-dw
1 3gpp-cbsp
2 iqobject
1 matahari
2 isnetserv
2 blp5
# tail /etc/services |awk '{a[$1]+=1}END{for(v in a)print a[v],v}'
2 com-bardac-dw
1 3gpp-cbsp
2 iqobject
1 matahari
2 isnetserv
2 blp5
# tail /etc/services |awk '/blp5/{a[$1]++}END{for(v in a)print a[v],v}'
2 blp5第一个字段作为下标,值被++初始化是 0,每次遇到下标(第一个字段)一样时,对应的值就会被
+1,因此实现了统计出现次数。
想要实现去重的的话就简单了,只要打印下标即可。
7)统计 TCP 连接状态
# netstat -antp |awk '/^tcp/{a[$6]++}END{for(v in a)print a[v],v}'
9 LISTEN
6 ESTABLISHED
6 TIME_WAIT8)只打印出现次数大于等于 2 的
# tail /etc/services |awk '{a[$1]++}END{for(v in a) if(a[v]>=2){print a[v],v}}'
2 com-bardac-dw
2 iqobject
2 isnetserv
2 blp59)去重
只打印重复的行:
# tail /etc/services |awk 'a[$1]++'
isnetserv 48128/udp # Image Systems Network Services
blp5 48129/udp # Bloomberg locator
com-bardac-dw 48556/udp # com-bardac-dw
iqobject 48619/udp # iqobject
不打印重复的行:
# tail /etc/services |awk '!a[$1]++'
3gpp-cbsp 48049/tcp # 3GPP Cell Broadcast Service
isnetserv 48128/tcp # Image Systems Network Services
blp5 48129/tcp # Bloomberg locator
com-bardac-dw 48556/tcp # com-bardac-dw
iqobject 48619/tcp # iqobject
matahari 49000/tcp # Matahari Broker先明白一个情况,当值是 0 是为假,非 0 整数为真,知道这点就不难理解了。
只打印重复的行说明:当处理第一条记录时,执行了++,初始值是 0 为假,就不打印,如果再遇到相同的记录,值就会+1,不为 0,则打印。
不打印重复的行说明:当处理第一条记录时,执行了++,初始值是 0 为假,感叹号取反为真,打
印,如果再遇到相同的记录,值就会+1,不为 0 为真,取反为假就不打印。
# tail /etc/services |awk '{if(a[$1]++)print $1}'
isnetserv
blp5
com-bardac-dw
iqobject
使用三目运算:
# tail /etc/services |awk '{print a[$1]++?$1:"no"}'
no
no
isnetserv
no
blp5
no
com-bardac-dw
no
iqobject
no
# tail /etc/services |awk '{if(!a[$1]++)print $1}'
3gpp-cbsp
isnetserv
blp5
com-bardac-dw
iqobject
matahari10)统计每个相同字段的某字段总数:
# tail /etc/services |awk -F'[ /]+' '{a[$1]+=$2}END{for(v in a)print v, a[v]}'
com-bardac-dw 97112
3gpp-cbsp 48049
iqobject 97238
matahari 49000
isnetserv 96256
blp5 9625811)多维数组
awk 的多维数组,实际上 awk 并不支持多维数组,而是逻辑上模拟二维数组的访问方式,比如
a[a,b]=1,使用 SUBSEP(默认\034)作为分隔下标字段,存储后是这样 a\034b。
示例:
# awk 'BEGIN{a["x","y"]=123;for(v in a) print v,a[v]}'
xy 123
我们可以重新复制 SUBSEP 变量,改变下标默认分隔符:
# awk 'BEGIN{SUBSEP=":";a["x","y"]=123;for(v in a) print v,a[v]}'
x:y 123
根据指定的字段统计出现次数:
# cat file
A 192.168.1.1 HTTP
B 192.168.1.2 HTTP
B 192.168.1.2 MYSQL
C 192.168.1.1 MYSQL
C 192.168.1.1 MQ
D 192.168.1.4 NGINX
# awk 'BEGIN{SUBSEP="-"}{a[$1,$2]++}END{for(v in a)print a[v],v}' file
1 D-192.168.1.4
1 A-192.168.1.1
2 C-192.168.1.1
2 B-192.168.1.2⑦ 内置函数


示例:
1)int()
截断为整数: # echo -e "123abc\nabc123\n123abc123" | awk '{print int($0)}'
123
0
123
# awk 'BEGIN{print int(10/3)}'
32)sqrt()
获取 9 的平方根:
# awk 'BEGIN{print sqrt(9)}'
33)rand()和 srand()
rand()并不是每次运行就是一个随机数,会一直保持一个不变:
# awk 'BEGIN{print rand()}'
0.237788
当执行 srand()函数后,rand()才会发生变化,所以一般在 awk 着两个函数结合生成随机数,但是
也有很大几率生成一样:
# awk 'BEGIN{srand();print rand()}'
0.31687
如果想生成 1-10 的随机数可以这样:
# awk 'BEGIN{srand();print int(rand()*10)}'
4如果想更完美生成随机数,还得做相应的处理!
4)asort()和 asorti()
排序数组:
# seq -f "str%.g" 5 |awk '{a[x++]=$0}END{s=asort(a,b);for(i=1;i<=s;i++)print
b[i],i}'
str1 1
str2 2
str3 3
str4 4
str5 5
# seq -f "str%.g" 5 |awk '{a[x++]=$0}END{s=asorti(a,b);for(i=1;i<=s;i++)print
b[i],i}'
0 1
1 2
2 3
3 4
4 5asort 将 a 数组的值放到数组 b,a 下标丢弃,并将数组 b 的总行号赋值给 s,新数组 b 下标从 1 开始,然后遍历。
5)sub()和 gsub()
替换正则匹配的字符串:
# tail /etc/services |awk '/blp5/{sub(/tcp/,"icmp");print $0}'
blp5 48129/icmp # Bloomberg locator
blp5 48129/udp # Bloomberg locator
# tail /etc/services |awk '/blp5/{gsub(/c/,"9");print $0}'
blp5 48129/t9p # Bloomberg lo9ator
blp5 48129/udp # Bloomberg lo9ator
# echo "1 2 2 3 4 5" |awk 'gsub(2,7,$2){print $0}'
1 7 2 3 4 5
# echo "1 2 3 a b c" |awk 'gsub(/[0-9]/, '0'){print $0}'
0 0 0 a b c在指定行前后加一行:
# seq 5 | awk 'NR==2{sub('/.*/',"txt\n&")}{print}'
1
txt
2
3
4
5
# seq 5 | awk 'NR==2{sub('/.*/',"&\ntxt")}{print}'
1
2
txt
3
4
56)index()
获取字段索引起始位置:
# tail -n 5 /etc/services |awk '{print index($2,"tcp")}'
7
0
7
0
77)length()
统计字段长度:
# tail -n 5 /etc/services |awk '{print length($2)}'
9
9
9
9
9
统计数组的长度:
# tail -n 5 /etc/services |awk '{a[$1]=$2}END{print length(a)}'
38)match
# echo "123abc#456cde 789aaa#234bbb 999aaa#aaabbb" |xargs -n1 |awk '{print
match($0,234)}'
0
8
0
如果记录匹配字符串 234,则返回索引位置,否则返回 0。
那么,我们只想打印包含这个字符串的记录就可以这样:
# echo "123abc#456cde 789aaa#234bbb 999aaa#aaabbb" |xargs -n1 |awk
'{if(match($0,234)!=0)print $0}'
789aaa#234bbb9)split()
切分记录为数组 a: # echo -e "123#456#789\nabc#cde#fgh" |awk '{split($0,a);for(v in a)print a[v],v}'
123#456#789 1
abc#cde#fgh 1
以#号切分记录为数据 a:
# echo -e "123#456#789\nabc#cde#fgh" |awk '{split($0,a,"#");for(v in a)print a[v],v}'
123 1
456 2
789 3
abc 1
cde 2
fgh 310)substr()
截取字符串索引 4 到最后:
# echo -e "123#456#789\nabc#cde#fgh" |awk '{print
substr($0,4)}'
#456#789
#cde#fgh
截取字符串索引 4 到长度 5:
# echo -e "123#456#789\nabc#cde#fgh" |awk '{print substr($0,4,5)}'
#456#
#cde#11)tolower()和 toupper()
转换小写:
# echo -e "123#456#789\nABC#cde#fgh" |awk '{print tolower($0)}'
123#456#789
abc#cde#fgh
转换大写:
# echo -e "123#456#789\nabc#cde#fgh" |awk '{print toupper($0)}'
123#456#789
ABC#CDE#FGH12)时间处理
返回当前时间戳:
# awk 'BEGIN{print systime()}'
1483297766
将时间戳转为日期和时间
# echo "1483297766" |awk '{print strftime("%Y-%m-%d %H:%M:%S",$0)}'
2017-01-01 14:09:26⑧ I/O 语句

示例:
1)getline
获取匹配的下一行:
# seq 5 |awk '/3/{getline;print}'
4
# seq 5 |awk '/3/{print;getline;print}'
3
4
在匹配的下一行加个星号:
# seq 5 |awk '/3/{getline;sub(".*","&*");print}'
4*
# seq 5 |awk '/3/{print;getline;sub(".*","&*")}{print}'
1
2
3
4*
52)getline var
把 a 文件的行追加到 b 文件的行尾:
# cat a
a
b
c
# cat b
1 one
2 two
3 three
# awk '{getline line<"a";print $0,line}' b
1 one a
2 two b
3 three c
把 a 文件的行替换 b 文件的指定字段:
# awk '{getline line<"a";gsub($2,line,$2);print}' b
1 a
2 b
3 c
把 a 文件的行替换 b 文件的对应字段:
# awk '{getline line<"a";gsub("two",line,$2);print}' b
1 one
2 b
3 three3)command | getline [var]
获取执行 shell 命令后结果的第一行:
# awk 'BEGIN{"seq 5"|getline var;print var}'
1
循环输出执行 shell 命令后的结果:
# awk 'BEGIN{while("seq 5"|getline)print}'
1
2
3
4
54)next
不打印匹配行:
# seq 5 |awk '{if($0==3){next}else{print}}'
1
2
4
5
删除指定行:
# seq 5 |awk 'NR==1{next}{print $0}'
2
3
4
5
如果前面动作成功,就遇到 next,后面的动作不再执行,跳过。
或者:
# seq 5 |awk 'NR!=1{print}'
2
3
4
5
把第一行内容放到每行的前面:
# cat a
hello
1 a
2 b
3 c
# awk 'NR==1{s=$0;next}{print s,$0}' a
hello 1 a
hello 2 b
hello 3 c
# awk 'NR==1{s=$0}NF!=1{print s,$0}' a
hello 1 a
hello 2 b
hello 3 c5)system()
执行 shell 命令判断返回值:
# awk 'BEGIN{if(system("grep root /etc/passwd &>/dev/null")==0)print "yes";else print
"no"}'
yes6)打印结果写到文件
# tail -n5 /etc/services |awk '{print $2 > "a.txt"}'
# cat a.txt
48049/tcp
48128/tcp
48128/udp
48129/tcp
48129/udp7)管道连接 shell 命令
将结果通过 grep 命令过滤:
# tail -n5 /etc/services |awk '{print $2|"grep tcp"}'
48556/tcp
48619/tcp
49000/tcp⑨ printf 语句
格式化输出,默认打印字符串不换行。
格式:
printf [format] arguments

示例:
将换行符换成逗号:
# seq 5 |awk '{if($0!=5)printf "%s,",$0;else print $0}'
1,2,3,4,5
小括号中的 5 是最后一个数字。
输出一个字符:
# awk 'BEGIN{printf "%.1s\n","abc"}'
a
保留一个小数点:
# awk 'BEGIN{printf "%.2f\n",10/3}'
3.33
格式化输出:
# awk 'BEGIN{printf "user:%s\tpass:%d\n","abc",123}'
user:abc pass:123
左对齐宽度 10:
# awk 'BEGIN{printf "%-10s %-10s %-10s\n","ID","Name","Passwd"}'
ID Name Passwd
右对齐宽度 10:
# awk 'BEGIN{printf "%10s %10s %10s\n","ID","Name","Passwd"}'
ID Name Passwd
打印表格:
# vi test.awk
BEGIN{
print "+--------------------+--------------------+";
printf "|%-20s|%-20s|\n","Name","Number";
print "+--------------------+--------------------+";
}
# awk -f test.awk
+--------------------+--------------------+
|Name |Number |
+--------------------+--------------------+
格式化输出:
# awk -F: 'BEGIN{printf "UserName\t\tShell\n-----------------------------\n"}{printf
"%-20s %-20s\n",$1,$7}END{print "END...\n"}' /etc/passwd
打印十六进制:
# awk 'BEGIN{printf "%x %X",123,123}'
7b 7B⑩ 自定义函数
格式:
function name(parameter list) { statements }示例:
# awk 'function myfunc(a,b){return a+b}BEGIN{print myfunc(1,2)}'
3⑪ 需求案例
1)分析 Nginx 日志
日志格式:
'$remote_addr - $remote_user [$time_local] "$request" $status $body_bytes_sent "
$http_referer" "$http_user_agent" "$http_x_forwarded_for"'统计访问 IP 次数:
# awk '{a[$1]++}END{for(v in a)print v,a[v]}' access.log
统计访问访问大于 100 次的 IP:
# awk '{a[$1]++}END{for(v in a){if(a[v]>100)print v,a[v]}}' access.log
统计访问 IP 次数并排序取前 10:
# awk '{a[$1]++}END{for(v in a)print v,a[v] |"sort -k2 -nr |head -10"}' access.log
统计时间段访问最多的 IP:
# awk '$4>="[02/Jan/2017:00:02:00" && $4<="[02/Jan/2017:00:03:00"{a[$1]++}END{for(v in
a)print v,a[v]}' access.log
统计上一分钟访问量:
# date=$(date -d '-1 minute' +%d/%d/%Y:%H:%M)
# awk -vdate=$date '$4~date{c++}END{print c}' access.log
统计访问最多的 10 个页面:
# awk '{a[$7]++}END{for(v in a)print v,a[v] |"sort -k1 -nr|head -
n10"}' access.log
统计每个 URL 数量和返回内容总大小:
# awk '{a[$7]++;size[$7]+=$10}END{for(v in a)print a[v],v,size[v]}' access.log
统计每个 IP 访问状态码数量:
# awk '{a[$1" "$9]++}END{for(v in a)print v,a[v]}' access.log
统计访问 IP 是 404 状态次数:
# awk '{if($9~/404/)a[$1" "$9]++}END{for(i in a)print v,a[v]}' access.log2)两个文件对比
找出 b 文件在 a 文件相同记录:
# seq 1 5 > a
# seq 3 7 > b
方法 1:
# awk 'FNR==NR{a[$0];next}{if($0 in a)print $0}' a b
3
4
5
# awk 'FNR==NR{a[$0];next}{if($0 in a)print FILENAME,$0}' a b
b 3
b 4
b 5
# awk 'FNR==NR{a[$0]}NR>FNR{if($0 in a)print $0}' a b
3
4
5
# awk 'FNR==NR{a[$0]=1;next}(a[$0]==1)' a b # a[$0]是通过 b 文件每行获取值,如果是 1
说明有
# awk 'FNR==NR{a[$0]=1;next}{if(a[$0]==1)print}' a b
3
4
5
方法 2: # awk 'FILENAME=="a"{a[$0]}FILENAME=="b"{if($0 in a)print $0}' a b
3
4
5
方法 3: # awk 'ARGIND==1{a[$0]=1}ARGIND==2 && a[$0]==1' a b
3
4
5找出 b 文件在 a 文件不同记录:
方法 1:
# awk 'FNR==NR{a[$0];next}!($0 in a)' a b
6
7
# awk 'FNR==NR{a[$0]=1;next}(a[$0]!=1)' a b
# awk 'FNR==NR{a[$0]=1;next}{if(a[$0]!=1)print}' a b
6
7
方法 2: # awk 'FILENAME=="a"{a[$0]=1}FILENAME=="b" && a[$0]!=1' a b
方法 3: # awk 'ARGIND==1{a[$0]=1}ARGIND==2 && a[$0]!=1' a b3)合并两个文件
将 a 文件合并到 b 文件:
# cat a
zhangsan 20
lisi 23
wangwu 29
# cat b
zhangsan man
lisi woman
wangwu man
# awk 'FNR==NR{a[$1]=$0;next}{print a[$1],$2}' a b
zhangsan 20 man
lisi 23 woman
wangwu 29 man
# awk 'FNR==NR{a[$1]=$0}NR>FNR{print a[$1],$2}' a b
zhangsan 20 man
lisi 23 woman
wangwu 29 man将 a 文件相同 IP 的服务名合并:
# cat a
192.168.1.1: httpd
192.168.1.1: tomcat
192.168.1.2: httpd
192.168.1.2: postfix
192.168.1.3: mysqld
192.168.1.4: httpd
# awk 'BEGIN{FS=":";OFS=":"}{a[$1]=a[$1] $2}END{for(v in a)print v,a[v]}' a
192.168.1.4: httpd
192.168.1.1: httpd tomcat
192.168.1.2: httpd postfix
192.168.1.3: mysqld说明:数组 a 存储是$1=a[$1] $2,第一个 a[$1]是以第一个字段为下标,值是 a[$1] $2,也就是
$1=a[$1] $2,值的 a[$1]是用第一个字段为下标获取对应的值,但第一次数组 a 还没有元素,那么
a[$1]是空值,此时数组存储是 192.168.1.1=httpd,再遇到 192.168.1.1 时,a[$1]通过第一字段
下标获得上次数组的 httpd,把当前处理的行第二个字段放到上一次同下标的值后面,作为下标
192.168.1.1 的新值。此时数组存储是 192.168.1.1=httpd tomcat。每次遇到相同的下标(第一个
字段)就会获取上次这个下标对应的值与当前字段并作为此下标的新值。
4)将第一列合并到一行
# cat file
1 2 3
4 5 6
7 8 9
# awk '{for(i=1;i<=NF;i++)a[i]=a[i]$i" "}END{for(v in a)print a[v]}' file
1 4 7
2 5 8
3 6 9说明:
for 循环是遍历每行的字段,NF 等于 3,循环 3 次。
读取第一行时:
第一个字段:a[1]=a[1]1" " 值 a[1]还未定义数组,下标也获取不到对应的值,所以为空,因此a[1]=1 。
第二个字段:a[2]=a[2]2" " 值 a[2]数组 a 已经定义,但没有 2 这个下标,也获取不到对应的
值,为空,因此 a[2]=2 。
第三个字段:a[3]=a[3]3" " 值 a[2]与上面一样,为空,a[3]=3 。
读取第二行时:
第一个字段:a[1]=a[1]4" " 值 a[2]获取数组 a 的 2 为下标对应的值,上面已经有这个下标了,
对应的值是 1,因此 a[1]=1 4
第二个字段:a[2]=a[2]5" " 同上,a[2]=2 5
第三个字段:a[3]=a[3]6" " 同上,a[2]=3 6
读取第三行时处理方式同上,数组最后还是三个下标,分别是 1=1 4 7,2=2 5 8,3=3 6 9。最后
for 循环输出所有下标值。
5)字符串拆分,统计出现的次数
字符串拆分:
方法 1: # echo "hello world" |awk -F '' '{print $1}'
h
# echo "hello" |awk -F '' '{for(i=1;i<=NF;i++)print $i}'
h
e
l
l
o
方法 2:
# echo "hello" |awk '{split($0,a,"''");for(v in a)print a[v]}'
l
o
h
e
l统计字符串中每个字母出现的次数:
# echo "a.b.c,c.d.e" |awk -F '[.,]' '{for(i=1;i<=NF;i++)a[$i]++}END{for(v in a)print
v,a[v]}'
a 1
b 1
c 2
d 1
e 16)统计平均成绩
# cat file
job 80
dave 84
tom 75
dave 73
job 72
tom 83
dave 88
# awk '{a[$1]+=$2;b[$1]++}END{for(i in a)print i,a[i]/b[i]}' file
job 76
dave 81.6667
tom 797)费用统计
# cat file
zhangsan 8000 1
zhangsan 5000 1
lisi 1000 1
lisi 2000 1
wangwu 1500 1
zhaoliu 6000 1
zhaoliu 2000 1
zhaoliu 3000 1
# awk '{name[$1]++;cost[$1]+=$2;number[$1]+=$3}END{for(v in name)print
v,cost[v],number[v]}' file
zhangsan 5000 1
lisi 3000 2
wangwu 1500 1
zhaoliu 11000 3# cat file
a b 1
c d 2
e f 3
g h 3
i j 2
获取第三字段最大值:
# awk 'BEGIN{max=0}{if($3>max)max=$3}END{print max}' file
3
打印第三字段最大行:
# awk 'BEGIN{max=0}{a[$0]=$3;if($3>max)max=$3}END{for(v in a)print v,a[v],max}' a
g h 3 3 3
e f 3 3 3
c d 2 2 3
a b 1 1 3
i j 2 2 3
# awk 'BEGIN{max=0}{a[$0]=$3;if($3>max)max=$3}END{for(v in a)if(a[v]==max)print v}' a
g h 3
e f 39)去除第一行和最后一行
# seq 5 |awk 'NR>2{print s}{s=$0}'
2
3
4读取第一行,NR=1,不执行 print s,s=1
读取第二行,NR=2,不执行 print s,s=2 (大于为真)
读取第三行,NR=3,执行 print s,此时 s 是上一次 p 赋值内容 2,s=3
最后一行,执行 print s,打印倒数第二行,s=最后一行
获取 Nginx 负载均衡配置端 IP 和端口:
# cat nginx.conf
upstream example-servers1 {
server 127.0.0.1:80 weight=1 max_fails=2 fail_timeout=30s;
}
upstream example-servers2 {
server 127.0.0.1:80 weight=1 max_fails=2 fail_timeout=30s;
server 127.0.0.1:82 backup;
}
# awk '/example-servers1/,/}/{if(NR>2){print s}{s=$2}}' nginx.conf
127.0.0.1:80
# awk '/example-servers1/,/}/{if(i>1)print s;s=$2;i++}' nginx.conf
# awk '/example-servers1/,/}/{if(i>1){print s}{s=$2;i++}}' nginx.conf
127.0.0.1:80读取第一行,i 初始值为 0,0>1 为假,不执行 print s,x=example-servers1,i=1
读取第二行,i=1,1>1 为假,不执行 print s,s=127.0.0.1:80,i=2
读取第三行,i=2,2>1 为真,执行 print s,此时 s 是上一次 s 赋值内容 127.0.0.1:80,i=3
最后一行,执行 print s,打印倒数第二行,s=最后一行。
这种方式与上面一样,只是用 i++作为计数器。
10)知道上述方式,就可以实现这种需求了,打印匹配行的上一行
# seq 5 |awk '/3/{print s}{s=$0}'
2详情,请参考:The GNU Awk User’s Guide
八、Shell标准输入与输出重定向
文件描述符(fd):文件描述符是一个非负整数,在打开现存文件或新建文件时,内核会返回一个
文件描述符,读写文件也需要使用文件描述符来访问文件。
内核为每个进程维护该进程打开的文件记录表。文件描述符只适于 Unix、Linux 操作系统。
① 标准输入、输出和错误

② 重定向符号


输入和输出可以被重定向符号解释到 shell。
shell 命令是从左到右依次执行命令。
下面 n 字母是文件描述符。
③ 重定向输出
一般格式:
[n]>word如果 n 没有指定,默认是 1
打印结果写到文件:
# echo "test" > a.txt
当没有安装 bc 计算器时,错误输出结果写到文件:
# echo "1 + 1" |bc 2 > error.log2)追加重定向输出
一般格式:
[n]>>word如果 n 没有指定,默认是 1。
示例:
打印结果追加到文件:
# echo "test" >> a.txt
当没有安装 bc 计算器时,错误输出结果追加文件:
# echo "1 + 1" |bc 2 > error.log④ 重定向输入
一般格式:
[n]如果 n 没有指定,默认是 0
示例:
a.txt 内容作为 grep 输入:
# grep "test" --color < a.txt⑤ 重定向标准输出和标准错误
当不确定执行对错时都覆盖到文件:
# echo "1 + 1" |bc &> error.log
当不确定执行对错时都覆盖到文件:
# echo "1 + 1" |bc > error.log 2>&12)追加重定向标准输出和标准错误
&>>word 等价于>>word 2>&1
示例:
当不确定执行对错时都追加文件:
# echo "1 + 1" |bc &>> error.log<< delimiter
here-document
delimiter从当前 shell 读取输入源,直到遇到一行只包含 delimiter 终止,内容作为标准输入。
将 eof 标准输入作为 cat 标准输出再写到 a.txt:
# cat << eof
123
abc
eof
123
abc
# cat > a.txt << eof
> 123
> abc
> eof⑥ 重定向到空设备
/dev/null 是一个空设备,向它写入的数组都会丢弃,但返回状态是成功的。与其对应的还有一个
/dev/zero 设备,提供无限的 0 数据流。
在写 Shell 脚本时我们经常会用到/dev/null 设备,将 stdout、stderr 输出给它,也就是我们不想
要这些输出的数据。
通过重定向到/dev/null 忽略输出,比如我们没有安装 bc 计算器,正常会抛出没有发现命令:
# echo "1 + 1" |bc >/dev/null 2>&1这就让标准和错误输出到了空设备。
忽略标准输出:
# echo "test" >/dev/null忽略错误输出:
# echo "1 + 1" |bc 2>/dev/null⑦ read 命令
read 命令从标准输入读取,并把输入的内容复制给变量。
命令格式:
read [-ers] [-a array] [-d delim] [-i text] [-n nchars] [-N nchars] [-p
prompt] [-t timeout] [-u fd] [name ...]
示例:
获取用户输入保存到变量:
# read -p "Please input your name: " VAR
Please input your name: lizhenliang
# echo $VAR
lizhenliang
用户输入保存为数组:
# read -p "Please input your name: " -a ARRAY
Please input your name: a b c # echo ${ARRAY[*]}
a b c
遇到 e 字符返回:
# read -d e VAR
123
456
e# echo $VAR
123 456
从文件作为 read 标准输入:
# cat a.txt
adfasfd
# read VAR < a.txt
# echo $VAR
adfasfd
while 循环读取每一行作为 read 的标准输入:
# cat a.txt |while read LINE; do echo $LINE; done
123
abc
分别变量赋值:
# read a b c 1 2 3 # echo $a
1
# echo $b
2
# echo $c
3# echo 1 2 3 | while read a b c;do echo "$a $b $c"; done
1 2 3九、Shell信号发送与捕捉
1、Linux 信号类型
信号(Signal):信号是在软件层次上对中断机制的一种模拟,通过给一个进程发送信号,执行相
应的处理函数。
进程可以通过三种方式来响应一个信号:
1)忽略信号,即对信号不做任何处理,其中有两个信号不能忽略:SIGKILL 及 SIGSTOP。
2)捕捉信号。
3)执行缺省操作,Linux 对每种信号都规定了默认操作。
Linux 究竟采用上述三种方式的哪一个来响应信号呢?取决于传递给响应的 API 函数。
Linux 支持的信号有:




CoreDump(核心转储):当程序运行过程中异常退出时,内核把当前程序在内存状况存储在一个
core 文件中,以便调试。执行命令 ulimit -c 如果是 0 则没有开启,也不会生成 core dump 文件,
可通过 ulimit -c unlimited 命令临时开启 core dump 功能,只对当前终端环境有效,如果想永久
生效,可修改/etc/security/limites.conf 文件,添加一行 "* soft core unlimited"
默认生成的 core 文件保存在可执行文件所在的目录下,文件名为 core。
如果想修改 core 文件保存路径,可通过修改内核参数:echo "/tmp/corefile-%e-%p-%t" > /proc/sys/kernel/core_pattern,则文件名格式为 core-命名名-pid-时间戳。
Linux 支持两种信号:
一种是标准信号,编号 1-31,称为非可靠信号(非实时),不支持队列,信号可能会丢失,比如发送多次相同的信号,进程只能收到一次,如果第一个信号没有处理完,第二个信号将会丢弃。
另一种是扩展信号,编号 32-64,称为可靠信号(实时),支持队列,发多少次进程就可以收到多
少次。
信号类型比较多,我们只要了解下,记住几个常用信号就行了,红色标记的我觉得需要记下。
发送信号一般有两种情况:
一种是内核检测到系统事件,比如键盘输入 CTRL+C 会发送 SIGINT 信号。另一种是通过系统调用 kill 命令来向一个进程发送信号。
2、kill 命令
kill 命令发送信号给进程。
命令格式:
kill [-s sigspec | -n signum | -sigspec] pid | jobspec ... kill -l [sigspec]
-s # 信号名称
-n # 信号编号
-l # 打印编号 1-31 信号名称示例:
给一个进程发送终止信号:
kill -s SIGTERM pid
或
kill -n 15 pid
或
kill -15 pid
或
kill -TREM pid3、trap 命令
trap 命令定义 shell 脚本在运行时根据接收的信号做相应的处理。
命令格式:
trap [-lp] [[arg] signal_spec ...]
-l # 打印编号 1-64 编号信号名称
arg # 捕获信号后执行的命令或者函数
signal_spec # 信号名或编号一般捕捉信号后,做以下几个动作:
1)清除临时文件
2)忽略该信号
3)询问用户是否终止脚本执行
示例 1:按 CTRL+C 不退出循环
#!/bin/bash
trap "" 2 # 不指定 arg 就不做任何操作,后面也可以写多个信号,以空格分隔
for i in {1..10}; do
echo $i
sleep 1
done
# bash a.sh
1
2
3
^C4
56
^C7
8
9
10#!/bin/bash
trap "echo 'exit...';exit" 2
for i in {1..10}; do
echo $i
sleep 1
done
# bash test.sh
1
2
3
^Cexit...示例 3:让用户选择是否终止循环
#!/bin/bash
trap "func" 2
func() {
read -p "Terminate the process? (Y/N): " input
if [ $input == "Y" ]; then
exit
fi
}
for i in {1..10}; do
echo $i
sleep 1
done
# bash a.sh
1
2
3
^CTerminate the process? (Y/N): Y
# bash a.sh
1
2
3
^CTerminate the process? (Y/N): N
4
5
6
...十、Shell编程时常用的系统文件
1、Linux 系统目录结构


2、环境变量文件
① 系统级
系统级变量文件对所有用户生效。
/etc/profile # 系统范围内的环境变量和启动文件。不建议把要做的事情写在这里面,最好创建
一个自定义的,放在/etc/profile.d 下。
/etc/bashrc # 系统范围内的函数和别名。
② 用户级
用户级变量文件对自己生效,都在自己家目录下:
~/.bashrc # 用户指定别名和函数
~/.bash_logout # 用户退出执行
~/.bash_profile # 用户指定变量和启动程序
~/.bash_history # 用户执行命令历史文件
开启启动脚本顺序:/etc/profile -> /etc/profile.d/*.sh -> ~/.bash_profile -> ~/.bashrc ->
/etc/bashrc
因此,我们可以把写的脚本放到以上文件里执行。
3、系统配置文件
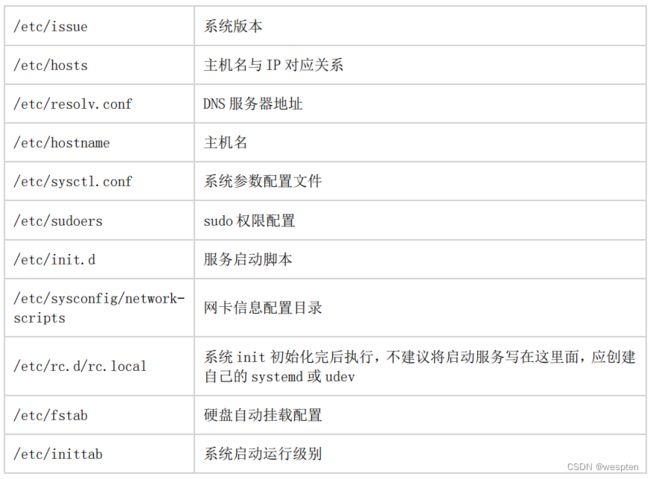
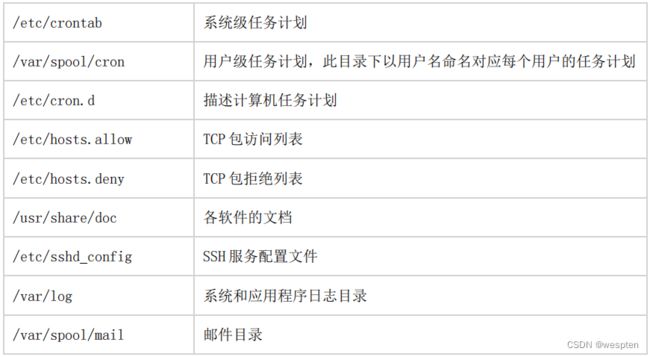
crontab 任务计划说明:
# Example of job definition:
# .---------------- minute (0 - 59)
# | .------------- hour (0 - 23)
# | | .---------- day of month (1 - 31)
# | | | .------- month (1 - 12) OR jan,feb,mar,apr ...
# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR
sun,mon,tue,wed,thu,fri,sat
# | | | | | # * * * * * user-name command to be executed4、/dev 目录

5、/proc 目录
1)/proc

2)/proc/net
/proc/net 目录存放的是一些网络协议信息。

![]()
3)/proc/sys
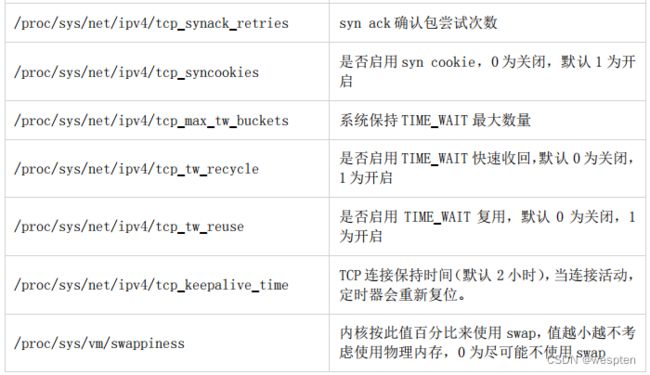
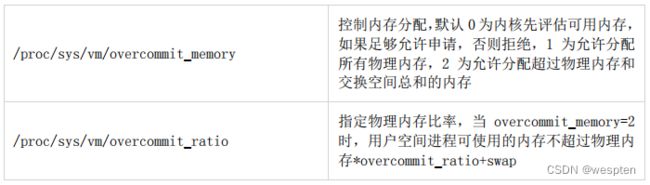
这个目录下的文件可被读写,存了大多数内核参数,可以修改改变内核行为。所以修改这些文件要特别小心,修改错误可能导致内核不稳定。
有四个主要的目录:
fs # 文件系统各方面信息,包括配额、文件句柄、inode 和目录项。
kernel # 内核行为的信息
net # 网络配置信息,包括以太网、ipx、ipv4 和 ipv6。
vm # Linux 内核的虚拟内存子系统,通常称为交换空间。

详情参考:E.3.9. /proc/sys/ Red Hat Enterprise Linux 6 | Red Hat Customer Portal
十一、Shell常用命令与工具
本节学习一些在编写 Shell 时的常用命令或工具及使用技巧。有人说 Shell 脚本是命令堆积的一
个文件,按顺序去执行。还有人说想学好 Shell 脚本,要把 Linux 上各种常见的命令或工具掌握
了,这些说法都没错。由于 Shell 语言本身在语法结构上比较简单,是面向过程编程,想实现复杂
的功能有点强人所难!
而且 Shell 本身又工作在 Linux 内核之上,在用户态调用 Linux 命令会很方面,所以大多数情况下我们都是依靠这些命令来完成脚本中的某些功能,比如文本处理、获取系统状态等等,然后通过 Shell 语法结构组织代码逻辑。不管是学 Linux 系统好还是写 Shell 脚本也好,有些命令都是必须要会的,以下是根据个人经验总结的一些常用的命令。
怎么更好的学习命令呢?
当然查看官方帮助文档了,可以通过 man cmd、cmd --help、help cmd、info cmd 等方式查看命令的使用。
1、ls
功能:列出目录内容。
常用选项:
-a 显示所有文件,包括隐藏的
-l 长格式列出信息
-i 显示文件 inode 号 -t 按修改时间排序
-r 按修改时间倒序排序
-h 打印易读大小单位示例:
按修改时间排序:
# ls -t
按修改时间倒序排序:
# ls -rt
长格式列出:
# ls -lh
查看文件 inode:
# ls -i file2、echo
功能:打印一行
常用选项:
-n 不加换行符
-e 解释转义符示例:
解释换行符。
# echo -e "1\n2\n3"
1
2
33、printf
功能:格式化打印数据。默认打印字符串不换行。
格式:
printf format [arguments]
一些常用的空白符:
\n 换行
\r 回车
\t 水平制表符示例:
输出一个字符:
# printf "%.1s" abc
a
保留一个小数点:
# printf "%.1f" 1.333
1.3
输出换行:
# printf "%.1f\n" 1.333
1.3
格式化输出:
# printf "user: %s\tpass: %d\n" abc 123
user: abc pass: 1
左对齐宽度 10: # printf "%-10s %-10s %-10s\n" ID Name Number
ID Name Number
右对齐宽度 10: # printf "%10s %10s %10s\n" ID Name Number
ID Name Number
每段对齐:
# printf "%10s\n" ID Name Number
ID
Name
Number
# printf "%-10s\n" ID Name Number
ID
Name
Number4、cat
功能:连接文件和标准输出打印。
常用选项:
-b 显示非空行行号
-n 显示所有行行号
-T 显示 tab,用^I 表示
-E 显示以$结尾示例:
连接两个文件:
# cat a b # cat << EOF
> 123
> abc
> EOF
123
abc
将 eof 标准输入作为 cat 标准输出再写到 a.txt: # cat > a.txt << eof
> 123
> abc
> eof5、tac
# tac a.txt6、rev
# echo "123" |rev
3217、wc
-c 打印文件字节数,一个英文字母 1 字节,一个汉字占 2-4 字节(根据编码)
-m 打印文件字符数,一个汉字占 2 个字符
-l 打印多少行
-L 打印最长行的长度,也可以统计字符串长度示例:
统计文件多少行:
# wc -l file
统计字符串长度:
# echo "hello" |wc -L
58、cp
功能:复制文件或目录。
常用选项:
-a 归档
-b 目标文件存在创建备份,备份文件是文件名跟~ -f 强制复制文件或目录
-r 递归复制目录
-p 保留原有文件或目录属性
-i 覆盖文件之前先询问用户
-u 当源文件比目的文件修改时间新时才复制
-v 显示复制信息示例:
复制目录:
# cp -rf test /opt9、mkdir
功能:创建目录。
常用选项:
-p 递归创建目录
-v 显示创建过程示例:
创建多级目录:
# mkdir /opt/test/abc
创建多个目录:
# mkdir {install,tmp}
创建连续目录:
# mkdir {a..c}10、mv
-b 目标文件存在创建备份,备份文件是"文件名后跟~"
-u 当源文件比目的文件修改时间新时才移动
-v 显示移动信息示例:
移动文件:
# mv a.txt /opt
重命名文件:
# mv a.txt b.txt11、rename
功能:重命名文件,支持通配符。
示例:批量命名文件
将 foo1-foo9 替换为 foo01-foo09:
# rename foo foo0 foo?
将以.htm 后缀的文件替换为.html:
# rename .htm .html *.htm12、dirname
功能:去除路径的最后一个名字。
示例:
# dirname /usr/bin/
/usr
# dirname dir1/str dir2/str
dir1
dir2
# dirname stdio.h
.13、basename
功能:打印路径的最后一个名字。
常用选项:
-a 支持多个参数
-s 删除后面的后缀示例:
# basename /usr/bin/sort
sort
# basename include/stdio.h .h
stdio
# basename -s .h include/stdio.h
stdio
# basename -a any/str1 any/str2
str1
str214、du
功能:估算文件磁盘空间使用。
常用选项:
-h 易读格式显示(K,M,G) -b 单位 bytes 显示
-k 单位 KB 显示
-m 单位 MB 显示
-s 只显示总大小
--max-depth=<目录层数>,超过层数的目录忽略
--exclude=file 排除文件或目录
--time 显示大小和创建时间示例:
查看目录大小:
# du -sh /opt
排除目录某个文件:
# du -sh --exclude=test /opt15、cut
功能:选取文件的每一行数据。
常用选项:
-b 选中第几个字符
-c 选中多少个字符
-d 指定分隔符分字段,默认是空格
-f 显示选中字段示例:
打印 b 字符:
# echo "abc" |cut -b "2"
b
截取 abc 字符:
# echo "abcdef" |cut -c 1-3
abc
以冒号分隔,显示第二个字段:
# echo "a:b:c" |cut -d: -f2
b16、tr
功能:替换或删除字符。
格式:
Usage: tr [OPTION]... SET1 [SET2]常用选项:
-c 替换 SET1 没有 SET2 的字符
-d 删除 SET1 中字符
-s 压缩 SET1 中重复的字符
-t 将 SET1 用 SET2 转换,默认示例:
替换 SET1 没有 SET2 的字符:
# echo "aaabbbccc" | tr -c c 1
111111ccc
去重字符:
# echo "aaacccddd" | tr -s '[a-z]'
acd
删除字符:
# echo "aaabbbccc" | tr -d bbb
aaaccc
删除换行符:
# echo -e "a\nb\nc" | tr -d '\n'
abc
替换字符:
# echo "aaabbbccc" | tr '[a-z]' '[A-Z]'
AAABBBCCC17、stat
-Z 显示 selinux 安全上下文
-f 显示文件系统状态
-c 指定格式输出内容
-t 以简洁的形式打印示例:
显示文件信息:
# stat file
只显示文件修改时间:
# stat -c %y file18、seq
功能:打印序列化数字。
常用选项:
-f 使用 printf 样式格式
-s 指定换行符,默认是\n -w 等宽,用 0 填充示例:
数字序列:
# seq 3
1
2
3
带0的数字序列:
# seq -w 03
01
02
03
范围数字序列:
# seq 2 5
2
3
4
5
步长序列:
# seq 1 2 5 # 2 是步长
1
3
5
以冒号分隔序列:
# seq -s "+" 5
1+2+3+4+5
等宽并在数字前面加字符串:
# seq -f "str%02g" 3 # %g 是默认数字位数,02 是数字不足 2 位时用 0 填充。
str01
str02
str0319、shuf
功能:生成随机序列。
常用选项:
-i 输出数字范围
-o 结果写入文件示例:
输出范围随机数。
# seq 5 |shuf
2
1
5
4
3
# shuf -i 5-10
8
10
7
9
6
520、sort
功能:排序文本,默认对整列有效。
常用选项:
-f 忽略字母大小写
-M 根据月份比较,比如 JAN、DEC
-h 根据易读的单位大小比较,比如 2K、1G
-g 按照常规数值排序
-n 根据字符串数值比较
-r 倒序排序
-k 位置 1,位置 2 根据关键字排序,在从第位置 1 开始,位置 2 结束
-t 指定分隔符
-u 去重重复行
-o 将结果写入文件示例:
随机数字排序:
# seq 5 |shuf |sort
随机字母排序:
# printf "%c\n" {a..f} |shuf |sort
倒序排序:
# seq 5 |shuf |sort -r
分隔后的字段排序:
# cat /etc/passwd |sort -t : -k 3 -n
去重重复行:
# echo -e "1\n1\n2\n3\n3" |sort -u
大小单位排序:
# du -h |sort -k 1 -h -r
分隔后第一个字段的第二个字符排序:
# echo -e "fa:1\neb:2\ncc:3" |sort -t : -k 1.2
tab 作为分隔符:
# sort -t $"\t"
file 文件内容:
zhangsan 6 100
lisi 8 80
wangwu 7 90
zhaoliu 9 70
对 file 文件的第二列正序排序,再次基础再对第三列倒序排序(多列排序):
# sort -k 2,2 -n -k 3,3 -nr file
# sort -k 2 -n -k 3 -nr file
zhaoliu 9 70
lisi 8 80
wangwu 7 90
zhangsan 6 100
对两个文件同时排序:
# sort file1 file221、uniq
功能:去除重复行,只会统计相邻的。
常用选项:
-c 打印出现的次数
-d 只打印重复行
-u 只打印不重复行
-D 只打印重复行,并且把所有重复行打印出来
-f N 比较时跳过前 N 列 -i 忽略大小写
-s N 比较时跳过前 N 个字符
-w N 对每行第 N 个字符以后内容不做比较示例:
测试文本如下:
# cat file
abc
cde
xyz
cde
xyz
abd
去重复行:
# sort file |uniq
abc
abd
cde
xyz
打印每行重复次数:
# sort file |uniq -c
1 abc
1 abd
2 cde
2 xyz
打印不重复行:
# sort file |uniq -u
abc
abd
打印重复行:
# sort file |uniq -d
cde
xyz
打印重复行并统计出现次数:
# sort file |uniq -d -c
2 cde
2 xyz
根据前几个字符去重:
# sort file |uniq -w 2
abc
cde
xyz22、tee
功能:从标准输入读取写到标准输出和文件。
常用选项:
-a 追加到文件示例:
打印并追加到文件:
# echo 123 |tee -a a.log23、join
功能:连接两个文件。
常用选项:
-i 忽略大小写
-o 按照指定文件栏位显示
-t 使用字符作为输入和输出字段分隔符示例:
# cat file1
1 a
2 b
3 c
# cat file2
1 x
2 y
3 z
将两个文件相同字段合并一列: # join file1 file2
1 a x
2 b y
3 c z
打印 file1 第二列和 file2 第二列:
# join -o 1.2 2.2 file1 file2
a x
b y
c z
# join -t ':' -o 1.1 2.1 /etc/passwd /etc/shadow
user1:user1
……24、paste
功能:合并文件。
常用选项:
-d 指定分隔符,默认是 tab 键分隔
-s 将文件内容平行合并,默认 tab 键分隔示例:
# seq 1 3 > file1
# seq 4 6 > file2
两个文件合并:
# paste file1 file2
1 4
2 5
3 6
两个文件合并,+号分隔:
# paste -d "+" file1 file2
1+4
2+5
3+6
文件内容平行显示:
# paste -s file1 file2
1 2 3
4 5 625、head
-c 打印前多少 K,M
-n 打印前多少行示例:
打印文件前 50 行:
# head -n 50 file26、tail
功能:输出文件的后几行。
常用选项:
-c 打印后多少 K,M -f 实时读文件,随着文件输出附加输出
-n 输出最后几行
--pid 与-f 一起使用,表示 pid 死掉后结束
-s 与-f 一起使用,表示休眠多少秒输出示例:
打印文件后 50 行:
# tail -n 50 file
实时输出新增行:
# tail -f file27、find
功能:目录层次结构中搜索文件。
格式:
find path -option actions常用选项:
-name 文件名,支持(‘*’, ‘?’) -type 文件类型,d 目录,f 常规文件等
-perm 符合权限的文件,比如 755
-atime -/+n 在 n 天以内/过去 n 天被访问过
-ctime -/+n 在 n 天以内/过去 n 天被修改过
-amin -/+n 在 n 天以内/过去 n 分钟被访问过
-cmin -/+n 在 n 天以内/过去 n 分钟被修改过
-size -/+n 文件大小小于/大于,b、k、M、G -maxdepth levels 目录层次显示的最大深度
-regex pattern 文件名匹配正则表达式模式
-inum 通过 inode 编号查找文件
动作:
-detele 删除文件
-exec command {} \; 执行命令,花括号代表当前文件
-ls 列出当前文件,ls -dils 格式
-print 完整的文件名并添加一个回车换行符
-print0 打印完整的文件名并不添加一个回车换行符
-printf format 打印格式
其他字符:
! 取反
-or/-o 逻辑或 -and 逻辑和示例:
查找文件名:
# find / -name "*http*"
查找文件名并且文件类型:
# find /tmp -name core -type f -print
查找文件名并且文件类型删除:
# find /tmp -name core -type f -delete
查找当前目录常规文件并查看文件类型:
# find . -type f -exec file '{}' \;
查找文件权限是 664: # find . -perm 664
查找大于 1024k 的文件:
# find . -size -1024k
查找 3 天内修改的文件:
# find /bin -ctime -3
查找 3 分钟前修改的文件:
# find /bin -cmin +3
排除多个类型的文件:
# find . ! -name "*.sql" ! -name "*.txt"
或条件查找多个类型的文件:
# find . -name '*.sh' -o -name '*.bak'
# find . -regex ".*\.sh\|.*\.bak"
# find . -regex ".*\.\(sh\|bak\)"
并且条件查找文件:
# find . -name "*.sql" -a -size +1024k
只显示第一级目录:
# find /etc -type d -maxdepth 1
通过 inode 编号删除文件:
# rm `find . -inum 671915`
# find . -inum 8651577 -exec rm -i {} \;28、xargs
功能:从标准输入执行命令。
常用选项:
-a file 从指定文件读取数据作为标准输入
-0 处理包含空格的文件名,print0
-d delimiter 分隔符,默认是空格分隔显示
-i 标准输入的结果以{}代替
-I 标准输入的结果以指定的名字代替
-t 显示执行命令
-p 交互式提示是否执行命令
-n 最大命令行参数
--show-limits 查看系统命令行长度限制示例:
删除/tmp 下名字是 core 的文件:
# find /tmp -name core -type f -print | xargs /bin/rm -f # find /tmp -name core -type f -print0 | xargs -0 /bin/rm -f
列转行(去除换行符 ):
# cut -d: -f1 < /etc/passwd | sort | xargs echo
行转列:
# echo "1 2 3 4 5" |xargs -n1
最长两列显示:
# echo "1 2 3 4 5" |xargs -n2
创建未来十天时间:
# seq 1 10 |xargs -i date -d "{} days " +%Y-%m-%d
复制多个目录:
# echo dir1 dir2 |xargs -n1 cp a.txt
清空所有日志:
# find ./ -name "*.log" |xargs -i tee {} # echo ""> {} 这样不行,>把命令中断了
rm 在删除大量的文件时,会提示参数过长,那么可以使用 xargs 删除:
# ls |xargs rm –rf
或分配删除 rm [a-n]* -rf # getconf ARG_MAX 获取系统最大参数限制29、nl
功能:打印文件行号。
常用选项:
-b 指定行号显示方式,a 表示所有行都打印行号,b 表示空行不显示行号,默认是 a -n 行号显示方法,ln 左对齐,rn 右对齐,rz 右边显示,左边空白用 0 填充。
-w 行号栏位在左边占用的宽度 示例:
打印行号,空行不显示:
# nl a.txt
左对齐打印行号:
# nl -n ln a.txt
行号右移动五个空格:
# nl -w 5 a.txt30、date
功能:打印或设置系统日期和时间。
常用选项:
-d string 显示指定字符串所描述的时间,而非当前时间
-f datefile 从日期文件中按行读入时间描述
-I 输出 ISO 8601 格式的日期和时间
-r 显示文件的最后修改时间
-R 输出 RFC 2822 格式的日期和时间
-s string 设置时间所描述的字符串
-u 打印或设置 UTC 时间控制输出格式:
%% 一个文字的 %
%a 当前 locale 的星期名缩写(例如: 日,代表星期日)
%A 当前 locale 的星期名全称 (如:星期日)
%b 当前 locale 的月名缩写 (如:一,代表一月)
%B 当前 locale 的月名全称 (如:一月)
%c 当前 locale 的日期和时间 (如:2005 年 3 月 3 日 星期四 23:05:25)
%C 世纪;比如 %Y,通常为省略当前年份的后两位数字(例如:20)
%d 按月计的日期(例如:01)
%D 按月计的日期;等于%m/%d/%y
%e 按月计的日期,添加空格,等于%_d
%F 完整日期格式,等价于 %Y-%m-%d
%g ISO-8601 格式年份的最后两位 (参见%G)
%G ISO-8601 格式年份 (参见%V),一般只和 %V 结合使用
%h 等于%b
%H 小时(00-23)
%I 小时(00-12)
%j 按年计的日期(001-366)
%k 时(0-23)
%l 时(1-12)
%m 月份(01-12)
%M 分(00-59)
%n 换行
%N 纳秒(000000000-999999999)
%p 当前 locale 下的"上午"或者"下午",未知时输出为空
%P 与%p 类似,但是输出小写字母
%r 当前 locale 下的 12 小时时钟时间 (如:11:11:04 下午)
%R 24 小时时间的时和分,等价于 %H:%M
%s 自 UTC 时间 1970-01-01 00:00:00 以来所经过的秒数
%S 秒(00-60)
%t 输出制表符 Tab
%T 时间,等于%H:%M:%S
%u 星期,1 代表星期一
%U 一年中的第几周,以周日为每星期第一天(00-53)
%V ISO-8601 格式规范下的一年中第几周,以周一为每星期第一天(01-53)
%w 一星期中的第几日(0-6),0 代表周一
%W 一年中的第几周,以周一为每星期第一天(00-53)
%x 当前 locale 下的日期描述 (如:12/31/99)
%X 当前 locale 下的时间描述 (如:23:13:48)
%y 年份最后两位数位 (00-99)
%Y 年份示例:
设置系统日期和时间:
# date -s "2016-12-15 00:00:00"
查看当前系统时间戳:
# date +%s
查看当前系统时间:
# date +'%F %T'
把日期和时间转换成时间戳:
# date -d "2016-12-15 18:00:00" +%s
把时间戳转成时间:
# date -d '@1481842800' '+%F %T'
时间加减:
显示前 30 秒:date -d '-30 second' +'%F %T'
显示前一分钟:date -d '-1 minute' +'%F %T'
显示前一个时间:date -d '-1 hour' +'%F %T'
显示前一个天:date -d '-1 day' +'%F %T'
显示上一周:date -d '-1 week' +'%F %T'
显示上一个月日期:date -d '-1 month' +%F
显示上一年日期:date -d '-1 year' +%F
或
显示前一天日期:date -d yesterday +%F
显示后一天日期:date -d tomorrow +%F
时间比较:
NOW_DATE=$(date +%s)
AGO_DATE=$(date -d "2016-12-15 18:00:00" +%s)
[ $NOW_DATE -gt $AGO_DATE ] && echo yes || echo no31、wget
功能:非交互式网络下载,类似于 HTTP 客户端。
常用选项:
-b, --background 后台运行日志记录和输入文件:
-o, --output-file=FILE 日志写到文件
-a, --append-output=FILE 日志追加到文件
-d, --debug 打印 debug 信息,会包含头信息
-q, --quiet 退出,不输出
-i, --input-file=FILE 从文件中读取 URL 下载 下载选项:
-t, --tries=NUMBER 设置链接重试次数
-O, --output-document=FILE 写入内容到文件
-nc, --no-clobber 跳过下载现有的文件
-c, --continue 断点续传
--progress=TYPE 设置进度条(dot 和 bar) -S, --server-response 打印服务器响应头信息
--spider 不下载任何内容
-T, --timeout=SECONDS 设置相应超时时间(还有--dns-timeout、--connect-timeout 和
--read-timeout) -w, --wait=SECONDS 两次重试间隔等待时间
--bind-address=ADDRESS 设置绑定地址
--limit-rate=RATE 限制下载速度
--user=USER 设置 ftp 和 http 用户名
--password=PASS 设置 ftp 和 http 密码目录:
-P, --directory-prefix=PREFIX 保存文件目录HTTP 选项:
--http-user=USER 设置 http 用户名
--http-password=PASS 设置 http 密码
--proxy-user=USER 设置代理用户名
--proxy-password=PASS 设置代理密码
--referer=URL 设置 Referer
--save-headers 保存头到文件
--default-page=NAME 改变默认页面名字,默认 index.html
-U,--user-agent=AGENT 设置客户端信息
--no-http-keep-alive 禁用 HTTP keep-alive(长连接)
--load-cookies=FILE 从文件加载 cookies
--save-cookies=FILE 保存 cookies 到文件
--post-data=STRING 使用 POST 方法,发送数据FTP 选项:
--ftp-user=USER 设置 ftp 用户名
--ftp-password=PASS 设置 ftp 密码
--no-passive-ftp 禁用被动传输模式递归下载:
-r, --recursive 指定递归下载
-l, --level=NUMBER 最大递归深度
-A, --accept=LIST 逗号分隔下载的扩展列表
-R, --reject=LIST 逗号分隔不被下载的扩展列表
-D, --domains=LIST 逗号分隔被下载域的列表
--exclude-domains=LIST 排除不被下载域的列表示例:
下载单个文件到当前目录:
# wget http://nginx.org/download/nginx-1.11.7.tar.gz
放到后台下载:
# wget -b http://nginx.org/download/nginx-1.11.7.tar.gz
对于网络不稳定的用户使用-c 和--tries 参数,保证下载完成,并下载到指定目录:
# wget -t 3 -c http://nginx.org/download/nginx-1.11.7.tar.gz -P down
不下载任何内容,判断 URL 是否可以访问:
# wget --spider http://nginx.org/download/nginx-1.11.7.tar.gz
下载内容写到文件:
# wget http://www.baidu.com/index.html -O index.html
从文件中读取 URL 下载:
# wget -i url.list
下载 ftp 文件:
# wget --ftp-user=admin --ftp-password=admin ftp://192.168.1.10/ISO/CentOS-6.5-i386-
minimal.iso
伪装客户端,指定 user-agent 和 referer 下载:
# wget -U "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/44.0.2403.157 Safari/537.36" --referer "http://nginx.org/en/download.html"
http://nginx.org/download/nginx-1.11.7.tar.gz
查看 HTTP 头信息:
# wget -S http://nginx.org/download/nginx-1.11.7.tar.gz
# wget --debug http://nginx.org/download/nginx-1.11.7.tar.gz32、curl
功能:发送数据到 URL,类似于 HTTP 客户端。
常用选项:
-k, --insecure 允许 HTTPS 连接网站
-C, --continue-at 断点续传
-b, --cookie STRING/FILE 从文件中读取 cookie
-c, --cookie-jar 把 cookie 保存到文件
-d, --data 使用 POST 方式发送数据
--data-urlencode POST 的数据 URL 编码
-F, --form 指定 POST 数据的表单
-D, --dump-header 保存头信息到文件
--ftp-pasv 指定 FTP 连接模式 PASV/EPSV
-P, --ftp-port 指定 FTP 端口
-L, --location 遵循 URL 重定向,默认不处理
-l, --list-only 指列出 FTP 目录名
-H, --header 自定义头信息发送给服务器
-I, --head 查看 HTTP 头信息
-o, --output FILE 输出到文件
-#, --progress-bar 显示 bar 进度条
-x, --proxy [PROTOCOL://]HOST[:PORT] 使用代理
-U, --proxy-user USER[:PASSWORD] 代理用户名和密码
-e, --referer 指定引用地址 referer
-O, --remote-name 使用远程服务器上名字写到本地
--connect-timeout 连接超时时间,单位秒
--retry NUM 连接重试次数
--retry-delay 两次重试间隔等待时间
-s, --silent 静默模式,不输出任何内容
-Y, --speed-limit 限制下载速率
-u, --user USER[:PASSWORD] 指定 http 和 ftp 用户名和密码
-T, --upload-file 上传文件
-A, --user-agent 指定客户端信息示例:
下载页面:
# curl -o badu.html http://www.baidu.com
不输出下载信息:
# curl -s -o baidu.html http://www.baidu.com
伪装客户端,指定 user-agent 和 referer 下载:
# curl -A "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/44.0.2403.157 Safari/537.36" -e "baike.baidu.com" http://127.0.0.1
模拟用户登录,并保存 cookies 到文件:
# curl -c ./cookies.txt -F NAME=user -F PWD=123 http://www.example.com/login.html
使用 cookie 访问:
# curl -b cookies.txt http://www.baidu.com
访问 HTTP 认证页面:
# curl -u user:pass http://www.example.com
FTP 上传文件:
# curl -T filename ftp://user:pass@ip/a.txt
# curl ftp://ip -u user:pass-T filename
FTP 下载文件:
# curl -O ftp://user:pass@ip/a.txt
# curl ftp://ip/filename -u user:pass -o filename
FTP 下载多个文件:
# curl ftp://ip/img/[1,3,5].jpg
查看 HTTP 头信息:
# curl -I http://www.baidu.com32、scp
功能:基于 SSH 的安全远程服务器文件拷贝。
常用选项:
-i 指定私钥文件
-l 限制速率,单位 Kb/s,1024Kb=1Mb
-P 指定远程主机 SSH 端口
-p 保存修改时间、访问时间和权限
-r 递归拷贝目录
-o SSH 选项,有以下几个比较常用的:
ConnectionAttempts=NUM 连接失败后重试次数
ConnectTimeout=SEC 连接超时时间
StrictHostKeyChecking=no 自动拉去主机 key 文件
PasswordAuthentication=no 禁止密码认证示例:
本地目录推送到远程主机:
# scp -P 22 -r src_dir [email protected]:/dst_dir
远程主机目录拉取到本地:
# scp -P 22 -r [email protected]:dst_dir src_dir
同步文件方式一样,不用加-r 参数34、rsync
功能:远程或本地文件同步工具。
常用选项:
-v 显示复制信息
-q 不输出错误信息
-c 跳过基础效验,不判断修改时间和大小
-a 归档模式,等效-rlptgoD,保留权限、属组等
-r 递归目录
-l 拷贝软连接
-z 压缩传输数据
-e 指定远程 shell,比如 ssh、rsh
--progress 进度条,等同-P
--bwlimit=KB/s 限制速率,0 为没有限制
--delete 删除那些 DST 中 SRC 没有的文件
--exclude=PATTERN 排除匹配的文件或目录
--exclude-from=FILE 从文件中读取要排除的文件或目录
--password-file=FILE 从文件读取远程主机密码
--port=PORT 监听端口示例:
本地复制目录:
# rsync -avz abc /opt
本地目录推送到远程主机:
# rsync -avz SRC [email protected]:DST
远程主机目录拉取到本地:
# rsync -avz [email protected]:SRC DST
保持远程主机目录与本地一样:
# rsync -avz --delete SRC [email protected]:DST
排除某个目录:
# rsync -avz --exclude=no_dir SRC [email protected]:DST
指定 SSH 端口:
# rsync -avz /etc/hosts -e "ssh -p22" [email protected]:/opt35、nohup
功能:运行程序,忽略挂起信号。
示例:
后台运行程序,终端关闭不影响:
# nohup bash test.sh &>test.log &36、iconv
功能:将文件内容字符集转成其他字符集。
常用选项:
-l 列出所有已知的字符集
-f 原始文本编码
-t 输出编码
-o 输出到文件
-s 关闭警告示例:
将文件内容转换 UTF8:
# iconv -f gbk -t utf8 old.txt -o new.txt
将 csv 文件转换 GBK:
# iconv -f utf8 -t gbk old.txt -o new.txt
解决邮件乱码:
# echo $(echo "content" | iconv -f utf8 -t gbk) | mail -s "$(echo "title" | iconv -f
utf8 -t gbk)" [email protected]37、uname
功能:输出系统信息。
常用选项:
-a 输出以下所有信息
-s 输出内核名称
-n 输出主机名
-r 输出内核发行版
-v 输出内核版本
-m 输出主机的硬件架构名称
-p 输出处理器类型或"unknown"
-i 输出硬件平台或"unknown
-o 输出操作系统名称示例:
输出所有系统信息:
# uname -a
输出主机名:
# uname -a
输出内核版本:
# uname -r
输出操作系统:
# uname -o38、sshpass
功能:非交互 SSH 登录(需要安装)。
常用选项:
-f 从文件中获取密码
-d 用文件描述符数字获取密码
-p 指定 SSH 密码
-e 密码作为环境变量传递,变量名是 SSHPASS示例:
免交互 SSH 登录:
# sshpass -p 123456 ssh [email protected]
免交互传输文件:
# sshpass -p 123456 scp a.txt 192.168.1.10:/root
密码传入系统变量:
# SSHPASS=123456 rsync -avz /etc/hosts -e "sshpass -e ssh" [email protected]:/opt39、tar
功能:归档目录或文件。
常用选项:
-c 创建新归档
-d 比较归档和文件系统的差异
-r 追加文件到归档
-t 存档的内容列表
-x 提取归档所有文件
-C 改变解压目录
-f 使用归档文件或设备归档
-j bzip2 压缩
-z gzip 压缩
-v 输出处理过程示例:
创建归档文件来自 foo 和 bar:
# tar -cf archive.tar foo bar
提取归档的所有文件:
# tar -xf archive.tar
列出所有归档文件内容:
# tar -tvf archive.tar
创建归档并 gzip 压缩:
# tar -zcvf archive.tar.gz log
提取归档文件并 gzip 解压:
# tar -zxvf log.tar.gz
创建归档并 bzip2 压缩:
# tar -jcvf log.tar.bz log
提取归档并解压到指定目录:
# tar -zxvf log.tar.gz -C /opt40、logger
功能:系统日志的 shell 命令行接口。
常用选项:
-i 每行记录进程 ID
-f 指定输出日志到文件
-p 设置记录的优先级
-t 添加标签示例:
# logger -i -t "my_test" -p local3.notice "test_info"41、netstat
常用选项:
-r 显示路由表
-i 显示接口表
-n 不解析名字
-p 显示程序名 PID/Program
-l 显示监听的 socket
-a 显示所有 socket
-o 显示计时器
-Z 显示上下文
-t 只显示 tcp 连接
-u 只显示 udp 连接
-s 显示每个协议统计信息示例:
显示所有监听:
# netstat -anltu
显示所有 TCP 连接:
# netstat -antp
显示所有 UDP 连接:
# netstat -anup
显示路由表:
# netstat -r42、ss
功能:比 netstat 更强大的 socket 查看工具。
格式:
ss [options] [ FILTER ]常用选项:
-n 不解析名字
-a 显示所有 socket
-l 显示所有监听的 socket
-o 显示计时器
-e 显示 socket 详细信息
-m 显示 socket 内存使用
-p 显示进程使用的 socket
-i 显示内部 TCP 信息
-s 显示 socket 使用汇总
-4 只显示 IPV4 的 socket
-0 显示包 socket
-t 只显示 TCP socket
-u 只显示 UDP socket
-d 只显示 DCCP socket
-w 只显示 RAW socket
-x 只显示 Unix 域 socket
-f FAMILY 只显示 socket 族类型( unix, inet, inet6, link, netlink) -A 查询 socket {all|inet|tcp|udp|raw|unix|packet|netlink}[,QUERY]
-D 将原始的 TCP socket 转储到文件
-F 从文件中读取过滤信息
过滤:
-o state 显示 TCP 连接状态信息示例:
显示所有 TCP 连接:
# ss -t -a
显示所有 UDP 连接:
# ss -u –a
显示 socket 使用汇总:
# ss -s
显示所有建立的连接:
# ss -o state established
显示所有的 TIME-WAIT 状态:
# ss -o state TIME-WAIT
搜索所有本地进程连接到 X Server:
# ss -x src /tmp/.X11-unix/43、lsof
功能:列出打开的文件。
常用选项:
-i [i] 监听的网络地址,如果没有指定,默认列出所有。
[i]来自[46][protocol][@hostname|hostaddr][:service|port]
-U 列出 Unix 域 socket 文件
-p 指定 PID
-u 指定用户名或 UID 所有打开的文件
+D 递归搜索示例:
列出所有打开的文件:
# lsof
查看哪个进程占用文件:
# lsof /etc/passwd
列出所有打开的监听地址和 unix 域 socket 文件:
# lsof -i -U
列出 80 端口监听的进程:
# lsof -i:80
列出端口 1-1024 之间的所有进程:
# lsof -i:1-1024
列出所有 TCP 网络连接:
# lsof -i tcp
列出所有 UDP 网络连接:
# lsof -i udp
根据文件描述符列出打开的文件:
# lsof -d 1
列出某个目录被打开的文件:
# lsof +D /var/log
列出进程 ID 打开的文件:
# lsof -p 5373
打开所有登录用户名 abc 或 user id 1234,或 PID 123 或 PID 456:
# lsof -p 123,456 -u 123,abc
列出 COMMAND 列中包含字符串 sshd:
# lsof -c sshd44、ps
功能:报告当前进程的快照。
常用选项:
-a 显示所有进程
-u 选择有效的用户 ID 或名称
-x 显示无控制终端的进程
-e 显示所有进程
-f 全格式
-r 只显示运行的进程
-T 这个终端的所有进程
-p 指定进程 ID
--sort 对某列排序
-m 线程
-L 格式化代码列表
-o 用户自定义格式
CODE NORMAL HEADER
%C pcpu %CPU
%G group GROUP
%P ppid PPID
%U user USER
%a args COMMAND
%c comm COMMAND
%g rgroup RGROUP
%n nice NI
%p pid PID
%r pgid PGID
%t etime ELAPSED
%u ruser RUSER
%x time TIME
%y tty TTY
%z vsz VSZ示例:
打印系统上所有进程标准语法:
# ps -ef
打印系统上所有进程 BSD 语法:
# ps aux
打印进程树:
# ps axjf 或 ps -ejH
查看进程启动的线程:
# ps -Lfp PID
查看当前用户的进程数:
# ps uxm 或 ps -U root -u root u
自定义格式显示并对 CPU 排序:
# ps -eo user,pid,pcpu,pmem,nice,lstart,time,args --sort=-pcpu
或
ps -eo "%U %p %C %n %x %a"USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
USER 进程所有者
PID 进程 ID
%CPU 占用 CPU 时间
%MEM 物理内存
VSZ 虚拟内存大小(kb)
RSS 驻留集内存页数量(kb)
TTY 终端
STAT 进程状态;R 运行,S 休眠,D 不可中断,T 停止,Z 僵尸,N 表示普通优先级更低的优先级
START 进程启动时间
TIME 使用 CPU 总时间
COMMAND 命令名称和参数45、top
功能:动态显示活动的进程和系统资源利用率。
常用选项:
-d 信息刷新时间间隔
-p 只监控指定的进程 PID
-i 只显示正在使用 CPU 的进程
-H 显示线程
-u 只查看指定用户名的进程
-b 将输出编排成易处理格式,适合输出到文件处理
-n 指定最大循环刷新数交互命令:
f 添加或删除显示的指标
c 显示完整命令
P 按 CPU 使用百分比排序
M 按驻留内存大小排序
T 按进程使用 CPU 时间排序
1 显示每个 CPU 核心使用率
k 终止一个进程示例:
刷新一次并输出到文件:
# top -b -n 1 > top.log
只显示指定进程的线程:
# top -Hp 123
第一行:当前系统时间,系统运行了多长时间(9 天 22 小时 16 分钟),CPU 负载:1 分钟、5 分钟、15 分钟。
第二行:系统总共 178 个进程,3 个 CPU 正在处理,175 在休眠等待处理,0 个停止,0 个僵尸进程。
第三行:us 用户空间使用 CPU 时间 0.3%,sy 内核空间使用 CPU 时间 0.3%,ni 系统调整进程优先级。使用 CPU 时间 0.0%,id 空闲 CPU 时间 99.3%,wa 等待 I/O 响应 CPU 时间 0.0%,hi 硬中断,si 软中断。
第四行和第五行:物理内存与交换分区使用率。
第六行:
PID 进程 ID
USER 进程所有者
PR 进程优先级
NI 负值表示高优先级,正值表示低优先级
VIRT 进程启动后使用虚拟内存总量(KB),VIRT=SWAP+RES
RES 实际物理内存使用大小(KB),RES=CODE+DATA
SHR 共享内存大小(KB),可能与其他进程共享的内存;计算进程使用物理内存大小:RES-SHR
S 进程状态;R 运行,S 休眠,D 不可中断,T 停止,Z 僵尸
%CPU 上次更新到现在的 CPU 时间占用百分比
%MEM 使用物理内存百分比
TIME+ 使用 CPU 总时间
COMMAND 命令名称和参数
46、free
功能:查看内存使用率。
常用选项:
-b bytes 显示
-k KB 显示
-m M 显示
-g G 显示
-h 易读单位显示
-s 每几秒重复打印
-c 重复打印几次退出示例:
查看物理内存:
# free -m
易读单位显示:
# free -h47、df
功能:查看文件系统的磁盘空间使用情况。
常用选项:
-a 包含虚拟文件系统
-h 可易读单位显示
-i 显示 inode 信息而非块使用量
-k 1K 块的数量
-t 只显示指定文件系统为指定类型的信息
-T 显示文件系统类型示例:
查看所有文件系统:
# df -ah
输出指定文件系统:
# df -t xfs48、vmstat
功能:报告虚拟内存、swap、io、上下文和 CPU 统计信息。
分析了这些文件:
/proc/meminfo
/proc/stat
/proc/*/stat常用选项:
-a 打印活跃和不活跃的内存页
-d 打印硬盘统计信息
-D 打印硬盘表
-p 打印硬盘分区统计信息
-s 打印虚拟内存表
-m 打印内存分配(slab)信息
-t 添加时间戳到输出
-S 显示单位,默认 k、KB、m、M,大写是*1024示例:
每秒刷新一次,统计五次:
# vmstat -t 1 5
r:CPU 正在运行的进程数
b:在等待 I/O 的进程数
swpd:已经使用的交换内存(kb)
free:空闲的物理内存(kb)
buff:已经使用的缓冲区内存(kb);一般对设备数据缓存,写入到磁盘的数据。
cache:已经使用的缓冲区内存(kb);一般对文件数据缓存,从磁盘读取的数据。
si:从磁盘交换到内存的交换页数量(kb/s)
so:从内存交换到磁盘的交换页数据(kb/s)
bi:块设备接收的块数量(kb/s)
bo:块设备发送的块数量(kb/s)
in:每秒 CPU 中断次数
cs:每秒 CPU 上下文切换次数
us:用户进程使用 CPU 时间(%)
sy:系统进程使用 CPU 时间(%)
id:CPU 空闲时间(%)
wa:等待 I/O 响应所消耗的 CPU 时间(%)
st:从虚拟设备中获得的时间(%)
49、iostat
功能:报告 CPU 利用率和磁盘 I/O。
用法:
iostat [ 选项 ] [ <时间间隔> [ <次数> ] ]常用选项:
-c 显示 CPU 使用率
-d 只显示磁盘使用率
-k 单位 KB/s 代替 Block/s
-m 单位 MB/s 代替 Block/s
-N 显示所有映射设备名字
-t 打印报告时间
-x 显示扩展统计信息示例:
显示 CPU 使用率:
# iostat -c 1 3
显示 I/O 磁盘统计信息:
# iostat -d -x -k 1 3 # 间隔 1 秒,输出 3 次50、sar
功能:查看系统资源综合方面利用率。
常用选项:
-u, CPU
-r, memory
-b, disk
-n DEV, NIC traffic
-q, systemload
-b, TPS(Transaction Per Second,每秒事务处理量)
-o, output to file示例:
# sar -u 2 3 #每两秒执行一次,采集三次
# sar -u 2 3 -o cpu.out
# sar -f cpu.out #读取文件51、dstat
-c cpu 统计
-d 磁盘统计
-m 内存统计
-n 网络统计
-s swap 统计
-l 负载统计
--tcp tcp 状态统计
--udp udp 状态统计
--socket socket 数量统计
-t 输出时间
--output 写入 csv 文件插件:
--list
支持的插件
--top-bio-adv
详细显示 I/O 进程写入 block 量,包括 pid、r、w 和 cpu
--top-io-adv
进程写入磁盘总量
--top-cpu
占用 CPU 进程
--top-cpu-adv
查看最高 CPU 进程
--top-mem
内存进程示例:
查看 CPU 利用率:
# dstat -c
查看 TCP 连接状态:
# dstat --tcp52、ip
功能:查看/操作路由表、设备、路由策略和隧道。
格式:
ip [ OPTIONS ] OBJECT { COMMAND | help }常用选项:
-b, -batch 从文件或标准输入读取命令并调用他们,第一次失败将终止
-force 批量模式有错误不终止,如果有错误则状态返回非 0 -s, -statistics 输出更多的统计信息
-l, -loops 指定最大的循环数 操作对象(OBEJECT):
address 网络设备地址
12tp 以太网 IP 隧道
link 配置网络设备
maddress 多播地址
monitor 动态监控网络连接
mroute 多播路由缓存条目
mrule 角色在多播路由策略数据库
neighbour 管理 ARP 或 NDISC 缓存条目
netns 管理网络命名空间
ntable 管理 neighbour 缓存操作
route 路由表
rule 角色在路由策略数据库
tpc_metrics/tcpmetrics 管理 TCP 指标
tunnel IP 隧道
tuntap 管理 TUN/TAP 设备
xfrm 管理 IPSec 策略
可通过 ip OBEJECT help 再查看对象的操作方法。示例:
查看网络设备地址:
# ip addr
查看网卡统计信息:
# ip -s link
查看单个网卡统计信息:
# ip -s link ls eth0
查看 ARP 缓存表:
# ip neighbour
查看路由表:
# ip route
查看路由策略:
# ip rule
网卡设置/删除 IP:
# ip addr add/del 192.168.1.201/24 dev eth0
添加/删除默认路由:
# ip route add default via 192.168.1.1 dev eth0
# ip route del 192.168.1.0/24 via 192.168.1.1
添加静态路由:
# ip route add 172.17.2.0/24 via 192.168.2.1 dev eth0
开启/关闭网卡:
# ip link set dev eth0 up/down
设置最大传输单元:
# ip link set dev eth0 mtu 1500
设置 MAC 地址:
# ip link set dev eth0 address 00:0c:29:52:73:8e53、nc
功能:TCP 和 UDP 连接和监听。
常用选项:
-i interval 指定间隔时间发送和接受行文本
-l 监听模式,管理传入的连接
-n 不解析域名
-p 指定本地源端口
-s 指定本地源 IP 地址
-u 使用 udp 协议,默认是 tcp
-v 执行过程输出
-w timeout 连接超时时间
-x proxy_address[:port] 请求连接主机使用代理地址和端口
-z 指定扫描监听端口,不发送任何数据示例:
端口扫描:
# nc -z 192.168.1.10 1-65535
TCP 协议连接到目标端口:
# nc -p 31337 -w 5 192.168.1.10 22
UDP 协议连接到目的端口:
# nc -u 192.168.1.10 53
指定本地 IP 连接:
# nc -s 192.168.1.9 192.168.1.10 22
探测端口是否开启:
# nc -z -w 2 192.168.1.10 22
创建监听 Unix 域 Socket:
# nc -lU /var/tmp/ncsocket
通过 HTTP 代理连接主机:
# nc -x10.2.3.4:8080 -Xconnect 10.0.0.10 22
监听端口捕获输出到文件:
# nc -l 1234 > filename.out
从文件读入到指定端口:
# nc host.example.com 1234 < filename.in
收发信息:
# nc -l 1234
# nc 127.0.0.1 1234
执行 memcahced 命令:printf "stats\n" |nc 127.0.0.1 11211
发送邮件:
# nc [-C] localhost 25 << EOF
HELO host.example.com
MAIL FROM:
RCPT TO:
DATA
Body of email.
.
QUIT
EOF
# echo -n "GET / HTTP/1.0\r\n\r\n" | nc host.example.com 80 54、time
功能:执行脚本时间。
示例:
查看执行 ls 所需的时间:
# time ls55、eval
for i in $@; do
eval $i
done
echo ---
echo $a
echo $b
# bash test.sh a=1 b=2
---
1256、ssh
功能:SSH 客户端。
常用选项:
-p 指定远程主机端口
-i 指定认证文件
-L [bind_address:]port:host:hostport
-R [bind_address:]port:host:hostport]
-D [bind_address:]port
-o SSH 选项,有以下几个比较常用的:
ConnectionAttempts=NUM 连接失败后重试次数
ConnectTimeout=SEC 连接超时时间
StrictHostKeyChecking=no 自动拉去主机 key 文件
PasswordAuthentication=no 禁止密码认证示例:
登录到远程主机:
# ssh [email protected]
远程主机执行命令:
# ssh [email protected] 'ifconfig'
本地文件内容写到远程主机文件:
# ssh [email protected] 'cat >> file' < /etc/passwdSSH 还提供了一个非常有用的功能,就是端口转发,能帮你解决一些无法建立的连接。
1)本地端口转发
应用场景 1:A 不能访问 C,B 能访问 A 和 C,实现通过 B 能让 A 访问 C,在主机 A 执行:
# ssh -L 2222:主机 C:22 主机 B
# ssh -L [绑定地址:]本地端口:主机 C:C 端口 主机 B 将 SSH 绑定本地端口 2222,本地 2222 端口数据转发主机 B,主机 B 的所有数据转发到主机 C 的 22 端口;这样一来,只要在主机 A ssh -p 2222 localhost,就等于连上了主机 C 的 22 端口。
应用场景 2:一台 Squid 代理服务器,限制了本机可以清理缓存,但是我想从远程服务器清理
在远程服务器执行:
# ssh -L 31280:localhost:3128 SquidHost在远程服务器上执行清理命令到本机 31280 端口,31280 收到的数据加密转发到 SquidHost 的 SSH Server 上,SSH Client 解密收到的数据并转发到监听的 3128 端口上,最后将 Squid 返回的数据原路返回。
2)远程端口转发
应用场景 1:A 不能访问 C,B 能访问 A 和 C,但 A 不能访问 B,比如 A 在外网,B 在内网
在主机 B 执行:
# ssh -R 2222:主机 C:22 主机 A将 SSH 绑定本机 2222 端口,与主机 A 建立 SSH 通道,当主机 A 访问本地 2222 端口,就等于访问主机B 的 2222 端口,主机 B 的 2222 端口把数据转发到主机 C 的 22 端口。
应用常见 2:公司有一台内网服务器,还有一台云主机不能 SSH 直接连接这台公司内网服务器,但内网服务器可以 SSH 连接云主机,在公司内网服务器执行:
# ssh -R 2222:localhost:22 云主机将云主机上的 2222 端口数据转发到内网服务器 SSH Client 上,SSH Client 解密收到的数据并转发到监听的 22 端口上,最后再将返回的数据原路返回。
3)动态端口转发(不限定端口,全权代理)
应用场景:访问国外网站
如果是 MAC 系统直接在终端执行:
ssh -D 2222 国外云主机如果是 Windows 系统可借助 putty 工具实现,在 putty 里面端口转发->本地端口转发属性里面添加
一个本地端口,并勾选 SOCKS4/5 动态转发,连接即可。
将 SSH 绑定本机 8080 端口,SSH 就会创建一个 SOCKS 代理服务,直接在浏览器上设置代理本机127.0.0.1 的 8080 端口即可,当浏览器访问国外网站时,本地代理把请求转发到国外云主机的 SSH Server,SSH 解密并转发给指定的网站。
注意:再 Linux 终端执行 ssh 绑定命令后,默认会进入一个新的 shell,只要这个 shell 不退出,此
端口转发就一直有效。如果要想放到后台执行就加-Nf 两个选项,-N 是不执行命令,-f 后台执行,
这样就转入后台运行,就可以在本地 shell 执行操作了,如果想关闭后台就 kill 这个进程。
详情,请参考:IBM Developer
57、iptables
常见几种类型防火墙?
包过滤防火墙:包过滤是 IP 层实现,包过滤根据数据包的源 IP、目的 IP、协议类型
(TCP/UDP/ICMP)、源端口、目的端口等包头信息及数据包传输方向灯信息来判断是否允许数据包通过。
应用层防火墙:也称为应用层代理防火墙,基于应用层协议的信息流检测,可以拦截某应用程序的
所有封包,提取包内容进行分析。有效防止 SQL 注入或者 XSS(跨站脚本攻击)之类的恶意代码。
状态检测防火墙:结合包过滤和应用层防火墙优点,基于连接状态检测机制,将属于同一连接的所
有包作为一个整体的数据流看待,构成连接状态表(通信信息,应用程序信息等),通过规则表与
状态表共同配合,对表中的各个连接状态判断。
iptables 是 Linux 下的配置防火墙的工具,用于配置 Linux 内核集成的 IP 信息包过滤系统,使增
删改查信息包过滤表中的规则更加简单。
iptables 分为四表五链,表是链的容器,链是规则的容器,规则指定动作。
四表:
![]()

五链:

表中的链:

命令格式:
iptables [-t table] 命令 [chain] 匹配条件 动作 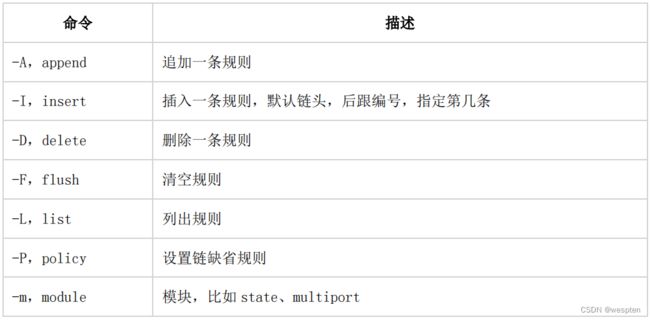
![]()



示例:常用的规则配置方法
iptables -F # 清空表规则,默认 filter 表
iptables -t nat -F # 清空 nat 表
iptables -A INPUT -p tcp --dport 22 -j ACCEPT # 允许 TCP 的 22 端口访问
iptables -I INPUT -p udp --dport 53 -j ACCEPT # 允许 UDP 的 53 端口访问,插入在第一条
iptables -A INPUT -p tcp --dport 22:25 -j ACCEPT # 允许端口范围访问
iptables -D INPUT -p tcp --dport 22:25 -j ACCEPT # 删除这条规则
# 允许多个 TCP 端口访问
iptables -A INPUT -p tcp -m multiport --dports 22,80,8080 -j ACCEPT
iptables -A INPUT -s 192.168.1.0/24 -j ACCEPT # 允许 192.168.1.0 段 IP 访问
iptables -A INPUT -s 192.168.1.10 -j DROP # 对 1.10 数据包丢弃
iptables -A INPUT -i eth0 -p icmp -j DROP # eth0 网卡 ICMP 数据包丢弃,也就是禁 ping
# 允许来自 lo 接口,如果没有这条规则,将不能通过 127.0.0.1 访问本地服务
iptables -A INPUT -i lo -j ACCEPT
# 限制并发连接数,超过 30 个拒绝
iptables -I INPUT -p tcp --syn --dport 80 -m connlimit --connlimit-above 30 -j
REJECT
# 限制每个 IP 每秒并发连接数最大 3 个
iptables -I INPUT -p tcp --syn -m limit --limit 1/s --limit-burst 3 -j
ACCEPT
iptables -A FORWARD -p tcp --syn -m limit --limit 1/s -j ACCEPT
# iptables 服务器作为网关时,内网访问公网
iptables –t nat -A POSTROUTING -s [内网 IP 或网段] -j SNAT --to [公网 IP]
# 访问 iptables 公网 IP 端口,转发到内网服务器端口
iptables –t nat -A PREROUTING -d [对外 IP] -p tcp --dport [对外端口] -j DNAT --to [内 网 IP:内网端口] # 本地 80 端口转发到本地 8080 端口
iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-ports 8080
# 允许已建立及该链接相关联的数据包通过
iptables -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
# ASDL 拨号上网
iptables -t nat -A POSTROUTING -s 192.168.1.0/24 -o pppo -j MASQUERADE
# 设置 INPUT 链缺省操作丢弃所有数据包,只要不符合规则的数据包都丢弃。注意要在最后设置,
以免把自己关在外面!
iptables -P INPUT DROP十二、Shell脚本编写实战
注意事项:
1)开头加解释器:#!/bin/bash
2)语法缩进,使用四个空格;多加注释说明。
3)命名建议规则:变量名大写、局部变量小写,函数名小写,名字体现出实际作用。
4)默认变量是全局的,在函数中变量 local 指定为局部变量,避免污染其他作用域。
5)有两个命令能帮助我调试脚本:set -e 遇到执行非 0 时退出脚本,set -x 打印执行过程。
6)写脚本一定先测试再到生产上。
1、获取随机字符串或数字
获取随机 8 位字符串:
方法 1:
# echo $RANDOM |md5sum |cut -c 1-8
471b94f2
方法 2: # openssl rand -base64 4
vg3BEg==
方法 3: # cat /proc/sys/kernel/random/uuid |cut -c 1-8
ed9e032c方法 1: # echo $RANDOM |cksum |cut -c 1-8
23648321
方法 2: # openssl rand -base64 4 |cksum |cut -c 1-8
38571131
方法 3: # date +%N |cut -c 1-8
690248152、定义一个颜色输出字符串函数
方法 1:
function echo_color() {
if [ $1 == "green" ]; then
echo -e "\033[32;40m$2\033[0m"
elif [ $1 == "red" ]; then
echo -e "\033[31;40m$2\033[0m"
fi
}
方法 2:
function echo_color() {
case $1 in
green)
echo -e "\033[32;40m$2\033[0m"
;;
red)
echo -e "\033[31;40m$2\033[0m"
;;
*)
echo "Example: echo_color red string"
esac
}
使用方法:echo_color green "test"3、批量创建用户
#!/bin/bash
DATE=$(date +%F_%T)
USER_FILE=user.txt
echo_color(){
if [ $1 == "green" ]; then
echo -e "\033[32;40m$2\033[0m"
elif [ $1 == "red" ]; then
echo -e "\033[31;40m$2\033[0m"
fi
}# 如果用户文件存在并且大小大于 0 就备份
if [ -s $USER_FILE ]; then
mv $USER_FILE ${USER_FILE}-${DATE}.bak
echo_color green "$USER_FILE exist, rename ${USER_FILE}-${DATE}.bak"
fi
echo -e "User\tPassword" >> $USER_FILE
echo "----------------" >> $USER_FILE
for USER in user{1..10}; do
if ! id $USER &>/dev/null; then
PASS=$(echo $RANDOM |md5sum |cut -c 1-8)
useradd $USER
echo $PASS |passwd --stdin $USER &>/dev/null
echo -e "$USER\t$PASS" >> $USER_FILE
echo "$USER User create successful."
else
echo_color red "$USER User already exists!"
fi
done4、检查软件包是否安装
#!/bin/bash
if rpm -q sysstat &>/dev/null; then
echo "sysstat is already installed."
else
echo "sysstat is not installed!"
fi5、检查服务状态
#!/bin/bash
PORT_C=$(ss -anu |grep -c 123)
PS_C=$(ps -ef |grep ntpd |grep -vc grep)
if [ $PORT_C -eq 0 -o $PS_C -eq 0 ]; then
echo "内容" | mail -s "主题" [email protected]
fi6、检查主机存活状态
方法 1:将错误 IP 放到数组里面判断是否 ping 失败三次。
#!/bin/bash
IP_LIST="192.168.18.1 192.168.1.1 192.168.18.2"
for IP in $IP_LIST; do
NUM=1
while [ $NUM -le 3 ]; do
if ping -c 1 $IP > /dev/null; then
echo "$IP Ping is successful."
break
else
# echo "$IP Ping is failure $NUM"
FAIL_COUNT[$NUM]=$IP
let NUM++
fi
done
if [ ${#FAIL_COUNT[*]} -eq 3 ];then
echo "${FAIL_COUNT[1]} Ping is failure!"
unset FAIL_COUNT[*]
fi
done方法 2:将错误次数放到 FAIL_COUNT 变量里面判断是否 ping 失败三次。
#!/bin/bash
IP_LIST="192.168.18.1 192.168.1.1 192.168.18.2"
for IP in $IP_LIST; do
FAIL_COUNT=0
for ((i=1;i<=3;i++)); do
if ping -c 1 $IP >/dev/null; then
echo "$IP Ping is successful."
break
else
# echo "$IP Ping is failure $i"
let FAIL_COUNT++
fi
done
if [ $FAIL_COUNT -eq 3 ]; then
echo "$IP Ping is failure!"
fi
done方法 3:利用 for 循环将 ping 通就跳出循环继续,如果不跳出就会走到打印 ping 失败。
#!/bin/bash
ping_success_status() {
if ping -c 1 $IP >/dev/null; then
echo "$IP Ping is successful."
continue
fi
}
IP_LIST="192.168.18.1 192.168.1.1 192.168.18.2"
for IP in $IP_LIST; do
ping_success_status
ping_success_status
ping_success_status
echo "$IP Ping is failure!"
done7、 监控 CPU、内存和硬盘利用率
1)CPU
借助 vmstat 工具来分析 CPU 统计信息。
#!/bin/bash
DATE=$(date +%F" "%H:%M)
IP=$(ifconfig eth0 |awk -F '[ :]+' '/inet addr/{print $4}') # 只支持 CentOS6
MAIL="[email protected]"
if ! which vmstat &>/dev/null; then
echo "vmstat command no found, Please install procps package."
exit 1
fi
US=$(vmstat |awk 'NR==3{print $13}')
SY=$(vmstat |awk 'NR==3{print $14}')
IDLE=$(vmstat |awk 'NR==3{print $15}')
WAIT=$(vmstat |awk 'NR==3{print $16}')
USE=$(($US+$SY))
if [ $USE -ge 50 ]; then
echo "
Date: $DATE
Host: $IP
Problem: CPU utilization $USE
" | mail -s "CPU Monitor" $MAIL
fi#!/bin/bash
DATE=$(date +%F" "%H:%M)
IP=$(ifconfig eth0 |awk -F '[ :]+' '/inet addr/{print $4}')
MAIL="[email protected]"
TOTAL=$(free -m |awk '/Mem/{print $2}')
USE=$(free -m |awk '/Mem/{print $3-$6-$7}')
FREE=$(($TOTAL-$USE))
# 内存小于 1G 发送报警邮件
if [ $FREE -lt 1024 ]; then
echo "
Date: $DATE
Host: $IP
Problem: Total=$TOTAL,Use=$USE,Free=$FREE
" | mail -s "Memory Monitor" $MAIL
fi3)硬盘
#!/bin/bash
DATE=$(date +%F" "%H:%M)
IP=$(ifconfig eth0 |awk -F '[ :]+' '/inet addr/{print $4}')
MAIL="[email protected]"
TOTAL=$(fdisk -l |awk -F'[: ]+' 'BEGIN{OFS="="}/^Disk \/dev/{printf "%s=%sG,",$2,$3}')
PART_USE=$(df -h |awk 'BEGIN{OFS="="}/^\/dev/{print $1,int($5),$6}')
for i in $PART_USE; do
PART=$(echo $i |cut -d"=" -f1)
USE=$(echo $i |cut -d"=" -f2)
MOUNT=$(echo $i |cut -d"=" -f3)
if [ $USE -gt 80 ]; then
echo "
Date: $DATE
Host: $IP
Total: $TOTAL
Problem: $PART=$USE($MOUNT)
" | mail -s "Disk Monitor" $MAIL
fi
done8、批量主机磁盘利用率监控
前提监控端和被监控端 SSH 免交互登录或者密钥登录。
写一个配置文件保存被监控主机 SSH 连接信息,文件内容格式:IP User Port
#!/bin/bash
HOST_INFO=host.info
for IP in $(awk '/^[^#]/{print $1}' $HOST_INFO); do
USER=$(awk -v ip=$IP 'ip==$1{print $2}' $HOST_INFO)
PORT=$(awk -v ip=$IP 'ip==$1{print $3}' $HOST_INFO)
TMP_FILE=/tmp/disk.tmp
ssh -p $PORT $USER@$IP 'df -h' > $TMP_FILE
USE_RATE_LIST=$( awk 'BEGIN{OFS="="}/^\/dev/{print $1,int($5)}' $TMP_FILE)
for USE_RATE in $USE_RATE_LIST; do
PART_NAME=${USE_RATE%=*}
USE_RATE=${USE_RATE#*=}
if [ $USE_RATE -ge 80 ]; then
echo "Warning: $PART_NAME Partition usage $USE_RATE%!"
fi
done
done9、检查网站可用性
1)检查 URL 可用性
方法 1:
check_url() {
HTTP_CODE=$(curl -o /dev/null --connect-timeout 3 -s -w "%{http_code}" $1)
if [ $HTTP_CODE -ne 200 ]; then
echo "Warning: $1 Access failure!"
fi
}
方法 2:
check_url() {
if ! wget -T 10 --tries=1 --spider $1 >/dev/null 2>&1; then
#-T 超时时间,--tries 尝试 1 次,--spider 爬虫模式
echo "Warning: $1 Access failure!"
fi
}
使用方法:check_url www.baidu.com2)判断三次 URL 可用性
思路与上面检查主机存活状态一样。
方法 1:利用循环技巧,如果成功就跳出当前循环,否则执行到最后一行
#!/bin/bash
check_url() {
HTTP_CODE=$(curl -o /dev/null --connect-timeout 3 -s -w "%{http_code}" $1)
if [ $HTTP_CODE -eq 200 ]; then
continue
fi
}
URL_LIST="www.baidu.com www.agasgf.com"
for URL in $URL_LIST; do
check_url $URL
check_url $URL
check_url $URL
echo "Warning: $URL Access failure!"
done
方法 2:错误次数保存到变量
#!/bin/bash
URL_LIST="www.baidu.com www.agasgf.com"
for URL in $URL_LIST; do
FAIL_COUNT=0
for ((i=1;i<=3;i++)); do
HTTP_CODE=$(curl -o /dev/null --connect-timeout 3 -s -w "%{http_code}" $URL)
if [ $HTTP_CODE -ne 200 ]; then
let FAIL_COUNT++
else
break
fi
done
if [ $FAIL_COUNT -eq 3 ]; then
echo "Warning: $URL Access failure!"
fi
done
方法 3:错误次数保存到数组
#!/bin/bash
URL_LIST="www.baidu.com www.agasgf.com"
for URL in $URL_LIST; do
NUM=1
while [ $NUM -le 3 ]; do
HTTP_CODE=$(curl -o /dev/null --connect-timeout 3 -s -w "%{http_code}" $URL)
if [ $HTTP_CODE -ne 200 ]; then
FAIL_COUNT[$NUM]=$IP #创建数组,以$NUM 下标,$IP 元素
let NUM++
else
break
fi
done
if [ ${#FAIL_COUNT[*]} -eq 3 ]; then
echo "Warning: $URL Access failure!"
unset FAIL_COUNT[*] #清空数组
fi
done10、检查 MySQL 主从同步状态
#!/bin/bash
USER=bak
PASSWD=123456
IO_SQL_STATUS=$(mysql -u$USER -p$PASSWD -e 'show slave status\G' |awk -F:
'/Slave_.*_Running/{gsub(": ",":");print $0}') #gsub 去除冒号后面的空格
for i in $IO_SQL_STATUS; do
THREAD_STATUS_NAME=${i%:*}
THREAD_STATUS=${i#*:}
if [ "$THREAD_STATUS" != "Yes" ]; then
echo "Error: MySQL Master-Slave $THREAD_STATUS_NAME status is
$THREAD_STATUS!"
fi
done11、屏蔽网站访问频繁的 IP
1)屏蔽每分钟访问超过 200 的 IP
方法 1:以 Nginx 日志作为测试
DATE=$(date +%d/%b/%Y:%H:%M)
ABNORMAL_IP=$(tail -n5000 access.log |grep $DATE |awk '{a[$1]++}END{for(i in
a)if(a[i]>100)print i}')
#先 tail 防止文件过大,读取慢,数字可调整每分钟最大的访问量。awk 不能直接过滤日志,因为
包含特殊字符。
for IP in $ABNORMAL_IP; do
if [ $(iptables -vnL |grep -c "$IP") -eq 0 ]; then
iptables -I INPUT -s $IP -j DROP
fi
done
方法 2:通过建立连接数
ABNORMAL_IP=$(netstat -an |awk '$4~/:80$/ && $6~/ESTABLISHED/{gsub(/:[0-
9]+/,"",$5);{a[$5]++}}END{for(i in a)if(a[i]>100)print i}')
#gsub 是将第五列(客户端 IP)的冒号和端口去掉
for IP in $ABNORMAL_IP; do
if [ $(iptables -vnL |grep -c "$IP") -eq 0 ]; then
iptables -I INPUT -s $IP -j DROP
fi
done2)屏蔽每分钟 SSH 暴力破解超过 10 次的 IP
方法 1:通过 lastb 获取登录状态:
DATE=$(date +"%a %b %e %H:%M") #星期月天时分 %e 单数字时显示 7,而%d 显示 07
ABNORMAL_IP=$(lastb |grep "$DATE" |awk '{a[$3]++}END{for(i in a)if(a[i]>10)print i}')
for IP in $ABNORMAL_IP; do
if [ $(iptables -vnL |grep -c "$IP") -eq 0 ]; then
iptables -I INPUT -s $IP -j DROP
fi
done
方法 2:通过日志获取登录状态
DATE=$(date +"%b %d %H")
ABNORMAL_IP="$(tail -n10000 /var/log/auth.log |grep "$DATE" |awk '/Failed/{a[$(NF-
3)]++}END{for(i in a)if(a[i]>5)print i}')"
for IP in $ABNORMAL_IP; do
if [ $(iptables -vnL |grep -c "$IP") -eq 0 ]; then
iptables -A INPUT -s $IP -j DROP
echo "$(date +"%F %T") - iptables -A INPUT -s $IP -j DROP" >>~/ssh-loginlimit.log
fi
done12、判断输入是否为 IP
方法 1:
function check_ip(){
IP=$1
VALID_CHECK=$(echo $IP|awk -F. '$1<=255&&$2<=255&&$3<=255&&$4<=255{print "yes"}')
if echo $IP|grep -E "^[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}$">/dev/null;
then
if [ $VALID_CHECK == "yes" ]; then
echo "$IP available."
else
echo "$IP not available!"
fi
else
echo "Format error!"
fi
}
check_ip 192.168.1.1
check_ip 256.1.1.1
方法 2:
function check_ip(){
IP=$1
if [[ $IP =~ ^[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}$ ]]; then
FIELD1=$(echo $IP|cut -d. -f1)
FIELD2=$(echo $IP|cut -d. -f2)
FIELD3=$(echo $IP|cut -d. -f3)
FIELD4=$(echo $IP|cut -d. -f4)
if [ $FIELD1 -le 255 -a $FIELD2 -le 255 -a $FIELD3 -le 255 -a $FIELD4 -le
255 ]; then
echo "$IP available."
else
echo "$IP not available!"
fi
else
echo "Format error!"
fi
}
check_ip 192.168.1.1
check_ip 256.1.1.1
增加版:加个死循环,如果 IP 可用就退出,不可用提示继续输入,并使用 awk 判断
function check_ip(){
local IP=$1
VALID_CHECK=$(echo $IP|awk -F. '$1<=255&&$2<=255&&$3<=255&&$4<=255{print "yes"}')
if echo $IP|grep -E "^[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}$" >/dev/null;
then
if [ $VALID_CHECK == "yes" ]; then
return 0
else
echo "$IP not available!"
return 1
fi
else
echo "Format error! Please input again."
return 1
fi }
while true; do
read -p "Please enter IP: " IP
check_ip $IP
[ $? -eq 0 ] && break || continue
done13、判断输入是否为数字
方法 1:
if [[ $1 =~ ^[0-9]+$ ]]; then
echo "Is Number."
else
echo "No Number."
fi
方法 2:
if [ $1 -gt 0 ] 2>/dev/null; then
echo "Is Number."
else
echo "No Number."
fi
方法 3:
echo $1 |awk '{print $0~/^[0-9]+$/?"Is Number.":"No Number."}' #三目运算符14、找出包含关键字的文件
DIR=$1
KEY=$2
for FILE in $(find $DIR -type f); do
if grep $KEY $FILE &>/dev/null; then
echo "--> $FILE"
fi
done15、监控目录,将新创建的文件名追加到日志中
需安装 inotify-tools 软件包。
#!/bin/bash
MON_DIR=/opt
inotifywait -mq --format %f -e create $MON_DIR |\
while read files; do
echo $files >> test.log
done16、多个网卡选择
function local_nic() {
local NUM ARRAY_LENGTH
NUM=0
for NIC_NAME in $(ls /sys/class/net|grep -vE "lo|docker0"); do
NIC_IP=$(ifconfig $NIC_NAME |awk -F'[: ]+' '/inet addr/{print $4}')
if [ -n "$NIC_IP" ]; then
NIC_IP_ARRAY[$NUM]="$NIC_NAME:$NIC_IP" #将网卡名和对应 IP 放到数
组
let NUM++
fi
done
ARRAY_LENGTH=${#NIC_IP_ARRAY[*]}
if [ $ARRAY_LENGTH -eq 1 ]; then #如果数组里面只有一条记录说明就一个网卡
NIC=${NIC_IP_ARRAY[0]%:*}
return 0
elif [ $ARRAY_LENGTH -eq 0 ]; then #如果没有记录说明没有网卡
echo "No available network card!"
exit 1
else
#如果有多条记录则提醒输入选择
for NIC in ${NIC_IP_ARRAY[*]}; do
echo $NIC
done
while true; do
read -p "Please enter local use to network card name: "
INPUT_NIC_NAME
COUNT=0
for NIC in ${NIC_IP_ARRAY[*]}; do
NIC_NAME=${NIC%:*}
if [ $NIC_NAME == "$INPUT_NIC_NAME" ]; then
NIC=${NIC_IP_ARRAY[$COUNT]%:*}
return 0
else
COUNT+=1
fi
done
echo "Not match! Please input again."
done
fi
}
local_nic如果有只有一个网卡就不选择。
17、查看网卡实时流量
#!/bin/bash
# Description: Only CentOS6
traffic_unit_conv() {
local traffic=$1
if [ $traffic -gt 1024000 ]; then
printf "%.1f%s" "$(($traffic/1024/1024))" "MB/s"
elif [ $traffic -lt 1024000 ]; then
printf "%.1f%s" "$(($traffic/1024))" "KB/s"
fi
}
NIC=$1
echo -e " In ------ Out"
while true; do
OLD_IN=$(awk -F'[: ]+' '$0~"'$NIC'"{print $3}' /proc/net/dev)
OLD_OUT=$(awk -F'[: ]+' '$0~"'$NIC'"{print $11}' /proc/net/dev)
sleep 1
NEW_IN=$(awk -F'[: ]+' '$0~"'$NIC'"{print $3}' /proc/net/dev)
NEW_OUT=$(awk -F'[: ]+' '$0~"'$NIC'"{print $11}' /proc/net/dev)
IN=$(($NEW_IN-$OLD_IN))
OUT=$(($NEW_OUT-$OLD_OUT))
echo "$(traffic_unit_conv $IN) $(traffic_unit_conv $OUT)"
sleep 1
done
# 也可以通过 ficonfig 命令获取收发流量
while true; do
OLD_IN=$(ifconfig $NIC |awk -F'[: ]+' '/bytes/{print $4}')
OLD_OUT=$(ifconfig $NIC |awk -F'[: ]+' '/bytes/{print $9}')
sleep 1
NEW_IN=$(ifconfig $NIC |awk -F'[: ]+' '/bytes/{print $4}')
NEW_OUT=$(ifconfig $NIC |awk -F'[: ]+' '/bytes/{print $9}')
IN=$(($NEW_IN-$OLD_IN))
OUT=$(($NEW_OUT-$OLD_OUT))
echo "$(traffic_unit_conv $IN) $(traffic_unit_conv $OUT)"
sleep 1
done18、MySQL 数据库备份
#!/bin/bash
DATE=$(date +%F_%H-%M-%S)
HOST=192.168.1.120
DB=test
USER=bak
PASS=123456
MAIL="[email protected] [email protected]"
BACKUP_DIR=/data/db_backup
SQL_FILE=${DB}_full_$DATE.sql
BAK_FILE=${DB}_full_$DATE.zip
cd $BACKUP_DIR
if mysqldump -h$HOST -u$USER -p$PASS --single-transaction --routines --triggers -B
$DB > $SQL_FILE; then
zip $BAK_FILE $SQL_FILE && rm -f $SQL_FILE
if [ ! -s $BAK_FILE ]; then
echo "$DATE 内容" | mail -s "主题" $MAIL
fi
else
echo "$DATE 内容" | mail -s "主题" $MAIL
fi
find $BACKUP_DIR -name '*.zip' -ctime +14 -exec rm {} \;19、Nginx 启动脚本
#!/bin/bash
# Description: Only support RedHat system
. /etc/init.d/functions
WORD_DIR=/data/project/nginx1.10
DAEMON=$WORD_DIR/sbin/nginx
CONF=$WORD_DIR/conf/nginx.conf
NAME=nginx
PID=$(awk -F'[; ]+' '/^[^#]/{if($0~/pid;/)print $2}' $CONF)
if [ -z "$PID" ]; then
PID=$WORD_DIR/logs/nginx.pid
else
PID=$WORD_DIR/$PID
fi
stop() {
$DAEMON -s stop
sleep 1 [ ! -f $PID ] && action "* Stopping $NAME" /bin/true || action "* Stopping
$NAME" /bin/false
}
start() {
$DAEMON
sleep 1 [ -f $PID ] && action "* Starting $NAME" /bin/true || action "* Starting $NAME"
/bin/false
}
reload() {
$DAEMON -s reload
}
test_config() {
$DAEMON -t }
case "$1" in
start)
if [ ! -f $PID ]; then
start
else
echo "$NAME is running..."
exit 0
fi
;;
stop)
if [ -f $PID ]; then
stop
else
echo "$NAME not running!"
exit 0
fi
;;
restart)
if [ ! -f $PID ]; then
echo "$NAME not running!"
start
else
stop
start
fi
;;
reload)
reload
;;
testconfig)
test_config
;;
status)
[ -f $PID ] && echo "$NAME is running..." || echo "$NAME not running!"
;;
*)
echo "Usage: $0 {start|stop|restart|reload|testconfig|status}"
exit 3
;;
esac20、选择 SSH 连接主机
写一个配置文件保存被监控主机 SSH 连接信息,文件内容格式:主机名 IP User Port。
#!/bin/bash
PS3="Please input number: "
HOST_FILE=host
while true; do
select NAME in $(awk '{print $1}' $HOST_FILE) quit; do
[ ${NAME:=empty} == "quit" ] && exit 0
IP=$(awk -v NAME=${NAME} '$1==NAME{print $2}' $HOST_FILE)
USER=$(awk -v NAME=${NAME} '$1==NAME{print $3}' $HOST_FILE)
PORT=$(awk -v NAME=${NAME} '$1==NAME{print $4}' $HOST_FILE)
if [ $IP ]; then
echo "Name: $NAME, IP: $IP"
ssh -o StrictHostKeyChecking=no -p $PORT -i id_rsa $USER@$IP # 密钥登录
break
else
echo "Input error, Please enter again!"
break
fi
done
done21、FTP 下载文件
#!/bin/bash
if [ $# -ne 1 ]; then
echo "Usage: $0 filename"
fi
dir=$(dirname $1)
file=$(basename $1)
ftp -n -v << EOF # -n 自动登录
open 192.168.1.10
user admin adminpass
binary # 设置 ftp 传输模式为二进制,避免 MD5 值不同或.tar.gz 压缩包格式错误
cd $dir
get "$file"
EOF22、输入五个 100 数之内的字符,统计和、最小和最大
COUNT=1
SUM=0
MIN=0
MAX=100
while [ $COUNT -le 5 ]; do
read -p "请输入 1-10 个整数:" INT
if [[ ! $INT =~ ^[0-9]+$ ]]; then
echo "输入必须是整数!"
exit 1
elif [[ $INT -gt 100 ]]; then
echo "输入必须是 100 以内!"
exit 1
fi
SUM=$(($SUM+$INT))
[ $MIN -lt $INT ] && MIN=$INT
[ $MAX -gt $INT ] && MAX=$INT
let COUNT++
done
echo "SUM: $SUM"
echo "MIN: $MIN"
echo "MAX: $MAX"23、将结果分别赋值给变量
方法 1:
for i in $(echo "4 5 6"); do
eval a$i=$i
done
echo $a4 $a5 $a6
方法 2:将位置参数 192.168.18.1{1,2}拆分为到每个变量
num=0
for i in $(eval echo $*);do #eval 将{1,2}分解为 1 2
let num+=1
eval node${num}="$i"
done
echo $node1 $node2 $node3
# bash a.sh 192.168.18.1{1,2}
192.168.18.11 192.168.18.12
方法 3:
arr=(4 5 6)
INDEX1=$(echo ${arr[0]})
INDEX2=$(echo ${arr[1]})
INDEX3=$(echo ${arr[2]})24、批量修改文件名
# touch article_{1..3}.html
# ls
article_1.html article_2.html article_3.html现在想把 article 改为 bbs:
方法 1:
for file in $(ls *html); do
mv $file bbs_${file#*_}
# mv $file $(echo $file |sed -r 's/.*(_.*)/bbs\1/')
# mv $file $(echo $file |echo bbs_$(cut -d_ -f2)
done
方法 2:
for file in $(find . -maxdepth 1 -name "*html"); do
mv $file bbs_${file#*_}
done
方法 3: # rename article bbs *.html25、统计当前目录中以.html 结尾的文件总大小
方法 1: # find . -name "*.html" -maxdepth 1 -exec du -b {} \; |awk '{sum+=$1}END{print sum}'
方法 2:
for size in $(ls -l *.html |awk '{print $5}'); do
sum=$(($sum+$size))
done
echo $sum
递归统计:
# find . -name "*.html" -exec du -k {} \; |awk '{sum+=$1}END{print sum}'26、扫描主机端口状态
#!/bin/bash
HOST=$1
PORT="22 25 80 8080"
for PORT in $PORT; do
if echo &>/dev/null > /dev/tcp/$HOST/$PORT; then
echo "$PORT open"
else
echo "$PORT close"
fi
done27、Expect 实现 SSH 免交互执行命令
需要先安装 expect 工具,expect 涉及用法说明:
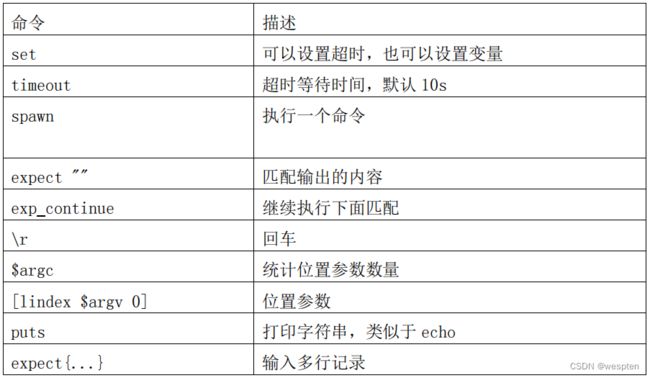
方法 1:EOF 标准输出作为 expect 标准输入
#!/bin/bash
USER=root
PASS=123.com
IP=192.168.1.120
expect << EOF
set timeout 30
spawn ssh $USER@$IP
expect {
"(yes/no)" {send "yes\r"; exp_continue}
"password:" {send "$PASS\r"}
}
expect "$USER@*" {send "$1\r"}
expect "$USER@*" {send "exit\r"}
expect eof
EOF方法 2:
#!/bin/bash
USER=root
PASS=123.com
IP=192.168.1.120
expect -c "
spawn ssh $USER@$IP
expect {
\"(yes/no)\" {send \"yes\r\"; exp_continue}
\"password:\" {send \"$PASS\r\"; exp_continue}
\"$USER@*\" {send \"df -h\r exit\r\"; exp_continue}
}"方法 3:将 expect 脚本独立出来
login.exp 登录文件:
#!/usr/bin/expect
set ip [lindex $argv 0]
set user [lindex $argv 1]
set passwd [lindex $argv 2]
set cmd [lindex $argv 3]
if { $argc != 4 } {
puts "Usage: expect login.exp ip user passwd"
exit 1
}
set timeout 30
spawn ssh $user@$ip
expect {
"(yes/no)" {send "yes\r"; exp_continue}
"password:" {send "$passwd\r"}
}
expect "$user@*" {send "$cmd\r"}
expect "$user@*" {send "exit\r"}
expect eof执行命令脚本:
#!/bin/bash
HOST_INFO=user_info
for ip in $(awk '{print $1}' $HOST_INFO)
do
user=$(awk -v I="$ip" 'I==$1{print $2}' $HOST_INFO)
pass=$(awk -v I="$ip" 'I==$1{print $3}' $HOST_INFO)
expect login.exp $ip $user $pass $1
doneSSH 连接信息文件:
# cat user_info
192.168.1.120 root 12345628、批量修改服务器用户密码
旧密码 SSH 主机信息 old_info 文件:
# ip user passwd port
#--------------------------------------
192.168.18.217 root 123456 22
192.168.18.218 root 123456 22修改密码脚本:
#!/bin/bash
OLD_INFO=old_info
NEW_INFO=new_info
for IP in $(awk '/^[^#]/{print $1}' $OLD_INFO); do
USER=$(awk -v I=$IP 'I==$1{print $2}' $OLD_INFO)
PASS=$(awk -v I=$IP 'I==$1{print $3}' $OLD_INFO)
PORT=$(awk -v I=$IP 'I==$1{print $4}' $OLD_INFO)
NEW_PASS=$(mkpasswd -l 8)
echo "$IP $USER $NEW_PASS $PORT" >> $NEW_INFO
expect -c "
spawn ssh -p$PORT $USER@$IP
set timeout 2
expect {
\"(yes/no)\" {send \"yes\r\";exp_continue}
\"password:\" {send \"$PASS\r\";exp_continue}
\"$USER@*\" {send \"echo \'$NEW_PASS\' |passwd --stdin $USER\r
exit\r\";exp_continue}
}"
done生成新密码 new_info 文件:
192.168.18.217 root n8wX3mU% 22
192.168.18.218 root c87;ZnnL 2229、打印乘法口诀
方法 1: # awk 'BEGIN{for(n=0;n++<9;){for(i=0;i++30、getopts 工具完善脚本命令行参数
getopts 是一个解析脚本选项参数的工具。
命令格式:
getopts optstring name [arg]初次使用你要注意这几点:
1)脚本位置参数会与 optstring 中的单个字母逐个匹配,如果匹配到就赋值给 name,否则赋值 name为问号;
2)optstring 中单个字母是一个选项,如果字母后面加冒号,表示该选项后面带参数,参数值并会赋值给 OPTARG 变量;
3)optstring 中第一个是冒号,表示屏蔽系统错误(test.sh: illegal option -- h); 4)允许把选项放一起,例如-ab;
下面写一个打印文件指定行的简单例子,用于引导你思路,扩展你的脚本选项功能:
#!/bin/bash
while getopts :f:n: option; do
case $option in
f)
FILE=$OPTARG
[ ! -f $FILE ] && echo "$FILE File not exist!" && exit
;;
n)
sed -n "${OPTARG}p" $FILE
;;
?)
echo "Usage: $0 -f -n "
echo "-f, --file specified file"
echo "-n, --line-number print specified line"
exit 1
;;
esac
done
# bash test.sh -h
Usage: test.sh -f -n
-f, --file specified file
-n, --line-number print specified line
# bash test.sh -f /etc/passwd -n 1
root:x:0:0:root:/root:/bin/bash