Redis 的过期策略及手写LRU算法
一、Redis 的过期策略都有哪些?内存淘汰机制都有哪些?手写一下 LRU 代码实现?
1.1Redis 过期策略
Redis 过期策略是:定期删除+惰性删除。
所谓定期删除,指的是 Redis 默认是每隔 100ms 就随机抽取一些设置了过期时间的 key,检查其是否过期,如果过期就删除。
假设 Redis 里放了 10w 个 key,都设置了过期时间,你每隔几百毫秒,就检查 10w 个 key,那 Redis 基本上就死了,cpu 负载会很高的,消耗在你的检查过期 key 上了。注意,这里可不是每隔 100ms 就遍历所有的设置过期时间的 key,那样就是一场性能上的灾难。实际上 Redis 是每隔 100ms 随机抽取一些 key 来检查和删除的。
但是问题是,定期删除可能会导致很多过期 key 到了时间并没有被删除掉,那咋整呢?所以就是惰性删除了。这就是说,在你获取某个 key 的时候,Redis 会检查一下 ,这个 key 如果设置了过期时间那么是否过期了?如果过期了此时就会删除,不会给你返回任何东西。
1.2内存淘汰机制
Redis 内存淘汰机制有以下几个:
noeviction: 当内存不足以容纳新写入数据时,新写入操作会报错,redis默认配置的内存淘汰策略。
allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除LRU(最近时间段最少)使用的 key(这个是最常用的,生产上建议使用)。
allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个 key,这个一般没人用吧,为啥要随机,肯定是把最近最少使用的 key 给干掉啊。
volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的 key(这个一般不太合适)。
volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个 key。
volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的 key 优先移除。
allkeys-lfu:对所有key使用LFU(最近使用频率最少)算法进行删除。
volatile-lfu:对所有设置了过期时间的key使用LFU算法进行删除。
二、手写一下 LRU算法实现
使用LinkedHashMap,一个有序的HashMap。
LinkedHashMap继承了HashMap,拥有HashMap的所有特性,同时LinkedHashMap在增加了head和tail指针,用于实现双向链表。
LinkedHashMap默认按照插入顺序保存数据,新的数据插入双向链表尾部。
LinkedHashMap中有构造方法支持按顺序访问,最新访问的数据放到链表尾部。
其中一个使用场景是Excel的导出功能
public void exportYS(List data) {
LinkedHashMap<String, String> columnName = new LinkedHashMap<String, String>();
columnName.put("QA_PRODUCTLINE", "产品线 ");
columnName.put("QA_THETYPE", "类型");
columnName.put("THEYEAR", "年度");
columnName.put("QUARTER", "季度");
columnName.put("TOTALPRICEOFQUOTATION", "预算金额");
columnName.put("OUTSOURCING", "预算总金额-外购");
columnName.put("SELFCONTROL", "预算总金额-自制");
new ExportExcelUtil().exportExcel(response, request, "", true, data, null, columnName);
}
1.1定义一个类继承LinkedHashMap
package com.test1;
import java.util.LinkedHashMap;
import java.util.Map;
public class LRULinkedMap<K,V> extends LinkedHashMap<K,V> {
private int size;
public LRULinkedMap(int initialCapacity,float loadFactor,boolean accessOrder){
//super()表示父类的构造方法:LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder);
//initialCapacity:初始容量
//loadFactor:装载因子
//accessOrder:访问顺序 false,所有的Entry按照插入的顺序排列;true,所有的Entry按照访问的顺序排列
super(initialCapacity,loadFactor,accessOrder);
this.size = initialCapacity;
}
/**
* 重写LinkedHashMap的removeEldestEntry方法
* 当LRU元素超过容量上限size后,删除最不经常使用的
* @param eldest
* @return
*/
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > size;
}
}
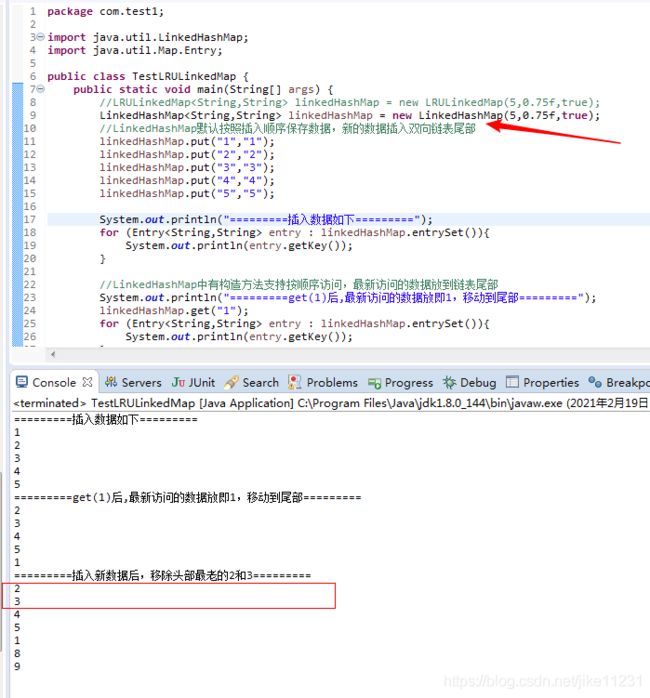
1.2定义一个测试类TestLRULinkedMap
package com.test1;
import java.util.Map.Entry;
public class TestLRULinkedMap {
public static void main(String[] args) {
LRULinkedMap<String,String> linkedHashMap = new LRULinkedMap(5,0.75f,true);
//LinkedHashMap默认按照插入顺序保存数据,新的数据插入双向链表尾部
linkedHashMap.put("1","1");
linkedHashMap.put("2","2");
linkedHashMap.put("3","3");
linkedHashMap.put("4","4");
linkedHashMap.put("5","5");
System.out.println("=========插入数据如下=========");
for (Entry<String,String> entry : linkedHashMap.entrySet()){
System.out.println(entry.getKey());
}
//LinkedHashMap中有构造方法支持按顺序访问,最新访问的数据放到链表尾部
System.out.println("=========get(1)后,最新访问的数据放即1,移动到尾部=========");
linkedHashMap.get("1");
for (Entry<String,String> entry : linkedHashMap.entrySet()){
System.out.println(entry.getKey());
}
System.out.println("=========插入新数据后,移除头部最老的2和3=========");
linkedHashMap.put("8","8");
linkedHashMap.put("9","9");
for (Entry<String,String> entry : linkedHashMap.entrySet()){
System.out.println(entry.getKey());
}
}
}
测试结果
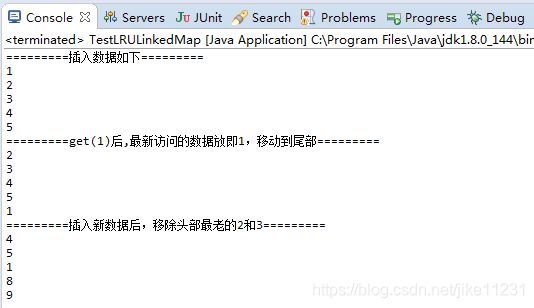
这里自定义LRULinkedMap类继承LinkedHashMap,并且重写removeEldestEntry方法,如果不重写,不会删除最老的数据,测试结果如下:
参考文章
https://doocs.github.io/advanced-java/#/./docs/high-concurrency/redis-expiration-policies-and-lru
https://blog.csdn.net/qq_32100465/article/details/90690640
https://blog.csdn.net/czxlylc/article/details/102763156