Pytorch训练神经网络完整步骤:搭建一个完整的神经网络(以用于Mnist手写数字识别的卷积神经网络为例)
搭建神经网络完整步骤
- 一、搭建流程
- 二、Mnist手写数字识别案例
-
- 1. 导入相关包:如torch、numpy、matplotlib等
- 2. 数据集准备
- 3. 搭建网络架构
- 4. 训练目标:损失函数
- 5. 优化器
- 6. 网络训练
- 7. 保存网络模型
- 三、完整代码
-
- 1. 网络训练完整代码
- 2. 网络测试完整代码
一、搭建流程
- 导入相关包:如torch、numpy、matplotlib等;
- 数据集准备:训练集、测试集;
- 搭建网络架构;
- 训练目标:损失函数
- 优化器
- 网络训练;
- 保存网络模型;
注意:考虑到有时候根据不同需求,我们需要从控制台读取一些参数,此时在项目中涉及到的所有超参数可以通过Python自带的参数解析包argparse来实现,在https://blog.csdn.net/qq_43665602/article/details/126489753这篇文章中我完整的实现过一个简单的生成对抗网络(GAN),其中所有超参数通过Python自带的参数解析包argparse来实现。
二、Mnist手写数字识别案例
1. 导入相关包:如torch、numpy、matplotlib等
import os
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms,datasets
from PIL import Image
import numpy as np
from matplotlib import pyplot as plt
2. 数据集准备
在进行网络搭建之前,我们首先需要准备好网络训练和评估需要的数据集,一般将所有数据按照8:2或7:3的比例划分为训练集和测试集,训练集和测试集要完全互斥,不能有重叠。此外,在准备数据集的时候,我们可以对数据进行一定的预处理,包括归一化、随机旋转、随机裁剪等。当然我们更多的是根据自己的任务需求去自定义数据集,通过继承Dataset类并重写其中的__len__()和__getitem__()方法完成特定数据集制作,https://blog.csdn.net/qq_43665602/article/details/126290600这篇文章中我以输入、输出皆为图像的自定义数据集展示了案例,大家可以进行了解。
transform=transforms.Compose([
transforms.ToTensor(), # 可将PIL类型的图像或者Numpy数组转为Tensor,并将其像素值归一化到[0,1]
])
# 训练集
train_dataset=datasets.MNIST(
root='./dataset',
train=True,
transform=transform,
download=True
)
# 测试集
test_dataset=datasets.MNIST(
root='./dataset',
train=False,
transform=transform,
download=True
)
# 利用DataLoader制作数据迭代器
train_dataloader=DataLoader(
dataset=train_dataset,
batch_size=32,
shuffle=True,
num_workers=0,
drop_last=False
)
test_dataloader=DataLoader(
dataset=test_dataset,
batch_size=32,
shuffle=True,
num_workers=0,
drop_last=False
)
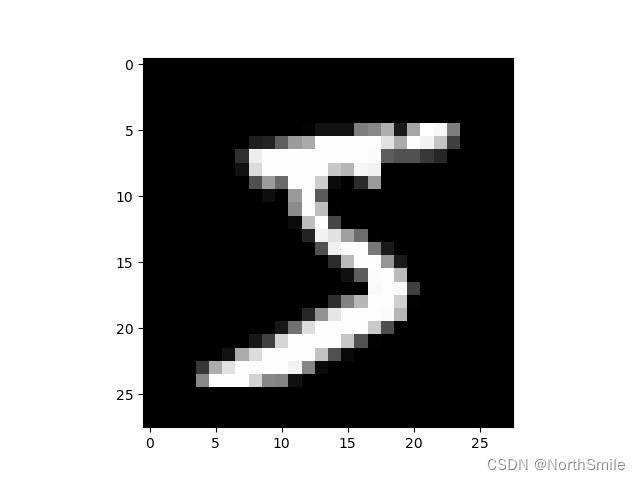
Mnist数据集包含大量形状大小为(1,28,28)的手写数字,在未利用transforms.ToTensor()之前,图像类型是PIL.Image,且像素值范围是[0,255],ToTensor()可以将其转换为Tensor,并将像素值归一化到[0,1],这样有利于加快网络收敛的速度。下图为Mnist数据集中的一个样本:
3. 搭建网络架构
到这里我们就需要根据任务需求进行网络的实体搭建了,这里我搭建一个简单的卷积神经网络(CNN)进行展示,尽量把平常会用到的网络层都使用一下比如卷积层、全连接层、池化层等,大家搭建时更多的还是根据自己设计的神经网络进行代码编写(因为Mnist数据集比较简单,如果使用太复杂的网络容易过拟合,所以这里搭建的网络是一个小模型)。
我们可提前设计好网络,绘制网络结构图,然后进行代码编写。
# 输入数据形状:(32,1,28,28)
class DemoModel(nn.Module):
def __init__(self):
super(DemoModel, self).__init__()
self.model=nn.Sequential(
nn.Conv2d(in_channels=1,out_channels=8,kernel_size=3,padding='same'),
nn.AvgPool2d(kernel_size=2), # (32,8,14,14)
nn.BatchNorm2d(num_features=8),
nn.ReLU(),
nn.Conv2d(in_channels=8, out_channels=16, kernel_size=3, padding='same'),
nn.ReLU(),
nn.Flatten(),
nn.Linear(in_features=14*14*16,out_features=10),
nn.Softmax()
)
def forward(self,x):
return self.model(x)
device=torch.cuda("cuda" if torch.cuda.is_available() else "cpu") # 确定采用cpu还是gpu计算
model=DemoModel()
model=model.to(device) # gpu加速
搭建并确认网络结构是我们期望的结果之后,可通过以下两种方式进行网络结构的查看:
1)使用print直接打印模型结构:
print(model)
DemoModel(
(model): Sequential(
(0): Conv2d(1, 8, kernel_size=(3, 3), stride=(1, 1), padding=same)
(1): AvgPool2d(kernel_size=2, stride=2, padding=0)
(2): BatchNorm2d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): ReLU()
(4): Conv2d(8, 16, kernel_size=(3, 3), stride=(1, 1), padding=same)
(5): ReLU()
(6): Flatten(start_dim=1, end_dim=-1)
(7): Linear(in_features=3136, out_features=10, bias=True)
(8): Softmax(dim=None)
)
)
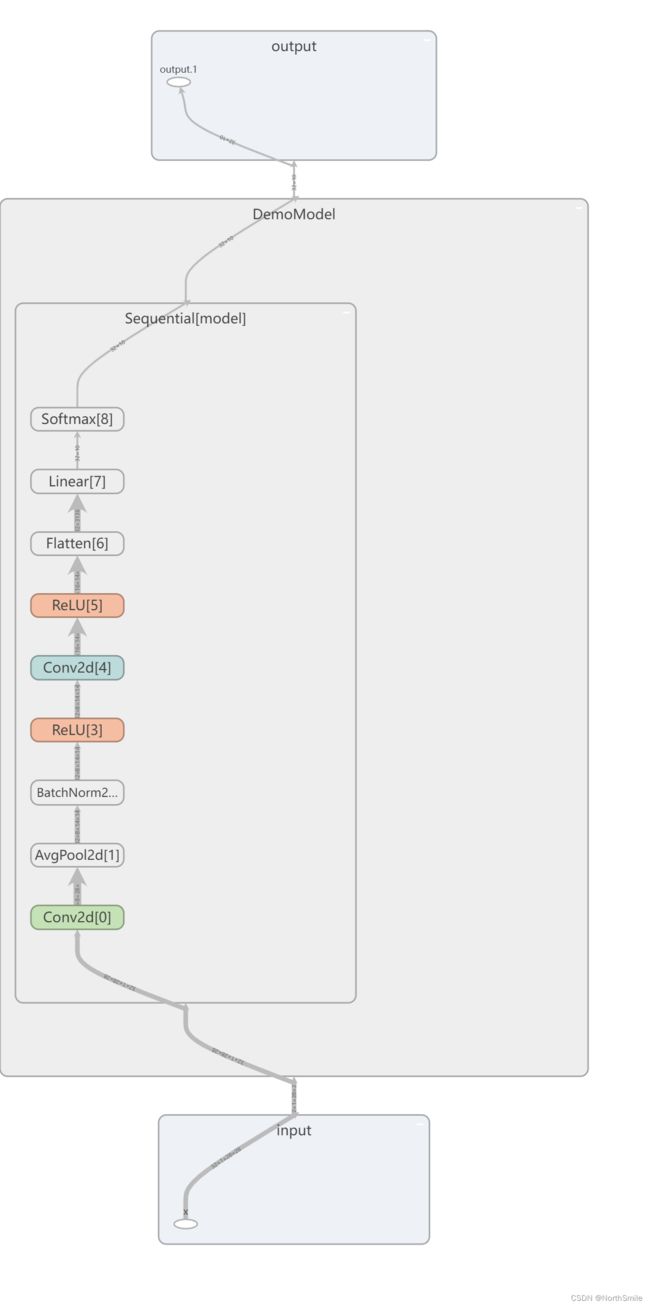
2)利用tensorboard将网络模型结构添加到日志中,并通过浏览器进行查看验证:
writer=SummaryWriter('./logs')
writer.add_graph(model,img)
writer.close()
4. 训练目标:损失函数
在网络进行训练之间我们要提前确定好网络的训练目标,既损失函数,常见损失函数包括L1(MAE)、L2(MSE)以及交叉熵函数等,对于分类任务常用交叉熵函数,更细致地对于二分类任务有2值交叉熵函数,回归任务使用L1、L2函数等。
creation=nn.CrossEntropyLoss() # 损失函数:分类任务常用交叉熵函数,二分类任务可用nn.BCELoss()
creation=creation.to(device)
5. 优化器
在网络进行训练之间除了确定训练目标,我们必须选择适合网络训练的优化器,并对他们的初始参数进行设置,引导网络的优化训练,常见优化器包括SGD、ADAM等,这里我们采用ADAM优化器。此外,在确定优化器时我们可以根据自己的需求对权重衰减和学习率衰减策略进行设置,比如学习率衰减策略我推荐大家尝试一下“余弦退火策略”,这个Pytorch已经内置了,我们调用torch.optim.lr_scheduler.CosineAnnealingLR即可。
learning_rate=1e-2
beta1=0.9
beta2=0.999
optimizer=torch.optim.Adam(model.parameters(),lr=learning_rate,betas=(beta1,beta2)) # 优化器
# lr_scheduler=torch.optim.lr_scheduler.CosineAnnealingLR(optimizer,T_max=32) # 学习率衰减:余弦退火策略
6. 网络训练
到这里所有的准备工作已经完成,我们接下来就需要编写网络训练过程,在这一步骤,我们主要工作是对整个数据集进行迭代训练,每次给网络送入一小批量数据进行学习训练,在每一轮的完整训练过程中,我们通常包括训练步骤以及验证步骤,这是为了更好的观察到网络是否过拟合,以及确定网络何时收敛。在此过程中大家可以根据任务需要打印或记录一些需要的信息,比如训练损失、验证损失、准确率、中间训练结果等指标,以便后期查看。
model_save_path='./models/'
os.makedirs(model_save_path,exist_ok=True)
EPOCHS=50
train_steps=0
test_steps=0
for epoch in range(EPOCHS): # 0-99
print("第{}轮训练过程:".format(epoch+1))
# 训练步骤
model.train() # 训练模式
epoch_train_loss=0.0
for train_batch,(train_image,train_label) in enumerate(train_dataloader):
print("第{}批数据进行训练".format(train_batch+1))
train_image,train_label=train_image.to(device),train_label.to(device) # 将数据送到GPU
train_predictions=model(train_image)
batch_train_loss=creation(train_predictions,train_label)
optimizer.zero_grad() # 梯度清零
batch_train_loss.backward()
optimizer.step()
epoch_train_loss+=batch_train_loss.item()
train_steps+=1
if train_steps%50==0:
print("第{}次训练,训练损失为{}".format(train_steps,batch_train_loss.item()))
# 测试步骤
model.eval()
epoch_test_loss=0.0
epoch_test_acc=0.0
with torch.no_grad():
for test_batch,(test_image,test_label) in enumerate(test_dataloader):
print("第{}批数据进行测试".format(test_batch + 1))
test_image, test_label = test_image.to(device), test_label.to(device)
predictions=model(test_image)
test_loss=creation(predictions,test_label)
epoch_test_loss+=test_loss.item()
test_steps+=1
# 计算每个批次数据测试时的准确率
batch_test_acc=(predictions.argmax(dim=1)==test_label).sum()
epoch_test_acc+=batch_test_acc
if test_steps%50==0:
print("第{}次测试,测试损失为{}".format(test_steps,test_loss.item()))
if (epoch+1)%10==0:
print("第{}轮训练结束,训练损失为{},测试损失为{},测试准确率为{}".format
(epoch+1, epoch_train_loss,epoch_test_loss,epoch_test_acc/len(test_dataset)))
# 7.保存模型
torch.save(model.state_dict(),model_save_path+"model{}.pth".format(epoch+1))
print("训练结束!")
7. 保存网络模型
保存网络模型的方式有两种,我们采用官网推荐的方式,只存储网络参数:
torch.save(model.state_dict(),model_save_path+"model{}.pth".format(epoch+1))
三、完整代码
1. 网络训练完整代码
'''
Mnist手写数字识别:
1. 导入相关包:如torch、numpy、matplotlib等;
2. 数据集准备:训练集、测试集;
3. 搭建网络架构;
4. 训练目标:损失函数
5. 优化器
6. 网络训练;
7. 保存网络模型;
'''
# 1. 导入相关包:如torch、numpy、matplotlib等
import os
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms,datasets
from PIL import Image
import numpy as np
from matplotlib import pyplot as plt
import warnings
warnings.filterwarnings('ignore')
# 2. 数据集准备:训练集、测试集:可在这时进行数据预处理,包括归一化、随机旋转、随机裁剪等
'''
Pytorch自己内置了一些入门数据集:包括Mnist、Cifar10等,直接导入即可
'''
transform=transforms.Compose([
transforms.ToTensor(), # 可将PIL类型的图像或者Numpy数组转为Tensor,并将其像素值归一化到[0,1]
])
# 训练集、测试集
train_dataset=datasets.MNIST(
root='./dataset',
train=True,
transform=transform,
download=True
)
test_dataset=datasets.MNIST(
root='./dataset',
train=False,
transform=transform,
download=True
)
train_dataloader=DataLoader(
dataset=train_dataset,
batch_size=32,
shuffle=True,
num_workers=0,
drop_last=False
)
test_dataloader=DataLoader(
dataset=test_dataset,
batch_size=32,
shuffle=True,
num_workers=0,
drop_last=False
)
# 3.搭建网络架构:输入数据形状:(32,1,28,28)
class DemoModel(nn.Module):
def __init__(self):
super(DemoModel, self).__init__()
self.model=nn.Sequential(
nn.Conv2d(in_channels=1,out_channels=8,kernel_size=3,padding='same'),
nn.AvgPool2d(kernel_size=2), # (32,1,14,14)
nn.BatchNorm2d(num_features=8),
nn.ReLU(),
nn.Conv2d(in_channels=8, out_channels=16, kernel_size=3, padding='same'),
nn.ReLU(),
nn.Flatten(),
nn.Linear(in_features=14*14*16,out_features=10),
nn.Softmax()
)
def forward(self,x):
return self.model(x)
device=torch.device("cuda" if torch.cuda.is_available() else "cpu") # 确定采用cpu还是gpu计算
model=DemoModel()
model=model.to(device) # gpu加速
# img,label=next(iter(train_dataloader))
# # out=model(img)
# # print(out.shape)
# # print(model)
# writer=SummaryWriter('./logs')
# writer.add_graph(model,img)
# writer.close()
# 4.训练目标:损失函数
creation=nn.CrossEntropyLoss() # 损失函数:分类任务常用交叉熵函数,二分类任务可用nn.BCELoss()
creation=creation.to(device)
# 5.优化器
learning_rate=1e-2
beta1=0.9
beta2=0.999
optimizer=torch.optim.Adam(model.parameters(),lr=learning_rate,betas=(beta1,beta2)) # 优化器
lr_scheduler=torch.optim.lr_scheduler.CosineAnnealingLR(optimizer,T_max=32) # 学习率衰减:余弦退火策略
# 6.网络训练
model_save_path='./models/'
os.makedirs(model_save_path,exist_ok=True)
EPOCHS=50
train_steps=0
test_steps=0
for epoch in range(EPOCHS): # 0-99
print("第{}轮训练过程:".format(epoch+1))
# 训练步骤
model.train() # 训练模式
epoch_train_loss=0.0
for train_batch,(train_image,train_label) in enumerate(train_dataloader):
print("第{}批数据进行训练".format(train_batch+1))
train_image,train_label=train_image.to(device),train_label.to(device) # 将数据送到GPU
train_predictions=model(train_image)
batch_train_loss=creation(train_predictions,train_label)
optimizer.zero_grad() # 梯度清零
batch_train_loss.backward()
optimizer.step()
epoch_train_loss+=batch_train_loss.item()
train_steps+=1
if train_steps%50==0:
print("第{}次训练,训练损失为{}".format(train_steps,batch_train_loss.item()))
# 测试步骤
model.eval()
epoch_test_loss=0.0
epoch_test_acc=0.0
with torch.no_grad():
for test_batch,(test_image,test_label) in enumerate(test_dataloader):
print("第{}批数据进行测试".format(test_batch + 1))
test_image, test_label = test_image.to(device), test_label.to(device)
predictions=model(test_image)
test_loss=creation(predictions,test_label)
epoch_test_loss+=test_loss.item()
test_steps+=1
# 计算每个批次数据测试时的准确率
batch_test_acc=(predictions.argmax(dim=1)==test_label).sum()
epoch_test_acc+=batch_test_acc
if test_steps%50==0:
print("第{}次测试,测试损失为{}".format(test_steps,test_loss.item()))
if (epoch+1)%10==0:
print("第{}轮训练结束,训练损失为{},测试损失为{},测试准确率为{}".format
(epoch+1, epoch_train_loss,epoch_test_loss,epoch_test_acc/len(test_dataset)))
# 7.保存模型
torch.save(model.state_dict(),model_save_path+"model{}.pth".format(epoch+1))
print("训练结束!")
训练过程部分记录:

2. 网络测试完整代码
此处需要注意,因为我们保存模型时只保存了网络参数,所以在重新加载网络时,必须提前创建一个相同的网络,然后将参数加载到该网络才可以。在这里我没有对训练过程中的损失函数以及准确率进行可视化,大家可以尝试使用Matplotlib或Tensorboard进行可视化描述,这里不再赘述(个人认为Tensorboard更好操作,毕竟他可以把网络结构也进行可视化)。
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import datasets,transforms
test_dataset=datasets.MNIST(
root='./dataset',
train=False,
transform=transforms.ToTensor(),
download=True
)
test_dataloader=DataLoader(
dataset=test_dataset,
batch_size=32,
shuffle=True,
num_workers=0,
drop_last=False
)
class DemoModel(nn.Module):
def __init__(self):
super(DemoModel, self).__init__()
self.model=nn.Sequential(
nn.Conv2d(in_channels=1,out_channels=8,kernel_size=3,padding='same'),
nn.AvgPool2d(kernel_size=2), # (32,1,14,14)
nn.BatchNorm2d(num_features=8),
nn.ReLU(),
nn.Conv2d(in_channels=8, out_channels=16, kernel_size=3, padding='same'),
nn.ReLU(),
nn.Flatten(),
nn.Linear(in_features=14*14*16,out_features=10),
nn.Softmax()
)
def forward(self,x):
return self.model(x)
device=torch.device("cuda" if torch.cuda.is_available() else "cpu")
model=DemoModel().to(device)
model_save_path='./models/model50.pth'
model.load_state_dict(torch.load(model_save_path))
print(model)
model.eval()
with torch.no_grad():
total_acc=0
for image,label in test_dataloader:
image, label=image.to(device),label.to(device)
predictions=model(image)
acc=(predictions.argmax(dim=1)==label).sum()
total_acc+=acc
print("测试集上准确率:{}".format(total_acc/len(test_dataset)))
整个测试集上的测试结果:这准确率其实不算很高,这里主要目的是将Pytorch搭建整个神经网络以及训练测试的流程进行展示,大家感兴趣可以尝试优化!
