干货|只需5步,手把手教你识别客户购买意愿(附代码数据)
工作中是否经常遇到这样的场景:业务部门希望通过营销活动来提高产品的销量,但是预算是有限的。在预算允许范围内,如何更多的提升转化率是每个从事数据分析、数据挖掘人员需要面临的问题。
本篇将以银行营销活动相关数据为例,手把手教大家如何识别客户是否有意愿购买该银行的产品,针对高意愿客户进行精准营销来提升转化率。废话不多说,下面开始详细介绍我们的解决方案。
原文链接如下:
干货|只需5步,手把手教你识别客户购买意愿(附代码数据)
数据说明
数据中包含客户基本信息、活动行为信息。在实际场景中,如果有客户的偏好信息,参与活动历史信息等,也可以加入其中。
数据预处理
1、数据查看
我们可以看到数据共计 25317 行,空数据暂无,详情如下:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
train=pd.read_csv('train_set.csv')
test=pd.read_csv('test_set.csv')
train.info()
2、数据预处理
对源数据进行观察,可以发现分类字段有’unknown’这个类别,此时将该类别也当作缺失值,进一步查看
# 对object型数据查看unique
str_features = []
num_features=[]
for col in train.columns:
if train[col].dtype=='object':
str_features.append(col)
print(col,': ',train[col].unique())
if train[col].dtype=='int64' and col not in ['ID','y']:
num_features.append(col)
train.isin(['unknown']).mean()*100
通常对于缺失值的处理,最常用的方法无外乎删除法、替换法和插补法。
- 删除法是指将缺失值所在的观测行删除(前提是缺失行的比例非常低,如 5%以内),或者删除缺失值所对应的变量(前提是该变量中包含的缺失值比例非常高,如 70%左右)
- 替换法是指直接利用缺失变量的均值、中位数或众数替换该变量中的缺失值,其好处是缺失值的处理速度快,弊端是易产生有偏估计,导致缺失值替换的准确性下降
- 插补法则是利用有监督的机器学习方法(如回归模型、树模型、网络模型等)对缺失值作预测,其优势在于预测的准确性高,缺点是需要大量的计算,导致缺失值的处理速度大打折扣
这里观察到 contact 和 poutcome 的’unknow’类别分别达到 28.76%和 81.67%,在展示数据后考虑进一步处理,job 和 education 的 unknown 占比较小,考虑不对这两个特征的 unknow 进行处理。
数据分析
下面我们对源数据进行数据分析,数据字段分为离散变量和连续变量,下面我们将逐一进行分析。
1、离散变量
plt.figure(figsize=(15,15))
i=1
for col in str_features:
plt.subplot(3,3,i)
# 这里用mean是因为标签是0,1二分类,0*0的行数(即没购买的人数)+1*1的行数(购买的人数)/所有行数=购买率
train.groupby([col])['y'].mean().plot(kind='bar',stacked=True,rot=90,title='Purchase rate of {}'.format(col))
plt.subplots_adjust(wspace=0.2,hspace=0.7) # 调整子图间距
i=i+1
plt.show()
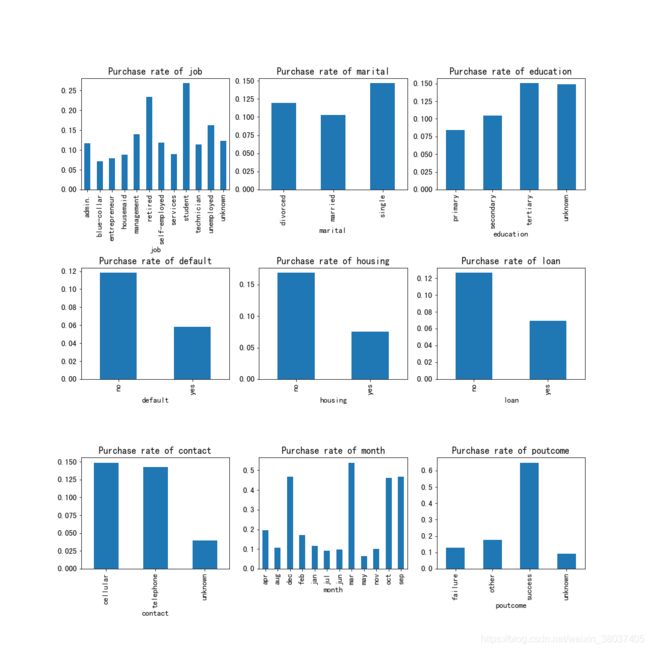
通过可视图我们可以对每个特征情况进行初步观察,方便分析这些特征是否会影响购买率。
2、连续变量
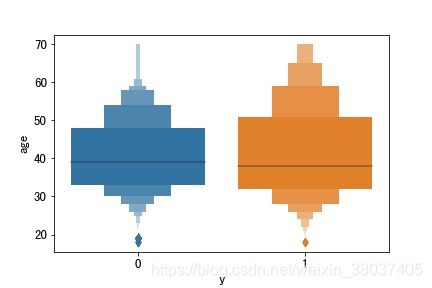
1、age 年龄
plt.figure()
sns.boxenplot(x='y', y=u'age', data=train)
plt.show()
train[train['y']==0]['age'].plot(kind='kde',label='0')
train[train['y']==1]['age'].plot(kind='kde',label='1')
plt.legend()
plt.show()
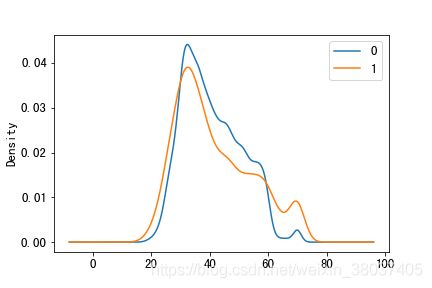
从上图我们可以看出两类客户的购买年龄分布差异不大;
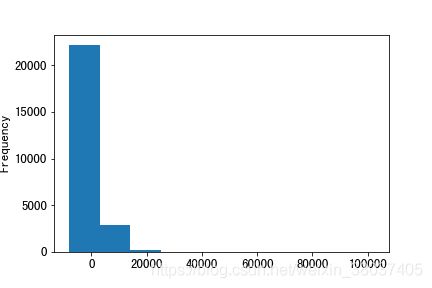
2、balance 每年账户的平均余额
train['balance'].plot(kind='hist')
plt.show()
3、duration 最后一次联系的交流时长
plt.figure()
sns.boxplot(y=u'duration', data=train)
plt.show()

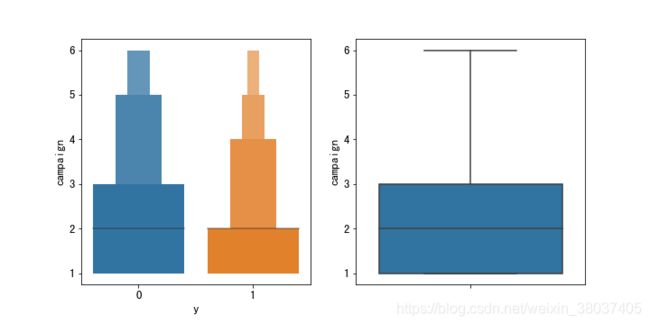
4、campaign 在本次活动中,与该客户交流过的次数
plt.figure(figsize=(10,5))
plt.subplot(1,2,1)
sns.boxenplot(x='y', y=u'campaign', data=train)
plt.subplot(1,2,2)
sns.boxplot(y=u'campaign', data=train)
plt.show()
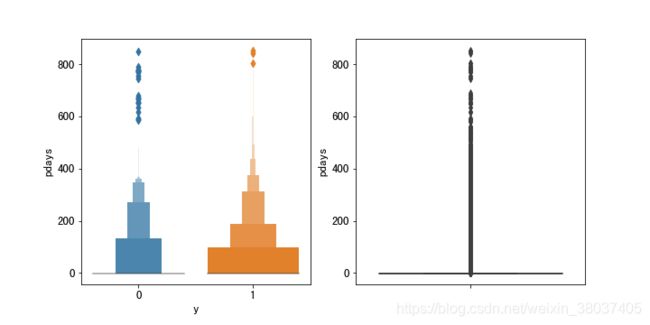
5、pdays 距离上次活动最后一次联系该客户,过去了多久(999表示没有联系过)
plt.figure(figsize=(10,5))
plt.subplot(1,2,1)
sns.boxenplot(x='y', y=u'pdays', data=train)
plt.subplot(1,2,2)
sns.boxplot(y=u'pdays', data=train)
plt.show()
6、previous 在本次活动之前,与该客户交流过的次数
plt.figure(figsize=(10,5))
plt.subplot(1,2,1)
sns.boxenplot(x='y', y=u'previous', data=train)
plt.subplot(1,2,2)
sns.boxplot(y=u'previous', data=train)
plt.show()

特征工程
通过上述对每个特征进行数据分析,我们对数据有了大致了解,下面我们从数据平衡性、数据标准化等角度进行特征工程处理。
1、从训练集查看是否平衡数据集
plt.rc('font', family='SimHei', size=13)
fig = plt.figure()
plt.pie(train['y'].value_counts(),labels=train['y'].value_counts().index,autopct='%1.2f%%',counterclock = False)
plt.title('购买率')
plt.show()

我们可以看到是9:1,数据集是不平衡数据集
2、连续变量即数值化数据做标准化处理
def outlier_processing(dfx):
df = dfx.copy()
q1 = df.quantile(q=0.25)
q3 = df.quantile(q=0.75)
iqr = q3 - q1
Umin = q1 - 1.5*iqr
Umax = q3 + 1.5*iqr
df[df>Umax] = df[df<=Umax].max()
df[df=Umin].min()
return df
train['age']=outlier_processing(train['age'])
train['day']=outlier_processing(train['day'])
train['duration']=outlier_processing(train['duration'])
train['campaign']=outlier_processing(train['campaign'])
test['age']=outlier_processing(test['age'])
test['day']=outlier_processing(test['day'])
test['duration']=outlier_processing(test['duration'])
test['campaign']=outlier_processing(test['campaign'])
3、分类变量做编码处理
dummy_train=train.join(pd.get_dummies(train[str_features])).drop(str_features,axis=1).drop(['ID','y'],axis=1)
dummy_test=test.join(pd.get_dummies(test[str_features])).drop(str_features,axis=1).drop(['ID'],axis=1)
4、不平衡数据集处理
X=dummy_train
y=train['y']
X_train,X_valid,y_train,y_valid=train_test_split(X,y,test_size=0.2,random_state=2020)
smote_tomek = SMOTETomek(random_state=2020) #SMOTETomek
X_resampled, y_resampled = smote_tomek.fit_sample(X_train, y_train)
数据建模
为了方便讲解,本篇使用逻辑回归进行数据分析建模,在实际工作场景中,我们可以使用随机森林、lgb、xgboost、DNN等模型都是可以的,根据具体场景和建模效果进行选择。
#逻辑回归
param = {"penalty": ["l1", "l2", ], "C": [0.1, 1, 10], "solver": ["liblinear","saga"]}
gs = GridSearchCV(estimator=LogisticRegression(), param_grid=param, cv=2, scoring="roc_auc",verbose=10)
gs.fit(X_resampled,y_resampled)
print(gs.best_params_)
y_pred = gs.best_estimator_.predict(X_valid)
print(classification_report(y_valid, y_pred))
# 训练集
confusion_matrix(y_resampled,gs.best_estimator_.predict(X_resampled),labels=[1,0])
# 验证集
confusion_matrix(y_valid,y_pred,labels=[1,0])
#画roc-auc曲线
def get_rocauc(X,y,clf):
from sklearn.metrics import roc_curve
FPR,recall,thresholds=roc_curve(y,clf.predict_proba(X)[:,1],pos_label=1)
area=roc_auc_score(y,clf.predict_proba(X)[:,1])
maxindex=(recall-FPR).tolist().index(max(recall-FPR))
threshold=thresholds[maxindex]
plt.figure()
plt.plot(FPR,recall,color='red',label='ROC curve (area = %0.2f)'%area)
plt.plot([0,1],[0,1],color='black',linestyle='--')
plt.scatter(FPR[maxindex],recall[maxindex],c='black',s=30)
plt.xlim([-0.05,1.05])
plt.ylim([-0.05,1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('Recall')
plt.title('Receiver operating characteristic example')
plt.legend(loc='lower right')
plt.show()
return threshold
threshold=get_rocauc(X_resampled, y_resampled,gs.best_estimator_)
roc-auc曲线

上面我们进行了数据训练、数据预测、模型性能评估等操作。
推荐阅读
-
Python绘图库,能做到极致简洁也只有这款了
-
8个好用到爆炸的Jupyter Notebook小技巧!
-
太香了!强烈安利14个Python奇技淫巧
-
一文详解八大数据分析方法,数据分析必备!
-
Python数分实战|从六个视角分析了58万条电商用户行为数据
技术交流
欢迎转载、收藏本文,码字不易,有所收获点赞支持一下!
为方便进行学习交流,本号开通了技术交流群,添加方式如下:
直接添加小助手微信号:pythoner666,备注:CSDN+python/数据分析,或者按照如下方式添加均可!
