第十三章 大数据Hadoop原理应用
13.1 HDFS原理及应用 13.2 MapReduce与Yarn原理及应用
13.1 HDFS原理及应用
分而治之简单介绍
Hadoop(5.x版本比较好)。批转流计算(批量积攒一段时间数据,然后流式处理)
内存寻址(纳秒级)比IO寻址(磁盘毫秒级)快10万倍,差6个0
固态硬盘IO一般 500mb/s, 机械硬盘 几百mb/s. IO是瓶颈
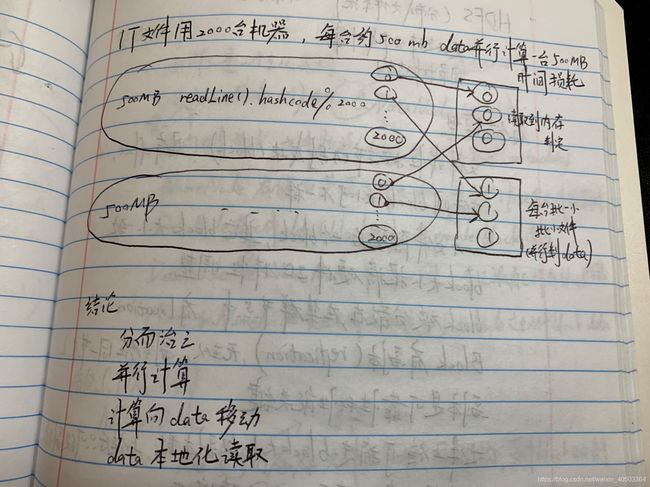
问题:1T文件如何在内存50mb的单机上排序存储文件?
1 Hash Mod三列到200个小文件中(每个文件50mb)。然后每个小文件放到内存排序
2 每个文件之间内部有序,外部无序。每个文件设置一个变量,200个变量中依次取数比较放入新文件(归并排序思想)
 HDFS
HDFS
用来分治的分布式文件系统。
更好的支持分布式计算,目录树结构
HDFS整体介绍,我的笔记都来源于此:储存模型,架构设计,持久化,读写流程等很全面
应用
1 基础设施
安装hadoop,java jdk
下载ssh(可远程登录管理)
可在A服务器下输入B服务器账号密码,然后在A服务器下操作B服务器
ssh设免秘钥
设host IP地址映射,关闭防火墙,不同系统之间时间同步
设置主机名称 HOSTNAME=node1
设置IP
2 部署配置
1 hadoop配置,创建文件夹并解压
2 vi/etc/profile配置环境变量
export JAVA_HOME=...
export HADOOP_HOME=...
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin(hadoop有两个bin)
3 source/etc/profile(加载配置文件)
4 配置hadoop角色
a cd $HADOOP_HOME/etc/hadoop
b vi hadoop_env.sh -> export JAVA_HOME=/user/java/default
(跨系统取不到对方JAVA_HOME,也就无法运行代码,直接再这里本地暴露自己JAVA_HOME)
c vi core-site.xml 定义NameNode在哪里 如hdfs:node1:9000 (ip:port)
d vi halfs-site.xml 配置副本数量,NameNode数据和DataNode数据放哪个目录。HA模式下,配置JournalNode。非HA模式下,配置SSN在这里
e vi slaves 配置DataNode在哪里启动
5 初始化启动
格式化数据,基本仅一次。
-start-dfs.sh 读取我们配置文件并启动
HA模式
高可用,多个NameNode,主备切换
多个NN如何数据同步?-- 哎又是Zookeeper啊
1 树节点强锁(临时节点)
2 事件机制-> watch监控 callback回调
3 临时节点
多台NN分Active状态和StandBy状态。Active对外服务。增加JournalNode角色(大于3台)负责同步NN editlog(最终一致)。增加Zookeeper(与NN同台)负责NN主从选举和切换,DN同时向NN们回报block清单。
HA中无SNN角色(一段时间),由StandBy代替(实时的)
集群
应用搭建:HA依赖ZK,搭建ZK集群。修改hadoop配置文件并集群同步
初始化启动
1 启动JournalNode
2 选一个NN格式化,仅一次
3 启动这个NN以备另一台同步
4 另一台机器中:hdfs namenode_bootstrapStandby 同步
5 格式化ZK,仅一次
6 start_dfs.sh启动
使用
权限
hdfs是一个文件系统,类似unix,linux
有用户权限概念,有超级用户概念
权限hdfs来自namenode自己控制
默认hdfs依赖操作系统上用户和组
HDFS API
windows下
环境变量配置HADOOP_USER_NAME
maven加入依赖
eclipse下
配置类Resource下有core-site.xml/hdfs-site.xml
public Configuartion conf = new Configuration(true)//调用配置类信息
public FileSystem fs = FileSystem.get(conf);
Path dir = new Path("xxx");
if(fs.exists(dir)){
fs.delete(dir,true);
}
fk.mkdirs(dir);
fs = FileSystem.get(URL.create("xxx"),conf,"user") // 拿文件,user为用户
上传文件
BufferInputStream input = new ~(xxx.txt);
Path outfile = new Path(xxx);
FSDataOutputStream output = fc.create(outfile);
IOUtils.copyBytes(input,output,conf,true);
下载文件
Path file = new ~;
FileStatus fss = fs.getFileStatus(file);
BlockLocation [] blks = fc.getFileBlockLocations(fss,0,fss.getLen()); //0偏移量,fss.getLen()返回fss所有block数据
for(BlockLocation b:bks){
System.out.println(b);
}
FSDataInputStream in = fs.open(file);
in.seek(123456);//根据偏移量只读自己需要的数据,同时数据从距离近的DataNode上读
13.2 MapReduce与Yarn原理及应用
Map:映射 ,变换,过滤。 1进n出
Reduce:分解,缩小,归纳
key value:key划分数据分组(group),group不可拆分
data经过map到中间数据集,经过reduce最终result集
简单流程图
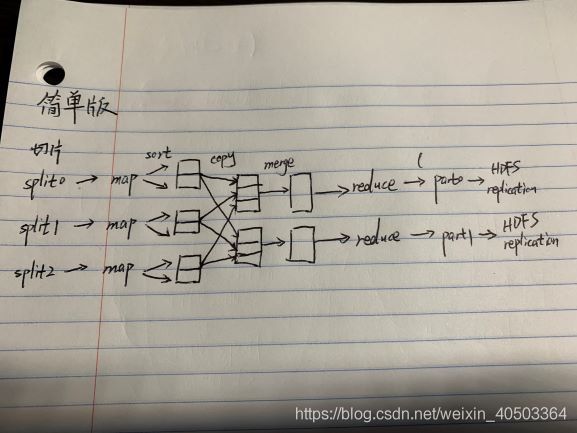
一个切片约为一个block块。block为物理切分,split切片为逻辑切分。加入逻辑切分用来解耦
map并行数量由切片决定,只有map部分1对1,一个切片对应一个map。
reduce并行度由人决定
详细流程图
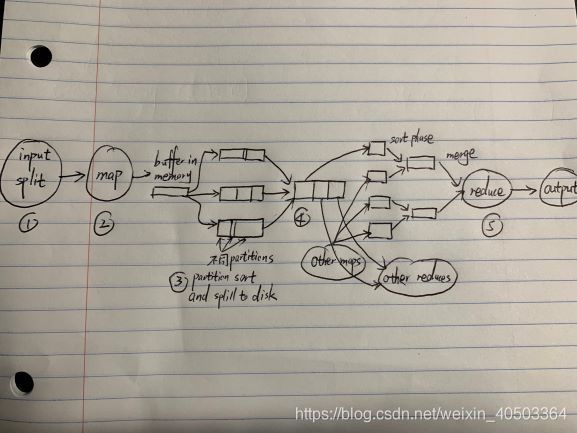
序号1 切片会格式化出记录,以记录为单位调用map方法
序号2 map输出kv映射(kv参与分区计算,拿k计算出 kvp (partition分区号))放入内存中
map任务输出是一个文件,保存在本地系统中
序号3 在内存中分区有序的排序,减少后面排序压力。
序号4 当内存写满则批量数据写入磁盘,并进行二次排序,分区内有序。批量是为了减少操作系统上下文开销
序号5 reduce归并排序和reduce方法计算同时发生,尽量减少IO开销
有批量计算中非常好的迭代器模式支持
具体Map_Reduce例子

总结
HDFS
储存模型:切块;散列->分治
目的:分布式计算
实现:角色NN,DN
重点:读写流程
MapReduce
计算模型(批量计算)
2阶段
map:单条记录加工处理
reduce:多条记录加工处理
实现
JobTracker (做决策)
TaskTracker
Client
角色实现具体流程
Client:会根据每次计算数据查询NameNode元数据block计算出切片,做出规划得到切片清单。最后真正数据放哪还是JobTracker决策
JobTracker:
1 启动后从HDFS中读取split切片清单
2 根据自己收到的TaskTracker(有心跳)回报资源,最终确定每一个切片对应的map去哪个节点(确定最终清单)
3 TaskTracker心跳时取回分配给自己任务信心执行
TaskTracker (在DataNode下)
1 心跳取到任务
2 从HDFS下载jar.xml等到本机
3 最终启动任务描述中的map和reduce任务
代码从某一个节点启动,通过客户端上传初步决策,JobTracker最终决策,TaskTracker下载执行计算
问题
JobTracker
1 单点故障
2 压力过大
3 集成资源管理任务调度,未来新计算框架不能复用资源管理(互相不能感知,资源争抢,如2个隔离JobTracker就无法调度)
Yarn诞生了,解决了所有这些问题
Yarn
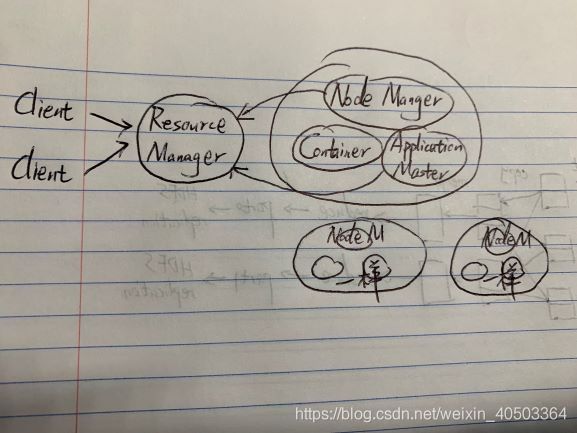
跳过一大段复杂具体细节,直接简单总结
每个节点都有一个Application Master(有资源调度能力,但是没有资源管理能力)。
Resource Manager选出一个Application Master帮他分析用哪个container执行
然后RM来具体要求container从HDFS下载jar.xml并启动map reduce任务
Resource Manager是主节点,NodeManager从节点,NodeManager包含Container和Application master
TaskTracker类似container,JobTracker类似Application master,然后Resource Manager统顾所有
Resource Manager主从则需要用Zookeeper。Yarn会RM进程中加入HA,Zookeeper自动连接不用再配置
Yarn和HDFS互相独立不冲突。
Yarn搭建
mapred-site.xml配置yarn,表示要用yarn而不是单机
yarn-site.xml配置
nodemanager
mapreduce_shuffle
配置ResourceManager设成true,Zookeeper,集群id和集群物理映射
start-yarn.sh启动yarn
测试wordcount(cd到mapreduce目录下)
jar hadoop xx.jar wordcount 输入path 输出path
Eclipse下
写代码表面类似单机运行,底层分布式运行
resource下配置mapred-site.xml/yarn-site.xml
~WordCount~{
Configuration conf = new Configuration(true);
Job job = Job.getInstance(conf);
job.setJarByClass(WordCount.class);
//输入文件路径 job.setInputPath();
//输出文件路径 job.setOutputPath();
Path infile = new Path(~由参数动态写入) //现在使用方法
TestInputFormat.addInputPath(job.infile);
Path outfile = new Path(~由参数动态写入)
TestInputFormat.addOutputPath(job.outfile);
job.setMapperClass(mapper.class);//map逻辑
job.setMapOutputKeyClass(Text.class); //告诉map key是什么类型
job.setReduceClass(reduce.class);//reduce逻辑
job.waitForCompletion(true);
}
实现map.class和reduce.class逻辑
public class mapper extends Mapper<Object,Text,Text,IntWritable>{
//hadoop有一套自己的序列化,反序列化
//也可以自己开发序列化,反序列化
private Text word = new Text();
public void map(Object key, Text value,Context context){
//Object key每一行字符串第一个字节面向源文件的偏移量
//Text value真正字符串
//写入map业务逻辑,通过前面具体Map_Reduce例子笔记图
}
}
public class reduce extends Reducer~{
~
~reduce~{
//写入reduce业务逻辑,通过前面具体Map_Reduce例子笔记图
}
}