【哈工大李治军】操作系统课程笔记6:CPU调度策略 + 【实验 4】进程运行轨迹的跟踪与统计实验
1、操作系统的那颗“树”
上图为Linux核心源码所形成的一个结构。
(1)最初的种子

我们的目标是让机器可以执行我们的指令,从而完成计算,这里涉及到两个关键的步骤:取值、执行
(2)I/O处理带来的等待
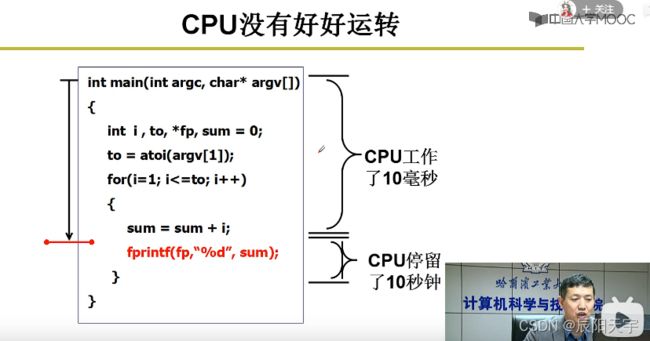
在使用CPU执行指令的过程中,我们发现只写这段程序时,会让CPU先执行10ms,然后I/O处理却等待了10s,导致CPU有大部分时间处于空闲状态没有被利用起来。
因此,我们就设想能否进行改善,在执行I/O设备处理时,让CPU先去执行其他任务,而被利用起来。
(3)让CPU可以切换执行

我们就想出了一种方式,在执行到I/O处理时,让CPU可以切换到另一个程序进行执行。当I/O处理完后,再让CPU回来去执行程序1里下面的指令。
这里我们就会想,如何切换呢?

这是一个多程序跳转,而栈中的地址会记录程序的入口地址、返回参数地址,因此我们就用栈来实现多程序切换。
当我们使用栈来实现多程序跳转时,发现没有顺利的切换回来,而是又切换了回来。
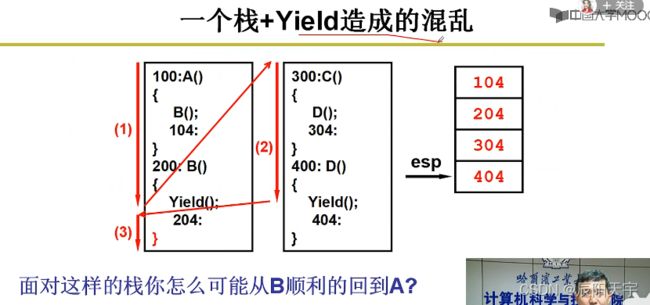
通过分析,我们发现在两个程序使用一个栈时,会造成记录上的混乱。因此,我们使用两个栈来分别记录两个程序在中执行中记录的返回地址。
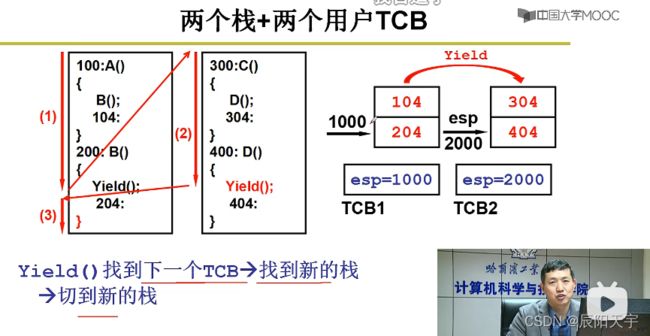
我们再设置TCB来记录每个线程的信息,当要使用yield()切换时,就会根据TCB里的信息来找到新栈,从而切换到新的栈里。

但上述的方式只能用在用户态,当我们从用户态切换到内核态时,发现内核态下,同一个进程内的线程无法进行切换。因此,我们就需要一种方式来帮助我们实现正常的内核态切换。
我们会思考,既然在用户态的时候有用户栈来实现切换,那么到了内核的时候,是否可以使用内核栈来实现切换呢?

我们就想到一种方式:
(1)由用户栈切换到内核栈(int 0x80)。因为执行的线程不变,只是需要在内核态下运行,因此还使用该线程的TCB,而为了还可以正确的返回到用户态,就用内核栈记录用户栈的es、ss、cs、ip。
(2)当内核栈之间想要切换时,使用TCB、schedule和switch_to来实现。首先,使用schedule来选取要换上哪个线程,然后将切换前的线程信息保存在自己的TCB当中,再用switch_to将选取到的线程的TCB信息覆盖到CPU中,让esp指向该线程的栈,从而完成切换。
(3)由内核栈切换到用户栈(iret)。根据内核栈的信息,切换到用户栈。
精简来说就是,用户栈到内核栈,内核栈到TCB,TCB之间切换,再内核栈之间切换,最后内核栈返回到用户栈。
2、CPU调度策略



让进程满意:周转时间(从任务进入到结束)、响应时间(从操作发生到响应)和吞吐量(完成的任务量)。
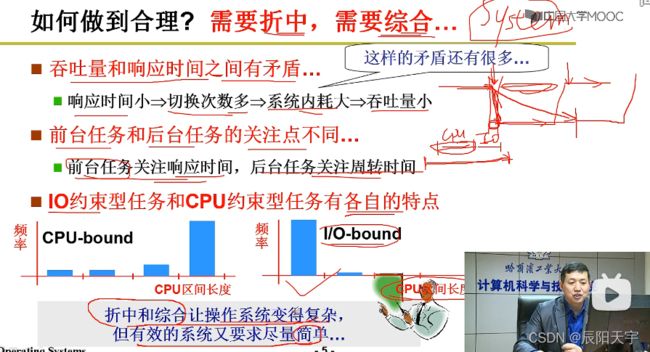
操作系统设计时候的原则是既要折中,又要综合。前台任务更关注响应时间,后台任务更关注周转时间。
而吞吐量和响应时间之间是由矛盾的。比如,想要让响应时间段,则就需要切换次数多,从而会导致系统内增大,吞吐量减小。
一般会设置I/O约束型任务的优先级要高于CPU约束性任务,因为先执行I/O操作后,可以让CPU去执行任务,让CPU不会空闲。如果先执行CPU而再执行I/O任务的话,当把CPU任务执行完后,再执行I/O任务,此时CPU会处于空闲状态,CPU利用率不高。
(1)各种CPU调度算法
1)先来先服务FCFS

在先来先服务方法中,这里如果让短作业的作业先进来先执行,则很多任务就可以提前结束,而很多任务提前结束了,则这些短作业的周转时间就会很小,短作业就会比较满意。短的作业比较满意了,就可以整体系统的满意度,整体系统的满意度(一堆作业满意度的加和)提高了,就可以让平均周转时间更小。短作业越先执行,平均周转时间越小。
2)短作业优先SJF:满足周转时间
所以,就有了短作业优先SJF方法,将短作业提前。
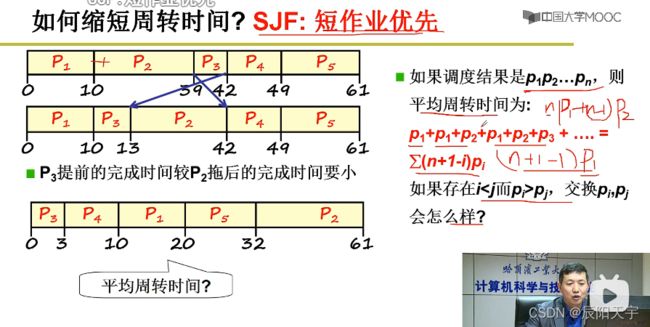
按作业执行时间排序,得到调度顺序为 P 1 P 2 . . . P n P_1 P_2 ... P_n P1P2...Pn。平均周转时间为 ∑ ( n + 1 − i ) P i \sum(n+1-i)P_i ∑(n+1−i)Pi,其中 P 1 P_1 P1 被计算了n次, P 2 P_2 P2 被计算了n-1次。
这种方式平均周转时间最小,但对于长作业的响应时间会太长。
3)轮转调度RR:满足响应时间

所以,为了来均衡作业的响应时间,我们引入时间片机制——轮转调度(Round Robin),来轮转调度,让每个任务都可以被照顾到。
时间片:P1分配10个,P2分配10,P3分配13个,P4分配7个…以此方式可以保证响应时间。但时间片越大,响应时间就会越长;时间片越小,吞吐量就会小。
4)优先级调度
在实际中,我们对于不同的任务,关注点不一样。对于前台任务,我们更关注它的响应时间;对于后台任务,我们更专注它的周转时间。
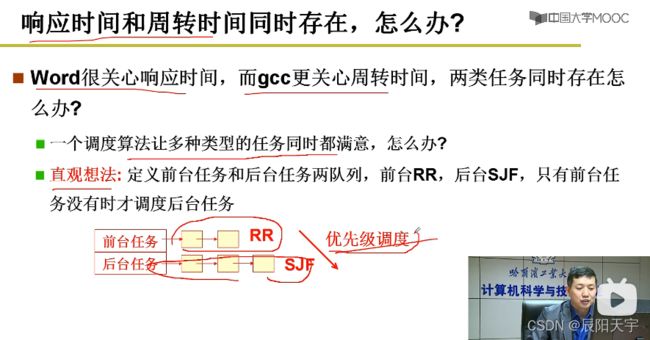
所以,我们采用对于不同种类的任务设定不同的优先标准,采用优先级调度方式对不同任务的队列进行调度。
但如果单纯的执行短作业优先作为优先级调度策略,可能会出现有作业饥饿的现象,较长执行时间的作业一直很难被执行。

我们就想,让后台任务优先级可以动态调整,让长作业可以被执行到。但后台任务占用CPU时间较长任务的优先级如果提升的话,前台的响应时间就又会受到到影响。
为了保证响应时间,所有的任务都需要有时间片,但如果前后台任务都是用时间片的话,又会退化到RR,没有短作业优先级的体现,后台任务就无法提升平均周转时间。

所以,我们就需要这个调度算法有学习机制,能够根据任务的情况来自行的调整,从而达到操作系统对整个任务的折中综合。
(2)schedule()函数

在Linux0.11中将PCB设置成了一个数组task[n],将p设置为最后一个进程的地址。while()循环从数组末尾往前开始找就绪进程且counter时间片大于c,则让c等于所选取进程的时间片、next等于这个进程位于PCB数组中的位置。最后,得到 counter最大的就绪进程 。
如果c不等于0,意味着找到了就绪进程,则跳出执行switch_to()完成调度。
如果c等于0,则说明没有可用的还有时间片的就绪进程,就让所有就绪态进程的counter=0/2 + priority恢复到counter的初值。而对于阻塞态进程,例如I/O进程,counter=counter/2 + priority,这样会导致I/O进程的时间片数值会增大,优先级会增大。
此时,counter就有两个作用。一个是时间片,一个是优先级。

时钟中断的作用是每次都让counter减1,如果减到等于0的话,就进行schedule()调度。每次产生时钟中断时都会修改counter。

在schedul()中是根据counter的大小来选取,所以counter此时也就表示为优先级,找到最大的counter。同时,也会对counter进行动态调整,阻塞态进程(I/O)的优先级就在调整中会被升高,I/O时间越长,则在阻塞队列中的时间就越长,则经历的counter = counter/2 + priority就可能越多,优先级被升高的可能性就越大。(这就是学习机制)
而I/O进程正是前台进程的特征,你I/O时间的越长,就可认为此进程具有前台进程的特征,当具有前台进程的特征越高,进程的优先级就会越高(满足相应时间的要求)。

时间片轮转的目标是为了满足响应时间。但引入学习机制后,随着带counter的不断变化又是否能保证响应时间有界吗?
依然有界,下面来研究counter最大的情况下,此时的状况是初始状态时就被阻塞且随后一直被阻塞,则 c ( 0 ) = p c(0) = p c(0)=p, c ( t ) = c ( t − 1 ) 2 + p c(t) = \frac{c(t-1)}{2} + p c(t)=2c(t−1)+p,可得 c ( t ) = ∑ i = 1 n p i ≤ 2 p c(t) = \sum_{i=1}^n p_i ≤ 2p c(t)=∑i=1npi≤2p。如果每个进程最多的时间片是2p,那么n个进程最多的周转时间便是2np。这也就是在更新counter时,除以一个常数的原因,之所以选择2是因为可以通过右移操作,实现起来更加快捷。
经过I/O以后,counter就会变大;I/O时间越长,counter越大,照顾了I/O进程,变相的照顾了前台进程。而后台进程已知按照counter轮转,近似了SJF调度(不断轮转一圈一圈的执行,短作业的进程一定最先执行完!)并且也不尽可能的避免了出现作业饥饿现象。最终实现每个进程只用维护一个counter变量,简单、高效。
所以,我们在未来写操作系统时,要考虑到折中。既要满足多个任务的特点,又要保证简单、高效。
[实验 4]:进程运行轨迹的跟踪与统计实验
实验的第一部分是多进程创建,第二部分是调度跟踪。分别和笔记4与笔记6相关,便都放在了笔记4当中:
【哈工大李治军】操作系统课程笔记4:CPU和多进程 + 【实验】进程运行轨迹的跟踪与统计实验