solr初体验
【1】http://cxshun.iteye.com/blog/1039445
由于工作原因,这段时间接触到solr,一个基于lucene的企业级搜索引擎。不怎么了解它的童鞋可以去GOOGLE一下。
下面开始正题:
1)要开始solr的学习,首先当然是要下载它啦(这是一句废话),可以到http://www.apache.org/dyn/closer.cgi/lucene/solr/这里去下载,最新的是1.4.1。下完后当然要解压啦(这也是废话)。我们看到它的结构是这样的。
相信搞JAVA的同志们应该都大概了解对应的文件夹的意思啦,在dist里面是它的一些JAR包,当中包含了一个war包,这个是我们做例子时用到的项目。直接把它丢到tomcat的webapps里面去。
example目录里面有一些solr的索引数据,它自带了一个jetty方便运行,可以直接运行java -jar start.jar就可以运行jetty,但jetty的默认端口是8983,这个是跟tomcat不同的地方,要注意啦。
2)搞定了这些之后,那么我们应该继续来试运行一下这个东西啦。solr最重要的东西就是solr home,这个东西指定了solr建立的索引文件的存放位置。不知道是什么东西,可以先不用管它,一步步来也许就会明白了。
进到tomcat文件夹conf\Catalina\localhost这个文件夹内,建立一个solr.xml(其实名字是随便的,这里起的名字跟以后访问的项目名字一致,不过为了好找,还是跟部署的项目名一样吧),这里面的内容呢,其实很简单,就和下面类似:
- <Context docBase="D:/server/apache-tomcat-6.0.32/webapps/apache-solr-1.4.1.war" reloadable="true">
- <Environment name="solr/home" type="java.lang.String" value="E:/framework/libPack/apache-solr-1.4.1/example/solr" override="true" />
- </Context>
这个Context相信大家都知道罗,它是指定了war包的位置,当启动tomcat后它会自动被部署到webapps目录下,这也是eclipse所集成tomcat用的部署方式。而reloadable="true"则表明可以重新加载,即当这个部署内容改变时,它会自动进行加载。
下面的solr/home是重点啦,type是固定的,先不管,value指定的就是它用的索引目录。override当然就是覆盖啦,如果存在则覆盖。
这个solr/home其实在solr的下载包中已经带有一个,我们可以找到solr目录下的example/solr这个目录,下面就是我们所说的solr/home,其实当中最重要的还是config目录下的solrconfig.xml,这个是solr的主要配置文件,可以在里面找到<dataDir>${solr.data.dir:./solr/data}</dataDir>这样一句,它指定了索引记录放置的位置,我们启动tomcat后它会在我们当前的目录下生成solr/data文件夹,里面就是索引文件。如果我们从tomcat的bin启动,那么它会在bin目录下生成solr/data文件夹,可以根据自己需要进行修改,只要把./solr/data改成想让它放在目录就可以了。
这样配置完成后,我们启动tomcat之后在浏览器输入http://localhost:8080/solr/admin就可以看到solr的管理界面啦。

这样我们的配置就大功告成了。
曾经看过javaeye上一位朋友问过淘宝上的分面搜索是怎么实现的,当时有一位高人说是用solr,没想到它可以做出这么牛的东西,还有好多要学习呢。
---------------------------------------------------------------------------
【2】http://cxshun.iteye.com/blog/1040656
接着上篇http://cxshun.iteye.com/blog/1039445,我们讲了怎么初始化配置solr,并运行。问题来了,当我们配置完成后,索引当中并没有任何东西,就是说我们查询得到的结果永远是0。
现在这篇文章,我们要讲的就是如果添加数据和删除数据,并体验一下solr的基本请求参数的用法。
1)首先,我们必须知道,solr添加数据类型可以有多种格式,最常用的是XML和JSON,这两种的可读性是最好的。在solr的example/exampledocs文件夹内有自带一些XML格式的文件,便于我们进行添加数据。

首先呢,又是一些废话,当然是启动example自带的jetty啦,还是上次的命令,java -jar start.jar。
接着另外开一下cmd,进入到example/exampledocs文件夹内,运行java -jar post.jar *.xml,这里的*.xml代表文件夹内的所有XML文件,当然你也可以选择其他一个进行添加,执行后我们看到执行结果。
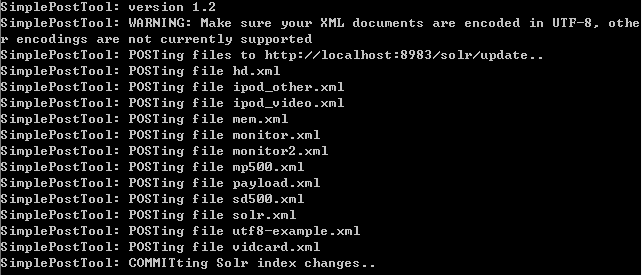
看到最后一句,它表明提交这次索引所有的变化。这个提交的设置我们在后面会看到它的用法。
2)这里我们再进入到solr的管理页面,http://localhost:8983/solr/admin,我们直接搜索solr,看到页面大概如下:

我们进行搜索的结果默认是用XML格式显示,当然我们可以让它用JSON格式来显示,只要加上wt=json即可,加上后我们看到的结果为:

可以看到正确的结果。
http://localhost:8983/solr/select/?q=solr&version=2.2&start=0&rows=10&indent=on&wt=json下面我们分析一下这个链接中参数的意义,q当然是搜索的内容啦,version暂时可以不管,用处不在,start和rows与hibernate中的分页参数类似,指开始的记录位置和查询的条数,indent指返回代码的缩进,可以试一下不加这个和加这个的区别,wt则是返回的结果格式。
3)上面是我们用的它自带的XML文件提交的结果,下面我们自己来写一个。为了方便,我们就参照它的救命文件写一个。我们找到schema.xml可以看到:

这个是它允许我们提交的field的名称,我们就参照这些字段写几个试试吧。我把这个文件命名为test.xml
- <add>
- <doc>
- <field name="id">Donnie Yen</field>
- <field name="text">Great</field>
- </doc>
- </add>
接着我们用java -jar post.jar test.xml出现下面的结果:

这表明我们的数据已经提交成功,我们可以搜索一下:
http://localhost:8983/solr/select/?q=text:great&version=2.2&start=0&rows=10&indent=on
这表明我们提交的数据已经成功更新到索引了。
4)说了添加,现在也该来删除一些东西了,我们想删除我们刚才添加的那条记录,我们可以发送命令java -Ddata=args -jar post.jar "<delete><id>Donnie Yen</id></delete>"(这个命令中的-Ddata=args表明数据是中参数中获取),出现

则我们删除成功,不确定?那么我们再去查一下:

没了吧,证明我们删除成功了。
这些东西不难吧。solr用得比较多的东西就是分面浏览,也就是facet navigation。下面我们来学习一下。
5)分面浏览指的是像淘宝的功能一样,我们搜索一种产品,它会在上面再根据类别分出好多小类,直接看图:

我们看到它又分出了好多类,这种效果就叫分面浏览。
solr可以轻松做到分面浏览,比如我们在浏览器输入http://localhost:8983/solr/select/?q=solr&version=2.2&start=0&rows=10&indent=on&facet=true&facet.field=name&facet.query=price:[300%20TO%20400],我们可以看到:
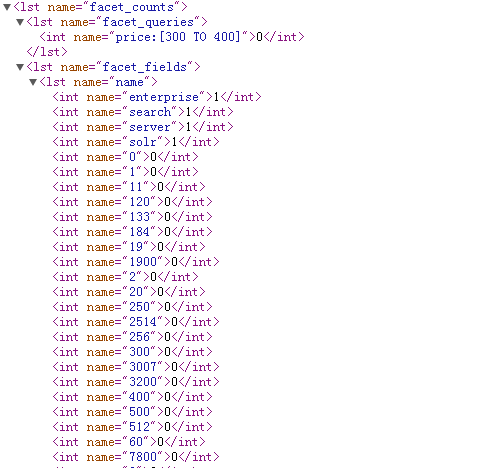
这就是分面浏览的结果,它根据每个值再重新统计,统计出该类别下有多少个值。分面浏览的参数比较多,大家可以上WIKi上面看看http://wiki.apache.org/solr/SimpleFacetParameters。
--------------------------------------------------------------------------------------------------------------
【3】http://cxshun.iteye.com/blog/1041742
前两天,学习了solr的基本用法,接下来我们就开始真正来学习一下solr。学习一下它的文件结构,配置文件等。
以我们现在学习的阶段,最重要的文件夹就是example文件夹,这个里面包含了许多我们要学习的东西。
我们再来看一下该文件夹结构

我们看到这样的文件结构,文件夹的意思大家肯定都看得懂,这里只介绍两个文件夹,multicore和solr。
multicore是多个solr实例时才需要用到,现在我们暂时没用,先不管它。solr是自带的一个solr.home,这个是我们此次介绍的重点。
进入此文件夹,我们可以看到如下的结构:

bin文件夹为我们有额外的处理脚本时,需要放在这里,这里暂时没用到,我们先跳过。
conf是solr的配置文件所在,这里是重点。
data为索引目录。
由于我以为运行过,所以有这个data.bak目录,这具是以前的备份。
我们主要来看一下conf文件夹内的配置文件:
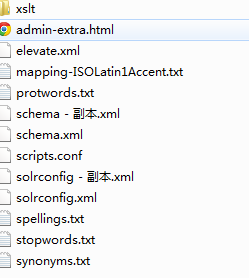
这里带副本的是我的备份文件。最主要的文件是schema.xml和solrconfig.xml,其余的如stopwords.txt为停顿词,当索引和查询时遇到这些词会自动忽略,其他文件,我们暂时不用,先不讲了。
打开solrconfig.xml我们可以看到<dataDir>这个标签,默认情况下是这样的
<dataDir>${solr.data.dir:./solr/data}</dataDir>
它默认在当前目录下的solr目录下创建data目录来存放索引。这就是为什么当我们把solr.home设置成这个时,在tomcat的bin文件夹内启动时会生成solr/data文件夹。因为我们启动tomat时的当前目录为bin。
当然这个不是solr配置错误,对于它自带的jetty服务器来说,它是正确的,因为当前目录,正好是solr的目录。
这个文件我们需要配置的东西不多,先讲到这里,以后用到时再慢慢讲解。
接下来我们看一下重点的schema.xml,这个文件是对我们索引字段的说明,我们可以索引什么field都在这里进行了说明。
我们可以看到里面有一大堆注释,其实看里面的注释,大部分都是可以理解的。这个文件的配置跟我们以后需要进行的中文分词的集成有很大关系,所以这个文件要多看看。
我们看到types标签,而在它里面有一大堆fieldType,里面也有一大堆属性,这里大概介绍一下:
fieldType是定义索引的field类型,它有好几个属性,最主要的是name和class:
name是类型的名称,class是相应的solr中的类。还有两个属性看英文注释可能比较难理解,是sortMissingLast和sortMissingFirst,这两个属性是指当查找出来的内容为空时,它被排在哪里,当sortMissingLast为true时,表示放在最后,sortMissingFirst为true时,表示放在最前。为false时相反。
注意,我们看到后面时发现有fieldType里面有<Analyzer>标签,这个是用于配置分词器的,这个我们以后再说。
接着是<fields>标签和在它里面的<field>,field当然就是我们在索引的内容啦。
它有属性indexed和stored分别对应是否索引和保存,另外还有一个multiValued表示是否允许多值。

这里我们看到features有好几个值,而我们看到配置文件中配置的features也是这样的:
- <field name="features" type="text" indexed="true" stored="true" multiValued="true"/>
它表示我们索引的field有多个值,如果这里没配置,在发送数据的时候会报错。
这里的type是对应我们前面配置的fieldType。
另外有一个<dynamicField>这是一个动态匹配的域,
- <dynamicField name="*_i" type="int" indexed="true" stored="true"/>
我们看到它的name指定了通配符,它指的是可以匹配所有以_i结尾的名称的field,如果我们指定
- <dynamicField name="*"/>
那我们就可以匹配所有的field。
接下来,我们看到:
- <uniqueKey>id</uniqueKey>
- <defaultSearchField>text</defaultSearchField>
- <solrQueryParser defaultOperator="OR"/>
- <copyField source="cat" dest="text"/>
这里应该看英文就可以看明白了,最主要是最下面的copyField,它是指复制field,它会把在source field里的值拷贝到text field里面,这样方便进行索引。注意,这里一般也只有对多值的才会这样做,也即是配置了multiValued为true的field才用copyField.
--------------------------------------------------------------------------------------------------------------
【4】http://cxshun.iteye.com/blog/1043200
前几次我们讲到了solr的基本用法和配置文件,接下来就开始进入我们真正的代码之旅啦。
1)首先以一个简单的程序来开头:
- public static void main(String[] args) throws SolrServerException, IOException, ParserConfigurationException, SAXException{
- //设置solr.home,注意这时通过环境变量是solr.solr.home
- System.setProperty("solr.solr.home","E:\\solr");
- //初始化容器,让它加载solr.home的配置文件
- CoreContainer.Initializer initializer = new CoreContainer.Initializer();
- CoreContainer coreContainer = initializer.initialize();
- EmbeddedSolrServer solrServer = new EmbeddedSolrServer(coreContainer,"");
- //构造参数列表
- SolrQuery solrQuery = new SolrQuery();
- Map<String,String> map = new HashMap<String,String>();
- map.put(FacetParams.FACET_DATE, "manufacturedate_dt");
- map.put(FacetParams.FACET_DATE_START,"2004-01-01T00:00:00Z");
- map.put(FacetParams.FACET_DATE_END,"2010-01-01T00:00:00Z");
- map.put(FacetParams.FACET_DATE_GAP,"+1YEAR");
- map.put("indent","on");
- map.put("wt","xml");
- map.put("hl.fl","name");
- SolrParams params = new MapSolrParams(map);
- solrQuery.add(params);
- solrQuery.setFacet(true);
- solrQuery.setFields("name,price,score");
- solrQuery.setQuery("solr");
- solrQuery.setSortField("price",SolrQuery.ORDER.asc);
- solrQuery.setHighlight(true);
- System.out.println(solrQuery.toString());
- QueryResponse queryResponse = solrServer.query(solrQuery);
- System.out.println(queryResponse.toString());
- System.out.println("共找到:"+queryResponse.getResults().getNumFound()+"个结果");
- //解析返回的参数
- SolrDocumentList sdl = (SolrDocumentList)queryResponse.getResponse().get("response");
- for (int i = 0; i< sdl.size(); i++){
- Object obj = sdl.get(i).get("manufacturedate_dt");
- String date = "";
- if (obj!= null){
- date = new SimpleDateFormat("yyyy-MM-dd").format((Date)obj);
- }
- System.out.println(((SolrDocument)sdl.get(i)).get("name")+":"+date+":"+(sdl.get(i).get("price")));
- }
- }
这时我们所用到的是EmbeddedSolrServer,它是用于嵌入式地solr服务,这里我们不需要向外提供服务,所以我们就用到这个。另外有一个
CommonsHttpSolrServer这个类是用于发送指令的服务,例如我们需要发送HTTP命令来查询,就可以用这个。
下面我们分析一下代码,首先,我们设置了一个环境变量的名称为solr.solr.home,是这个,你没看错,确实是要这样。接下来我们初始化容器,让它加载solr.home的配置文件等。接下来的一系统代码就是构造参数列表。
我们构造完成后的参数列表是这样的:facet.date.start=2004-01-01T00%3A00%3A00Z&indent=on&facet.date=manufacturedate_dt&hl.fl=name&facet.date.gap=%2B1YEAR&wt=xml&facet.date.end=2010-01-01T00%3A00%3A00Z&facet=true&fl=name%2Cprice%2Cscore&q=solr&sort=price+asc&hl=true
跟我们直接在浏览器输入的不太一样,因为它是进行过编码的。构造完成后我们就可以用solrServer进行查询了。
查询得到的结果是JSON格式的,注意,通过程序来查询得到的都是JSON格式,而不是XML格式,不过这样更好,方便我们进行接下来的解析。
接下来的代码就是解析内容啦,应该很容易看懂的。
2)接下来的我们就尝试自己写一个程序来进行索引,而不用post.jar。
程序代码如下:
- public static void main(String[] args) throws IOException, ParserConfigurationException, SAXException{
- System.setProperty("solr.solr.home","e:\\solrIndex");
- //这下面三行代码主要是用于加载配置文件
- SolrConfig solrConfig = new SolrConfig("E:\\solrIndex\\conf\\solrconfig.xml");
- FileInputStream fis = new FileInputStream("E:\\solrIndex\\conf\\schema.xml");
- IndexSchema indexSchema = new IndexSchema(solrConfig,"solrconfig",fis);
- SolrIndexWriter siw = new SolrIndexWriter("solrIndex","E:\\solrIndex",new StandardDirectoryFactory()
- ,true,indexSchema);
- Document document = new Document();
- document.add(new Field("text","测试一下而已",Field.Store.YES,Field.Index.ANALYZED,Field.TermVector.WITH_POSITIONS_OFFSETS));
- document.add(new Field("test_t","再测试一下而已",Field.Store.YES,Field.Index.ANALYZED,Field.TermVector.WITH_POSITIONS_OFFSETS));
- siw.addDocument(document);
- siw.commit();
- siw.close();
- SolrCore solrCore = new SolrCore("E:\\solrIndex",indexSchema);
- SolrIndexSearcher sis = new SolrIndexSearcher(solrCore,indexSchema,"solrIndex",
- new StandardDirectoryFactory().open("E:\\solrIndex"),true);
- TopDocs docs = sis.search(new TermQuery(new Term("test_t","再")),1);
- System.out.println("找到"+docs.totalHits+"个结果 ");
- for (int i = 0; i < docs.scoreDocs.length; i++) {
- System.out.println(sis.doc(docs.scoreDocs[i].doc).get("test_t"));
- }
- }
代码不难理解,所以就没写注释了。主要是那段加载配置文件的代码。接下来是添加索引,然后是查询索引,删除的比较简单,直接一句代码
- solrServer.solrServer.deleteById("SOLR1000");
或者
- solrServer.deleteByQuery()
都比较简单。
3)接下来我们讲一下,很可能会在项目中用到的,就是中文分词,中文分词有蛮多的,有IK,Paoding,mmseg4j,还有另外一些中科院什么地方的。但个人建议用IK或者mmseg4j,这两个有solr都有比较直接的支持,paoding也可以,但可能需要自己写类继承BaseTokenizerFactory然后再进行配置,不难。
上面的例子就是用到中文分词了,如果你发现找不到结果,那很正常,因为还没添加中文分词,你可以把中文改成英文,再查一下,就可以查出来了。
需要添加中文分词,我们要在schema.xml中做文章。找到types标签,在里面找到你想要进行中文分词的类型,比如text类型,我们想要让它的内容用中文分词来进行分析,可以进行配置:
- <analyzer type="index">
- <tokenizer class="org.wltea.analyzer.solr.IKTokenizerFactory"/>
- <filter class="solr.StopFilterFactory"
- ignoreCase="true"
- words="stopwords.txt"
- enablePositionIncrements="true"
- />
- <filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="1" catenateNumbers="1" catenateAll="0" splitOnCaseChange="1"/>
- <filter class="solr.LowerCaseFilterFactory"/>
- <filter class="solr.SnowballPorterFilterFactory" language="English" protected="protwords.txt"/>
- </analyzer>
- <analyzer type="query">
- <tokenizer class="org.wltea.analyzer.solr.IKTokenizerFactory"/>
- <filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
- <filter class="solr.StopFilterFactory"
- ignoreCase="true"
- words="stopwords.txt"
- enablePositionIncrements="true"
- />
- <filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="0" catenateNumbers="0" catenateAll="0" splitOnCaseChange="1"/>
- <filter class="solr.LowerCaseFilterFactory"/>
- <filter class="solr.SnowballPorterFilterFactory" language="English" protected="protwords.txt"/>
- </analyzer>
你可以先不理解filter的那些东西,但你一定要理解tokenizer这些地方的配置,它配置了你想要应用的分词器,它必须继承于BaseTokenizerFactory。我们看到analyzer有一个type属性,它表示你要在哪个阶段运用此分词器,如果索引和查询都要用,我们可以不写type,这样solr就会在索引和查询时都使用此分词器,这样配置完成后就可以进行中文分词的测试啦。我们重新把上面的例子添加中文进行索引,然后查询出来,看有没有问题。我的运行结果如下:

我们找到了结果,证明我们的中文分词已经没问题了。