CPUCPU流水线与指令重排序
目录
-
- 1. Compiler Reordering
- 2. CPU 流水线
-
- 2.1. 从汽车装配谈起
- 2.2. 现代CPU的流水线
- 3. 超长流水线的瓶颈
-
- 3.1. 性能瓶颈
- 3.2. 功耗瓶颈
- 3.3. 指令乱序
- 4. 总结
青蛙见了蜈蚣,好奇地问:“蜈蚣大哥,我很好奇,你那么多条腿,走路的时候先迈哪一条啊?”
蜈蚣听后说:“青蛙老弟,我一直就这么走路,从没想过先迈哪一条腿,等我想一想再回答你。”
蜈蚣站立了几分钟,它一边思考一边向前,蹒跚了几步,终于趴下去了。
它对青蛙说:“请你再也别问其它蜈蚣这个问题了!我一直都在这样走路,这根本不成问题!可现在你问我先移动哪一条腿,我也不知道了。搞得我现在连路都不会走了,我该怎么办呢?”
这个小故事属实反映了我最近的心态:
越学越不会了。。。
本来synchronized和volatile关键字用得好好的,我非要深入研究一下他们的原理,所以研究了内存屏障,又研究了和内存屏障相关的MESI,又研究了Cache Coherence和Memory Consistency,发现一切问题都出在CPU身上。于是又惊叹Java一次编写到处运行的特性,最终又研究到JMM。
说是研究,其实就是把学习过程中自己抛出来的问题解决掉,把所有知识穿成一条线罢了。
这条线的线头就从指令的乱序执行开始了。
经典的指令乱序执行的原因有两种,分别是Compiler Reordering和CPU Reordering。
1. Compiler Reordering
编译器会对高级语言的代码进行分析,如果它认为你的代码可以优化,那么他会对你的代码进行各种优化然后生成汇编指令。当然,本文说的优化主要是指令重排(Compiler Reordering)。
但是编译器的优化必须满足特定的条件,一个非常重要的原则就是as-if-serial语义:
Allows any and all code transformations that do not change the observable behavior of the program.
编译器必须遵守as-if-serial语义,也就是编译器不会对存在数据依赖关系的操作做重排序,因为这种重排序会改变执行结果。 但是,如果操作之间不存在数据依赖关系,这些操作就可能被编译器和处理器重排序。
我们用非常简单的C++代码举个例子(因为编译更简单,看起来也更直观)。
int a,b,c;
void bar()
{
a = c + 1;
b = 1;
}
int main()
{
bar();
return 0;
}
我们对这段代码进行变异,让编译器在O2级别优化的情况下编译代码,我截取其中的bar()的汇编代码,如下所示:
_Z3barv:
.LFB0:
.cfi_startproc
endbr64
movl $1, b(%rip) #将1的值赋给b,即b = 1
movl c(%rip), %eax #将c的值放到寄存器%eax中
addl $1, %eax #将寄存器%eax的值+1,即c + 1
movl %eax, a(%rip) #将寄存器%eax的值赋给a,即a = c + 1
ret
我们发现,编译得到的汇编代码和我们原本的C语言代码顺序并不一致。
汇编指令先执行了b = 1,之后才执行了a = c + 1。说明变量a和b的store操作并没有按照他们在程序中定义的顺序来执行。
既然汇编指令被重排了,CPU的执行顺序自然是根据汇编指令对应的机器指令执行的,大概率也会被重排。其实除此之外,CPU本身也会对指令进行重排(CPU Reordering)。
2. CPU 流水线
谈及处理器必谈及流水线,处理器的流水线结构是处理器微架构最基本的一个要素,也是造成CPU Reordering的主要因素。
2.1. 从汽车装配谈起
流水线的概念始于工业制造领域,但是鉴于大部分人其实都没接触过流水线,我们不妨举一个汽车生产的例子来解释流水线的诞生。
我们首先粗浅地认为汽车的装配需要两个步骤:
- 制作零件:制作车身外壳、发动机和各种其他部件;
- 组装:将各零部件(自己制作和外采的所有零部件)组装成车。
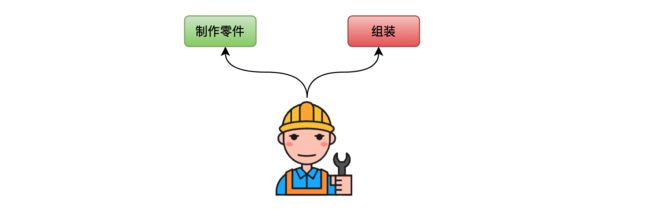
假设一个工人进行每个步骤都占用1个月,如果不采用流水线,而采用串行方式来执行的话,一年时间可以装配6辆汽车,过程见下图:

串行的效率实在是太有限了,根本原因就是装配的两个步骤都是由一个人完成的。如果有人能在组装进行的同时制作零件,效率会大大提升,也就是每个流程只专注一件事情,我们再引入一个工人。
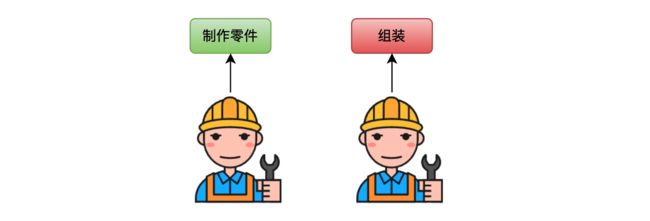
这样一个人专门负责制作零件,另一个人专门组装零件,两个工作交叠进行,过程见下图:
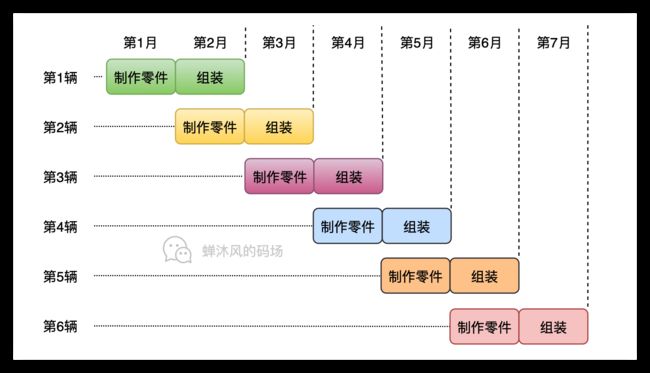
增加一个人手之后,除了第一个月,每一个月都有完整的制作零件和组装流程,因此一年内可以完成11台汽车的装配(相比于串行方式的6台,几乎翻倍了),从第二年开始,每年就能装配12台了(直接翻倍)。
这个过程就是流水线的执行过程,因为我们把汽车的制作过程分成了两个步骤,因此以上流水线成为二级流水线。
我们继续优化,我们将制作零件的步骤分成时间周期更短的冲压和焊接两步,将组装步骤分为时间周期更短的涂装和总装两步,并且假设每个步骤的时间周期为0.5个月。
当然喽,我们得再雇佣俩人。
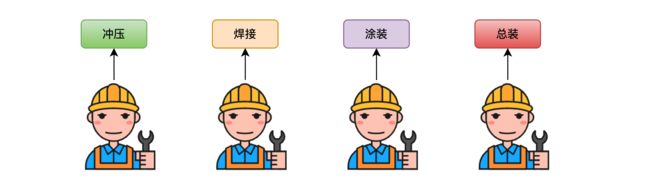
现在就是四级流水线了,神奇的事情发生了,四级流水线使得原本需要一年时间的任务现在只需要4.5个月便可以完成,再次提升了效率。如下图所示:

2.2. 现代CPU的流水线
现代 CPU 支持多级指令流水线,例如支持同时执行 取指令 - 指令译码 - 执行指令 - 内存访问 - 数据写回的处理器,就可以称之为五级指令流水线。
这时 CPU 可以在一个时钟周期内,同时运行五条指令的不同阶段,其中每个阶段的都占用一个或多个指令周期(CPU以执行时间最长),本质上,流水线技术井不能缩短单条指令的执行时间,但它变相地提高了指令的吞吐率。
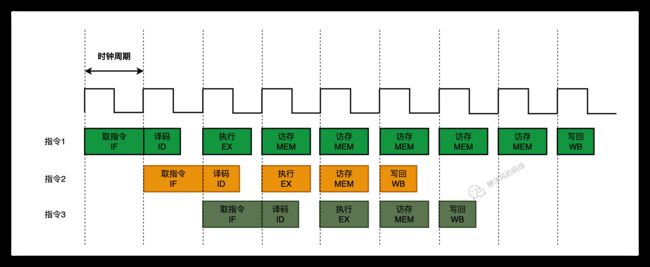
上面的CPU流水线图并非特定型号的CPU的示例,而是为了说明几个问题特意画成了这个样子。
-
通常而言,CPU设计者会选择执行时间最长的流水线阶段作为一个时钟周期,这样能保证其他阶段能在一个时钟周期内完成,避免出现流水线断流。
-
每一个流水线级的时间都是一个时钟周期,但是其中实际操作的时间,可能短于一个时钟周期。比如译码器其实就是一个组合逻辑电路,门延迟很低,就不需要一个完整的时钟周期就能完成自己的任务,任务完成之后CPU其实是在“等待”。
很多人可能会问,既然流水线这么好用,那为什么CPU设计者不设计一个超长流水线呢?这就需要说明一下超长流水线的瓶颈了。
3. 超长流水线的瓶颈
3.1. 性能瓶颈
流水线长度的增加,是有性能成本的。
每一级流水线的输出都需要放在流水线寄存器中,然后再下一个时钟周期,交给下一个流水线级去处理。每增加一级流水线,就要多一级写入流水线寄存器的操作。
以多线程为例,数量合适的多线程会提高数据的处理速度,但是当线程数量太多,线程之间的时间切换成本就无法被忽视,线程的增加甚至可能成为性能提升的负担。
3.2. 功耗瓶颈
提升流水线的深度,需要同步提高CPU的主频。再看一下这个图:
由于流水线的每一级被分得特别细,甚至有的还没有完全占满单个时钟周期,也就意味着单个时钟周期内能完成的事情变少了,因此只有提升主频,CPU 在指令的响应时间这个指标上才能保持和原来相同的性能。
提升主频和流水线深度就以为这晶体管的增加,也就以为这功耗变大。
没人想拥有一台“充电3小时,办公20分钟”的一台笔记本电脑吧。
3.3. 指令乱序
还是以上面的图为例(就不再贴一遍了),指令1的访存操作使用了多个时钟周期,导致指令2和指令3在指令1之前完成了。
如果是一般的代码还好,但如果是具有依赖性的代码,比如:
float a = 3.14159 * 0.2; // 指令1
float b = a * 2; // 指令2
float c = b + 1; // 指令3
float d = 10; // 指令4
指令1、2、3的执行顺序就绝不能向图中表示的那样乱序执行。其中有两点需要我们注意:
- 由于上图中情形的存在,导致CPU确实有可能出现乱序执行的情况;
- CPU需要阻止具有依赖关系的指令乱序执行(指令1,2,3),转而让后续没有依赖关系的指令(指令4)先执行。
对于第2条,如果流水线只有5级还好说,CPU自然有办法判断哪些指令具有依赖性,并拒绝做出指令乱序。但是如果有20条流水线,CPU肯定还有办法判断,但是可想而知,这种判断势必会影响CPU的性能。
回到本文一开始说的编译器指令重排序,当然喽,也包含Java的JIT将字节码编译成机器码时的指令重排序,就是为了把没有依赖关系的指令放一起,本质上都是为了适配CPU,更好地发挥出CPU流水线的功能,从而提升性能罢了。
4. 总结
说了这么多,很可能在我之后的文章中被一句话带过。
其实我想表达的思想就是,实际代码运行的顺序可能和我们代码编写的顺序并不一致。记住这句话很容易,但或许总会有人像我一样想稍微深入一点来了解这句话的本质吧。
除了本文所述,CPU和高速缓存之间的交互过程中,硬件工程师也着实给软件开发者挖了不少坑,内存屏障就是在这种背景下产生的。
更多内容,下期见!