基于PaddlePaddle的飞桨论文解读:StarGAN v2: Diverse Image Synthesis for Multiple Domains
目录
摘要
StarGAN v2网络架构
实验
1.Baselines
2.数据集
3.评价指标
实验结果分析
1.个别成分分析
2.多种图像合成方法的比较
结论
模型代码(model.py)
主体代码(main.py)
总结
摘要
一个好的图像到图像的翻译模型应该学习不同视觉域之间的映射,同时满足以下特性:1)生成图像的多样性 2)多域的可伸缩性。现有的方法解决了这两个问题中的任何一个,其多样性有限,或者所有领域都有多个模型。我们提出了starganv2,一个单一的框架,它可以同时处理这两个问题,并在基线上显示出显著改进的结果。在CelebAHQ和一个新的动物面孔数据集(AFHQ)上的实验验证了我们在视觉质量、多样性和可扩展性方面的优势。为了更好地评估图像到图像的转换模型,我们发布了AFHQ,高质量的动物脸,具有较大的域间和域内差异。
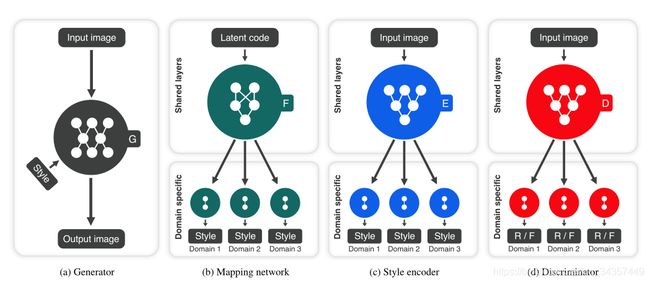
StarGAN v2网络架构
- Generator
- Mapping network
- Style encoder
- Discriminator
实验
1.Baselines
我们使用MUNIT、DRIT和MSGAN作为Baselines,它们都学习两个域之间的多模映射。对于多域比较,我们为每对图像域多次训练这些模型。我们还将我们的方法与StarGAN进行了比较,StarGAN使用单个生成器学习多个域之间的映射。所有Baselines都是使用作者提供的实现进行训练的。
2.数据集
我们评估CelebA HQ上的StarGAN v2和我们新的AFHQ数据集,我们将CelebAHQ分为两个领域:雄性和雌性;AFHQ分为三个领域:猫、狗和野生动物。除域名标签外,我们不使用任何附加信息(如CelebA HQ的面部特征或AFHQ的品种),并让模型在没有监督的情况下学习样式等信息。为了公平比较,所有的图像都被调整到256×256分辨率,这是baseline中使用的最高分辨率。
3.评价指标
我们使用Frechet inception distance (FID)和learning perceptual image patch similarity (LPIPS)来评估生成图像的视觉质量和多样性。我们为数据集中的每对图像域计算FID和LPIPS,并报告它们的平均值。
实验结果分析
1.个别成分分析
使用CelebA-HQ来评估添加到baseline的StarGAN中的单个成分。表格给出了几种配置的FID和LPIPS,其中每个组件都是在StarGAN上累积添加的。每个配置的输入图像和相应生成的图像如图所示。baseline设置对应于StarGAN的基本设置,使用WGAN-GP、ACGAN鉴别器、深度级联为生成器提供目标域信息。如图所示,通过在输入图像上应用化妆品,原始StarGAN只产生一个局部变化。
我们首先通过用多任务鉴别器替换ACGAN鉴别器来改进baseline,允许生成器转换输入图像的全局结构,并且通过应用R1正则化并将深度连接转换为自适应实例规范化(AdaIN),进一步提高了训练的稳定性并构造了一个新的基线(C)。

2.多种图像合成方法的比较
- 潜在引导合成
CelebAHQ与baseline模型相比,我们的方法合成的图像具有更高的视觉质量。此外,我们的方法是唯一能够成功地改变源图像的整个发型的模型,这需要非常大的努力(例如生成耳朵)。对于变化较大的AFHQ,基线的性能大大降低,而我们的方法仍然可以生成高质量和多样化的图像。
- 参考指导合成
从目标域中抽取测试图像,并将它们馈送给每种方法的编码器网络。对于CelebA HQ,我们的方法成功地渲染了独特的样式(例如刘海、胡须、化妆品和发型),而其他方法大多与参考图像的颜色分布相匹配。对于更具挑战性的AFHQ,baseline模型会经历一个大的域转移。它们很难反映每个参考图像的风格,只与域匹配。相比之下,该模型渲染每个参考图像的不同风格(例如品种),以及它的皮毛图案和眼睛颜色。
结论
本文的模型解决了图像到图像转换的两个主要挑战:将一个域的图像转换为目标域的不同图像,以及支持多个目标域。实验结果表明,我们的模型可以在多个领域生成风格丰富的图像,显著优于以前的主流方法[16,28,34]。另外还发布了一个新的动物脸数据集(AFHQ),用于在一个大的域间和域内变化环境中评估方法。
模型代码(model.py)
"""
StarGAN v2
Copyright (c) 2020-present NAVER Corp.
This work is licensed under the Creative Commons Attribution-NonCommercial
4.0 International License. To view a copy of this license, visit
http://creativecommons.org/licenses/by-nc/4.0/ or send a letter to
Creative Commons, PO Box 1866, Mountain View, CA 94042, USA.
"""
import copy
import math
from munch import Munch
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from core.wing import FAN
class ResBlk(nn.Module):
def __init__(self, dim_in, dim_out, actv=nn.LeakyReLU(0.2),
normalize=False, downsample=False):
super().__init__()
self.actv = actv
self.normalize = normalize
self.downsample = downsample
self.learned_sc = dim_in != dim_out
self._build_weights(dim_in, dim_out)
def _build_weights(self, dim_in, dim_out):
self.conv1 = nn.Conv2d(dim_in, dim_in, 3, 1, 1)
self.conv2 = nn.Conv2d(dim_in, dim_out, 3, 1, 1)
if self.normalize:
self.norm1 = nn.InstanceNorm2d(dim_in, affine=True)
self.norm2 = nn.InstanceNorm2d(dim_in, affine=True)
if self.learned_sc:
self.conv1x1 = nn.Conv2d(dim_in, dim_out, 1, 1, 0, bias=False)
def _shortcut(self, x):
if self.learned_sc:
x = self.conv1x1(x)
if self.downsample:
x = F.avg_pool2d(x, 2)
return x
def _residual(self, x):
if self.normalize:
x = self.norm1(x)
x = self.actv(x)
x = self.conv1(x)
if self.downsample:
x = F.avg_pool2d(x, 2)
if self.normalize:
x = self.norm2(x)
x = self.actv(x)
x = self.conv2(x)
return x
def forward(self, x):
x = self._shortcut(x) + self._residual(x)
return x / math.sqrt(2) # unit variance
class AdaIN(nn.Module):
def __init__(self, style_dim, num_features):
super().__init__()
self.norm = nn.InstanceNorm2d(num_features, affine=False)
self.fc = nn.Linear(style_dim, num_features*2)
def forward(self, x, s):
h = self.fc(s)
h = h.view(h.size(0), h.size(1), 1, 1)
gamma, beta = torch.chunk(h, chunks=2, dim=1)
return (1 + gamma) * self.norm(x) + beta
class AdainResBlk(nn.Module):
def __init__(self, dim_in, dim_out, style_dim=64, w_hpf=0,
actv=nn.LeakyReLU(0.2), upsample=False):
super().__init__()
self.w_hpf = w_hpf
self.actv = actv
self.upsample = upsample
self.learned_sc = dim_in != dim_out
self._build_weights(dim_in, dim_out, style_dim)
def _build_weights(self, dim_in, dim_out, style_dim=64):
self.conv1 = nn.Conv2d(dim_in, dim_out, 3, 1, 1)
self.conv2 = nn.Conv2d(dim_out, dim_out, 3, 1, 1)
self.norm1 = AdaIN(style_dim, dim_in)
self.norm2 = AdaIN(style_dim, dim_out)
if self.learned_sc:
self.conv1x1 = nn.Conv2d(dim_in, dim_out, 1, 1, 0, bias=False)
def _shortcut(self, x):
if self.upsample:
x = F.interpolate(x, scale_factor=2, mode='nearest')
if self.learned_sc:
x = self.conv1x1(x)
return x
def _residual(self, x, s):
x = self.norm1(x, s)
x = self.actv(x)
if self.upsample:
x = F.interpolate(x, scale_factor=2, mode='nearest')
x = self.conv1(x)
x = self.norm2(x, s)
x = self.actv(x)
x = self.conv2(x)
return x
def forward(self, x, s):
out = self._residual(x, s)
if self.w_hpf == 0:
out = (out + self._shortcut(x)) / math.sqrt(2)
return out
class HighPass(nn.Module):
def __init__(self, w_hpf, device):
super(HighPass, self).__init__()
self.filter = torch.tensor([[-1, -1, -1],
[-1, 8., -1],
[-1, -1, -1]]).to(device) / w_hpf
def forward(self, x):
filter = self.filter.unsqueeze(0).unsqueeze(1).repeat(x.size(1), 1, 1, 1)
return F.conv2d(x, filter, padding=1, groups=x.size(1))
class Generator(nn.Module):
def __init__(self, img_size=256, style_dim=64, max_conv_dim=512, w_hpf=1):
super().__init__()
dim_in = 2**14 // img_size
self.img_size = img_size
self.from_rgb = nn.Conv2d(3, dim_in, 3, 1, 1)
self.encode = nn.ModuleList()
self.decode = nn.ModuleList()
self.to_rgb = nn.Sequential(
nn.InstanceNorm2d(dim_in, affine=True),
nn.LeakyReLU(0.2),
nn.Conv2d(dim_in, 3, 1, 1, 0))
# down/up-sampling blocks
repeat_num = int(np.log2(img_size)) - 4
if w_hpf > 0:
repeat_num += 1
for _ in range(repeat_num):
dim_out = min(dim_in*2, max_conv_dim)
self.encode.append(
ResBlk(dim_in, dim_out, normalize=True, downsample=True))
self.decode.insert(
0, AdainResBlk(dim_out, dim_in, style_dim,
w_hpf=w_hpf, upsample=True)) # stack-like
dim_in = dim_out
# bottleneck blocks
for _ in range(2):
self.encode.append(
ResBlk(dim_out, dim_out, normalize=True))
self.decode.insert(
0, AdainResBlk(dim_out, dim_out, style_dim, w_hpf=w_hpf))
if w_hpf > 0:
device = torch.device(
'cuda' if torch.cuda.is_available() else 'cpu')
self.hpf = HighPass(w_hpf, device)
def forward(self, x, s, masks=None):
x = self.from_rgb(x)
cache = {}
for block in self.encode:
if (masks is not None) and (x.size(2) in [32, 64, 128]):
cache[x.size(2)] = x
x = block(x)
for block in self.decode:
x = block(x, s)
if (masks is not None) and (x.size(2) in [32, 64, 128]):
mask = masks[0] if x.size(2) in [32] else masks[1]
mask = F.interpolate(mask, size=x.size(2), mode='bilinear')
x = x + self.hpf(mask * cache[x.size(2)])
return self.to_rgb(x)
class MappingNetwork(nn.Module):
def __init__(self, latent_dim=16, style_dim=64, num_domains=2):
super().__init__()
layers = []
layers += [nn.Linear(latent_dim, 512)]
layers += [nn.ReLU()]
for _ in range(3):
layers += [nn.Linear(512, 512)]
layers += [nn.ReLU()]
self.shared = nn.Sequential(*layers)
self.unshared = nn.ModuleList()
for _ in range(num_domains):
self.unshared += [nn.Sequential(nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, style_dim))]
def forward(self, z, y):
h = self.shared(z)
out = []
for layer in self.unshared:
out += [layer(h)]
out = torch.stack(out, dim=1) # (batch, num_domains, style_dim)
idx = torch.LongTensor(range(y.size(0))).to(y.device)
s = out[idx, y] # (batch, style_dim)
return s
class StyleEncoder(nn.Module):
def __init__(self, img_size=256, style_dim=64, num_domains=2, max_conv_dim=512):
super().__init__()
dim_in = 2**14 // img_size
blocks = []
blocks += [nn.Conv2d(3, dim_in, 3, 1, 1)]
repeat_num = int(np.log2(img_size)) - 2
for _ in range(repeat_num):
dim_out = min(dim_in*2, max_conv_dim)
blocks += [ResBlk(dim_in, dim_out, downsample=True)]
dim_in = dim_out
blocks += [nn.LeakyReLU(0.2)]
blocks += [nn.Conv2d(dim_out, dim_out, 4, 1, 0)]
blocks += [nn.LeakyReLU(0.2)]
self.shared = nn.Sequential(*blocks)
self.unshared = nn.ModuleList()
for _ in range(num_domains):
self.unshared += [nn.Linear(dim_out, style_dim)]
def forward(self, x, y):
h = self.shared(x)
h = h.view(h.size(0), -1)
out = []
for layer in self.unshared:
out += [layer(h)]
out = torch.stack(out, dim=1) # (batch, num_domains, style_dim)
idx = torch.LongTensor(range(y.size(0))).to(y.device)
s = out[idx, y] # (batch, style_dim)
return s
class Discriminator(nn.Module):
def __init__(self, img_size=256, num_domains=2, max_conv_dim=512):
super().__init__()
dim_in = 2**14 // img_size
blocks = []
blocks += [nn.Conv2d(3, dim_in, 3, 1, 1)]
repeat_num = int(np.log2(img_size)) - 2
for _ in range(repeat_num):
dim_out = min(dim_in*2, max_conv_dim)
blocks += [ResBlk(dim_in, dim_out, downsample=True)]
dim_in = dim_out
blocks += [nn.LeakyReLU(0.2)]
blocks += [nn.Conv2d(dim_out, dim_out, 4, 1, 0)]
blocks += [nn.LeakyReLU(0.2)]
blocks += [nn.Conv2d(dim_out, num_domains, 1, 1, 0)]
self.main = nn.Sequential(*blocks)
def forward(self, x, y):
out = self.main(x)
out = out.view(out.size(0), -1) # (batch, num_domains)
idx = torch.LongTensor(range(y.size(0))).to(y.device)
out = out[idx, y] # (batch)
return out
def build_model(args):
generator = Generator(args.img_size, args.style_dim, w_hpf=args.w_hpf)
mapping_network = MappingNetwork(args.latent_dim, args.style_dim, args.num_domains)
style_encoder = StyleEncoder(args.img_size, args.style_dim, args.num_domains)
discriminator = Discriminator(args.img_size, args.num_domains)
generator_ema = copy.deepcopy(generator)
mapping_network_ema = copy.deepcopy(mapping_network)
style_encoder_ema = copy.deepcopy(style_encoder)
nets = Munch(generator=generator,
mapping_network=mapping_network,
style_encoder=style_encoder,
discriminator=discriminator)
nets_ema = Munch(generator=generator_ema,
mapping_network=mapping_network_ema,
style_encoder=style_encoder_ema)
if args.w_hpf > 0:
fan = FAN(fname_pretrained=args.wing_path).eval()
nets.fan = fan
nets_ema.fan = fan
return nets, nets_ema主体代码(main.py)
"""
StarGAN v2
Copyright (c) 2020-present NAVER Corp.
This work is licensed under the Creative Commons Attribution-NonCommercial
4.0 International License. To view a copy of this license, visit
http://creativecommons.org/licenses/by-nc/4.0/ or send a letter to
Creative Commons, PO Box 1866, Mountain View, CA 94042, USA.
"""
import os
import argparse
from munch import Munch
from torch.backends import cudnn
import torch
from core.data_loader import get_train_loader
from core.data_loader import get_test_loader
from core.solver import Solver
def str2bool(v):
return v.lower() in ('true')
def subdirs(dname):
return [d for d in os.listdir(dname)
if os.path.isdir(os.path.join(dname, d))]
def main(args):
print(args)
cudnn.benchmark = True
torch.manual_seed(args.seed)
solver = Solver(args)
if args.mode == 'train':
assert len(subdirs(args.train_img_dir)) == args.num_domains
assert len(subdirs(args.val_img_dir)) == args.num_domains
loaders = Munch(src=get_train_loader(root=args.train_img_dir,
which='source',
img_size=args.img_size,
batch_size=args.batch_size,
prob=args.randcrop_prob,
num_workers=args.num_workers),
ref=get_train_loader(root=args.train_img_dir,
which='reference',
img_size=args.img_size,
batch_size=args.batch_size,
prob=args.randcrop_prob,
num_workers=args.num_workers),
val=get_test_loader(root=args.val_img_dir,
img_size=args.img_size,
batch_size=args.val_batch_size,
shuffle=True,
num_workers=args.num_workers))
solver.train(loaders)
elif args.mode == 'sample':
assert len(subdirs(args.src_dir)) == args.num_domains
assert len(subdirs(args.ref_dir)) == args.num_domains
loaders = Munch(src=get_test_loader(root=args.src_dir,
img_size=args.img_size,
batch_size=args.val_batch_size,
shuffle=False,
num_workers=args.num_workers),
ref=get_test_loader(root=args.ref_dir,
img_size=args.img_size,
batch_size=args.val_batch_size,
shuffle=False,
num_workers=args.num_workers))
solver.sample(loaders)
elif args.mode == 'eval':
solver.evaluate()
elif args.mode == 'align':
from core.wing import align_faces
align_faces(args, args.inp_dir, args.out_dir)
else:
raise NotImplementedError
if __name__ == '__main__':
parser = argparse.ArgumentParser()
# model arguments
parser.add_argument('--img_size', type=int, default=256,
help='Image resolution')
parser.add_argument('--num_domains', type=int, default=2,
help='Number of domains')
parser.add_argument('--latent_dim', type=int, default=16,
help='Latent vector dimension')
parser.add_argument('--hidden_dim', type=int, default=512,
help='Hidden dimension of mapping network')
parser.add_argument('--style_dim', type=int, default=64,
help='Style code dimension')
# weight for objective functions
parser.add_argument('--lambda_reg', type=float, default=1,
help='Weight for R1 regularization')
parser.add_argument('--lambda_cyc', type=float, default=1,
help='Weight for cyclic consistency loss')
parser.add_argument('--lambda_sty', type=float, default=1,
help='Weight for style reconstruction loss')
parser.add_argument('--lambda_ds', type=float, default=1,
help='Weight for diversity sensitive loss')
parser.add_argument('--ds_iter', type=int, default=100000,
help='Number of iterations to optimize diversity sensitive loss')
parser.add_argument('--w_hpf', type=float, default=1,
help='weight for high-pass filtering')
# training arguments
parser.add_argument('--randcrop_prob', type=float, default=0.5,
help='Probabilty of using random-resized cropping')
parser.add_argument('--total_iters', type=int, default=100000,
help='Number of total iterations')
parser.add_argument('--resume_iter', type=int, default=0,
help='Iterations to resume training/testing')
parser.add_argument('--batch_size', type=int, default=8,
help='Batch size for training')
parser.add_argument('--val_batch_size', type=int, default=32,
help='Batch size for validation')
parser.add_argument('--lr', type=float, default=1e-4,
help='Learning rate for D, E and G')
parser.add_argument('--f_lr', type=float, default=1e-6,
help='Learning rate for F')
parser.add_argument('--beta1', type=float, default=0.0,
help='Decay rate for 1st moment of Adam')
parser.add_argument('--beta2', type=float, default=0.99,
help='Decay rate for 2nd moment of Adam')
parser.add_argument('--weight_decay', type=float, default=1e-4,
help='Weight decay for optimizer')
parser.add_argument('--num_outs_per_domain', type=int, default=10,
help='Number of generated images per domain during sampling')
# misc
parser.add_argument('--mode', type=str, required=True,
choices=['train', 'sample', 'eval', 'align'],
help='This argument is used in solver')
parser.add_argument('--num_workers', type=int, default=4,
help='Number of workers used in DataLoader')
parser.add_argument('--seed', type=int, default=777,
help='Seed for random number generator')
# directory for training
parser.add_argument('--train_img_dir', type=str, default='data/celeba_hq/train',
help='Directory containing training images')
parser.add_argument('--val_img_dir', type=str, default='data/celeba_hq/val',
help='Directory containing validation images')
parser.add_argument('--sample_dir', type=str, default='expr/samples',
help='Directory for saving generated images')
parser.add_argument('--checkpoint_dir', type=str, default='expr/checkpoints',
help='Directory for saving network checkpoints')
# directory for calculating metrics
parser.add_argument('--eval_dir', type=str, default='expr/eval',
help='Directory for saving metrics, i.e., FID and LPIPS')
# directory for testing
parser.add_argument('--result_dir', type=str, default='expr/results',
help='Directory for saving generated images and videos')
parser.add_argument('--src_dir', type=str, default='assets/representative/celeba_hq/src',
help='Directory containing input source images')
parser.add_argument('--ref_dir', type=str, default='assets/representative/celeba_hq/ref',
help='Directory containing input reference images')
parser.add_argument('--inp_dir', type=str, default='assets/representative/custom/female',
help='input directory when aligning faces')
parser.add_argument('--out_dir', type=str, default='assets/representative/celeba_hq/src/female',
help='output directory when aligning faces')
# face alignment
parser.add_argument('--wing_path', type=str, default='expr/checkpoints/wing.ckpt')
parser.add_argument('--lm_path', type=str, default='expr/checkpoints/celeba_lm_mean.npz')
# step size
parser.add_argument('--print_every', type=int, default=10)
parser.add_argument('--sample_every', type=int, default=5000)
parser.add_argument('--save_every', type=int, default=10000)
parser.add_argument('--eval_every', type=int, default=50000)
args = parser.parse_args()
main(args)
总结
- 要把pytorch框架的代码读熟注释,初步理解论文大体内容
- 查阅paddlepaddle的API函数,并复现代码