Code For Better 谷歌开发者之声——使用TensorFlow的时间序列预测

一、 前言
对未来的预测能够帮助企业更好的把握当下。因此,时间序列任务广泛应用于交通、气象、金融、零售等行业
本文介绍如何使用TensorFlow进行时间序列预测,主要依托我即将发布的一个时序包东流TFTS (TensorFlow Time Series) 。TFTS是一个时间序列的开源工具,采用TensorFlow框架,支持多种深度学习SOTA模型。中文名“东流”,源自辛弃疾“青山遮不住,毕竟东流去。江晚正愁余,山深闻鹧鸪”。
1.1 开源地址
https://github.com/LongxingTan/Time-series-prediction
1.2 取得成绩
- Bert模型 获得KDD CUP2022百度风机功率预测第3名
- Seq2seq模型 获得阿里天池-AI earth人工智能气象挑战赛第4名
接下来,我们介绍面对一个新任务时,如何采用TensorFlow获得一个好的结果
二、应用案例
2.1 准备环境
- 可以选择docker安装,参照tensorflow文档
- 也可以参照tfts中的requirements
2.2 准备数据
我们这里采用kaggle中的数据集,下载地址
我们首先对数据进行探索性分析
2.3 特征工程
虽然,深度学习具有学习交叉特征的能力,但显式的特征工程仍然是不可获取的。
def add_features(df):
df['cross']= df['u_in'] * df['u_out']
df['cross2']= df['time_step'] * df['u_out']
df['area'] = df['time_step'] * df['u_in']
df['area'] = df.groupby('breath_id')['area'].cumsum()
df['time_step_cumsum'] = df.groupby(['breath_id'])['time_step'].cumsum()
df['u_in_cumsum'] = (df['u_in']).groupby(df['breath_id']).cumsum()
print("Step-1...Completed")
df['u_in_lag1'] = df.groupby('breath_id')['u_in'].shift(1)
df['u_out_lag1'] = df.groupby('breath_id')['u_out'].shift(1)
df['u_in_lag_back1'] = df.groupby('breath_id')['u_in'].shift(-1)
df['u_out_lag_back1'] = df.groupby('breath_id')['u_out'].shift(-1)
df['u_in_lag2'] = df.groupby('breath_id')['u_in'].shift(2)
df['u_out_lag2'] = df.groupby('breath_id')['u_out'].shift(2)
df['u_in_lag_back2'] = df.groupby('breath_id')['u_in'].shift(-2)
df['u_out_lag_back2'] = df.groupby('breath_id')['u_out'].shift(-2)
df['u_in_lag3'] = df.groupby('breath_id')['u_in'].shift(3)
df['u_out_lag3'] = df.groupby('breath_id')['u_out'].shift(3)
df['u_in_lag_back3'] = df.groupby('breath_id')['u_in'].shift(-3)
df['u_out_lag_back3'] = df.groupby('breath_id')['u_out'].shift(-3)
df['u_in_lag4'] = df.groupby('breath_id')['u_in'].shift(4)
df['u_out_lag4'] = df.groupby('breath_id')['u_out'].shift(4)
df['u_in_lag_back4'] = df.groupby('breath_id')['u_in'].shift(-4)
df['u_out_lag_back4'] = df.groupby('breath_id')['u_out'].shift(-4)
df = df.fillna(0)
print("Step-2...Completed")
df['breath_id__u_in__max'] = df.groupby(['breath_id'])['u_in'].transform('max')
df['breath_id__u_in__mean'] = df.groupby(['breath_id'])['u_in'].transform('mean')
df['breath_id__u_in__diffmax'] = df.groupby(['breath_id'])['u_in'].transform('max') - df['u_in']
df['breath_id__u_in__diffmean'] = df.groupby(['breath_id'])['u_in'].transform('mean') - df['u_in']
print("Step-3...Completed")
df['u_in_diff1'] = df['u_in'] - df['u_in_lag1']
df['u_out_diff1'] = df['u_out'] - df['u_out_lag1']
df['u_in_diff2'] = df['u_in'] - df['u_in_lag2']
df['u_out_diff2'] = df['u_out'] - df['u_out_lag2']
df['u_in_diff3'] = df['u_in'] - df['u_in_lag3']
df['u_out_diff3'] = df['u_out'] - df['u_out_lag3']
df['u_in_diff4'] = df['u_in'] - df['u_in_lag4']
df['u_out_diff4'] = df['u_out'] - df['u_out_lag4']
print("Step-4...Completed")
return df
train = add_features(train)
test = add_features(test)
2.4 模型
tfts在tensorflow的基础上可以快速搭建不同时序模型。只需要传入对应模型名字即可
def build_model(use_model, train_sequence_length, predict_sequence_length=288, target_aggs=1, short_feature_nums=10, long_feature_nums=1, custom_model_params=None):
inputs = (
Input([1]),
Input([train_sequence_length, short_feature_nums]), # raw feature numbers
Input([train_sequence_length+predict_sequence_length, long_feature_nums]) # 长版
)
teacher_inputs = Input([predict_sequence_length//target_aggs, 1])
ts_inputs = KDD(train_sequence_length, predict_sequence_length)(inputs)
outputs = build_tfts_model(use_model=use_model, predict_sequence_length=predict_sequence_length//target_aggs, custom_model_params=custom_model_params)(ts_inputs, teacher_inputs)
model = tf.keras.Model(inputs={'inputs':inputs, 'teacher': teacher_inputs}, outputs=outputs)
return model
目前已经支持的模型包括,点击可查看具体tensorflow实现
- RNN
- Seq2seq
- TCN
- wavenet
- bert
- transoformer
2.5 训练与验证
线下验证是衡量模型水平的重要依据,对于时序任务多采取time split的方式。
def run_train(cfg, args):
train_data_reader, train_data_loader, valid_data_reader, valid_data_loader, valid_df = build_data(cfg, args)
print(len(train_data_reader), len(valid_data_reader), len(valid_df))
build_model_fn = functools.partial(build_model, cfg.use_model, train_sequence_length=cfg.train_sequence_length, predict_sequence_length=cfg.predict_sequence_length, target_aggs=cfg.target_aggs, short_feature_nums=len(cfg.feature_column_short), long_feature_nums=len(cfg.feature_column_long), custom_model_params=cfg.custom_model_params)
optimizer = tf.keras.optimizers.Adam(learning_rate = cfg.fit_params['learning_rate'])
loss_fn = custom_loss # tf.keras.losses.MeanSquaredError()
trainer = KerasTrainer(build_model_fn, loss_fn=loss_fn, optimizer=optimizer, strategy=None)
trainer.train(train_data_loader, valid_dataset=valid_data_loader, **cfg.fit_params)
valid_pred = trainer.predict(valid_data_loader, batch_size=cfg.fit_params['batch_size'] * 2) # 3746 * 288
trainer.save_model(model_dir=cfg.model_dir + '/checkpoints/{}_day'.format(cfg.use_model), checkpoint_dir=cfg.checkpoint_dir+'/nn_day_{}.h5'.format(cfg.use_model))
trainer.plot()
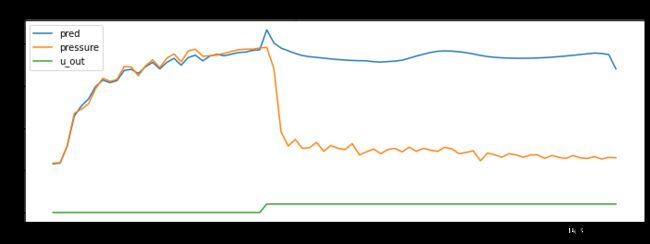
2.6 部署
利用训练过程中生成的二进制模型,可以采用tf-serving或Flask快速部署。
三、未来展望
做时序demo时,可以直接采用pip安装的方式进行,而做比赛的话,由于对精度有更高要求,模型本身可调节地方较多,建议修改源代码并从源码import的方式,例如取得成绩里的seq2seq和bert模型都是采用代码import的方式。
除了时间序列的多步预测任务之外,未来考虑结构不变的情况下,支持更多时序任务,欢迎支持
- 区间预测
- 异常检测
- 分类