Hadoop学习笔记: 分布式数据库 HBase
HBase概述
HBase是一个构建在HDFS上的分布式列存储系统,是Apache Hadoop生态系统中的重要一员,主要用于海量结构化数据存储。HBase是Google Bigtable的开源实现,从逻辑上讲,HBase将数据按照表、行和列进行存储,它是一个分布式的、稀疏的、持久化存储的多维度排序表。Hbase会把数据写到HDFS文件系统中。
HBase具有以下特点:1)良好的扩展性;2)读和写的强一致性;3)高可靠性,任何一个节点挂掉,都不会影响读写;4)与MapReduce良好的集成。
HBase VS HDFS:1)HDFS适合批处理场景;2)HDFS不支持数据随机查找;3)HDFS不支持数据更新。
HBase VS Hive:1)Hive适合批处理数据分析场景;2)Hive不适合实时的数据访问。
HBase应用在360搜索的网页库、淘宝的商品库和淘宝数据魔方的交易信息。
HBase数据模型
HBase由 (Table, RowKey, Family, Qualifer, TimeStamp)确定Value。在HBase中,一行数据由行健(RowKey)作为键,包含多个列族 (Family),列族是由具有同时访问特性的多个列(Qualifer)组成的。数据是可以具有多版本的,由时间戳(TimeStamp)索引。时间戳和列的值绑定,如果一行所有的列都没有值,就不会有时间戳。
行键是主键,它是数据行在表中的唯一标识,表中的数据按照行键排序,所有操作都是基于主键的。表是稀疏的,空值不被存储,一行有可能会有几百万列,但是只有几十列有数据。每行都有一个可排序的主键和任意多的列,列可以根据需要动态的增加,同一张表中不同的行可以有截然不同的列。在HBase中只需要定义到列组,列组提前创建好后,列可以在写数据的时候动态的增加,理论上可以有无穷多列。
 RowKey:row1
RowKey:row1
Family:data
Qualifer:name
TimeStamp:t3
Value:lars
HBase数据模型具有以下特点:
1)大:一个表可以有数十亿行,上百万列,可以达到PB级;
2)面向列:面向列(族)的存储,列(族)独立检索;
3)稀疏:对于空(null)的列,并不占用存储空间,表可以设计的非常稀疏;
4)数据多版本:每个单元中的数据可以有多个版本,由时间戳实现;
5)数据类型单一:HBase中的数据都是字节型,没有其他类型,数据读出时由用户做类型转换成他们想要的类型。RowKey的排序也是按照字节排序。
行存储与列存储区别:
1)行存储数据是按行存储,没有索引的查询使用大量I/O,建立索引和物化视图需要花费大量时间和资源,行存更容易定位到一行数据,所以比较适合对事物的处理,面向查询的需求,数据库必须被大量膨胀才能满足性能要求;
2)列存储数据是按列存储,每一列单独存放,数据即是索引,当访问要查询的列时,可以大量降低系统I/O。数据类型一致,数据特征相似,可以高效压缩。每一列由一个线索来处理,支持查询的并发处理。列存更容易将所有相同的数据统计到一起,所以比较适合数据分析,一般分析的维度没有那么多,而又需要统计所有行的信息的时候,比较适合用列存,列存不容易定位一行数据。
HBase物理模型
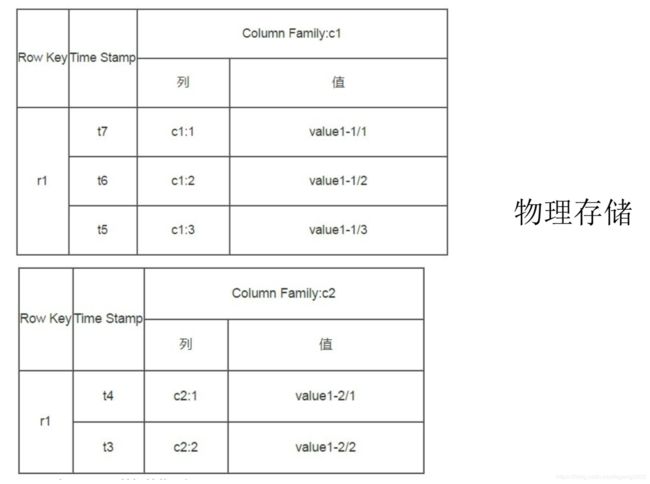
HBase面向列组存储。
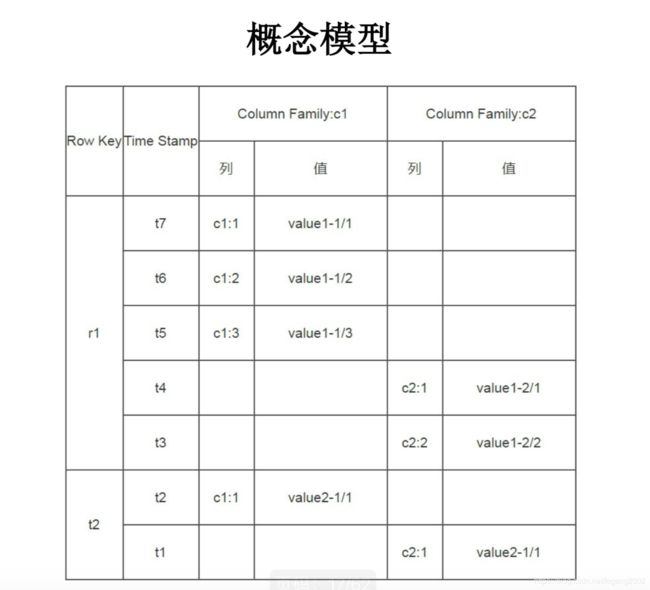
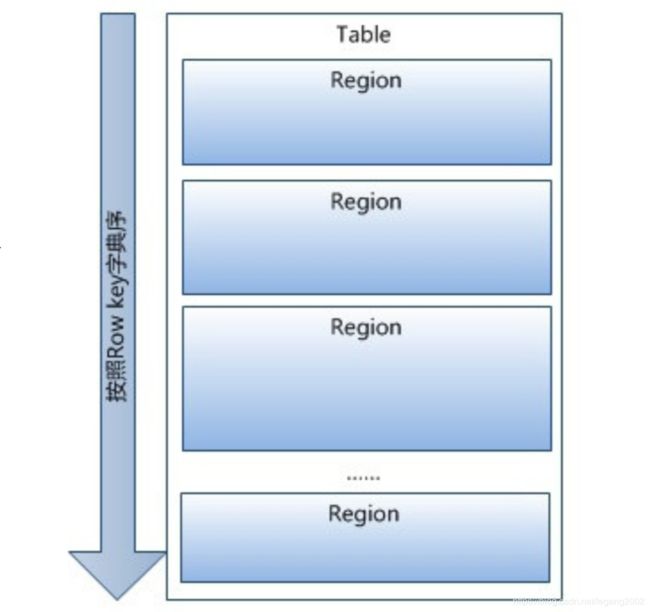
 Table中的所有行都按照RowKey的字典序排列,Table 在行的方向上分割为多个Region。某个Region会包含某一个或几个RowKey,一个Region类似于一个行分组。行本身不可以按照列再划分Region,一个Region一般是1G-100G,如果一行的数据大于100G,那说明组织有问题。一行不能分为不同的Region。一个Region放到HDFS上会被再切分成128M的Block来存储。HBase对Table的切分,以及HDFS对Block的切分由内部处理机制完成,对外暴露的都是数据库表和文件。
Table中的所有行都按照RowKey的字典序排列,Table 在行的方向上分割为多个Region。某个Region会包含某一个或几个RowKey,一个Region类似于一个行分组。行本身不可以按照列再划分Region,一个Region一般是1G-100G,如果一行的数据大于100G,那说明组织有问题。一行不能分为不同的Region。一个Region放到HDFS上会被再切分成128M的Block来存储。HBase对Table的切分,以及HDFS对Block的切分由内部处理机制完成,对外暴露的都是数据库表和文件。
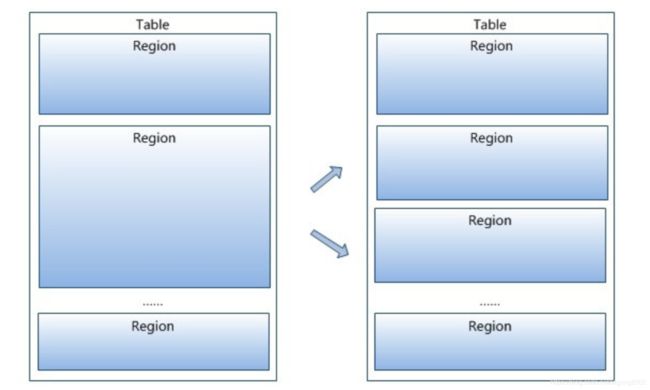
 Region按大小分割的,每个表开始只有一个Region,随着数据增多Region不断增大,当增大到一个阀值的时候,Region就会等分为两个新的Region,之后会有越来越多的Region。也可以在建立Table的时候就建立多个Region。
Region按大小分割的,每个表开始只有一个Region,随着数据增多Region不断增大,当增大到一个阀值的时候,Region就会等分为两个新的Region,之后会有越来越多的Region。也可以在建立Table的时候就建立多个Region。
 HBase把Table分割成不同的Region,再把Region随机分配到不同的机器(Region Server)上来实现分布式。Region是HBase中分布式存储和负载均衡的最小单元,不同Region分布到不同Region Server上。
HBase把Table分割成不同的Region,再把Region随机分配到不同的机器(Region Server)上来实现分布式。Region是HBase中分布式存储和负载均衡的最小单元,不同Region分布到不同Region Server上。
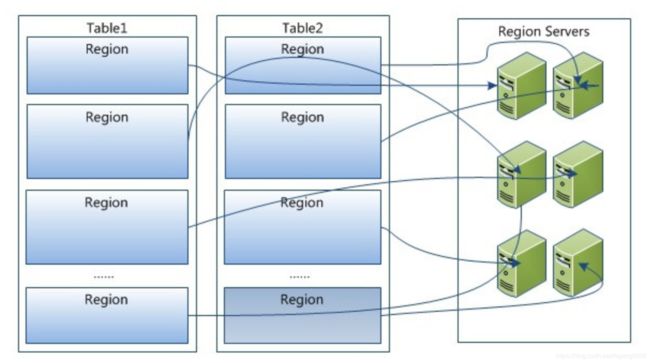 Region虽然是分布式存储的最小单元,但并不是存储的最小单元。Region由一个或者多个Store组成,每个Store保存一个Columns Family;每个Store又由一个MemStore和0至多个StoreFile组成,MemStore存储在内存中,StoreFile存储在HDFS上。HBase写操作是先写到内存的MemStore中,在内存写到一定程度比如到128M或256M后再作为一个文件写入到磁盘中形成StoreFile,每个文件一次写入。
Region虽然是分布式存储的最小单元,但并不是存储的最小单元。Region由一个或者多个Store组成,每个Store保存一个Columns Family;每个Store又由一个MemStore和0至多个StoreFile组成,MemStore存储在内存中,StoreFile存储在HDFS上。HBase写操作是先写到内存的MemStore中,在内存写到一定程度比如到128M或256M后再作为一个文件写入到磁盘中形成StoreFile,每个文件一次写入。
HBase架构
-
HRegion
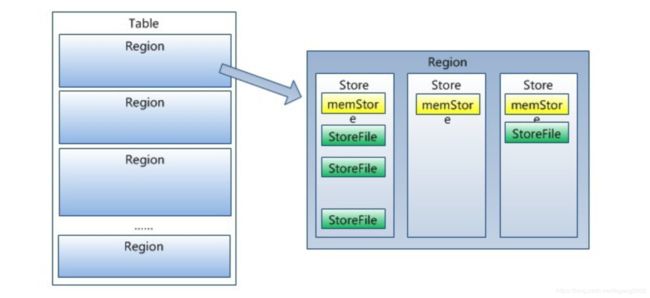
HBase 会自动地将表划分为不同的区域HRegion,每个HRegion包含所有行的一个子集。对用户来说,每个表是一堆数据的集合,靠主键RowKey来区分。从物理上来说,一张表被拆分成了多块,每一块是一个HRegion,HBase用表名+ 开始和结束主键,来区分每一个HRegion。一个 HRegion 会保存一个表里面某段连续的数据,从开始主键到结束主键。一张完整的表格是保存在多个HRegion上面。HRegion也是三副本存在HDFS上,所以它也是HA。 -
HRegionServer
HBase所有的数据库数据都保存在HDFS上面,用户通过访问HRegionServer获取这些数据,一台机器上面一般只运行一个HRegionServer,一个HRegionServer上面部署了多个HRegion,一个HRegion 也只会被一个 HRegionServer维护。HRegionServer主要负责响应用户I/O请求,从HDFS读写数据,是 HBase中最核心的模块,HRegionServer内部管理了一系列HRegion对象,每个HRegion对应了Table中的一个Region,HRegion中由多个HStore组成,每个HStore 对应了Table中的一个Column Family的存储,最好将具备共同 IO特性的Column放在一个Column Family中。 -
HMaster
每个HRegionServer都会与HMaster通信,HMaster的主要任务就是给HRegionServer分配HRegion,HMaster指定HRegionServer 要维护哪些HRegion。当一台HRegionServer宕机时,HMaster会把它负责的HRegion标记为未分配,然后再把它们分配到其他HRegionServer中。HMaster有多个,由Zookeeper选举哪些为Active哪些为Standby。
HMaster 没有单点问题,HBase中可以启动多个HMaster,通过 Zookeeper的Master Selection机制保证总有一个Master 运行,HMaster 在功能上主要负责 Table 和 Region 的管理工作:
1)管理用户对 Table 的增、删、改、查操作;
2)管理 HRegion Server 的负载均衡,调整 Region 分布;
3)在 Region Split 后,负责新 Region 的分配;
4)在 HRegion Server 停机后,负责失效 HRegion Server 上的
Regions 迁移。 -
Client
Client负责提交请求。HBase Client使用HBase的RPC机制与HMaster和HRegionServer进行通信:
1)对于管理类操作,Client与HMaster进行RPC;
2)对于数据读写类操作,Client与HRegionServer进行RPC。 -
Zookeeper
Zookeeper负责协调。Zookeeper中存储了Meta表的地址和HMaster的地址,HRegionServer也会把自己以 Ephemeral方式注册到Zookeeper中, 使得HMaster可以随时感知到各个HRegionServer的健康状态。此 外,Zookeeper也避免了HMaster的单点问题,负责Active HMaster的选举。
HBase数据寻址的原理是:
首先,HBase有一个Meta表,表里存储一个HRegion包括的Table的Start Key和End Key,存储在哪个HRegionServer上,这样Table名+HRegion名就可以确定数据以及从哪个HRegionServer取数据。Meta表本身也是HBase的一个表,也可能会被横向切分后放到一个HRegion中,但因为Meta表中存储的数据一般不多,所以大小一般不会超过1G,所以Meta表一般就存在一个HRegion上,Meta表的地址写到Zookeeper中。这样Client就会从Zookeeper中读取Meta表地址,然后再从Meta表中读取RowKey为某个值的数据的存放位置。客户端第一次读完Meta表的元数据后会缓存下来,这样以后再读就可以直接从缓存读了。一旦HRegion所在的HRegsionServer变了,缓存失效,取数据出错,可以更新缓存,继续使用。
HBase数据修改的原理是:
HDFS上的文件是不支持修改的,但HBase是如何实现修改的?事实上HBase没有数据修改,都是新增,通过时间戳来标识哪些是最新的数据,数据读取的时候,HDFS返回最新时间戳的数据,这就实现了数据的修改。默认返回最新时间戳的数据,也可以指定返回哪个或哪几个时间戳的数据。HBase默认保留三个版本(时间戳),多余的会删除,保留的版本数可以配置。HBase会在HDFS上生成很多文件,定期会合并成一个大文件。
数据文件目录结构:Table名+Region名+Column Family名字+文件,所以不同的Table的数据不可能存到一个文件的。
HBase访问方式
-
HBase Shell
HBase的命令行工具,最简单的接口,适合HBase管理使用;
1)启动HBase Shell$ ./bin/hbase shell
2)建表:表名scores,有两个列族:‘grade’和‘course’
> create 'scores', 'grade', 'course'
3)查看HBase中的表
> list
4) 查看表结构
> describe 'scores'
5) put: 写入数据
> put 't1', 'r1', 'c1', 'value', ts1
t1指表名,r1指行键(key),c1指列名,value指值,ts1指数据戳( 一般都省略不设置)。
6)向scores表中插入数据
> put 'scores', 'Tom', 'grade', 5
> put 'scores', 'Tom', 'course:math', 97
> put 'scores', 'Tom', 'course:art', 87
> put 'scores', 'Jim', 'grade', 4
> put 'scores', 'Jim', 'course:math', 68
> put 'scores', 'Jim', 'course:science', 89
7)get: 随机查找数据
>get 't1', 'r1'
>get 't1', 'r1', 'c1'
>get 't1', 'r1', 'c1', 'c2'
>get 't1', 'r1', {COLUMN => 'c1', TIMESTAMP => ts1}
>get 't1', 'r1', {COLUMN => 'c1', TIMERANGE => [ts1, ts2], VERSIONS => 4}
>get 'scores', 'Tom'
> get 'scores', 'Tom', 'grade'
> get 'scores', 'Tom', 'grade', 'course'
8)scan: 范围查找数据
>scan 't1'
>scan 't1', {COLUMNS => 'c1:q1'}
>scan 't1', {COLUMNS => ['c1', 'c2'], LIMIT => 10, STARTROW => 'xyz'}
>scan 't1', {REVERSED => true}
> scan 'scores'
> scan 'scores',{COLUMNS =>'course:math'}
> scan 'scores',{COLUMNS =>'course'}
> scan 'scores',{COLUMNS =>'course', LIMIT => 1, STARTROW => 'Jim'}
9)delete: 删除数据
>delete 't1', 'r1', 'c1', ts1
>delete 'scores', 'Jim', 'course:math'
10)Truncate删除全表数据
> truncate 'scores'
11)alter: 修改表结构
为scores表增加一个family列族,名为profile
> alter 'scores', NAME => 'profile'
删除profile列族
> alter 'scores', NAME => 'profile', METHOD => 'delete'
12)删除表的步骤
先disable Table,然后drop Table
> disable 'scores'
> drop 'scores'
参考链接:
http://hbase.apache.org/book.html#shell_exercises
https://learnhbase.net/2013/03/02/hbase-shell-commands/
-
Native Java API
HBase是用Java语言编写的,支持Java编程是自然的事情,Java API支持CRUD(Create, Read, Update, Delete)操作,并且包含HBase Shell支持的所有功能,甚至更多,并且Java API是访问HBase最快的方式。
Java API程序设计步骤:
1)创建一个Configuration对象,包含各种配置信息;
2)构建一个Connection连接,提供Configuration对象;
3)根据不同的功能来获得相应的角色,管理->Admin,访问数据-> Table;
4)执行相应的操作,如put、get、delete、scan等操作;
5)关闭连接句柄,释放各种资源。
示例代码:
Java API - putpublic static void put_example() { Configuration conf = HBaseConfiguration.create(); conf.set("hbase.zookeeper.quorum", "zookeeper-01.com, zookeeper-02.com, zookeeper-02.com, zookeeper-02.com, zookeeper-02.com"); conf.set("zookeeper.znode.parent", "/hbase_root_dir"); //establish the connection to the cluster. Connection connection = ConnectionFactory.createConnection(conf); //retrieve a handler to the target table Table table = connection.getTable(TableName.valueOf("mytable")); //describe the data Put put = new Put(Bytes.toBytes("row1")); put.addColumn(Bytes.toBytes("f1"), Bytes.toBytes((”q1"), Bytes.toBytes(0)); //send the data table.put(put); //close if (table != null) table.close(); connection.close(); }1)创建一个Configuration对象,包含各种配置信息(Zookeeper地址以及HBase信息在Zookeeper上的目录位置);
2)构建一个Connection连接,封装了客户端到整个集群的连接,用户从Connection中可以得到访问数据的Table对象、管理HBase的Admin对象和定位Region的RegionLocator对象,从线程安全考虑,建立了与Zookeeper的连接,创建成本大, 后续代码可以重用Connection对象;
3)构建Table对象,与HBase的表交流,传入表名;Table table = connection.getTable(TableName.valueOf("mytable"));4)Put对象,构造对象传入行键RowKey,加入需要插入的列值,发送数据;
Put put = new Put(Bytes.toBytes("row1")); put.addColumn(Bytes.toBytes("f1"), Bytes.toBytes((”q1"), Bytes.toBytes(0));//send the data table.put(put);5)关闭连接句柄
Java API - get
public static void get_example() { Configuration conf = HBaseConfiguration.create(); conf.set(“hbase.zookeeper.quorum”, “zookeeper-01.com, zookeeper-02.com, zookeeper-02.com, zookeeper-02.com, zookeeper-02.com”); conf.set(“zookeeper.znode.parent”, “/hbase_root_dir”); //establish the connection to the cluster. Connection connection = ConnectionFactory.createConnection(conf); //retrieve a handler to the target table Table table = connection.getTable(TableName.valueOf(“mytable”)); Get get = new Get(Bytes.toBytes(“row1”)); get.addColumn(Bytes.toBytes(“f1”), Bytes.toBytes(”q1“)); Result result = table.get(get); while (result.advance()) { System.out.println(result.current()); } table.close(); connection.close(); }1)构造get 对象(读取一行数据) ,传入行键RowKey,加入需要访问的列,发送请求,获得Result;
Get get = new Get(Bytes.toBytes(“row1”)); get.addColumn(Bytes.toBytes(“f1”), Bytes.toBytes(”q1“)); Result result = table.get(get);2)遍历结果
while (result.advance()) { System.out.println(result.current()); }Java API - scan
public static void scan_example() { Configuration conf = HBaseConfiguration.create(); conf.set(“hbase.zookeeper.quorum”, “zookeeper-01.com, zookeeper-02.com, zookeeper-02.com, zookeeper-02.com, zookeeper-02.com”); conf.set(“zookeeper.znode.parent”, “/hbase_root_dir”); //establish the connection to the cluster. Connection connection = ConnectionFactory.createConnection(conf); //retrieve a handler to the target table Table table = connection.getTable(TableName.valueOf(“mytable”)); Scan scan = new Scan(); scan.setStartRow(Bytes.toBytes(“row1”)); scan.setStopRow(Bytes.toBytes("row11")); scan.addColumn(Bytes.toBytes(“f1”), Bytes.toBytes(”q1“)); scan.setCaching(100); ResultScanner results = table.getScanner(scan); for (Result result : results) { while (result.advance()) { System.out.println(result.current()); } } table.close(); connection.close(); }创建scan 对象(读取多行数据)
1)设置起始和结束行键RowKey,[start_key, stop_key) ;
2)加入需要访问的列;
3)设置每次返回的结果数量;
4)发送请求,获得ResultScanner句柄。Scan scan = new Scan(); scan.setStartRow(Bytes.toBytes(“row1”)); scan.setStopRow(Bytes.toBytes("row11")); scan.addColumn(Bytes.toBytes(“f1”), Bytes.toBytes(”q1“)); scan.setCaching(100);Java API - delete
public static void delete_example() { Configuration conf = HBaseConfiguration.create(); conf.set(“hbase.zookeeper.quorum”,“zookeeper-01.com, zookeeper-02.com, zookeeper-02.com, zookeeper-02.com, zookeeper-02.com”); conf.set(“zookeeper.znode.parent”, “/hbase_root_dir”);//establish the connection to the cluster. Connection connection = ConnectionFactory.createConnection(conf); //retrieve a handler to the target table Table table = connection.getTable(TableName.valueOf(“mytable”)); Delete delete = new Delete(Bytes.toBytes(“row1”)); delete.addColumn(Bytes.toBytes(TableInformation.FAMILY_NAME_1), Bytes.toBytes(TableInformation.QUALIFIER_NAME_1_1)); table.delete(delete); table.close(); connection.close(); }构造delete 对象
1)构造对象传入行键key
2)加入需要删除的列,删除最新版本的列
3)发送请求Delete delete = new Delete(Bytes.toBytes("row1")); delete.addColumn(Bytes.toBytes(TableInformation.FAMILY_NAME_1), Bytes.toBytes(TableInformation.QUALIFIER_NAME_1_1)); table.delete(delete);4)也可以指定删除的版本
delete.addColumn(Bytes.toBytes(TableInformation.FAMILY_NAME_1), Bytes.toBytes(TableInformation.QUALIFIER_NAME_1_2), 1000000); -
Thrift Gateway
利用Thrift序列化技术,支持C++,PHP,Python等多种语言, 适合其他异构系统在线访问HBase表数据; -
MapReduce
直接使用MapReduce作业处理HBase数据或使用Pig/Hive处理HBase数据。
HBase参考文档
http://abloz.com/hbase/book.html
https://www.oschina.net/p/hbase/