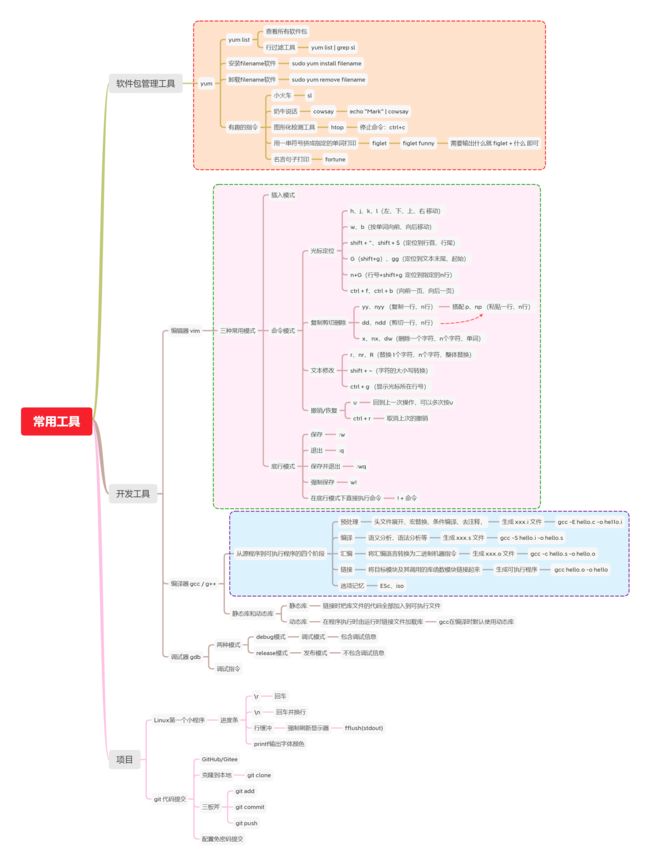
【Linux编程】二、Linux常见工具和项目开发(思维导图总结)
文章目录
- Linux 软件包管理工具 yum
-
-
- 什么是软件包?
- 关于rzsz
- 注意事项
- 查看软件包
- 如何安装软件
- 如何卸载软件
- 总结:三板斧操作
- 用yum来安装几个好玩的东西
-
- 前期准备
- 安装小火车
- 安装cowsay(奶牛说话)
- 图形化检测工具
- 用一串符号拼成指定的单词打印
- 名言句子打印
-
- Linux 开发工具
-
- Linux编辑器-vim的使用
-
- vim是什么?
- vim的基本概念
- vim的基本操作
- vim正常模式命令集
- vim底行模式命令集
- vim操作总结
- 简单vim配置[拓展]
-
- 配置文件的位置
- 常用配置选项,用来测试
- 使用插件
- vim环境配置---一键配置专用(多快好省,强烈推荐)
- vim相关问题补充
- 更多参考资料
- Linux编译器-gcc/g++使用
-
- 背景知识
- gcc 执行格式
- gcc选项
- gcc 选项记忆
- Linux调试器-gdb使用
-
- 背景
- 开始使用
- 深入理解
- Linux项目自动化构建工具-make/Makefile
-
- 背景
- 深入理解
- 实例代码
- 依赖关系
- 依赖方法
- 原理
- 项目清理
- Linux第一个小程序 进度条
-
- 前提准备
-
- \r和\n
- 行缓冲区的概念
- 倒计时程序
- 进度条
- Linux代码托管/开源项目
-
- 使用git命令行
- 在Github上创建项目
-
- 注册Github账号
- 创建项目
- 下载项目到本地
- Git操作---三板斧
- 配置免密码提交
- 思维导图总结
思维导图预览
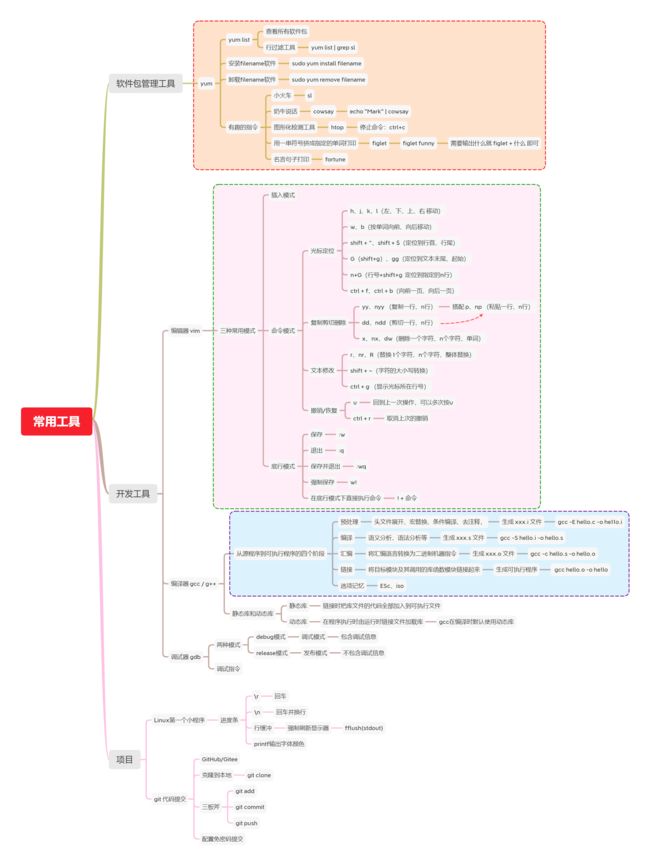
| 【内容概览】 |
|---|
| 1)学习yum工具,进行软件安装 |
| 2)掌握vim编辑器使用,学会vim的简单配置 |
| 3)掌握gcc/g++编译器的使用,并了解其过程,原理 |
| 4)掌握简单gdb使用于调试 |
| 5)掌握简单的Makefile编写,了解其运行思想 |
| 6)编写自己的第一个Linux程序:进度条 |
| 7)学习git命令行的简单操作,能够将代码上传到Github 上 |
| 常用工具 | 作用 |
|---|---|
| 软件包管理工具 | 安装其他软件的工具 |
| 编辑器 | 我们写代码的地方 |
| 编译器 | 将高级语言代码转换成机器语言(解释成机器指令集) |
| 调试器 | 调试程序运行过程 |
| 项目自动化构建工具 | 自动化的将某个项目构建成功 |
| 项目版本管理工具 | 可以实现项目的回滚、合并等项目管理操作 |
Linux 软件包管理工具 yum
什么是软件包?
1)在Linux下安装软件,一个通常的办法是下载程序的源代码,并进行编译,得到可执行程序。
2)但是这样太麻烦了,于是有些人就把一些常用的软件提前编译好做成软件包(可以理解成Windows上的.exe安装程序)放在一个服务器上,通过包管理器我们就可以很方便的获取到这个编译好的软件包,从而直接进行软件的安装。
3)软件包和软件包管理器之间的关系,就好比"App"和"应用商店"这样的关系。
4)yum(Yellow dog Updater,Modified)是Linux下非常常用的一种包管理器。主要应用在Fedora、RedHat、Centos等发行版上。
总结:yum是 Yellow dog Updater,Modified 的首字母缩写,并不是直接由单词yum (好吃的)得来的,yum的作用类似于手机上的应用商店
关于rzsz
这个工具用于Windows机器和远端的Linux机器通过XShell传输文件。
安装完毕之后可以通过拖拽的方式将文件上传过去。
注意事项
关于yum的所有操作必须保证主机虚拟机网络畅通!我们可以通过ping 指令来验证网络连接状态。(如果是云服务器的话,就不用考虑这个问题了,因为云服务一定是联网的,不然你咋登录的咧~)
ping www.baidu.com//这条命令在Windows/Linux 均可以直接用来测试联网情况
在Windows主界面(就是我们开机登录后第一眼看到的界面,有回收站那个)按住win + R 打开下面这个东东,输入cmd(表示command命令行)

进入小黑框后,输入ping www.baidu.com
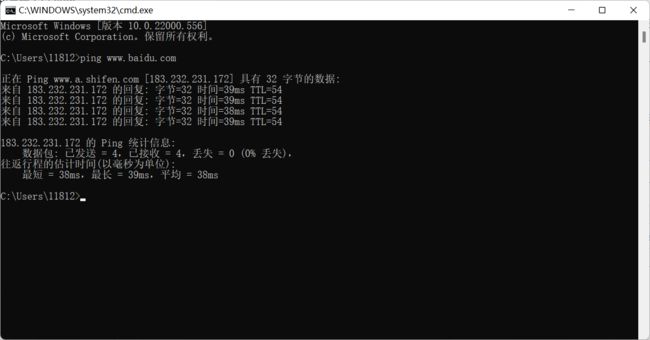
像上面这个样子,网络就是没问题的。
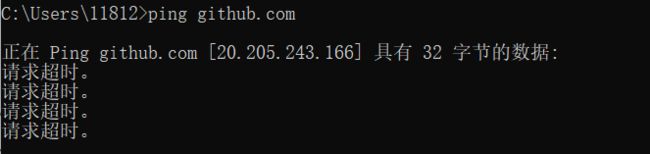
像这种情况,网络就是有问题的,可能是我们自己的主机没连上网,或者是服务器本身的网络很差。
【Linux下演示】

可以看到Linux下测试的时候并不是通过4个分组包来探测,而是不停的发。
为了让这个测试可以停下来,我们可以指定执行的次数,也就是网络分组包packet的探测数量。
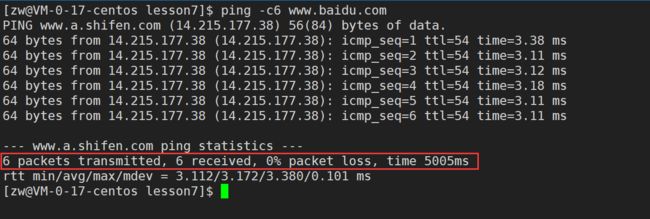
ping -c6 www.baidu.com//-c6 表示指定执行6次探测
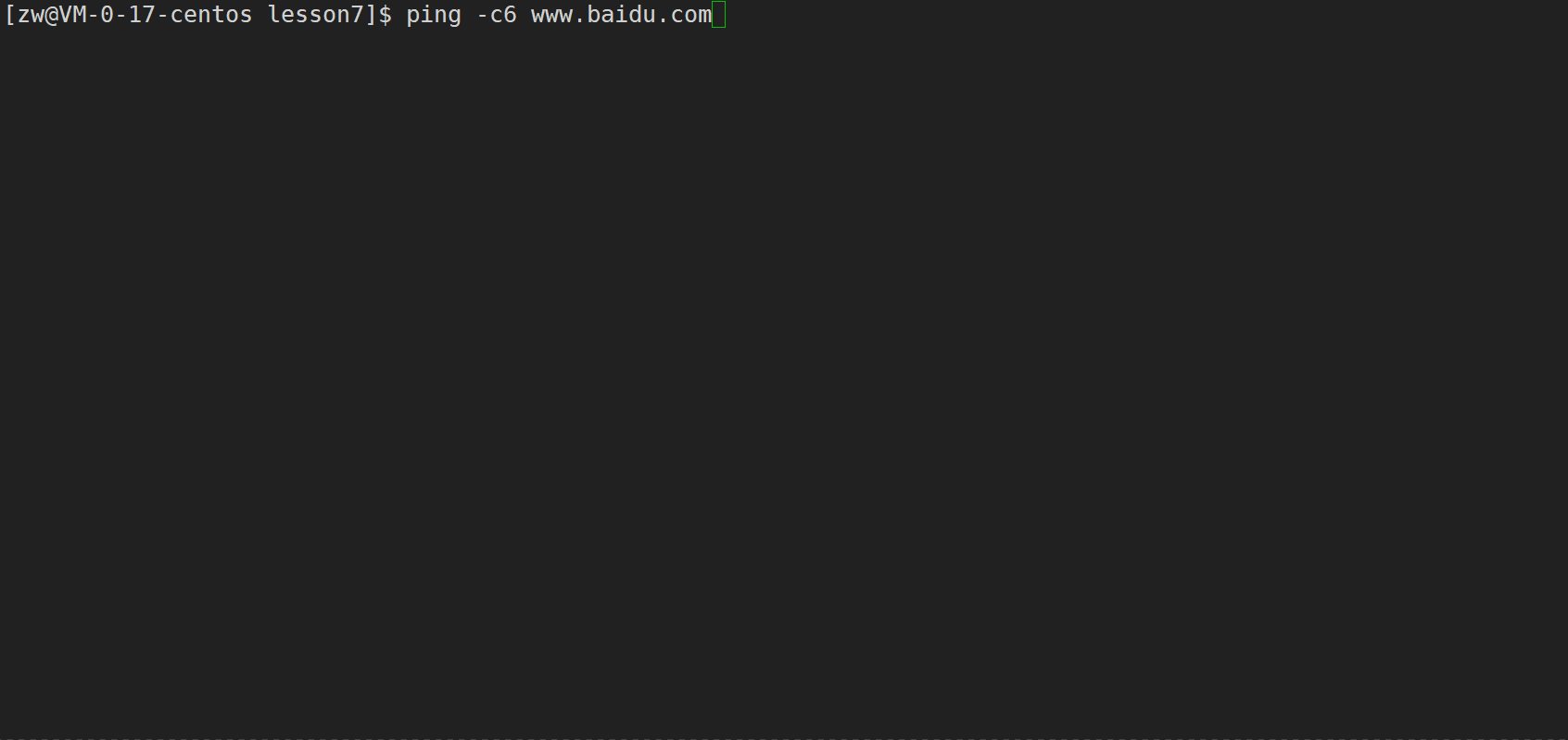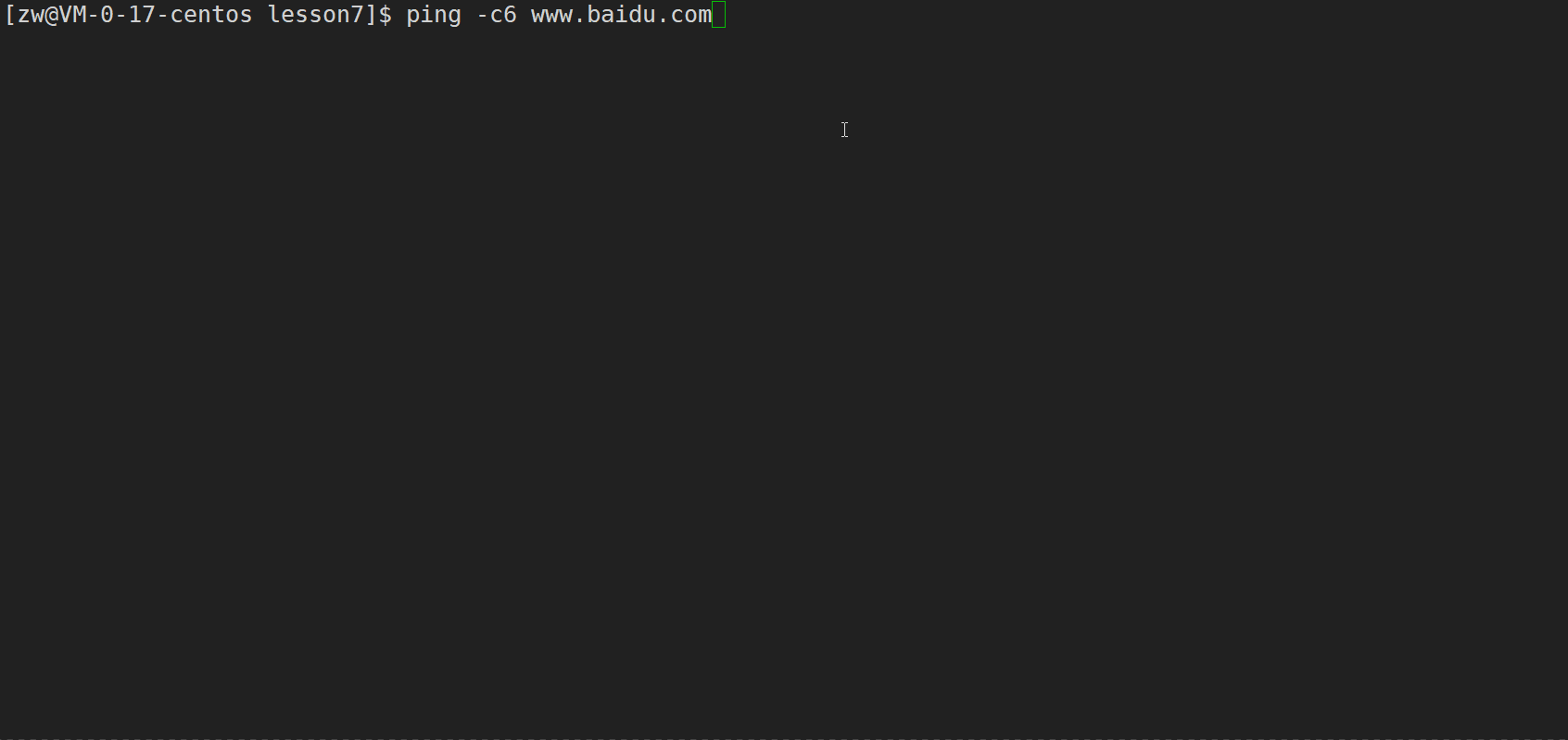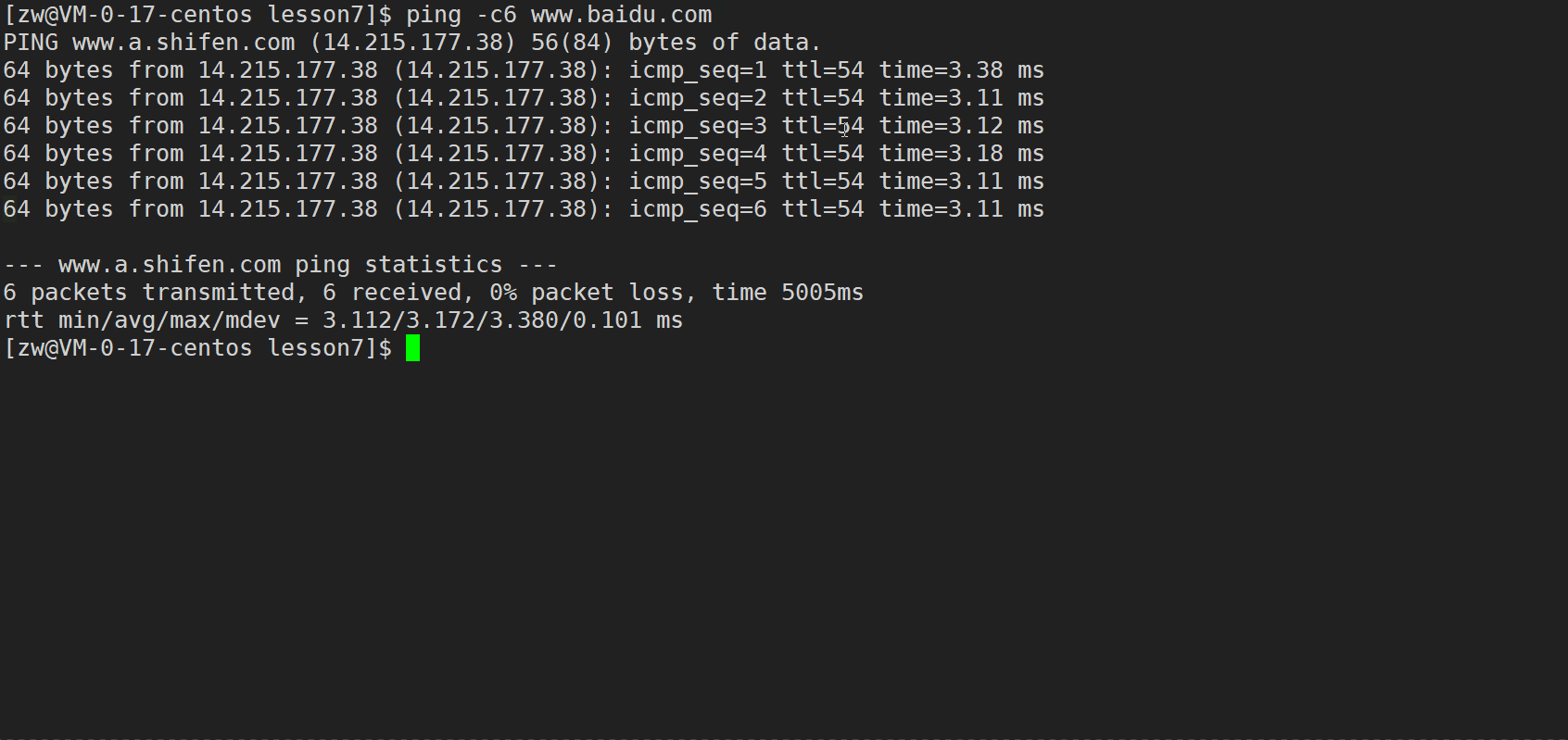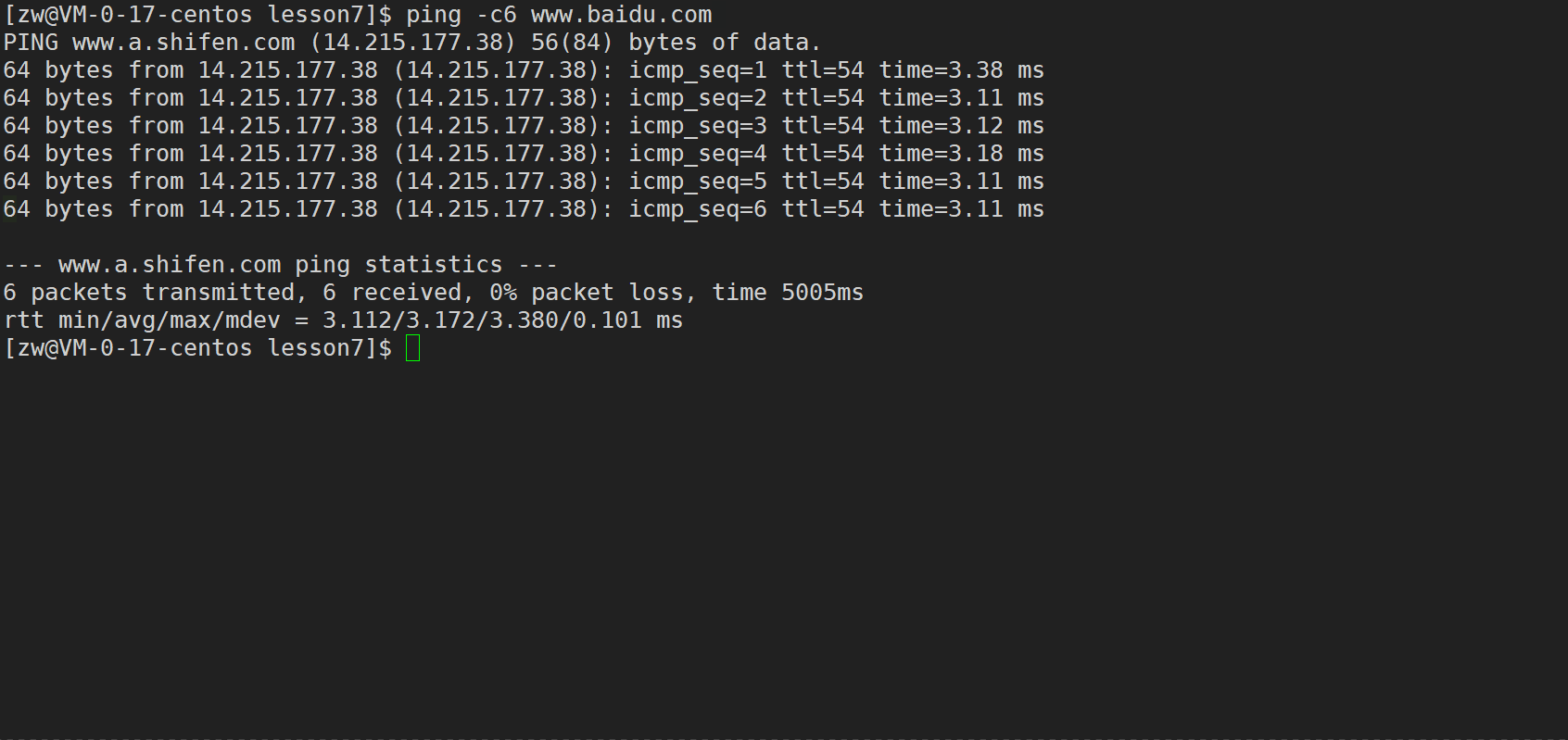
红框部分表示:传输了6个分组包,6个都被(百度服务器)成功接收了,丢包率是0%,耗时 5005ms(5.005s)
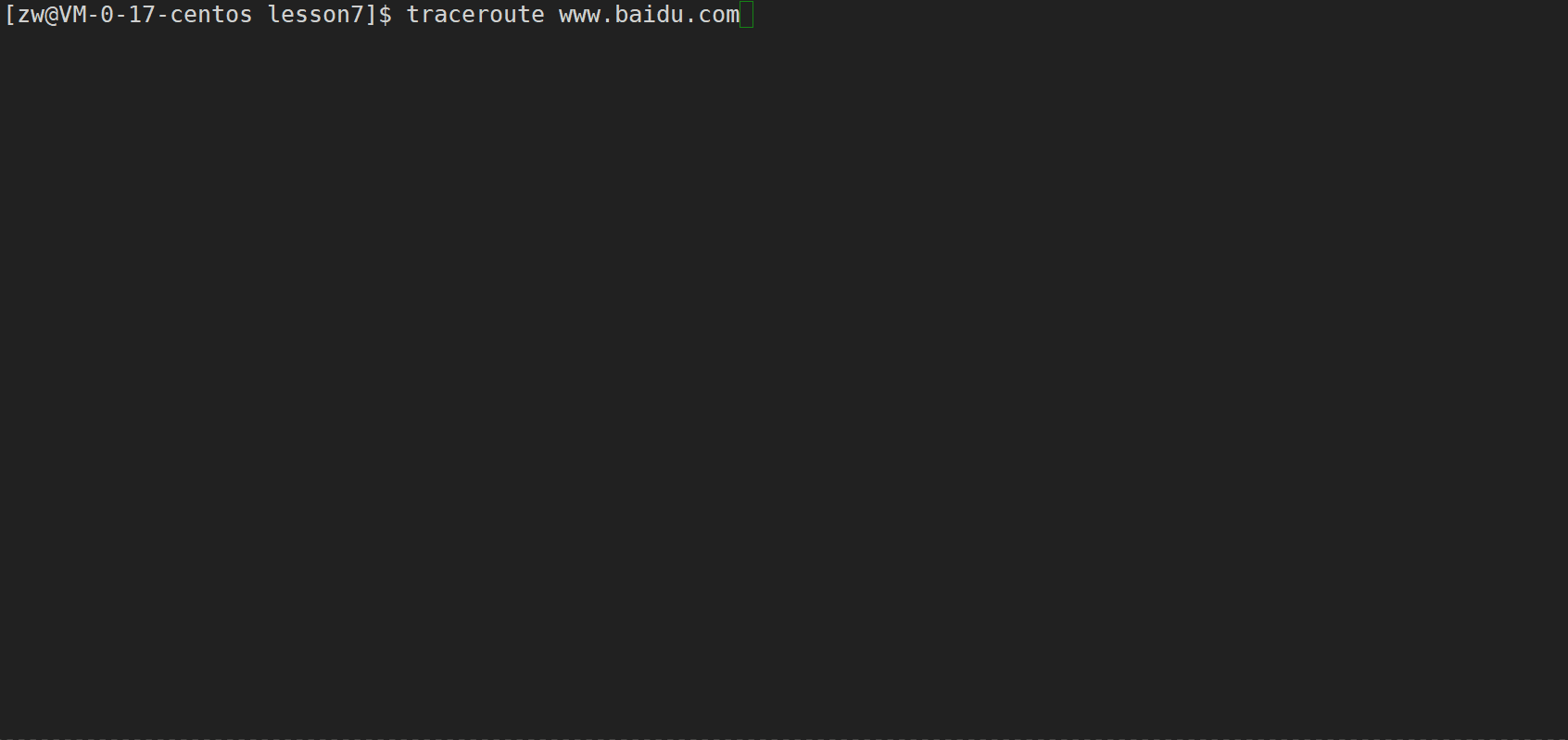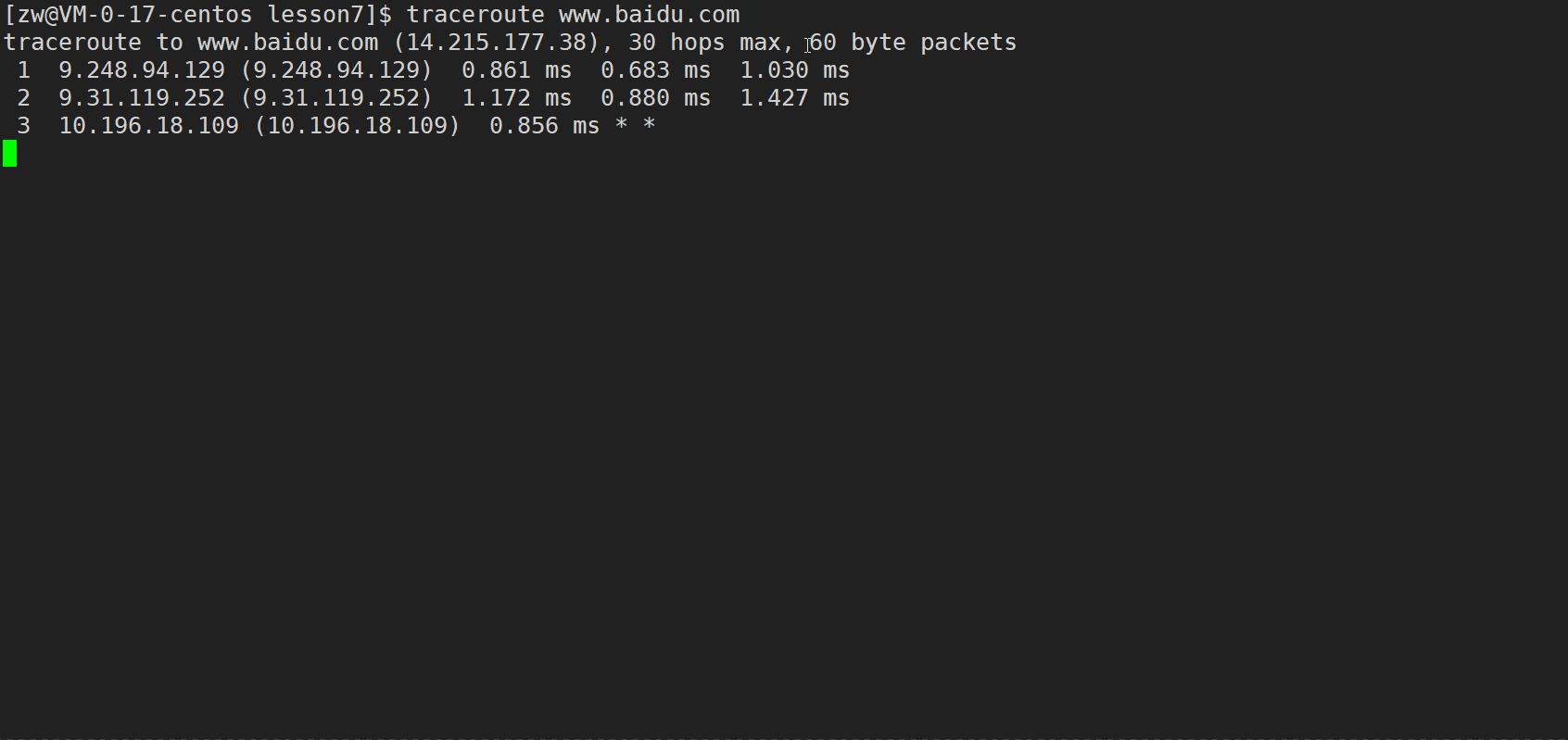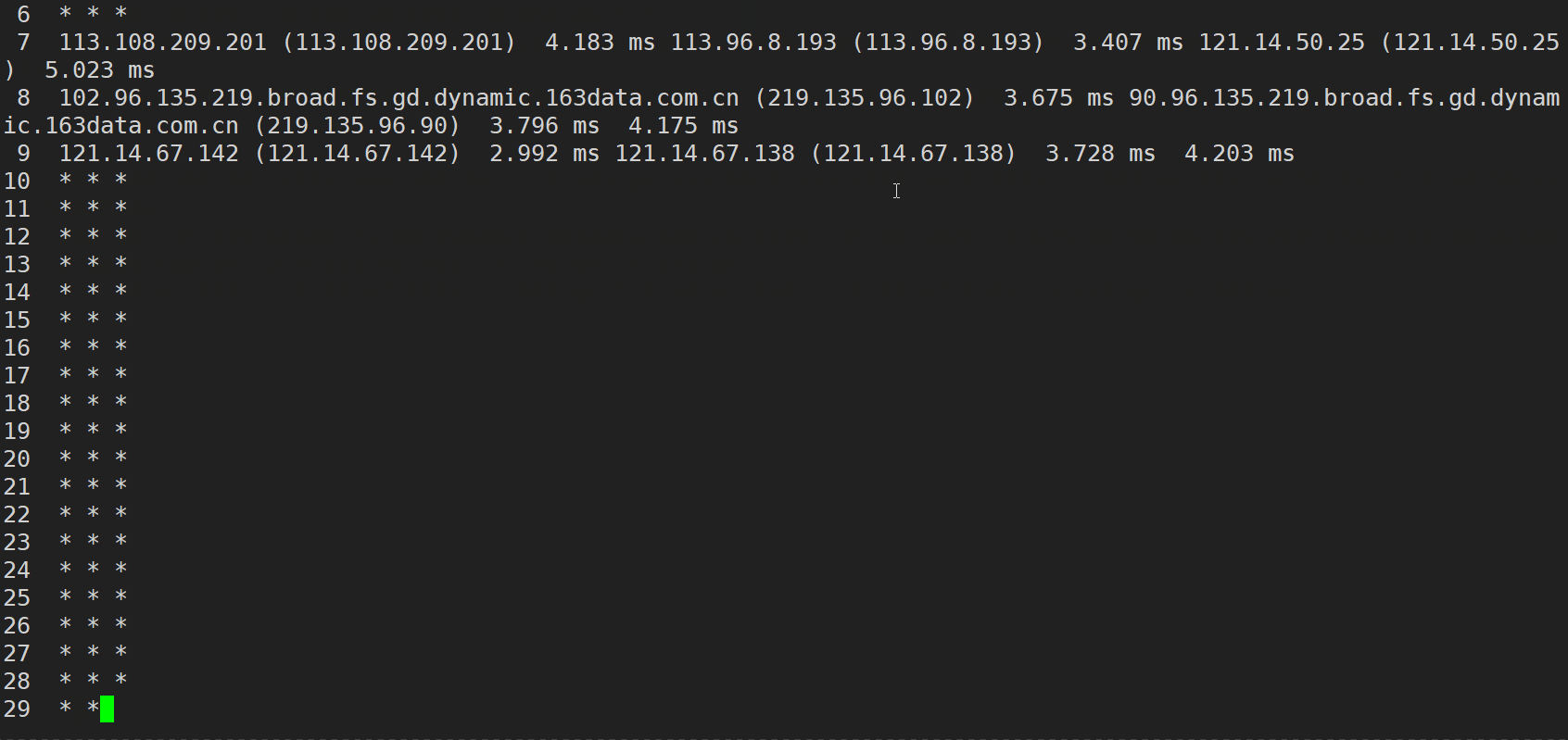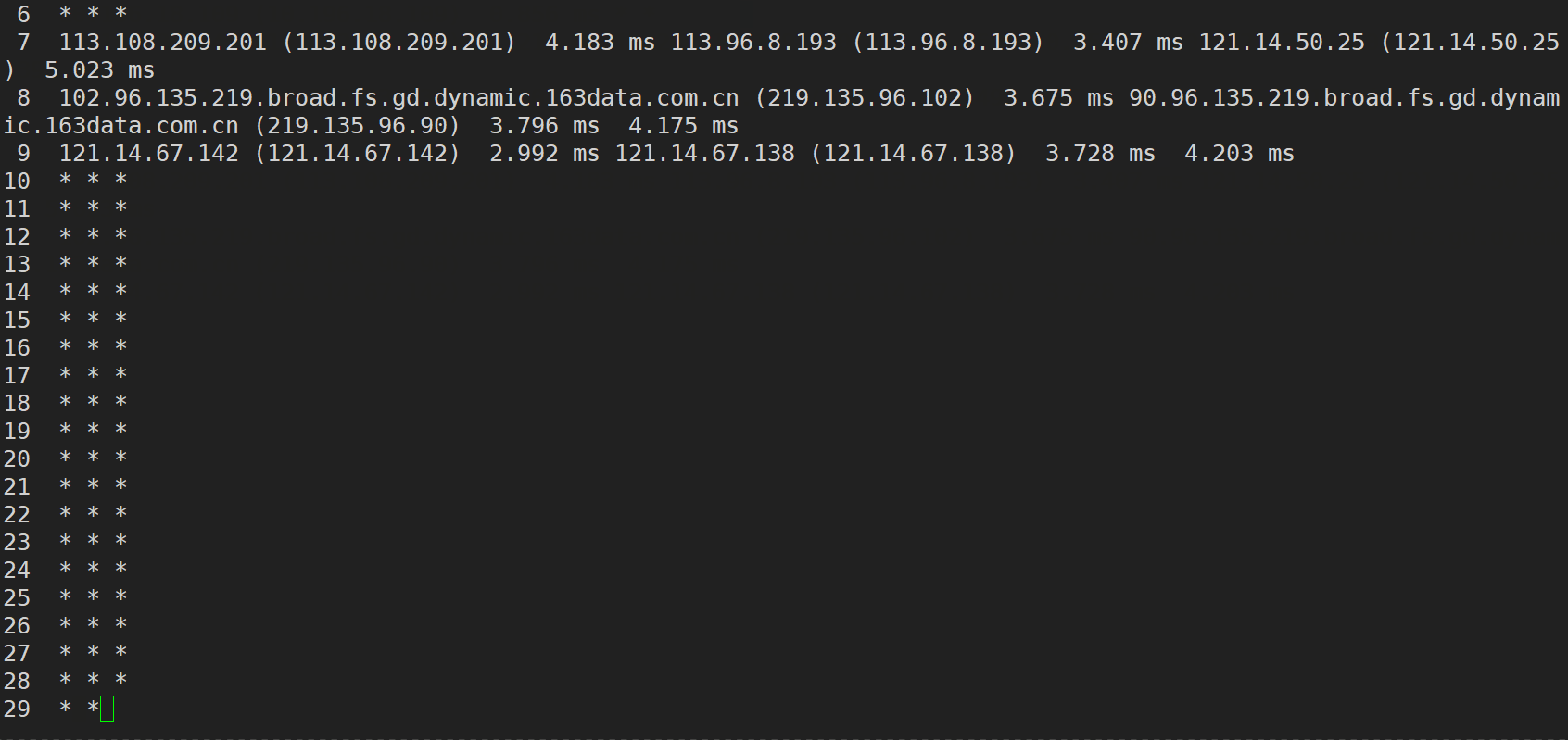
此外,我们还可以利用 traceroute(路由追踪)来进行网络分析
traceroute (Windows系统下是 tracert) 命令利用 ICMP 协议 (互联网控制报文协议,用来报告ip分组传输的差错情况)定位我们的计算机和目标计算机之间的所有路由器。TTL (Time To Live,生存时间,实际上就是跳数,每经过一个路由器,跳数-1,变为0的时候就不能继续在网络中传输了,会被路由器直接丢弃)值可以反映数据包经过的路由器或网关的数量,通过操纵独立ICMP 呼叫报文的TTL 值和观察该报文被抛弃的返回信息,traceroute命令能够遍历到数据包传输路径上的所有路由器。
查看软件包
通过yum list命令可以罗列出当前一共有哪些软件包。由于包的数目可能非常之多,这里我们需要使用grep命令(行过滤)筛选出我们关注的包。
如果我们直接用 yum list 来查看这些软件包,然后去找我们想要安装的软件包,根本就找不到!
yum list
假如我们想要查看 lrzsz软件包,那么我们可以先将yum list 的内容放入管道 | 中,然后用grep 行过滤工具根据关键字 lrzsz 进行过滤查看。可以很方便的找到!
yum list | grep lrzsz

1)软件包名称:主版本号、次版本号、源程序发行号、软件包的发行号主机平台、cpu架构。
2)"x86_64"后缀表示64位系统的安装包,"i686"后缀则表示32位系统安装包,选择包时要和系统匹配。
3)"el7”"表示操作系统发行版的版本, "el7”表示的是centos7/redhat7。 “el6”表示centos6/redhat6。
4)最后一列,os/base/epel 表示的是"软件源”的名称,类似于"小米应用商店”,"华为应用商店"这样的概念
【扩展】
yum search lrzsz//我们也可以用yum search 来搜索软件包

如何安装软件
我们可以通过 yum install 这条很简单的一条命令来完成 lrzsz 的安装,lrzsz是一款在linux里可代替ftp上传和下载的程序。(在使用 **yum install / remove ** 来进行软件安装/卸载时,要注意当前用户的权限)
sudo yum install lrzsz//安装软件需要比较高的权限,所以要用sodu来暂时提升权限
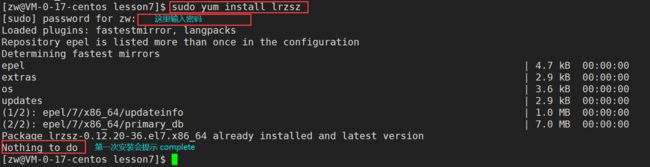
yum会自动找到都有哪些软件包需要下载,这时候敲"y"确认安装。出现"complete"字样,说明安装完成。
【注意事项】
1)安装软件时,由于需要向系统目录中写入内容,一般需要sudo提权或者切到root账户下才能完成。
2)yum安装软件只能一个安装完了再安装另一个。
3)yum正在安装一个软件的过程中,如果再尝试用yum安装另外—个软件,yum会报错。
如果出现yum 报错,问问度娘或者Google一下。
如何卸载软件
通过下面这条命令卸载
sudo yum remove lrzsz //卸载软件也需要比较高的权限,所以要用sodu来暂时提升权限
总结:三板斧操作
1)通过 yum list 查看所有软件包
yum list | grep lrzsz 过滤出指定关键字的软件包,或者 搜索指定软件包 比如:yum search gcc 搜索gcc的软件包,当然,我们也可以用yum makecache 将软件包信息保存到本地(加快软件包查看速度)
2)安装 用sudo提权(或者su root切换成超级用户/管理员) 安装软件必须具有管理员权限 yum install — 安装软件包 比如:yum install lrzsz
3)卸载 用sudo提权(或者su root切换成超级用户/管理员) 卸载软件必须具有管理员权限 yum remove — 卸载软件包 比如: yum remove lrzsz
用yum来安装几个好玩的东西
前期准备
先安装软件包epel-release,epel (Extra Packages for Enterprise Linux)是基于Fedora的一个项目,为“红帽系”的操作系统提供额外的软件包,适用于RHEL、CentOS和Scientific Linux。相当于安装了一个第三方的扩展软件安装应用商城~,接下来要安装的几条命令都是在这个扩展源里面的。
【说明】以下安装默认都是使用非root用户,所以yum前面都添加了sudo进行暂时提权,如果我们是用root用户安装,直接忽略sudo即可。
sudo yum install epel-release
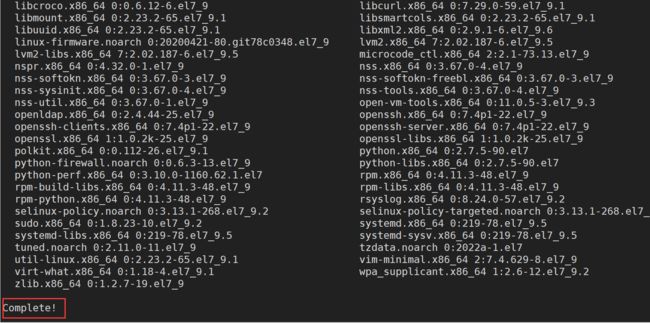
出现 Complete表示安装完成。
安装小火车
sudo yum install sl
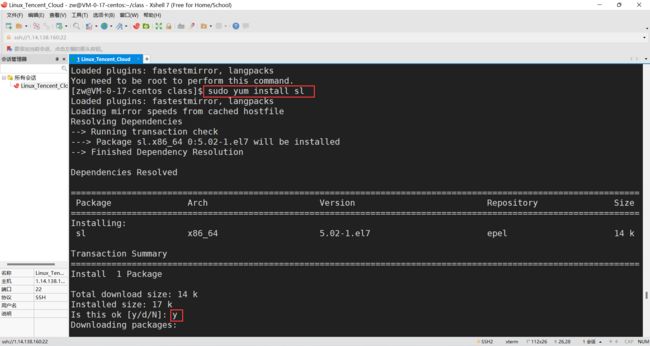
【效果展示】
卸载小火车 sudo yum remove sl

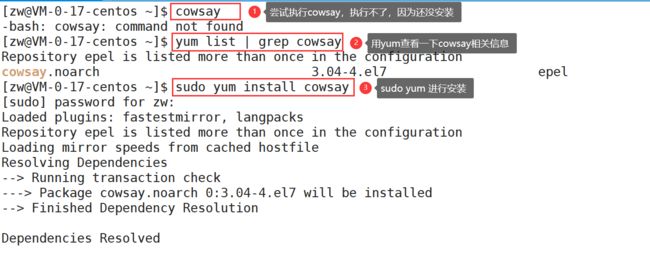
安装cowsay(奶牛说话)
sudo yum install cowsay
echo "xxxx" | cowsay//使用方式:将xxxx替换成我们要说的内容即可
【效果展示】
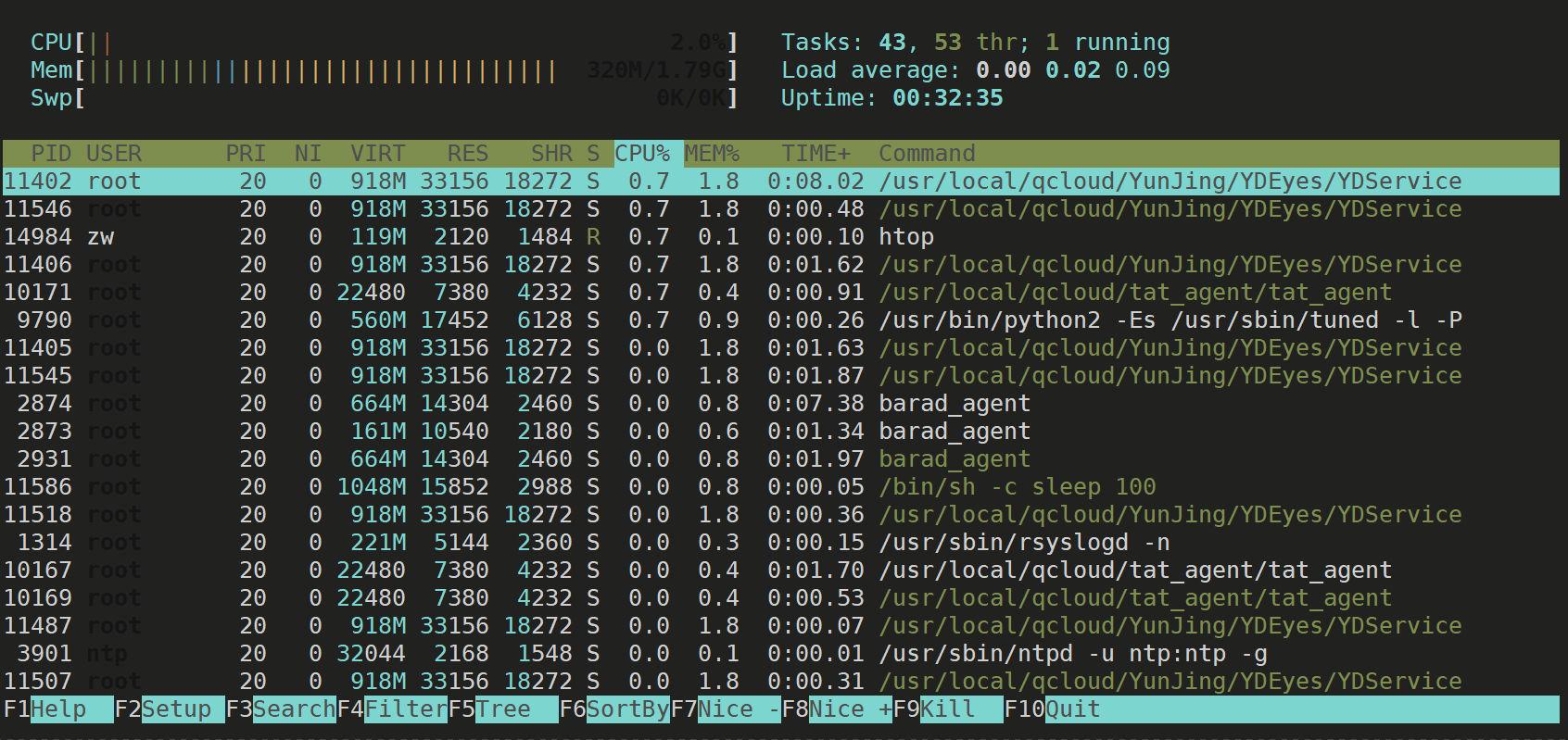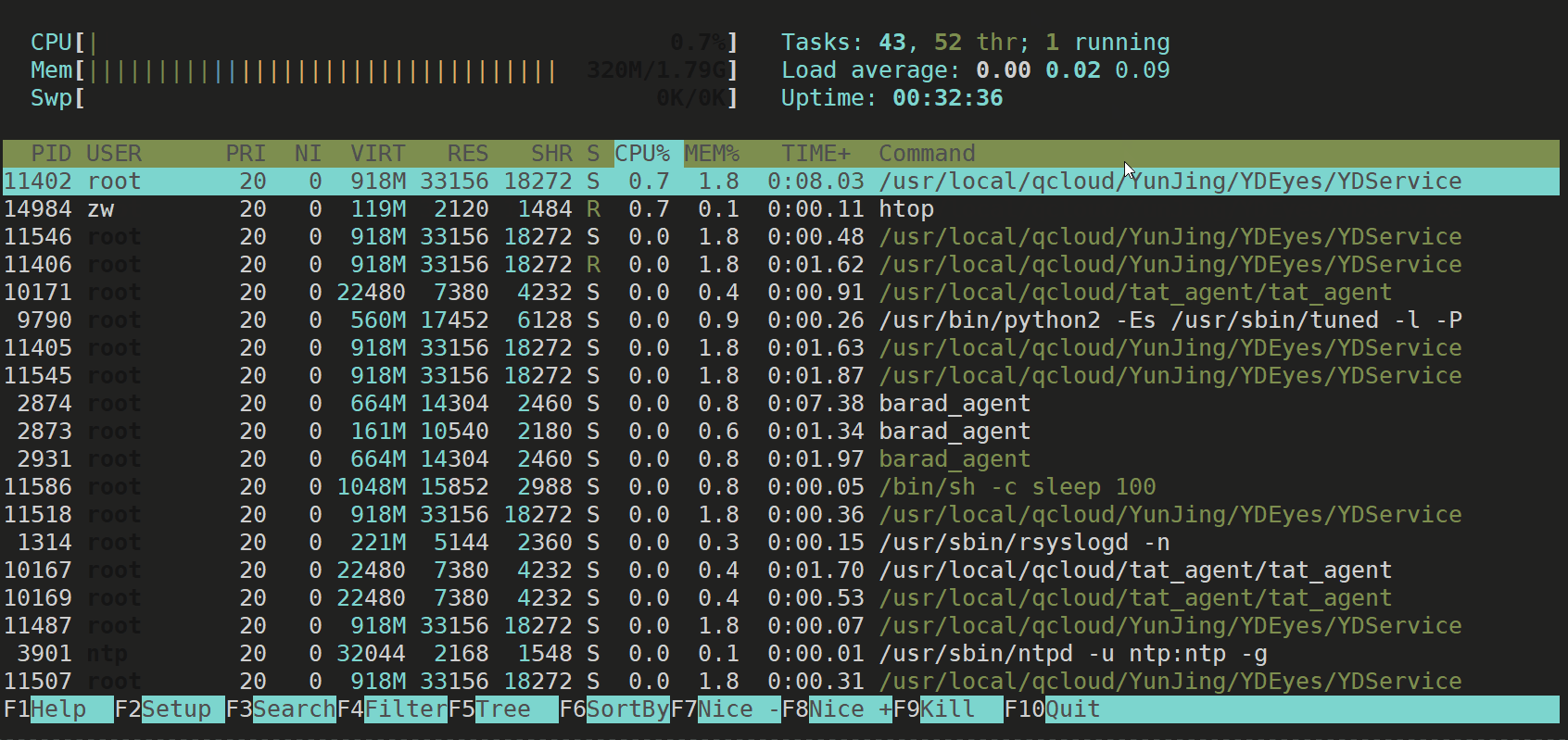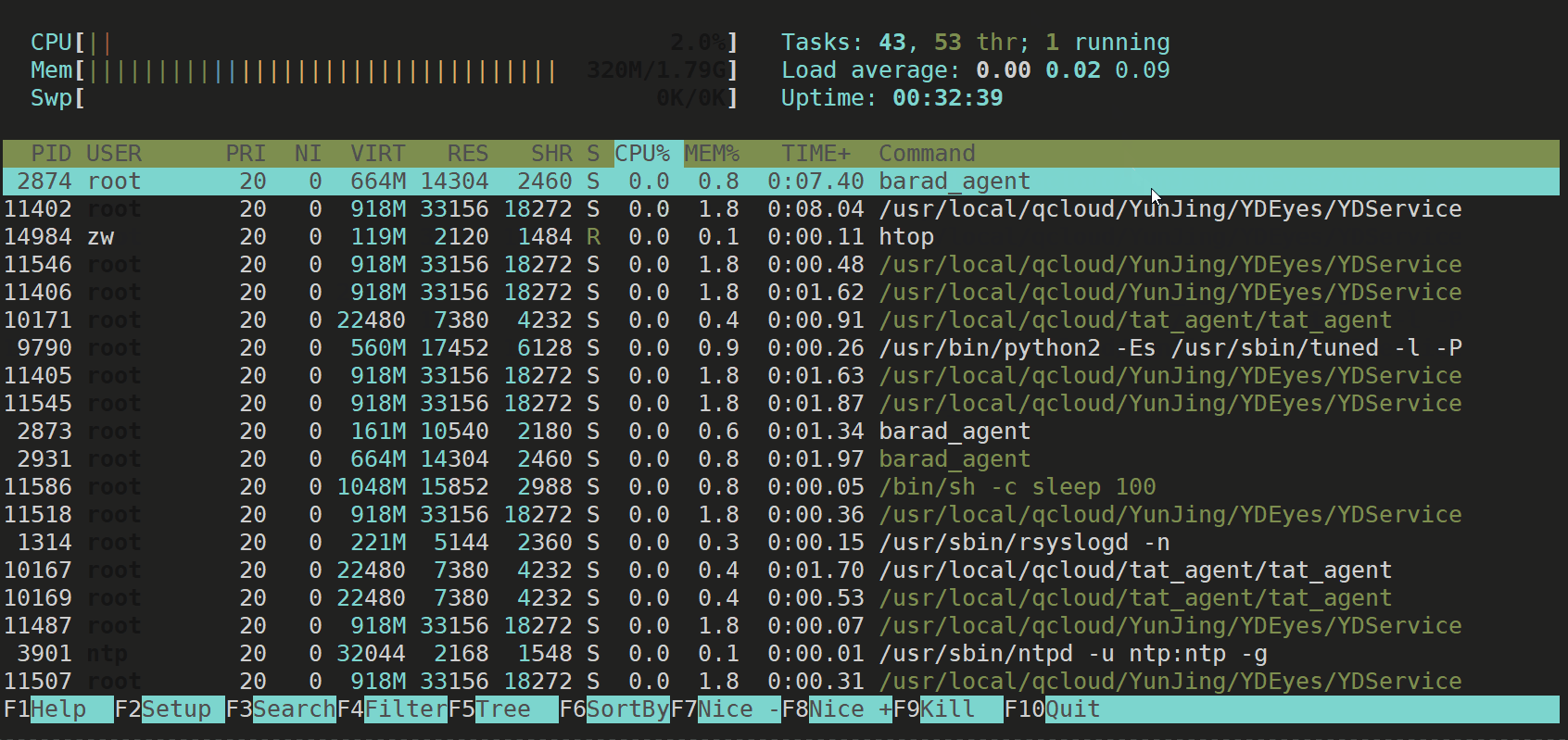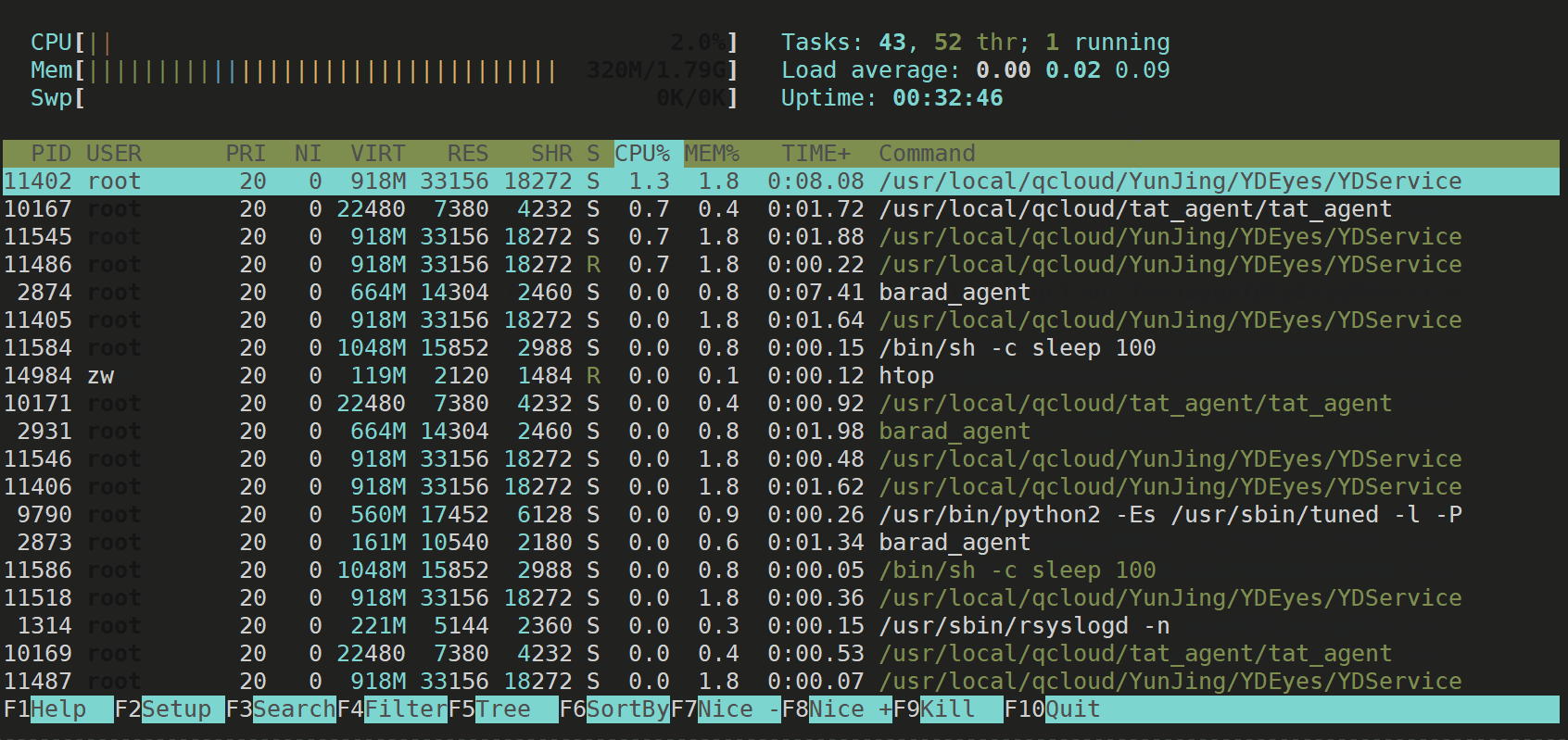
图形化检测工具
1)安装epel-release源
yum install -y epel-release
2)安装
sudo yum install htop
备注:如果有提示输入 y 即可。
3)安装成功
执行方式:直接输入htop,按enter执行即可。
htop
停止命令:ctrl+c
【效果展示】
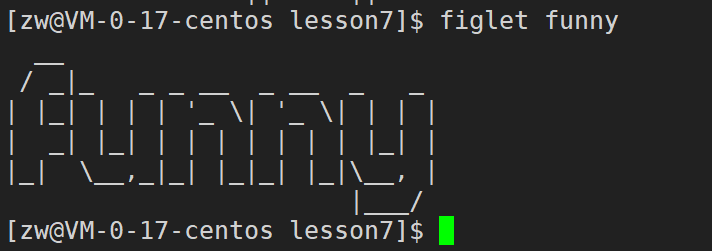
用一串符号拼成指定的单词打印
1)安装epel-release源
yum install -y epel-release
2)安装
sudo yum install figlet
备注:如果有提示输入 y 即可。
3)安装成功
执行命令:
figlet funny
备注:需要输出什么就 figlet + 什么 即可。
【效果展示】
名言句子打印
1)安装epel-release源
yum install -y epel-release
2)安装
sudo yum install fortune-mod
【备注】如果有提示输入 y 即可。
3)安装成功
执行命令:
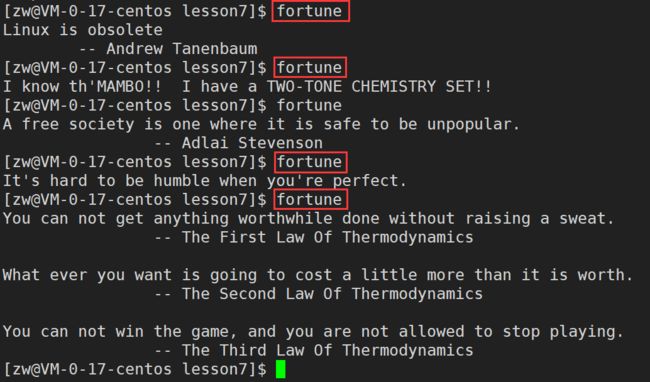
fortune
【效果展示】
Linux 开发工具
Linux下常用的软件工具:
| 工具 | 内容 |
|---|---|
| 编译器 | gcc / g++ |
| 编辑器 | vim、vi、nano |
| 调试器 | gdb |
| 版本管理工具 | git |
查看常用工具是否已经安装:查看每个工具是否有版本信息
gcc --version :查看gcc版本信息(注意要有2个 - )

git --version :查看git版本信息

如果能看到版本信息,就表明已经安装了,如果查看不到,就表示还没安装,安装方式
sudo yum install git
Linux编辑器-vim的使用
vim是什么?
Vim是一个类似于Vi的著名的功能强大、高度可定制的文本编辑器,在Vi的基础上改进和增加了很多特性。VIM是自由软件。Vim普遍被推崇为类Vi编辑器中最好的一个,事实上真正的劲敌来自Emacs的不同变体。1999 年Emacs被选为Linuxworld文本编辑分类的优胜者,Vim屈居第二。但在2000年2月Vim赢得了Slashdot Beanie的最佳开放源代码文本编辑器大奖,又将Emacs推至二线, 总的来看, Vim和Emacs在文本编辑方面都是非常优秀的。

vim的基本概念
虽然vim有很多种模式,但是我们只需要掌握三种模式就够用了,分别是命令模式(command mode)、插
入模式(Insert mode)和底行模式(last line mode),各模式的功能区分如下:
1)正常/普通/命令模式(Normal mode)
控制屏幕光标的移动,字符、字或行的删除,移动复制某区段及进入Insert mode下,或者到last line mode。
2)插入模式(Insert mode)
只有在Insert mode下,才可以做文字输入,按「ESC」键可口到命令行模式。该模式是我们后面用的最频繁的编辑模式。
3)底行模式(last line mode)
文件保存或退出,也可以进行文件替换,找字符串,列出行号等操作。在命令模式下,shift+: 即可进入该模式。要查看你的所有模式:打开vim,底行模式直接输入
:help vim-modes
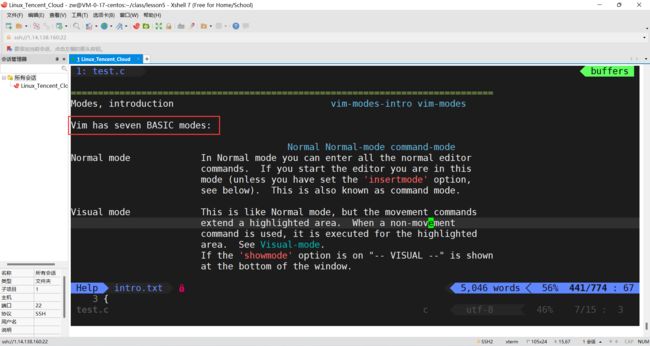
我这里一共有13种模式:seven BASIC modes 和 six ADDITIONAL modes(7种基本模式和6种附加模式)
但是我们实际中使用的仅有3种,不要被迷惑了!
vim的基本操作
1)进入vim,在系统提示符号输入vim及文件名称后,就进入vim全屏幕编辑画面:
vim test.c
不过有一点要特别注意,就是但我们进入vim之后,是处于[正常模式],要切换到[插入模式]才能够输入文字。
2)[正常模式]切换至[插入模式]
①输入a
②输入i
③输入o
3)[插入模式]切换至[正常模式]
目前处于[插入模式],就只能一直输入文字,如果发现输错了字,想用光标键往回移动,将该字删除,可
以先按一下「ESC」键转到[正常模式]再删除文字。当然,也可以直接删除。
4)[正常模式]切换至[底行模式]。
「shift +;」,其实就是输入「:」
5)退出vim及保存文件,在[正常模式]下,按一下「:」冒号键(「shift +;」)进入「Last line mode」
例如:
:w//(保存当前文件)
:wq//(输入「wq」 ,存盘并退出vim):q!(输入q!,不存盘强制退出vim)
是不是看的有点晕,我刚接触的时候也很晕,所以就画了一个图,然后在Xshell下面多敲几次就不晕了。

【动图演示】

vim正常模式命令集
温习提示:下面的命令会比较多,不需要全部记下来,只需要根据实际使用记住一些常用的就ok了,建议参考思维导图,里面列出来的就是常用的和重点的。
插入模式
1)按「i」切换进入插入模式「insert mode」,按"I"进入插入模式后是从光标当前位置开始输入文件。
2)按「a」进入插入模式后,是从目前光标所在位置的下一个位置开始输入文字。
3)按「o」进入插入模式后,是插入新的一行,从行首开始输入文字。
从插入模式切换为命令模式
按「ESC」键
移动光标
1)vim可以直接用键盘上的光标来上下左右移动,但正规的vim是用小写英文字母[h]、[j] 、[k」[l](左下上右)
分别控制光标左、下、上、右移一格。记忆方法:h在最左边表示左,l在最右边表示右,j(jump跳,跳下去,表示下)k(king,国王总是一副高高在上的样子,表示上)。
2)按「G」:移动到文章的最后。
3)按「$」:移动到光标所在行的“行尾”。
4)按「^」:移动到光标所在行的“行首”。
5)按「w」︰光标跳到下个字的开头。
6)按「e」 :光标跳到下个字的字尾。
7)按「b」:光标回到上个字的开头。
8)按「#l」:光标移到该行的第#个位置,如:5l,56I。
9)按[gg]:进入到文本开始。
10)按[shift +g]︰进入文本末端。
11)按「ctrl] +「b」:屏幕往"后′移动一页。
12)按「ctrl]+[f︰屏幕往′前"移动一页。
13)按「ctrl」 +「u」︰屏幕在"后移动页。
14)按「ctrl」 + 「d」 :屏幕往前"移动半页。
删除文字
1)「x」:每按一次,删除光标所在位置的一个字符。
「#x」︰例如,「6x」表示删除光标所在位置的"后面(包含自己在内)"6个字符。
2)「X」:大写的X,每按一次,删除光标所在位置的“前面"一个字符。
「#X」︰例如,「20X]表示删除光标所在位置的“前面"20个字符。
3)[dd]:删除光标所在行。
[#dd]:从光标所在行开始删除#行。
复制
1) [yw」:将光标所在之处到字尾的字符复制到缓冲区中。
「#yw」:复制#个字到缓冲区。
2)[yy]:复制光标所在行到缓冲区。
「#yy|:例如,「6yy」表示拷贝从光标所在的该行"往下数"6行文字。
3)[p]:将缓冲区内的字符贴到光标所在位置。
注意:所有与’y"有关的复制命令都必须与"p"配合才能完成复制与粘贴功能。
替换
1)[r]:替换光标所在处的字符。
2)[R]:替换光标所到之处的字符,直到按下「ESC」键为止。
撤销上—次操作
1)[u]:如果我们误执行一个了命令,可以马上按下「u」,回到上一个操作。
按多次"u"可以执行多次回复。
2)[ctrl+ r]︰撤销的恢复,也就对撤销的撤销。
更改
1)「cw」 :更改光标所在处的字到字尾处
「c#w」:例如,「c3w」表示更改3个字
跳至指定的行
1)[ctrl+g]列出光标所在行的行号。[重要]
2)「#G」:例如,「15G」,表示移动光标至文章的第15行行首。
vim底行模式命令集
在使用底行模式之前,请记住先按「ESC」键确定您已经处于正常模式,再按「:」冒号即可进入底行模式。
列出行号
1)「[set nu」:输入「set nu」后,会在文件中的每、行前面列出行号。
跳到文件中的某一行
1)「#」︰「#」号表示一个数字,在冒号后输入一个数字,再按回车键就会跳到该行了,如输入数字15,
再回车,就会跳到文章的第15行。
查找字符
1)「/关键字」︰先按「」键,再输入我们想寻找的字符,如果第一次找的关键字不是想要的,可以一直按
「n」会往后寻找到想要的关键字为止。
2)「?关键字」︰先按「『?」链,再输入我们想寻找的字符,如果第一次找的关键字不是想要的,可以一直按「n」会往前寻找到想要的关键字为止。
3)问题:/和?查找有和区别?有兴趣的小伙伴可以自己动手操作实验一下。
保存文件
1)「w」:在冒号后面输入字母「w」就可以将文件保存起来
离开vim
1)「q」:按[q](quit)就是退出,如果无法离开vim,可以在「q」后跟一个「!」强制离开vim,也就是[q!]。
2)「wq」:一般建议离开时,搭配「w」一起使用,这样在退出的时候还可以保存文件。
vim操作总结
三种模式
正常模式、插入模式、底行模式
我们一共有13种模式,大家感兴趣可以自己研究一下
vim操作
打开,关闭,查看,查询,插入,删除,替换,撤销,复制等操作。
简单vim配置[拓展]
【温馨提示】
以下内容有兴趣的同学可以看一下,没有兴趣的同学可以直接跳到一键配置vim环境处,开启懒人模式~
配置文件的位置
1)在目录/etc/下面,有个名为vimrc的文件,这是系统中公共的vim配置文件,对所有用户都有效。
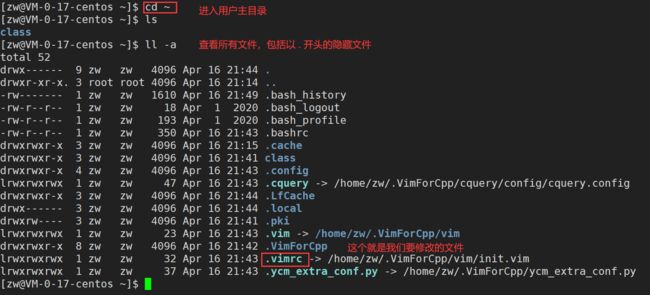
2)而在每个用户的主目录下,都可以自己建立私有的配置文件,命名为:“.vimrc”。例如:./root目录下,通常已经存在一个.vimrc文件。如果不存在,那么我们需要自己创建它。(按下面的步骤)
3)进入自己的主工作目录,执行cd~(注意不要使用root用户)
4)打开自己目录下的.vimrc文件,执行vim .vimrc
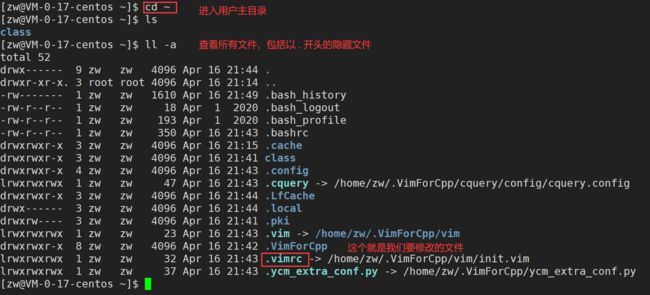
常用配置选项,用来测试
1)设置语法高亮: syntax on
2)显示行号: set nu
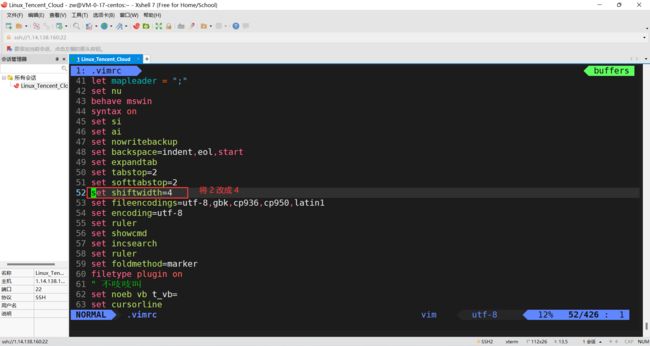
3)设置缩进的空格数为4: set shiftwidth=4

使用插件
要配置好看的vim,原生的配置可能功能不全,可以选择安装插件来完善配置,保证用户是我们要配置的用户,接下来:
1)安装TagList插件,下载taglist_xx.zip ,解压完成,将解压出来的doc的内容放到/.vim/doc,将解压出来的plugin下的内容拷贝到/.vim/plugin
2)在~ .vimrc中添加:let Tlist show_one_Fjte 1 let Tlist_Exit_onlywindow=1 letTlist_use_Right_window=1
3)安装文件浏览器和窗口管理器插件: WinManager
4)下载winmanager.zip,2.X版本以上的
5)解压winmanager.zip,将解压出来的do c的内容放到~l.vim/doc,将解压出来的plugin下的内容拷贝到~/.vim/plugin
6)在~ /.vimrc中添加let g :winManagerwindowLayout='FileExplorer|TagList nmap wm: wMToggle
更具体移步:点我,其他手册,请执行vimtutor命令。
从上面这些步骤我们可以看到,如果要我们按部就班自己去配置vim环境是非常非常麻烦了,没有几天的工夫根本配置不出来我们想要的效果,好在有开源的存在,哪里有困难哪里就有解决的方案~
vim环境配置—一键配置专用(多快好省,强烈推荐)
gitee搜索开源vimforcpp
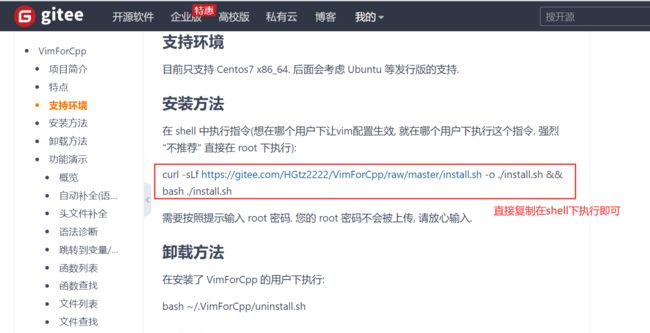
提示:如果网络不好,下载的时候需要等一小会,下载结束后,会提示我们下载成功并需要我们进行手动输入命令来重启vim
开始下载:
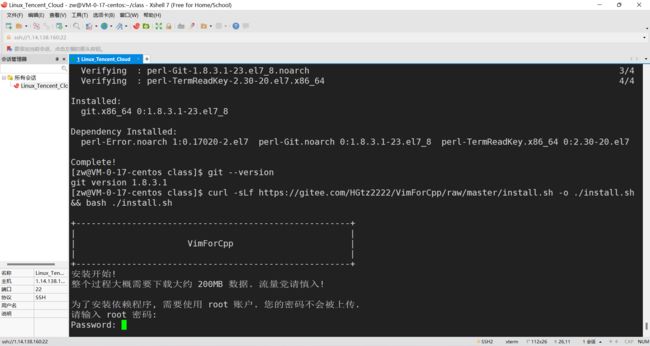
下载完成:

如果某些配置不喜欢,比方说行距不喜欢(VS下默认是4个空格,这里是2个),我们可以自己通过【.vimrc】修改相应的配置。
【效果展示】
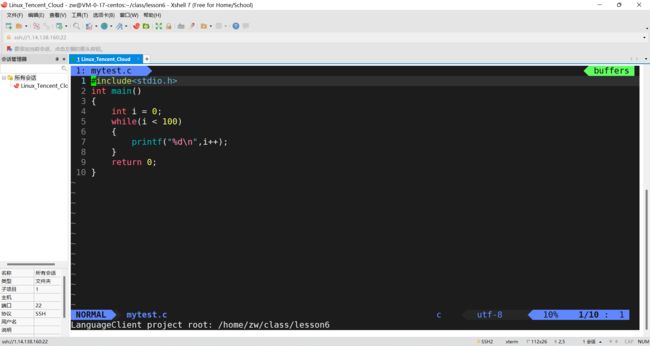
vim相关问题补充
vim 打开文件报错
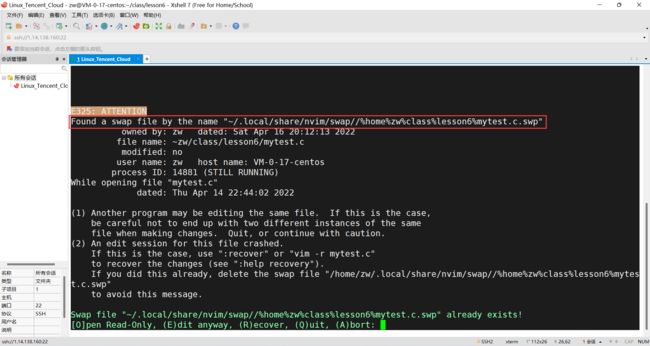
vim打开文件,其实每次都是打开一个临时文件,作为中间交换文件,然后关闭源文件,编辑的操作都是在中间文件中完成的,只有正常退出【:wq】的时候才会将改变的数据写入到源文件中,并且删除中间文件,否则中间文件存在的情况下,下次vim打开文件的时候就会报出警告。比如用ctrl+z退出mytest.c文件,会生成.mytest.c.swp(以.开头的文件是隐藏文件,用ls -a查看),将.mytest.c.swap删除后,才能正常打开mytest.c文件(这时候,这个交换文件可能会在.c源文件所在的文件夹下面,可以直接用ls -a查看并用rm删除)。
如果交换文件不在当前文件夹下,则可以采取下面这种方式,将路径信息从报错信息中复制出来,再用rm删除。

vim键盘图
更多参考资料
Vim 从入门到精通 (github.com)
Linux编译器-gcc/g++使用
背景知识
| 阶段 | 任务 |
|---|---|
| 预处理 | 头文件展开、宏替换、条件编译、去注释,生成 xxx.i 文件 |
| 编译 | 语义分析、语法分析等,生成 xxx.s 文件 |
| 汇编 | 将汇编语言转换为二进制机器指令,生成 xxx.o 文件 |
| 链接 | 将目标模块及其调用的库函数模块链接起来,生成可执行程序(Windows下 xxx.exe文件) |
gcc 执行格式
格式:gcc [选项] 要编译的文件「选项]「目标文件]
预处理
1)预处理功能主要包括:宏替换、头文件包含、条件编译、去注释等。
2)预处理指令是以#号开头的代码行。eg:#include
3)实例:
gcc -E hello.c -o he11o.i
4)选项"-E,作用是让gcc在预处理结束后停止编译过程。
5)选项"-o"是指要生成的目的文件,“.i"文件为已经过预处理的C原始程序。
编译(生成汇编)
1)在这个阶段中,gcc编译器首先要检查代码的规范性、是否有语法错误等,以确定代码的实际要做的工作,在检查无误后,gc编译器c会把代码翻译成汇编语言。
2)用户可以使用”-S"选项来进行查看,该选项只进行编译而不进行汇编,生成汇编代码。
3)实例:
gcc -S hello.i -o hello.s
汇编(生成机器可识别代码)
1)汇编阶段是把编译阶段生成的".s"文件转成目标文件
2)我们在此可使用选项"-c"就可看到汇编代码已转化为".o"的二进制目标代码了
3)实例:
gcc -c hello.s -o hello.o
连接(生成可执行文件或库文件)
1)在成功编译之后,就进入了链接阶段。
2)实例:
gcc hello.o -o he1lo
在这里涉及到一个重要的概念:函数库
1)我们的C程序中,并没有定义"printf"“的函数实现,且在预编译中包含的"stdio.h"中也只有该函数的声明,而没有定义函数的实现,那么,是在哪里实"printf"函数的呢?
2)最后的答案是:系统把这些函数实现都被做到名为 libc.so.6 的库文件中去了,在没有特别指定时,gcc 会到系统默认的搜索路径**”/usr/lib"下进行查找,也就是链接到 libc.so.6 库函数中去,这样就能实现函数"printf"了,而这也就是链接的作用。
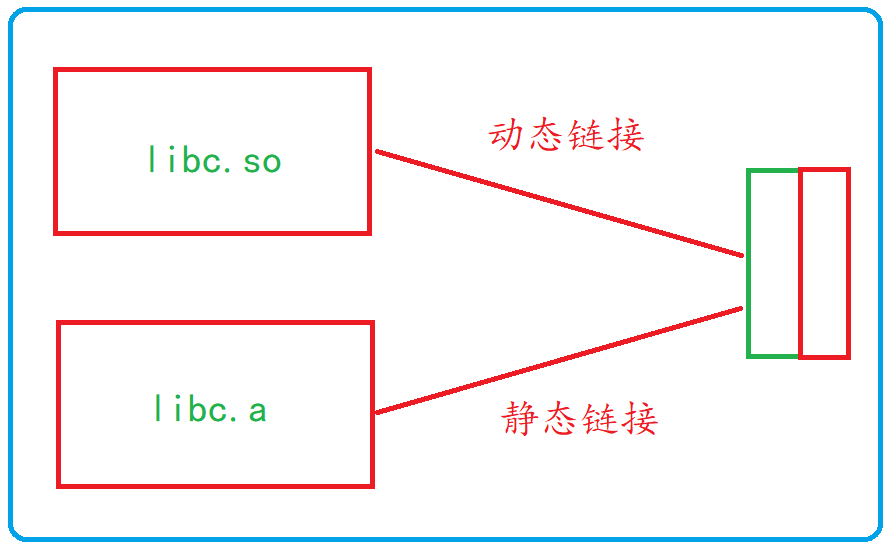
函数库一般分为静态库和动态库两种。
1)静态库是指编译链接时,把库文件的代码全部加入到可执行文件中,因此生成的文件比较大,但在运行时也就不再需要库文件了。其后缀名一般为.a**。
2)动态库与之相反,在编译链接时并没有把库文件的代码加入到可执行文件中,而是在程序执行时由运行时链接文件加载库,这样可以节省系统的开销。动态库一殷后缀名为**.so**,如前面所述的libc.so.6就是动态库。gcc在编译时默认使用动态库。完成了链接之后,gcc就可以生成可执行文件,如下所示。
gcc hello.o -o hello
3)gcc默认生成的二进制程序,是动态链接的,这点可以通过filee命令验证。

gcc选项
| 选项 | 作用 |
|---|---|
| -E | 只激活预处理,不生成文件,我们需要把它重定向到一个输出文件里面,生成 xxx.i 文件 |
| -S | 编译到汇编语言不进行汇编和链接 |
| -c | 编译到目标代码 |
| -o | 文件输出到文件 |
| -static | 此选项对生成的文件采用静态链接 |
| -g | 生成调试信息。GNU调试器可利用该信息。 |
| -shared | 此选项将尽量使用动态库,所以生成文件比较小,但是需要系统由动态库. |
| -O0 | 编译器的优化选项的4个级别,-O0表示没有优化,-O1为缺省值,-O3优化级别最高 |
| -O1 | |
| -O2 | |
| -O3 | |
| -w | 不生成任何警告信息。 |
| -Wall | 生成所有警告信息。 |
gcc 选项记忆
预处理、编译、汇编对应的是 ESc(看看我们键盘最左上角的键是什么),生成的文件后缀分别是 iso 。(国际标准化组织 (International Organization for Standardization)
Linux调试器-gdb使用
背景
1)程序的发布方式有两种,debug模式和release模式
2)Linux gcc/g++出来的二进制程序,默认是release模式
3)要使用gdb调试,必须在源代码生成二进制程序的时候,加上 【-g】 选项
gcc -g mytest.c -o mytest.exe
不加【-g】选项生成的程序,用gdb进行调试,会发现无法调试。(no debugging symbols found)
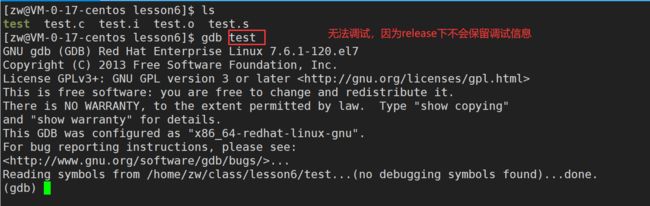
加上【-g】选项生成的程序,用gdb进行调试
开始使用
【进入调试】
gdb filename //gdb + 文件名进入调试
//例如:
gdb test_gdb//test_gdb 是 gcc -g test.c -o test_gdb 生成的
【退出调试】
ctrl + d // 或者输入 quit 命令
list / l 行号(list可以简写成l):显示源文件的源代码信息,接着上次的位置往下列,每次列出10行
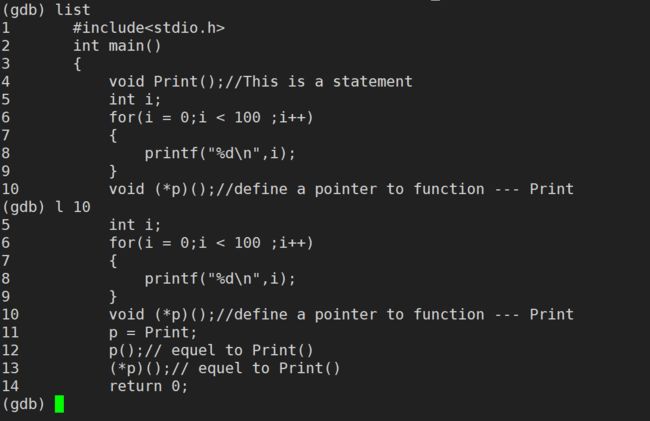
list / I 函数名(list可以简写成l):列出某个函数的源代码

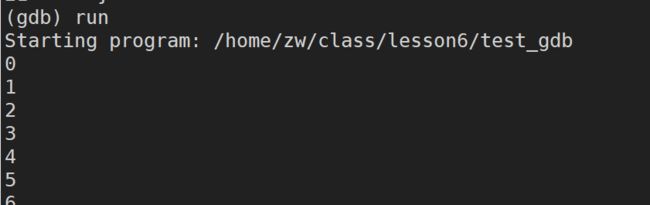
run / r (run可以简写成r):运行程序

break / b 行号(break可以简写成 b):在某一行设置断点
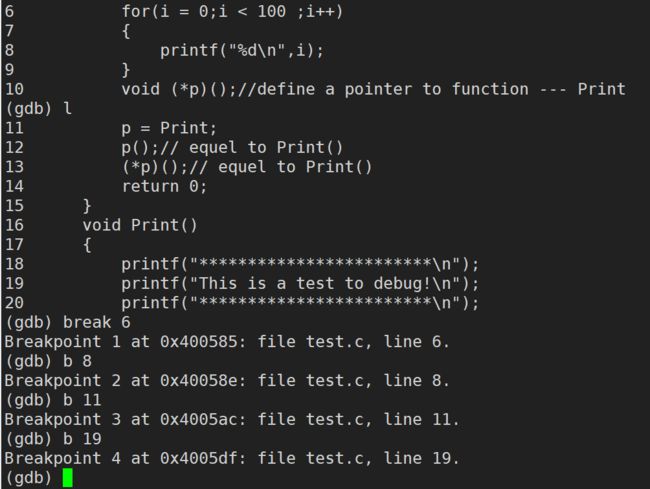
break / b 函数名(break可以简写成 b):在某个函数开头(入口地址)设置断点
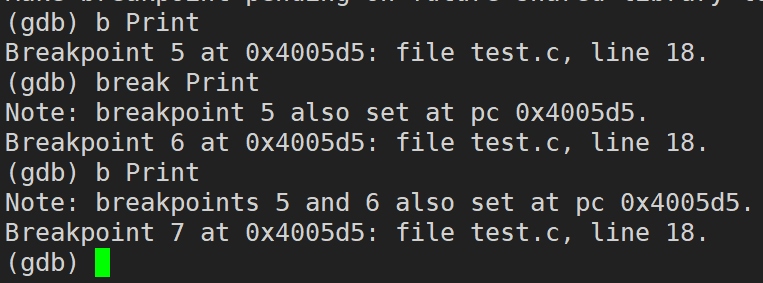
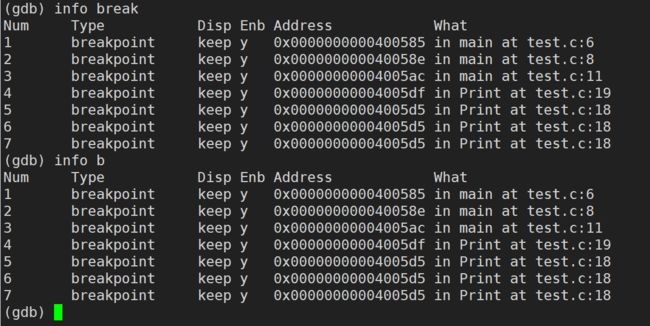
info break / b(break可以简写成 b) :查看断点信息
delete / d breakpoints(delete 可以简写成 d,breakpoints可以简写成break):删除所有断点

delete / d breakpoints n(delete 可以简写成 d,breakpoints可以简写成break):删除序号为n的断点

disable breakpoints(breakpoints可以简写成break):禁用断点
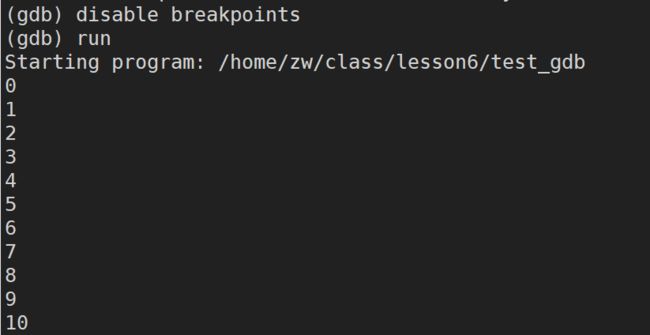
enable breakpoints(breakpoints可以简写成break):启用断点
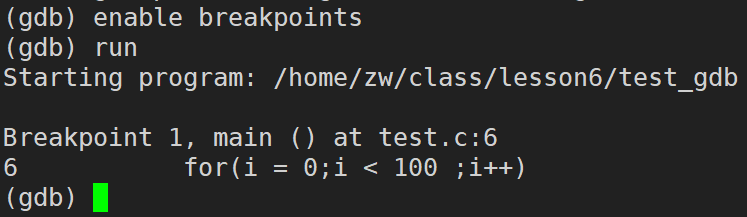
next / n (next 可以简写成 n):逐语句调试,遇到函数调用,不进入函数调用中。(相当于Windows下VS中的 F10 或者 Fn + F10,逐语句调试)
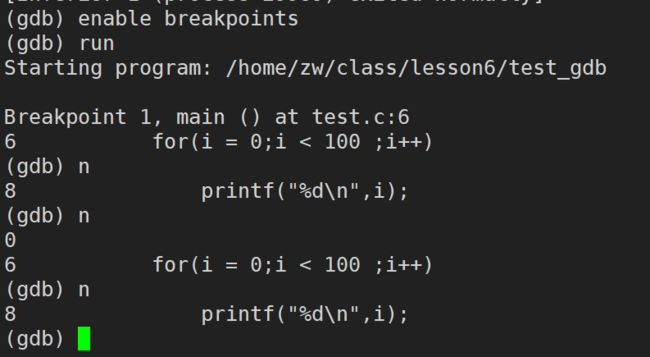
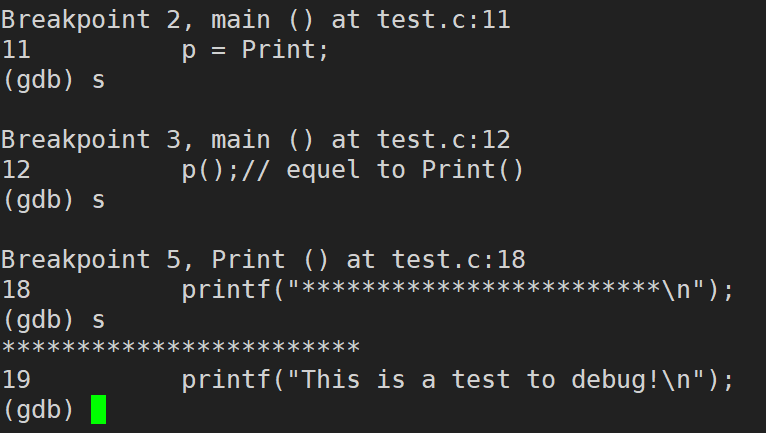
step / s (step可以简写成s):逐过程调试,遇到函数调用,进入函数调用中(相当于Windows下VS中的 F11 或者 Fn + F11,逐过程调试)
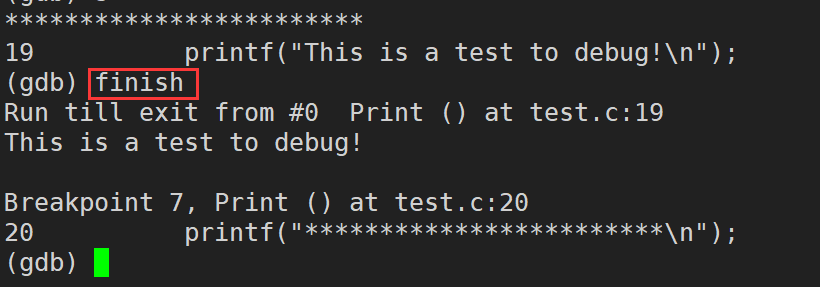
finish:执行到当前函数返回,然后等待命令。finish只在函数调用内部执行,在main函数中不会执行
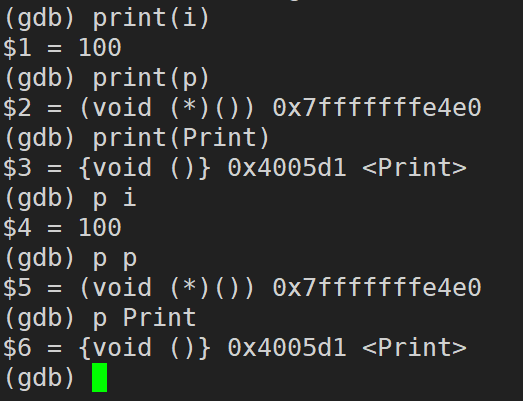
print / p (变量/表达式) (print 可以简写成 p):打印变量/表达式的值,通过表达式可以修改变量的值或者调用函数
print / p 变量 / 表达式(print 可以简写成 p):打印变量/表达式的值,通过表达式可以修改变量的值或者调用函数
set var 表达式:修改(设置)变量的值

continue / c(continue可以简写成 c):从当前位置开始连续而非单步执行程序(遇到断点才停下)

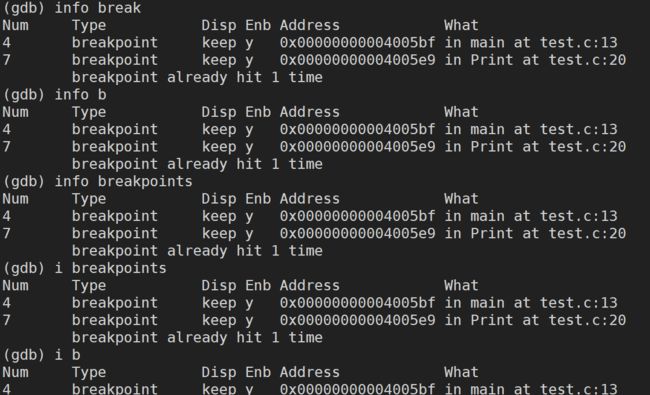
info / i (info可以简写成 i)breakpoint / break / b:查看断点信息
//以下几条指令是等价的
info breakpoints
info break
info b
i breakpoints
i break
i b
display 变量名:跟踪查看一个变量,每次停下来都显示它的值
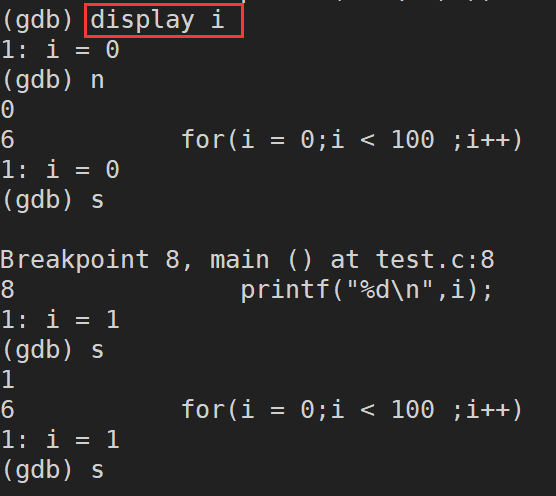
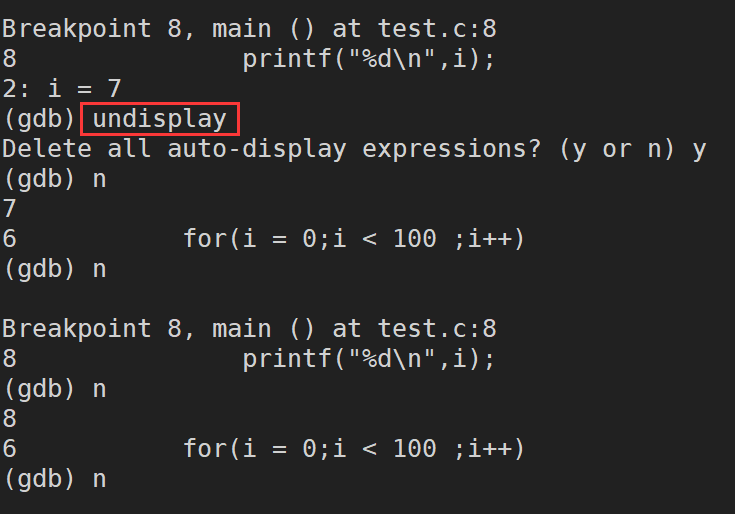
undisplay:取消先前设置的跟踪查看一个变量
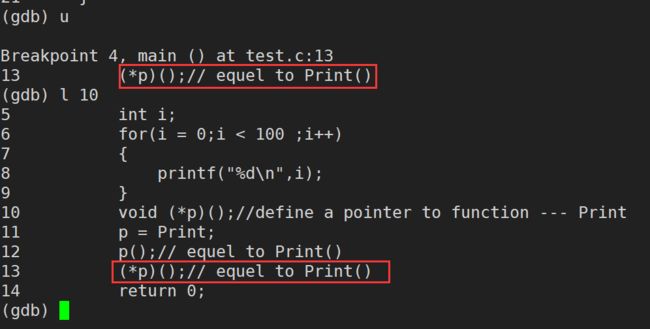
until n(行)(until 可以简写成 u):跳到第n行
不带参数的 until 命令,可以使 GDB 调试器快速运行完当前的循环体,并运行至循环体外停止。注意,until 命令并非任何情况下都会发挥这个作用,只有当执行至循环体尾部(最后一行代码)时,until 命令才会发生此作用;反之,until 命令和 next 命令的功能一样,只是单步执行程序。
(gdb) until/u
(gdb) until/u location
bt:查看各级函数调用及参数。(注意:bt是breaktrace的简称,但是直接使用breaktrace却无法识别,问了度娘暂时没弄懂咋回事~)


info / i locals(info可以简写成i):查看当前栈帧局部变量的值
//使用方式
info locals//
i locals//两种方式均可
quit:退出gdb,也可按快捷键ctrl + d,实际上会转换为quit
深入理解
可以和Windows下面的VS或者其它IDE(集成开发环境)做对比,进行记忆和学习
Linux项目自动化构建工具-make/Makefile
背景
1)会不会写makefile,从一个侧面说明了一个人是否具备完成大型工程的能力
2)一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的规则来指定哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译。甚至于进行更复杂的功能操作
3)makefile带来的好处就是――“自动化编译”,一旦写好,只需要一个make命令,整个工程完全自动编译,极大的提高了软件开发的效率
4)make是一个命令工具,是一个解释makefile中指令的命令工具,一般来说,大多数的IDE都有这个命令。比如: Delphi的make,Visual C++的nmake,Linux下GNU的make。可见,makefile都成为了一种在工程方面的编译方法。
5)make是一条命令,makefile是一个文件,两个搭配使用,完成项目自动化构建
深入理解
makefile中用于存放目标文件和源文件之间依赖关系,以及具体的依赖方法。
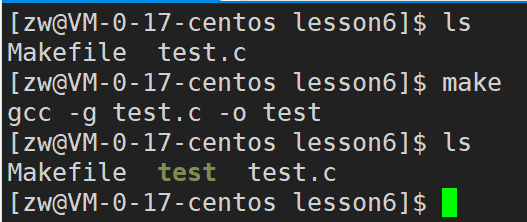
比方说我们用gcc将test.c文件生成为test文件。那么test.c就是源文件,test就是我们要生成的目标文件。
gcc test.c -o test
目标文件test要想生成要依赖于有源文件test.c,如果test.c不存在,那么将无法生成目标文件test。这就是目标文件对源文件的一个依赖关系(简单来说:先有你才能有我)
此外,光有依赖关系还是不够的,还必须指出具体的依赖方法是什么,这里的依赖方法就是:
gcc test.c -o test //这条语句本身就是依赖方法,通过gcc编译test.c 再 -o 生成test文件

实例代码
【test.c文件】
#include【Makefile文件】
touch Makefile // 先创建Makefile文件,也可以命名为makefile
vim Makefile //进入Makefile文件中进行编辑
test:test.c//表示test目标文件依赖于test.c源文件
gcc -g test.c -o test//依赖方法是这个,实际上就是目标文件test的生成方式,行首tab键开头
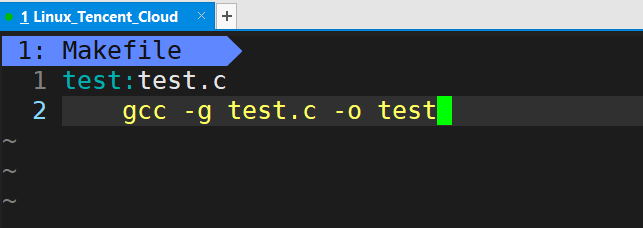
注意:在Makefile中依赖方法语句中,行首必须要用tab键来进行缩进,不能用四个空格来代替,虽然两者看起来的文本效果是一样的,但是本质上是不同的,tab会被保存为’\t’。个人猜测:在为依赖关系确定依赖方法时,会去找依赖关系后面的’\t’,找到了,后面的一条语句就是依赖方法。
如果我们需要删除test文件,那么可以在Makefile当中再添加一条语句
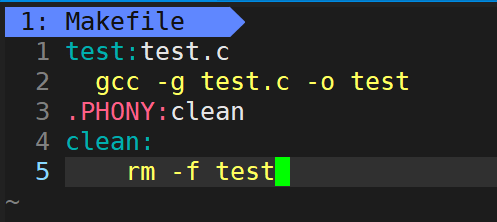
.PHONY:clean //Phony:伪造的,这里用.PHoNY:clean定义了一个伪目标clean
clean:
rm -f test //注意以tab键开头
注意:
目标文件:之前根据 test.c 生成的 test 文件是一个目标文件,是一个真正的文件,对于目标文件,如果当前目录下已经生成且为最新时,再次执行将不会做任何事情(会提示我们该文件已经是最新的)。
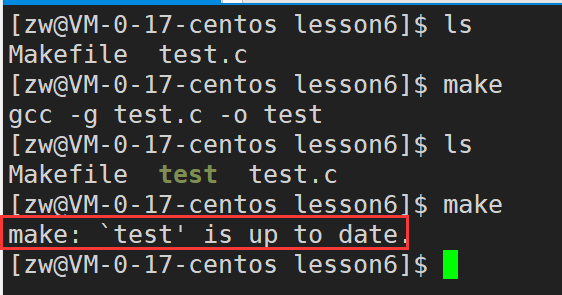
伪目标:所谓伪目标就是它不代表一个真正的文件名,在执行make时,可以只当这个目标是用来执行所定义规则的一条命令,有时候我们也会将一个伪目标称为一个标签。对于伪目标,总是可以执行的,不会去考虑是不是最新
伪目标文件定义方法:
.PHONY: 目标名1 目标名2 ...
目标名1:
定义规则1
目标名2:
定义规则2
......
//当使用定义过后的目标名,无论当前文件夹下是否存在同名的文件都会执行该目标下的所有命令
伪目标文件执行方式
make 伪目标名/伪标签//用make加上伪目标名,表示执行该伪目标所对应的规则
如果我们想要用make来依次进行预处理、编译、汇编、链接,生成对应的目标文件,那么Makefile中可改写成
test:test.o//表示test文件依赖于test.s文件,要想生成test文件,必须先有test.o文件
gcc test.o -o test
test.o:test.s//表示test.o文件依赖于test.s文件,要想生成test.o文件,必须先有test.s文件
gcc -c test.s -o test.c
test.s:test.i//表示test.s文件依赖于test.i文件,要想生成test.s文件,必须先有test.i文件
gcc -S test.i -o test.s
test.i:test.c//表示test.i文件依赖于test.c文件,要想生成test.i文件,必须先有test.c文件
gcc -E test.c -O test.i
.PHONY:clean
clean:
rm -f test.i test.s test.o test //删除编译过程生成的所有文件
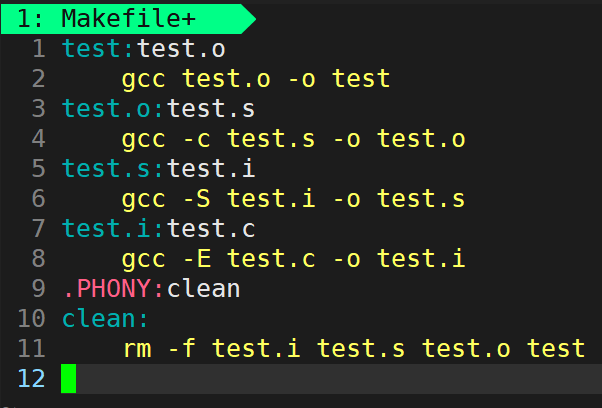
执行 make 和 make clean :
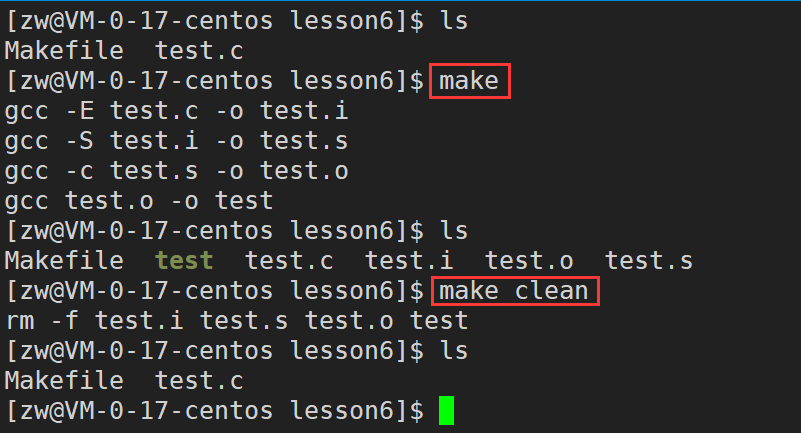
依赖关系
1)test文件依赖于test.o文件
2)test.o文件依赖于test.s文件
3)test.s文件依赖于test.i文件
4)test.i文件依赖于test.c文件
依赖方法
gcc test.* -option test.* //这个就是与之对应的依赖方法
原理
make是如何工作的,在默认的方式下,也就是我们只输入make命令。那么,
1)make会在当前目录下找名字叫"Makefile"或"makefile"的文件。
2)如果找到,它会找文件中的第一个目标文件(target),在上面的例子中,他会找到"test"这个文件,并把这个文件作为最终的目标文件。(make 默认生成第一条命令)
3)如果test文件不存在,或是test所依赖的后面的test.o文件的文件修改时间要比test这个文件新(可以用touch 测试),那么,他就会执行后面所定义的命令来生成test这个文件。(make会生成最新的目标文件,若最新目标文件已经存在,则不执行)
4)如果test所依赖的test.o文件不存在,那么make会在当前文件中找目标为test.o文件的依赖性,如果找到则再根据那一个规则生成test.o文件。(这有点像一个堆栈或递归的过程)
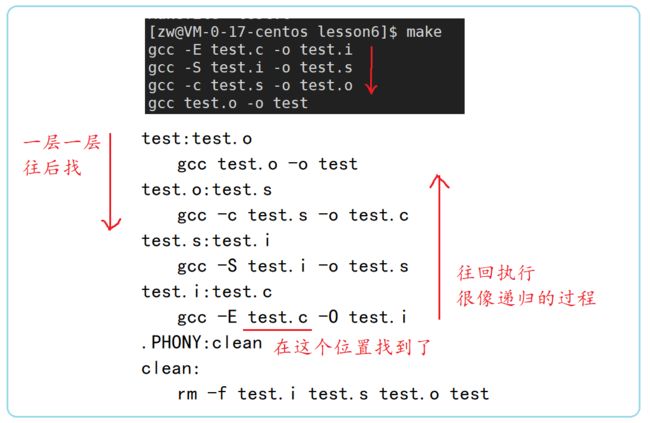
5)当然,我们的.c源文件(和.h头文件)是存在的,于是make会生成test.o文件,然后再用test.o文件声明make的终极任务,也就是执行文件test了。
6)这就是整个make的依赖性,make会一层又一层地去找文件的依赖关系,直到最终编译出第一个目标文件。
7)在找寻的过程中,如果出现错误,比如最后被依赖的文件找不到,那么make就会直接退出,并报错,而对于所定义的命令的错误,或是编译不成功,make根本不理。
8)make只管文件的依赖性,即,如果在找了依赖关系之后,冒号后面的文件还是不在,那么对不起,它就不会继续工作。
项目清理
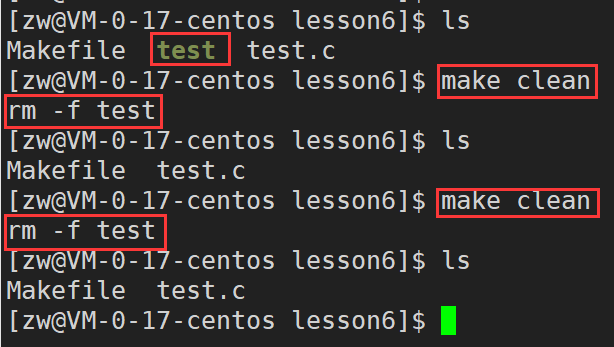
1)工程是需要被清理的
2)像clean这种,没有被第一个目标文件直接或间接关联,那么它后面所定义的命令将不会被自动执行,不过,我们可以显示要make执行。即命令—一"make clean”,以此来清除所有的目标文件,以便重新编译
3)但是一般我们这种clean的目标文件,我们将它设置为伪目标,用 【.PHONY】修饰,伪目标的特性是,总是可以被执行(伪目标不会生成文件,所以不会存在已有文件与其产生冲突)
Linux第一个小程序 进度条
前提准备
看一下enter键上面的方向箭头是什么?(向下的同时向左,这意味着什么呢?)

\r和\n
回车(\r):回到本行开始的位置
换行:保存当前位置不变,向下移动一行,不回到新行开始的位置
回车并换行(\n):向下移动一行,并从该行起始位置开始

行缓冲区的概念
#include//Windows下的头文件
int main()
{
printf("Hello Linux,Hello Makeflie\n");
//Sleep(3000);//Windows下的Sleep函数,首字母大写,单位是毫秒,1000ms = 1s
sleep(3);//Linux下的sleep函数,首字母小写,单位是秒
return 0;
}
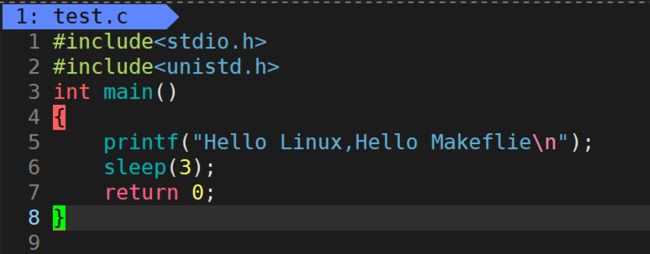
现象描述:会先打印 Hello Linux,Hello Makeflie,然后等待3s
【动图演示】

如果我们将 printf 后面的\n去掉会发生什么现象?
#include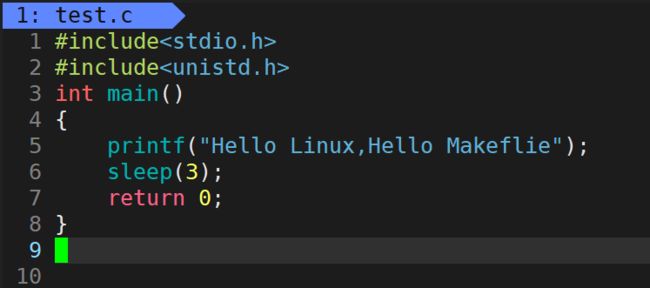
现象描述:会先等待3s,然后打印 Hello Linux,Hello Makeflie
【动图演示】

缓冲区:本质上就是一段内存空间,暂存临时数据,在合适的时候刷新出去
【刷新策略】
1)直接刷新,不缓冲
2)缓冲区写满,再刷新,全缓冲
3)碰到\n就刷新,行刷新
4)强制刷新,把数据直接写入磁盘、文件、显示器、网络等设备或者文件
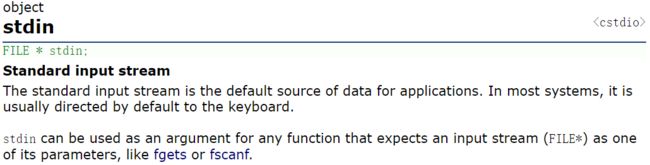
任何一个C程序,启动的时候,会默认打开三个输入输出流(文件)
stdin:键盘
stdout:显示器
stderr:显示器
现象分析:
为什么将\n去掉后,printf会后打印内容呢?
很明显,这里采用的刷新策略是:3)碰到\n就刷新,行刷新
1)printf执行完了,只是代表字符串被读入缓存区了,并不一定会显示出来,只有当缓存区的内容被显示器读取出来后才会在屏幕中显示出来
2)如果在字符串后面加\n表示回车并换行,这时候,print将字符串送到缓冲区,缓冲区会将内容立刻送到显示器
3)如果在字符串后面没有\n,那么printf会先将字符串送入缓冲区,缓冲区不会立刻将内容送到显示器
如果我们想要强制刷新,该怎么办呢?

#include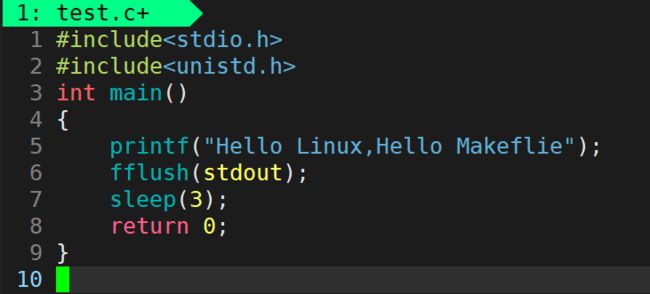
【动图演示】

倒计时程序
实际上我们在屏幕上看到的内容,都是以字符的形式展示的,比方说:将int类型数 10 用printf 以%d打印出来,屏幕上显示的是10,但是这个10是字符(不再是数字了)。printf格式化输出会将整数10转换成字符10(字符1和字符0),然后送到屏幕显示出来。
#include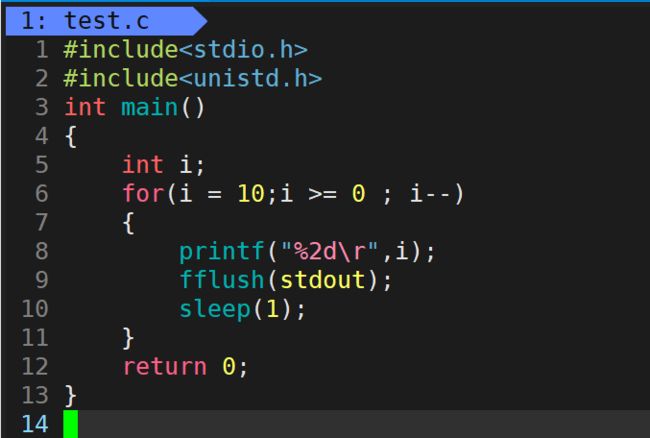
【动图演示】

进度条
预期效果
我们在Linux下安装软件的时候,经常可以看到某一个软件包安装的进度条,用来告诉我们已经安装了多少,或者还有多少没有安装。
//printf字体、背景颜色修改,只适用于Linux,Windows下无效
#include【动图演示】
在给printf打印的字符串添加purple色号(粉红色)后,进行打印,显示效果如下

如果不喜欢粉红色,我们也可以修改成黄颜色。

当然,我们还可以加上字体的背景,但是我感觉这里加上背景可能还没不加好看。

关于printf输出有颜色的字体和背景可以参考下面的代码
//printf字体、背景颜色修改,只适用于Linux,Windows下无效
#include【动图演示】

【截图效果】方便查看

Linux代码托管/开源项目
使用git命令行
安装git
如果Linux机器上没有安装git,可以使用下面方法进行安装(不知道有没有安装的可以直接执行这条命令)
sudo yum install git

在Github上创建项目
考虑到在国内访问Github网络速度会比较慢,可以用Gitee(码云)来代替。Gitee是国内的开源平台,功能和Github类似,但是在国内使用速度会比较快一些。
注册Github账号
https://github.com
这个比较简单,参考官网提示一步步执行就行,最后进行邮箱验证,注册完成。
创建项目
登录Github,创建一个新的代码仓库。
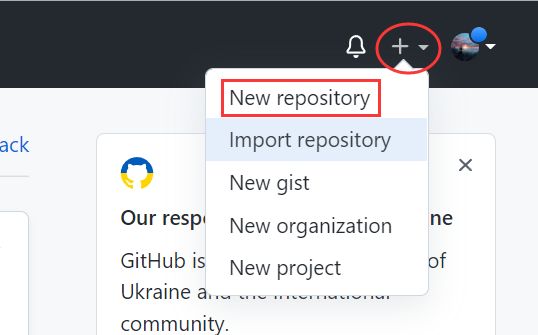
创建完成后,在创建好的项目页面中复制项目的链接,方面后续我们在Linux中将其clone(克隆)下来。
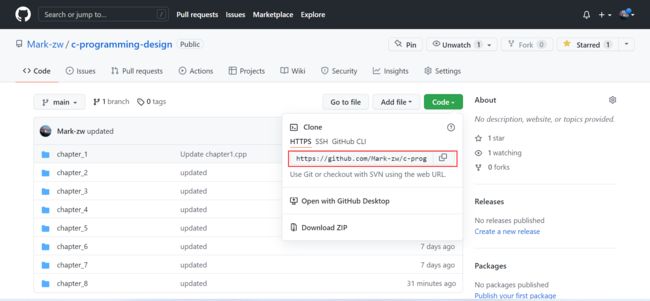
下载项目到本地
先创建好一个放置代码的目录,然后将GitHub的代码仓库克隆到这个目录中。
git clone url //clone 后面加刚刚复制的链接,
Git操作—三板斧
1)git add:将代码放到刚下载好的目录中,将需要用git管理的文件告诉git
git add filename
2)git commit:将代码提交到本地
git commit . // . 表示当前目录,提交的时候要注明提交日志、信息,方便以后回溯
3)git push:将已经提交到本地的代码同步到远程服务器上(这个就是我们GitHub上面小绿点的来源)
git push
需要填写用户名密码,同步成功后,刷新GitHub页面就能看到代码的提交情况了。
配置免密码提交
git本地免密码和账号pull、push_CamilleZJ的博客-CSDN博客
git remote set-url origin https://
*
**:是你自己github的用户名
**:是你的仓库名称**
例如:(下面的token是根据我自己的token改造的,嘻嘻,能看懂就行),可以直接替换上面哪三个地方。
git remote set-url origin https://[email protected]/Mark-zw/c-programming-design
如果不小心遇到下面这样的问题,莫慌,很好解决
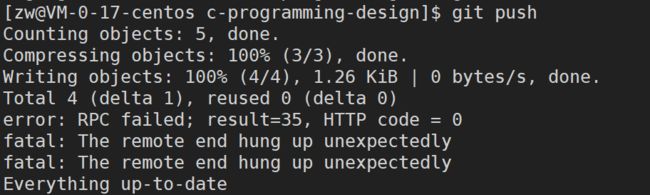
error: RPC failed; result=35, HTTP code = 0
原因:The problem is most likely because your git buffer is too low.
解决:You will need to increase Git’s HTTP buffer by setting.
通过 Git 命令将 http.postBuffer 值提高到 50M(这个根据项目设定,不知道就往高了设)
git config --global http.postBuffer 50M
思维导图总结