pandas数据处理(一)---常用方法
pandas数据处理
一、数据类型
pandas包含两种数据类型:series和dataframe。
1、dataframe
二维数据结构,表格形式,多行多列
每一列可以实不同的值类型(数值、字符串、布尔值等)
行索引:index; 列名:columns
df.dtypes:查看每列的数据类型
查询一行或者一列:Series df.loc[index]
查询多行多列:DataFrame df.loc[index:index+n]
df = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3', 'K4', 'K5'],
'A': ['A0', 'A1', 'A2', 'A3', 'A4', 'A5']})
df.index:数据的索引
df.columns:数据的列名

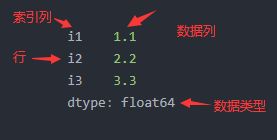
1、 Series
一维数据结构,每一个元素都带有一个索引,与一维数组的含义相似,其中索引可以为数字或字符串。
DataFrame的一行或者一列就是Series类型
df1 = pd.Series([1.1, 2.2, 3.3],index=['i1', 'i2', 'i3'])
二、基本操作
1、读入、保存数据

读取纯文本文件
(1) 读入数据 read_csv
# 以BeiJing PM2.5数据为例
import pandas as pd
file_path = 'pm25_data_2010.1.1-2014.12.31.csv'
data = pd.read_csv(file_path)
print(data.index,data.columns,data.shape)#查看索引 列名 数据形状
print(data)
#输出结果:原数据
No year month day hour pm2.5 ... TEMP PRES cbwd Iws Is Ir
1 2010 1 1 0 NaN ... -11.0 1021.0 0 1.79 0 0
2 2010 1 1 1 NaN ... -12.0 1020.0 0 4.92 0 0
... ... ... ... ... ... ... ... ... ... ... .. ..
43823 2014 12 31 22 8.0 ... -4.0 1034.0 0 246.72 0 0
43824 2014 12 31 23 12.0 ... -3.0 1034.0 0 249.85 0 0
[43824 rows x 12 columns]
(2)读取txt文件
自己指定分隔符sep=“ … … ”和列名names=[… … … ]
data=pd.read_csv(file_path,sep="\t",headr=None,names=['time','a1','a2'])
(3)读取excel文件: read_excel()
data=pd.read_excel(file_path)
(4)读取mySql数据表:read_sql()
该方法有两个参数:
1、sql语句
2、数据库的连接 connection
import pymysql
conn=pymysql.connect(
host='127.0.0.1',
user='root',
password='12345678',
database='test',
charset='utf8')
data=pd.read_sql("select * from tableName",con=conn)
(5)保存数据 to_csv()
new_path = 'pm_new_data.csv'
usedData.to_csv(new_path, index=False)
2、查询数据
- df.loc:根据行、列的标签值查询 — 既能查询,又能覆盖写入,推荐
- df.iloc:根据行列的数字位置查询
- df.where方法
- df.query方法
(1) df.head() :查看前5行
(2) df.tail():查看最后5行
(3) 使用单个label值查询数据
#获得单个值
df.loc["2020-12-29", "a1"]
#获得一个Series:
df.loc["2020-12-29",[ "a1"], "a2"]
(4) 使用值列表批量查询
#获得Series:
df.loc[["2020-12-29", "2020-12-30", "2020-12-31" ],"a1"]
#获得DataFrame:
df.loc[["2020-12-29", "2020-12-30", "2020-12-31" ], ["a1", "a2" ]]
(5) 使用数值区间进行范围查询
区间既包含开始,也包含结束
#行index按区间
df.loc["2018-12-15" : "2018-12-31" , "a1"]
#列index按区间
df.loc["2018-12-31" , "a1" : "a10"]
#行和列都按区间查询
df.loc["2018-12-15" : "2018-12-31", "a1" : "a10"]
(6) 使用条件表达式查询
#简单条件查询 获取列a1数值小于100的所有行
df.loc[ df[" a1"] < 100, :]
#df[" a1"] < 100返回true/false
#复杂条件查询
df.loc[(da[" a1"] < 100) & (df[" a10"] < 10) & (df["a20"] < 5) & (df["a50"] < 1)]
(7) 调用函数查询
#lambda 函数:
df.loc[ lambda df : ( df[" a1"] < = 100 ) & (df["a10"] < 10) , :]
#编写自己的函数
def query_my_data(df):
return df.index.str.startwith("2018-12") & df["a1"] == 1
df.loc[query_my_data, : ]
3、行列操作
(1)交换列的位置
cols = list(data)
cols.pop(cols.index('No')) # pop()方法删除指定列
cols.insert(len(data),cols.pop(cols.index('pm2.5'))) # 将pm2.5插入到最后一列
newData = data.loc[:, cols]
print("pm2.5")
#输出结果:对比原数据,可以看到pm2.5现在被移动到最后一列,其他列依次前移
year month day hour DEWP TEMP PRES cbwd Iws Is Ir pm2.5
2010 1 1 0 -21 -11.0 1021.0 0 1.79 0 0 NaN
2010 1 1 1 -21 -12.0 1020.0 0 4.92 0 0 NaN
2010 1 1 2 -21 -11.0 1019.0 0 6.71 0 0 NaN
... ... ... ... ... ... ... ... ... .. .. ...
2014 12 31 21 -22 -3.0 1034.0 0 242.70 0 0 10.0
2014 12 31 22 -22 -4.0 1034.0 0 246.72 0 0 8.0
2014 12 31 23 -21 -3.0 1034.0 0 249.85 0 0 12.0
[43824 rows x 12 columns]
4、处理缺省值NaN
(1)判断是否存在NaN notnull() isnull()
print(pd.notnull(data)) # pd.isnull(data)
#data["pm2.5"].notnull() 查看单列的NaN值
#输出结果: 可以看到, PM2.5该列显示False的位置存在NaN值
No year month day hour pm2.5 ... TEMP PRES cbwd Iws Is Ir
True True True True True False ... True True True True True True
True True True True True False ... True True True True True True
True True True True True False ... True True True True True True
... ... ... ... ... ... ... ... ... ... ... ... ...
True True True True True True ... True True True True True True
True True True True True True ... True True True True True True
[43824 rows x 12 columns]
(2)删除含有NaN的行/列 dropna()
noNaN = data.dropna(how='any',axis=0, inplace=True)
#axis=0 删除该行 axis=1 删除该列 inplace=True:修改源数据
print(noNaN)
#输出结果:对比原数据,含有NaN的1、2等行均被删除
No year month day hour pm2.5 ... TEMP PRES cbwd Iws Is Ir
25 2010 1 2 0 129.0 ... -4.0 1020.0 3 1.79 0 0
26 2010 1 2 1 148.0 ... -4.0 1020.0 3 2.68 0 0
... ... ... ... ... ... ... ... ... ... ... .. ..
43823 2014 12 31 22 8.0 ... -4.0 1034.0 0 246.72 0 0
43824 2014 12 31 23 12.0 ... -3.0 1034.0 0 249.85 0 0
[43824 rows x 12 columns]
(3)将NaN设置为指定值 *fillna() *
meanNaN = data.fillna(value = newData.mean()['pm2.5'])
# data.loc[:, "pm2.5"] = data["pm2.5"].fillna(method="ffill")
# method="ffill" : #用前面的非空值来填充
print(meanData)
#输出结果:对比原数据,NaN都被赋值为pm2.5的平均值: 98.613215
No year month day hour pm2.5 ... TEMP PRES cbwd Iws Is Ir
1 2010 1 1 0 98.613215 ... -11.0 1021.0 0 1.79 0 0
2 2010 1 1 1 98.613215 ... -12.0 1020.0 0 4.92 0 0
3 2010 1 1 2 98.613215 ... -11.0 1019.0 0 6.71 0 0
... ... ... ... ... ... ... ... ... ... ... .. ..
43823 2014 12 31 22 8.0 ... -4.0 1034.0 0 246.72 0 0
43824 2014 12 31 23 12.0 ... -3.0 1034.0 0 249.85 0 0
[43824 rows x 12 columns]
5、新增数据列
- 直接赋值
- df.apply方法
- df.assign方法
- 按条件选择分组分别赋值
(1) 直接赋值
df.loc[: , "max"] = df[" max"].str.replace(";", ".").astype("float")
df.loc[: , "min"] = df[" min"].str.replace(";", ".").astype("float")
df.loc[: , "err"] = df["max"] - df["min"] #增加了一列err
(2) df.apply()
def get_value_type(x):
if x["max"] > 100:
return "太高"
if x["min"] < 10:
return "太低"
return "正常"
df.loc[:, "value_type"] = df.apply(get_value_type, axis=1) #a_type就是新增的列
#查看a_type的计数
df["value_type"].value_counts()
(3) df.assign()
可以同时新增多个列
df.assign(
max_type= lambda x : x["max"] * 9 / 5 +32,
min_type= lambda x : x["min"] * 9 / 5 +32,
)
(4)按照条件选择分组分别赋值
按照条件先选择数据,然后对这部分数据赋值新列
#先创建空列
df["a_typpe"] = " "
df.loc[ df["max"] - df["min"] >= 100, "err_type"] = "差距太大"
df.loc[ df["max"] - df["min"] <= 10, "err_type"] = "差距太小"
#查看err_type的统计值
df["err_type"].value_counts()
6、统计方法
- 汇总类统计
- 唯一去重和按值计数
- 相关系数和协方差
(1) describe
一次性提取出所有数字列的统计结果
df.describe()
#能看到每一列数据的count mean std min max 25% 50% 75% max等统计结果
(2) mean()
查看平均值
#以最开始的pm2.5为例
dataMean= data.mean() #计算所有列的平均值(计算时会忽略NaN
print(dataMean)
#输出结果:
No 21912.500000
year 2012.000000
month 6.523549
day 15.727820
hour 11.500000
pm2.5 98.613215
DEWP 1.817246
TEMP 12.448521
PRES 1016.447654
cbwd 1.488933
Iws 23.889140
Is 0.052734
Ir 0.194916
dtype: float64
print(dataMean["pm2.5"]) #输出指定列
#输出结果:
98.61321455085375
pmMean = data["pm2.5"].mean() #只计算pm2.5列的平均值
print(pmMean)
#输出结果:
98.61321455085375
(3) max()、min()、argmax()、argmin()
查看最大/最小值及其位置
dataMax = data.max() #查看所有列的最大值
print(dataMax)
#输出结果:
No 43824.0
year 2014.0
month 12.0
day 31.0
hour 23.0
pm2.5 994.0
DEWP 28.0
TEMP 42.0
PRES 1046.0
cbwd 3.0
Iws 585.6
Is 27.0
Ir 36.0
dtype: float64
pmMax = data["pm2.5"].max() #只计算pm2.5列的最大值
pmMaxIndex = data["pm2.5"].argmax()#取最大值位置
print(pmMax ,pmMaxIndex)
#输出结果:
994.0 18049
#min()的用法与max()的用法相同,这里不再赘述
(4)median()
查看中位数
dataMid = newData.median()
print(dataMid )
#输出结果:
No 21912.50
year 2012.00
month 7.00
day 16.00
hour 11.50
pm2.5 72.00
DEWP 2.00
TEMP 14.00
PRES 1016.00
cbwd 1.00
Iws 5.37
Is 0.00
Ir 0.00
dtype: float64
pmMid = newData["pm2.5"].median() #查看指定列的中位数
print(pmMid)
#输出结果:
72.0
(5) unique()
唯一去重和按值计数;获取不重复列表数据;
一般不用于数值列,而是枚举、分类列
uniqueData = newData["pm2.5"].unique()#获取不重复的列表数据
print(uniqueData)
#输出结果:
[ nan 129. 148. 159. 181. 138. 109. 105. ... ... ... ... 2. 3. 577. 483. 519. 551. 542. 580.]
(5) value_counts()
按值计数
monthCount = newData["month"].value_counts()
(6) 相关系数和协方差
- 协方差:衡量同向反向程度;如果协方差为正,说明X Y同向变化,协方差越大说明同向程度越高;如果协方差为负,说明X Y 反向运动,协方差越小说明反向程度越高;
- 相关系数:衡量相似度程度,当他们的相关系数为1时,说明两个变量变化时的正向相似度最大,当相关系数为-1时,说明两个变量变化的反向相似度最大;
#协方差矩阵
df.cov()
#相关系数矩阵
df.corr()
df["max"].corr(df["min"])
df["max"].corr(df["med"] - df["min"])