Transformers
概述
Transformer 是一种非常流行的架构,它利用和扩展自注意力的概念,为下游任务创建非常有用的输入数据表示。
-
优点:
- 通过上下文嵌入更好地表示我们的输入令牌,其中令牌表示基于使用自我注意的特定相邻令牌。
- 子词标记,而不是字符标记,因为它们可以为我们的许多关键字、前缀、后缀等提供更有意义的表示。
- 参与(并行)我们输入中的所有标记,而不是受到过滤器跨度(CNN)或顺序处理(RNN)的内存问题的限制。
-
缺点:
- 计算密集型
- 需要大量数据(使用预训练模型缓解)

设置
让我们为我们的主要任务设置种子和设备。
import numpy as np
import pandas as pd
import random
import torch
import torch.nn as nnSEED = 1234def set_seeds(seed=1234):
"""Set seeds for reproducibility."""
np.random.seed(seed)
random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed) # multi-GPU
# Set seeds for reproducibility
set_seeds(seed=SEED)# Set device
cuda = True
device = torch.device("cuda" if (
torch.cuda.is_available() and cuda) else "cpu")
torch.set_default_tensor_type("torch.FloatTensor")
if device.type == "cuda":
torch.set_default_tensor_type("torch.cuda.FloatTensor")
print (device)加载数据
我们将下载AG News 数据集Business,该数据集包含来自 4 个独特类别( 、Sci/Tech、Sports、World) 的 120K 文本样本
# Load data
url = "https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/news.csv"
df = pd.read_csv(url, header=0) # load
df = df.sample(frac=1).reset_index(drop=True) # shuffle
df.head()| 标题 | 类别 | |
|---|---|---|
| 0 | 沙龙接受减少加沙军队行动的计划...... | 世界 |
| 1 | 野生动物犯罪斗争中的互联网关键战场 | 科技 |
| 2 | 7 月耐用品订单增长 1.7% | 商业 |
| 3 | 华尔街放缓的迹象越来越多 | 商业 |
| 4 | 真人秀的新面孔 | 世界 |
# Reduce data size (too large to fit in Colab's limited memory)
df = df[:10000]
print (len(df))预处理
我们将首先通过执行诸如下部文本、删除停止(填充)词、使用正则表达式的过滤器等操作来清理我们的输入数据。
import nltk
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer
import renltk.download("stopwords")
STOPWORDS = stopwords.words("english")
print (STOPWORDS[:5])
porter = PorterStemmer()[nltk_data] 正在下载包停用词到 /root/nltk_data...
[nltk_data] 包停用词已经是最新的!
['我','我','我的','我自己','我们']def preprocess(text, stopwords=STOPWORDS):
"""Conditional preprocessing on our text unique to our task."""
# Lower
text = text.lower()
# Remove stopwords
pattern = re.compile(r"\b(" + r"|".join(stopwords) + r")\b\s*")
text = pattern.sub("", text)
# Remove words in parenthesis
text = re.sub(r"\([^)]*\)", "", text)
# Spacing and filters
text = re.sub(r"([-;;.,!?<=>])", r" \1 ", text)
text = re.sub("[^A-Za-z0-9]+", " ", text) # remove non alphanumeric chars
text = re.sub(" +", " ", text) # remove multiple spaces
text = text.strip()
return text# Sample
text = "Great week for the NYSE!"
preprocess(text=text)纽约证券交易所伟大的一周# Apply to dataframe
preprocessed_df = df.copy()
preprocessed_df.title = preprocessed_df.title.apply(preprocess)
print (f"{df.title.values[0]}\n\n{preprocessed_df.title.values[0]}")
沙龙接受减少加沙军队行动的计划,国土报说
沙龙接受减少加沙军队行动的计划 国土报说拆分数据
import collections
from sklearn.model_selection import train_test_split
TRAIN_SIZE = 0.7
VAL_SIZE = 0.15
TEST_SIZE = 0.15def train_val_test_split(X, y, train_size):
"""Split dataset into data splits."""
X_train, X_, y_train, y_ = train_test_split(X, y, train_size=TRAIN_SIZE, stratify=y)
X_val, X_test, y_val, y_test = train_test_split(X_, y_, train_size=0.5, stratify=y_)
return X_train, X_val, X_test, y_train, y_val, y_test
# Data
X = preprocessed_df["title"].values
y = preprocessed_df["category"].values
# Create data splits
X_train, X_val, X_test, y_train, y_val, y_test = train_val_test_split(
X=X, y=y, train_size=TRAIN_SIZE)
print (f"X_train: {X_train.shape}, y_train: {y_train.shape}")
print (f"X_val: {X_val.shape}, y_val: {y_val.shape}")
print (f"X_test: {X_test.shape}, y_test: {y_test.shape}")
print (f"Sample point: {X_train[0]} → {y_train[0]}")
X_train: (7000,), y_train: (7000,)
X_val: (1500,), y_val: (1500,)
X_test: (1500,), y_test: (1500,)
样本点:失去的流感发薪日 → 业务标签编码
接下来,我们将定义 aLabelEncoder将我们的文本标签编码为唯一索引
import itertoolsclass LabelEncoder(object):
"""Label encoder for tag labels."""
def __init__(self, class_to_index={}):
self.class_to_index = class_to_index or {} # mutable defaults ;)
self.index_to_class = {v: k for k, v in self.class_to_index.items()}
self.classes = list(self.class_to_index.keys())
def __len__(self):
return len(self.class_to_index)
def __str__(self):
return f""
def fit(self, y):
classes = np.unique(y)
for i, class_ in enumerate(classes):
self.class_to_index[class_] = i
self.index_to_class = {v: k for k, v in self.class_to_index.items()}
self.classes = list(self.class_to_index.keys())
return self
def encode(self, y):
y_one_hot = np.zeros((len(y), len(self.class_to_index)), dtype=int)
for i, item in enumerate(y):
y_one_hot[i][self.class_to_index[item]] = 1
return y_one_hot
def decode(self, y):
classes = []
for i, item in enumerate(y):
index = np.where(item == 1)[0][0]
classes.append(self.index_to_class[index])
return classes
def save(self, fp):
with open(fp, "w") as fp:
contents = {'class_to_index': self.class_to_index}
json.dump(contents, fp, indent=4, sort_keys=False)
@classmethod
def load(cls, fp):
with open(fp, "r") as fp:
kwargs = json.load(fp=fp)
return cls(**kwargs)
# Encode
label_encoder = LabelEncoder()
label_encoder.fit(y_train)
NUM_CLASSES = len(label_encoder)
label_encoder.class_to_index{“商业”:0,“科技”:1,“体育”:2,“世界”:3}# Class weights
counts = np.bincount([label_encoder.class_to_index[class_] for class_ in y_train])
class_weights = {i: 1.0/count for i, count in enumerate(counts)}
print (f"counts: {counts}\nweights: {class_weights}")
计数:[1746 1723 1725 1806]
权重:{0: 0.000572737686139748, 1: 0.0005803830528148578, 2: 0.00057971# Convert labels to tokens
print (f"y_train[0]: {y_train[0]}")
y_train = label_encoder.encode(y_train)
y_val = label_encoder.encode(y_val)
y_test = label_encoder.encode(y_test)
print (f"y_train[0]: {y_train[0]}")
print (f"decode([y_train[0]]): {label_encoder.decode([y_train[0]])}")y_train[0]:业务
y_train[0]:[1 0 0 0]
解码([y_train[0]]):['业务']分词器
我们将使用BertTokenizer将输入文本标记为子词标记。
from transformers import DistilBertTokenizer
from transformers import BertTokenizer
# Load tokenizer and model
# tokenizer = DistilBertTokenizer.from_pretrained("distilbert-base-uncased")
tokenizer = BertTokenizer.from_pretrained("allenai/scibert_scivocab_uncased")
vocab_size = len(tokenizer)
print (vocab_size)
31090
# Tokenize inputs
encoded_input = tokenizer(X_train.tolist(), return_tensors="pt", padding=True)
X_train_ids = encoded_input["input_ids"]
X_train_masks = encoded_input["attention_mask"]
print (X_train_ids.shape, X_train_masks.shape)
encoded_input = tokenizer(X_val.tolist(), return_tensors="pt", padding=True)
X_val_ids = encoded_input["input_ids"]
X_val_masks = encoded_input["attention_mask"]
print (X_val_ids.shape, X_val_masks.shape)
encoded_input = tokenizer(X_test.tolist(), return_tensors="pt", padding=True)
X_test_ids = encoded_input["input_ids"]
X_test_masks = encoded_input["attention_mask"]
print (X_test_ids.shape, X_test_masks.shape)
# Decode
print (f"{X_train_ids[0]}\n{tokenizer.decode(X_train_ids[0])}")# Sub-word tokens
print (tokenizer.convert_ids_to_tokens(ids=X_train_ids[0]))数据集
我们将创建数据集和数据加载器,以便能够使用我们的数据拆分有效地创建批次。
class TransformerTextDataset(torch.utils.data.Dataset):
def __init__(self, ids, masks, targets):
self.ids = ids
self.masks = masks
self.targets = targets
def __len__(self):
return len(self.targets)
def __str__(self):
return f""
def __getitem__(self, index):
ids = torch.tensor(self.ids[index], dtype=torch.long)
masks = torch.tensor(self.masks[index], dtype=torch.long)
targets = torch.FloatTensor(self.targets[index])
return ids, masks, targets
def create_dataloader(self, batch_size, shuffle=False, drop_last=False):
return torch.utils.data.DataLoader(
dataset=self,
batch_size=batch_size,
shuffle=shuffle,
drop_last=drop_last,
pin_memory=False)
# Create datasets
train_dataset = TransformerTextDataset(ids=X_train_ids, masks=X_train_masks, targets=y_train)
val_dataset = TransformerTextDataset(ids=X_val_ids, masks=X_val_masks, targets=y_val)
test_dataset = TransformerTextDataset(ids=X_test_ids, masks=X_test_masks, targets=y_test)
print ("Data splits:\n"
f" Train dataset:{train_dataset.__str__()}\n"
f" Val dataset: {val_dataset.__str__()}\n"
f" Test dataset: {test_dataset.__str__()}\n"
"Sample point:\n"
f" ids: {train_dataset[0][0]}\n"
f" masks: {train_dataset[0][1]}\n"
f" targets: {train_dataset[0][2]}")
# Create dataloaders
batch_size = 128
train_dataloader = train_dataset.create_dataloader(
batch_size=batch_size)
val_dataloader = val_dataset.create_dataloader(
batch_size=batch_size)
test_dataloader = test_dataset.create_dataloader(
batch_size=batch_size)
batch = next(iter(train_dataloader))
print ("Sample batch:\n"
f" ids: {batch[0].size()}\n"
f" masks: {batch[1].size()}\n"
f" targets: {batch[2].size()}")
培训
让我们创建一个Trainer类,我们将使用它来促进我们的实验训练。
import torch.nn.functional as Fclass Trainer(object):
def __init__(self, model, device, loss_fn=None, optimizer=None, scheduler=None):
# Set params
self.model = model
self.device = device
self.loss_fn = loss_fn
self.optimizer = optimizer
self.scheduler = scheduler
def train_step(self, dataloader):
"""Train step."""
# Set model to train mode
self.model.train()
loss = 0.0
# Iterate over train batches
for i, batch in enumerate(dataloader):
# Step
batch = [item.to(self.device) for item in batch] # Set device
inputs, targets = batch[:-1], batch[-1]
self.optimizer.zero_grad() # Reset gradients
z = self.model(inputs) # Forward pass
J = self.loss_fn(z, targets) # Define loss
J.backward() # Backward pass
self.optimizer.step() # Update weights
# Cumulative Metrics
loss += (J.detach().item() - loss) / (i + 1)
return loss
def eval_step(self, dataloader):
"""Validation or test step."""
# Set model to eval mode
self.model.eval()
loss = 0.0
y_trues, y_probs = [], []
# Iterate over val batches
with torch.inference_mode():
for i, batch in enumerate(dataloader):
# Step
batch = [item.to(self.device) for item in batch] # Set device
inputs, y_true = batch[:-1], batch[-1]
z = self.model(inputs) # Forward pass
J = self.loss_fn(z, y_true).item()
# Cumulative Metrics
loss += (J - loss) / (i + 1)
# Store outputs
y_prob = F.softmax(z).cpu().numpy()
y_probs.extend(y_prob)
y_trues.extend(y_true.cpu().numpy())
return loss, np.vstack(y_trues), np.vstack(y_probs)
def predict_step(self, dataloader):
"""Prediction step."""
# Set model to eval mode
self.model.eval()
y_probs = []
# Iterate over val batches
with torch.inference_mode():
for i, batch in enumerate(dataloader):
# Forward pass w/ inputs
inputs, targets = batch[:-1], batch[-1]
z = self.model(inputs)
# Store outputs
y_prob = F.softmax(z).cpu().numpy()
y_probs.extend(y_prob)
return np.vstack(y_probs)
def train(self, num_epochs, patience, train_dataloader, val_dataloader):
best_val_loss = np.inf
for epoch in range(num_epochs):
# Steps
train_loss = self.train_step(dataloader=train_dataloader)
val_loss, _, _ = self.eval_step(dataloader=val_dataloader)
self.scheduler.step(val_loss)
# Early stopping
if val_loss < best_val_loss:
best_val_loss = val_loss
best_model = self.model
_patience = patience # reset _patience
else:
_patience -= 1
if not _patience: # 0
print("Stopping early!")
break
# Logging
print(
f"Epoch: {epoch+1} | "
f"train_loss: {train_loss:.5f}, "
f"val_loss: {val_loss:.5f}, "
f"lr: {self.optimizer.param_groups[0]['lr']:.2E}, "
f"_patience: {_patience}"
)
return best_model
变压器
我们将首先了解 Transformer 架构中的独特组件,然后为我们的文本分类任务实现一个。
缩放点积注意力
最流行的自我关注类型是来自被广泛引用的Attention is all you need paper 的缩放点积注意力。这种类型的注意力涉及将我们编码的输入序列投影到三个矩阵上,查询(Q)、键(K)和值(V),我们学习它们的权重。
多头注意力
除了在整个编码输入中仅应用一次自我注意之外,我们还可以分离输入并将自我注意并行(头)应用到每个输入部分并将它们连接起来。这允许不同的头部学习独特的表示,同时保持复杂性,因为我们将输入分成更小的子空间。
位置编码
通过 self-attention,我们无法解释输入标记的顺序位置。为了解决这个问题,我们可以使用位置编码来创建每个标记相对于整个序列的位置的表示。这可以学习(使用权重),或者我们可以使用可以更好地扩展的固定函数来创建在推理期间未观察到的长度的位置编码.
这有效地允许我们使用非常大的序列的固定函数来表示每个标记的相对位置。而且因为我们已经将位置编码限制为与我们的编码输入具有相同的维度,所以我们可以简单地将它们连接起来,然后再将它们输入到多头注意力头中。
建筑学
这就是这一切如何结合在一起的!它是一种端到端架构,可创建这些上下文表示并使用编码器-解码器架构来预测结果(一对一、多对一、多对多等)。在该架构中,它们需要大量数据进行训练而不会过度拟合,但是,它们可以用作预训练模型来微调类似于最初训练的较大数据集的较小数据集。

我们不会从头开始实现 Transformer,但我们将在基线课程中使用Hugging Face 库来实现!
模型
我们将使用预训练的BertModel作为特征提取器。我们只会使用编码器来接收顺序和池化的输出(is_decoder=False默认)。
from transformers import BertModel# transformer = BertModel.from_pretrained("distilbert-base-uncased")
# embedding_dim = transformer.config.dim
transformer = BertModel.from_pretrained("allenai/scibert_scivocab_uncased")
embedding_dim = transformer.config.hidden_sizeclass Transformer(nn.Module):
def __init__(self, transformer, dropout_p, embedding_dim, num_classes):
super(Transformer, self).__init__()
self.transformer = transformer
self.dropout = torch.nn.Dropout(dropout_p)
self.fc1 = torch.nn.Linear(embedding_dim, num_classes)
def forward(self, inputs):
ids, masks = inputs
seq, pool = self.transformer(input_ids=ids, attention_mask=masks)
z = self.dropout(pool)
z = self.fc1(z)
return z
我们决定使用池化输出,但我们可以同样轻松地使用顺序输出(每个子令牌的编码器表示)并在其上应用 CNN(或其他解码器选项)。
# Initialize model
dropout_p = 0.5
model = Transformer(
transformer=transformer, dropout_p=dropout_p,
embedding_dim=embedding_dim, num_classes=num_classes)
model = model.to(device)
print (model.named_parameters)训练
# Arguments
lr = 1e-4
num_epochs = 10
patience = 10# Define loss
class_weights_tensor = torch.Tensor(np.array(list(class_weights.values())))
loss_fn = nn.BCEWithLogitsLoss(weight=class_weights_tensor)# Define optimizer & scheduler
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
optimizer, mode="min", factor=0.1, patience=5)# Trainer module
trainer = Trainer(
model=model, device=device, loss_fn=loss_fn,
optimizer=optimizer, scheduler=scheduler)评估
import json
from sklearn.metrics import precision_recall_fscore_support
def get_performance(y_true, y_pred, classes):
"""Per-class performance metrics."""
# Performance
performance = {"overall": {}, "class": {}}
# Overall performance
metrics = precision_recall_fscore_support(y_true, y_pred, average="weighted")
performance["overall"]["precision"] = metrics[0]
performance["overall"]["recall"] = metrics[1]
performance["overall"]["f1"] = metrics[2]
performance["overall"]["num_samples"] = np.float64(len(y_true))
# Per-class performance
metrics = precision_recall_fscore_support(y_true, y_pred, average=None)
for i in range(len(classes)):
performance["class"][classes[i]] = {
"precision": metrics[0][i],
"recall": metrics[1][i],
"f1": metrics[2][i],
"num_samples": np.float64(metrics[3][i]),
}
return performance
# Get predictions
test_loss, y_true, y_prob = trainer.eval_step(dataloader=test_dataloader)
y_pred = np.argmax(y_prob, axis=1)# Determine performance
performance = get_performance(
y_true=np.argmax(y_true, axis=1), y_pred=y_pred, classes=label_encoder.classes)
print (json.dumps(performance["overall"], indent=2)){
“精度”:0.8085194951783808,
“召回”:0.8086666666666666,
“f1”:0.8083051845125695,
“num_samples”:1500.0
}# Save artifacts
from pathlib import Path
dir = Path("transformers")
dir.mkdir(parents=True, exist_ok=True)
label_encoder.save(fp=Path(dir, "label_encoder.json"))
torch.save(best_model.state_dict(), Path(dir, "model.pt"))
with open(Path(dir, "performance.json"), "w") as fp:
json.dump(performance, indent=2, sort_keys=False, fp=fp)推理
def get_probability_distribution(y_prob, classes):
"""Create a dict of class probabilities from an array."""
results = {}
for i, class_ in enumerate(classes):
results[class_] = np.float64(y_prob[i])
sorted_results = {k: v for k, v in sorted(
results.items(), key=lambda item: item[1], reverse=True)}
return sorted_results
# Load artifacts
device = torch.device("cpu")
tokenizer = BertTokenizer.from_pretrained("allenai/scibert_scivocab_uncased")
label_encoder = LabelEncoder.load(fp=Path(dir, "label_encoder.json"))
transformer = BertModel.from_pretrained("allenai/scibert_scivocab_uncased")
embedding_dim = transformer.config.hidden_size
model = Transformer(
transformer=transformer, dropout_p=dropout_p,
embedding_dim=embedding_dim, num_classes=num_classes)
model.load_state_dict(torch.load(Path(dir, "model.pt"), map_location=device))
model.to(device);
# Initialize trainer
trainer = Trainer(model=model, device=device)
# Create datasets
train_dataset = TransformerTextDataset(ids=X_train_ids, masks=X_train_masks, targets=y_train)
val_dataset = TransformerTextDataset(ids=X_val_ids, masks=X_val_masks, targets=y_val)
test_dataset = TransformerTextDataset(ids=X_test_ids, masks=X_test_masks, targets=y_test)
print ("Data splits:\n"
f" Train dataset:{train_dataset.__str__()}\n"
f" Val dataset: {val_dataset.__str__()}\n"
f" Test dataset: {test_dataset.__str__()}\n"
"Sample point:\n"
f" ids: {train_dataset[0][0]}\n"
f" masks: {train_dataset[0][1]}\n"
f" targets: {train_dataset[0][2]}")
数据拆分:
训练数据集:
Val 数据集:
测试数据集:
样本点:
ids: tensor([ 102, 6677, 1441, 3982, 17973, 103, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0])
掩码: 张量([1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0])
目标:张量([1., 0., 0., 0.], device="cpu") # Dataloader
text = "The final tennis tournament starts next week."
X = preprocess(text)
encoded_input = tokenizer(X, return_tensors="pt", padding=True).to(torch.device("cpu"))
ids = encoded_input["input_ids"]
masks = encoded_input["attention_mask"]
y_filler = label_encoder.encode([label_encoder.classes[0]]*len(ids))
dataset = TransformerTextDataset(ids=ids, masks=masks, targets=y_filler)
dataloader = dataset.create_dataloader(batch_size=int(batch_size))# Inference
y_prob = trainer.predict_step(dataloader)
y_pred = np.argmax(y_prob, axis=1)
label_encoder.index_to_class[y_pred[0]]运动的# Class distributions
prob_dist = get_probability_distribution(y_prob=y_prob[0], classes=label_encoder.classes)
print (json.dumps(prob_dist, indent=2)){
“体育”:0.9999359846115112,
“世界”:4.0660612285137177e-05,
“科技”:1.1774928680097219e-05,
“商业”:1.1545793313416652e-05
}可解释性
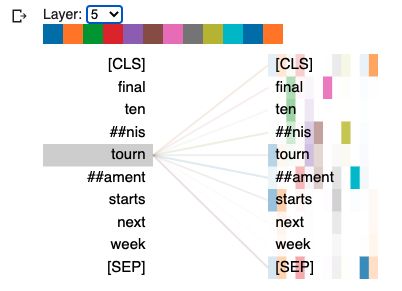
让我们可视化编码器中每个注意力头的自注意力权重。
import sys
!rm -r bertviz_repo
!test -d bertviz_repo || git clone https://github.com/jessevig/bertviz bertviz_repo
if not "bertviz_repo" in sys.path:
sys.path += ["bertviz_repo"]from bertviz import head_view# Print input ids
print (ids)
print (tokenizer.batch_decode(ids))# Get encoder attentions
seq, pool, attn = model.transformer(input_ids=ids, attention_mask=masks, output_attentions=True)
print (len(attn)) # 12 attention layers (heads)
print (attn[0].shape)# HTML set up
def call_html():
import IPython
display(IPython.core.display.HTML('''
'''))
# Visualize self-attention weights
call_html()
tokens = tokenizer.convert_ids_to_tokens(ids[0])
head_view(attention=attn, tokens=tokens)