我复现的第一个神经网络: LeNet
目录
1. LeNet简介
2. LeNet实现
3. 实验结果
Reference
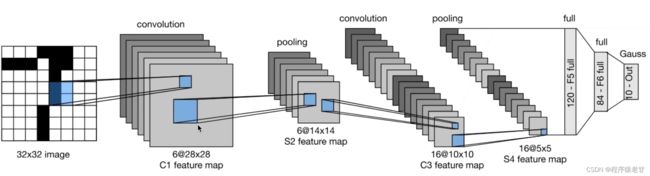
学习深度学习已经有小一年的时间,看了很多视频和书本内容,学习了很多代码,可始终感觉认知不够扎实。结合李沐老师的视频课程,我决定在本博客中介绍下复现LeNet的过程。代码基于pycharm2021平台,选用python3.8版本+pytorch1.12.1+cu116。基本上把各个包的版本都刷到最新版本,以方便后续的网络升级和向后兼容。
1. LeNet简介
LeNet网络 [1] 由时任AT&T贝尔实验室的研究员Yann LeCun提出,可以被看作是卷积神经网络的开山之作。之所以选用LeNet作为尝试复现的第一个神经网络,是因为该网络本身的结构简单清晰,便于理解。作为早期成功应用于银行和邮政系统的实用型卷积神经网络,LeNet的结构足够经典,其中很多思想传承至今。因此,LeNet作为深度网络代码复现的一个经典案例,十分恰当。
我们首先回顾下LeNet的基本结构。输入是一个32*32的单通道图片 (更新版本的minist数据集的图片尺寸可能减到28*28,那么在卷积的时候需要padding以保证卷积后的特征图为28*28),之后使用一个卷积层,变换出6通道的28*28的C1 feature map;加一步pooling,由28*28的feature压到14*14。之后按照相同的步骤,压出一个16通道的5*5的feature map,最后加两个全连接层,并输出10个元素组成的向量,以判断输入数字的类别。可以看到,整个结构是非常清晰,便于理解的。
2. LeNet实现
LeNet的网络搭建如下:
import torch
from torch import nn
from d2l import torch as s2l
class Reshape(torch.nn.Module):
def forward(self, x):
return x.view(-1,1,28,28)
net = torch.nn.Sequential(Reshape(),
nn.Conv2d(1,6,kernel_size = 5,padding=2),
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2,stride=2),
nn.Conv2d(6,16,kernel_size=5),
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2,stride=2),
nn.Flatten(),
nn.Linear(16*5*5, 120),
nn.Sigmoid(),
nn.Linear(120, 84),
nn.Sigmoid(),
nn.Linear(84, 10))
X = torch.rand(size = (1,1,28,28),dtype=torch.float32)
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape:\t',X.shape)可以看到,整个网络的实现还是比较简单的。这里,按照李沐老师视频的介绍,我们给一个随机的输入,来输出网络中各个层对于输入数据的改变,结果如下:
Reshape output shape: torch.Size([1, 1, 28, 28])
Conv2d output shape: torch.Size([1, 6, 28, 28])
Sigmoid output shape: torch.Size([1, 6, 28, 28])
AvgPool2d output shape: torch.Size([1, 6, 14, 14])
Conv2d output shape: torch.Size([1, 16, 10, 10])
Sigmoid output shape: torch.Size([1, 16, 10, 10])
AvgPool2d output shape: torch.Size([1, 16, 5, 5])
Flatten output shape: torch.Size([1, 400])
Linear output shape: torch.Size([1, 120])
Sigmoid output shape: torch.Size([1, 120])
Linear output shape: torch.Size([1, 84])
Sigmoid output shape: torch.Size([1, 84])
Linear output shape: torch.Size([1, 10])
在确定网络结构后,我们提取测试数据。这里,我们使用Fashion-MNIST数据集来训练和测试网络的性能。数据提取代码如下:
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size = batch_size)使用GPU计算模型在数据集上的精度:
def evaluate_accuracy_gpu(net, data_iter,device=None):
if isinstance(net, torch.nn.Module):
net.eval()
if not device:
device = next(iter(net.parameters())).device
metric = d2l.Accumulator(2)
for X,y in data_iter:
if isinstance(X,list):
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
metric.add(d2l.accuracy(net(X),y), y.numel())
return metric[0]/metric[1]添加训练函数的完整代码:
import torch
from torch import nn
from d2l import torch as d2l
class Reshape(torch.nn.Module):
def forward(self, x):
return x.view(-1,1,28,28)
def evaluate_accuracy_gpu(net, data_iter,device=None):
if isinstance(net, torch.nn.Module):
net.eval()
if not device:
device = next(iter(net.parameters())).device
metric = d2l.Accumulator(2)
for X,y in data_iter:
if isinstance(X,list):
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
metric.add(d2l.accuracy(net(X),y), y.numel())
return metric[0]/metric[1]
def train_ch6(net, train_iter, test_iter, num_epochs, lr ,device):#lr: learning rate
"""train a model woth GPU"""
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on', device)
net.to(device)
optimizer = torch.optim.SGD(net.parameters(),lr=lr)
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel = 'epoch', xlim = [1, num_epochs],
legend = ['train loss', 'train acc', 'test acc'])
timer, num_batches = d2l.Timer(),len(train_iter)
for epoch in range(num_epochs):
metric = d2l.Accumulator(3)
net.train()
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if(i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1)/ num_batches,(train_l, train_acc, None))
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print('Epoch:', epoch)
print(f'loss {train_l:.3f}, train acc {train_acc:,.3f},' f'test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec' f'on {str(device)}')
print(f'loss {train_l:.3f}, train acc {train_acc:,.3f},' f'test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs/timer.sum():.1f} examples/sec' f'on {str(device)}')
print('finished')
def main():
net = torch.nn.Sequential(Reshape(),
nn.Conv2d(1, 6, kernel_size=5, padding=2),
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5),
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(16 * 5 * 5, 120),
nn.Sigmoid(),
nn.Linear(120, 84),
nn.Sigmoid(),
nn.Linear(84, 10))
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)
lr, num_epochs = 0.9, 10
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
if __name__ == '__main__':
main()3. 实验结果
打印结果:
training on cuda:0
Epoch: 0
loss 2.317, train acc 0.102,test acc 0.100
174566.9 examples/secon cuda:0
Epoch: 1
loss 1.383, train acc 0.459,test acc 0.580
139471.3 examples/secon cuda:0
Epoch: 2
loss 0.857, train acc 0.661,test acc 0.652
115809.0 examples/secon cuda:0
Epoch: 3
loss 0.718, train acc 0.716,test acc 0.701
99568.9 examples/secon cuda:0
Epoch: 4
loss 0.648, train acc 0.748,test acc 0.752
87336.1 examples/secon cuda:0
Epoch: 5
loss 0.590, train acc 0.770,test acc 0.776
77399.1 examples/secon cuda:0
Epoch: 6
loss 0.550, train acc 0.787,test acc 0.781
69605.1 examples/secon cuda:0
Epoch: 7
loss 0.515, train acc 0.800,test acc 0.793
63230.5 examples/secon cuda:0
Epoch: 8
loss 0.485, train acc 0.816,test acc 0.799
57836.1 examples/secon cuda:0
Epoch: 9
loss 0.459, train acc 0.829,test acc 0.761
53456.0 examples/secon cuda:0
loss 0.459, train acc 0.829,test acc 0.761
53456.0 examples/secon cuda:0
动态曲线图:

注:如果动画无法显示,参考博客:无法显示动图怎么办?
Reference
[1] LeCun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324.