MySQL主从复制读写分离
目录
准备工作
读写分离原理
配置主从
配置主机MySQL Master
配置从机MySQL Slave
读写分离
案例:
准备工作
Centos7系统:192.168.127.128 xiaoying1 (当主机 Master)
Centos7系统:192.168.127.131 xiaoying2 (当从机 Slave)
在这两台操作系统安装MySQL,建议MySQL版本一致(本案例使用的是MySQL8.X )
读写分离原理
MySQL要做到主从复制,其实依靠的是二进制日志。
举例:假设主服务器叫A,从服务器叫B;主从复制就是B跟着A学,A做什么,B就做什么。那么B怎么同步A的动作呢﹖现在A有一个日志功能,把自己所做的增删改(Insert、Delete、Update)的动作,全都记录在日志中,B只需要拿到这份日志,照着日志上面的动作施加到自己身上就可以了。这样就实现了主从复制。

配置主从
配置主机MySQL Master
1.修改MySQL my.cnf 文件或my.ini
vim /etc/my.cnf[mysqld]
log-bin=mysql-bin #[必须]启用二进制日志
binlog_format=mixed #二进制日志的格式,有三种
server_id=128 #[必须]服务器唯一id,默认是1,一般取ip最后一段
expire-logs-days=10 # [可选]binlog日志保留的天数,清除超过10天的日志 防止日志文件过大,导致磁盘空间不足
2.重启MySQL服务
systemctl restart mysqld 3.在主服务器上为从服务器分配一个账号,就像一把钥匙,从服务器拿着这个钥匙,才能到主服务器来共享主服务器的日志文件。此命令也可以在Navicat中执行
mysql> create user 'slave'@'%' identified by 'Slave123.'; -- 创建用户
mysql> grant REPLICATION SLAVE on *.* to slave@'%' with grant option; -- 授权
# 如果授权出现异常:Access denied; you need (at least one of) the SYSTEM_USER privilege(s) for this operation
mysql> grant system_user on *.* to 'root'; #则先执行给root,SYSTEM_USER权限然后在执行授权
mysql> grant REPLICATION SLAVE on *.* to slave@'%' with grant option; - replication slave:分配的权限
- *.*:可操作的数据库
- 'slave': 用户名
- '%':可以在那台电脑登录
- '1234':密码
4.查看配置状态
mysql> show master status;
配置从机MySQL Slave
1.修改MySQL my.cnf或my.ini
vim /etc/my.cnf[mysqld]
log-bin=mysql-bin #[不是必须]启用二进制日志
binlog-do-db=test #同步的数据库
server_id=131 #服务器唯一id,默认是1,一般取ip最后一段
2.重启MySQL服务
systemctl restart mysqld3.关闭slave(一定要先关闭)
mysql> stop slave4.开始配置
mysql> change master to
master_host='192.168.127.128',
master_user='slave',
master_password='Slave123.',
master_log_file='mysql-bin.000003',
master_log_pos=1135;- master_host:要连接的主服务器ip地址
- master_user:要连接主服务器用户名
- master_password:要连接主服务器密码
- master_log_file:要连接的主服务器的bin日志的日志名称,即配置master第四步可得到该信息
- master_log_pos:要连接的主服务器的bin日志的记录位置,即配置master第四步可得到该信息

5.启动slave同步
mysql> start slave6.检查从服务器复制功能状态
mysql> show slave status;结果如下即成功:
- Slave_IO_Running=Yes
- Slave_SQL_Running=Yes

7.创建一个只读账号
#创建用户用户名:reader 密码:Reader123.
create user 'reader'@'%' identified by 'Reader123.';
#赋予SELECT权限
grant SELECT on *.* to 'reader'@'%' with grant option;
#刷新权限
flush privileges;实验结果:
主服务器(xiaoying1) 中创建 "test" 数据库,再看从服务器(xiaoying2 )也多了个 "test" 数据库

在 xiaoying1中创建表并插入数据、修改数据 ,在xiaoying2已刷新就会发现同步了
不会实现同步的情况:
- 从服务器(xiaoying2)使用root账号,增删改
读写分离
主从复制完成后,还需要实现读写分离,Master负责写入数据,Slave负责读取数据, 本文采用Sharding-JDBC定位为轻量级Java框架实现。
Sharding-JDBC定位为轻量级Java框架,在Java的DBC层提供的额外服务。它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的DBC驱动,完全兼容JDBC和各种ORM框架。使用Sharding-JDBC可以在程序中轻松的实现数据库读写分离。
- 适用于任何基于JDBC的ORM框架,如:JPA,Hibernate,.Mybatis,Spring JDBC Template或直接使用DBC。
- 支持任何第三方的数据库连接池,如:DBCP,C3PO,BoneCP,Druid,HikariCP等。
- 支持任意实现DBC规范的数据库。目前支持MySQL,Oracle,SQLServer,PostgreSQL以及任何遵循SQL92标准的数据库
案例:
主库(Master)用来增删改、从库(Slave)用来查询
1.导入相关依赖
mysql
mysql-connector-java
8.0.24
com.alibaba
druid
1.1.22
com.baomidou
mybatis-plus-boot-starter
3.4.3
org.projectlombok
lombok
org.apache.shardingsphere
sharding-jdbc-spring-boot-starter
4.1.1
org.springframework.boot
spring-boot-starter-web
2.在Master的test数据库创建User表
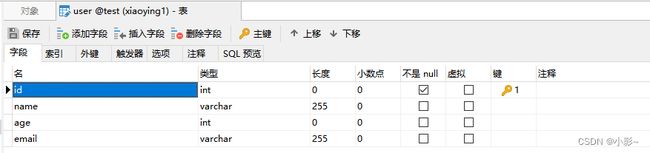
3.创建项目结构:

Mapper、Service、ServiceImpl配置
Mapper:
public interface UserMapper extends BaseMapper {
}
Service:
public interface UserService extends IService {
}
Impl:
@Service
public class UserServiceImpl extends ServiceImpl implements UserService {
} Controller:
/**
* @author 小影
* @create: 2022/9/9 14:05
* @describe:
*/
@RestController
public class UserController {
@Autowired
private DataSource dataSource;
@Autowired
private UserService userService;
/**
* 新增用户
*
* @param user
* @return
*/
@PostMapping
public User save(User user) {
userService.save(user);
return user;
}
/**
* 根据id删除
*
* @param id
*/
@DeleteMapping("/{id}")
public void delete(@PathVariable("id") Long id) {
userService.removeById(id);
}
/**
* 根据id修改用户
*
* @param user
* @return
*/
@PutMapping
public User update(User user) {
userService.updateById(user);
return user;
}
/**
* 根据id查询用户
*
* @param id
* @return
*/
@GetMapping("/{id}")
public User getById(@PathVariable("id") Long id) {
return userService.getById(id);
}
/**
* 条件查询
*
* @param user
* @return
*/
@GetMapping("/list")
public List list(User user) {
QueryWrapper queryWrapper = new QueryWrapper<>();
queryWrapper.eq(user.getId() != null, "id", user.getId());
queryWrapper.eq(user.getName() != null,"name", user.getName());
return userService.list(queryWrapper);
}
} YML:
server:
port: 8080
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
map-underscore-to-camel-case: true
global-config:
db-config:
id-type: ASSIGN_ID
spring:
shardingsphere:
datasource:
names: master,slave01 #因为我就配置了一个从机,多个从机使用逗号隔开 master,slave01,slave02...
# 主数据源Master
master:
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://192.168.127.128:3306/test?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&useSSL=false&allowPublicKeyRetrieval=true
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: 123456
# 从数据源slave
slave01:
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://192.168.127.131:13306/test?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&useSSL=false&allowPublicKeyRetrieval=true
driver-class-name: com.mysql.cj.jdbc.Driver
username: reader
password: Reader123.
masterslave:
# 读写分离设置【负载均衡策略】
load-balance-algorithm-type: round_robin
# 最终的数据源名称
name: dataSource
# 主数据源名称【与上面对应】
master-data-source-name: master
# 从数据源名称【与上面对应】
slave-data-source-names: slave01 #多个从机使用逗号隔开
props:
sql:
show: true # 开启SQL显示,默认false
main:
allow-bean-definition-overriding: true # 允许bean覆盖在配置项中设置允许bean定义覆盖配置项如果不进行设置就会出现启动项目报错,主要的原因是引两个jar包都会创建数据源对象,导致报错,开启bean配置覆盖就可以解决问题了
启动项目控制台输出:
发送请求查看日志或DBug方式查看是谁操作了数据源
测试添加:
查询测试:
缺点:
尽管主从复制、读写分离能很大程度保证MySQL服务的高可用和提高整体性能,但是问题也不少:
- 从机是通过binlog日志从master同步数据的,如果在网络延迟的情况,从机就会出现数据延迟。那么就有可能出现master写入数据后,slave读取数据不一定能马上读出来。
事务问题:

这是小编在开发学习使用和总结的小Demo, 这中间或许也存在着不足,希望可以得到大家的理解和建议。如有侵权联系小编!