数据库-mysql集群方案总结
一 概念解读
1 数据库高可用
高可用指的是:如果数据库发生了宕机或者意外中断等故障,能尽快恢复数据库的 可用性,保证业务不会因为数据库的故障而中断。
另外,数据库高可用还要数据一致性,如下:
(1) 用作备份、只读副本等功能的非主节点的数据应该和主节点的数据实时,并最终保持一致;
(2) 当业务发生数据库切换时,切换前后的数据库内容应当一致,不会因为数据缺失或者数据不一致而影响业务。
2 数据一致性
关系型数据库 MySQL 高可用关键的是数据一致性,目前业界内有三种保证数据一致性的方法:MySQL 原生复制方式、共享存储和分布式协议。
关系型数据库 MySQL 原生数据复制的方式有两种:
(1) 异步复制
主库将事务 Binlog 事件写入到 Binlog 文件中,此时主库只会通知一下 Dump 线程发送这些新的 Binlog,然后主库就会继续处理提交操作,而此时不会保证这些 Binlog 传到任何一个从库节点上。

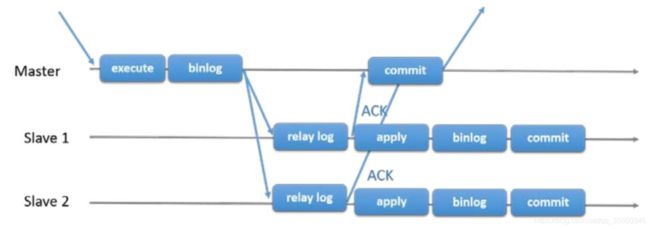
2)半同步复制
主库只需要等待至少一个从库节点收到并且 Flush Binlog 到 Relay Log 文 件即可,主库不需要等待所有从库给主库反馈。同时,这里只是一个收到的反馈,而不是已 经完全完成并且提交的反馈。
共享存储:
(1) SAN 共享存储
SAN 的概念是允许存储设备和处理器(服务器)之间建立直接的高速网络(与 LAN 相 比)连接,通过这种连接实现数据的集中式存储。
(2) DRBD 磁盘复制
DRBD 是一种基于软件、基于网络的块复制存储解决方案,主要用于对服务器之间的磁 盘、分区、逻辑卷等进行数据镜像,当用户将数据写入本地磁盘时,还会将数据发送到网络 中另一台主机的磁盘上,这样的本地主机(主节点)与远程主机(备节点)的数据就可以保证实 时同步。
另外,分布式算法 2PC 、Paxos、Raft 用来解决 MySQL 数据库数据一致性的问题,随着官方 MySQL Group Replication 的发布,使用分布式协议来解决数据一致性问题已经成为了主流的方向。
二 方案介绍
1 常见方案
1.1 第三方 HA 和原生复制
1)Lvs+Keepalived+ MySQL 主主复制

MySQL 主主复制是集群的基础,每个节点都是 Master,均可对外提供服务。Lvs 服务器 提供了负载均衡的作用,将用户请求分发到 Real Server,一台 Real Server 故障并不会影响整 个集群的。Keepalived 搭建主备 Lvs 服务器,避免了 Lvs 服务器的单点故障,出现故障时可 以自动切换到正常的节点。
2)HaProxy+Keepalived+ MySQL 主主复制
和1)中的架构类似
3)常用的简单架构


优点:
架构比较简单,使用原生半同步复制作为数据同步的依据;
双节点,没有主机宕机后的选主问题,直接切换即可;
双节点,需求资源少,部署简单;
缺点:
完全依赖于半同步复制,如果半同步复制退化为异步复制,数据一致性无法得到保证;
需要额外考虑haproxy、keepalived的高可用机制。
1.2 SAN 共享存储 + VIP
SAN 英文全称:Storage Area Network,即存储区域网络。它是一种通过光纤集线器、光 纤路由器、光纤交换机等连接设备将磁盘阵列、磁带等存储设备与相关服务器连接起来的高 速专用子网。
SAN(Storage Area Network)简单点说就是可以实现网络中不同服务器的数据共享,共享 存储能够为数据库服务器和存储解耦。使用共享存储时,服务器能够正常挂载文件系统并操 作,如果服务器挂了,备用服务器可以挂载相同的文件系统,执行需要的恢复操作,然后启 动 MySQL。

优点:
两节点即可,部署简单,切换逻辑简单;
很好的保证数据的强一致性;
不会因为MySQL的逻辑错误发生数据不一致的情况;
缺点:
需要考虑共享存储的高可用;
价格昂贵;
1.3 DRBD + heartbeat
Distributed Replicated Block Device(DRBD)是一个用软件实现的、无共享的、服务器之间镜像块设备内容的存储复制解决方案。DRBD 的核心功能通过 Linux 的内核实现,最接近系 统的 IO 栈。DRBD 的位置处于文件系统以下,比文件系统更加靠近操作系统内核及IO 栈。
方案采用 Heartbeat 双机热备软件来保证数据库的高稳定性和连续性,数据的一致性 由 DRBD 这个工具来保证。默认情况下只有一台 mysql 在工作,当主 mysql 服务器出现问题 后,系统将自动切换到备机上继续提供服务,当主数据库修复完毕,又将服务切回继续由主 mysql 提供服务。

优点:
两节点即可,部署简单,切换逻辑简单;
相比于SAN储存网络,价格低廉;
保证数据的强一致性;
缺点:
对io性能影响较大;
从库不提供读操作;
1.4 MMM
MMM(Master-Master replication manager for MySQL)是一套支持双主故障切换和双主日常管理的脚本程序。业务上同一时刻只允许对一个主进行写入,另一台备选主上提供部分读服务,其他的 slave 提供读服务。
MMM 是 Google 技术团队开发的一款比较老的高可用产品,在业内使用的并不多,社区也不活跃, Google 很早就不再维护 MMM 的代码分支
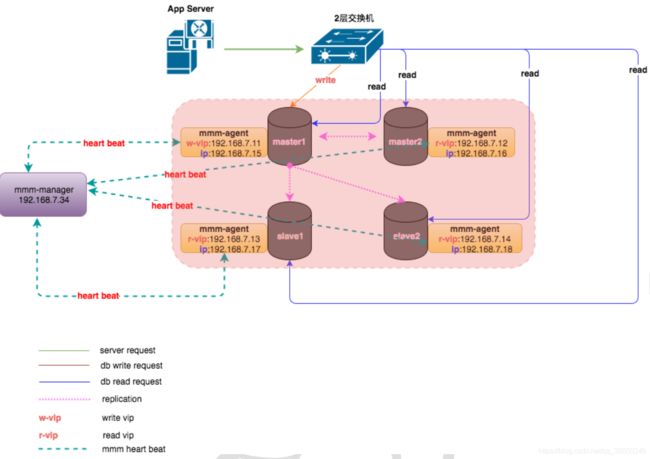
整个 MySQL 集群提供 1 个写 VIP(Virtual IP)和 N(N>=1)个读 VIP 提供 对外服务(美团 MySQL 集群中曾经用过 1 主 6 从,因此要 7 个 VIP,不便于管理)。每个 MySQL 节点均部署有一个 Agent(mmm-agent),mmm-agent 和 mmm-manager 保持通信状 态,定期向 mmm-manager 上报当前 MySQL 节点的存活情况(这里称之为心跳)。当 mmm- manager 连续多次无法收到 mmm-agent 的心跳消息时,会进行切换操作。
但存在很多缺点:
(1)VIP 的数量过多,管理困难;
(2)mmm-agent 过度敏感,容易导致 VIP 丢失,会误判 MySQL 节点异常; (3)mmm-manager 存在单点,一旦由于某些原因挂掉,整个集群就失去了高可用; (4)VIP 需要使用 ARP 协议,跨网段、跨机房的高可用基本无法实现,保障能力有限。
1.5 MHA
MHA(Master High Availability)在 MySQL 高可用方面是一个相对成熟的解决方案,是一 套优秀的作为 MySQL 高可用性环境下故障切换和主从提升的高可用软件。在 MySQL 故障切 换过程中,MHA 能在最大程度上保证数据的一致性,以达到真正意义上的高可用。

MHA 也可以扩展到如下的多节点集群:

各 MySQL Master 之间没有数据共享,为不同业务数据库。
优点:
方案成熟,故障切换时,MHA会做到较严格的判断,尽量减少数据丢失,保证数据一致性;
提供一个通用框架,可根据自己的情况做自定义开发,尤其是判断和切换操作步骤;
支持binlog server,可提高binlog传送效率,进一步减少数据丢失风险。
缺点:
- 需要在各个节点间打通ssh信任(这对某些公司安全制度来说是个挑战,因为如果某个节点被黑客攻破的话,其他节点也会跟着遭殃);
- 自带提供的脚本还需要进一步补充完善,当然了,一般的使用还是够用的。
- 虽然一个MHA Manger可以管理多个集群,但是没有大规模集群的经验。
- 高可用依赖于vip的方案,譬如采用keepalive来达到vip的切换,但是keepalive会限制切换的主机必须在一个网段,对于跨机房不在一个网段的服务器来说,就无法支持了。在大规模为每个MySQL集群安排一个vip也是难以实现的。keepalive在一个网段内,部署多套也会互相影响。
- 逻辑较为复杂,发生故障后排查问题,定位问题更加困难。
1.6 MySQL NDB Cluster
MySQL cluster 是官方集群的部署方案,通过使用 NDB 存储引擎实时备份冗余数据,实现数据库的高可用性和数据一致性。

MySQL Cluster 全部使用官方组件,不依赖于第三方软件,可以实现数据的强一致性;
由于 MySQL Cluster 架构复杂,部署费时(通常需要 DBA 几个小时的时间才能完成搭 建),而依靠 MySQL Cluster Manager 只需一个命令即可完成,但 MySQL Cluster Manager 是 收费的。并且业内资深人士认为 NDB 不适合大多数业务场景,而且有安全问题。因此,使 用的人数较少。
1.7 Galera
Galera Cluster 是集成了 Galera 插件的 MySQL 集群,是一种新型的,数据不共享的,高 度冗余的高可用方案。Galera 本身具有多主特性,所以 Galera Cluster 也就是 Multi-Master 的 集群结构。国外有 3 千多家客户使用 Galera,国内例如去哪儿
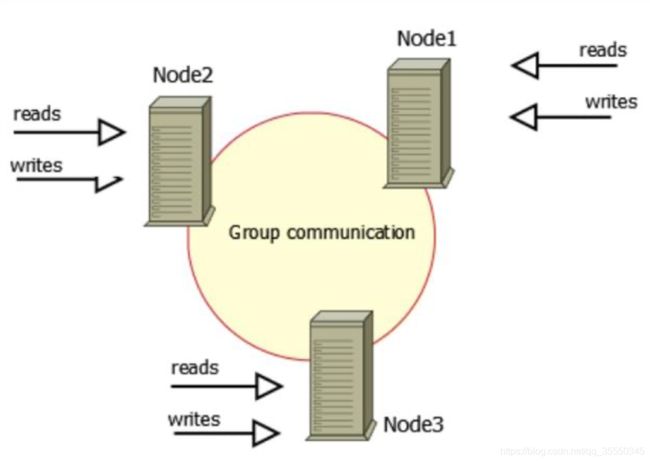
图中有三个实例,组成了一个集群,而这三个节点与普通主从架构不同,都可作为主节点,三个节点对等,这种一般称为 Multi-Master 架构,当有客户端要写入或读取数据时,随 便连接哪个实例都一样,读到的数据相同,写入某一节点后,集群自己会将新数据同步到其他节点上,这种架构不共享任何数据,是一种高冗余架构。
Galera replication 是一种 Certification based replication,保证 one-copy serializability。
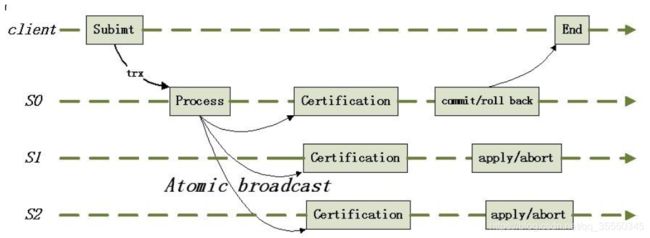
传统的 2PC(两阶段提交)做法:
(1)2PC 事务结束时,所有节点数据达到一致
(2)协调者与参与者之间通信,参与者之间无连接
(3)受网络状态影响较大
(4)两次通信,需要得到每个参与者的反馈后才能决定是否提交事务
因此 Galera replicateion 相对于 2PC 减少了网络传输次数,消除了等待节点返回“决定 是否冲突”的时间,从而可以提高了性能
Galera replication 原理总结:
(1)事务在本地节点执行时采取乐观策略,成功广播到所有节点后再做冲突检测
(2)检测出冲突时,本地事务优先被回滚
(3)每个节点独立、异步执行队列中的 WS事务 T 在 A 节点执行成功返回客户端后,其他节点保证 T 一定会被执行,因此有可能存在延迟,即虚拟同步
基于Galera的高可用方案主要有MariaDB Galera Cluster, Mysql Galera Cluster 和 Percona XtraDB Cluster(简称PXC),目前PXC用的会比较多一些。
PXC优点:
服务高可用;
数据同步复制(并发复制),几乎无延迟;
多个可同时读写节点,可实现写扩展,不过最好事先进行分库分表,让各个节点分别写不同的表或者库,避免让galera解决数据冲突;
新节点可以自动部署,部署操作简单;
数据严格一致性,尤其适合电商类应用;
完全兼容MySQL;
PXC缺点:
只支持InnoDB引擎;
所有表都要有主键;
不支持LOCK TABLE等显式锁操作;
加入新节点,开销大。需要复制完整的数据。
所有的写操作都将发生在所有节点上。
有多少个节点就有多少重复的数据。
不支持XA分布式事务协议
1.8 MGR
MySQL Group Replication(简称 MGR)是 MySQL 官方于 2016 年 12 月推出的一个全新 的高可用与高扩展的解决方案。MySQL 组复制提供了高可用、高扩展、高可靠的 MySQL 集群服务。
基于原生复制及 paxos 协议的组复制技术,并以插件的方式提供,提供一致数据安全保证,其原理如下图:

组复制不同于异步复制和半同步复制的主从模式,而是多主模式,是一种 share-nothing 的复制方案,其中每个 master server 都有完整的数据副本。其中组复制方案 MySQL Group Replication 是 MySQL 官方于 2016 年 12 月 12 日发布。
复制组是一个通过消息传递相互交互的 server 集群。通信层提供了原子消息和完全有 序信息交互等保障机制。MySQL 组复制以这些功能和架构为基础,实现了基于复制协议的多 主更新。复制组由多个 server 成员构成,并且组中的每个 server 成员可以独立地执行事务。 对于任何 RW 事务,提交操作并不是由始发 server 单向决定的,而是由组来决定是否提交。 最终,所有 server 成员以相同的顺序接收同一组事务,所有 server 成员以相同的顺序应用 相同的更改,以确保组内一致。
引入组复制,主要是为了解决传统异步复制和半同步复制可能产生数据不一致的问题。 组复制依靠分布式一致性协议 Paxos 协议,实现了分布式下数据的最终一致性,提供了真正 的数据高可用方案(是否真正高可用还有待商榷)。其提供的多写方案,给我们实现多活方案 带来了希望。
GR 提供了 single-primary 和 multi-primary 两种模式。single-primary 模式下,组内只有一 个节点负责写入,读可以从任意一个节点读取,组内数据保持最终一致;而 multi-primary 模 式即为多写方案,即写操作会下发到组内所有节点,组内所有节点同时可读可写,该模式也 是能够保证组内数据最终一致性。
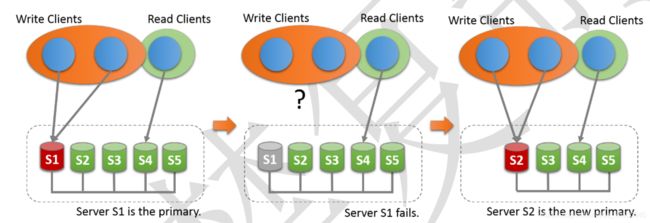

多主模式,即多写,没有选择新 primary 的概念(无需进行选举),group 内的所有机器 都是 primary 节点,同时可以进行读写操作,并且数据是最终一致的。
京东商城技术部对官方文档的译文: http://storage.360buyimg.com/brickhaha/Mysql.pdf
2 多说一句
选择方案时需考虑的几个方面:
1)如果数据库发生了宕机或者意外中断等故障,能尽快恢复数据库的可用性,尽可能的减少停机时间,保证业务不会因为数据库的故障而中断。
2)用作备份、只读副本等功能的非主节点的数据应该和主节点的数据实时或者最终保持一致。
3)当业务发生数据库切换时,切换前后的数据库内容应当一致,不会因为数据缺失或者数据不一致而影响业务。
建议:
对数据一致性要求较高的建议是基于Galera的PXC
尽可能减少数据丢失的建议MHA
允许丢一些数据的可以使用mysql + keepalived