Pytorch利用ddddocr辅助识别点选验证码
本篇文章的主要目的是识别点选验证码,其中利用ddddocr来辅助识别,这样整体识别验证码的步骤将会非常简单,具体有多简单,请看步骤
首先展示一下点选验证码的数据集



**数据集介绍:**可以看到,该点选验证码识别是有一张图主背景图,提示需要依次点击哪些字,基本上大部分点选验证码都是这样,按照语序点击主背景图上的字,可能有些是直接以文本的形式告诉你,有些是给你一张图,这样的话识别起来更麻烦一些,因为还要识别语序图上的字
具体步骤,步骤其实就很简单了,就是做目标检测,识别到哪个字在哪个位置,然后做匹配,调整下顺序即可,单纯的目标检测可以用yolov5完成,但是可能有些人不会训练,或者觉得麻烦,所以我这边也可以采用另一种方式,就是将检测任务和分类任务分开进行,这里ddddocr就可以用上了, ddddocr负责检测任务,然后我们自己实现分类任务,如下看具体步骤
1、检测文字位置
ddddocr github 链接
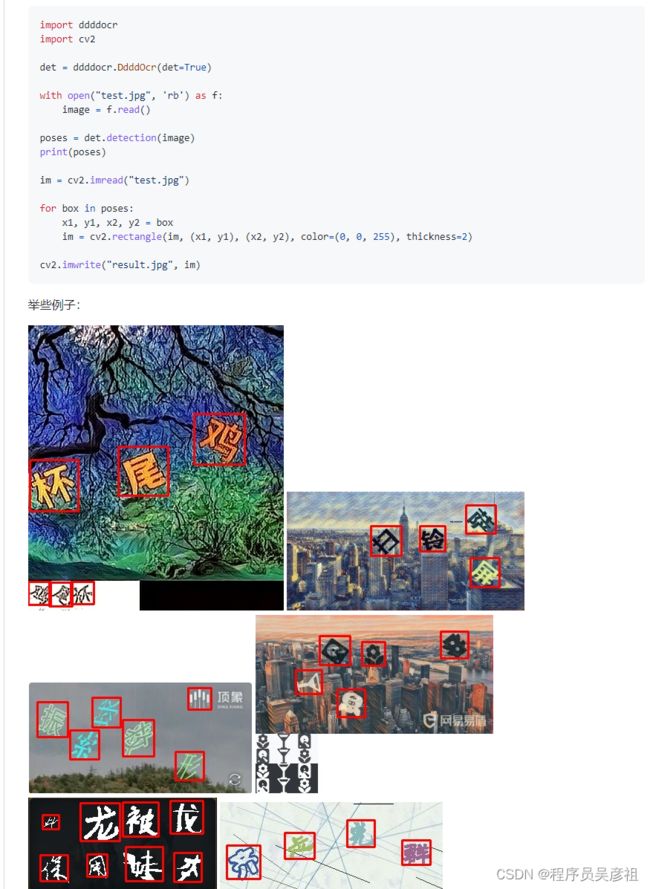
这里可以点进去看一下ddddocr的官方文档,可以看到,ddddocr具体基本的文字和图形检测功能,经测试,使用ddddocr检测该类点选验证码数据集准确率高达95,所以完全可以使用ddddocr来做检测,具体代码在上述截图中也有,返回的poses是所有检测到的文字bbox,ddddocr还是能适用于大多数点选验证码的。
2、文字分类
有了具体的位置之后, 就需要做分类任务,当然做分类模型的话,也需要用到数据集,这里的数据集,就使用ddddocr检测之后的位置切片下来,然后使用超级鹰进行识别,我没记错的是超级鹰识别文字类型应该是2001类型
使用超级鹰标注后,具体的数据集,按照文字的分类建立文件夹,一个文件夹代表一个类,如下图:
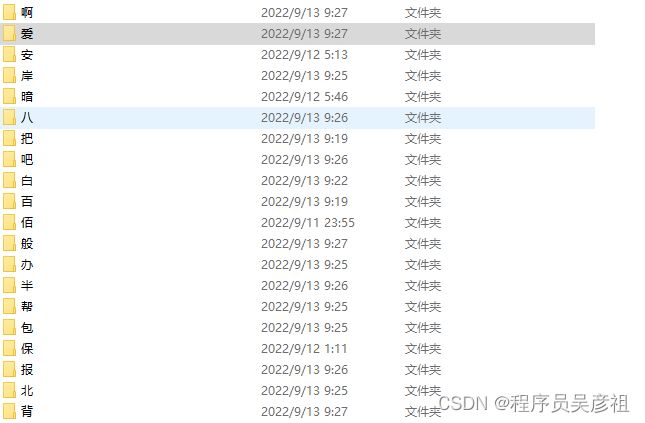

这里需要注意几个点,首先一个文字最好爬取个50张左右,当然,如果你的数据集比较简单,也可以适量减少,50张只是对于我的数据集有更好的效果,在采集的过程中可能会遇到标记错的图片,少量的话也没有关系,神经网络也会拟合
3、训练分类网络
然后就可以开始训练文字的分类网络了,这里我使用resnet50网络进行分类训练,目前我使用resnet50效果较好,以下是代码
1.导入库
import torch
from torch import nn
import torchvision.transforms as T
from torchvision import datasets
from torchvision import models
from torch.utils.data import DataLoader
from torch.optim.lr_scheduler import ReduceLROnPlateau
from tqdm import tqdm
import torch.nn.functional as F
import time
import os
import cv2
from PIL import Image
import numpy as np
2.加载数据集和加载器
在获取数据集之前,还要有一个文本字库,这个自己收集就行,如下图。

这里由于之前爬取的数据集都是按分类建立文件夹的,所以这里使用datasets里面的ImageFolder读取目录就行,文字图片统一大小为(64,64)
DEVICE = torch.device('cuda:1') # 使用第二张显卡
BATCH_SIZE = 2048
label_map = [i for i in os.listdir('./alldata/test')]
CAPTCHA_CHARS = len(label_map) # 分类数
train_set = datasets.ImageFolder(
'./alldata/train',
transform=T.Compose([
#to_rgb,
#T.ToPILImage(),
T.Resize((64, 64)),
#T.RandomRotation(10, fill=255, expand=True),
T.ColorJitter(hue=.05, saturation=.05),
T.RandomResizedCrop((64, 64), scale=(0.8, 1)),
T.Resize((64, 64)),
T.ToTensor(),
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]))
valid_set = datasets.ImageFolder(
'./alldata/test',
transform=T.Compose([
#to_rgb,
#T.ToPILImage(),
T.Resize((64, 64)),
T.ToTensor(),
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
)
train_loader = DataLoader(dataset=train_set, batch_size=BATCH_SIZE, shuffle=True, num_workers=4)
valid_loader = DataLoader(dataset=valid_set, batch_size=8, shuffle=False, num_workers=0)
3、加载模型
直接使用迁移学习中的resnet50,使用sgd随机梯度下降,损失函数使用交叉熵
model = models.resnet50(num_classes=CAPTCHA_CHARS)
#model = resnet50(num_classes=CAPTCHA_CHARS)
model = model.to(DEVICE)
# optimizer = torch.optim.Adam(model.parameters())
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9, weight_decay=0.01)
loss_func = nn.CrossEntropyLoss()
scheduler = ReduceLROnPlateau(optimizer, mode='min', patience=3,factor=0.98,min_lr=0.0001)
start_epoch = 0
4、开始训练
sum_strat = time.time()
for epoch in range(start_epoch, 500):
start = time.time()
# Train
model.train()
bar = tqdm(train_loader)
for x, label in bar:
x, label = x.to(DEVICE), label.to(DEVICE)
out = model(x)
loss = loss_func(out, label)
# 快乐三步曲
optimizer.zero_grad()
loss.backward()
optimizer.step()
lr = optimizer.param_groups[0]['lr']
bar.set_description("Train epoch %d, loss %.4f, lr %.6f" % (
epoch, loss.detach().cpu().numpy(), lr
))
# Valid
model.eval()
bar = tqdm(valid_loader)
total_loss = num_loss = 0
correct = top10 = count = 0
for x, label in bar:
x, label = x.to(DEVICE), label.to(DEVICE)
out = model(x)
loss = loss_func(out, label)
predict = out.topk(10, dim=1).indices
total_loss += float(loss)
num_loss += 1
count += x.shape[0]
correct += (predict[:, 0] == label).sum()
for i in range(10):
top10 += (predict[:, i] == label).sum()
lr = optimizer.param_groups[0]['lr']
bar.set_description("Eval epoch %d, acc %.4f, top10 %.4f, loss %.4f, lr %.6f" % (
epoch, float(correct) / float(count), float(top10) / float(count), loss.detach().cpu().numpy(), lr
))
scheduler.step(total_loss / num_loss)
# torch.save(model.state_dict(), "./save_%d.model" % epoch)
end = time.time()
print("epoch ", epoch, "time ", end-start)
# 断点续训保存模型
checkpoint = {
"net": model.state_dict(),
'optimizer':optimizer.state_dict(),
"epoch": epoch
}
torch.save(checkpoint, './models/ckpt_best.pth')
sum_end = time.time()
print("总计所有时间:", sum_end - sum_strat)
5、查看准确率
通过命令行的输出显示可以看到,最终的acc准确率高达97,top10的准确率的高达99

6、保存为onnx模型
我这里保存onnx模型是为了方便脱离环境使用,这个看具体需求
import datetime
now = str(datetime.datetime.now()).split()[0]
batch_size = 1 #批处理大小
input_shape = (3, 64, 64) #输入数据,改成自己的输入shape
x = torch.randn(batch_size, *input_shape) # 生成张量
x = x.to(DEVICE)
export_onnx_file = "./onnx/font_classification" + now + ".onnx" # 目的ONNX文件名
torch.onnx.export(model,
x,
export_onnx_file,
opset_version=10,
do_constant_folding=True, # 是否执行常量折叠优化
input_names=["input"], # 输入名
output_names=["output"], # 输出名
dynamic_axes={"input":{0:"batch_size"}, # 批处理变量
"output":{0:"batch_size"}})
print("保存为", export_onnx_file)
# 保存字典
with open("./onnx/font_classification" + now + ".txt", "w") as f:
f.write(str(train_set.classes))
4、完整测试
有了ddddocr的位置检测和resnet50分类模型后,就可以合在一起做完整测试了
首先读取onnx模型,再读取图片,利用ddddocr检测出目标,再通过cv2转换成ndarray格式,然后循环bbox,去除较小的框(可能太小不是文字),转换图片尺寸,归一化后,利用分类模型获得预测文字,将文字进行匹配即可
def normalization2batch(image_array):
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
image_array = image_array.transpose(2, 0, 1)
image_array = np.array(image_array, dtype=np.float32)
# 归一化
image_array = image_array / 255.0
for i in range(3):
image_array[i, :, :] = (image_array[i, :, :] - mean[i]) / std[i]
image_array = np.expand_dims(image_array, 0) # 增加一个维度
return image_array
font_model = ort.InferenceSession(os.path.join(model_path, "font_classification.onnx"),
providers=['CPUExecutionProvider',])
image = open("test.jpg", "rb").read()
poses = self.det.detection(image)
image_array = cv2.imdecode(np.array(bytearray(image), dtype='uint8'), cv2.IMREAD_UNCHANGED)
# 查看是否有四通道,如果有,只取三通道
image_array = self.BGRA2BGR(image_array)
end_fonts = [] # 没有找到坐标的字体
# 先查top1字体
for i, box in enumerate(poses):
x1, y1, x2, y2 = box
if x2 - x1 < 15 or y2 - y1 < 15: continue
font_img = image_array[y1:y2 + 1, x1:x2 + 1, ]
# cv2.imwrite(str(i) + str(i) + ".png", font_img)
font_img = cv2.resize(font_img, (64, 64))
font_img = normalization2batch(font_img)
input_ = font_model.get_inputs()[0].name
pred = font_model.run(None, {input_: font_img})[0][0]
font = pred.argsort()[::-1][0]
print(font_lib[font], box)
我们找一张图片来进行测试

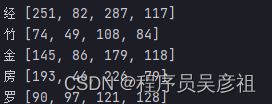
可以看到,准确率还是可以的