以写Hbase表的方式更新Phoenix索引
第一步
查询出Phoenix表所有的索引以及索引对应的字段。
Phoenix元数据表:system.catalog
Phoenix在执行查询语句:
select TABLE_NAME as INDEX_NAME,COLUMN_NAME
from system.catalog
where DATA_TABLE_NAME='${hbaseTable}'
and INDEX_TYPE is null and COLUMN_NAME!=':ROW'
order by TABLE_NAME,ORDINAL_POSITION
此处:hbaseTable与Phoenix表名一致,是相互对应的。
将查询结果进行处理,得到如下数据,以index_name为key,以index字段为value:
indexFeildMap =
Map(AC_INDEX01 -> List(sale_id, dt),
AC_INDEX02 -> List(object_id, dt),
AC_INDEX05 -> List(loan_id, dt))
第二步
查询出hive源表中,所有的索引字段、rowkey字段,组成DataFrame临时表,此临时表提供给查询生成每个索引对应的hbase表。
所有索引字段和rowkey的查询语句如下:
Select md5(concat(type,loan_id,item_id,date)) as md5Id
,sale_id
,loan_id
,'20220801' as dt
,object_id
from temp.acc_20220801
第三步
遍历如下indexFeildMap,将md5Id(即rowkey,还可以做加盐处理)与各个索引字段,结合在一起,即为“索引对应的hbase表”的rowkey,插入进去,则Phoenix索引更新完毕。
注意:注意:注意:源hbase表的rowkey与索引字段,结合时,不能直接用"\\x00”字符串。
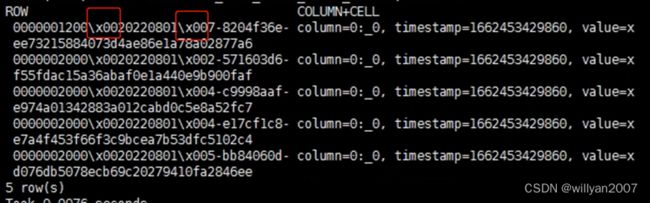
经观察,索引的主键是原表的字段组合而成的,索引表会把所有索引字段+rowkey拼接起来写进Hbase ,做索引的主键为索引表的RowKey。并且组合的时候还要加上\x00这样的字符串。
经观察,索引hbase表,只有rowkey、0:_0两个有效字段,且字段0:_0,值为“x”。
但是直接使用"\\x00”字符串,生产新rowkey时,会出错。
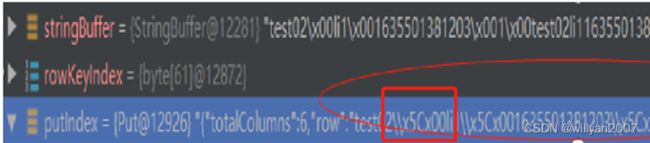
如上图,直接以拼接字符串的形式往里插就可以,但是发现hbase会对\做二进制转译,‘\’会被转译为\x5c。
如上问题怎么解决了?
解决的方案就是:
在插入数据的时候直接以byte[] 的形式往hbase表插。
本例中,先用var rowkeyBtBf: Array[Byte]封装索引的主键,再转成string类型,便于DataFrame临时表做查询。
例如:
AC_INDEX01索引对应的子查询single_sql ==== :
select md5Id,sale_id,dt
from cache_all_index_field
本例用scala代码
val single_df = spark.sql(single_sql)
伪码indexFieldList = List(sale_order_id, dt)
//df转rdd
val singleIndexFieldList = List("md5Id") ++ indexFieldList
val single_index_field_rdd: RDD[Map[String, String]] = single_df.map(row => {
val fields_map = row.getValuesMap[String](singleIndexFieldList)
fields_map
}).rdd因索引字段,是灵活变动的,组成map,再用字段名称去取值。当前map中有md5Id,sale_order_id,dt字段对应的值。
本例:
索引表主键 = sale_order_id +“\\x00” +dt +“\\x00”+加盐操作(md5Id)
注意:注意:注意:字段顺序很重要,索引字段在前(多个索引字段也有顺序,顺序从Phoenix system.catalog表ORDINAL_POSITION字段可以查看到),源hbase表rowkey在后。
转换符
val transformChar: Byte = 0.toByte
val transfromChars: Array[Byte] = Array[Byte](transformChar)
ArrayUtils类
import org.apache.commons.lang.ArrayUtils
val single_index_rdd: RDD[Row] = single_index_field_rdd.map(single_map => {
//生成一个空的Array[Byte],用来装rowkey
var rowkeyBtBf: Array[Byte] = Array.empty[Byte]
for (f <- indexFieldList) {
rowkeyBtBf = ArrayUtils.addAll(rowkeyBtBf, single_map.getOrElse(f, "").getBytes()) //索引字段的内容
rowkeyBtBf = ArrayUtils.addAll(rowkeyBtBf, transfromChars) //加字段隔间转换符
}
val idStr = single_map("md5Id")
val rowkey = getRowkey(idStr, hbaseTable, saltNum) //rowkey加盐处理
rowkeyBtBf = ArrayUtils.addAll(rowkeyBtBf, rowkey.getBytes()) //最后一个不需要再加转换符
rowkeyBtBf
}).map(newrowkey => Row(new String(newrowkey), "x"))
//rdd再转df,Row对象包含两个字段,一个 索引字段+\x00+hbase_rowkey,另一个字段的值为x
//单个索引对应的df
val indexNameDF: DataFrame = spark.createDataFrame(single_index_rdd, getSchema()) //当前schema只有hbaseRowkey _0两个字段
indexNameDF.createOrReplaceTempView(s"cache_${indexName}")val getSql =
s"""
|select hbaseRowkey ,_0
| from cache_${indexName}
|""".stripMargin
val IndexFamilyByte: Array[Byte] = "0".getBytes() //列族
再加上“0”列族,即可保存到hbase索引表中。
完成
方法2,见如下blog
https://blog.csdn.net/qq_35207086/article/details/121141086