微服务架构 | 分布式存储 -算法
INDEX
-
-
- §1 场景
- §2 hash 取余算法
- §3 一致性 hash 算法
- §3 hash 槽算法
-
§1 场景
问:海量数据(亿即)作为缓存如何实现(其他持久化组件也适用)
答:肯定是多个缓存实例
问:海量数据是如何存在于多个缓存实例的
答:使数据尽量均匀的落入多个缓存实例中,同时考虑缓存实例数量变更的场景
问:如何具体实现
答:顺次参考下面三个算法
§2 hash 取余算法
通过公式
hash % N
计算数据落点,N 是缓存集群节点数量
优缺点
优点
- 简单
- 粗暴
- 有效
缺点
- 不利于缓存集群的缩容扩容
扩容时,会导致所有数据都需要根据新的集群容量进行取余,可能导致 100% 的数据迁移
翻倍扩容(N 个节点扩容到 2N)只会使 50% 的数据迁移,但数据量较大时,50% 也很多 - 缓存节点挂掉时应该落入此节点的数据卡死
§3 一致性 hash 算法
步骤
- 逻辑上认为 hash 的最小最大值相连,形成 hash 环
一些讲解说 hash 环是通过 hash 值对 232 取模得到,但一些 hash 算法本身就是 32 位的,取不取模没有区别,比如 java 的 hashcode(),因此,可以理解取余和哈希值空间的收尾相连是两回事
收尾相连只是使 hash 值的最大值的下一个值是 0 ,用于找存储节点时不会遇到最大值就停下 - 通过一定规则(比如通过 IP)计算缓存节点的 hash 值,并将此值对应 hash 环上的位置
- 计算 key 的 hash ,key 存入此 hash 沿着 hash 环顺时针找到的第一个存储节点 hash 对应的存储节点。即,若
存储节点A 的 hash=1000000
存储节点B 的 hash=2000000
存储节点C 的 hash=3000000
则
hash=1000100 的 key 存入 A
hash=2000100 的 key 存入 B
hash=3000100 的 key 存入C
示意图如下

优缺点
以下图为例,原始 hash 环上只有 4 台存储节点,其位置分别是 node 1-4
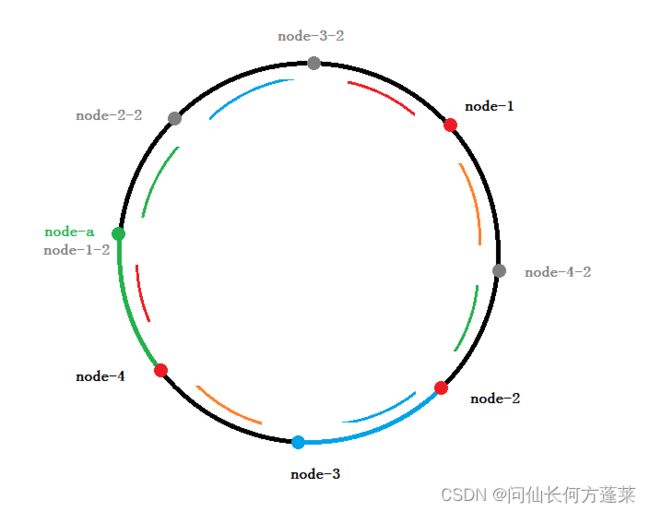
优点
- 容错性
假设 node-3 节点挂了
对存储集群的影响仅仅是 在 node-3 上读写的数据(蓝色部分)转由 node-4 负责
从上面例子中可以看到,这个比例远少于 hash 取余算法的 50% - 扩展性
假设集群扩容,增加了 node-a 节点
对存储集群的影响仅仅是 在 node-a 与它上一个节点之间的数据(绿色部分)转由 node-a 负责
从上面例子中可以看到,这个比例也只是整个 hash 环上的一小部分
缺点
-
数据倾斜问题
回到一开始只有 node 1-4 的状态,
可以发现 node-1 节点的任务明显更繁重,它负责了 hash 环上一半左右的数据
这会使不同存储节点上的负载不均衡,实际开发生产环境中可能导致雪崩效应 -
雪崩效应
回到一开始只有 node 1-4 的状态,因为数据倾斜的问题,node -1 节点任务繁重
假设 node-1 挂了,则原先在 node-1 上读写的数据都落入 node-2 上
加上 node-2 本身的数据,node-2 很可能也扛不住,挂了
以此类推,全集群都挂了
虚拟节点
可以通过添加虚拟节点的方式一定程度上解决数据倾斜问题
虚拟节点的添加有两个原则
- 以均匀的分割 hash 环为宜,但不一定等分
- 虚拟节点到真实节点的映射也要均匀
如上图,在 hash 环上添加 4 个灰色节点 node-x-2 作为 node-x 的虚拟节点,则整个 hash 环大致被 8 等分
实际操作中,也不一定是添加一倍的虚拟节点,而只需要参考虚拟节点到真实节点的映射,最终达到负载均衡即可
此时,上图中,
每段有颜色的圆弧上的数据对应一个节点(可能是真实节点,也可能是虚拟节点)
每两端颜色相同的圆弧上的数据由一个真实节点负责,做到每个真实节点负载大致均衡
也可以这样理解,8 个节点实际上都是虚拟节点(上图的的 node-x 理解为 node-x-1 的虚拟节点),负责差不多范围的数据
所有落在虚拟节点上的数据均由对应的真实节点处理,对应的规则为 node-x-1 与 node-x-2 都由 node-x 处理
虚拟节点一致性 hash 的问题
hash 取余算法存在存在两个问题
- 死节点的数据卡死
- 节点数量变化时的大量数据迁移
原始一致性 hash 解决了这两个问题,但因为它存储存储节点落点是通过 hash 计算的,因此带来了新问题
- 数据倾斜问题
数据倾斜的本质是存储节点负载不均匀,因此引入虚拟节点解决了这一问题
但是,如上图,在虚拟节点一致性 hash 的基础上再增加存储节点呢
即,原本是 8 虚拟节点 对应 4 真实存储节点,
但,现在是 5 个真实存储节点了,如何分配虚拟节点或增长虚拟节点呢
一种可行的方式是:预设足够多的虚拟节点
比如,预设 120 个虚拟节点
假设原始有 10 个真实存储节点,那每个节点映射 12 个虚拟节点
现在增加 2 个节点,那每个节点改为映射 10 个虚拟节点
不能均分的话也只是某几个真实存储节点相对其他节点增减一部分工作量,这部分工作量通常不会造成什么后果
但是这种方式依然有局限性,局限性在于:
若真实物理节点超过一定数量,导致不能给真实物理节点相对均匀的分配虚拟节点
就可能导致某些节点的工作量是其他节点的多倍(比如 100 虚拟节点,70 真实节点),这又有可能导致雪崩
因此又要考虑扩展虚拟节点,而对虚拟节点的扩展,约等于扩展 hash 取余算法中的集群数量
最少又是 50% 的数据迁移量
§3 hash 槽算法
步骤
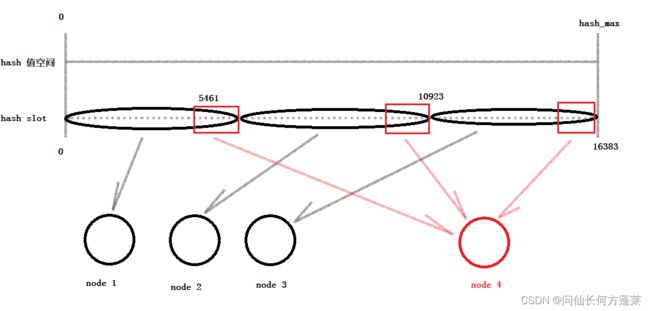
- 在整个 hash 值空间上覆盖一层 hash 槽,这个 hash 槽是一个比较长的数组,有 16384 个槽位 (为什么是 16384)
- 变更存储的 hash 算法,从产生 32 位的 hash 算法变更为产生 16 位 hash 值的 CYC16
- 数据的 key 通过 CYC16 算法后对 hash 槽长度(16384) 取余得到在 hash 槽上的索引,并落在对应的槽上
即 slot_index = CRC16(key) % 16384 - hash 槽的每个槽位与存储节点之间存在对应关系
- 默认是按区间均分,假设有 3 个存储节点,则第一个节点处理前 1/3 hash 槽的数据,以此类推
- 扩展节点后,每个扩展前的节点让渡一部分自己负载的 hash 槽给新节点
从带有虚拟节点的一致性 hash 理解 hash 槽
hash 槽可以看做带有虚拟节点的一致性hash 的变种,或 一致性 hash 与 hash 取余 的结合
将每个 hash 槽都视为一个虚拟节点
hash 槽就是一个预设了 16384 个虚拟节点的一致性 hash(当然,此时无所谓 hash 环不环了)
然后在去解决 16384 个虚拟节点和真实节点的映射问题
换句话说,本帖子讨论到的 分布式存储中数据分布的核心问题 其实只有两个
- 负载均衡
- 存储集群节点数量变化造成数据迁移
hash 取余 的等分思想(对几取余就是几等分)解决了 负载均衡,但在 节点数量变化 上瘸了
一致性 hash 的 hash 环解决了 节点数量变化(在环上拆补线段玩),但又不够 负载均衡
带有虚拟节点的一致性 hash 到是同时解决了二者,但存在局限性
虚拟节点大致实现了等分,虚拟节点到实际节点的映射解决 节点数量变化,同时兼顾负载均衡
整合上面的思路,
首先,设置足够多的区间段(类似虚拟节点):16384 个
每个区间段的大小完全一致,这就是实现了对整个 hash 值空间(此时是 16 位的 CYC16 空间了)的绝对等分
这就是 hash 槽的数据结构
然后,尽量均匀的完成 hash 槽对真实存储节点的映射
因为划分的碎片足够碎,并且每个碎片一样大,因此总能给每个真实存储节点分配近乎一样的工作量,达成负载均衡
因为划分的碎片足够多,所以每个碎片足够小,通过划拨碎片可以做到在 存储集群节点数量变化造成数据迁移 尽可能少
为什么 hash 槽有 16384 个槽位 TBC
16384 个槽位够用了
分配足够多的槽位是为了可以不破坏 负载均衡 的前提下尽量灵活的映射 槽位 和 存储节点
一个集群中,节点的数量几乎不会超过 1000
即使按 1000 算,16K+ 个槽位去分配 1K 个节点也足够兼顾灵活映射且尽量负载均衡
考虑心跳包数据大小
每个集群中的节点都需要定时发送心跳
心跳包中包含槽位的信息,应该是当前节点具体包含哪些槽位,每个槽位是否包含可以用 1 bit 传输
一共 16384 个槽位即需要 16384 bit = 16384 / 8 / 1024 = 2Kb 的数据量进行描述,可以接受
当 65536 个槽位且集群中节点很多时,就需要 8Kb * 节点数量的数据流量,只用于传输心跳,浪费
压缩率高(没看明白)
Redis主节点的配置信息中,它所负责的哈希槽是通过一张bitmap的形式来保存的,在传输过程中,会对bitmap进行压缩,但是如果bitmap的填充率slots / N很高的话(N表示节点数),bitmap的压缩率就很低。 如果节点数很少,而哈希槽数量很多的话,bitmap的压缩率就很低。