Hadoop完全分布式部署
Hadoop完全分布式部署
- 一、 任务描述
- 二、任务目标
- 三、 任务环境
- 四、任务分析
- 五、 任务实施
-
- 步骤1、网络配置
- 步骤2、解压Hadoop压缩包
- 六、任务测试
原创申明: 未经许可,禁止以任何形式转载,若要引用,请标注链接地址
全文共计5984字,阅读大概需要3分钟
欢迎关注我的个人公众号:不懂开发的程序猿
一、 任务描述
要想深入的学习hadoop数据分析技术,首要的任务是必须要将hadoop集群环境搭建起来,可以将hadoop简化地想象成一个小软件,通过在各个物理节点上安装这个小软件,然后将其运行起来,就是一个hadoop分布式集群了。
二、任务目标
(1)学会hadoop完全分布式配置
(2)理解完全分布式配置的配置文件
三、 任务环境
本次环境是:Ubuntu16.04 + jdk1.8.0_73+hadoop-2.7.3
四、任务分析
Hadoop 集群的安装配置大致为如下流程:
选定一台机器作为 master,在 master 节点上安装 Hadoop,配置网络环境和免密。将 master 节点上的 /simple/hadoop-2.7.3 复制到其他 slave 节点上。在 master 节点上开启 Hadoop服务,查看集群启动状态。
五、 任务实施
步骤1、网络配置
由于在实际环境中每次生成的主机名都不一致,为了命名的规范和简洁,需要修改每台虚拟机的主机名。在ip为192.168.0.2的虚拟机终端输入命令【vim /etc/hostname】,进入编辑页面输入“master”,编辑完成后保存退出。在终端输入命令【reboot】重启后,主机名就修改完成了。然后将ip为192.168.0.3的虚拟机的主机名修改slave1,ip为19.168.0.4的虚拟机的主机名修改为salve2。如图1所示。

图1 修改主机名
修改每台电脑的hosts文件。hosts文件和windows上的功能是一样的。存储主机名和ip地址的映射。在每台linux上,【vim /etc/hosts】 编写hosts文件。将主机名和ip地址的映射填写进去。编辑完后,结果如图2所示:

图2 编辑hosts文件
配置完网络之后,可以通过ping命令进行测试是否能够连通,ping除了可以直接连接IP地址,也可以连接主机名,不过此时需要对配置文件hosts进行修改。“etc/hosts“文件是用来配置主机用的DNS服务器信息,是记载LAN内接各主机名称和IP地址,当用户在连接网络时,首先查找该文件,寻找对应的主机名和IP地址。这样就可以实现不同节点之间可以通过ip地址或主机名相互ping通。如图3所示
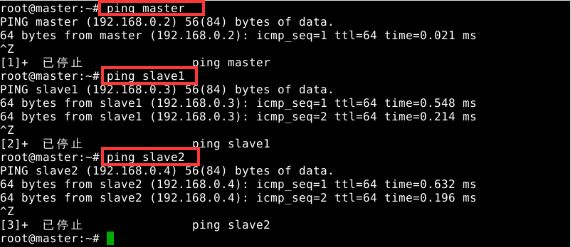
图3 测试机器之间的联通
完成以上操作即表示完成一个小的局域网络,为hadoop集群搭建准备好条件,由于每个节点之间需要相互配合,相互访问,为避免反复出现输入密码,此时需要对各个节点之间配置免密码配置。 无密码登陆,效果也就是在master上,通过 ssh salve1 或 ssh salve2 就可以登陆到对方计算机上。而且不用输入密码进入ssh目录。下面开始配置免密,进入ssh目录并查看。如图4所示

图4 进入ssh目录
使用命令【ssh-keygen -t rsa】,一路按回车就行了。刚才的步骤主要是设置ssh的密钥和密钥的存放路径。 路径为~/.ssh下。
打开~/.ssh 下面有三个文件
(1)authorized_keys,已认证的keys
(2)id_rsa,私钥
(3)id_rsa.pub,公钥三个文件。
下面就是关键的地方了,(下面的操作为ssh认证。进行下面操作前,可以先搜关于认证和加密区别以及各自的过程。)在master上将公钥放到authorized_keys里。命令:【 cat ~/.ssh/id_rsa.pub >>~/.ssh/authorized_keys】。如图5所示

图5 生成公钥和私钥
如果有其他 slave 节点,也要执行将 master 公钥传输到 slave 节点、在 slave 节点上加入授权这两步。这样,在 master 节点上就可以无密码 SSH 到各个 slave 节点了,可在 master 节点上执行如下命令进行检验,如下图所示
将master上的公钥放到其他虚拟机的~/.ssh目录下,并测试免密是否成功。下面是放到对slave1的免密配置,依次完成salve2。如图6所示。注意:在进行文件传输时需要密码为“Simplexue123“。上述的操作过程只是单向的,即此时,ssh root@slave1和ssh root@slave2是不需要密码的。而ssh root@master等反向仍然是需要密码的。执行【ssh slave1】后进入slave1节点,通过【ssh master】可以再次回到master节点。

图6 将公钥传给其他机器
♥ 温馨提示
需要在所有节点上完成网络配置,如上面讲的是 master 节点的配置,而在其他的 slave 节点上,也要对/etc/hosts(跟 master 的配置一样)文件进行修改!
步骤2、解压Hadoop压缩包
在master节点执行命令【cd /simple/soft】进入软件包的所在文件夹中,并通过【ls】查看文件夹下所有软件。如图7所示。

图7 进入软件所在目录
在simple目录下执行解压命令。如图8所示
![]()
图8 解压hadoop
步骤3、配置hadoop文件
切换到配置文件所在目录下并查看。如图9所示
图9 查看配置文件
在当前目录下执行命令:【vim hadoop-env.sh】,按i键之后进入编辑状态,在文件中添加如下内容: export JAVA_HOME=/simple/jdk1.8.0_73。如图10所示。保存后在终端输入命令【vim yarn-env.sh】对yarn-env.sh进行同样的配置,如图11所示。
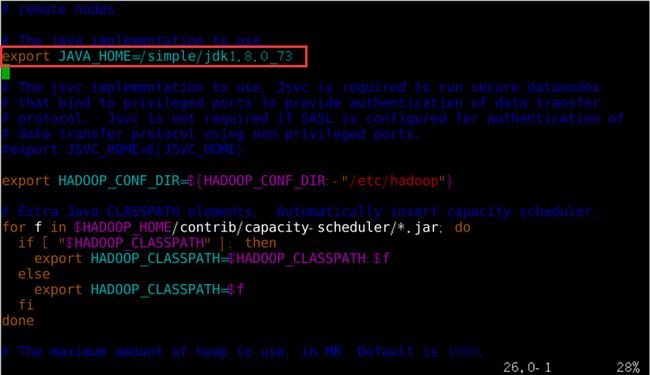
图10 配置hadoop-env.sh
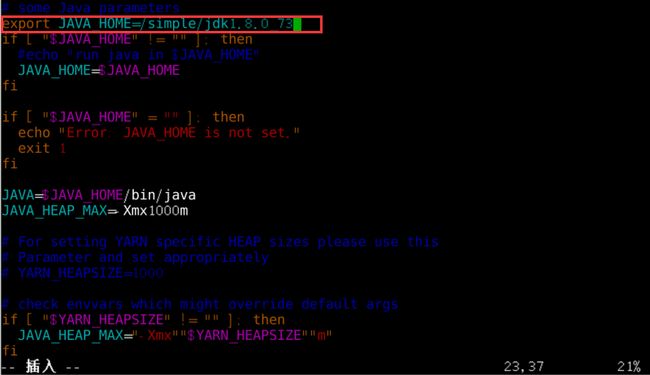
图11 配置yarn-env.sh
在当前目录下执行【vim core-site.xml】并修改配置文件core-site.xml的 内容如下(实际修改不需要写中文注释)。如果没有配置hadoop.tmp.dir参数,此时系统默认的临时文件为/tmp/Hadoop,而这个目录在每次重启机器后会删除,需要重新格式化,否则报错。
1.
2. <property>
3. <name>fs.default.namename>
4. <value>hdfs://master:9000value>
5. property>
6. <property>
7.
8. /**tmp提前创建好 */
9. <name>hadoop.tmp.dirname>
10. <value>/simple/hadoop-2.7.3/tmpvalue>
11. property>
在当前目录下执行【vim hdfs-site.xml】并修改配置文件hdfs-site.xml
1.
2. <property>
3. <name>dfs.name.dirname>
4. <value>/simple/hadoop-2.7.3/hdfs/namevalue>
5. property>
6.
7. <property>
8. <name>dfs.data.dirname>
9. <value>/simple/hadoop-2.7.3/hdfs/datavalue>
10. property>
在当前目录下执行编辑文件命令:【`vim mapred-site.xml`】并修改该文件内容
1.
2. <property>
3. <name>mapreduce.framework.namename>
4. <value>yarnvalue>
5. property>
6.
7. <property>
8. <name>mapreduce.jobhistory.addressname>
9. <value>master:10020value>
10. property>
11.
12. <property>
13. <name>mapreduce.jobhistory.webapp.addressname>
14. <value>master:19888value>
15. property>
在当前目录下执行【`vim yarn-site.xml`】,这个文件就是配置资源管理系统yarn了,其中主要指定了一些节点资源管理器nodemanager,以及总资源管理器resourcemanager的配置。 可以看到这个配置中,跟mapreduce框架是相关的。修改配置文件内容如下
可见yarn首先是为了支持mapreduce这个模型,之后很多其他的框架都是基于mapreduce以及yarn的功能基础上开发出来的。
1.
2. <property>
3. <name>yarn.nodemanager.aux-services.mapreduce.shuffle.classname>
4. <value>org.apache.mapred.ShuffleHandlervalue>
5. property>
6.
7. <property>
8. <name>yarn.resourcemanager.addressname>
9. <value>master:8032value>
10. property>
11.
12. <property>
13. <name>yarn.resourcemanager.scheduler.addressname>
14. <value>master:8030value>
15. property>
16.
17. <property>
18. <name>yarn.resourcemanager.resource-tracker.addressname>
19. <value>master:8031value>
20. property>
21.
22. <property>
23. <name>yarn.resourcemanager.admin.addressname>
24. <value>master:8033value>
25. property>
26.
27. <property>
28. <name>yarn.resourcemanager.webapp.addressname>
29. <value>master:8088value>
30. property>
31.
32. <property>
33. <name>yarn.nodemanager.aux-servicesname>
34. <value>mapreduce_shufflevalue>
35. property>
在master节点上完成以上所有操作之后,需要把master上的hadoop分别远程拷贝到slave1,slave2上。例如:【scp –r hadoop-2.7.3/ slave1:/simple/】,如图12所示。然后使用命令【vim hadoop-2.7.3/etc/hadoop/slaves】修改文件slaves的内容,将原来的内容删掉替换为图13所示内容。
![]()
图12 将hadoop拷贝到子节点

图13 修改主节点的slaves文件
执行【vim /etc/profile】。把hadoop的安装目录配置到环境变量中。如图14所示。注意:依次在slave1,slave2虚拟机上配置环境变量。

图14 配置环境变量
这里为了方便可以通过命令【scp –r /etc/profile slave1:/etc/profile】将环境变量传到其它的虚拟机环境中。如图13所示。然后对slave2执行同样的操作。
![]()
图15 传输环境变量
然后让配置文件生效:【source /etc/profile】,依次在slave1和slave2节点上执行该命令。如图16所示
![]()
图16 使配置文件生效
格式化namenode。在任意目录下执行如下命令进行格式化:【hdfs namenode -format】 或者 【hadoop namenode -format】 。 如图17所示
![]()
图17 在master节点格式化namenode
在master节点启动hadoop,输入命令:【start-all.sh】。如图18所示
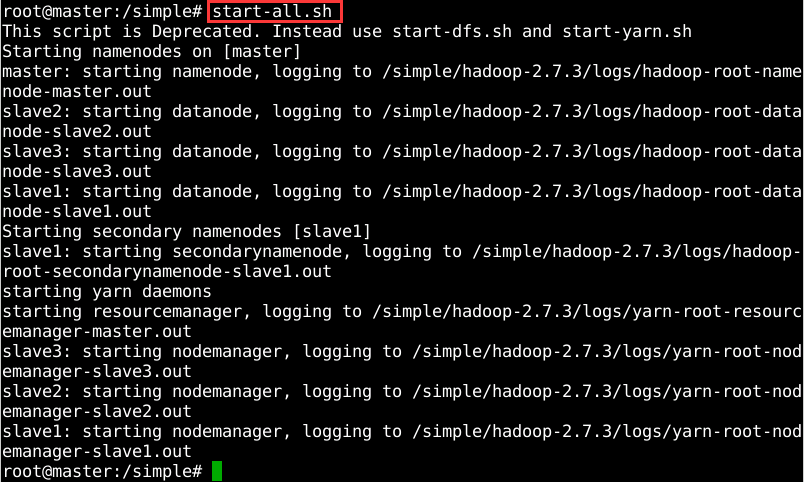
图18 启动hadoop服务
♥ 知识链接
hosts文件
配置hosts文件的作用,它主要用于确定每个结点的IP地址,方便后续master结点能快速查到并访问各个结点。在上述4个虚机结点上均需要配置此文件。由于需要确定每个结点的IP地址,所以在配置hosts文件之前需要先查看当前虚机结点的IP地址是多少,可以通过ifconfig命令进行查看
六、任务测试
启动之后,分别在master,slave1,slave2节点的任意目录下执行【jps】命令验证进程是否正常启动。如图19、20、21所示

图19 jps查看服务

图20 jps查看服务

图21 jps查看服务
测试hdfs和yarn(推荐火狐浏览器),首先在浏览器地址栏中输入:http://master:50070 (HDFS管理界面)。如图22所示
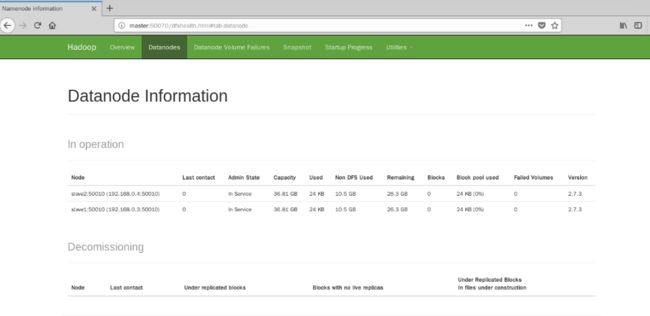
图22 webui查看集群信息
