基于Python实现的决策树模型
决策树模型
目录
人工智能第五次实验报告 1
决策树模型 1
一 、问题背景 1
1.1 监督学习简介 1
1.2 决策树简介 1
二 、程序说明 3
2.1 数据载入 3
2.2 功能函数 3
2.3 决策树模型 4
三 、程序测试 5
3.1 数据集说明 5
3.2 决策树生成和测试 6
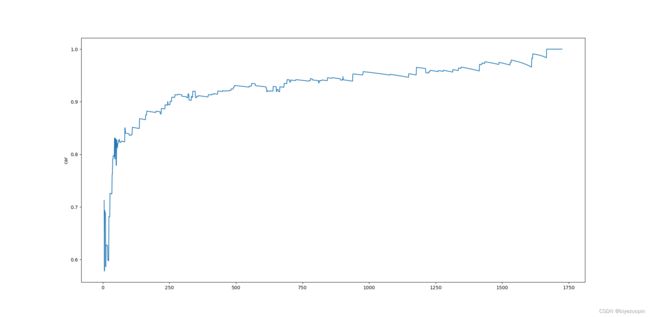
3.3 学习曲线评估算法精度 7
四 、实验总结 8
附 录 - 程序代码 8
一 、问题背景
1.1监督学习简介
机器学习的形式包括无监督学习,强化学习,监督学习和半监督学习;学习任务有分类、聚类和回 归等。
监督学习通过观察“输入—输出”对,学习从输入到输出的映射函数。分类监督学习的训练集为标记 数据,本文转载自http://www.biyezuopin.vip/onews.asp?id=16720每一条数据有对应的”标签“,根据标签可以将数据集分为若干个类别。分类监督学习经训练集生 成一个学习模型,可以用来预测一条新数据的标签。
常见的监督学习模型有决策树、KNN算法、朴素贝叶斯和随机森林等。
1.2决策树简介
决策树归纳是一类简单的机器学习形式,它表示为一个函数,以属性值向量作为输入,返回一个决策。
决策树的组成
决策树由内节点上的属性值测试、分支上的属性值和叶子节点上的输出值组成。
import numpy as np
from matplotlib import pyplot as plt
from math import log
import pandas as pd
import pydotplus as pdp
"""
19335286 郑有为
人工智能作业 - 实现ID3决策树
"""
nonce = 0 # 用来给节点一个全局ID
color_i = 0
# 绘图时节点可选的颜色, 非叶子节点是蓝色的, 叶子节点根据分类被赋予不同的颜色
color_set = ["#AAFFDD", "#DDAAFF", "#DDFFAA", "#FFAADD", "#FFDDAA"]
# 载入汽车数据, 判断顾客要不要买
class load_car:
# 在表格中,最后一列是分类结果
# feature_names: 属性名列表
# target_names: 标签(分类)名
# data: 属性数据矩阵, 每行是一个数据, 每个数据是每个属性的对应值的列表
# target: 目标分类值列表
def __init__(self):
df = pd.read_csv('../dataset/car/car_train.csv')
labels = df.columns.values
data_array = np.array(df[1:])
self.feature_names = labels[0:-1]
self.target_names = labels[-1]
self.data = data_array[0:,0:-1]
self.target = data_array[0:,-1]
# 载入蘑菇数据, 鉴别蘑菇是否有毒
class load_mushroom:
# 在表格中, 第一列是分类结果: e 可食用; p 有毒.
# feature_names: 属性名列表
# target_names: 标签(分类)名
# data: 属性数据矩阵, 每行是一个数据, 每个数据是每个属性的对应值的列表
# target: 目标分类值列表
def __init__(self):
df = pd.read_csv('../dataset/mushroom/agaricus-lepiota.data')
data_array = np.array(df)
labels = ["edible/poisonous", "cap-shape", "cap-surface", "cap-color", "bruises", "odor", "gill-attachment",
"gill-spacing", "gill-size", "gill-color", "stalk-shape", "stalk-root", "stalk-surface-above-ring",
"stalk-surface-below-ring", "stalk-color-above-ring", "stalk-color-below-ring",
"veil-type", "veil-color", "ring-number", "ring-type", "spore-print-color", "population", "habitat"]
self.feature_names = labels[1:]
self.target_names = labels[0]
self.data = data_array[0:,1:]
self.target = data_array[0:,0]
# 创建一个临时的子数据集, 在划分测试集和训练集时使用
class new_dataset:
# feature_names: 属性名列表
# target_names: 标签(分类)名
# data: 属性数据矩阵, 每行是一个数据, 每个数据是每个属性的对应值的列表
# target: 目标分类值列表
def __init__(self, f_n, t_n, d, t):
self.feature_names = f_n
self.target_names = t_n
self.data = d
self.target = t
# 计算熵, 熵的数学公式为: $H(V) = - \sum_{k} P(v_k) \log_2 P(v_k)$
# 其中 P(v_k) 是随机变量 V 具有值 V_k 的概率
# target: 分类结果的列表, return: 信息熵
def get_h(target):
target_count = {}
for i in range(len(target)):
label = target[i]
if label not in target_count.keys():
target_count[label] = 1.0
else:
target_count[label] += 1.0
h = 0.0
for k in target_count:
p = target_count[k] / len(target)
h -= p * log(p, 2)
return h
# 取数据子集, 选择条件是原数据集中的属性 feature_name 值是否等于 feature_value
# 注: 选择后会从数据子集中删去 feature_name 属性对应的一列
def get_subset(dataset, feature_name, feature_value):
sub_data = []
sub_target = []
f_index = -1
for i in range(len(dataset.feature_names)):
if dataset.feature_names[i] == feature_name:
f_index = i
break
for i in range(len(dataset.data)):
if dataset.data[i][f_index] == feature_value:
l = list(dataset.data[i][:f_index])
l.extend(dataset.data[i][f_index+1:])
sub_data.append(l)
sub_target.append(dataset.target[i])
sub_feature_names = list(dataset.feature_names[:f_index])
sub_feature_names.extend(dataset.feature_names[f_index+1:])
return new_dataset(sub_feature_names, dataset.target_names, sub_data, sub_target)
# 寻找并返回信息收益最大的属性划分
# 信息收益值划分该数据集前后的熵减
# 计算公式为: Gain(A) = get_h(ori_target) - sum(|sub_target| / |ori_target| * get_h(sub_target))$
def best_spilt(dataset):
base_h = get_h(dataset.target)
best_gain = 0.0
best_feature = None
for i in range(len(dataset.feature_names)):
feature_range = []
for j in range(len(dataset.data)):
if dataset.data[j][i] not in feature_range:
feature_range.append(dataset.data[j][i])
spilt_h = 0.0
for feature_value in feature_range:
subset = get_subset(dataset, dataset.feature_names[i], feature_value)
spilt_h += len(subset.target) / len(dataset.target) * get_h(subset.target)
if best_gain <= base_h - spilt_h:
best_gain = base_h - spilt_h
best_feature = dataset.feature_names[i]
return best_feature
# 返回数据集中一个数据最可能的标签
def vote_most(dataset):
target_range = {}
best_target = None
best_vote = 0
for t in dataset.target:
if t not in target_range.keys():
target_range[t] = 1
else:
target_range[t] += 1
for t in target_range.keys():
if target_range[t] > best_vote:
best_vote = target_range[t]
best_target = t
return best_target
# 返回测试的正确率
# predict_result: 预测标签列表, target_result: 实际标签列表
def accuracy_rate(predict_result, target_result):
# print("Predict Result: ", predict_result)
# print("Target Result: ", target_result)
accuracy_score = 0
for i in range(len(predict_result)):
if predict_result[i] == target_result[i]:
accuracy_score += 1
return accuracy_score / len(predict_result)
# 决策树的节点结构
class dt_node:
def __init__(self, content, is_leaf=False, parent=None):
global nonce
self.id = nonce # 为节点赋予一个全局ID, 目的是方便画图
nonce += 1
self.feature_name = None
self.target_value = None
self.vote_most = None # 记录当前节点最可能的标签
if not is_leaf:
self.feature_name = content # 非叶子节点的属性名
else:
self.target_value = content # 叶子节点的标签
self.parent = parent
self.child = {} # 以当前节点的属性对应的属性值作为键值
# 决策树模型
class dt_tree:
def __init__(self):
self.tree = None # 决策树的根节点
self.map_str = """
digraph demo{
node [shape=box, style="rounded", color="black", fontname="Microsoft YaHei"];
edge [fontname="Microsoft YaHei"];
""" # 用于作图: pydotplus 格式的树图生成代码结构
self.color_dir = {} # 用于作图: 叶子节点可选颜色, 以标签值为键值
# 训练模型, train_set: 训练集
def fit(self, train_set):
if len(train_set.target) <= 0: # 如果测试集数据为空, 则返回空节点, 结束递归
return None
target_all_same = True
for i in train_set.target:
if i != train_set.target[0]:
target_all_same = False
break
if target_all_same: # 如果测试集数据中所有数据的标签相同, 则构造叶子节点, 结束递归
node = dt_node(train_set.target[0], is_leaf=True)
if self.tree == None: # 如果根节点为空,则让该节点成为根节点
self.tree = node
# 用于作图, 更新 map_str 内容, 为树图增加一个内容为标签值的叶子节点
node_content = "标签:" + str(node.target_value)
self.map_str += "id" + str(node.id) + "[label=\"" + node_content + "\", fillcolor=\"" + self.color_dir[node.target_value] + "\", style=filled]\n"
return node
elif len(train_set.feature_names) == 0: # 如果测试集待考虑属性为空, 则构造叶子节点, 结束递归
node = dt_node(vote_most(train_set), is_leaf=True) # 这里让叶子结点的标签为概率上最可能的标签
if self.tree == None: # 如果根节点为空,则让该节点成为根节点
self.color_dir[vote_most(train_set)] = color_set[0]
self.tree = node
# 用于作图, 更新 map_str 内容, 为树图增加一个内容为标签值的叶子节点
node_content = "标签:" + str(node.target_value)
self.map_str += "id" + str(node.id) + "[label=\"" + node_content + "\", fillcolor=\"" + self.color_dir[node.target_value] + "\", style=filled]\n"
return node
else: # 普通情况, 构建一个内容为属性的非叶子节点
best_feature = best_spilt(train_set) # 寻找最优划分属性, 作为该结点的值
best_feature_index = -1
for i in range(len(train_set.feature_names)):
if train_set.feature_names[i] == best_feature:
best_feature_index = i
break
node = dt_node(best_feature)
node.vote_most = vote_most(train_set)
if self.tree == None: # 如果根节点为空,则让该节点成为根节点
self.tree = node
# 用于作图, 初始化叶子节点可选颜色
for i in range(len(train_set.target)):
if train_set.target[i] not in self.color_dir:
global color_i
self.color_dir[train_set.target[i]] = color_set[color_i]
color_i += 1
color_i %= len(color_set)
feature_range = [] # 获取该属性出现在数据集中的可选属性值
for t in train_set.data:
if t[best_feature_index] not in feature_range:
feature_range.append(t[best_feature_index])
# 用于做图, 创建一个内容为属性的非叶子节点
node_content = "属性:" + node.feature_name
self.map_str += "id" + str(node.id) + "[label=\"" + node_content + "\", fillcolor=\"#AADDFF\", style=filled]\n"
for feature_value in feature_range:
subset = get_subset(train_set, best_feature, feature_value) # 获取每一个子集
node.child[feature_value] = self.fit(subset) # 递归调用 fit 函数生成子节点
if node.child[feature_value] == None:
# 如果创建的子节点为空, 则创建一个叶子节点作为其子节点, 其中标签值为概率上最可能的标签
node.child[feature_value] = dt_node(vote_most(train_set), is_leaf=True)
node.child[feature_value].parent = node
# 用于做图, 创建当前节点到所有子节点的连线
self.map_str += "id" + str(node.id) + " -> " + "id" + str(node.child[feature_value].id) + "[label=\"" + str(feature_value) + "\"]\n"
# print("Rest Festure: ", train_set.feature_names)
# print("Best Feature: ", best_feature_index, best_feature, "Feature Range: ", feature_range)
# for feature_value in feature_range:
# print("Child[", feature_value, "]: ", node.child[feature_value].feature_name, node.child[feature_value].target_value)
return node
# 测试模型, 对测试集 test_set 进行预测
def predict(self, test_set):
test_result = []
for test in test_set.data:
node = self.tree # 从根节点一只往下找, 知道到达叶子节点
while node.target_value == None:
feature_name_index = -1
for i in range(len(test_set.feature_names)):
if test_set.feature_names[i] == node.feature_name:
feature_name_index = i
break
if test[feature_name_index] not in node.child.keys():
break
else:
node = node.child[test[feature_name_index]]
if node.target_value == None:
test_result.append(node.vote_most)
else: # 如果没有到达叶子节点, 则取最后到达节点概率上最可能的标签为目标值
test_result.append(node.target_value)
return test_result
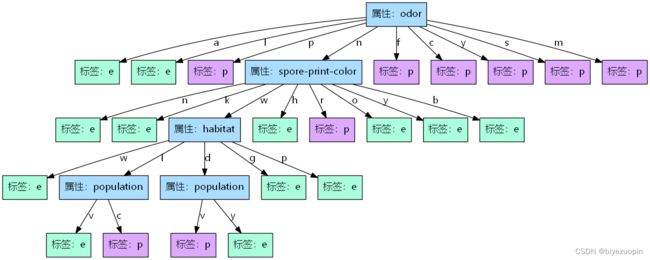
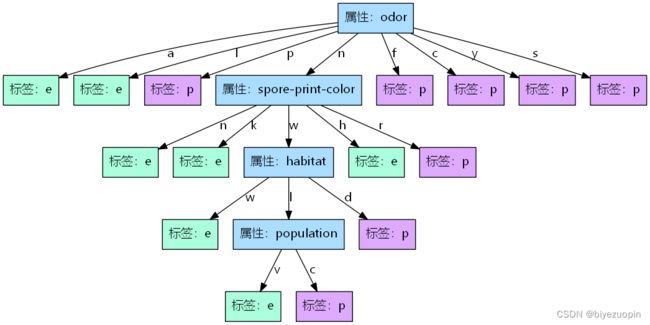
# 输出树, 生成图片, path: 图片的位置
def show_tree(self, path="demo.png"):
map = self.map_str + "}"
print(map)
graph = pdp.graph_from_dot_data(map)
graph.write_png(path)
# 学习曲线评估算法精度 dataset: 数据练集, label: 纵轴的标签, interval: 测试规模递增的间隔
def incremental_train_scale_test(dataset, label, interval=1):
c = dataset
r = range(5, len(c.data) - 1, interval)
rates = []
for train_num in r:
print(train_num)
train_set = new_dataset(c.feature_names, c.target_names, c.data[:train_num], c.target[:train_num])
test_set = new_dataset(c.feature_names, c.target_names, c.data[train_num:], c.target[train_num:])
dt = dt_tree()
dt.fit(train_set)
rates.append(accuracy_rate(dt.predict(test_set), list(test_set.target)))
print(rates)
plt.plot(r, rates)
plt.ylabel(label)
plt.show()
if __name__ == '__main__':
c = load_car() # 载入汽车数据集
# c = load_mushroom() # 载入蘑菇数据集
train_num = 1000 # 训练集规模(剩下的数据就放到测试集)
train_set = new_dataset(c.feature_names, c.target_names, c.data[:train_num], c.target[:train_num])
test_set = new_dataset(c.feature_names, c.target_names, c.data[train_num:], c.target[train_num:])
dt = dt_tree() # 初始化决策树模型
dt.fit(train_set) # 训练
dt.show_tree("../image/demo.png") # 输出决策树图片
print(accuracy_rate(dt.predict(test_set), list(test_set.target))) # 进行测试, 并计算准确率吧
# incremental_train_scale_test(load_car(), "car")
# incremental_train_scale_test(load_mushroom(), "mushroom", interval=20)