机器学习必备算法之(二)支持向量机(SVM)及Python实现
什么是支持向量机
从定义上来说是在特征空间上的间隔最大化的线性分类器。…(好像很复杂的样子)…简单的来说,特征空间内,有一些数据点,我们想用一个超平面把他们分成两半,且正类和反类到这个超平面的距离要最大,这种分类模型就是支持向量机。比如,二维空间中,我找一条直线把数据点们划分为两部分,如图,B是但AC都不是。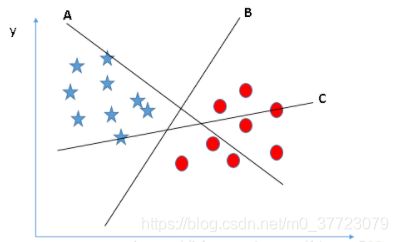
那什么是超平面呢?数学意义上是 w T x + b = 0 , x ∈ R n w^Tx+b=0,x\in R^n wTx+b=0,x∈Rn,对于一条线来说,一个点是超平面;对于二维平面来说,一条线就是超平面;对于三位空间来说,一个平面就是超平面(一个大西瓜,一个刀面切两半~)…n维空间来说的超平面是n-1维的。
支持向量机分类
那么接下来我们来聊一聊具体的模型,基本思想:写出优化模型 → \to →用拉格朗日乘子法求出对偶问题 → \to →聊一聊KKT条件。(求对偶问题及KKT条件不太会的同学可以查一查袁亚湘院士的最优化理论与方法那本书或者直接搜索一下,想深入学数学优化的可以看看王宜举和修乃华老师编的非线性最优化理论与方法那本黄皮书哦~)
我们的分类决策是 f ( x ) = s g n ( w T x + b ) f(x)=sgn(w^Tx+b) f(x)=sgn(wTx+b)
线性可分之最大化硬间隔模型
什么是线性可分呢? 简单来说就是字面意思,真的存在先行超平面能把特征空间上的数据分开。那么怎么分呢?如图,我们想把这个星星和圆圈分开,那么实际上在两条虚线之间的任意一条直线好像都可以做到,但中间这条红线最好,因为他对于数据的扰动包容性最强,专业一点就是最鲁棒的,对未知数据集泛化能力更强。
举个例子,如果我不取红线作为分类决策,而是取穿过红点的虚线作为决策,目前看来也是可以的,但当我们把他用于测试集(未知的新数据)的时候,假设有一个点是红点,离右侧虚线很近,但就是超过了一点点,但我们的决策还是会把它分到蓝色星星里去,这就是分错了!
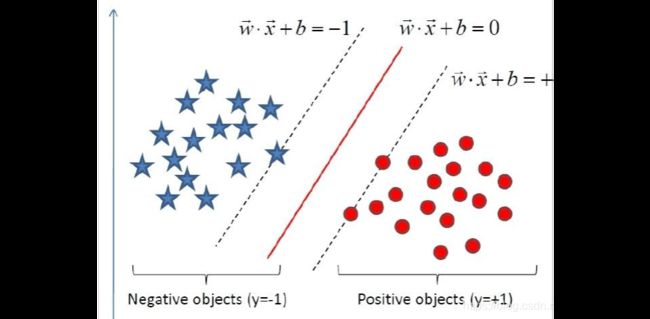
所以我们要寻找星星和圆圈到超平面距离最大的那个超平面。那么求间隔就是图上两次平行线之间求距离啦,这里不细推啦哈~直接给出这个距离是
γ = 2 ∣ ∣ w ∣ ∣ \gamma=\frac{2}{||w||} γ=∣∣w∣∣2
那么目标就是最大化这个间隔,约束呢就是它要满足能分开这些数据,也就是当 y i = 1 y_i=1 yi=1时(比如星星),它要满足 w T x i + b ≥ 1 w^Tx_i+b\ge 1 wTxi+b≥1,即在穿过蓝色星星的上面;红色就有 y i = − 1 y_i=-1 yi=−1时 w T x i + b ≤ 1 w^Tx_i+b\le 1 wTxi+b≤1,我们写出这个标准的问题:
max w , b 2 ∣ ∣ w ∣ ∣ s . t . y i ( w T x i + b ) ≥ 1 , i = 1 , … , m \begin{aligned} \max_{w,b} \quad & \frac{2}{||w||}\\ s.t. \quad & y_i(w^Tx_i+b)\ge 1,i=1,\dots,m \end{aligned} w,bmaxs.t.∣∣w∣∣2yi(wTxi+b)≥1,i=1,…,m
为了方便,我们变化一下得到SVM的基本模型:
min w , b 1 2 ∣ ∣ w ∣ ∣ 2 s . t . y i ( w T x i + b ) ≥ 1 , i = 1 , … , m \begin{aligned} \min_{w,b} \quad & \frac{1}{2}||w||^2\\ s.t. \quad & y_i(w^Tx_i+b)\ge 1,i=1,\dots,m \end{aligned} w,bmins.t.21∣∣w∣∣2yi(wTxi+b)≥1,i=1,…,m
这是一个有约束的凸二次规划模型,我们可以通过对偶去求解,首先写出拉格朗日函数,拉格朗日乘子为 μ \mu μ:
L ( w , b , μ ) = 1 2 ∣ ∣ w ∣ ∣ 2 + ∑ i = 1 m μ i ( 1 − y i ( w T x i + b ) ) L(w,b,\mu)=\frac{1}{2}||w||^2+\sum^m_{i=1}\mu_i(1-y_i(w^Tx_i+b)) L(w,b,μ)=21∣∣w∣∣2+i=1∑mμi(1−yi(wTxi+b))
用其分别对 w , b w,b w,b求偏导令其为0
∂ L ∂ w = w − ∑ i = 1 m μ i y i x i = 0 ∂ L ∂ b = ∑ i = 1 m μ i y i = 0 \begin{aligned} \frac{\partial L}{\partial w}&=w-\sum_{i=1}^m\mu_iy_ix_i=0\\ \frac{\partial L}{\partial b}&=\sum_{i=1}^m\mu_iy_i=0 \end{aligned} ∂w∂L∂b∂L=w−i=1∑mμiyixi=0=i=1∑mμiyi=0
带入到拉格朗日函数中我们就得到了其对偶问题:
min μ ∑ i = 1 m ∑ j = 1 m μ i μ j y i y j x i T x j − ∑ i = 1 m μ i s . t . μ i ≥ 0 , i = 1 , … , m ∑ i = 1 m μ i y i = 0 \begin{aligned} \min_{\mu} \quad &\sum_{i=1}^m\sum_{j=1}^m\mu_i\mu_jy_iy_jx_i^Tx_j-\sum_{i=1}^m\mu_i\\ s.t. \quad & \mu_i\ge0,i=1,\dots,m\\ &\sum_{i=1}^m\mu_iy_i=0 \end{aligned} μmins.t.i=1∑mj=1∑mμiμjyiyjxiTxj−i=1∑mμiμi≥0,i=1,…,mi=1∑mμiyi=0
求解这个问题,我们就能到得到 μ i \mu_i μi带入得到 w , b w,b w,b,最终的分类决策为:
f ( x ) = w T x + b = ∑ i = 1 m μ i y i x i T x i + b f(x)=w^Tx+b=\sum_{i=1}^m\mu_iy_ix_i^Tx_i+b f(x)=wTx+b=i=1∑mμiyixiTxi+b
我们来观察一下KKT条件:
{ μ i ≥ 0 y i ( w T x i + b ) ≥ 1 μ i ( y i ( w T x i + b ) − 1 ) = 0 \begin{cases} \mu_i\ge0 \\ y_i(w^Tx_i+b)\ge 1 \\ \mu_i(y_i(w^Tx_i+b)-1)=0 \end{cases} ⎩⎪⎨⎪⎧μi≥0yi(wTxi+b)≥1μi(yi(wTxi+b)−1)=0
如果 μ i = 0 \mu_i=0 μi=0,则其不会在 f ( x ) f(x) f(x)中的求和号内出现,对其无影响;若 μ i > 0 \mu_i>0 μi>0,则 y i ( w T x i + b ) − 1 = 0 y_i(w^Tx_i+b)-1=0 yi(wTxi+b)−1=0,即这个样本点在最大间隔边界上(虚线)。我们把出现边界上的这些样本点叫支持向量,所以,最终模型只与支持向量有关!
近似线性可分之最大化软间隔模型
我们接下来考虑,如果不那么满足条件怎么办?总有那么几个不听话的星星跑到了圆圈中怎么办?如果这样的样本比较少的话,我们还是说他几乎是线性可分的,也就是可以允许它有一些错误在。在数学意义上来说就是把条件松弛一些,但在目标中要考虑到这个错误不能太多。根据上面的模型以及刚刚的分析,我们直接给出这个最大化软间隔的原模型:
min w , b 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 m ξ i s . t . y i ( w T x i + b ) ≥ 1 − ξ i ξ i ≥ 0 , i = 1 , … , m \begin{aligned} \min_{w,b} \quad & \frac{1}{2}||w||^2+C\sum_{i=1}^m\xi_i\\ s.t. \quad & y_i(w^Tx_i+b)\ge 1-\xi_i\\ &\xi_i\ge0,i=1,\dots,m \end{aligned} w,bmins.t.21∣∣w∣∣2+Ci=1∑mξiyi(wTxi+b)≥1−ξiξi≥0,i=1,…,m
同样的方法求其对偶问题:
min μ ∑ i = 1 m ∑ j = 1 m μ i μ j y i y j x i T x j − ∑ i = 1 m μ i s . t . C ≥ μ i ≥ 0 , i = 1 , … , m ∑ i = 1 m μ i y i = 0 \begin{aligned} \min_{\mu} \quad &\sum_{i=1}^m\sum_{j=1}^m\mu_i\mu_jy_iy_jx_i^Tx_j-\sum_{i=1}^m\mu_i\\ s.t. \quad & C\ge\mu_i\ge0,i=1,\dots,m\\ &\sum_{i=1}^m\mu_iy_i=0 \end{aligned} μmins.t.i=1∑mj=1∑mμiμjyiyjxiTxj−i=1∑mμiC≥μi≥0,i=1,…,mi=1∑mμiyi=0
发现什么没?只是和硬间隔的对偶问题差了一个C! C > 0 C>0 C>0表示的是一个常数,是对错误率的一个容忍情况。 C → ∞ C\to \infty C→∞就是要求这个错误一点都不能有,就是硬间隔问题啦~所以只要掌握了最基础一个推导,其他的就很容易啦。接下来,我们同样来看看KKT条件(注意:在推到过程中原问题有两个约束条件,所以拉格朗日乘子有两个哦):
{ μ i ≥ 0 , α i ≥ 0 y i ( w T x i + b ) ≥ 1 − ξ i , ξ i ≥ 0 μ i ( y i ( w T x i + b ) − 1 + ξ i ) = 0 α i ξ i = 0 \begin{cases} \mu_i\ge0,\alpha_i\ge0 \\ y_i(w^Tx_i+b)\ge 1-\xi_i,\xi_i\ge0 \\ \mu_i(y_i(w^Tx_i+b)-1+\xi_i)=0\\ \alpha_i\xi_i=0 \end{cases} ⎩⎪⎪⎪⎨⎪⎪⎪⎧μi≥0,αi≥0yi(wTxi+b)≥1−ξi,ξi≥0μi(yi(wTxi+b)−1+ξi)=0αiξi=0
同样,我们也可以得出最大软间隔的模型也是只和支持向量有关。
线性不可分之核方法
假如就算我们允许几个错误也不能得到一个很好的划分怎么办呢?如图(不知道哪个大神画的很贴切哈哈哈),我们可以把其映射在高维空间中,然后可以找到一个新的好的决策。
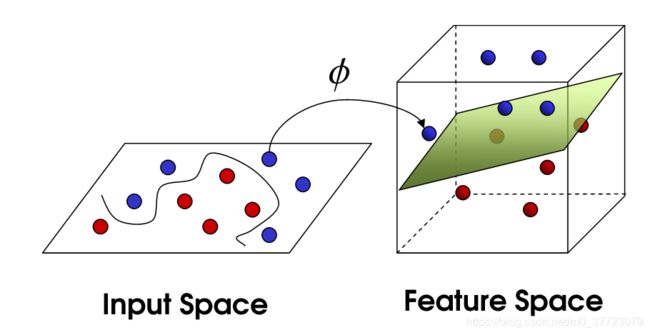
对应的数学表达就是找到一个低维到高维的映射 ϕ ( x ) \phi(x) ϕ(x),然后对高维的进行正常的SVM求解得到决策 f ( x ) = w T ϕ ( x ) + b f(x)=w^T\phi(x)+b f(x)=wTϕ(x)+b,理论推导过程还是一样的,我们直接给出原问题:
min w , b 1 2 ∣ ∣ w ∣ ∣ 2 s . t . y i ( w T ϕ ( x i ) + b ) ≥ 1 , i = 1 , … , m \begin{aligned} \min_{w,b} \quad & \frac{1}{2}||w||^2\\ s.t. \quad & y_i(w^T\phi(x_i)+b)\ge 1,i=1,\dots,m \end{aligned} w,bmins.t.21∣∣w∣∣2yi(wTϕ(xi)+b)≥1,i=1,…,m
以及对偶问题:
min μ ∑ i = 1 m ∑ j = 1 m μ i μ j y i y j ϕ ( x i ) T ϕ ( x j ) − ∑ i = 1 m μ i s . t . μ i ≥ 0 , i = 1 , … , m ∑ i = 1 m μ i y i = 0 \begin{aligned} \min_{\mu} \quad &\sum_{i=1}^m\sum_{j=1}^m\mu_i\mu_jy_iy_j \phi(x_i)^T \phi(x_j)-\sum_{i=1}^m\mu_i\\ s.t. \quad & \mu_i\ge0,i=1,\dots,m\\ &\sum_{i=1}^m\mu_iy_i=0 \end{aligned} μmins.t.i=1∑mj=1∑mμiμjyiyjϕ(xi)Tϕ(xj)−i=1∑mμiμi≥0,i=1,…,mi=1∑mμiyi=0
高维空间中内积往往很难算,所以定义一个核函数来代替内积计算:
k ( x i , x j ) = ϕ ( x i ) T ϕ ( x j ) k(x_i,x_j)=\phi(x_i)^T\phi(x_j) k(xi,xj)=ϕ(xi)Tϕ(xj)
于是核方法的SVM模型的对偶问题为:
min μ ∑ i = 1 m ∑ j = 1 m μ i μ j y i y j k ( x i , x j ) − ∑ i = 1 m μ i s . t . μ i ≥ 0 , i = 1 , … , m ∑ i = 1 m μ i y i = 0 \begin{aligned} \min_{\mu} \quad &\sum_{i=1}^m\sum_{j=1}^m\mu_i\mu_jy_iy_j k(x_i,x_j)-\sum_{i=1}^m\mu_i\\ s.t. \quad & \mu_i\ge0,i=1,\dots,m\\ &\sum_{i=1}^m\mu_iy_i=0 \end{aligned} μmins.t.i=1∑mj=1∑mμiμjyiyjk(xi,xj)−i=1∑mμiμi≥0,i=1,…,mi=1∑mμiyi=0
核函数:若一个对称函数的核矩阵 A i j = k ( x i , x j ) A_{ij}=k(x_i,x_j) Aij=k(xi,xj)为半正定的,则其为核函数。那么我们介绍几个常用的核函数:
a)线性核: k ( x i , x j ) = x i T x j k(x_i,x_j)=x_i^Tx_j k(xi,xj)=xiTxj,特征提取好,且包含的信息量足够大且很多问题都是线性可分时使用。
b)高斯核: k ( x i , x j ) = e x p ( − ∣ ∣ x i − x j ∣ ∣ 2 2 σ 2 ) k(x_i,x_j)=exp(-\frac{||x_i-x_j||^2}{2\sigma^2}) k(xi,xj)=exp(−2σ2∣∣xi−xj∣∣2),特征数少,样本适中且对时间不敏感,遇到的问题是线性不可分时使用。
SVM与LR对比
SVM:
a)一个二分类的非参数模型;
b)模型相对复杂;
c)其解具有稀疏性;
d)只依赖于少数支撑向量;
LR:
a)一个分类的参数模型;
b)模型相对简单,大规模线性分类时比较方便;
c)其输出具有概率意义;
d)依赖于更多样本预测开销大
Python实现
主要思想:利用SMO算法,不断地将原来的二次规划问题分解为只有两个变量的二次规划子问题求解:
1)初始化
2)反复选取不满足KKT条件的拉格朗日乘子 μ i 、 μ j ‘ 在 这 里 插 入 代 码 片 ‘ \mu_i、\mu_j`在这里插入代码片` μi、μj‘在这里插入代码片‘进行优化使其满足且更新截断b
参考:https://blog.csdn.net/weixin_42051109/article/details/87889834
先把数据txt中哦
3.542485 1.977398 -1
3.018896 2.556416 -1
7.551510 -1.580030 1
2.114999 -0.004466 -1
8.127113 1.274372 1
7.108772 -0.986906 1
8.610639 2.046708 1
2.326297 0.265213 -1
3.634009 1.730537 -1
0.341367 -0.894998 -1
3.125951 0.293251 -1
2.123252 -0.783563 -1
0.887835 -2.797792 -1
7.139979 -2.329896 1
1.696414 -1.212496 -1
8.117032 0.623493 1
8.497162 -0.266649 1
4.658191 3.507396 -1
8.197181 1.545132 1
1.208047 0.213100 -1
1.928486 -0.321870 -1
2.175808 -0.014527 -1
7.886608 0.461755 1
3.223038 -0.552392 -1
3.628502 2.190585 -1
7.407860 -0.121961 1
7.286357 0.251077 1
2.301095 -0.533988 -1
-0.232542 -0.547690 -1
3.457096 -0.082216 -1
3.023938 -0.057392 -1
8.015003 0.885325 1
8.991748 0.923154 1
7.916831 -1.781735 1
7.616862 -0.217958 1
2.450939 0.744967 -1
7.270337 -2.507834 1
1.749721 -0.961902 -1
1.803111 -0.176349 -1
8.804461 3.044301 1
1.231257 -0.568573 -1
2.074915 1.410550 -1
-0.743036 -1.736103 -1
3.536555 3.964960 -1
8.410143 0.025606 1
7.382988 -0.478764 1
6.960661 -0.245353 1
8.234460 0.701868 1
8.168618 -0.903835 1
1.534187 -0.622492 -1
9.229518 2.066088 1
7.886242 0.191813 1
2.893743 -1.643468 -1
1.870457 -1.040420 -1
5.286862 -2.358286 1
6.080573 0.418886 1
2.544314 1.714165 -1
6.016004 -3.753712 1
0.926310 -0.564359 -1
0.870296 -0.109952 -1
2.369345 1.375695 -1
1.363782 -0.254082 -1
7.279460 -0.189572 1
1.896005 0.515080 -1
8.102154 -0.603875 1
2.529893 0.662657 -1
1.963874 -0.365233 -1
8.132048 0.785914 1
8.245938 0.372366 1
6.543888 0.433164 1
-0.236713 -5.766721 -1
8.112593 0.295839 1
9.803425 1.495167 1
1.497407 -0.552916 -1
1.336267 -1.632889 -1
9.205805 -0.586480 1
1.966279 -1.840439 -1
8.398012 1.584918 1
7.239953 -1.764292 1
7.556201 0.241185 1
9.015509 0.345019 1
8.266085 -0.230977 1
8.545620 2.788799 1
9.295969 1.346332 1
2.404234 0.570278 -1
2.037772 0.021919 -1
1.727631 -0.453143 -1
1.979395 -0.050773 -1
8.092288 -1.372433 1
1.667645 0.239204 -1
9.854303 1.365116 1
7.921057 -1.327587 1
8.500757 1.492372 1
1.339746 -0.291183 -1
3.107511 0.758367 -1
2.609525 0.902979 -1
3.263585 1.367898 -1
2.912122 -0.202359 -1
1.731786 0.589096 -1
2.387003 1.573131 -1
接下来是代码啦
from numpy import *
import random
import matplotlib.pyplot as plt
import numpy
class SVM:
def __init__(self,dataMain,classLabel,C,toler,kTup):
self.X = dataMain # 样本矩阵
self.labelMat = classLabel
self.C = C # 惩罚因子
self.tol = toler # 容错率
self.m = shape(dataMain)[0] # 样本点个数
self.alphas = mat(zeros((self.m,1))) # 产生m个拉格郎日乘子,组成一个m×1的矩阵
self.b =0 # 决策面的截距
self.eCache = mat(zeros((self.m,2))) # 产生m个误差 E=f(x)-y ,设置成m×2的矩阵,矩阵第一列是标志位,标志为1就是E计算好了,第二列是误差E
def loadDataSet(filename): # 加载数据
dataMat = []
labelMat = []
fr = open(filename)
for line in fr.readlines():
lineArr = line.split()
dataMat.append([float(lineArr[0]),float(lineArr[1])])
labelMat.append(float(lineArr[2]))
return dataMat, labelMat
def selectJrand(i, m): # 随机选择一个不等于i的下标
j =i
while(j==i):
j = int(random.uniform(0,m))
return j
def clipAlpha(aj, H,L):
if aj>H: # 如果a^new 大于上限值,那么就把上限赋给它
aj = H
if L>aj: # 如果a^new 小于下限值,那么就把下限赋给它
aj = L
return aj
def calcEk(oS, k): # 计算误差E, k代表第k个样本点,它是下标, 公式f(x)=sum(ai*yi*xi^T*x)+b
fXk = float(multiply(oS.alphas,oS.labelMat).T * (oS.X*oS.X[k,:].T)) +oS.b
Ek = fXk - float(oS.labelMat[k]) # 计算误差 E=f(x)-y
return Ek
def selectJ(i, oS, Ei): # 选择两个拉格郎日乘子,在所有样本点的误差计算完毕之后,寻找误差变化最大的那个样本点及其误差
maxK = -1 # 最大步长的因子的下标
maxDeltaE = 0 # 最大步长
Ej = 0 # 最大步长的因子的误差
oS.eCache[i] = [1,Ei]
valiEcacheList = nonzero(oS.eCache[:,0].A)[0]
print("valiEcacheList is {}".format(valiEcacheList))
if (len(valiEcacheList))>1:
for k in valiEcacheList: # 遍历所有计算好的Ei的下标,valiEcacheLIst保存了所有样本点的E,计算好的有效位置是1,没计算好的是0
if k == i:
continue
Ek = calcEk(oS,k)
deltaE = abs(Ei-Ek) # 距离第一个拉格朗日乘子a1绝对值最远的作为第二个朗格朗日乘子a2
if deltaE>maxDeltaE:
maxK = k # 记录选中的这个乘子a2的下标
maxDeltaE = deltaE # 记录他俩的绝对值
Ej = Ek # 记录a2此时的误差
return maxK, Ej
else: # 如果是第一次循环,随机选择一个alphas
j = selectJrand(i, oS.m)
# j = 72
Ej = calcEk(oS, j)
return j,Ej
def updateEk(oS, k):
Ek = calcEk(oS, k)
oS.eCache[k] = [1,Ek] # 把第k个样本点的误差计算出来,并存入误差矩阵,有效位置设为1
def innerL(i, oS):
Ei = calcEk(oS, i) # KKT条件, 若yi*(w^T * x +b)-1<0 则 ai=C 若yi*(w^T * x +b)-1>0 则 ai=0
print("i is {0},Ei is {1}".format(i,Ei))
if ((oS.labelMat[i]*Ei < -oS.tol) and (oS.alphas[i] < oS.C)) or ((oS.labelMat[i]*Ei > oS.tol) and (oS.alphas[i] > 0)):
j,Ej = selectJ(i,oS,Ei)
print("第二个因子的坐标{}".format(j))
alphaIold = oS.alphas[i].copy() # 用了浅拷贝, alphaIold 就是old a1,对应公式
alphaJold = oS.alphas[j].copy()
if oS.labelMat[i] != oS.labelMat[j]: # 也是根据公式来的,y1 不等于 y2时
L = max(0,oS.alphas[j] - oS.alphas[i])
H = min(oS.C, oS.C+oS.alphas[j]-oS.alphas[i])
else:
L = max(0,oS.alphas[j]+oS.alphas[i]-oS.C)
H = min(oS.C,oS.alphas[j]+oS.alphas[i])
if L==H: # 如果这个j让L=H,i和j这两个样本是同一类别,且ai=aj=0或ai=aj=C,或者不同类别,aj=C且ai=0
# 当同类别时 ai+aj = 常数 ai是不满足KKT的,假设ai=0,需增大它,那么就得减少aj,aj已经是0了,不能最小了,所以此情况不允许发生
# 当不同类别时 ai-aj=常数,ai是不满足KKT的,ai=0,aj=C,ai需增大,它则aj也会变大,但是aj已经是C的不能再大了,故此情况不允许
print("L=H")
return 0
# eta = 2.0*oS.K[i,j]-oS.K[i,i]-oS.K[j,j] # eta=K11+K22-2*K12
eta = 2.0*oS.X[i,:]*oS.X[j,:].T - oS.X[i,:]*oS.X[i,:].T - oS.X[j,:]*oS.X[j,:].T
if eta >= 0: # 这里跟公式正好差了一个负号,所以对应公式里的 K11+K22-2*K12 <=0,即开口向下,或为0成一条直线的情况不考虑
print("eta>=0")
return 0
oS.alphas[j]-=oS.labelMat[j]*(Ei-Ej)/eta # a2^new = a2^old+y2(E1-E2)/eta
print("a2 归约之前是{}".format(oS.alphas[j]))
oS.alphas[j]=clipAlpha(oS.alphas[j],H,L) # 根据公式,看看得到的a2^new是否在上下限之内
print("a2 归约之后is {}".format(oS.alphas[j]))
# updateEk(oS,j) # 把更新后的a2^new的E更新一下
if abs(oS.alphas[j]-alphaJold)<0.00001:
print("j not moving enough")
return 0
oS.alphas[i] +=oS.labelMat[j]*oS.labelMat[i]*(alphaJold-oS.alphas[j]) # 根据公式a1^new = a1^old+y1*y2*(a2^old-a2^new)
print("a1更新之后是{}".format(oS.alphas[i]))
b1 = oS.b-Ei-oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.X[i,:]*oS.X[i,:].T-oS.labelMat[j]* \
(oS.alphas[j]-alphaJold)*oS.X[i,:]*oS.X[j,:].T
b2 = oS.b-Ej-oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.X[i,:]*oS.X[j,:].T-oS.labelMat[j]* \
(oS.alphas[j]-alphaJold)*oS.X[j,:]*oS.X[j,:].T
updateEk(oS,j)
updateEk(oS,i)
if (0 < oS.alphas[i]) and (oS.C > oS.alphas[i]):
oS.b = b1.A[0][0]
elif (0<oS.alphas[j]) and (oS.C > oS.alphas[j]):
oS.b = b2.A[0][0]
else:
oS.b = (b1+b2)/2.0
print("b is {}".format(oS.b))
return 1
else:
return 0
def smoP(dataMatIn, classLabels, C,toler,maxIter,kTup=('lin',)):
oS = SVM(mat(dataMatIn), mat(classLabels).transpose(),C,toler,kTup)
iter = 0
entireSet = True # 两种遍历方式交替
alphaPairsChanged = 0
while (iter<maxIter) and ((alphaPairsChanged>0) or (entireSet)):
alphaPairsChanged = 0
if entireSet:
for i in range(oS.m):
alphaPairsChanged += innerL(i,oS)
print("fullSet, iter:%d i: %d pairs changed %d"%(iter,i ,alphaPairsChanged))
iter+=1
print("第一种遍历alphaRairChanged is {}".format(alphaPairsChanged))
print("-----------eCache is {}".format(oS.eCache))
print("***********alphas is {}".format(oS.alphas))
print("---------------------------------------")
else:
nonBoundIs = nonzero((oS.alphas.A > 0) * (oS.alphas.A < C))[0] # 这时数组相乘,里面其实是True 和False的数组,得出来的是
# 大于0并且小于C的alpha的下标
for i in nonBoundIs:
alphaPairsChanged += innerL(i,oS)
print("non-bound, iter: %d i:%d, pairs changed %d"%(iter,i,alphaPairsChanged))
print("第二种遍历alphaPairChanged is {}".format(alphaPairsChanged))
iter+=1
if entireSet:
entireSet = False # 当第二种遍历方式alpha不再变化,那么继续第一种方式扫描,第一种方式不再变化,此时alphachanged为0且entireSet为false,退出循环
elif (alphaPairsChanged==0):
entireSet=True
print("iteration number: %d"%iter)
return oS.b,oS.alphas
def calcWs(alphas,dataArr,classLabels): # 通过alpha来计算w
X = mat(dataArr)
labelMat = mat(classLabels).transpose()
m,n = shape(X)
w = zeros((n,1))
for i in range(m):
w += multiply(alphas[i]*labelMat[i], X[i,:].T) # w = sum(ai*yi*xi)
return w
def draw_points(dataArr,classlabel, w,b,alphas):
plt.rcParams['axes.unicode_minus'] = False # 防止坐标轴的‘-’变为方块
m = len(classlabel)
red_points_x=[]
red_points_y =[]
blue_points_x=[]
blue_points_y =[]
svc_points_x =[]
svc_points_y =[]
# print(type(alphas))
svc_point_index = nonzero((alphas.A>0) * (alphas.A <0.8))[0]
svc_points = array(dataArr)[svc_point_index]
svc_points_x = [x[0] for x in list(svc_points)]
svc_points_y = [x[1] for x in list(svc_points)]
print("svc_points_x",svc_points_x)
print("svc_points_y",svc_points_y)
for i in range(m):
if classlabel[i] ==1:
red_points_x.append(dataArr[i][0])
red_points_y.append(dataArr[i][1])
else:
blue_points_x.append(dataArr[i][0])
blue_points_y.append(dataArr[i][1])
fig = plt.figure() # 创建画布
ax = fig.add_subplot(111)
ax.set_title("SVM-Classify") # 设置图片标题
ax.set_xlabel("x1") # 设置坐标名称
ax.set_ylabel("x2")
ax1=ax.scatter(red_points_x, red_points_y, s=30,c='red', marker='s')
ax2=ax.scatter(blue_points_x, blue_points_y, s=40,c='green')
# ax.set_ylim([-6,5])
print("b",b)
print("w",w)
x1 = arange(-2.0, 12.0, 0.1) # 分界线x范围,步长为0.1
# x = arange(-2.0,10.0)
if isinstance(b,numpy.matrixlib.defmatrix.matrix):
b = b.A[0][0]
x2 = (-b-w[0][0]*x1)/w[1][0] # 划分决策超平面 在LR那节中讲过为什么是这样的
ax3,=plt.plot(x1,x2, 'k')
plt.xlim((-1.5, 11))
plt.ylim((-12, 12))
ax4=plt.scatter(svc_points_x,svc_points_y,s=50,c='orange',marker='p')
plt.legend([ax1, ax2,ax3,ax4], ["red points","green points", "decision boundary","support vector"], loc='lower right') # 标注
plt.show()
#测试
dataArr,labelArr = loadDataSet('data.txt')
b,alphas = smoP(dataArr,labelArr,0.8,0.001,40)
w=calcWs(alphas,dataArr,labelArr)
draw_points(dataArr,labelArr,w,b,alphas)
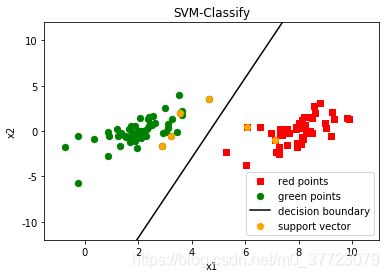
结果: