使用基于LSTM的变分自编码器对股票序列数据进行降噪并重构
考虑到针对股票市场的噪音特性,我们尝试使用变分自编码器(VAE)对价格数据进行重构,并且考虑到股票数据的时序性,我们在自编码器网络中加入LSTM网络提升表现。
第一步:获取数据:
pip install tushare
#获取使用接口
def get_token():
ts.set_token("xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx")
pro=ts.pro_api()
return pro
##获取数据列表
def get_data_list(cursor,sql,conn):
cursor.execute(sql)
res=cursor.fetchall()
conn.commit()
ts_codes_list=list(res)
ts_codes_list=[",".join(list(x)) for x in ts_codes_list]
return ts_codes_list
##获取数据
def get_data(ts_codes_list,pro):
daily=pd.DataFrame(columns=["ts_code","trade_date","open","close","high","low","volume"]) ##获取相应的列信息
for i in range(0,len(ts_codes_list),100):
j=i+100
if(j>=len(ts_codes_list)):
j=len(ts_codes_list)
name=",".join(ts_codes_list[i:j])
part= pro.daily(ts_code=name, trade_date=get_date())[["ts_code","trade_date","open","close","high","low","volume"]]
daily=pd.concat([daily,part],ignore_index=True)
daily["trade_date"]=daily["trade_date"].apply(get_date_format)
return daily
使用stockstats库进行对OHCLV的转换。
```python
from stockstats import StockDataFrame as Sdf
df = data.copy()
df = df.sort_values(by=['tic','date'])
stock = Sdf.retype(df.copy())
unique_ticker = stock.tic.unique()
for indicator in self.tech_indicator_list:
indicator_df = pd.DataFrame()
for i in range(len(unique_ticker)):
try:
temp_indicator = stock[stock.tic == unique_ticker[i]][indicator]
temp_indicator = pd.DataFrame(temp_indicator)
temp_indicator['tic'] = unique_ticker[i]
temp_indicator['date'] = df[df.tic == unique_ticker[i]]['date'].to_list()
indicator_df = indicator_df.append(
temp_indicator, ignore_index=True
)
except Exception as e:
print(e)
df =df.merge(indicator_df[['tic','date',indicator]],on=['tic','date'],how='left')
df = df.sort_values(by=['date','tic'])
第二步:构造LSTM_Variational_Autoencoder network
class LSTM_VAutoencoder(object):
"""
Variational Autoencoder based on lstm
"""
def __init__(self, input_shape, intermediate_cfg, latent_dim):
"""
Args:
input_shape : dimension of input data
latent_dim : dimension of latent space
intermediate_cfg : dimension of hidden spaces
"""
self.input_shape = input_shape
self.latent_dim = latent_dim
self.intermediate_cfg = intermediate_cfg
self.mu = None
self.log_sigma = None
self.vae = None
if len(intermediate_cfg)<3 or 'latent' not in intermediate_cfg:
raise ValueError("You should set intermediate_cfg list that containts number of LSTM layers and their dimensions "
" \n")
def add_layers(self):
inputs = Input(shape=self.input_shape)
if self.intermediate_cfg.index('latent') == 1:
encoded = LSTM(self.intermediate_cfg[0])(inputs)
else:
encoded = LSTM(self.intermediate_cfg[0], return_sequences=True)(inputs)
for dim in self.intermediate_cfg[1:self.intermediate_cfg.index('latent')-1]:
encoded = LSTM(dim, return_sequences=True)(encoded)
encoded = LSTM(self.intermediate_cfg[self.intermediate_cfg.index('latent')-1])(encoded)
self.mu = Dense(self.latent_dim)(encoded)
self.log_sigma = Dense(self.latent_dim)(encoded)
z = Lambda(self.sampling, output_shape=(self.latent_dim,))([self.mu, self.log_sigma])
decoded = RepeatVector(self.input_shape[0])(z)
for dim in self.intermediate_cfg[self.intermediate_cfg.index('latent')+1:]:
decoded = LSTM(dim, return_sequences=True)(decoded)
decoder_dense = Dense(self.input_shape[1])
decoded = TimeDistributed(decoder_dense, name='ae')(decoded)
return inputs, decoded
def fit(self, X, epochs=10, batch_size=32, validation_split=None, verbose=1):
inputs,decoded = self.add_layers()
self.vae = Model(inputs, decoded)
self.vae.compile(optimizer='rmsprop', loss=self.loss)
self.vae.fit(X, X, epochs=epochs, batch_size=batch_size, validation_split=validation_split,verbose=verbose)
def reconstruct(self, X):
return self.vae.predict(X)
def sampling(self, args):
mu, log_sigma = args
batch_size = K.shape(mu)[0]
latent_dim = K.int_shape(mu)[1]
epsilon = K.random_normal(shape=(batch_size, latent_dim), mean=0., stddev=1.)
return mu + K.exp(log_sigma / 2) * epsilon
def loss(self, y_true, y_pred):
reconstruction_loss = mse(y_true, y_pred)
reconstruction_loss = K.mean(reconstruction_loss)
kl_loss = - 0.5 * K.sum(1 + self.log_sigma - K.square(self.mu) - K.exp(self.log_sigma), axis=-1)
loss = K.mean(reconstruction_loss + kl_loss)
return loss
第三步:进行训练并对原始数据进行降噪与重构
import preprocessing as ps
import pandas as pd
from utils import temporalize, flatten, anomaly_detector
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import tensorflow as tf
from pylab import rcParams
rcParams['figure.figsize'] = 15, 7
RANDOM_SEED = 42
tf.random.set_seed(RANDOM_SEED)
url = "MV2020-2022.csv"
df = pd.read_csv(url, index_col='Date', parse_dates=True)
df = df[['Close']]
train, test = train_test_split(df, test_size=0.1, shuffle=False)
scaler = StandardScaler()
scaler = scaler.fit(train[['Close']])
train['NClose'] = scaler.transform(train[['Close']])
test['NClose'] = scaler.transform(test[['Close']])
from tensorflow.python.framework.ops import disable_eager_execution
disable_eager_execution()
sequence_length = 30
X_train, y_train = temporalize(train[['NClose']], train.NClose, False, sequence_length)
X_test, y_test = temporalize(test[['NClose']], test.NClose, False, sequence_length)
from models import LSTM_VAutoencoder
input_shape=(X_train.shape[1], X_train.shape[2],)
intermediate_cfg = [64, 32, 'latent', 32, 64]
latent_dim = 10
vae = LSTM_VAutoencoder(input_shape, intermediate_cfg, latent_dim)
vae.fit(X_train, epochs=10, batch_size=32, validation_split=None, verbose=1)
reconstructed = vae.reconstruct(X_test)
画图看看效果:
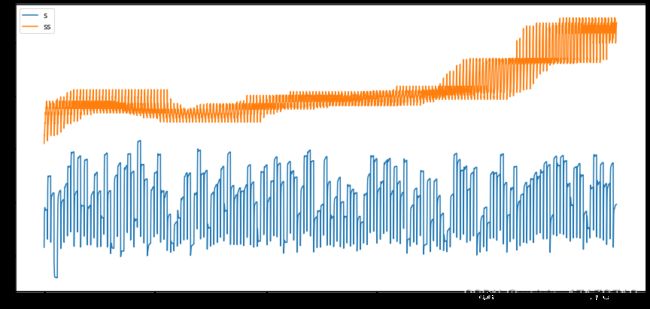
这便是全部过程。