什么是自注意力机制(Self-attention)
文章目录
- 1. Self-attention的基本概念
-
- 1.1. Self-attention的单个输出
- 1.2. Self-attention的并行计算
- 1.3. Multi-head Self-attention
- 1.4. Positional Encoding
- 2. Self-attention for Image
-
- 2.1. Self-attention v.s. CNN
- 2.2. Self-attention v.s. RNN
RNN网络的的输入是一个定长的向量。例如,分类网络的输入图片大小是固定的。当网络的输入变为变长的向量时,RNN网络就不再适用了,自注意力机制(Self-attention)可以解决这一问题,通过“动态”地生成不同连接地权重。
1. Self-attention的基本概念
如下图所示,自注意力机制的输入为长度为 N N N( N N N可变化)的向量,输出同样为长度为 N N N的向量。

1.1. Self-attention的单个输出
自注意力机制根据各个输入向量的关联输出,使得每个输出向量包含输入向量的上下文关系。首先需要计算两个输入向量的关联 α \alpha α。

如下图所示为Dot-product和Additive两种计算关联 α \alpha α的方法。
- Dot-product: α = ( W q a 1 ) ⋅ ( W k a 2 ) \alpha=(W^qa^1)\cdot(W^ka^2) α=(Wqa1)⋅(Wka2)
- Additive: α = W tanh ( W q a 1 ⊕ W k a 2 ) \alpha=W\tanh(W^qa^1\oplus W^ka^2) α=Wtanh(Wqa1⊕Wka2), ⊕ \oplus ⊕表示拼接
其中 W q W^q Wq和 W k W^k Wk分别为计算query和key的权重矩阵,通过学习得到。

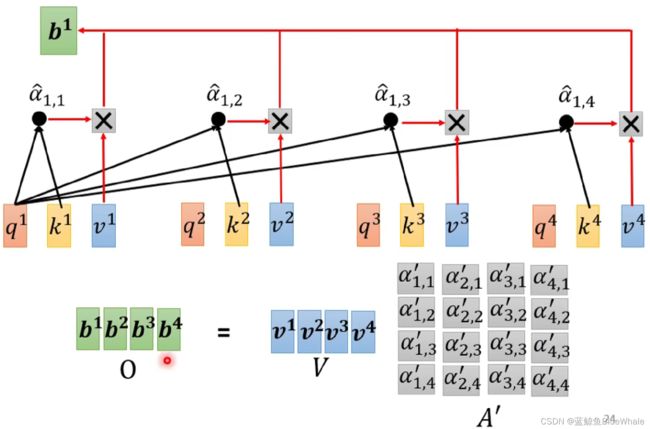
假设使用最常用的Dot-product方法,分别计算输入向量 a 1 a^1 a1和向量 a 1 , a 2 , a 3 , a 4 a^1,a^2,a^3,a^4 a1,a2,a3,a4的关联性,并经过softmax处理(或relu等其他方法),得到的关联性分别为 α 1 , 1 ′ , α 1 , 2 ′ , α 1 , 3 ′ , α 1 , 4 ′ \alpha'_{1,1},\alpha'_{1,2},\alpha'_{1,3},\alpha'_{1,4} α1,1′,α1,2′,α1,3′,α1,4′

根据输入向量 a 1 a^1 a1和向量 a i a^i ai的关联性的 α i , 1 ′ \alpha'_{i,1} αi,1′( i = 1 , 2 , 3 , 4 i=1,2,3,4 i=1,2,3,4),可以计算得到 a 1 a^1 a1对应的输出向量 b 1 = ∑ i α 1 , i ′ v i b^1=\sum_i\alpha'_{1,i}v^i b1=i∑α1,i′vi其中 v i = W v a i v^i=W^va^i vi=Wvai, W v W^v Wv为计算value的权重矩阵,通过学习得到。
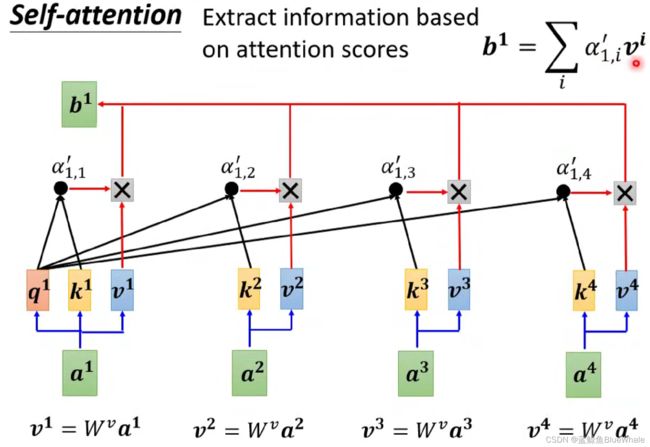
同样地,根据输入向量 a 2 a^2 a2计算向量 a i a^i ai的关联性的 α i , 1 ′ \alpha'_{i,1} αi,1′( i = 1 , 2 , 3 , 4 i=1,2,3,4 i=1,2,3,4),然后计算 a 2 a^2 a2对应的输出向量 b 2 = ∑ i α 2 , i ′ v i b^2=\sum_i\alpha'_{2,i}v^i b2=i∑α2,i′vi其中 v i = W v a i v^i=W^va^i vi=Wvai。
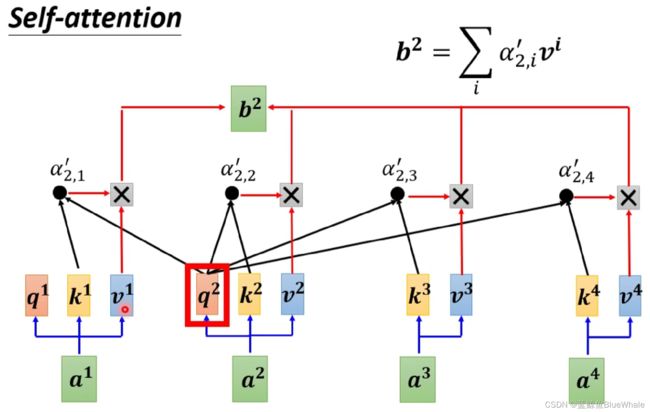
将相同的过程应用于 b 2 , b 3 , b 4 b^2,b^3,b^4 b2,b3,b4,就可以得到输入向量 a 1 , a 2 , a 3 , a 4 a^1,a^2,a^3,a^4 a1,a2,a3,a4对应的自注意力机制的输出。
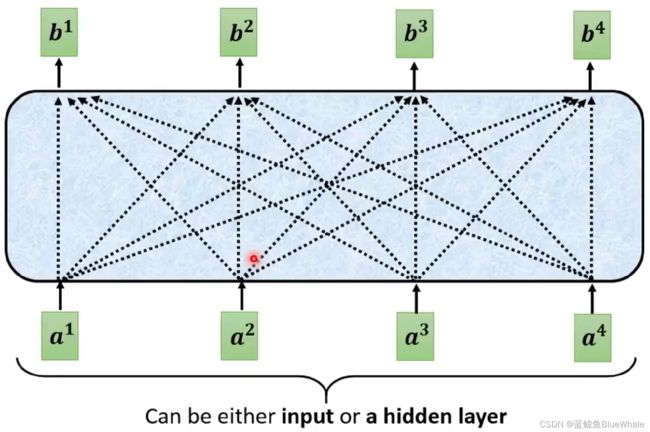
1.2. Self-attention的并行计算
注意到输出 b 1 , b 2 , b 3 , b 4 b^1,b^2,b^3,b^4 b1,b2,b3,b4是无先后顺序的,因此可以同时计算。在机器学习中,通过矩阵运算实现。
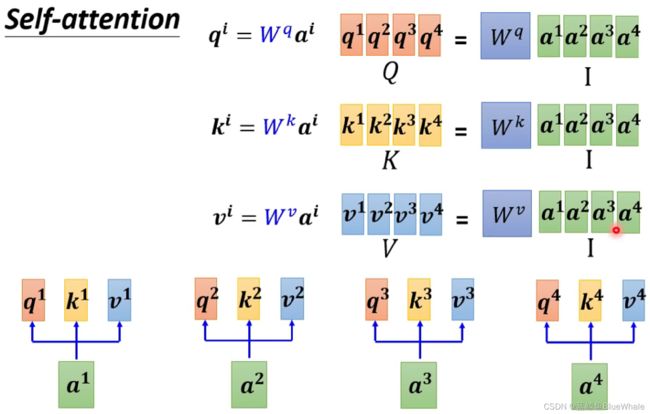
得到: Q = W q I Q=W^qI Q=WqI K = W k I K=W^kI K=WkI V = W v I V=W^vI V=WvI之后使用Dot-product方法用矩阵计算输入向量 a 1 a^1 a1和向量 a 1 , a 2 , a 3 , a 4 a^1,a^2,a^3,a^4 a1,a2,a3,a4的关联性为 α 1 , 1 ′ , α 1 , 2 ′ , α 1 , 3 ′ , α 1 , 4 ′ \alpha'_{1,1},\alpha'_{1,2},\alpha'_{1,3},\alpha'_{1,4} α1,1′,α1,2′,α1,3′,α1,4′:

同理可以计算输入向量 a 1 , a 2 , a 3 , a 4 a^1,a^2,a^3,a^4 a1,a2,a3,a4和向量 a 1 , a 2 , a 3 , a 4 a^1,a^2,a^3,a^4 a1,a2,a3,a4的关联性矩阵并做softmax处理:

得到: A ′ = s o f t m a x ( K T Q ) A'=softmax(K^TQ) A′=softmax(KTQ),最后,同理通过矩阵的方式得到输出 O O O:
即: O = V A ′ O=VA' O=VA′整个自注意力机制从输入 I I I到输出 O O O的流程为:
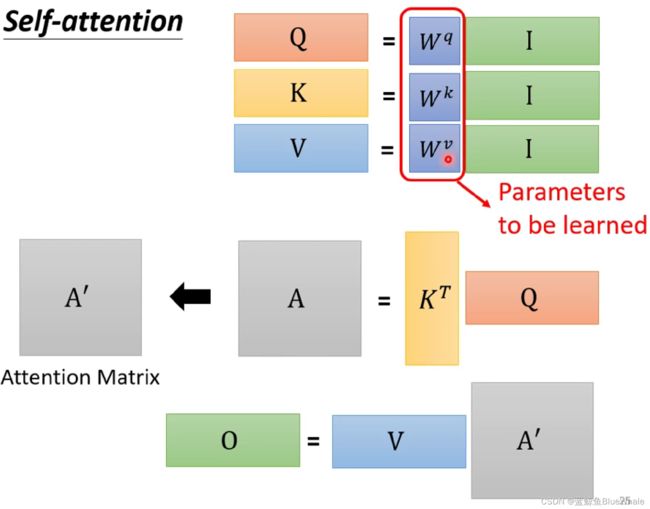
用公式的形式为 O = V s o f t m a x ( K T Q ) O=Vsoftmax(K^TQ) O=Vsoftmax(KTQ)
1.3. Multi-head Self-attention
对于多头自注意力机制,原本的参数矩阵 W q , W k , W v W^q,W^k,W^v Wq,Wk,Wv都被分割成2个新的矩阵(以2头自注意力机制为例),在进行输出计算的时候,分别计算输入和每一个分割后的矩阵的计算结果。
对于第1个头的结果 b i , 1 b^{i,1} bi,1,将输入和 W q , 1 , W k , 1 , W v , 1 W^{q,1},W^{k,1},W^{v,1} Wq,1,Wk,1,Wv,1计算:
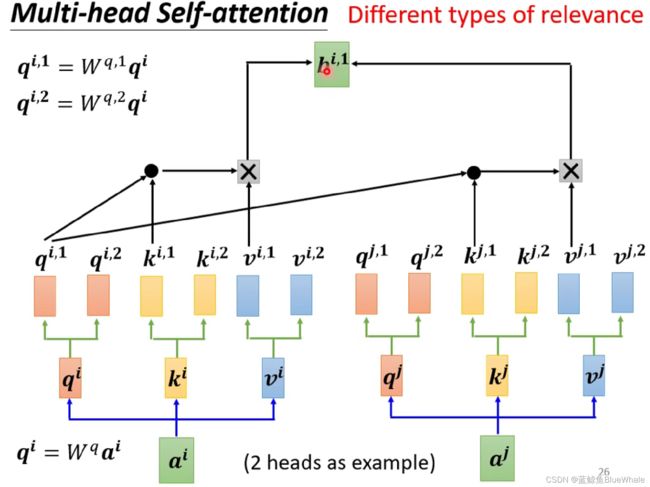
对于第2个头的结果 b i , 2 b^{i,2} bi,2,将输入和 W q , 2 , W k , 2 , W v , 2 W^{q,2},W^{k,2},W^{v,2} Wq,2,Wk,2,Wv,2计算:

1.4. Positional Encoding
注意到,在之前的自注意力机制中,没有位置信息,即调换 a 1 a^1 a1和 a 4 a^4 a4的顺序对结果也没有任何影响,但是在实际情况中,有时候位置的信息也是重要的,这时候就需要Positional Encoding。
在每一个位置上设置一个位置向量 e i e^i ei,使用时和输入向量 a i a^i ai求和
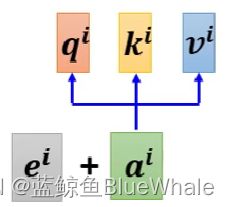
e i e^i ei可以通过人为给定或者机器学习得到,下图为一些 e i e^i ei:

2. Self-attention for Image
可以将一张图片考虑为一个向量的结合,每一个像素点的RGB三个元素组成一个向量,因此就可以用自注意力机制进行图像的处理:

两个用自注意力机制处理图像的例子:
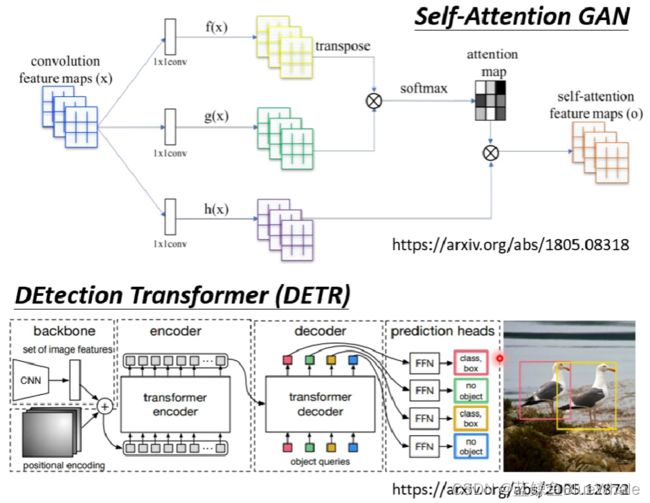
2.1. Self-attention v.s. CNN
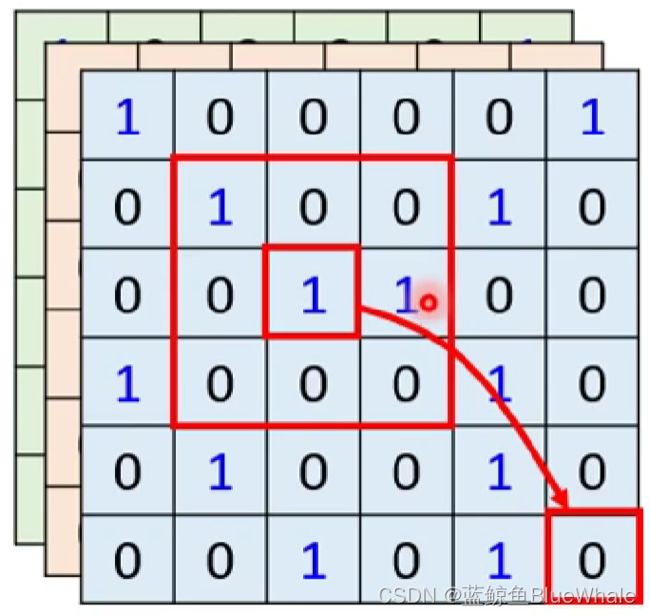
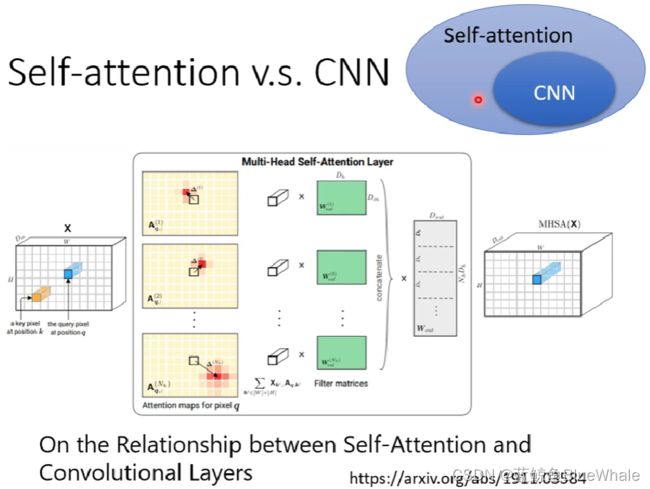
由于CNN只考虑一个 K × K K \times K K×K的接受域内的像素,而self-attention的接受域为整张图片,如下图所示。因此CNN可以视为一个简化版的self-attention。
事实上,如下的文章严谨地证明了这一结论:只要设定合适的参数,self-attention可以达到和CNN一样的效果。
由于CNN可以视为一个简化版的模型,而self-attention相对复杂。因此CNN适合于相对较小地数据集,而self-attention适合于更大的数据集。如下图所示,self-attention在大数据集上的效果更好。

2.2. Self-attention v.s. RNN
Self-attention和RNN的主要区别在于:
- Self-attention可以考虑全部的输入,而RNN似乎只能考虑之前的输入(左边)。但是当使用双向RNN的时候可以避免这一问题。
- Self-attention可以容易地考虑比较久之前的输入,而RNN的最早输入由于经过了很多层网络的处理变得较难考虑。
- Self-attention可以并行计算,而RNN不同层之间具有先后顺序。

课程链接:不会还有人没听【2022】最新 李宏毅大佬的深度学习与机器学习吧???