Linux配置安装 Elasticsearch 7.10.2 详细教程
文章目录
- 引言
- 一、ES 安装
- 二、head 插件安装
- 三、Kibana 安装
- 四、IK分词器 安装
引言
- 由于后续都基于 Elasticsearch 7.10.2 版本进行操作,所以此处相关安装版本都为 7.10.2
- 由于容器安装十分方便,仅需几行代码即可搞定,此处只提供正常安装
一、ES 安装
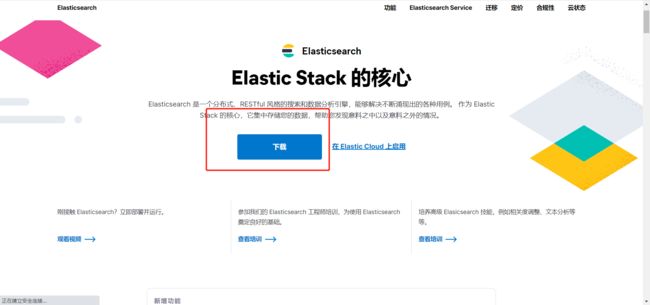
1. 打开 官网,点击下载
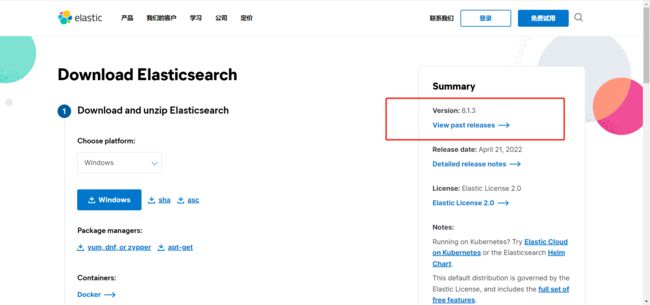
2. 点击 View past releases,查看过去的版本
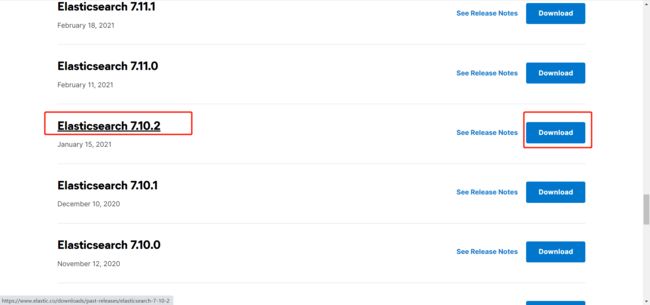
3. 选择版本 Elasticsearch 7.10.2,点击 Download,进入下载详情
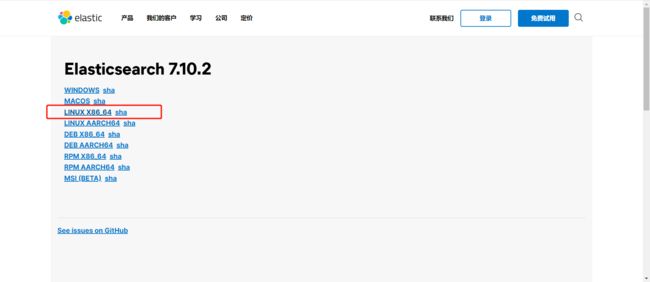
4. 点击 LINUX X86_64,进行 下载
5. 下载成功 elasticsearch-7.10.2-linux-x86_64.tar.gz
![]()
6. 打开linux,创建新用户(es不能在root用户下启动,必须创建新的用户,用来启动es)
useradd es -s /bin/bash
7. 进入 /home/es 目录下,上传 elasticsearch-7.10.2-linux-x86_64.tar.gz
cd /home/es

8. 解压 elasticsearch-7.10.2-linux-x86_64.tar.gz
tar -zxvf elasticsearch-7.10.2-linux-x86_64.tar.gz

9. 使用 root 用户对 es 进行授权
chown -R es:es elasticsearch-7.10.2

10. 创建日志、数据存储目录:(留作备用,初次先创建)
mkdir -p /data/logs/es
mkdir -p /data/es/{data,work,plugins,scripts}
![]()
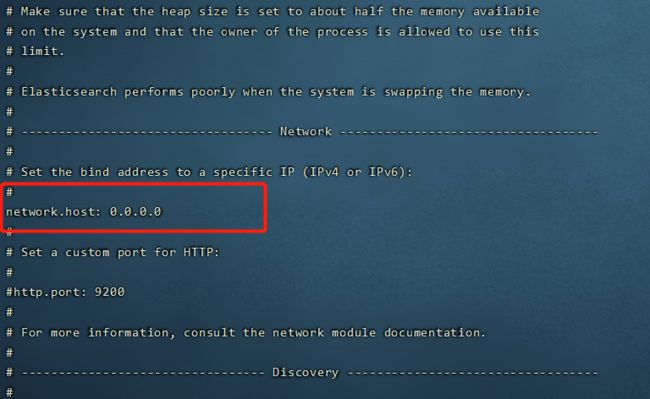
11. 此处浏览器还不能访问,需修改配置 0.0.0.0
cd /home/es/elasticsearch-7.10.2/config
vi elasticsearch.yml
12. elasticsearch 启动
#切换用户es
su es
#启动es(-d : 后台运行,不加则为运行并输入日志)
./elasticsearch-7.10.2/bin/elasticsearch -d

13. 启动后报错:Native controller process has stopped - no new native processes can be started
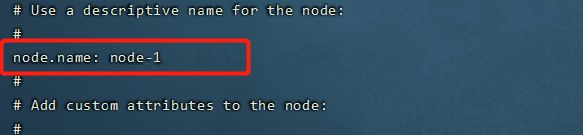
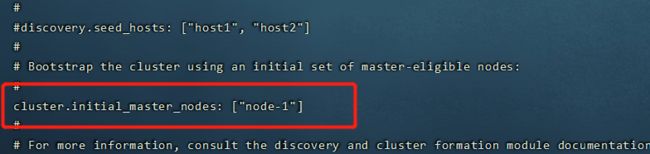
- 修改config文件夹下的elasticsearch.yml文件:
- node.name: node-1
- cluster.initial_master_nodes: [“node-1”]
- 修改之后保存,再次启动elasticsearch,就成功启动elasticsearch了。
vi elasticsearch-7.10.2/config/elasticsearch.yml
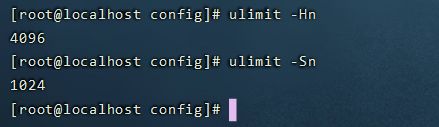
14. 启动后报错:max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
- 需要修改每个进程最大同时打开文件数,先通过下面2个命令查看当前数量
#通过命令查看
ulimit -Hn
ulimit -Sn
- 修改/etc/security/limits.conf文件,增加配置,用户退出后重新登录生效
vi /etc/security/limits.conf
#添加以下配置信息
* soft nofile 65536
* hard nofile 65536

- 查询修改后信息
#先切换用户:es
su es
#查询信息
ulimit -Hn
ulimit -Sn
#退出es
exit

15. 启动后报错:max number of threads [3818] for user [es] is too low, increase to at least [4096]
#通过命令查看
ulimit -Hu
ulimit -Su
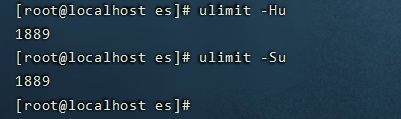
- 问题同上,最大线程个数太低。修改配置文件/etc/security/limits.conf,增加配置
vi /etc/security/limits.conf
#添加以下配置信息
* soft nproc 4096
* hard nproc 4096

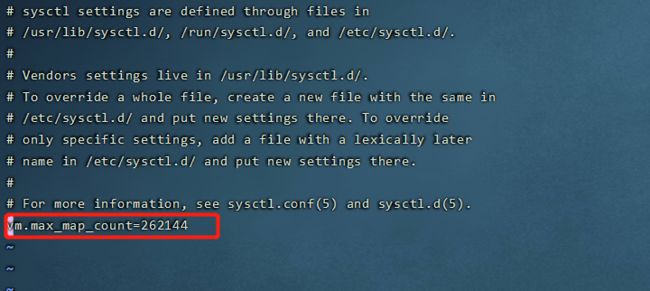
16. 启动后报错:max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
#修改/etc/sysctl.conf文件
vi /etc/sysctl.conf
#增加配置
vm.max_map_count=262144
#执行命令sysctl -p生效
sysctl -p

17. 错误解决完毕,重新启动 elasticsearch
#切换用户es
su es
#启动es(-d : 后台运行,不加则为运行并输入日志)
./elasticsearch-7.10.2/bin/elasticsearch -d
18. 输入 192.168.56.91:9200(自己IP:9200),es启动成功

二、head 插件安装
1. 用途
- elasticsearch-head是一个用来浏览、与Elastic Search簇进行交互的web前端展示插件。
- elasticsearch-head是一个用来监控Elastic Search状态的客户端插件。
- elasticsearch主要有以下三个主要操作:
1) 簇浏览,显示簇的拓扑并允许你执行索引(index)和节点层面的操作。
2) 查询接口,允许你查询簇并以原始json格式或表格的形式显示检索结果。
3) 显示簇状态,有许多快速访问的tabs用来显示簇的状态。
4) 支持Restful API接口,包含了许多选项产生感兴趣的结果,包括:
1) 请求方式:get,put,post,delete; json请求数据,节点node, 路径path。
2) JSON验证器。
3) 定时请求的能力。
4) 用javascript表达式传输结果的能力。
5) 统计一段时间的结果或该段时间结果比对的能力。
6) 以简单图标的形式绘制传输结果
2. 安装
#下载nodejs,head插件运行依赖node
wget https: i nodejs.org/dist/v9.9.0/node-v9.9.0-linux-x64.tar.xz
#解压
tar -xf node-v9.9.0-linux-x64.tar.xz
#重命名
mv node-v9.9.0-linux-x64 /usr/local/node
#配置文件
vi /etc/profile
#将node的路径添加到path中
export PATH=$PATH:$JAVA_HOME/bin:/home/es/node-v9.9.0-linux-x64/bin
#刷新配置
source /etc/profile
#查询node版本,同时查看是否安装成功
node -v
#下载head插件
wget https: i github.com/mobz/elasticsearch-head/archive/master.zip
#解压
unzip master.zip
#使用淘宝的镜像库进行下载,速度很快
npm install -g cnpm --registry=https://registry.npm.taobao.org
#进入head插件解压目录,执行安装命令
cnpm install
3. 运行
#root用户进入es目录
cd /home/es
#授权
chown -R es:es elasticsearch-head-master/
#进入head目录
cd elasticsearch-head-master/
#启动head插件
npm start
#或者使用
grunt server
4. 启动运行端口为:9100
- 当head插件访问es时,必须在elasticsearch中启用CORS,否则浏览器将拒绝跨域。
- 必须设置http.cors.allow-origin 因为默认情况下不允许跨域。
- http.cors.allow-origin: “*” 是允许配置的,但由于这样配置的任何地方都可以访问,所以有安全风险。
#修改es配置
vi /home/es/elasticsearch-7.10.2/config/elasticsearch.yml
#加入下面两行配置
http.cors.enabled: true
http.cors.allow-origin: "*"

三、Kibana 安装
1. 介绍
- kibana 插件提供了Marvel监控的UI界面。
- kibana是一个与elasticsearch一起工作的开源的分析和可视化的平台。
- 使用kibana可以查询、查看并与存储在elasticsearch索引的数据进行交互操作。
- 使用kibana能执行高级的数据分析,并能以图表、表格和地图的形式查看数据。
- kibana使得理解大容量的数据变得非常容易。它非常简单,基于浏览器的接口使我们能够快速的创建和分享显示elasticsearch查询结果实时变化的仪表盘。
2. 下载
- 进入 Kibana下载界面,点击 View past releases 查看过去的版本
- 选择版本 Elasticsearch 7.10.2,点击 Download
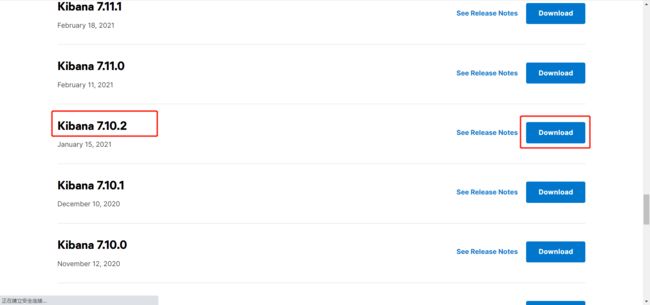
- 点击 LINUX 64-BIT,进行下载
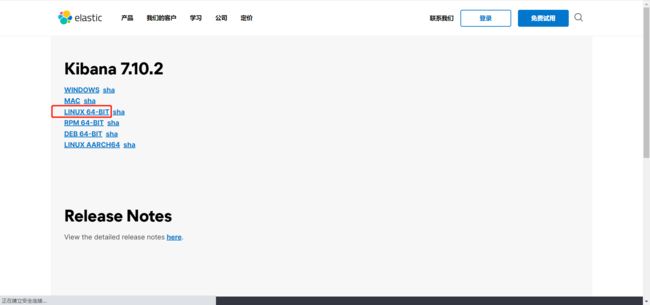
- 下载成功 kibana-7.10.2-linux-x86_64.tar.gz

- 进入 /home/es 目录下,上传 kibana-7.10.2-linux-x86_64.tar.gz
#解压
tar -xzf kibana-7.10.2-linux-x86_64.tar.gz
#修改配置文件
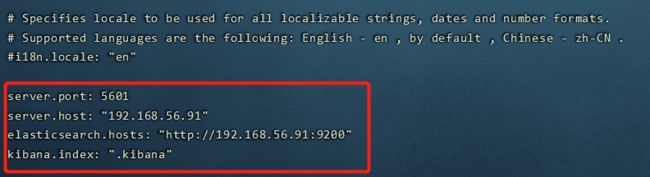
vi ./kibana-7.10.2-linux-x86_64/config/kibana.yml
# 将默认配置改成如下:
server.port: 5601
server.host: "192.168.56.91"
#修改成自己集群的端口号及IP
elasticsearch.hosts: "http://192.168.56.91:9200"
kibana.index: ".kibana"
3. 启动
#进入/home/es
cd /home/es
#授权
chown -R es:es kibana-7.10.2-linux-x86_64
#启动kibana
nohup ./kibana-7.10.2-linux-x86_64/bin/kibana &
- 启动成功
4. 进入Dev Tools
- 无安装其它分词器时,es通过自带的分词机制进行分词
#默认分词:standard
#IK分词: 最细粒度分析:ik_max_word、粗粒度分词:ik_smart,
#此处没有安装ik分词器,使用会报错
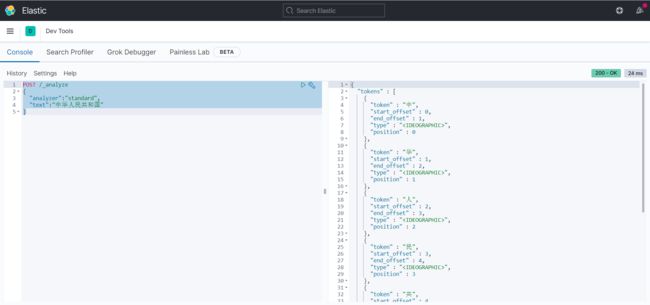
POST /_analyze
{
"analyzer":"standard",
"text":"中华人民共和国"
}
四、IK分词器 安装
这里推荐 ElasticSearch 中文分词 写的非常详细
1. 进入 IK分词器下载页面,选择 7.10.2 版本,点击 elasticsearch-analysis-ik-7.10.2.zip 进行下载
2. 下载成功 elasticsearch-analysis-ik-7.10.2.zip
![]()
3. IK分词器安装
#进入es-plugins
cd /home/es/elasticsearch-7.10.2/plugins
#创建名为ik的文件夹
mkdir ik
#进入ik
cd ik/
#文件传入该目录下,并解压
unzip elasticsearch-analysis-ik-7.10.2.zip

4. IK分词器解压完成后,需重新启动es
#默认分词:standard
#IK分词: 最细粒度分析:ik_max_word、粗粒度分词:ik_smart
POST /_analyze
{
"analyzer":"standard",
"text":"中华人民共和国"
}

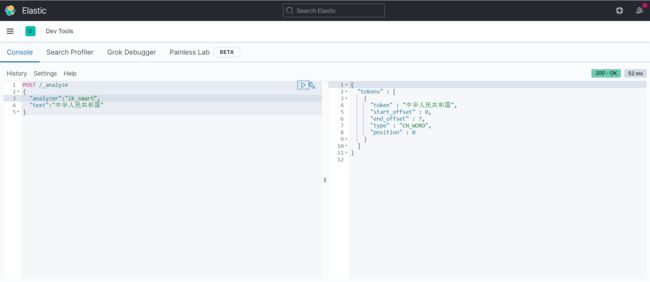
ik分词器安装完成!